����֪ʶ
ΪʲôҪʹ�ò������(������̵��ŵ�)
������ö��CPU�ļ�������:ͨ��������̵���ʽ���Խ����CPU�ļ����������ӵ�����,���ܵõ�����
�������ҵ����,����ϵͳ��������������:�������ҵ����,����ľ��ʺ��ڲ�����̡����ڵ�ϵͳ��������Ҫ���������ǧ�IJ�����,�����̲߳���������ǿ����߲���ϵͳ�Ļ���,���úö��̻߳��ƿ��Դ�����ϵͳ����IJ��������Լ����ܡ���Ը���ҵ��ģ��,���г����ȴ��г������Ӧҵ������,��������̸����Ǻ�����ҵ���� ��
���������ʲôȱ��
������̵�Ŀ�ľ���Ϊ������߳����ִ��Ч��,��߳��������ٶ�,���Dz�����̲�����������߳��������ٶȵ�,���Ҳ�����̿��ܻ������ܶ�����,����:�ڴ�й©���������л����̰߳�ȫ�����������⡣
���������Ҫ����ʲô?�� Java ��������ô��֤���̵߳����а�ȫ?
���������Ҫ��(�̵߳İ�ȫ������������):
ԭ����:ԭ��,��һ�������ٱ��ָ�Ŀ�����ԭ����ָ����һ����������Ҫôȫ��ִ�гɹ�Ҫôȫ��ִ��ʧ�ܡ�(synchronized,lock,����������)
�ɼ���:һ���̶߳Թ�����������,��һ���߳��ܹ����̿�����(synchronized,volatile)
������:����ִ�е�˳���մ�����Ⱥ�˳��ִ�С�(���������ܻ��ָ�����������)(volatile)
�����̰߳�ȫ�����ԭ��:
-
�߳��л�������ԭ��������
-
���浼�µĿɼ�������
-
�����Ż�����������������
����취:
- JDK Atomic��ͷ��ԭ���ࡢsynchronized��LOCK,���Խ��ԭ��������
- synchronized��volatile��LOCK,���Խ���ɼ�������
- Happens-Before ����,volatile���Խ������������
���кͲ�����ʲô����?
����:���������ͬһ�� CPU ����,��ϸ�ֵ�ʱ��Ƭ����(����)ִ��,������������Щ������ͬʱִ�С�
����:��λʱ����,������������˴�����ͬʱ�����������,�����������ϵġ�ͬʱ���С���
����:��n������,��һ���̰߳�˳��ִ�С���������������һ���߳�ִ�����Բ������̲߳���ȫ���,Ҳ�Ͳ������ٽ��������⡣
��һ������ı���:
���� = �������к�һ̨���Ȼ���
���� = �������к���̨���Ȼ���
���� = һ�����к�һ̨���Ȼ���
ʲô�Ƕ��߳�,���̵߳�����?
���߳�:���߳���ָ�����а������ִ����,����һ�������п���ͬʱ���ж����ͬ���߳���ִ�в�ͬ������
���̵߳ĺô�:
������� CPU �������ʡ��ڶ��̳߳�����,һ���̱߳���ȴ���ʱ��,CPU ���������������̶߳����ǵȴ�,�����ʹ������˳����Ч�ʡ�Ҳ����˵�������������������ִ�е��߳�����ɸ��Ե�����
���̵߳�����:
�߳�Ҳ�dz���,�����߳���Ҫռ���ڴ�,�߳�Խ��ռ���ڴ�ҲԽ��;
���߳���ҪЭ������,������Ҫ CPU ʱ������߳�;
�߳�֮��Թ�����Դ�ķ��ʻ��Ӱ��,���������ù�����Դ�����⡣
�ڴ�й©���������л����̰߳�ȫ������
ʲô���̺߳ͽ���?
����
һ�����ڴ������е�Ӧ�ó���ÿ�����̶����Լ�������һ���ڴ�ռ�,һ�����̿����ж���߳�,������Windowsϵͳ��,һ�����е�xx.exe����һ�����̡�
�߳�
�����е�һ��ִ������(���Ƶ�Ԫ),����ǰ�����г����ִ�С�һ������������һ���߳�,һ�����̿������ж���߳�,����߳̿ɹ������ݡ�
�������̵߳�����
�߳̾������ഫͳ���������е�����,���ֳ�Ϊ���ͽ���(Light��Weight Process)�����Ԫ;���Ѵ�ͳ�Ľ��̳�Ϊ���ͽ���(Heavy��Weight Process),���൱��ֻ��һ���̵߳��������������̵߳IJ���ϵͳ��,ͨ��һ�����̶������ɸ��߳�,���ٰ���һ���̡߳�
��������:�����Dz���ϵͳ��Դ����Ļ�����λ,���߳��Ǵ�����������Ⱥ�ִ�еĻ�����λ
��Դ����:ÿ�����̶��ж����Ĵ�������ݿռ�(����������),����֮����л����нϴ�Ŀ���;�߳̿��Կ����������Ľ���,ͬһ���̹߳�����������ݿռ�,ÿ���̶߳����Լ�����������ջ�ͳ��������(PC),�߳�֮���л��Ŀ���С��
������ϵ:���һ���������ж���߳�,��ִ�й��̲���һ���ߵ�,���Ƕ�����(�߳�)��ͬ��ɵ�;�߳��ǽ��̵�һ����,�����߳�Ҳ����Ϊ��Ȩ���̻������������̡�
�ڴ����:ͬһ���̵��̹߳��������̵ĵ�ַ�ռ����Դ,������֮��ĵ�ַ�ռ����Դ���������
Ӱ���ϵ:һ�����̱�����,�ڱ���ģʽ�²�����������̲���Ӱ��,����һ���̱߳����������̶����������Զ����Ҫ�ȶ��߳̽�׳��
ִ�й���:ÿ�������Ľ����г������е���ڡ�˳��ִ�����кͳ�����ڡ������̲߳��ܶ���ִ��,����������Ӧ�ó�����,��Ӧ�ó����ṩ����߳�ִ�п���,���߾��ɲ���ִ��
ʲô���������л�?
���̱߳����һ���̵߳ĸ��������� CPU ���ĵĸ���,��һ�� CPU ����������ʱ��ֻ�ܱ�һ���߳�ʹ��,Ϊ������Щ�̶߳��ܵõ���Чִ��,CPU ��ȡ�IJ�����Ϊÿ���̷߳���ʱ��Ƭ����ת����ʽ����һ���̵߳�ʱ��Ƭ�����ʱ��ͻ����´��ھ���״̬�ø������߳�ʹ��,������̾�����һ���������л���
������˵����:��ǰ������ִ���� CPU ʱ��Ƭ�л�����һ������֮ǰ���ȱ����Լ���״̬,�Ա��´����л����������ʱ,�����ټ�����������״̬������ӱ��浽�ټ��صĹ��̾���һ���������л���
�������л�ͨ���Ǽ����ܼ��͵ġ�Ҳ����˵,����Ҫ�൱�ɹ۵Ĵ�����ʱ��,��ÿ�뼸ʮ�ϰٴε��л���,ÿ���л�����Ҫ����������ʱ�䡣����,�������л���ϵͳ��˵��ζ�����Ĵ����� CPU ʱ��,��ʵ��,�����Dz���ϵͳ��ʱ���������IJ�����
Linux �������������ϵͳ(���������� Unix ϵͳ)�кܶ���ŵ�,������һ�����,���������л���ģʽ�л���ʱ�����ķdz��١�
�ػ��̺߳��û��߳���ʲô������?
�û� (User) �߳�:������ǰ̨,ִ�о��������,���������̡߳�������������̵߳ȶ����û��߳�
�ػ� (Daemon) �߳�:�����ں�̨,Ϊ����ǰ̨�̷߳���Ҳ����˵�ػ��߳��� JVM �з��ػ��̵߳� ��Ӷ�ˡ���һ�������û��̶߳���������,�ػ��̻߳��� JVM һ���������
main �������ڵ��߳̾���һ���û��̰߳�,main ����������ͬʱ�� JVM �ڲ�ͬʱ�������˺ö��ػ��߳�,�������������̡߳�
�Ƚ����Ե�����֮һ���û��߳̽���,JVM �˳�,�������ʱ����û���ػ��߳����С����ػ��̲߳���Ӱ�� JVM ���˳���
ע������:
-
setDaemon(true)������start()����ǰִ��,������׳� IllegalThreadStateException �쳣
-
���ػ��߳��в��������߳�Ҳ���ػ��߳�
-
�������е������Է�����ػ��߳���ִ��,�����д������������
-
�ػ� (Daemon) �߳��в������� finally ���������ȷ��ִ�йرջ�������Դ��������Ϊ��������Ҳ˵����һ�������û��̶߳���������,�ػ��̻߳��� JVM һ���������,�����ػ� (Daemon) �߳��е� finally �����������ִ�С�
����� Windows �� Linux �ϲ����ĸ��߳�cpu���������?
windows�����������������,linux�¿����� top ������߿���
�ҳ�cpu���������Ľ���pid, �ն�ִ��top����,Ȼ����shift+p ���ҳ�cpu������������pid��
���������һ���õ���pid��,top -H -p pid ��Ȼ����shift+p,���ҳ�cpu���������������̺߳�,����top -H -p 1328
����ȡ�����̺߳�ת����16����,ȥ�ٶ�ת��һ�¾���
ʹ��jstack���߽�������Ϣ��ӡ���,jstack pid�� > /tmp/t.dat,����jstack 31365 > /tmp/t.dat
�༭/tmp/t.dat�ļ�,�����̺߳Ŷ�Ӧ����Ϣ
ʲô���߳�����
�ٶȰٿ�:������ָ�������������ϵĽ���(�߳�)��ִ�й�����,���ھ�����Դ�������ڱ˴�ͨ�Ŷ���ɵ�һ������������,������������,���Ƕ������ƽ���ȥ����ʱ��ϵͳ��������״̬��ϵͳ����������,��Щ��Զ�ڻ���ȴ��Ľ���(�߳�)��Ϊ��������(�߳�)��
����߳�ͬʱ������,�����е�һ������ȫ�����ڵȴ�ij����Դ���ͷš������̱߳������ڵ�����,��˳�����������ֹ��
����ͼ��ʾ,�߳� A ������Դ 2,�߳� B ������Դ 1,����ͬʱ��������Է�����Դ,�����������߳̾ͻụ��ȴ�����������״̬��
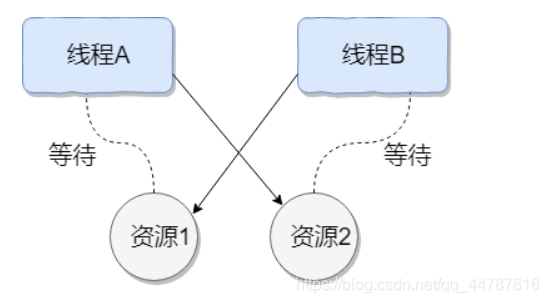
����ͨ��һ��������˵���߳�����,����ģ������ͼ�����������
public class DeadLockDemo {
private static Object resource1 = new Object();//��Դ 1
private static Object resource2 = new Object();//��Դ 2
public static void main(String[] args) {
new Thread(() -> {
synchronized (resource1) {
System.out.println(Thread.currentThread() + "get resource1");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread() + "waiting get resource2");
synchronized (resource2) {
System.out.println(Thread.currentThread() + "get resource2");
}
}
}, "�߳� 1").start();
new Thread(() -> {
synchronized (resource2) {
System.out.println(Thread.currentThread() + "get resource2");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread() + "waiting get resource1");
synchronized (resource1) {
System.out.println(Thread.currentThread() + "get resource1");
}
}
}, "�߳� 2").start();
}
}
�߳� A ͨ�� synchronized (resource1) ��� resource1 �ļ�������,Ȼ��ͨ��Thread.sleep(1000);���߳� A ���� 1s Ϊ�������߳� B �õ�CPUִ��Ȩ,Ȼ���ȡ�� resource2 �ļ����������߳� A ���߳� B ���߽����˶���ʼ��ͼ�����ȡ�Է�����Դ,Ȼ���������߳̾ͻ����뻥��ȴ���״̬,��Ҳ�Ͳ�������������������ӷ��ϲ����������ĸ���Ҫ������
�γ��������ĸ���Ҫ������ʲô
-
��������:�߳�(����)���������䵽����Դ����������,��һ����Դֻ�ܱ�һ���߳�(����)ռ��,ֱ�������߳�(����)�ͷ�
-
�����뱣������:һ���߳�(����)������ռ����Դ����������ʱ,���ѻ�õ���Դ���ֲ��š�
-
����������:�߳�(����)�ѻ�õ���Դ��ĩʹ����֮ǰ���ܱ������߳�ǿ�а���,ֻ���Լ�ʹ����Ϻ���ͷ���Դ��
-
ѭ���ȴ�����:����������ʱ,���ȴ����߳�(����)�ض����γ�һ����·(��������ѭ��),�����������
��α����߳�����
����ֻҪ�ƻ������������ĸ������е�����һ���Ϳ����ˡ�
new Thread(() -> {
synchronized (resource1) {
System.out.println(Thread.currentThread() + "get resource1");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread() + "waiting get resource2");
synchronized (resource2) {
System.out.println(Thread.currentThread() + "get resource2");
}
}
}, "�߳� 2").start();
�����̵߳����ַ�ʽ
�����߳������ַ�ʽ:
1���̳� Thread ��;
2��ʵ�� Runnable �ӿ�;
3��ʵ�� Callable �ӿ�;
4��ʹ�� Executors �����ഴ���̳߳�
�̳� Thread ��
public class MyThread extends Thread {
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + " run()��������ִ��...");
}
}
public class TheadTest {
public static void main(String[] args) {
MyThread myThread = new MyThread();
myThread.start();
System.out.println(Thread.currentThread().getName() + " main()����ִ�н���");
}
}
ʵ�� Runnable �ӿ�
public class MyRunnable implements Runnable {
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + " run()����ִ����...");
}
}
public class RunnableTest {
public static void main(String[] args) {
MyRunnable myRunnable = new MyRunnable();
Thread thread = new Thread(myRunnable);
thread.start();
System.out.println(Thread.currentThread().getName() + " main()����ִ�����");
}
}
ʵ�� Callable �ӿ�
��futureTask��ΪRunnable��Callable��������
public class MyCallable implements Callable<Integer> {
@Override
public Integer call() {
System.out.println(Thread.currentThread().getName() + " call()����ִ����...");
return 1;
}
}
public class CallableTest {
public static void main(String[] args) {
FutureTask<Integer> futureTask = new FutureTask<Integer>(new MyCallable());
Thread thread = new Thread(futureTask);
thread.start();
try {
Thread.sleep(1000);
System.out.println("���ؽ�� " + futureTask.get());
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + " main()����ִ�����");
}
}
ʹ��ThreadPoolExecutor
https://blog.csdn.net/qq_44787816/article/details/119023713
˵һ�� runnable �� callable ��ʲô����?
��ͬ��
���ǽӿ�
�����Ա�д���̳߳���
������Thread.start()�����߳�
��Ҫ����
Runnable �ӿ� run ��������ֵ,Callable �ӿ� call �����з���ֵ,�Ǹ�����,��Future��FutureTask��Ͽ���������ȡ�첽ִ�еĽ��
Runnable �ӿ� run ���������׳��쳣;Callable �ӿ� call ���������׳��쳣,���Ի�ȡ�쳣��Ϣ
ע:Callalbe�ӿ�֧�ַ���ִ�н��,��Ҫ����FutureTask.get()�õ�,�˷��������������̵ļ�������ִ��,��������ò���������
�̵߳� run()�� start()��ʲô����?
ÿ���̶߳���ͨ��ij���ض�Thread��������Ӧ�ķ���run()������������,run()������Ϊ�߳��塣ͨ������Thread���start()����������һ���̡߳�
start() �������������߳�,run() ��������ִ���̵߳�����ʱ���롣run() �����ظ�����,�� start() ֻ�ܵ���һ�Ρ�
start()����������һ���߳�,����ʵ���˶��߳����С�����start()��������ȴ�run���������ִ�����,����ֱ�Ӽ���ִ�������Ĵ���; ��ʱ�߳��Ǵ��ھ���״̬,��û�����С� Ȼ��ͨ����Thread����÷���run()�����������״̬, run()�������н���, ���߳���ֹ��Ȼ��CPU�ٵ��������̡߳�
run()�������ڱ��߳����,ֻ���߳����һ������,�����Ƕ��̵߳ġ� ���ֱ�ӵ���run(),��ʵ���൱���ǵ�����һ����ͨ��������,ֱ�Ӵ���run()��������ȴ�run()����ִ����ϲ���ִ������Ĵ���,����ִ��·������ֻ��һ��,������û���̵߳�����,�����ڶ��߳�ִ��ʱҪʹ��start()����������run()������
Ϊʲô���ǵ��� start() ����ʱ��ִ�� run() ����,Ϊʲô���Dz���ֱ�ӵ��� run() ����?
new һ�� Thread,�߳̽������½�״̬������ start() ����,������һ���̲߳�ʹ�߳̽����˾���״̬,�����䵽ʱ��Ƭ��Ϳ��Կ�ʼ�����ˡ� start() ��ִ���̵߳���Ӧ������,Ȼ���Զ�ִ�� run() ����������,���������Ķ��̹߳�����(New-Runnable-running)
��ֱ��ִ�� run() ����,��� run ��������һ�� main �߳��µ���ͨ����ȥִ��,��������ij���߳���ִ����,�����Ⲣ���Ƕ��̹߳�����
�ܽ�: ���� start �������������̲߳�ʹ�߳̽������״̬,�� run ����ֻ�� thread ��һ����ͨ��������,���������߳���ִ�С�
ʲô�� Callable �� Future?
Callable �ӿ������� Runnable,�����־Ϳ��Կ�������,���� Runnable ���᷵�ؽ��,�������׳����ؽ�����쳣,�� Callable ���ܸ�ǿ��һЩ,���߳�ִ�к�,���Է���ֵ,�������ֵ���Ա� Future �õ�,Ҳ����˵,Future �����õ��첽ִ������ķ���ֵ��
Future �ӿڱ�ʾ�첽����,��һ�����ܻ�û����ɵ��첽����Ľ��������˵ Callable���ڲ������,Future ���ڻ�ȡ�����
ʲô�� FutureTask
FutureTask ��ʾһ���첽���������FutureTask ������Դ���һ�� Callable �ľ���ʵ����,���Զ�����첽���������Ľ�����еȴ���ȡ���ж��Ƿ��Ѿ���ɡ�ȡ������Ȳ�����ֻ�е�������ɵ�ʱ��������ȡ��,���������δ��� get ��������������һ�� FutureTask ������ԶԵ����� Callable �� Runnable �Ķ�����а�װ,���� FutureTask Ҳ��Runnable �ӿڵ�ʵ����,���� FutureTask Ҳ���Է����̳߳��С�
˵˵�̵߳��������ڼ����ֻ���״̬?
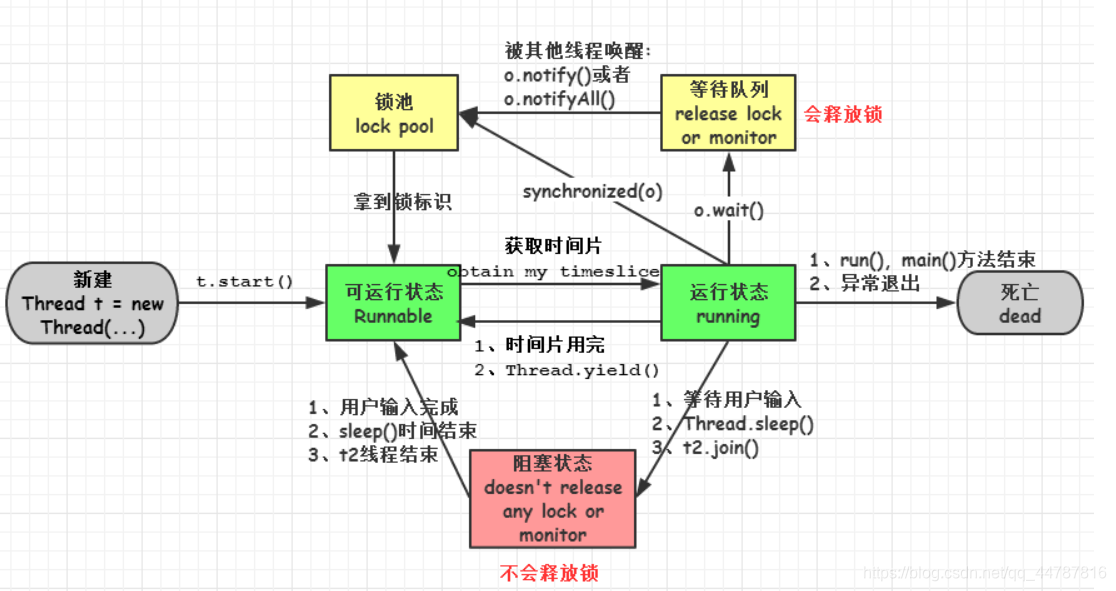
1���½�(new):�´�����һ���̶߳���
2��������(runnable):�̶߳�����,�������̶߳���� start()����,���̴߳��ھ���״̬,�ȴ����̵߳���ѡ��,��ȡcpu��ʹ��Ȩ��
3������(running):������״̬(runnable)���̻߳����cpuʱ��Ƭ(timeslice),ִ�г�����롣ע:����״̬�ǽ��뵽����״̬��Ψһ���,Ҳ����˵,�߳�Ҫ���������״ִ̬��,���ȱ��봦�ھ���״̬��;
4������(block):��������״̬�е��߳�����ij��ԭ��,��ʱ������ CPU��ʹ��Ȩ,ִֹͣ��,��ʱ��������״̬,ֱ������뵽����״̬,�� �л����ٴα� CPU �����Խ��뵽����״̬��
���������������:
(һ). �ȴ�����:����״̬�е��߳�ִ�� wait()����,JVM��Ѹ��̷߳���ȴ�����(waitting queue)��,ʹ���߳̽��뵽�ȴ�����״̬;
(��). ͬ������:�߳��ڻ�ȡ synchronized/lock.lock() ͬ����ʧ��(��Ϊ���������߳���ռ��),��JVM��Ѹ��̷߳�������(lock pool)��,�̻߳����ͬ������״̬;
(��). ��������: ͨ�������̵߳� sleep()�� join()���� I/O ����ʱ,�̻߳���뵽����״̬���� sleep()״̬��ʱ��join()�ȴ��߳���ֹ���߳�ʱ������ I/O �������ʱ,�߳�����ת�����״̬��
5������(dead):�߳�run()��main()����ִ�н���,�������쳣�˳���run()����,����߳̽����������ڡ��������̲߳����ٴθ�����
Java ���õ����̵߳����㷨��ʲô?
�����ͨ��ֻ��һ�� CPU,������ʱ��ֻ��ִ��һ������ָ��,ÿ���߳�ֻ�л��CPU ��ʹ��Ȩ����ִ��ָ���ν���̵߳IJ�������,��ʵ��ָ�Ӻ���Ͽ�,�����߳�������� CPU ��ʹ��Ȩ,�ֱ�ִ�и��Ե����������г���,���ж�����ھ���״̬���߳��ڵȴ� CPU,JAVA �������һ��������Ǹ����̵߳ĵ���,�̵߳�����ָ�����ض�����Ϊ����̷߳��� CPU ��ʹ��Ȩ��
�����ֵ���ģ��:��ʱ����ģ�ͺ���ռʽ����ģ�͡�
��ʱ����ģ����ָ�����е��߳�������� cpu ��ʹ��Ȩ,����ƽ������ÿ���߳�ռ�õ� CPU ��ʱ��Ƭ���Ҳ�ȽϺ����⡣
Java�����������ռʽ����ģ��,��ָ�����ÿ����г������ȼ��ߵ��߳�ռ��CPU,��������г��е��߳����ȼ���ͬ,��ô�����ѡ��һ���߳�,ʹ��ռ��CPU����������״̬���̻߳�һֱ����,ֱ�������ò����� CPU��
ʲô���̵߳�����(Thread Scheduler)��ʱ���Ƭ(Time Slicing )?
�̵߳�������һ������ϵͳ����,������Ϊ Runnable ״̬���̷߳��� CPU ʱ�䡣һ�����Ǵ���һ���̲߳�������,����ִ�б��������̵߳�������ʵ�֡�
ʱ���Ƭ��ָ�����õ� CPU ʱ���������õ� Runnable �̵߳Ĺ��̡����� CPU ʱ����Ի����߳����ȼ������̵߳ȴ���ʱ�䡣
�̵߳��Ȳ����ܵ� Java ���������,������Ӧ�ó������������Ǹ��õ�ѡ��(Ҳ����˵��Ҫ����ij����������̵߳����ȼ�)��
��˵�����߳�ͬ���Լ��̵߳�����صķ�����
(1) wait():ʹһ���̴߳��ڵȴ�(����)״̬,�����ͷ������еĶ������;
(2)sleep():ʹһ���������е��̴߳���˯��״̬,��һ����̬����,���ô˷���Ҫ���� InterruptedException �쳣;
(3)notify():����һ�����ڵȴ�״̬���߳�,��Ȼ�ڵ��ô˷�����ʱ��,������ȷ�еĻ���ijһ���ȴ�״̬���߳�,������ JVM ȷ�������ĸ��߳�,���������ȼ���;
(4)notityAll():�������д��ڵȴ�״̬���߳�,�÷��������ǽ���������������߳�,���������Ǿ���,ֻ�л�������̲߳��ܽ������״̬;
ע����:����await/signal(signal all ),park,unpark��
sleep() �� wait() ��ʲô����?
���߶�������ͣ�̵߳�ִ��
��IJ�ͬ:sleep() �� Thread�߳���ľ�̬����,wait() �� Object��ķ�����
�Ƿ��ͷ���:sleep() ���ͷ���;wait() �ͷ�����
��;��ͬ:Wait ͨ���������̼߳佻��/ͨ��,sleep ͨ����������ִͣ�С�
�÷���ͬ:wait() ���������ú�,�̲߳����Զ�����,��Ҫ����̵߳���ͬһ�������ϵ� notify() ���� notifyAll() ������sleep() ����ִ����ɺ�,�̻߳��Զ����ѡ����߿���ʹ��wait(long timeout)��ʱ���̻߳��Զ����ѡ�
������ε��� wait() ������?ʹ�� if �黹��ѭ��?Ϊʲô?
���ڵȴ�״̬���߳̿��ܻ��յ�������α����,�������ѭ���м��ȴ�����,����ͻ���û���������������������˳���
wait() ����Ӧ����ѭ������,��Ϊ���̻߳�ȡ�� CPU ��ʼִ�е�ʱ��,�����������ܻ�û������,�����ڴ���ǰ,ѭ����������Ƿ��������á�������һ�α���ʹ�� wait �� notify �����Ĵ���:
synchronized (monitor) {
// �ж�����ν���Ƿ�õ�����
while(!locked) {
// �ȴ�����
monitor.wait();
}
// ����������ҵ����
}
Ϊʲô�߳�ͨ�ŵķ��� wait(), notify()�� notifyAll()�������� Object ����?
Java��,�κζ�������Ϊ��,���� wait(),notify()�ȷ������ڵȴ���������������߳�,�� Java ���߳��в�û�пɹ��κζ���ʹ�õ���,�������������÷���һ��������Object���С�
wait(), notify()�� notifyAll()��Щ������ͬ��������е���
�е��˻�˵,��Ȼ���̷߳���������,��Ҳ����wait()������Thread�����氡,�¶�����̼̳߳���Thread��,Ҳ����Ҫ���¶���wait()������ʵ�֡�Ȼ��,��������һ���dz��������,һ���߳���ȫ���Գ��кܶ���,��һ���̷߳�������ʱ��,����Ҫ�����ĸ���?��Ȼ��,������Ʋ����Dz���ʵ��,ֻ�ǹ����������Ӹ��ӡ�
��������,wait()��notify()��notifyAll()����Ҫ������Object���С�
Ϊʲô wait(), notify()�� notifyAll()������ͬ����������ͬ�����б�����?
��һ���߳���Ҫ���ö���� wait()������ʱ��,����̱߳���ӵ�иö������,�������ͻ��ͷ����������������ȴ�״ֱ̬�������̵߳�����������ϵ� notify()������ͬ����,��һ���߳���Ҫ���ö���� notify()����ʱ,�����ͷ�����������,�Ա������ڵȴ����߳̾Ϳ��Եõ�������������������е���Щ��������Ҫ�̳߳��ж������,������ֻ��ͨ��ͬ����ʵ��,��������ֻ����ͬ����������ͬ�����б����á�
Thread ���е� yield ������ʲô����?
ʹ��ǰ�̴߳�ִ��״̬(����״̬)��Ϊ��ִ��̬(����״̬)��
��ǰ�̵߳��˾���״̬,��ô�������ĸ��̻߳�Ӿ���״̬���ִ��״̬��?�����ǵ�ǰ�߳�,Ҳ�����������߳�,��ϵͳ�ķ����ˡ�
Ϊʲô Thread ��� sleep()�� yield ()�����Ǿ�̬��?
Thread ��� sleep()�� yield()�������ڵ�ǰ����ִ�е��߳������С��������������ڵȴ�״̬���߳��ϵ�����Щ������û������ġ������Ϊʲô��Щ�����Ǿ�̬�ġ����ǿ����ڵ�ǰ����ִ�е��߳��й���,���������Ա�������Ϊ�����������������̵߳�����Щ������
���ֹͣһ���������е��߳�?
��java��������3�ַ���������ֹ�������е��߳�:
-
ʹ���˳���־,ʹ�߳������˳�,Ҳ���ǵ�run������ɺ��߳���ֹ��
-
ʹ��stop����ǿ����ֹ,���Dz��Ƽ��������,��Ϊstop��suspend��resumeһ�����ǹ������ϵķ�����
-
ʹ��interrupt�����ж��̡߳�
Java ���ʵ�ֶ��߳�֮���ͨѶ��Э��?
����ͨ���ж� �� ���������ķ�ʽʵ���̼߳��ͨѶ��Э��
����˵����������-������ģ��:��������ʱ,��������Ҫ�ȴ������пռ���ܼ��������������Ʒ,���ڵȴ����ڼ���,�����߱����ͷŶ��ٽ���Դ(������)��ռ��Ȩ����Ϊ������������ͷŶ��ٽ���Դ��ռ��Ȩ,��ô�����߾������Ѷ����е���Ʒ,�Ͳ����ö����пռ�,��ô�����߾ͻ�һֱ���ȴ���ȥ�����,һ�������,��������ʱ,���������߽������ٽ���Դ��ռ��Ȩ,���������״̬��Ȼ��ȴ���������������Ʒ,Ȼ��������֪ͨ�����߶����пռ��ˡ�ͬ����,�����п�ʱ,������Ҳ����ȴ�,�ȴ�������֪ͨ������������Ʒ�ˡ����ֻ���ͨ�ŵĹ��̾����̼߳��Э����
Java���߳�ͨ��Э������������ַ�ʽ
һ.syncrhoized�������̵߳�Object���wait()/notify()/notifyAll()
��.ReentrantLock��������̵߳�Condition���await()/signal()/signalAll()
�̼߳�ֱ�ӵ����ݽ���:
��.ͨ���ܵ������̼߳�ͨ��:1)�ֽ���;2)�ַ���
ͬ��������ͬ����,�ĸ��Ǹ��õ�ѡ��?
ͬ�����Ǹ��õ�ѡ��,��Ϊ��������ס��������(��Ȼ��Ҳ����������ס��������)��ͬ����������ס��������,������������ж�����������ͬ����,��ͨ���ᵼ������ִֹͣ�в���Ҫ�ȴ������������ϵ�����
ͬ�����Ҫ���Ͽ��ŵ��õ�ԭ��,ֻ����Ҫ��ס�Ĵ������ס��Ӧ�Ķ���,�����Ӳ�����˵Ҳ���Ա���������
��֪��һ��ԭ��:ͬ���ķ�ΧԽСԽ�á�
ʲô���߳�ͬ�����̻߳���,���ļ���ʵ�ַ�ʽ?
��һ���̶߳Թ��������ݽ��в���ʱ,Ӧʹ֮��Ϊһ����ԭ�Ӳ�����,����û�������ز���֮ǰ,�����������̴߳����,����,�ͻ��ƻ����ݵ�������,��Ȼ��õ�����Ĵ������,������̵߳�ͬ����
�ڶ��߳�Ӧ����,���Dz�ͬ�߳�֮�������ͬ���ͷ�ֹ�����������������߳�֮��ͬʱ�ȴ��Է��ͷ���Դ��ʱ��ͻ��γ��߳�֮���������Ϊ�˷�ֹ�����ķ���,��Ҫͨ��ͬ����ʵ���̰߳�ȫ��
�̻߳�����ָ���ڹ����Ľ���ϵͳ��Դ,�ڸ������̷߳���ʱ�������ԡ��������ɸ��̶߳�Ҫʹ��ijһ������Դʱ,�κ�ʱ�����ֻ����һ���߳�ȥʹ��,����Ҫʹ�ø���Դ���̱߳���ȴ�,ֱ��ռ����Դ���ͷŸ���Դ���̻߳�����Կ�����һ��������߳�ͬ����
�̼߳��ͬ����������ɷ�Ϊ����:�û�ģʽ���ں�ģʽ������˼��,�ں�ģʽ����ָ����ϵͳ�ں˶���ĵ�һ��������ͬ��,ʹ��ʱ��Ҫ�л��ں�̬���û�̬,���û�ģʽ���Dz���Ҫ�л����ں�̬,ֻ���û�̬��ɲ�����
�û�ģʽ�µķ�����:ԭ�Ӳ���(����һ����һ��ȫ�ֱ���),�ٽ������ں�ģʽ�µķ�����:�¼�,�ź���,��������
ʵ���߳�ͬ���ķ���
ͬ�����뷽��:sychronized �ؼ������εķ���
ͬ�������:sychronized �ؼ������εĴ����
ʹ�����������volatileʵ���߳�ͬ��:volatile�ؼ���Ϊ������ķ����ṩ��һ����������
ʹ��������ʵ���߳�ͬ��:reentrantlock���ǿɳ��롢���⡢ʵ����lock�ӿڵ�������sychronized����������ͬ�Ļ�����Ϊ������
�ڼ�����(Monitor)�ڲ�,��������߳�ͬ����?����Ӧ�������ּ����ͬ��?
�� java �������,ÿ������( Object �� class )ͨ��ij��������������,ÿ����������һ���������������,Ϊ��ʵ�ּ������Ļ����,ÿ����������һ������
һ���������ߴ���鱻 synchronized ����,��ô������־ͷ����˼������ļ�������,(���֮��Ϊmonitorenter��monitorexit),ȷ��һ��ֻ����һ���߳�ִ�иò��ֵĴ���,�߳��ڻ�ȡ��֮ǰ������ִ�иò��ֵĴ���
���� java ���ṩ����ʽ������( Lock )����ʽ������( synchronized )����������
������ύ����ʱ,�̳߳ض�������,��ʱ�ᷢ��ʲô
��������һ��:
(1)���ʹ�õ�������� LinkedBlockingQueue,Ҳ��������еĻ�,û��ϵ,���������������������еȴ�ִ��,��Ϊ LinkedBlockingQueue ���Խ�����Ϊ��һ�������Ķ���,�������������
(2)���ʹ�õ����н���б��� ArrayBlockingQueue,�������Ȼᱻ���ӵ�ArrayBlockingQueue ��,ArrayBlockingQueue ����,�����maximumPoolSize ��ֵ�����߳�����,����������߳��������Ǵ���������,ArrayBlockingQueue ������,��ô���ʹ�þܾ�����RejectedExecutionHandler �������˵�����,Ĭ���� AbortPolicy
ʲô���̰߳�ȫ?servlet ���̰߳�ȫ��?
�̰߳�ȫ�DZ���е�����,ָij�������ڶ��̻߳����б�����ʱ,�ܹ���ȷ�ش�������߳�֮��Ĺ�������,ʹ��������ȷ��ɡ�
Servlet �����̰߳�ȫ��,servlet �ǵ�ʵ�����̵߳�,������߳�ͬʱ����ͬһ������,�Dz��ܱ�֤�����������̰߳�ȫ�Եġ�
Struts2 �� action �Ƕ�ʵ�����̵߳�,���̰߳�ȫ��,ÿ������������� new һ���µ� action ������������,������ɺ����١�
SpringMVC �� Controller ���̰߳�ȫ����?���ǵ�,�� Servlet ���ƵĴ������̡�
Struts2 �ô��Dz��ÿ����̰߳�ȫ����;Servlet �� SpringMVC ��Ҫ�����̰߳�ȫ����,�������ܿ����������ô���̫��� gc,����ʹ�� ThreadLocal ���������̵߳����⡣
�� Java ��������ô��֤���̵߳����а�ȫ?
����һ:ʹ��ԭ����,��������,���� java.util.concurrent �µ���,ʹ��ԭ����AtomicInteger
������:ʹ���Զ��� synchronized��
������:ʹ���ֶ��� Lock��
����߳����ȼ���������ʲô?
ÿһ���̶߳��������ȼ���,һ����˵,�����ȼ����߳�������ʱ���������Ȩ,�����������̵߳��ȵ�ʵ��,���ʵ���ǺͲ���ϵͳ��ص�(OS dependent)�����ǿ��Զ����̵߳����ȼ�,�����Ⲣ���ܱ�֤�����ȼ����̻߳��ڵ����ȼ����߳�ǰִ�С��߳����ȼ���һ�� int ����(�� 1-10),1 ����������ȼ�,10 ����������ȼ���
Java ���߳����ȼ����Ȼ�ί�и�����ϵͳȥ����,���������IJ���ϵͳ���ȼ��й�,����ر���Ҫ,һ�����������߳����ȼ���
�߳���Ĺ��췽������̬���DZ��ĸ��̵߳��õ�
����һ���dz�����ͽƻ������⡣���ס:�߳���Ĺ��췽������̬���DZ� new����߳������ڵ��߳������õ�,�� run ��������Ĵ�����DZ��߳����������õġ�
���˵�����˵������е�����,��ô�Ҿٸ�����,���� Thread2 �� new ��Thread1,main ������ new �� Thread2,��ô:
(1)Thread2 �Ĺ��췽������̬���� main �̵߳��õ�,Thread2 �� run()������Thread2 �Լ����õ�
(2)Thread1 �Ĺ��췽������̬���� Thread2 ���õ�,Thread1 �� run()������Thread1 �Լ����õ�
Java ����ô��ȡһ���߳� dump �ļ�?������� Java �л�ȡ�̶߳�ջ?
Dump�ļ��ǽ��̵��ڴ澵���ѳ����ִ��״̬ͨ�����������浽dump�ļ��С�
�� Linux ��,�����ͨ������ kill -3 PID (Java ���̵Ľ��� ID)����ȡ JavaӦ�õ� dump �ļ���
�� Windows ��,������� Ctrl + Break ����ȡ������ JVM �ͻὫ�̵߳� dump �ļ���ӡ�������������ļ���,�����ܴ�ӡ�ڿ���̨������־�ļ���,����λ������Ӧ�õ����á�
һ���߳�����ʱ�����쳣������?
����쳣û�б�������߳̽���ִֹͣ�С�Thread.UncaughtExceptionHandler�����ڴ���δ�����쳣����߳�ͻȻ�ж������һ����Ƕ�ӿڡ���һ��δ�����쳣������߳��жϵ�ʱ��,JVM ��ʹ�� Thread.getUncaughtExceptionHandler()����ѯ�̵߳� UncaughtExceptionHandler �����̺߳��쳣��Ϊ�������ݸ� handler �� uncaughtException()�������д�����
Java �߳�����������ʲô�쳣?
�̵߳��������ڿ����dz���
������� CPU
��Դ��������е��߳��������ڿ��ô�����������,��ô���߳̽��ᱻ���á��������е��̻߳�ռ�������ڴ�,����������������ѹ��,���Ҵ������߳��ھ��� CPU��Դʱ���������������ܵĿ�����
�����ȶ���JVM
�ڿɴ����̵߳������ϴ���һ������,�������ֵ������ƽ̨�IJ�ͬ����ͬ,���ҳ����Ŷ��������Լ,���� JVM ������������Thread ���캯��������ջ�Ĵ�С,�Լ��ײ����ϵͳ���̵߳����Ƶȡ�����ƻ�����Щ����,��ô�����׳�OutOfMemoryError �쳣��
��������
Java�ڴ�ģ��
https://blog.csdn.net/qq_44787816/article/details/119028250
Java������������ʲôĿ��?ʲôʱ�������������?
�������������ڴ��д���û�����õĶ����������Ķ���ʱ���еġ�
�������յ�Ŀ����ʶ���Ҷ���Ӧ�ò���ʹ�õĶ������ͷź�������Դ��
�����������ñ���Ϊnull,�����ռ����Ƿ�������ͷŶ���ռ�õ��ڴ�?
����,����һ�������ص�������,��������DZ��ɻ��յġ�
Ҳ����˵�����������������ռ������̻���,��������һ����������ʱ�Ż��ͷ���ռ�õ��ڴ档
��ʵû��ô��,������Կ��ҵIJ���ר��
finalize()����ʲôʱ����?��������(finalization)��Ŀ����ʲô?
1)����������(garbage colector)��������ij����ʱ,�ͻ����иö����finalize()����;
finalize��Object���һ������,�÷�����Object���е�����protected void finalize() throws Throwable { }
������������ִ��ʱ����ñ����ն����finalize()����,���Ը��Ǵ˷�����ʵ�ֶ�����Դ�Ļ��ա�ע��:һ���������������ͷŶ���ռ�õ��ڴ�,�����ȵ��øö����finalize()����,������һ���������ն�������ʱ,���������ն���ռ�õ��ڴ�ռ�
2)GC���������ڴ������,Ӧ�û���Ҫ��finalization��ʲô��? ���Ǵ�ʱ��,ʲô��������(Ҳ���Dz���Ҫ����)��ֻ����ijЩ������������,�����������һЩnative�ķ���(һ����Cд��),����Ҫ��finaliztion��ȥ����C���ͷź�����
������������������
Ϊʲô�����������?
��ִ�г���ʱ,Ϊ���ṩ����,�������ͱ������������ָ�����������,���Dz�������������,����������ô�������ô����,����Ҫ����������������:
�ڵ��̻߳����²��ܸı�������еĽ��;
��������������ϵ�IJ�����������
��Ҫע�����:������Ӱ�쵥�̻߳�����ִ�н��,���ǻ��ƻ����̵߳�ִ�����塣
as-if-serial�����happens-before���������
as-if-serial���屣֤���߳��ڳ����ִ�н�������ı�,happens-before��ϵ��֤��ȷͬ���Ķ��̳߳����ִ�н�������ı䡣
as-if-serial�������д���̳߳���ij���Ա������һ���þ�:���̳߳����ǰ������˳����ִ�еġ�happens-before��ϵ����д��ȷͬ���Ķ��̳߳���ij���Ա������һ���þ�:��ȷͬ���Ķ��̳߳����ǰ�happens-beforeָ����˳����ִ�еġ�
as-if-serial�����happens-before��ô����Ŀ��,����Ϊ���ڲ��ı����ִ�н����ǰ����,�����ܵ���߳���ִ�еIJ��жȡ�
synchronized ������?
�� Java ��,synchronized �ؼ��������������߳�ͬ����,�����ڶ��̵߳Ļ�����,���� synchronized ����β�������߳�ͬʱִ�С�synchronized ���������ࡢ������������
����,�� Java ���ڰ汾��,synchronized������������,Ч�ʵ���,��Ϊ��������(monitor)�������ڵײ�IJ���ϵͳ�� Mutex Lock ��ʵ�ֵ�,Java ���߳���ӳ�䵽����ϵͳ��ԭ���߳�֮�ϵġ����Ҫ���������һ���߳�,����Ҫ����ϵͳ��æ���,������ϵͳʵ���߳�֮����л�ʱ��Ҫ���û�̬ת�����ں�̬,���״̬֮���ת����Ҫ��ԱȽϳ���ʱ��,ʱ��ɱ���Խϸ�,��Ҳ��Ϊʲô���ڵ� synchronized Ч�ʵ͵�ԭ�����ҵ����� Java 6 ֮�� Java �ٷ��Դ� JVM �����synchronized �ϴ��Ż�,�������ڵ� synchronized ��Ч��Ҳ�Ż��úܲ����ˡ�JDK1.6������ʵ�������˴������Ż�,������������Ӧ���������������������ֻ���ƫ���������������ȼ����������������Ŀ�����
˵˵�Լ�����ôʹ�� synchronized �ؼ���,����Ŀ���õ�����
synchronized�ؼ�������Ҫ������ʹ�÷�ʽ:
����ʵ������: �����ڵ�ǰ����ʵ������,����ͬ������ǰҪ��õ�ǰ����ʵ������
���ξ�̬����: Ҳ���Ǹ���ǰ�����,��������������ж���ʵ��,��Ϊ��̬��Ա�������κ�һ��ʵ������,�����Ա( static �������Ǹ����һ����̬��Դ,����new�˶��ٸ�����,ֻ��һ��)���������һ���߳�A����һ��ʵ������ķǾ�̬ synchronized ����,���߳�B��Ҫ�������ʵ������������ľ�̬ synchronized ����,��������,���ᷢ����������,��Ϊ���ʾ�̬ synchronized ����ռ�õ����ǵ�ǰ�����,�����ʷǾ�̬ synchronized ����ռ�õ����ǵ�ǰʵ����������
���δ����: ָ����������,�Ը����������,����ͬ�������ǰҪ��ø������������
�ܽ�: synchronized �ؼ��ּӵ� static ��̬������ synchronized(class)������϶����Ǹ� Class ��������synchronized �ؼ��ּӵ�ʵ���������Ǹ�����ʵ��������������Ҫʹ�� synchronized(String a) ��ΪJVM��,�ַ��������ؾ��л��湦��!
��������һ��������������Ϊ������һ�� synchronized �ؼ��ֵľ���ʹ�á�
���������Թپ�����˵:������ģʽ�˽���?��������дһ��!���ҽ���һ��˫�ؼ�������ʽʵ�ֵ���ģʽ��ԭ����!��
˫��У����ʵ�ֶ�����(�̰߳�ȫ)
public class Singleton {
private volatile static Singleton uniqueInstance;
private Singleton() {
}
public static Singleton getUniqueInstance() {
//���ж϶����Ƿ��Ѿ�ʵ����,û��ʵ�������Ž����������
if (uniqueInstance == null) {
//��������
synchronized (Singleton.class) {
if (uniqueInstance == null) {
uniqueInstance = new Singleton();
}
}
}
return uniqueInstance;
}
}
����,��Ҫע�� uniqueInstance ���� volatile �ؼ�������Ҳ�Ǻ��б�Ҫ��
uniqueInstance ���� volatile �ؼ�������Ҳ�Ǻ��б�Ҫ�ġ�
uniqueInstance = new Singleton(); ��δ�����ʵ�Ƿ�Ϊ����ִ��:
1��Ϊ uniqueInstance �����ڴ�ռ�
2����ʼ�� uniqueInstance
3���� uniqueInstance ָ�������ڴ��ַ
�������� JVM ����ָ�����ŵ�����,ִ��˳���п��ܱ�� 1->3->2��ָ�������ڵ��̻߳����²����������,�����ڶ��̻߳����»ᵼ��һ���̻߳�û�û�г�ʼ����ʵ����
����,�߳� T1 ִ���� 1 �� 3,��ʱ T2 ���� getUniqueInstance() ���� uniqueInstance ��Ϊ��,��˷��� uniqueInstance,����ʱ uniqueInstance ��δ����ʼ����
ʹ�� volatile ���Խ�ֹ JVM ��ָ������,��֤�ڶ��̻߳�����Ҳ���������С�
˵һ�� synchronized �ײ�ʵ��ԭ��?
synchronized��Java�е�һ���ؼ���,��ʹ�õĹ����в�û�п�����ʾ�ļ����ͽ������̡�����б�Ҫͨ��javap����,�鿴��Ӧ���ֽ����ļ���
synchronized ͬ����������
public class SynchronizedDemo {
public void method() {
synchronized (this) {
System.out.println("synchronized �����");
}
}
}
ͨ��JDK �����ָ�� javap -c -v SynchronizedDemo
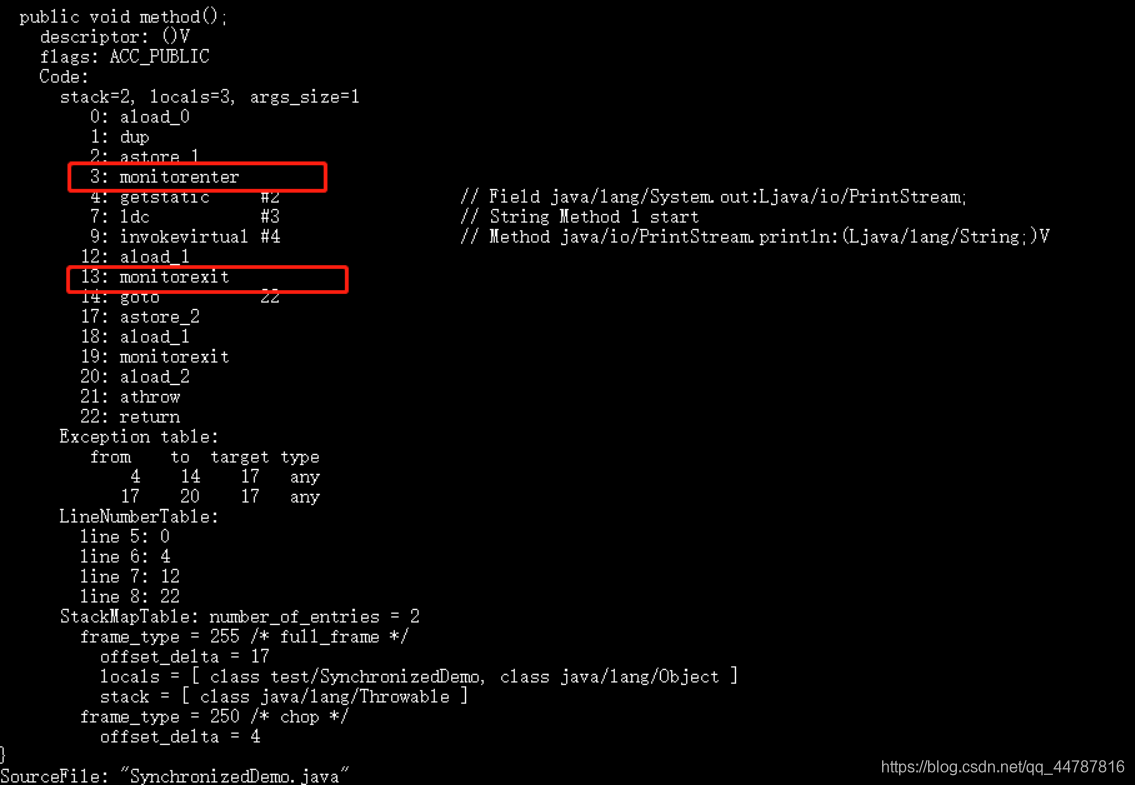
���Կ�����ִ��ͬ�������֮ǰ֮����һ��monitor����,����ǰ�����monitorenter,��������뿪monitorexit,��������һ���߳�Ҳִ��ͬ�������,����Ҫ��ȡ��,����ȡ���Ĺ��̾���monitorenter ,��ִ��������֮��,Ҫ�ͷ���,�ͷ�������ִ��monitorexitָ�
Ϊʲô��������monitorexit��?
�����Ҫ�Ƿ�ֹ��ͬ����������߳����쳣�˳�,����û�еõ��ͷ�,���Ȼ���������(�ȴ����߳���Զ��ȡ������)��������һ��monitorexit�DZ�֤���쳣�����,��Ҳ���Եõ��ͷ�,����������
����ACC_SYNCHRONIZED��ôһ����־,�ñ�DZ����߳̽���÷���ʱ,��Ҫmonitorenter,�˳��÷���ʱ��Ҫmonitorexit��
synchronized�������ԭ��
��������ָһ���̻߳�ȡ������֮��,���߳̿��Լ�����ø������ײ�ԭ��ά��һ��������,���̻߳�ȡ����ʱ,��������һ,�ٴλ�ø���ʱ������һ,�ͷ���ʱ,��������һ,��������ֵΪ0ʱ,��������δ���κ��߳�������,�����߳̿��Ծ�����ȡ����
ʲô������
�ܶ� synchronized ����Ĵ���ֻ��һЩ�ܼĴ���,ִ��ʱ��dz���,��ʱ�ȴ����̶߳�����������һ�ֲ�ֵ̫�õIJ���,��Ϊ�߳������漰���û�̬���ں�̬�л������⡣��Ȼ synchronized ����Ĵ���ִ�е÷dz���,�����õȴ������̲߳�Ҫ������,������ synchronized �ı߽���æѭ��,�����������������˶��ѭ�����ֻ�û�л����,������,����������һ�ָ��õIJ��ԡ�
ʹ��while,do-while,�������߳�,�����������л�
���߳��� synchronized ��������ԭ����ʲô?
synchronized ������ԭ��:��������Ķ���ͷ������һ�� threadid �ֶ�,�ڵ�һ�η��ʵ�ʱ�� threadid Ϊ��,jvm �������ƫ����,���� threadid ����Ϊ���߳� id,�ٴν����ʱ������ж� threadid �Ƿ������߳� id һ��,���һ�������ֱ��ʹ�ô˶���,�����һ��,������ƫ����Ϊ��������,ͨ������ѭ��һ����������ȡ��,ִ��һ������֮��,�����û��������ȡ��Ҫʹ�õĶ���,��ʱ�ͻ����������������Ϊ��������,�˹��̾����� synchronized ����������
����������Ŀ��:��������Ϊ�˼��������������������ġ��� Java 6 ֮���Ż� synchronized ��ʵ�ַ�ʽ,ʹ����ƫ��������Ϊ�������������������������ķ�ʽ,�Ӷ����������������������ġ�
�߳� B ��ô֪���߳� A ���˱���
(1)volatile �����
(2)synchronized �����ı����ķ���
(3)wait/notify
(4)while ��ѯ
��һ���߳̽���һ������� synchronized ���� A ֮��,�����߳��Ƿ�ɽ���˶���� synchronized ���� B?
���ܡ������߳�ֻ�ܷ��ʸö���ķ�ͬ������,ͬ���������ܽ��롣��Ϊ�Ǿ�̬�����ϵ� synchronized ���η�Ҫ��ִ�з���ʱҪ��ö������,����Ѿ�����A ����˵���������Ѿ���ȡ��,��ô��ͼ���� B �������߳̾�ֻ���ڵ�����(ע�ⲻ�ǵȴ���Ŷ)�еȴ����������
synchronized��volatile��CAS �Ƚ�
(1)synchronized �DZ�����,������ռʽ,�����������߳�������
(2)volatile �ṩ���̹߳��������ɼ��Ժͽ�ָֹ���������Ż���
(3)CAS �ǻ��ڳ�ͻ�����ֹ���(������)
synchronized �� Lock ��ʲô����?
����synchronized��Java���ùؼ���,��JVM����,Lock�Ǹ�Java��;
synchronized ���Ը��ࡢ��������������;�� lock ֻ�ܸ�����������
synchronized ����Ҫ�ֶ���ȡ�����ͷ���,ʹ�ü�,�����쳣���Զ��ͷ���,�����������;�� lock ��Ҫ�Լ��������ͷ���,���ʹ�ò���û�� unLock()ȥ�ͷ����ͻ����������
ͨ�� Lock ����֪����û�гɹ���ȡ��,�� synchronized ȴ���쵽��
synchronized �� ReentrantLock ������ʲô?
synchronized �Ǻ� if��else��for��while һ���Ĺؼ���,ReentrantLock ����,���Ƕ��ߵı������𡣼�Ȼ ReentrantLock ����,��ô�����ṩ�˱�synchronized �������������,���Ա��̳С������з����������и��ָ����������
synchronized ���ڵ�ʵ�ֱȽϵ�Ч,�Ա� ReentrantLock,������������ܶ����ϴ�,������ Java 6 �ж� synchronized �����˷dz���ĸĽ���
��ͬ��:���߶��ǿ�������
���߶��ǿ���������������������������:�Լ������ٴλ�ȡ�Լ����ڲ���������һ���̻߳����ij���������,��ʱ�����������û���ͷ�,�����ٴ���Ҫ��ȡ������������ʱ���ǿ��Ի�ȡ��,�������������Ļ�,�ͻ����������ͬһ���߳�ÿ�λ�ȡ��,���ļ�����������1,����Ҫ�ȵ����ļ������½�Ϊ0ʱ�����ͷ�����
��Ҫ��������:
ReentrantLock ʹ�������Ƚ����,���DZ������ͷ�������϶���;
ReentrantLock �����ֶ���ȡ���ͷ���,�� synchronized ����Ҫ�ֶ��ͷźͿ�����;
ReentrantLock ֻ�����ڴ������,�� synchronized ���������ࡢ�����������ȡ�
���ߵ���������ʵҲ�Dz�һ���ġ�ReentrantLock �ײ���õ��� Unsafe ��CAS,lockSuport��park�������߳�,synchronized ������Ӧ���Ƕ���ͷ�� mark word
Java��ÿһ����������Ϊ��,����synchronizedʵ��ͬ���Ļ���:
��ͨͬ������,���ǵ�ǰʵ������
��̬ͬ������,���ǵ�ǰ���class����
ͬ��������,������������Ķ���
volatile �ؼ��ֵ�����
���ڿɼ���,Java �ṩ�� volatile �ؼ�������֤�ɼ��Ժͽ�ָֹ�����š� volatile �ṩ happens-before �ı�֤,ȷ��һ���̵߳����ܶ������߳��ǿɼ��ġ���һ������������ volatile ����ʱ,���ᱣ֤�ĵ�ֵ�����������µ�����,���������߳���Ҫ��ȡʱ,����ȥ�ڴ��ж�ȡ��ֵ��
��ʵ���Ƕȶ���,volatile ��һ����Ҫ���þ��Ǻ� CAS ���,��֤��ԭ����,��ϸ�Ŀ��Բμ� java.util.concurrent.atomic ���µ���,���� AtomicInteger��
volatile �����ڶ��̻߳����µĵ��β���(���ζ����ߵ���д)��
Java ���ܴ��� volatile ������?
��,Java �п��Դ��� volatile ��������,����ֻ��һ��ָ�����������,�������������顣��˼��,����ı�����ָ�������,�����ܵ� volatile �ı���,�����������߳�ͬʱ�ı������Ԫ��,volatile ��ʾ���Ͳ�����֮ǰ�ı��������ˡ�
volatile ������ atomic ������ʲô��ͬ?
volatile ��������ȷ�����й�ϵ,��д�����ᷢ���ں����Ķ�����֮ǰ, ���������ܱ�֤ԭ���ԡ������� volatile ���� count ����,��ô count++ �����Ͳ���ԭ���Եġ�
�� AtomicInteger ���ṩ�� atomic �������������ֲ�������ԭ������getAndIncrement()������ԭ���ԵĽ������������ѵ�ǰֵ��һ,�����������ͺ����ñ���Ҳ���Խ������Ʋ�����
volatile ��ʹ��һ����ԭ�Ӳ������ԭ�Ӳ�����?
�ؼ���volatile����Ҫ������ʹ�����ڶ���̼߳�ɼ�,������֤ԭ����,���ڶ���̷߳���ͬһ��ʵ��������Ҫ��������ͬ����
��Ȼvolatileֻ�ܱ�֤�ɼ��Բ��ܱ�֤ԭ����,����volatile����long��double���Ա�֤�����ԭ���ԡ�
���Դ�Oracle Java Spec������Կ���:
����64λ��long��double,���û�б�volatile����,��ô����������Բ���ԭ�ӵġ��ڲ�����ʱ��,���Էֳ�����,ÿ�ζ�32λ������
���ʹ��volatile����long��double,��ô���д����ԭ�Ӳ���
����64λ�����õ�ַ�Ķ�д,����ԭ�Ӳ���
��ʵ��JVMʱ,��������ѡ���Ƿ�Ѷ�дlong��double��Ϊԭ�Ӳ���
�Ƽ�JVMʵ��Ϊԭ�Ӳ���
volatile ���η����й�ʲôʵ��?
����ģʽ
�Ƿ� Lazy ��ʼ��:��
�Ƿ���̰߳�ȫ:��
ʵ���Ѷ�:�ϸ���
����:����Double-Check���ֿ��ܳ��ֵ�����(��Ȼ���ָ����Ѿ��dz�С��,���Ͼ������е���~),���������:ֻ��Ҫ��instance����������volatile�ؼ��ּ���volatile�ؼ��ֵ�һ�������ǽ�ָֹ������,��instance����Ϊvolatile֮��,������д�����ͻ���һ���ڴ�����(ʲô���ڴ�����?),����,�����ĸ�ֵ���֮ǰ,�Ͳ��û���ö�������ע��:volatile��ֹ�IJ���singleton = newSingleton()��仰�ڲ�[1-2-3]��ָ������,���DZ�֤����һ��д����([1-2-3])���֮ǰ,������ö�����(if (instance == null))��
public class Singleton7 {
private static volatile Singleton7 instance = null;
private Singleton7() {}
public static Singleton7 getInstance() {
if (instance == null) {
synchronized (Singleton7.class) {
if (instance == null) {
instance = new Singleton7();
}
}
}
return instance;
}
}
synchronized �� volatile ��������ʲô?
synchronized ��ʾֻ��һ���߳̿��Ի�ȡ���ö������,ִ�д���,���������̡߳�
volatile ��ʾ������ CPU �ļĴ������Dz�ȷ����,����������ж�ȡ����֤���̻߳����±����Ŀɼ���;��ָֹ��������
����
1��volatile �DZ������η�;synchronized ���������ࡢ������������
2��volatile ����ʵ�ֱ������Ŀɼ���,���ܱ�֤ԭ����;�� synchronized ����Ա�֤�������Ŀɼ��Ժ�ԭ���ԡ�
3��volatile ��������̵߳�����;synchronized ���ܻ�����̵߳�������
4��volatile��ǵı������ᱻ�������Ż�;synchronized��ǵı������Ա��������Ż���
5��volatile�ؼ������߳�ͬ����������ʵ��,����volatile���ܿ϶���synchronized�ؼ���Ҫ�á�����volatile�ؼ���ֻ�����ڱ�����synchronized�ؼ��ֿ������η����Լ�����顣synchronized�ؼ�����JavaSE1.6֮���������Ҫ����Ϊ�˼��ٻ�������ͷ����������������Ķ������ƫ���������������Լ����������Ż�֮��ִ��Ч��������������,ʵ�ʿ�����ʹ�� synchronized �ؼ��ֵij������Ǹ���һЩ��
ʲô�Dz��ɱ����,����д����Ӧ����ʲô����?
���ɱ����(Immutable Objects)������һ������������״̬(���������,Ҳ����������ֵ)�Ͳ��ܸı�,��֮��Ϊ�ɱ����(Mutable Objects)��
���ɱ������༴Ϊ���ɱ���(Immutable Class)��Java ƽ̨����а�������ɱ���,�� String���������͵İ�װ�ࡢBigInteger �� BigDecimal �ȡ�
ֻ����������״̬,һ��������Dz��ɱ��;
����״̬�����ڴ������ٱ���;
�������� final ����;����,������ȷ����(�����ڼ�û�з��� this ���õ��ݳ�)��
���ɱ����֤�˶�����ڴ�ɼ���,�Բ��ɱ����Ķ�ȡ����Ҫ���ж����ͬ���ֶ�,�����˴���ִ��Ч�ʡ�
Lock��ϵ
Java Concurrency API �е� Lock �ӿ�(Lock interface)��ʲô?�Ա�ͬ������ʲô����?
Lock �ӿڱ�ͬ��������ͬ�����ṩ�˸�����չ�Ե����������������������Ľṹ,���Ծ�����ȫ��ͬ������,���ҿ���֧�ֶ����������������
����������:
(1)����ʹ������ƽ
(2)����ʹ�߳��ڵȴ�����ʱ����Ӧ�ж�
(3)�������̳߳��Ի�ȡ��,��������ȡ����ʱ���������ػ��ߵȴ�һ��ʱ��
(4)�����ڲ�ͬ�ķ�Χ,�Բ�ͬ��˳���ȡ���ͷ���
��������˵ Lock �� synchronized ����չ��,Lock �ṩ���������ġ�����ѯ��(tryLock ����)����ʱ��(tryLock ���η���)�����жϵ�(lockInterruptibly)���ɶ��������е�(newCondition ����)������������ Lock ��ʵ���������֧�ַǹ�ƽ��(Ĭ��)��ƽ��,synchronized ֻ֧�ַǹ�ƽ��,��Ȼ,�ڴ������,�ǹ�ƽ���Ǹ�Ч��ѡ��
�ֹ����ͱ����������⼰���ʵ��,����Щʵ�ַ�ʽ?
������:���Ǽ���������,ÿ��ȥ�����ݵ�ʱ����Ϊ���˻���,����ÿ���������ݵ�ʱ������,������������������ݾͻ�����ֱ�����õ�������ͳ�Ĺ�ϵ�����ݿ���߾��õ��˺ܶ�����������,��������,������,����,д����,������������֮ǰ���������ٱ��� Java �����ͬ��ԭ�� synchronized �ؼ��ֵ�ʵ��Ҳ�DZ�������
�ֹ���:����˼��,���Ǻ��ֹ�,ÿ��ȥ�����ݵ�ʱ����Ϊ���˲�����,���Բ�������,�����ڸ��µ�ʱ����ж�һ���ڴ��ڼ������û��ȥ�����������,����ʹ�ð汾�ŵȻ��ơ��ֹ��������ڶ����Ӧ������,�����������������,�����ݿ��ṩ�������� write_condition ����,��ʵ�����ṩ���ֹ������� Java�� java.util.concurrent.atomic �������ԭ�������ʹ�����ֹ�����һ��ʵ�ַ�ʽ CAS ʵ�ֵġ�
�ֹ�����ʵ�ַ�ʽ:
1��ʹ�ð汾��ʶ��ȷ���������������ύʱ�������Ƿ�һ�¡��ύ���İ汾��ʶ,��һ��ʱ���Բ�ȡ�������ٴγ��ԵIJ��ԡ�
2��java �е� Compare and Swap �� CAS ,������̳߳���ʹ�� CAS ͬʱ����ͬһ������ʱ,ֻ������һ���߳��ܸ��±�����ֵ,�������̶߳�ʧ��,ʧ�ܵ��̲߳����ᱻ����,���DZ���֪��ξ�����ʧ��,�������ٴγ��ԡ� CAS �����а������������� ���� ��Ҫ��д���ڴ�λ��(V)�����бȽϵ�Ԥ��ԭֵ(A)����д�����ֵ(B)������ڴ�λ�� V ��ֵ��Ԥ��ԭֵ A ��ƥ��,��ô���������Զ�����λ��ֵ����Ϊ��ֵ B���������������κβ�����
ʲô�� CAS
CAS �� compare and swap ����д,��������˵�ıȽϲ�������
cas ��һ�ֻ������IJ���,�������ֹ������� java ������Ϊ�ֹ����ͱ��������������ǽ���Դ��ס,��һ��֮ǰ��������߳��ͷ���֮��,��һ���̲߳ſ��Է��ʡ����ֹ�����ȡ��һ�ֿ�����̬��,ͨ��ij�ַ�ʽ��������������Դ,����ͨ������¼�� version ����ȡ����,���ܽϱ������кܴ����ߡ�
CAS ������������������ ���� �ڴ�λ��(V)��Ԥ��ԭֵ(A)����ֵ(B)������ڴ��ַ�����ֵ�� A ��ֵ��һ����,��ô�ͽ��ڴ������ֵ���³� B��CAS��ͨ������ѭ������ȡ���ݵ�,�����ڵ�һ��ѭ����,a �̻߳�ȡ��ַ�����ֵ��b �߳�����,��ô a �߳���Ҫ����,���´�ѭ�����п��ܻ���ִ�С�
java.util.concurrent.atomic ���µ�������ʹ�� CAS ������ʵ�ֵ�(AtomicInteger,AtomicBoolean,AtomicLong)��
CAS �Ļ����ʲô����?
1��ABA ����:
����˵һ���߳� one ���ڴ�λ�� V ��ȡ�� A,��ʱ����һ���߳� two Ҳ���ڴ���ȡ�� A,���� two ������һЩ��������� B,Ȼ�� two �ֽ� V λ�õ����ݱ�� A,��ʱ���߳� one ���� CAS ���������ڴ�����Ȼ�� A,Ȼ�� one �����ɹ��������߳� one �� CAS �����ɹ�,�����ܴ���DZ�ص����⡣�� Java1.5 ��ʼ JDK �� atomic�����ṩ��һ���� AtomicStampedReference ����� ABA ���⡣
2��ѭ��ʱ�䳤������:
������Դ��������(�̳߳�ͻ����)�����,CAS �����ĸ��ʻ�Ƚϴ�,�Ӷ��˷Ѹ���� CPU ��Դ,Ч�ʵ��� synchronized��
3��ֻ�ܱ�֤һ������������ԭ�Ӳ���:
����һ����������ִ�в���ʱ,���ǿ���ʹ��ѭ�� CAS �ķ�ʽ����֤ԭ�Ӳ���,���ǶԶ��������������ʱ,ѭ�� CAS ������֤������ԭ����,���ʱ��Ϳ���������
ʲô������?
���߳� A ���ж�ռ��a,������ȥ��ȡ��ռ�� b ��ͬʱ,�߳� B ���ж�ռ�� b,�����Ի�ȡ��ռ�� a �������,�ͻᷢ�� AB �����߳����ڻ�����жԷ���Ҫ����,����������������,���dz�Ϊ������
����������������ʲô?��ô��ֹ����?
���������ı�Ҫ����:
1����������:��ν������ǽ�����ijһʱ���ڶ�ռ��Դ��
2�������뱣������:һ��������������Դ������ʱ,���ѻ�õ���Դ���ֲ��š�
3������������:�����ѻ����Դ,��ĩʹ����֮ǰ,����ǿ�а��ᡣ
4��ѭ���ȴ�����:���ɽ���֮���γ�һ��ͷβ��ӵ�ѭ���ȴ���Դ��ϵ��
���ĸ������������ı�Ҫ����,ֻҪϵͳ��������,��Щ������Ȼ����,��ֻҪ��������֮ һ������,�Ͳ��ᷢ��������
������������ԭ��,�����Dz����������ĸ���Ҫ����,�Ϳ��������ܵر��⡢Ԥ���� ���������
��ֹ�������Բ������µķ���:
1������ʹ�� tryLock(long timeout, TimeUnit unit)�ķ���(ReentrantLock��ReentrantReadWriteLock),���ó�ʱʱ��,��ʱ�����˳���ֹ������
2������ʹ�� Java. util. concurrent ����������Լ���д����
3��������������ʹ������,������Ҫ����������ͬһ������
4����������ͬ���Ĵ���顣
���������������,�����뼢��������?
����:��ָ�������������ϵĽ���(���߳�)��ִ�й�����,��������Դ����ɵ�һ�ֻ���ȴ�������,������������,���Ƕ������ƽ���ȥ��
����:�������ִ����û�б�����,����ijЩ����û������,����һֱ�ظ�����,ʧ��,����,ʧ�ܡ�(������)
��������������������,���ڻ�����ʵ�����ڲ��ϵĸı�״̬,�������ν�ġ��, ������������ʵ�����Ϊ�ȴ�;�����п������н,�������ܡ�
����:һ�����߶���߳���Ϊ����ԭ�����������Ҫ����Դ,����һֱ��ִ�е�״̬��
Java �е��¼�����ԭ��:
1�������ȼ��߳��������еĵ����ȼ��̵߳� CPU ʱ�䡣
2���̱߳����ö�����һ���ȴ�����ͬ�����״̬,��Ϊ�����߳�����������֮ǰ�����ضԸ�ͬ������з��ʡ�
3���߳��ڵȴ�һ������Ҳ�������õȴ���ɵĶ���(��������������� wait ����),��Ϊ�����߳����DZ������ػ�û��ѡ�
���߳���������ԭ����ʲô?(����)
��Java��,������4��״̬,����ӵ͵�������Ϊ:��״̬��,ƫ����,������������������״̬,�⼸��״̬�����ž�����������������������������ܽ�����
Java�����ڴ沼��
���˽�������ԭ��֮ǰ��������Ҫ�˽�һ��Java�������ڴ��еIJ���
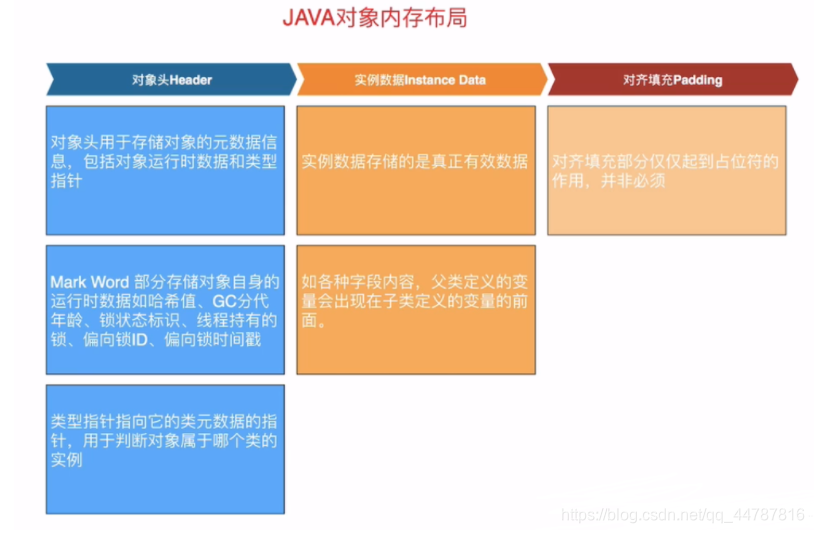
����ͷ���ڴ洢�����Ԫ������Ϣ,��������ʱ���ݺ�����ָ�롢ʵ�����ݴ洢����������Ч���ݡ����������Ҫ�����ֽ�,ʹ���ڴ���ռ�ֽ��ܱ�8������
���ж���ͷHeaderռ12���ֽ�:Mark Wordռ8���ֽ�,����ָ��class pointerռ4���ֽ�(Ĭ�Ͼ�����ѹ��,���������ѹ��ռ8���ֽ�)
ʵ������ʵ�ʴ洢�в�ͬ��С,����Ϊ��ʱ����0��
Padding��ʾ����,����ʱ�ڴ���ռ�ֽڲ��ܱ�8����ʱ������Ӧ�ֽ�����
synchronized������
Java�������������ʵ������synchronized,֮����Ҫ��������ڴ沼��,����Ϊsynchronized������Ϣ����ڶ���ͷ��MarkWord�С�
�����ڵ�jdk�汾��,synchronized��һ����������,��֤�̵߳İ�ȫ����Ч�ʺܵ͡�������synchronized�������Ż�,����һ���������Ĺ���:
����̬(new)�C>ƫ�����C>��������(������)�C>��������
ͨ��MarkWord�е�8���ֽ�Ҳ����64λ����¼����Ϣ��
�������������:
����һ����������synchronized��֮��,�൱������һ��ƫ������
����һ���߳�ȥ����ʱ,�Ͱ��������MarkWord��ID��Ϊ��ǰ�߳�ָ��ID(JavaThread),ֻ������һ���߳�ȥ�������
���������߳�Ҳȥ����ʱ,�Ͱ�������Ϊ����������ÿ���߳����Լ����߳�ջ������LockRecord,��CAS�����������������MarkWordID��Ϊ�Լ���LockRecord,�ɹ����߳������˸ö���,δ�ɹ��Ķ������������
��������Ӿ�,�����߳���������һ������ʱ(��JDK1.6֮��,�������������JVM�Լ�����),�ͽ�������������Ϊ��������,�̹߳���,����ȴ�����,�ȴ�����ϵͳ�ĵ��ȡ�
������
˵������������,�б�Ҫ˵һ��˵һ�������������ֻ���
��ijЩ�����,���JVM��Ϊ����Ҫ��,���Զ�������,����������δ���:
public void add(String a,String b){
StringBuffer sb=new StringBuffer();
sb.append(a).append(b);
}
StringBuffer���̰߳�ȫ��,���������add������stringbuffer�Dz��ܹ�������Դ,��˼���ֻ��ͽ����������,JVM�ͻ�����StringBuffer�ڲ�������
���ֻ�
��ijЩ�����,JVM��һ�����IJ������ڶ�ͬһ�����ϼ���,�ͻὫ������ӵ���һ�����������ⲿ,����:
StringBuffer sb=new StringBuffer();
while(i<100){
sb.append(str);
i++;
}
��������StringBufferÿ���������ݶ�Ҫ�����ͽ���,����100��,��ʱ��JVM�ͻὫ���ӵ������(while)���֡�
AQS(AbstractQueuedSynchronizer)�����Դ�����
AQS ����
AQS��ȫ��Ϊ(AbstractQueuedSynchronizer),�������java.util.concurrent.locks�����档

AQS��һ��������������ͬ�����Ŀ��,ʹ��AQS�ܼ��Ҹ�Ч�ع����Ӧ�ù㷺�Ĵ�����ͬ����,���������ᵽ��ReentrantLock,Semaphore,����������ReentrantReadWriteLock,SynchronousQueue,FutureTask�ȵȽ��ǻ���AQS�ġ���Ȼ,�����Լ�Ҳ������AQS�dz��������ع�������������Լ������ͬ������
AQS ԭ������
�����������ʵ��AQS��ע�����Ѿ�������,������Ӣ��űȽϳ���һ��,����Ȥ�Ļ����Կ���Դ�롣
AQS ԭ������
AQS����˼����,���������Ĺ�����Դ����,��ǰ������Դ���߳�����Ϊ��Ч�Ĺ����߳�,���ҽ�������Դ����Ϊ����״̬�����������Ĺ�����Դ��ռ��,��ô����Ҫһ���߳������ȴ��Լ�������ʱ������Ļ���,�������AQS����CLH������ʵ�ֵ�,������ʱ��ȡ���������̼߳��뵽�����С�
CLH(Craig,Landin,and Hagersten)������һ�������˫�����(�����˫����м������ڶ���ʵ��,�����ڽ��֮��Ĺ�����ϵ)��AQS�ǽ�ÿ����������Դ���̷߳�װ��һ��CLH�����е�һ�����(Node)��ʵ�����ķ��䡣
����AQS(AbstractQueuedSynchronizer)ԭ��ͼ:
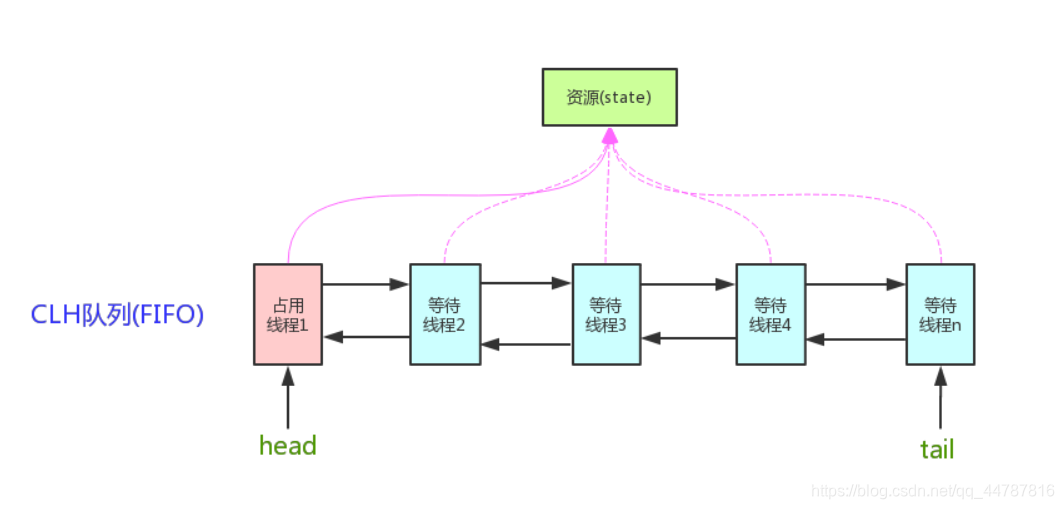
AQSʹ��һ��int��Ա��������ʾͬ��״̬,ͨ�����õ�FIFO��������ɻ�ȡ��Դ�̵߳��Ŷӹ�����AQSʹ��CAS�Ը�ͬ��״̬����ԭ�Ӳ���ʵ�ֶ���ֵ���ġ�
private volatile int state;//��������,ʹ��volatile���α�֤�߳̿ɼ���
״̬��Ϣͨ��protected���͵�getState,setState,compareAndSetState���в���
//����ͬ��״̬�ĵ�ǰֵ
protected final int getState() {
return state;
}
// ����ͬ��״̬��ֵ
protected final void setState(int newState) {
state = newState;
}
//ԭ�ӵ�(CAS����)��ͬ��״ֵ̬����Ϊ����ֵupdate�����ǰͬ��״̬��ֵ����expect(����ֵ)
protected final boolean compareAndSetState(int expect, int update) {
return unsafe.compareAndSwapInt(this, stateOffset, expect, update);
}
AQS ����Դ�Ĺ�����ʽ
AQS����������Դ������ʽ
Exclusive(��ռ):ֻ��һ���߳���ִ��,��ReentrantLock���ֿɷ�Ϊ��ƽ���ͷǹ�ƽ��:
��ƽ��:�����߳��ڶ����е��Ŷ�˳��,�ȵ������õ���
�ǹ�ƽ��:���߳�Ҫ��ȡ��ʱ,���Ӷ���˳��ֱ��ȥ����,˭��������˭��
Share(����):����߳̿�ͬʱִ��,��Semaphore/CountDownLatch��Semaphore��CountDownLatch�� CyclicBarrier��ReadWriteLock ���Ƕ����ں��潲����
ReentrantReadWriteLock ���Կ��������ʽ,��ΪReentrantReadWriteLockҲ���Ƕ�д����������߳�ͬʱ��ijһ��Դ���ж���
��ͬ���Զ���ͬ�������ù�����Դ�ķ�ʽҲ��ͬ���Զ���ͬ������ʵ��ʱֻ��Ҫʵ�ֹ�����Դ state �Ļ�ȡ���ͷŷ�ʽ����,���ھ����̵߳ȴ����е�ά��(���ȡ��Դʧ�����/���ѳ��ӵ�),AQS�Ѿ��ڶ���ʵ�ֺ��ˡ�
AQS�ײ�ʹ����ģ�巽��ģʽ
ͬ����������ǻ���ģ�巽��ģʽ��,�����Ҫ�Զ���ͬ����һ��ķ�ʽ������(ģ�巽��ģʽ�ܾ����һ��Ӧ��):
ʹ���̳�AbstractQueuedSynchronizer����дָ���ķ�����(��Щ��д�����ܼ�,���Ƕ��ڹ�����Դstate�Ļ�ȡ���ͷ�)
��AQS������Զ���ͬ�������ʵ����,��������ģ�巽��,����Щģ�巽�������ʹ������д�ķ�����
�����������ͨ��ʵ�ֽӿڵķ�ʽ�кܴ�����,����ģ�巽��ģʽ�ܾ����һ�����á�
AQSʹ����ģ�巽��ģʽ,�Զ���ͬ����ʱ��Ҫ��д���漸��AQS�ṩ��ģ�巽��:
isHeldExclusively()//���߳��Ƿ����ڶ�ռ��Դ��ֻ���õ�condition����Ҫȥʵ������
tryAcquire(int)//��ռ��ʽ�����Ի�ȡ��Դ,�ɹ���true,ʧ����false��
tryRelease(int)//��ռ��ʽ�������ͷ���Դ,�ɹ���true,ʧ����false��
tryAcquireShared(int)//������ʽ�����Ի�ȡ��Դ��������ʾʧ��;0��ʾ�ɹ�,��û��ʣ�������Դ;������ʾ�ɹ�,����ʣ����Դ��
tryReleaseShared(int)//������ʽ�������ͷ���Դ,�ɹ���true,ʧ����false��
Ĭ�������,ÿ���������׳� UnsupportedOperationException�� ��Щ������ʵ�ֱ������ڲ��̰߳�ȫ��,����ͨ��Ӧ�ü�̶�����������AQS���е�������������final ,��������������ʹ��,ֻ���⼸���������Ա�������ʹ�á�
��ReentrantLockΪ��,state��ʼ��Ϊ0,��ʾδ����״̬��A�߳�lock()ʱ,�����tryAcquire()��ռ��������state+1���˺�,�����߳���tryAcquire()ʱ�ͻ�ʧ��,ֱ��A�߳�unlock()��state=0(���ͷ���)Ϊֹ,�����̲߳��л����ȡ��������Ȼ,�ͷ���֮ǰ,A�߳��Լ��ǿ����ظ���ȡ������(state���ۼ�),����ǿ�����ĸ����Ҫע��,��ȡ���ٴξ�Ҫ�ͷŶ�ô��,�������ܱ�֤state���ܻص���̬�ġ�
����CountDownLatch����,�����ΪN�����߳�ȥִ��,stateҲ��ʼ��ΪN(ע��NҪ���̸߳���һ��)����N�����߳��Dz���ִ�е�,ÿ�����߳�ִ�����countDown()һ��,state��CAS(Compare and Swap)��1���ȵ��������̶߳�ִ�����(��state=0),��unpark()�������߳�,Ȼ���������߳̾ͻ��await()��������,�������ද����
һ����˵,�Զ���ͬ����Ҫô�Ƕ�ռ����,Ҫô�ǹ�����ʽ,����Ҳֻ��ʵ��tryAcquire-tryRelease��tryAcquireShared-tryReleaseShared�е�һ�ּ��ɡ���AQSҲ֧���Զ���ͬ����ͬʱʵ�ֶ�ռ�������ַ�ʽ,��ReentrantReadWriteLock��
����Դ����� https://blog.csdn.net/qq_44787816/article/details/119167956?spm=1001.2014.3001.5501
ReentrantLock(������)ʵ��ԭ���빫ƽ���ǹ�ƽ������
ʲô�ǿ�������(ReentrantLock)?
ReentrantLock������,��ʵ��Lock�ӿڵ�һ����,Ҳ����ʵ�ʱ����ʹ��Ƶ�ʺܸߵ�һ����,֧��������,��ʾ�ܹ��Թ�����Դ�ܹ��ظ�����,����ǰ�̻߳�ȡ�����ٴλ�ȡ���ᱻ������
��java�ؼ���synchronized��ʽ֧��������,synchronizedͨ����ȡ����,�ͷ��Լ��ķ�ʽʵ�����롣���ͬʱ,ReentrantLock��֧�ֹ�ƽ���ͷǹ�ƽ�����ַ�ʽ����ô,Ҫ������ȫȫ��Ū��ReentrantLock�Ļ�,��ҪҲ����ReentrantLockͬ�������ѧϰ:1. �����Ե�ʵ��ԭ��;2. ��ƽ���ͷǹ�ƽ����
�����Ե�ʵ��ԭ��
Ҫ��֧��������,��Ҫ�����������:1. ���̻߳�ȡ����ʱ��,����Ѿ���ȡ�����߳��ǵ�ǰ�̵߳Ļ���ֱ���ٴλ�ȡ�ɹ�;2. �������ᱻ��ȡn��,��ôֻ�����ڱ��ͷ�ͬ����n��֮��,������������ȫ�ͷųɹ���
ReentrantLock֧��������:��ƽ���ͷǹ�ƽ������ν��ƽ��,����Ի�ȡ�����Ե�,���һ�����ǹ�ƽ��,��ô���Ļ�ȡ˳���Ӧ�÷��������ϵľ���ʱ��˳��,����FIFO��
���ReentrantReadWriteLock(����)
ReadWriteLock ��ʲô
������ȷһ��,����˵ ReentrantLock ����,ֻ�� ReentrantLock ijЩʱ���о��ޡ����ʹ�� ReentrantLock,���ܱ�����Ϊ�˷�ֹ�߳� A ��д���ݡ��߳� B �ڶ�������ɵ����ݲ�һ��,������,����߳� C �ڶ����ݡ��߳� D Ҳ�ڶ�����,�������Dz���ı����ݵ�,û�б�Ҫ����,���ǻ��Ǽ�����,�����˳�������ܡ���Ϊ���,�ŵ����˶�д�� ReadWriteLock��
ReadWriteLock ��һ����д���ӿ�,��д�����������������������ܵ������뼼��,ReentrantReadWriteLock �� ReadWriteLock �ӿڵ�һ������ʵ��,ʵ���˶�д�ķ���,�����ǹ�����,д���Ƕ�ռ��,���Ͷ�֮�䲻�ụ��,����д��д�Ͷ���д��д֮��Żụ��,�����˶�д�����ܡ�
����д��������������Ҫ������:
(1)��ƽѡ����:֧�ַǹ�ƽ(Ĭ��)��ƽ������ȡ��ʽ,���������Ƿǹ�ƽ���ڹ�ƽ��
(2)�ؽ���:������д����֧���߳��ؽ��롣
(3)������:��ѭ��ȡд������ȡ�������ͷ�д���Ĵ���,д���ܹ�������Ϊ������
ԭ������
ReentrantLock����������,��Щ����ͬһʱ��ֻ����һ���߳̽��з���,����д����ͬһʱ�̿�����������̷߳���,������д�̷߳���ʱ,���еĶ�������д�̶߳�����������д��ά����һ����,һ��������һ��д��,ͨ�����������д��,ʹ�ò��������һ������������˺ܴ�������
�����������������ReentrantReadWriter����
��ƽ��ѡ��:֧�ַǹ�ƽ(Ĭ��)��ƽ������ȡģʽ,���������Ƿǹ�ƽ���ڹ�ƽ
������:����֧��������,�Զ�д�߳�Ϊ��:���߳��ڻ�ȡ����֮��,�ܹ��ٴζ�ȡ����,��д�߳��ڻ�ȡд��֮�����ͬʱ�ٴλ�ȡ������д��
������:��ѭ��ȡд��,��ȡ�������ͷ�д���Ĵ���,д���ܹ�����Ϊ����
��д���ӿ����
ReentrantReadWriterLock��ReadWriterLock�Ľӿ�ʵ����,����ReadWriterLock�ӿڽ��ж�����д����������
/** @see ReentrantReadWriteLock
* @see Lock
* @see ReentrantLock
*
* @since 1.5
* @author Doug Lea
*/
public interface ReadWriteLock {
/**
* Returns the lock used for reading.
*
* @return the lock used for reading.
*/
Lock readLock();
/**
* Returns the lock used for writing.
*
* @return the lock used for writing.
*/
Lock writeLock();
}
ReentrantReadWriterLock�Լ��ṩ��һЩ�ڲ�����״̬����,����
/**
* ���ص�ǰ��������ȡ�Ĵ���,�ô��������ڻ�ȡ�����߳���,��Ϊͬһ���߳̿��Զ�λ�ȡ֧��������
* Queries the number of read locks held for this lock. This
* method is designed for use in monitoring system state, not for
* synchronization control.
* @return the number of read locks held.
*/
public int getReadLockCount() {
return sync.getReadLockCount();
}
/**
*
* ���ص�ǰ�̻߳�ȡ�����Ĵ���,Java6֮��ʹ��ThreadLocal���浱ǰ�̻߳�ȡ�Ĵ���
*/
final int getReadHoldCount() {
if (getReadLockCount() == 0)
return 0;
Thread current = Thread.currentThread();
if (firstReader == current)
return firstReaderHoldCount;
HoldCounter rh = cachedHoldCounter;
if (rh != null && rh.tid == current.getId())
return rh.count;
int count = readHolds.get().count;
if (count == 0) readHolds.remove();
return count;
}
/**
* �ж�д���Ƿ�ȡ
* @author fuyuwei
* 2017��5��21�� ����11:04:01
* @return
*/
final boolean isWriteLocked() {
return exclusiveCount(getState()) != 0;
}
/**
* �жϵ�ǰд������ȡ�Ĵ���
* @author fuyuwei
* 2017��5��21�� ����11:05:05
* @return
*/
final int getWriteHoldCount() {
return isHeldExclusively() ? exclusiveCount(getState()) : 0;
}
������������һ��ͨ������ʾ��˵����д����ʹ��
public class Cache {
static Map<String,Object> map = new HashMap<String,Object>();
static ReentrantReadWriteLock rwl = new ReentrantReadWriteLock();
static Lock r = rwl.readLock();
static Lock w = rwl.writeLock();
public static final Object get(String key){
r.lock();
try {
return map.get(key);
} finally {
r.unlock();
}
}
public static final Object put(String key,String value){
w.lock();
try{
return map.put(key, value);
}finally{
w.unlock();
}
}
public static final void clear(){
w.lock();
try{
map.clear();
}finally{
w.unlock();
}
}
}
�����HashMap��Ȼ�Ƿ��̰߳�ȫ,����������get��putʱ��ֱ�ʹ�ö�д��,��֤���̰߳�ȫ,����д��֧�ֲ������ʡ�
��д����ʵ��ԭ������
��д״̬�����
��д��ͬ�������Զ���ͬ������ʵ��ͬ������,����д״̬������ͬ������ͬ��״̬������ReentrantLock���Զ���ͬ������ʵ��,ͬ��״̬��ʾ����һ���߳��ظ���ȡ�Ĵ���,����д�����Զ���ͬ������Ҫ��ͬ��״̬(һ�����ͱ���)��ά��������̺߳�һ��д�̵߳�״̬,ʹ�ø�״̬����Ƴ�Ϊ��д��ʵ�ֵĹؼ��������һ�����ͱ�����ά������״̬,��һ����Ҫ����λ�и�ʹ�á��������,��д���������зֳ�����������,��16λ��ʾ��,��16λ��ʾд,���ַ�ʽ����ͼ��ʾ
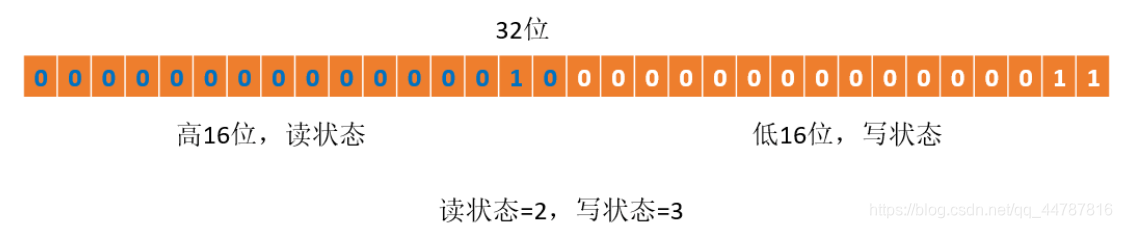
��ǰͬ��״̬��ʾһ���߳��Ѿ���ȡ��д��,���ؽ���������,ͬʱҲ������ȡ�����ζ�������д�������Ѹ��ȷ������д���Ե�״̬��?����ͨ��λ���㡣���赱ǰͬ��״ֵ̬ΪS,д״̬����S&0x0000FFFF(����16λȫ��Ĩȥ),��״̬����S>>>16(���Ų�0����16λ)����д״̬����1ʱ,����S+1,����״̬����1ʱ,����S+(1<<16),Ҳ����S+0x00010000������״̬�Ļ����ܵó�һ������:S������0ʱ,��д״̬(S&0x0000FFFF)����0ʱ,���״̬(S>>>16)����0,�������ѱ���ȡ��
д���Ļ�ȡ���ͷ�
д����һ��֧���ؽ�����������������ǰ�߳��Ѿ���ȡ��д��,������д״̬�������ǰ�߳��ڻ�ȡд��ʱ,�����Ѿ�����ȡ(��״̬��Ϊ0)���߸��̲߳����Ѿ���ȡд�����߳�,��ǰ�߳̽���ȴ�״̬,���ǿ���ReentrantReadWriteLock��tryAcquire����
protected final boolean tryAcquire(int acquires) {
/*
* Walkthrough:
* 1. If read count nonzero or write count nonzero
* and owner is a different thread, fail.
* 2. If count would saturate, fail. (This can only
* happen if count is already nonzero.)
* 3. Otherwise, this thread is eligible for lock if
* it is either a reentrant acquire or
* queue policy allows it. If so, update state
* and set owner.
*/
Thread current = Thread.currentThread();
int c = getState();
int w = exclusiveCount(c);
if (c != 0) {
// (Note: if c != 0 and w == 0 then shared count != 0)
// ���ڶ������ߵ�ǰ��ȡ�̲߳����Ѿ���ȡ�����߳�
if (w == 0 || current != getExclusiveOwnerThread())
return false;
if (w + exclusiveCount(acquires) > MAX_COUNT)
throw new Error("Maximum lock count exceeded");
// Reentrant acquire
setState(c + acquires);
return true;
}
if (writerShouldBlock() ||
!compareAndSetState(c, c + acquires))
return false;
setExclusiveOwnerThread(current);
return true;
}
�÷���������������(��ǰ�߳�Ϊ��ȡ��д�����߳�)֮��,������һ�������Ƿ���ڵ��жϡ�������ڶ���,��д�����ܱ���ȡ,ԭ������:��д��Ҫȷ��д���IJ����Զ����ɼ�,��������������ѱ���ȡ������¶�д���Ļ�ȡ,��ô�������е��������߳̾�����֪����ǰд�̵߳IJ��������,ֻ�еȴ��������̶߳��ͷ��˶���,д�����ܱ���ǰ�̻߳�ȡ,��д��һ������ȡ,��������д�̵߳ĺ������ʾ���������д�����ͷ���ReentrantLock���ͷŹ��̻�������,ÿ���ͷž�����д״̬,��д״̬Ϊ0ʱ��ʾд���ѱ��ͷ�,�Ӷ��ȴ��Ķ�д�߳��ܹ��������ʶ�д��,ͬʱǰ��д�̵߳��ĶԺ�����д�߳̿ɼ�
�����Ļ�ȡ���ͷ�
������һ��֧���ؽ���Ĺ�����,���ܹ�������߳�ͬʱ��ȡ,��û������д�̷߳���(����д״̬Ϊ0)ʱ,�����ܻᱻ�ɹ��ػ�ȡ,��������Ҳֻ��(�̰߳�ȫ��)���Ӷ�״̬�������ǰ�߳��Ѿ���ȡ�˶���,�����Ӷ�״̬�������ǰ�߳��ڻ�ȡ����ʱ,д���ѱ������̻߳�ȡ,�����ȴ�״̬����ȡ������ʵ�ִ�Java 5��Java 6��ø�������,��Ҫԭ����������һЩ����,����getReadHoldCount()����,�����Ƿ��ص�ǰ�̻߳�ȡ�����Ĵ�������״̬�������̻߳�ȡ�����������ܺ�,��ÿ���̸߳��Ի�ȡ�����Ĵ���ֻ��ѡ����ThreadLocal��,���߳�����ά��,��ʹ��ȡ������ʵ�ֱ�ø���
protected final boolean tryAcquire(int acquires) {
/*
* Walkthrough:
* 1. If read count nonzero or write count nonzero
* and owner is a different thread, fail.
* 2. If count would saturate, fail. (This can only
* happen if count is already nonzero.)
* 3. Otherwise, this thread is eligible for lock if
* it is either a reentrant acquire or
* queue policy allows it. If so, update state
* and set owner.
*/
Thread current = Thread.currentThread();
int c = getState();
int w = exclusiveCount(c);
if (c != 0) {
// (Note: if c != 0 and w == 0 then shared count != 0)
// ���ڶ������ߵ�ǰ��ȡ�̲߳����Ѿ���ȡ�����߳�
if (w == 0 || current != getExclusiveOwnerThread())
return false;
if (w + exclusiveCount(acquires) > MAX_COUNT)
throw new Error("Maximum lock count exceeded");
// Reentrant acquire
setState(c + acquires);
return true;
}
if (writerShouldBlock() ||
!compareAndSetState(c, c + acquires))
return false;
setExclusiveOwnerThread(current);
return true;
}
��tryAcquireShared(int unused)������,��������߳��Ѿ���ȡ��д��,��ǰ�̻߳�ȡ����ʧ��,����ȴ�״̬�������ǰ�̻߳�ȡ��д������д��δ����ȡ,��ǰ�߳�(�̰߳�ȫ,����CAS��֤)���Ӷ�״̬,�ɹ���ȡ������������ÿ���ͷ�(�̰߳�ȫ��,�����ж�����߳�ͬʱ�ͷŶ���)�����ٶ�״̬,���ٵ�ֵ��(1<<16)
������
������ָ����д��������Ϊ�����������ǰ�߳�ӵ��д��,Ȼ�����ͷ�,����ٻ�ȡ����,���ֶַ���ɵĹ��̲��ܳ�֮Ϊ����������������ָ�ѳ�ס(��ǰӵ�е�)д��,�ٻ�ȡ������,����ͷ�(��ǰӵ�е�)д���Ĺ��̡�
public void processData() {
readLock.lock();
if (!update) {
// �������ͷŶ���
readLock.unlock();
// ��������д����ȡ����ʼ
writeLock.lock();
try {
if (!update) {
// �����ݵ�����(��)
update = true;
}
readLock.lock();
} finally {
writeLock.unlock();
}// ���������,д������Ϊ����
}
try {// ʹ�����ݵ�����(��)
} finally {
readLock.unlock();
}
}
����ʾ����,�����ݷ��������,update����(����������volatile����)������Ϊfalse,��ʱ���з���processData()�������̶߳��ܹ���֪���仯,��ֻ��һ���߳��ܹ���ȡ��д��,�����̻߳ᱻ�����ڶ�����д����lock()�����ϡ���ǰ�̻߳�ȡд�����������֮��,�ٻ�ȡ����,����ͷ�д��,�����������������Ҫ�Ȼ�ȡд��Ϊ�˱�֤�̰߳�ȫ,����ͷ���д����ʱ�����߳̽���д���������ڻ�ȡ���������Ŀ��ܲ����������ݡ�
��������
��������֮ConcurrentHashMap���(JDK1.8�汾)��Դ�����(����)
https://blog.csdn.net/weixin_44460333/article/details/86770169
Java �� ConcurrentHashMap �IJ�������ʲô?
ConcurrentHashMap ��ʵ�� map ���ֳ����ɲ�����ʵ�����Ŀ���չ�Ժ��̰߳�ȫ�����ֻ�����ʹ�ò����Ȼ�õ�,���� ConcurrentHashMap ��캯����һ����ѡ����,Ĭ��ֵΪ 16,�����ڶ��߳�����¾��ܱ������á�
�� JDK8 ��,�������� Segment(����)�ĸ���,����������һ��ȫ�µķ�ʽʵ��,���� CAS �㷨��ͬʱ�����˸���ĸ�����������߲�����,�������ݻ��Dz鿴Դ��ɡ�
ʲô�Dz���������ʵ��?
��Ϊͬ������:���Լ�����Ϊͨ�� synchronized ��ʵ��ͬ��������,����ж���̵߳���ͬ�������ķ���,���ǽ��ᴮ��ִ�С����� Vector,Hashtable,�Լ� Collections.synchronizedSet,synchronizedList �ȷ������ص�����������ͨ���鿴 Vector,Hashtable ����Щͬ��������ʵ�ִ���,���Կ�����Щ����ʵ���̰߳�ȫ�ķ�ʽ���ǽ����ǵ�״̬��װ����,������Ҫͬ���ķ����ϼ��Ϲؼ��� synchronized��
��������ʹ������ͬ��������ȫ��ͬ�ļ����������ṩ���ߵIJ����Ժ�������,������ ConcurrentHashMap �в�����һ�����ȸ�ϸ�ļ�������,���Գ�Ϊ�ֶ���,��������������,�������������Ķ��̲߳����ط��� map,����ִ�ж��������̺߳�д�������߳�Ҳ���Բ����ķ��� map,ͬʱ����һ��������д�����̲߳������� map,�����������ڲ���������ʵ�ָ��ߵ���������
Java �е�ͬ�������벢��������ʲô����?(����)
ͬ�����Ͽ��Լ�����Ϊͨ��synchronized��ʵ��ͬ���ļ���������ж���̵߳���ͬ�����ϵķ���,���ǽ��ᴮ��ִ�С�
����ͬ������
arrayList��vector��stack:
- Vector���̰߳�ȫ��,Դ�����кܶ��synchronized���Կ���,��ArrayList���ǡ�����VectorЧ������ArrayList���
- ArrayList��Vector���������������洢�ռ�,���洢�ռ䲻���ʱ��,ArrayListĬ������Ϊԭ����50%,VectorĬ������Ϊԭ����һ��
- Vector��������capacityIncrement,��ArrayList������,�������������capacity����,Increment����,���������IJ���
- Stack�Ǽ̳���Vector,���ڶ�̬����ʵ�ֵ�һ���̰߳�ȫ��ջ
- arrayList��vector��Stack�Ĺ����ص�:��������ٶȿ�,������Ƴ����ܽϲ�(����������ص�,���ߵĵײ��Ϊ����ʵ��)
HashMap��Hashtable:
- HashMap�Ƿ�synchronized��,��Hashtable��synchronized�ġ���˵��Hashtable���̰߳�ȫ��,���Ҷ���߳̿��Թ���һ��Hashtable
- ����Hashtable���̰߳�ȫ��,Ҳ��synchronized��,�����ڵ��̻߳����±�HashMapҪ��
- HashMap���Դ���null�ļ�ֵ(key)��ֵ(value),
����Hashtable�Dz����Ե�
Collections:
Collections��Ϊ�����ṩ���ַ�������Ĺ�����,ͨ����,����ʵ�ּ��������ҡ��滻��ͬ�����ơ����ò��ɱ伯��
Collections.synchronizedCollection(Collectiont)
Collections.synchronizedList(Listlist)
Collections.synchronizedMap(Map<K, V>map)
Collections.synchronizedSet(Set t)
���漸��������Collections�����ཫ���ϱ�Ϊͬ������,�Ӷ�������ϵ��̰߳�ȫ���⡣
ͬ�������ڵ��̵߳Ļ������ܹ���֤�̰߳�ȫ,����ͨ��synchronizedͬ�����������ʲ������л�,���²���������Ч�ʵ��¡�����ͬ�������ڶ��̻߳����µĸ��ϲ���(����������������û�������ӵ�)�Ƿ��̰߳�ȫ,��Ҫ�ͻ��˴�����ʵ�ּ�����
�������� ��jdk5.0��Ҫ������,�����˲�����java.util.concurrent.*��Java�ڴ�ģ�͡�volatile������AbstractQueuedSynchronizer(���AQSͬ����),�Dz������ڶ�ʵ�ֵĻ�����
�����IJ�������:
ConcurrentHashMap:�̰߳�ȫ��HashMap��ʵ��
CopyOnWriteArrayList:�̰߳�ȫ���ڶ�����ʱ������ArrayList
CopyOnWriteArraySet:����CopyOnWriteArrayList,�������ظ�Ԫ��
ArrayBlockingQueue:�������顢�Ƚ��ȳ����̰߳�ȫ,��ʵ��ָ��ʱ���������д,����������������
LinkedBlockingQueue:��������ʵ��,��д����һ����,�ڸ߲�����д��������������,��������ArrayBlockingQueue
CopyOnWrite���ϼ�дʱ���Ƶļ��ϡ�
ͨ�������ǵ�������һ����������Ԫ�ص�ʱ��,��ֱ������ǰ��������,�����Ƚ���ǰ���Ͻ���Copy,���Ƴ�һ���µļ���,Ȼ���µļ���������Ԫ��,������Ԫ��֮��,�ٽ�ԭ���ϵ�����ָ���µļ��ϡ��������ĺô������ǿ��Զ�CopyOnWrite���Ͻ��в����Ķ�,������Ҫ����,��Ϊ��ǰ���ϲ��������κ�Ԫ�ء�����CopyOnWrite����Ҳ��һ�ֶ�д�����˼��,����д��ͬ�ļ��ϡ�
SynchronizedMap �� ConcurrentHashMap ��ʲô����?
SynchronizedMap һ����ס���ű�����֤�̰߳�ȫ,����ÿ��ֻ����һ���߳�����Ϊ map��
ConcurrentHashMap ʹ�÷ֶ�������֤�ڶ��߳��µ����ܡ�
ConcurrentHashMap ������һ����סһ��Ͱ��ConcurrentHashMap Ĭ�Ͻ�hash ����Ϊ 16 ��Ͱ,���� get,put,remove �ȳ��ò���ֻ����ǰ��Ҫ�õ���Ͱ��
����,ԭ��ֻ��һ���߳̽���,����ȴ��ͬʱ�� 16 ��д�߳�ִ��,�������ܵ��������Զ����ġ�
���� ConcurrentHashMap ʹ����һ�ֲ�ͬ�ĵ�����ʽ�������ֵ�����ʽ��,��iterator ���������ٷ����ı�Ͳ������׳�ConcurrentModificationException,ȡ����֮�����ڸı�ʱ new �µ����ݴӶ���Ӱ��ԭ�е�����,iterator ��ɺ��ٽ�ͷָ���滻Ϊ�µ����� ,���� iterator�߳̿���ʹ��ԭ���ϵ�����,��д�߳�Ҳ���Բ�������ɸı䡣
��������֮CopyOnWriteArrayList���(����)
CopyOnWriteArrayList ��ʲô,��������ʲôӦ�ó���?����Щ��ȱ��?
CopyOnWriteArrayList ��һ�������������кܶ��˳������̰߳�ȫ��,����Ϊ��仰���Ͻ�,ȱ��һ��ǰ������,�Ǿ��ǷǸ��ϳ����²��������̰߳�ȫ�ġ�
CopyOnWriteArrayList(��������)�ĺô�֮һ�ǵ����������ͬʱ������������б�ʱ,�����׳� ConcurrentModificationException����CopyOnWriteArrayList ��,д�뽫���´��������ײ�����ĸ���,��Դ���齫������ԭ��,ʹ�ø��Ƶ������ڱ���ʱ,��ȡ��������ȫ��ִ�С�
CopyOnWriteArrayList ��ʹ�ó���
ͨ��Դ�����,���ǿ���������ȱ��Ƚ�����,����ʹ�ó���Ҳ�ͱȽ����ԡ����Ǻ��ʶ���д�ٵij�����
CopyOnWriteArrayList ��ȱ��
����д������ʱ��,��Ҫ��������,�������ڴ�,���ԭ��������ݱȽ϶�������,���ܵ��� young gc ���� full gc��
��������ʵʱ���ij���,�����顢����Ԫ�ض���Ҫʱ��,���Ե���һ�� set ������,��ȡ�����ݿ��ܻ��Ǿɵ�,��ȻCopyOnWriteArrayList ����������һ����,���ǻ���û������ʵʱ��Ҫ��
����ʵ��ʹ���п���û����֤ CopyOnWriteArrayList ����Ҫ���ö�������,��һ�������е��,ÿ�� add/set ��Ҫ���¸�������,�������ʵ��̫�߰��ˡ��ڸ����ܵĻ�����Ӧ����,���ֲ����ַ���������ϡ�
CopyOnWriteArrayList �����˼��
��д����,����д�ֿ�
����һ����
ʹ������ٿռ��˼·,�����������ͻ
��������֮ThreadLocal���
ThreadLocal ��ʲô?����Щʹ�ó���?
ThreadLocal ��һ�������̸߳�������������,��ÿ���߳��ж�������һ�� ThreadLocalMap ����,��˵ ThreadLocal ����һ���Կռ任ʱ�������,ÿ���߳̿��Է����Լ��ڲ� ThreadLocalMap �����ڵ� value��ͨ�����ַ�ʽ,������Դ�ڶ��̼߳乲����
ԭ��:�ֲ߳̾������Ǿ������߳��ڲ��ı���,�����߳���������,���ڶ���̼߳乲����Java�ṩThreadLocal����֧���ֲ߳̾�����,��һ��ʵ���̰߳�ȫ�ķ�ʽ�������ڹ���������(�� web ������)ʹ���ֲ߳̾�������ʱ��Ҫ�ر�С��,�����������,�����̵߳��������ڱ��κ�Ӧ�ñ������������ڶ�Ҫ�����κ��ֲ߳̾�����һ���ڹ�����ɺ�û���ͷ�,Java Ӧ�þʹ����ڴ�й¶�ķ��ա�
�����ʹ�ó�����Ϊÿ���̷߳���һ�� JDBC ���� Connection�������Ϳ��Ա�֤ÿ���̵߳Ķ��ڸ��Ե� Connection �Ͻ������ݿ�IJ���,������� A �̹߳��� B�߳�����ʹ�õ� Connection; ���� Session ���� �����⡣
ThreadLocal ʹ������:
public class TestThreadLocal {
//�̱߳��ش洢����
private static final ThreadLocal<Integer> THREAD_LOCAL_NUM
= new ThreadLocal<Integer>() {
@Override
protected Integer initialValue() {
return 0;
}
};
public static void main(String[] args) {
for (int i = 0; i <3; i++) {//���������߳�
Thread t = new Thread() {
@Override
public void run() {
add10ByThreadLocal();
}
};
t.start();
}
}
/**
* �̱߳��ش洢������ 5
*/
private static void add10ByThreadLocal() {
for (int i = 0; i <5; i++) {
Integer n = THREAD_LOCAL_NUM.get();
n += 1;
THREAD_LOCAL_NUM.set(n);
System.out.println(Thread.currentThread().getName() + " : ThreadLocal num=" + n);
}
}
}
ʲô���ֲ߳̾�����?
�ֲ߳̾������Ǿ������߳��ڲ��ı���,�����߳���������,���ڶ���̼߳乲����Java �ṩ ThreadLocal ����֧���ֲ߳̾�����,��һ��ʵ���̰߳�ȫ�ķ�ʽ�������ڹ���������(�� web ������)ʹ���ֲ߳̾�������ʱ��Ҫ�ر�С��,�����������,�����̵߳��������ڱ��κ�Ӧ�ñ������������ڶ�Ҫ�����κ��ֲ߳̾�����һ���ڹ�����ɺ�û���ͷ�,Java Ӧ�þʹ����ڴ�й¶�ķ��ա�
ThreadLocal����ڴ�й©��ԭ��?
ThreadLocalMap ��ʹ�õ� key Ϊ ThreadLocal ��������,�� value ��ǿ���á�����,��� ThreadLocal û�б��ⲿǿ���õ������,���������յ�ʱ��,key �ᱻ������,�� value ���ᱻ������������һ��,ThreadLocalMap �оͻ����keyΪnull��Entry���������Dz����κδ�ʩ�Ļ�,value ��Զ����GC ����,���ʱ��Ϳ��ܻ�����ڴ�й¶��ThreadLocalMapʵ�����Ѿ��������������,�ڵ��� set()��get()��remove() ������ʱ��,�������� key Ϊ null �ļ�¼��ʹ���� ThreadLocal������ ����ֶ�����remove()����
ThreadLocal�ڴ�й©�������?
ÿ��ʹ����ThreadLocal,����������remove()����,������ݡ�
��ʹ���̳߳ص������,û�м�ʱ����ThreadLocal,�������ڴ�й©������,�����ص��ǿ��ܵ���ҵ�����������⡣����,ʹ��ThreadLocal��������Ҫ����һ��,�����������
��������֮BlockingQueue���
ʲô����������?�������е�ʵ��ԭ����ʲô?���ʹ������������ʵ��������-������ģ��?
��������(BlockingQueue)��һ��֧���������Ӳ����Ķ��С�
���������ӵIJ�����:�ڶ���Ϊ��ʱ,��ȡԪ�ص��̻߳�ȴ����б�Ϊ�ǿա���������ʱ,�洢Ԫ�ص��̻߳�ȴ����п��á�
�������г����������ߺ������ߵij���,��������������������Ԫ�ص��߳�,�������ǴӶ�������Ԫ�ص��̡߳��������о��������ߴ��Ԫ�ص�����,��������Ҳֻ����������Ԫ�ء�
JDK7 �ṩ�� 7 ���������С��ֱ���:
ArrayBlockingQueue :һ��������ṹ��ɵ��н��������С�
LinkedBlockingQueue :һ���������ṹ��ɵ��н��������С�
PriorityBlockingQueue :һ��֧�����ȼ���������������С�
DelayQueue:һ��ʹ�����ȼ�����ʵ�ֵ����������С�
SynchronousQueue:һ�����洢Ԫ�ص��������С�
LinkedTransferQueue:һ���������ṹ��ɵ����������С�
LinkedBlockingDeque:һ���������ṹ��ɵ�˫���������С�
Java 5 ֮ǰʵ��ͬ����ȡʱ,����ʹ����ͨ��һ������,Ȼ����ʹ���̵߳�Э�����߳�ͬ������ʵ��������,������ģʽ,��Ҫ�ļ��������ú�,wait,notify,notifyAll,sychronized ��Щ�ؼ��֡����� java 5 ֮��,����ʹ������������ʵ��,�˷�ʽ�������˴�����,ʹ�ö��̱߳�̸�������,��ȫ����Ҳ�б��ϡ�
BlockingQueue �ӿ��� Queue ���ӽӿ�,������Ҫ��;��������Ϊ����,������Ϊ�߳�ͬ���ĵĹ���,���������һ�������Ե�����,���������߳���ͼ�� BlockingQueue ����Ԫ��ʱ,�����������,���̱߳�����,���������߳���ͼ����ȡ��һ��Ԫ��ʱ,�������Ϊ��,����̻߳ᱻ����,������Ϊ���������������,�����ڳ����ж���߳̽����� BlockingQueue �з���Ԫ��,ȡ��Ԫ��,�����ԺܺõĿ����߳�֮���ͨ�š�
��������ʹ�����ij������� socket �ͻ������ݵĶ�ȡ�ͽ���,��ȡ���ݵ��̲߳��Ͻ����ݷ������,Ȼ������̲߳��ϴӶ���ȡ���ݽ�����
�̳߳�
�̳߳���ʲô�ŵ�?
1��������Դ����:���ô��ڵ��߳�,���ٶ������ٵĿ�����
2�������Ӧ�ٶȡ�����Ч�Ŀ�������߳���,���ϵͳ��Դ��ʹ����,ͬʱ���������Դ����,���������������ʱ,������Բ���Ҫ�ĵȵ��̴߳�����������ִ�С�
3������̵߳Ŀɹ����ԡ��߳���ϡȱ��Դ,��������ƵĴ���,����������ϵͳ��Դ,���ή��ϵͳ���ȶ���,ʹ���̳߳ؿ��Խ���ͳһ�ķ���,���źͼ�ء�
4�����ӹ���:�ṩ��ʱִ�С�����ִ�С����̡߳����������Ƶȹ��ܡ�
�̳߳ض�����Щ״̬?
1��RUNNING:������������״̬,�����µ�����,�����ȴ������е�����
2��SHUTDOWN:�������µ������ύ,���ǻ���������ȴ������е�����
3��STOP:�������µ������ύ,���ٴ����ȴ������е�����,�ж�����ִ��������̡߳�
4��TIDYING:���е�����������,workCount Ϊ 0,�̳߳ص�״̬��ת��Ϊ TIDYING ״̬ʱ,��ִ�й��ӷ��� terminated()��
5��TERMINATED:terminated()����������,�̳߳ص�״̬�ͻ��������
�̳߳���� https://blog.csdn.net/qq_44787816/article/details/119023713?spm=1001.2014.3001.5501
ԭ����
CAS��ԭ������� https://blog.csdn.net/qq_44787816/article/details/118895397?spm=1001.2014.3001.5501