Spring中的扫描
对Spring进行配置有三种方式,XML、java config、注解,今天我们只关注基于注解的配置方式。
基于注解的扫描就是在xml或者java config类中,指定需要扫描的包名,spring会把包中的所有的类扫描出来,然后根据扫描规则来确定都有哪些类要注册到spring容器当中。不管是基于xml配置还是基于java config配置,最终都会使用Scanner对象进行扫描,同样我们在调用AnnotationConfigApplicationContext.scan()方法时也会调用Scanner对象,这个在系列三中有提到。所以这三中扫描方式最终都会交给Scanner对象进行处理,但是今天只从AnnotationConfigApplicationContext.scan()这个流程进行分析,java config方式在后续文章中会提到。
AnnotationConfigApplicationContext.scan()的流程分析
从AnnotationConfigApplicationContext.scan()点进去我们可以看到调用了ClassPathBeanDefinitionScanner的scan()方法

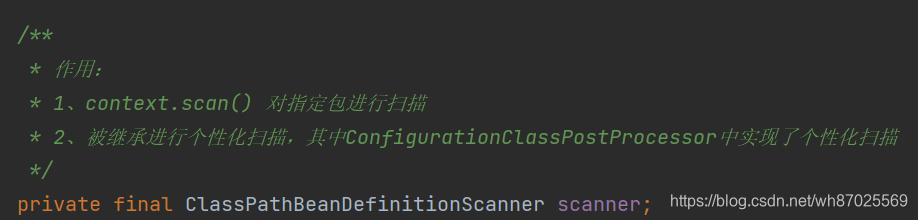
进入ClassPathBeanDefinitionScanner的scan()方法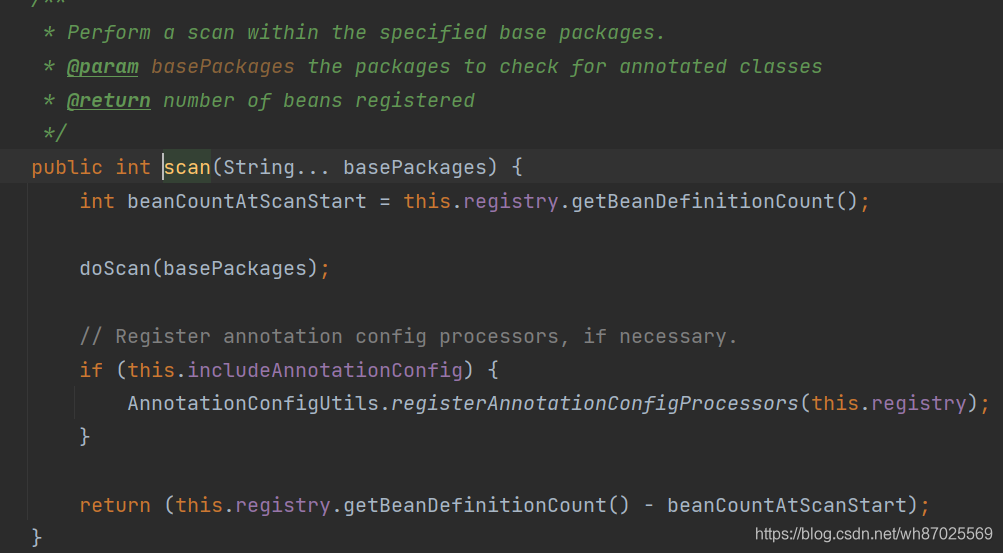
进入doScan方法,下面就是扫描方法的完整代码,其中findCandidateComponents完成了扫描
protected Set<BeanDefinitionHolder> doScan(String... basePackages) {
Assert.notEmpty(basePackages, "At least one base package must be specified");
Set<BeanDefinitionHolder> beanDefinitions = new LinkedHashSet<>();
for (String basePackage : basePackages) {
// 从指定包里获取所有的BeanDefinition 这里完成了扫描
Set<BeanDefinition> candidates = findCandidateComponents(basePackage);
for (BeanDefinition candidate : candidates) {
ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(candidate);
candidate.setScope(scopeMetadata.getScopeName());
String beanName = this.beanNameGenerator.generateBeanName(candidate, this.registry);
if (candidate instanceof AbstractBeanDefinition) {
postProcessBeanDefinition((AbstractBeanDefinition) candidate, beanName);
}
if (candidate instanceof AnnotatedBeanDefinition) {
AnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition) candidate);
}
if (checkCandidate(beanName, candidate)) {
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);
definitionHolder =
AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
beanDefinitions.add(definitionHolder);
registerBeanDefinition(definitionHolder, this.registry);
}
}
}
return beanDefinitions;
}
findCandidateComponents方法
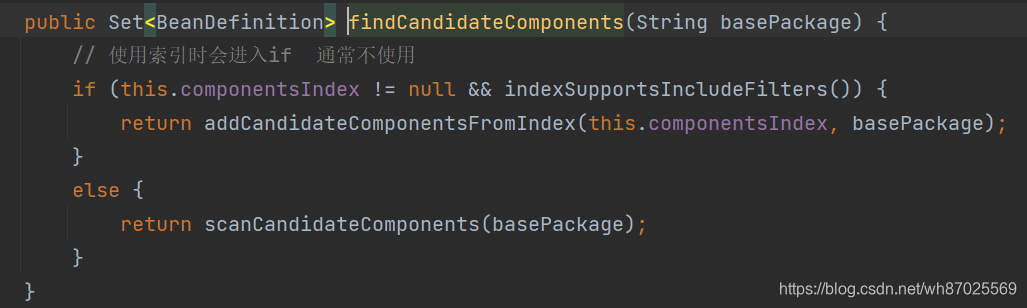
进入到scanCandidateComponents
private Set<BeanDefinition> scanCandidateComponents(String basePackage) {
Set<BeanDefinition> candidates = new LinkedHashSet<>();
try {
// 把包名转换为路径
String packageSearchPath = ResourcePatternResolver.CLASSPATH_ALL_URL_PREFIX +
resolveBasePackage(basePackage) + '/' + this.resourcePattern;
// 从相关路径中扫描出所有的类,里面主要保存了相关class文件的InputStream
Resource[] resources = getResourcePatternResolver().getResources(packageSearchPath);
boolean traceEnabled = logger.isTraceEnabled();
boolean debugEnabled = logger.isDebugEnabled();
for (Resource resource : resources) {
if (traceEnabled) {
logger.trace("Scanning " + resource);
}
// 判断InputStream指向的class是否存在
if (resource.isReadable()) {
try {
// 通过asm进行扫描并把扫描结果包装为MetadataReader
MetadataReader metadataReader = getMetadataReaderFactory().getMetadataReader(resource);
// 验证是否符合扫描规则
if (isCandidateComponent(metadataReader)) {
ScannedGenericBeanDefinition sbd = new ScannedGenericBeanDefinition(metadataReader);
sbd.setSource(resource);
if (isCandidateComponent(sbd)) {
if (debugEnabled) {
logger.debug("Identified candidate component class: " + resource);
}
candidates.add(sbd);
}
else {
if (debugEnabled) {
logger.debug("Ignored because not a concrete top-level class: " + resource);
}
}
}
else {
if (traceEnabled) {
logger.trace("Ignored because not matching any filter: " + resource);
}
}
}
catch (Throwable ex) {
throw new BeanDefinitionStoreException(
"Failed to read candidate component class: " + resource, ex);
}
}
else {
if (traceEnabled) {
logger.trace("Ignored because not readable: " + resource);
}
}
}
}
catch (IOException ex) {
throw new BeanDefinitionStoreException("I/O failure during classpath scanning", ex);
}
return candidates;
}
我们来分析这段代码,首先通过报名扫描出所有的Resource,我们可以把Resource理解为inputStream的包装类,拥有了某个文件的Resource对象就可以实现对这个类文件(类编译后的class文件)进行读取。那么我们看出resource对象被下面这个方法使用
MetadataReader metadataReader = getMetadataReaderFactory().getMetadataReader(resource);
这一行代码就实现了把类文件转换为MetadataReader 的动作,MetadataReader 里面封装了这个类的信息,里面有类名,注解信息等,也就是这里完成了asm扫描,可以看出asm完成的事情就是从class文件中解析出类的信息,有的小伙伴就要疑惑了,为啥这里不使用反射?反射也是可以完成对class文件的解析的,这里大家可以思考下,在文章末尾会给出答案。
那我们先进入这个方法,看看asm是怎么进行完成扫描的
可以看到这段代码根本看不懂,哈哈,能看懂也就没这篇文章了
那我先依照spring的实现自己实现一个从class到类信息的解析,首先看下代码结构

解释下每个类的作用
AsmBean:要扫描的示例类,也就是要从这个类的class文件中扫描出类的信息
AsmTest:测试类,里面的调用流程跟上面看到的spring中的扫描基本是一样的
MyAnnotationVisitor:Annotation的访问类
MyClassVisitor:Class的访问类
MyMetaData:保存类信息的包装类
先看一眼Test方法
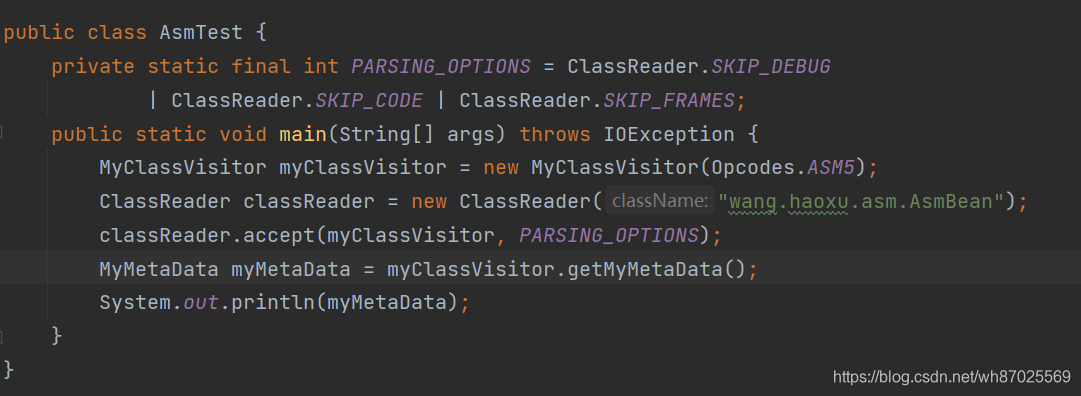
没有了解过设计模式中的访问者模式的小伙伴对这里面的两个Visitor一定很疑惑,这是啥?
我们先看这一行
ClassReader classReader = new ClassReader("wang.haoxu.asm.AsmBean");
ClassReader 类是asm提供的,我们把全类名传进去,asm就会去读取这个类的class文件,这里构造方法被重载为多个,可以直接传class文件。
当读取class文件时会获取到太多的信息,我们如何方便的获取部分信息呢?
那么使用访问者模式就可以实现,我们可以传进去一个Visitor(通过ClassReader 的accept方法传进去的),当ClassReader 读取到不同的信息时就会调用Visitor中的方法,这些方法都是定义到Visitor接口中的,所以我们只需要根据我们的需求实现Visitor接口的方法就可以。举个例子,这里我们可以这么理解,当ClassReader 扫描到类名的时候就调某个方法把类名当参数传进去, 扫描到方法时候就调某个方法把扫描的方法传进去,注解也是同理。所以我们就可以在Visitor中封装类的信息,然后提供一个get方法,为调用者提供获取封装类的途径
下面是我的MyClassVisitor得实现:

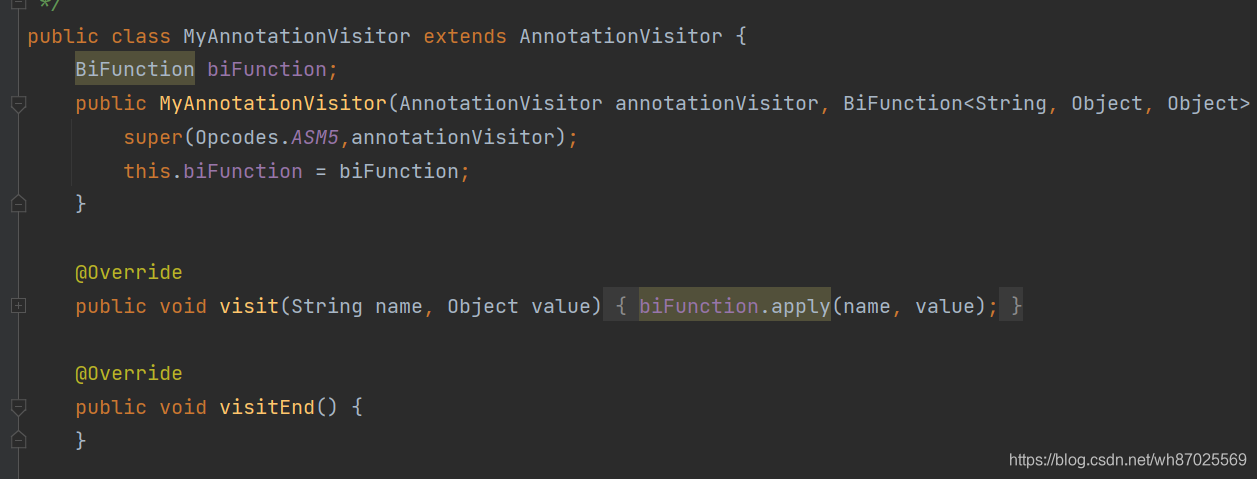
MyAnnotationVisitor的实现,我在这里完成了对注解属性和属性值得保存
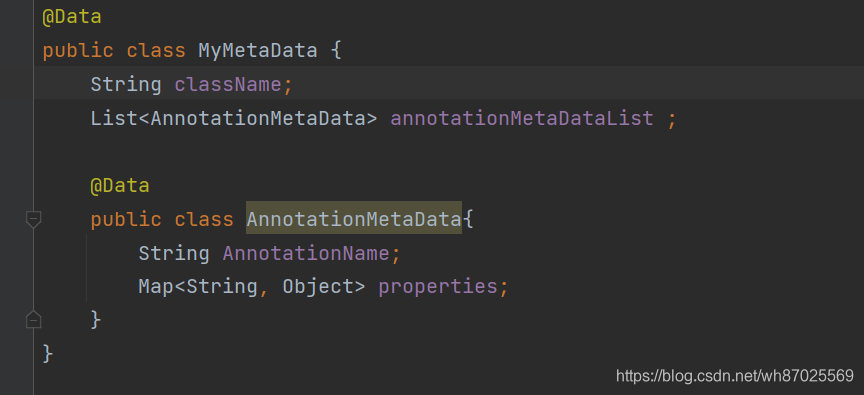
对类信息的封装
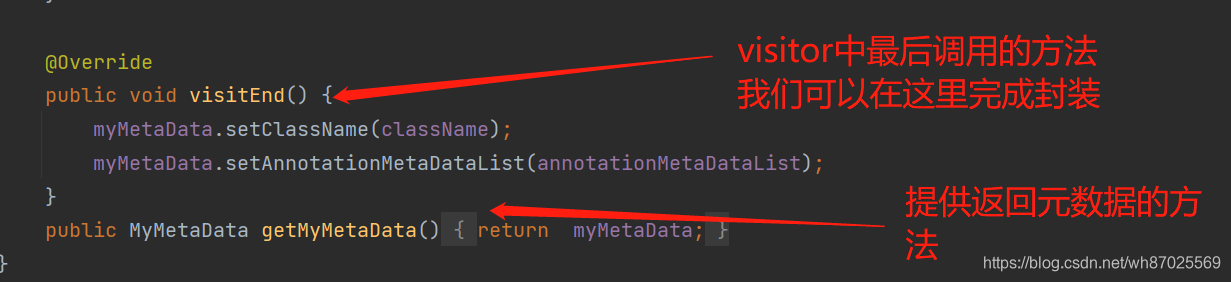
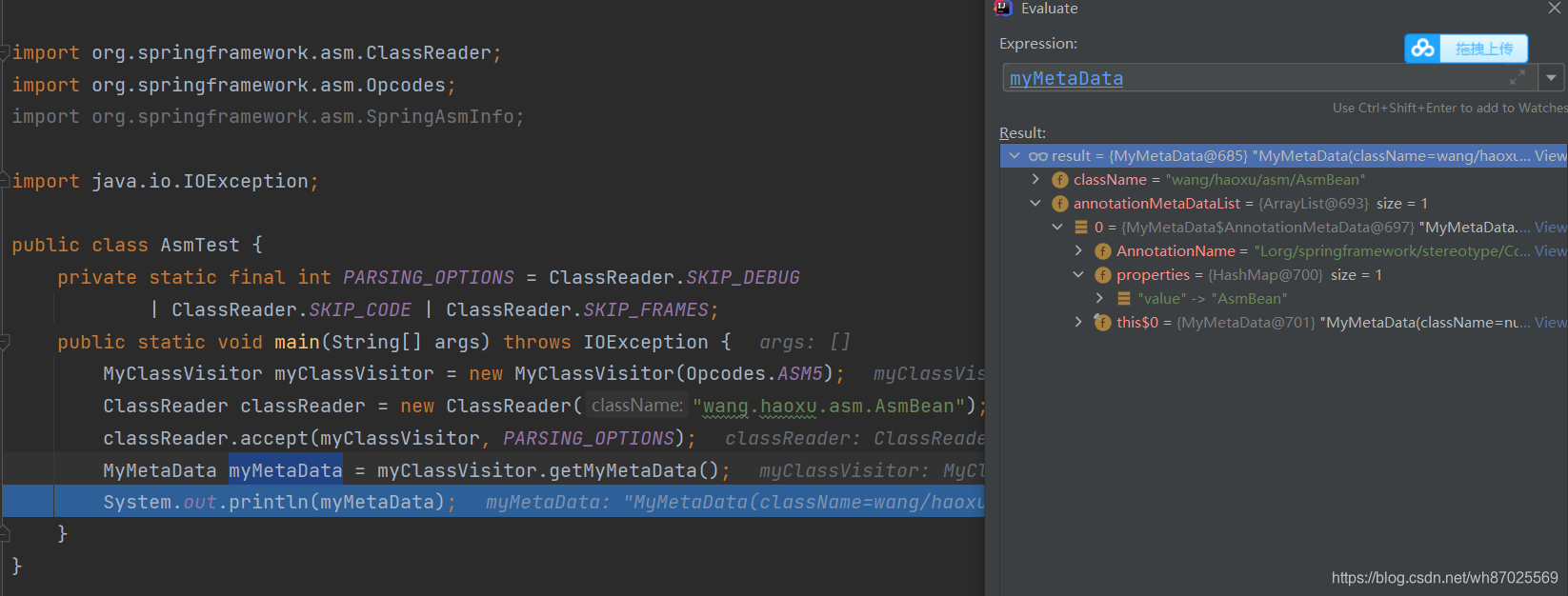
到这里我们就完成了对类的扫描,我们看下要扫描的类和扫描的结果
结果
支持我们的模拟扫描完成,代码传到了gitee中,需要的小伙伴自取
代码链接点击进入
下面我们就可以分析spring的源码了,其实在流程上跟我上面写的基本无异(其实我是参考spring源码写的)

具体的扫描,这次再看是不是很简单了


基本上跟我示例中的流程一样,所以不再做具体分析
为什么使用asm进行扫描?
当我们尝试搜索这个问题时,大多数的回答都是asm的性能比反射要好。但我一直觉着这点性能上区别不至于让spring选择sam;
从刚开始看spring源码我很困惑这个问题,最终通过路神的点播才能解惑,不管是一个类库还是一个框架的要追求对使用者的代码的最小侵入性,如果我们使用反射的方式,是需要把这个类加载到jvm中的,这时候就会执行一些固定的流程,比如初始化static的成员变量等,正常这些流程是要用户使用new对象时才执行的,不能在spring初始化时就执行,这违反了用户的行为,使用asm则可以解决这个问题。不知道你是不是认可这个观点?