�ܶ�С�����ѧϰ��Javaһ��ʱ���,���ɱ����Ҫ�������Ե�����
���Ա����Ǹ���ҿ����µ�ͼ������
��Ҫ��һЩ�����бȽ����ױ��ʵ�������,������~
1. ��������������������?
��:��������������Ҫ�����¼�������:
1.��װ:
��װ�ǰѹ��̺����ݰ�������,���������ݵIJ��������������ṩ�ķ�ʽ�����ǿ��Խ������и���������г����װ�γ���,Ҳ����ͨ��private���η�����װ�����뷽��,������Ҫע�����,��װ����Ҫ�ֶ��ṩ��Ӧ����װ��Դ������IJ�����ʽ��
2.�̳�:�̳���һ��������IJ��ģ��,�������������������,���ṩ��һ����ȷ�������Եķ��������ǿ��Դ����е�����������һ���µ���,������̳�Ϊ��̳С�����̳���ԭʼ�������,�����Ϊԭʼ���������(����),��ԭʼ���Ϊ����Ļ���(����)����������Դ����Ļ�������̳з�����ʵ������,����������Ļ������µķ���ʹ֮���ʺ��������Ҫ��
3.��̬��:��̬����ָ���Ծ������β�ͬ��IJ�����,�ṩͨ�õĽ����������̬�����Ծ�����������Ϊ���������빲��������,�ܺõĽ����Ӧ�ó�����ͬ�����⡣������ʹ�õ���:
�������͡����������ͳһ����������,���绨ľ���游�Ӿ���
�������͡���֮ǰ���������͵�������������»ָ����������,���绨ľ�����̽����ؼһ�ױ��
4.����:������Ǻ���һ���������뵱ǰĿ���ص���Щ����,�Ա����ֵ�ע���뵱ǰĿ���йصķ��档���������˽�ȫ������,��ֻ��ѡ�����е�һ����,��ʱ���ò���ϸ�ڡ����������������,һ�ǹ��̳���,�������ݳ���
2. ��������ӿڵ���ͬ:
������:
����������abstract�ؼ��ֽ������Ρ����һ���ຬ�г���,��������Ϊ������,�������������ǰ��abstract�ؼ������Ρ���Ϊ�������к�������ʵ�ֵķ���,���Բ����ó����ഴ������
���������ӵ�г�Ա��������ͨ�ij�Ա������
���������ͨ�����Ҫ����������:
1)��������Ϊpublic����protected(��Ϊ���Ϊprivate,���ܱ�����̳�,�������ʵ�ָ÷���),ȱʡ�����Ĭ��Ϊpublic��
2)�������������������;
3)���һ����̳���һ��������,���������ʵ�ָ���ij������������û��ʵ�ָ���ij���,����뽫����Ҳ����ΪΪabstract�ࡣ
�ӿ�:
�ӿ��еı����ᱻ��ʽ��ָ��Ϊpublic static final����,����ֻ����public static final����,��private���λᱨ�������,�������ᱻ��ʽ��ָ��Ϊpublic abstract������ֻ����public abstract����,�������ؼ���,����private��protected��static�� final�����λᱨ�������,���ҽӿ������еķ��������о����ʵ��,Ҳ����˵,�ӿ��еķ������붼�dz�����
������ͽӿڵ�����:
������ϵ�����
1)һ����ֻ�ܼ̳�һ��������,��һ����ȴ����ʵ�ֶ���ӿ�
2)�������еij�Ա���������Ǹ������͵�,���ӿ��еij�Ա����ֻ����public static final���͵�
3)�ӿ��в��ܺ��о�̬������Լ���̬����,������������о�̬�����;�̬����
4)����������ṩ��Ա������ʵ��ϸ��,���ӿ���ֻ�ܴ���public abstract ����
5)������ij���������public,protected,default����,���ӿڵķ���ֻ����public
��Ʋ����ϵ�����
1)�������Ƕ�һ������ij���,���������,���ӿ��Ƕ���Ϊ�ij��������Ƕ�������������г���,�������ԡ���Ϊ,���ǽӿ�ȴ�Ƕ���ֲ�(��Ϊ)���г���
���Գ������ع��Ľ��,�ӿ�����ƵĽ����
2)��Ʋ��治ͬ,��������Ϊ�ܶ�����ĸ���,����һ��ģ��ʽ��ơ����ӿ���һ����Ϊ�淶,����һ�ַ���ʽ��ơ�
3. ��˵һ�³��������ݽṹ:
1.ջStack:
�ֳƶ�ջ,���������������Ա�,�������ǽ������ڱ��һ�˽��в����ɾ������,�������������κ�λ�ý������ӡ����ҡ�ɾ���Ȳ�����
���ǿ��Լ������:ջ�ṹ��Ԫ�صĴ�ȡ������Ҫ��:
�Ƚ����(Ҳ����˵,ջ��Խ����ȥ��Ԫ��,��Խ��������)
����:�ӵ�ѹ������,��ѹ��ȥ���ӵ�������,��ѹ��ȥ���ӵ�������,����ǹʱ,�ȵ���������ӵ�,Ȼ����ܵ���������ӵ���
����,ջ����ڡ����ڵĶ���ջ�Ķ���λ�á�������Ҫ֪����������:
1)ѹջ:���Ǵ�Ԫ�ء���,��Ԫ�ش洢��ջ�Ķ���λ��,ջ������Ԫ��������ջ�����ƶ�һ��λ�á�
2)��ջ:����ȡԪ�ء���,��ջ�Ķ���λ��Ԫ��ȡ��,ջ������Ԫ��������ջ�������ƶ�һ��λ�á�
2.����queue:
�ֳƶ�,��ͬ��ջһ��,Ҳ��һ�������������Ա�,�������ǽ������ڱ���һ�˽��в���,���ڱ�����һ�˽���ɾ����
���ǿ��Լ������:���нṹ��Ԫ�صĴ�ȡ������Ҫ��:
�Ƚ��ȳ�(Ҳ����˵,���ȴ��ȥ��Ԫ��,�ǿ�������ȡ����)
����:�����������Ŷ������,���ȵ��������ȸ���,����˵õ�ǰ����˶������������ܸ��
����:���е���ڡ����ڸ�ռһ��
3.����Array:
�������Ԫ������,���������ڴ��п���һ�������Ŀռ�,���ڴ˿ռ���Ԫ�ء�������һ�л�,��1�ų��ᵽ���һ�ڳ���,ÿ�ڳ��ᶼ���Լ��Ĺ̶����,�������˿���ͨ������ſ����ҵ��Լ���λ�á�
���ǿ��Լ������:����ṹ��Ԫ�صĴ�ȡ������Ҫ��:
����Ԫ�ؿ�:ͨ������,���Կ��ٷ���ָ��λ�õ�Ԫ�ء�
��ɾԪ����:
����ָ��һ����������Ԫ��,������ԭ����ij���,������Ҫ����һ���³��ȵ�����,��ָ����Ԫ�ش洢��ָ������λ��,�ٰ�ԭ����Ԫ�ظ�������,���Ƶ��������Ӧ������λ�á�
����ָ��һ������ɾ��Ԫ��:������ԭ����ij���,������Ҫ����һ���³��ȵ�����,��ԭ����Ԫ�ظ����������Ƶ��������Ӧ������λ��,ԭ������ָ������λ��Ԫ�ز����Ƶ��������С�
4.����LinkedList:
��һϵ�нڵ�Node(������ÿһ��Ԫ�س�Ϊ�ڵ�)���,�ڵ����������ʱ��̬���ɡ�ÿ���ڵ������������:һ���Ǵ洢����Ԫ�ص�������,��һ���Ǵ洢��һ���ڵ��ַ��ָ�������dz�˵�������ṹ�е���������˫��������
����������ܵ��ǵ���������
���ǿ��Լ������:�����ṹ��Ԫ�صĴ�ȡ������Ҫ��:
����ڵ�֮��,ͨ����ַ�������ӡ�
����:���г�������,����ͨ����һ����������һ����,�������γ�һ��������
����Ԫ����:�����ij��Ԫ��,��Ҫͨ�����ӵĽڵ�,����������ָ��Ԫ��
��ɾԪ�ؿ�:
����Ԫ��:ֻ��Ҫ�������¸�Ԫ�صĵ�ַ���ɡ�
ɾ��Ԫ��:ֻ��Ҫ�������¸�Ԫ�صĵ�ַ���ɡ�
5.�����
������BinaryTree:ÿ���ڵ㲻����2��������(tree)
���ǿ��Լ��������������Ľṹ,ֻ����ÿ���ڵ��϶����ֻ���������ӽڵ㡣
��������ÿ���ڵ�������������������ṹ�����ϵĽи��ڵ�,���߱����������������͡�����������
�����:�������������һ�Ŷ��������,���ڵ�����,������Ȼ��һ�Ŷ����������Ҳ����ζ��,���ļ�ֵ��Ȼ������ġ���������ٶ��ر��,����ƽ����,����Ҷ��Ԫ�����ٺ������������ڶ���
��������ص�:
- �ڵ�����Ǻ�ɫ�Ļ��ߺ�ɫ��
- ���ڵ��Ǻ�ɫ��
- Ҷ�ӽڵ�(��ָ�սڵ�)�Ǻ�ɫ��
- ÿ����ɫ�ڵ���ӽڵ㶼�Ǻ�ɫ��
- �κ�һ���ڵ㵽��ÿһ��Ҷ�ӽڵ������·���Ϻ�ɫ�ڵ�����ͬ
4. ʲô������ת��?ʲô������ת��?
��JAVA��,�̳���һ����Ҫ������,ͨ��extends�ؼ���,������Ը��ø���Ĺ���,�����������㵱ǰ���������,�����������д�����еķ�����������չ��
��ô����������оʹ����Ŷ�̬��Ӧ�á�����������ת�ͷ�ʽ,�ֱ���:����ת�ͺ�����ת�͡�
����ת��:���Ѳ�ͬ�������������������,�������β�ͬ�������֮��IJ���,д��ͨ�õĴ���,����ͨ�õı��,ͳһ���ñ���
����:����Parent,����Child
���������ָ���������:Parent p=new Child();
˵��:����ת��ʱ,������ɸ������,ֻ�ܵ��ø���Ĺ���,���������д�˸������������ķ���,������ִ�еľ��������ع���Ĺ��ܡ����Ǵ�ʱ�����ǰ��Լ������Ǹ������͵�,����������Դʹ�õĻ��Ǹ����͵ġ�
����:��ľ���游�Ӿ�,��Ҷ��ѻ�ľ����������,����ʵ�ʴӾ����ǻ�ľ��,����,��ľ��ֻ����������������,�ھ�Ӫ���Dz����Ի�ױ�ġ�
����ת��(����):��������õ�ָ���������,�����б���Ҫ��ȡ��ǿ��ת�͡������֮ǰ�������������������Ȼ��ִ����������й���,������Ҫ���»ָ����������
Parent p = new Child();//����ת��,��ʱ,p��Parent����
Child c = (Child)p;//��ʱ,��Parent���͵�pת��С����Child
��ʵ,�൱�ڴ�����һ���������һ��,�����ø����,Ҳ�������Լ���
˵��:����ת��ʱ,��Ϊ�˷���ʹ����������ⷽ��,Ҳ����˵����������˹�����չ,�Ϳ���ֱ��ʹ������ܡ�
����:��ľ�����̽���,�Ͳ���Ҫ�ٿ�����������,�Ϳ��ԡ��Ծ������ơ���
5. �Ƚ�һ��String��StringBuilder
String
1. �ص�:
����֮�������Dz��ɱ��,ÿ��ƴ���ַ���,��������µĶ���
- �����ֱ�ӡ� �� �����ַ�������ƴ�Ӳ�����,�������ַ�����������
- �����ֱ��ͨ��new��ʽ������,�����ڶ���
2. ������ʽ:
String() String(String s) String(char[] c) String(byte[] b) String s = ��abc��;
3. ��ȱ��:
- �ŵ�:String���ṩ�˷ḻ�Ĺ��ڲ����ַ����ķ���,����:ƴ�ӡ���ȡ��Ӧ�±괦���ַ�����ȡ�Ӵ��ȵ�
- ȱ��:�ڽ����ַ���ƴ��+=��ʱ��,Ч�ʱȽϵ�
4. StringתStringBuilder:
String s = ��abc��; StringBuilder sb = new StringBuilder(s);
StringBuilder
1. �ص�:
StringBuilder��һ�����ȿɱ���ַ�������,�ڴ�����ʱ��,����һ������Ϊ16��Ĭ�Ͽռ�
��ƴ���ַ�����ʱ��,ʵ��ԭ����Ļ���֮�Ͻ���ƴ��,������Ȳ���������
����StringBuilder�ڴ���֮��,��Ӧ�IJ���һֱ����һ������
2. ������ʽ:
StringBuilder sb = new StringBuilder();//����һ������Ϊ16��StringBuilder����
StringBuilder sb = new StringBuilder(��abc��);//��ָ���ַ�������Ϊ��abc���ķ�ʽ����һ��StringBuilder����
3. ��ȱ��:
- �ŵ�:��ƴ�ӵ�ʱ��,��������µĶ���,�ͱ�������Ϊƴ��Ƶ�����ɶ��������,����˳����Ч��
- ȱ��:�����ַ����IJ���,��̫����,������ʹ�õ�ʱ��,���ƴ�Ӳ����ܶ�Ļ�:
�Ƚ�StringתΪStringBuilder����ƴ��,ƴ�����֮����ת��String
4. StringBuilderתString:
StringBuilder sb = new StringBuilder();
sb.append(��abc��);
String s = sb.toString();
6.ʲô�Ƿ���ͨ���?ʲô�Ƿ��͵�������?
��ʹ�÷�������߽ӿ�ʱ,���ݵ�������,�������Ͳ�ȷ��,����ͨ��ͨ���<?>��ʾ������һ��ʹ�÷��͵�ͨ�����,ֻ��ʹ��Object���еĹ��Է���,������Ԫ������������ʹ�á�
ͨ�������ʹ��
���͵�ͨ���:��֪��ʹ��ʲô���������յ�ʱ��,��ʱ����ʹ��?,?��ʾδ֪ͨ�����
ͨ�����ʹ��----������
֮ǰ���÷��͵�ʱ��,ʵ�����ǿ����������õ�,ֻҪ����Ϳ������á�������JAVA�ķ����п���ָ��һ�����͵�������������
���͵�����:
- ��ʽ:
�������� <? extends �� > �������� - ����:
ֻ�ܽ��ո����ͼ�������
���͵�����:
- ��ʽ:
�������� <? super �� > �������� - ����:
ֻ�ܽ��ո����ͼ��丸����
7. �߳��м���״̬?��������ô�л���?
�߳���������,��Ҫ������״̬:
- �½�״̬(New) : ���̶߳�����ͽ������½�״̬.��:Thread t = new MyThread();
- ����״̬(Runnable):�������̶߳����start()����,�̼߳�Ϊ�������״̬.
���ھ���(������)״̬���߳�,ֻ��˵���߳��Ѿ�������,��ʱ�ȴ�CPU����ִ��,������ִ����t.start()���߳������ͻ�ִ�� - ����״̬(Running):��CPU�����˴��ھ���״̬���߳�ʱ,���̲߳���������ִ��,�����뵽����״̬
����״̬�ǽ�������״̬��Ψһ���,Ҳ�����߳���Ҫ��������״̬״ִ̬��,�ȵô��ھ���״̬ - ����״̬(Blocked):������״̬�е��߳�����ij��ԭ��,��ʱ������CPU��ʹ��Ȩ,ִֹͣ��,��ʱ��������״̬,ֱ����������״̬���л��ᱻCPUѡ���ٴ�ִ��.
��������״̬������ԭ��ͬ,����״̬�ֿ���ϸ�ֳ�����:
�ȴ�����:����״̬�е��߳�ִ��wait()����,���߳̽��뵽�ȴ�����״̬
ͬ������:�߳��ڻ�ȡsynchronizedͬ����ʧ��(��Ϊ���������߳�ռ��),�������ͬ������״̬
��������:�����̵߳�sleep()����join()����I/O����ʱ,�̻߳���뵽����״̬.��sleep()״̬��ʱ.join()�ȴ��߳���ֹ���߳�ʱ����I/O�������ʱ�߳�����ת�����״̬ - ����״̬(Dead):�߳�ִ�����˻������쳣�˳���run()����,���߳̽�����������
���� �� ִ��:Ϊ�����̷߳���CPU���ɱ�Ϊִ��״̬"
ִ�� �� ����:����ִ�е��߳�����ʱ��Ƭ���걻����CPU��ִͣ��,�ͱ�Ϊ����״̬
ִ�� �� ����:���ڷ���ij�¼�,ʹ����ִ�е��߳�����,��ִ��,����ִ�б�Ϊ����
(�����߳����ڷ����ٽ���Դ,����Դ���ڱ������̷߳���)
��֮,��������֮ǰ��Ҫ����Դ,����������Ϊ����״̬,�ȴ�����CPU�ٴ�ִ��
8.ʲô���̳߳�?�̳߳���ʲô�ŵ�?
����ʹ���̵߳�ʱ���ȥ����һ���߳�,����ʵ�������dz����,���Ǿͻ���һ������:
����������߳������ܶ�,����ÿ���̶߳���ִ��һ��ʱ��̵ܶ�����ͽ�����,����Ƶ�������߳̾ͻ���ϵͳ��Ч��,��ΪƵ�������̺߳������߳���Ҫʱ�䡣
������������Java�п���ͨ���̳߳���������Щ����:
�̳߳�:��ʵ����һ�����ɶ���̵߳�����,���е��߳̿��Է���ʹ��,ʡȥ��Ƶ�������̶߳���IJ���,���跴�������̶߳����Ĺ�����Դ��
���������̳߳��ܹ����������ô�:
- ������Դ���ġ������˴����������̵߳Ĵ���,ÿ�������̶߳����Ա��ظ�����,��ִ�ж������
- �����Ӧ�ٶȡ�������ʱ,������Բ���Ҫ�ĵȵ��̴߳�����������ִ�С�
- ����̵߳Ŀɹ����ԡ����Ը���ϵͳ�ij�������,�����̳߳��й������̵߳���Ŀ,��ֹ��Ϊ���Ĺ�����ڴ�,���ѷ�������ſ��(ÿ���߳���Ҫ��Լ1MB�ڴ�,�߳̿���Խ��,���ĵ��ڴ�Ҳ��Խ��,�������)��
9. ���Java�ڴ�����˽����?��̸̸:
Java������������ڴ������������ʱ�����ڴ�:�������������ջ�����ط���ջ���ѡ����������,���з������Ͷ������̹߳�����������,�����������̸߳����������
1. ���������
�����������һ���С���ڴ�,�����Կ����ǵ�ǰ�߳���ִ�е��к�ָʾ�����ֽ��������������ʱ�����ͨ���ı������������ֵ��ѡȡ��һ����Ҫִ�е��ֽ����ָ��,��֧��ѭ������ת���쳣�������ָ̻߳��Ȼ������ܶ���Ҫ�����������������ɡ�����߳�����ִ�е���һ��Java����,�����������¼��������ִ�е�������ֽ���ָ��ĵ�ַ;�������ִ�е���Native����,�����������Ϊ�ա����ڴ�������Ψһһ����Java������淶��û�й涨�κ�OutOfMemotyError���������
2 Java�����ջ
�����ջ��������Java����ִ�е��ڴ�ģ��:ÿ��������ִ�е�ͬʱ���ᴴ��һ��ջ֡���ڴ���ֲ���������������ջ����̬���ӡ��������ڵ���Ϣ��ÿ�������ӵ���ֱ����ɵĹ���,�Ͷ�Ӧ��һ��ջ֡�������ջ����ջ����ջ�Ĺ��̡�
ջ�ڴ���������ջ,����˵�������ջ�оֲ��������IJ���
�ֲ�����������˱����ڿ�֪�ĸ��ֻ�����������(boolean��byte��char��short��int��float��long��double)����������(refrence)���ͺ�returnAddress����(ָ����һ���ֽ���ָ��ĵ�ַ)
����64λ���ȵ�long��double���͵����ݻ�ռ�������ֲ������ռ�,�������������ֻռ��1����
Java������淶���������涨�������쳣״��:����߳������ջ��ȴ�������������������,���׳�StackOverflowError�쳣������������չʱ�����뵽�㹻���ڴ�,�ͻ��׳�OutOfMemoryError�쳣
3 ���ط���ջ
���ط���ջ�������ջ���ӵ������Ƿdz����Ƶ�,���ǵ������������ջΪ�����ִ��Java����(Ҳ�����ֽ���)����,�����ط���ջ��Ϊ�����ʹ�õ���Native��������
���ط���ջ����Ҳ���׳�StackOverflowError��OutOfMemoryErroy�쳣
4 Java��
����Java��������������ڴ�������һ�顣Java���DZ������̹߳�����һ���ڴ�����,�������������ʱ��,���ڴ������ΨһĿ���Ǵ�Ŷ���ʵ��,�������еĶ���ʵ��������������ڴ档���еĶ���ʵ�������鶼�ڶ��Ϸ���
Java���������ռ�����������Ҫ����Java��ϸ��Ϊ�������������
��������,���ֵ�Ŀ�Ķ���Ϊ�˸��õĻ����ڴ�,���߸���ط����ڴ�
Java�ѿ��Դ��������ϲ��������ڴ�ռ���,ֻҪ�����������ļ��ɡ�����ڶ���û�����ʵ������,���Ҷ�Ҳ������չʱ�����׳�OutOfMemoryError�쳣
5 ������
�����������ڴ����ѱ���������ص�����Ϣ����������̬��������ʱ�����������Ĵ��������
����Java��һ������Ҫ�������ڴ�Ϳ���ѡ��̶���С���߿���չ��,������ѡ��ʵ�������ռ������������ڴ����Ŀ����Ҫ����Գ����صĻ��պͶ����͵�ж��
���������������ڴ��������ʱ,���׳�OutOfMemoryErroy�쳣
1.6 ����ʱ������
���Ƿ�������һ���֡�Class�ļ��г����йصİ汾���ֶΡ��������ӿڵ�������Ϣ�⡢����һ����Ϣ�dz�����,���ڴ�ű��������ɵĸ����������ͷ�������,�ⲿ�����ݽ�������غ���뷽����������ʱ�������д��
Java���Բ���Ҫ����һ��ֻ�б����ڲ��ܲ���,Ҳ���ǿ��ܽ��µij����������,�������Ա�������Ա���õñȽ϶�ı���String���intern()����
���������������뵽�ڴ�ʱ���׳�OutOfMemoryError�쳣
10. ̸̸���static���˽�
static��Java�е�һ���ؼ���,�����������η���������������顢�ڲ���,������ʹ�þ�̬����
1.static����
static����һ�������̬����,���ھ�̬�������������κζ���Ϳ��Խ��з���,��˶��ھ�̬������˵,��û��this��,��Ϊ�����������κζ���,��Ȼ��û�ж���,��̸����this�ˡ����������������,�ھ�̬�����в��ܷ�����ķǾ�̬��Ա�����ͷǾ�̬��Ա����,��Ϊ�Ǿ�̬��Ա����/�������DZ�����������Ķ�����ܹ������á�
ע��:��Ȼ�ھ�̬�����в��ܷ��ʷǾ�̬��Ա�����ͷǾ�̬��Ա����,�����ڷǾ�̬��Ա�������ǿ��Է��ʾ�̬��Ա����/�����ġ�
2.static����
static����Ҳ������̬����,��̬�����ͷǾ�̬������������:��̬���������еĶ���������,���ڴ���ֻ��һ������������ڷ�������,�����ҽ���������μ���ʱ�ᱻ��ʼ������final�Ͳ���final��static������ʼ����λ�ò�һ���������Ǿ�̬�����Ƕ�����ӵ�е�,�ڴ��������ʱ��ʼ��,���ڶ������,��������ӵ�еĸ�������Ӱ�졣
static��Ա�����ij�ʼ��˳���ն����˳����г�ʼ����
3.static�����
static�ؼ��ֻ���һ���ȽϹؼ������þ��������γɾ�̬��������Ż���������,��Ϊ��̬��Դֻ�����һ�Ρ�static������������е��κεط�,���п����ж��static�顣������α����ص�ʱ��,�ᰴ��static���˳����ִ��ÿ��static��,����ֻ��ִ��һ�Ρ�
��ʼ����˳�� ��̬����� > �������� > ���캯��
Ϊʲô˵static����������Ż���������,����Ϊ��������:ֻ��������ص�ʱ��ִ��һ�Ρ�
���濴������:
class Person{
private Date birthDate;
public Person(Date birthDate) {
this.birthDate = birthDate;
}
boolean isBornBoomer() {
Date startDate = Date.valueOf("1946");
Date endDate = Date.valueOf("1964");
return birthDate.compareTo(startDate)>=0 && birthDate.compareTo(endDate) < 0;
}
}
isBornBoomer������������Ƿ���1946-1964�������,��ÿ��isBornBoomer�����õ�ʱ��,��������startDate��birthDate��������,����˿ռ��˷�,����ij�����Ч�ʻ����,��ʵ���������˾�̬��������ڴ���ֵ����һ�εĻ���:
class Person{
private Date birthDate;
private static Date startDate,endDate;
static{
startDate = Date.valueOf("1946");
endDate = Date.valueOf("1964");
}
public Person(Date birthDate) {
this.birthDate = birthDate;
}
boolean isBornBoomer() {
return birthDate.compareTo(startDate)>=0 && birthDate.compareTo(endDate) < 0;
}
}
���,�ܶ�ʱ��ὫһЩֻ��Ҫ����һ�εij�ʼ������������static������н��С�
4.��̬�ڲ���
��̸�۾�̬�ڲ�֮ǰ,������̸̸,Ϊ��Ҫ���ڲ���?
������һ�����ڲ�������ڲ���,�����ڲ�������Ϊ�ⲿ�ࡣ�ڲ����������public��protected��private�ȷ�������,��������Ϊabstract�Ĺ������ڲ�����ⲿ��̳�����չ,��������Ϊstatic��final��,Ҳ����ʵ���ض��Ľӿڡ��ڲ����������ص�:
1.�ڲ���һ��ֻΪ���ⲿ��ʹ�á�����:hashmap������,�ڲ���Entry<K,V>��
2.�ڲ����ṩ��ij�ֽ����ⲿ��Ĵ���,�ڲ�������ⲿ�������,�����ڲ������ֱ�ӷ����ⲿ�������
3.ÿ���ڲ���ܶ����ؼ̳�һ���ӿ�,�������ⲿ���Ƿ��Ѿ��̳���ij���ӿڡ����,�ڲ���ʹ���ؼ̳еĽ��������ø���������
��̬�ڲ���
���徲̬�ڲ���:�ڶ����ڲ����ʱ��,��������ǰ�����һ��Ȩ�����η�static����ʱ����ڲ���ͱ�Ϊ�˾�̬�ڲ��ࡣͨ����ΪǶ����,���ڲ�����staticʱ,��ζ��:
- Ҫ����Ƕ����Ķ���,������Ҫ����Χ��Ķ���;
- ���ܴ�Ƕ����Ķ����з��ʷǾ�̬����Χ�����(���ܹ��Ӿ�̬�ڲ���Ķ����з����ⲿ��ķǾ�̬��Ա);
Ƕ��������ͨ���ڲ����һ������:��ͨ�ڲ�����ֶ��뷽��,ֻ�ܷ�������ⲿ�����,������ͨ���ڲ������static���ݺ�static�ֶ�, Ҳ���ܰ���Ƕ���ࡣ������Ƕ�����������������Щ������Ҳ����˵,�ڷǾ�̬�ڲ����в�����������̬��Ա,ֻ�н�ij���ڲ�������Ϊ��̬��,Ȼ����ܹ����� �����ж��徲̬�ij�Ա�������Ա������
����,�ڴ�����̬�ڲ���ʱ����Ҫ����̬�ڲ����ʵ�������ⲿ���ʵ���ϡ���ͨ�Ǿ�̬�ڲ���� �������������ⲿ�����֮�е�,Ҫ��һ���ⲿ���ж���һ����̬���ڲ���,����Ҫ���ùؼ���new�������ڲ����ʵ������̬��ͷ���ֻ�����౾��,�������� ����Ķ���,�������������ⲿ��Ķ���
����:�ڲ����ʶ��
ÿ��������һ��.class�ļ�,�ļ�����Ϊ������ͬ��,�ڲ���Ҳ�������ôһ��.class�ļ�,������������ȴ�����ڲ��������,���������ϸ������:��Χ�������,����$,�ټ����ڲ������֡�
5.��̬����
��̬��������java���ľ�̬����,��import static����import��̬�������JDK1.5�е������ԡ�
һ�����ǵ���һ����� import com����ClassName;
����̬����������:import static com����ClassName.* ;
����Ķ��˸�static,���о�������ClassName������˸�.* ,��˼�ǵ����������ľ�̬������
��Ȼ,Ҳ����ֻ����ij����̬����,ֻҪ�� .* ���ɾ�̬�����������ˡ�
Ȼ�����������,�Ϳ���ֱ���÷��������þ�̬����,��������ClassName.�������ķ�ʽ�����á�
�ô�:���ַ����ĺô����ǿ��Լ�һЩ����,�����ӡ����System.out.println(��);
�Ϳ��Խ���д��һ����̬����print(��),��ʹ��ʱֱ��print(��)�Ϳ����ˡ�
�������ַ����������кܶ��ظ����õ�ʱ��ʹ��,�������һ�����ε���,����ֱ��д���ķ���
�ھ�̬����֮ǰ:
public class TestStatic {
public static void main(String[] args) {
System.out.println(Integer.MAX_VALUE);
System.out.println(Integer.toHexString(42));
}
}
�ھ�̬����֮��:
import static java.lang.System.out;
import static java.lang.Integer.*;
public class TestStaticImport {
public static void main(String[] args) {
out.println(MAX_VALUE);
out.println(toHexString(42));
}
}
�����ǿ�һ��ʹ�þ�̬�������ԵĴ����н�����ʲô:
- ��Ȼ������ͨ����Ϊ����̬���롱,���������import static,��������뵼���static��Ա����ȫ������,����ͨ������ڱ�����,������System���out�����Ͻ��о�̬���롣
- �ڱ�����,���ǿ�����ʹ��java.lang.Integer��ļ���static��Ա���þ�̬�������ʹ��ͨ�������������ڴ����е����о�̬��Ա�Ͻ��о�̬���롱��
- �����������ڿ�����̬�������Եĺô�!���Dz�����System.out.println�м���System��̫����!����,���Dz�����Integer.MAX_VALUE�м���Integer�����,�����д�����,�����ܹ�����ݷ�ʽ���ھ�̬������һ��������
- ���,���ǽ��и���Ŀ�ݲ���,������Integer��ķ�����
������ʹ�þ�̬����ļ���ԭ��:
�����˵import static, ����˵static import��
����������������static��Ա������,������Integer���Long��ִ���˾�̬����,����MAX_VALUE������һ������������,��ΪInteger��Long����һ��MAX_VALUE����,����Java����֪�����������ĸ�MAX_VALUE��
�������static�������á�����(��ס,������static ��final)��static�����Ͻ��о�̬���롣
11.ʲô�Ƿ���?̸̸��Է���������
1.����
������ʵ�Ǿ���һ�����ܵĴ����,���ǿ�����Ҫ���ʹ�õĹ�����ȡ��һ������,�������ʹ�õ�ʱ��Ҳ����Ҫ����Щ�ظ��Ĵ���д�����ɴ�������ࡣ
2.��ʽ
��������ĸ�ʽ:���η� ����ֵ���� ������(�����б�){������}
����ǩ��:������(�����б�)
3.ע������
ע��:��������˵���Ƿ���ֵ���Ͷ����Ƿ���ֵ,���һ�������з���ֵ,��ô����ֵ���ͱ�������Ϊ�뷵��ֵ��ͬ������,���ҷ���ֵ��Ҫʹ��return�ؼ��������ء�
4.����������:
��ͬһ�����г��ַ�������ͬ�������б���ͬ����������
ע��:����֮���ܷ�����,ȡ���ڷ����IJ�������������,�뷽���IJ�������
���ǿ���ͨ��������+�����б��ķ�ʽȷ��Ҫ���õ����ĸ�����
�����Ĵ�ֵ:�������ʹ��ݵ���ʵ��ֵ,�������ʹ��ݵ��ǵ�ַ
���ҷ����IJ��������β�,ֻ�Ǹ�ʽ����Ҫ����,���ǵ��÷���ʱ�����Ƶ�����
�β�:���巽����ʱ��IJ����б�
ʵ��:ʹ�÷�����ʱ���������
���ص�����:
��Ϊ�˷������Է������е���,ʲô���IJ����������ҵ���Ӧ�ķ�����ִ��,���ֵ��dz���������
5.��������д:
����̳и����Ժ�,�������Ը���Ĺ��ܲ�����,������д����ķ���
������д��ʱ����Ҫע�����µĹ���:��ͬ��Сһ��
һ��:����������η���Χ >= ����������η���Χ�Cָ���Ƿ��ʿ��Ʒ�
��ͬ:��������ͬ,�����б���ͬ
��С: ������ķ���ֵ���� <= ������ķ���ֵ���͡������С�Ǽ̳й�ϵ,����ֵ�Ĵ�С��
������׳����쳣���� <= ������׳����쳣���͡������ûѧ,���ùܡ�
ע��:���������ķ���ֵ������void,���ౣ��һ�¼���
ע��:���������д�����˽�з���,������Ϊ���ɼ�
��д������:���ڲ���Դ���ǰ����,���й��ܵ��ĺ���չ
(OCPԭ��:�����Ĺر�,������չ����)
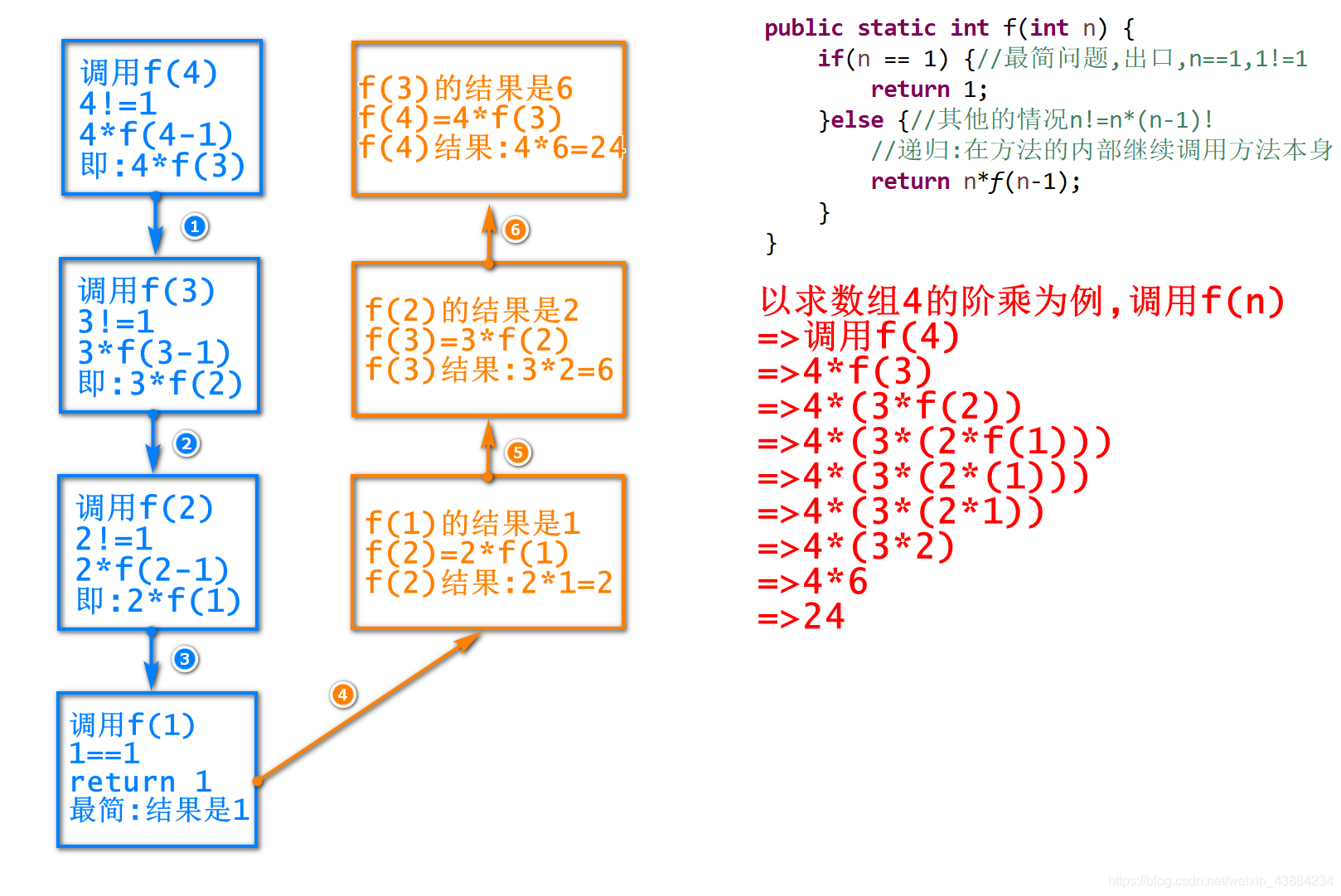
6.�����ĵݹ�:
�ݹ�:�ڷ����е����Լ�����
ע��ݹ��������ʱ,�����ջ����쳣
��ϰ�� : �����ֽ׳�(�ݹ�ⷨ��)
����:�����û����������,��������ֵĽ׳˽��
��֪:�����������н׳�,0�Ľ׳˽����1,
5 ! = 5 x 4 x 3 x 2 x 1
package cn.cxy.design;
//����:���û��������ֵĽ׳˽��
//f(int n)--������׳�
//����:
//f(n)= n*f(n-1)
//f(5)= 5*4*3*2*1 = 5*f(4)
//f(4)= 4*3*2*1 = 4*f(3)
//f(3)= 3*2*1 = 3*f(2)
//f(2)= 2*1 = 2*f(1)
//f(1)= 1
//
//5!=5*4*3*2*1=120
//4!=4*3*2*1
//3!=3*2*1
//2!=2*1
//1!=1
public class TestRecursion {
public static void main(String[] args) {
int result = f(15);//����f()������׳�
System.out.println(result);
}
/**�ݹ����Ҫ�� 1.�ܽ���� 2.�������*/
public static int f(int n) {
if(n == 1) {//�������
return 1;
}else {//������� n*f(n-1)
//�ݹ�:�ٷ����ڲ��Լ������Լ�
return n*f(n-1);
}
}
}
��ϰ�� : �ݹ���Ŀ¼�ܴ�С
����:�ݹ���Ŀ¼���ܴ�С D:\ready,�����������:
1.�г��ļ����е�������Դ�ClistFiles()�C>File[]
2.�ж�,��ǰ��Դ���ļ������ļ��ШC�ļ��д�СΪ0,�ļ���С��Ҫ�ۼ�
�C���ļ�,���ļ����ֽ�����Сlength(),�ۼӾ���
�C���ļ���,�����г��ļ����µ�������Դ�ClistFiles()�C>File[]
�C�ж�,���ļ�,���ļ����ֽ�����Сlength(),�ۼӾ���
�C�ж�,���ļ���,��һ���г��ļ����µ�������Դ
�C���ظ�����
Ҳ����˵,���ɾ���:ֻҪ���ļ���,����Ҫ�ظ�����1 2
package cn.cxy.file;
import java.io.File;
/**���������ݹ���Ŀ¼�ܴ�С*/
public class FileSumRecursion {
public static void main(String[] args) {
//1.ָ��Ҫ���ĸ�Ŀ¼���ܴ�С
/**ע��:�˴�ָ����Ŀ¼��������ʵ���ڵ�
* �����һ�������ڵ��ļ��лᱨ��,����Ǵ���һ�����ļ���,��СΪ0*/
File file = new File("D:\\ready");
//2.����size()��Ŀ¼��С
long total = size(file);
//3.���ս������ӡ
System.out.println("�ļ��е��ܴ�СΪ:"+total);
}
private static long size(File file) {
//1.�г��ļ����е�������Դ--listFiles()-->File[]
File[] fs = file.listFiles();
//2.��������,��ȡÿfile����
//2.1�������,��¼�ܺ�
long sum = 0;
for(int i = 0;i < fs.length ; i++) {
//2.2ͨ���±������ǰ����������Դ
File f = fs[i];
//2.3�ж�,��ǰ��Դ���ļ������ļ���--�ļ��д�СΪ0,�ļ���С��Ҫ�ۼ�
if(f.isFile()) {
//--���ļ�,���ļ����ֽ�����Сlength(),�ۼӾ���
sum += f.length();//�൱��:sum = sum + f.length();
}else if(f.isDirectory()) {
//--���ļ���,�����г��ļ����µ�������Դ,1 2����--listFiles()-->File[]
/**�����ĵݹ�,�ݹ�����,�����ڷ������ڲ����÷�������*/
sum += size(f);
}
}
return sum;//��sum��¼��ֵ���ص���λ��
}
}
��ϰ�� : �ݹ�ɾ���ļ���
����:�ݹ�ɾ���ļ��� D:\ready\a
1.�г��ļ����µ�������ԴlistFiles()
2.�ж�,��ǰ��Դ���ļ������ļ���
�C�ж�,���ļ�,ֱ��ɾ��delete()
�C�ж�,���ļ���,�����ظ�����1 2
����˼·���Է�Ϊ��ô����:
1.����,������Ҫָ��һ����Ŀ¼��ΪҪɾ���Ķ���
2.�г��ļ����µ�������ԴlistFiles(),�����б���
3.�жϵ�ǰ����Դ,������ļ�,ֱ��ɾ��;������ļ���,��ִ�в���2
4.���ļ����е�����ɾ����Ϻ�,ɾ���ļ��б���
package cn.tedu.file;
import java.io.File;
/**�������ڵݹ�ɾ��Ŀ¼*/
public class TestFileDeleteRecursion {
public static void main(String[] args) {
//1.ָ��Ҫɾ����Ŀ¼
/**Ϊ�˸��õIJ���,ע��ָ����Ŀ¼���Ѵ��ڵ�Ŀ¼,����,ǧ��Ҫɾ�̷�!!!!*/
/*����Ҳ��һЩû��Ȩ���ļ���,�Ǹ����������Ҳ���ɾ����Ŷ*/
File file = new File("D:\\ready\\a");
//2.����ɾ��Ŀ¼�ķ���
boolean result = del(file);
//3.��ӡɾ���Ľ��
System.out.println("ɾ���Ľ��Ϊ:"+result);
}
public static boolean del(File file) {//��ɵ�ͬѧ���Ǻܶ�,ץ��ʱ��д,д���ͼ��Ⱥ���,����������Ǽ���
//1.�г��ļ����µ�������Դ
File[] fs = file.listFiles();
//2.ѭ�������õ���������Դ
for (int i = 0; i < fs.length; i++) {
//2.1��ȡ����ѭ����������file����
File f = fs[i];
//3.�ж�,��ǰ��Դ���ļ������ļ���
if(f.isFile()) {
f.delete();//���ļ�,ֱ��ɾ��
System.out.println(file.getName()+"�ļ�ɾ���ɹ�!");
}else if(f.isDirectory()) {
//���ļ���,��Ҫ�������в���1 2 ,�������ظ����õ����
//�ݹ�,�ڷ������ڲ������Լ�
del(f);
}
}
//λ��:��forѭ��ִ��֮��ɾ���ļ���
file.delete();//���ļ���ֱ��ɾ��
System.out.println(file.getName()+"�ļ���ɾ���ɹ�!");
return true;
}
}
12.�ڲ�������Щ����?������Щʹ�ó���?
-
������һ�����л��߷����е����Ϊ�ڲ��ࡣ
-
�ڲ�����Է�Ϊ��������:
-
��Ա�ڲ����������ǷǾ�̬�ġ�
��������ͨ���ڲ���,��������һ������ڲ���,����ͬһ������ij�Ա����һ����
��Ա�ڲ�������������ķ����ⲿ��ij�Ա���Ժͳ�Ա����(���� private �� static ���͵ij�Ա)
������Ϊ�ڳ�Ա�ڲ�����,��ʽ�س������ⲿ������á�
ʹ�ó���:���� A ��Ҫʹ���� B ,ͬʱ B ��Ҫ���� A �ij�Ա/����ʱ,���Խ� B ��Ϊ A �ij�Ա�ڲ��ࡣͬʱ���ǿ������� private �ڲ����ֹ��������ʸ��ڲ���,�Ӷ������������ʵ��ϸ����ȫ���ء� -
��̬�ڲ����������dz�Ա�ڲ��౻��̬���Ρ�
����ʹ�� static �ؼ������ε��ڲ���,��̬�ڲ�������ⲿ�������,���Կ����Ǻ��ⲿ��ƽ�����ࡣ
�������ھ�̬�ڲ����з����ⲿ��ij�Աֻ�� new һ���ⲿ��Ķ���,����ֻ�ܷ����ⲿ��ľ�̬���Ժ;�̬������
ʹ�ó���:���� A ��Ҫʹ���� B,�� B ����Ҫֱ�ӷ����ⲿ�� A �ij�Ա�����ͷ���ʱ,���Խ� B ��Ϊ A �ľ�̬�ڲ��ࡣ -
�ֲ��ڲ���
�����ڴ������߷����д������ࡣ
�ֲ��ڲ����������ֻ���������ڵĴ������߷�����,�������ط�����������Ķ���
���ǿ��Ѿֲ��ڲ�������Ϊ�������С�ij�Ա�ڲ��ࡣ
ʹ�ó���:�ֲ��ڲ���ֻ���ڵ�ǰ�������ߴ�����д�����ʹ��,����һ���Բ�Ʒ,ʹ�ó����Ƚ��١� -
�����ڲ���
����һ��û�����ֵ��ڲ���,ͨ������������һ��ʹ��,ʵ���˴���ʵ����+ʵ�ַ���+���������÷����Ĺ���
����һ�������ڲ�����ص�:
1.����̳�һ�������ʵ��һ���ӿ�,������Ҫ���Ӷ���ķ���,ֻ�ǶԼ̳з�����ʵ�ֻ��Ǹ��ǡ�
2.ֻ��Ϊ�˻��һ������ʵ��,������Ҫ֪����ʵ�ʵ����͡�
3.�����ڲ��������ָ����û������,������û������ָ������
4.�����ڲ�����й��췽��,ֻ���г�ʼ������顣��Ϊ�����������������һ�����췽��Ȼ����á�
5.�����ڲ�����ʹ�õ��IJ�������Ҫ����Ϊ final ��,����������ᱨ����
ʹ�ó���:��������Ҫʵ��һ���ӿ�,������Ҫ������������,����Ҫʹ��һ������ijһ����Դʱʹ��
��ôΪʲô�����ڲ�����ʹ�ò�����Ҫ����Ϊfinal��?
��Ϊ�����ڲ����Ǵ���һ��������,�������ķ��������õ�ʱ����ȷ��,���������IJ����Ŀ���,����������ڲ��������˲���,�ⲿ���еIJ����Ƿ���Ҫͬ������?Java Ϊ�˱�����������,���������ڲ�����ʵı�����Ҫʹ�� final ����,�������Ա�֤���ʵı������ɱ䡣
����,���˾�̬�ڲ���,ʣ�µij�Ա�ڲ��ࡢ�ֲ��ڲ��ࡢ�����ڲ��� ����Ĭ����ʽ�س����ⲿ������á� -