JAVA����֮����
ǰ��
??ǰ���ѧϰ��������ѧ��������,����֪��������ij����ǹ̶���,�������Զ�����,������ǰ��Ҳ�нӴ������ϵĸ���,�Լ�һЩ���ϵ�Ӧ��,��Ȼ����֪�����ϵij����ǿɱ��,���ǿ�������Ԫ�ص����Ӷ�������,���������ǽ����о��彲��ͷ���һ�¼��ϵ����֪ʶ��,��������ṩ�˾���İ����C������,��ӭ��Ҳο�����!

���Ͽ��
??��ѧϰ����ǰ,�����������˽�һ�¼��ϵĿ��ͼ:
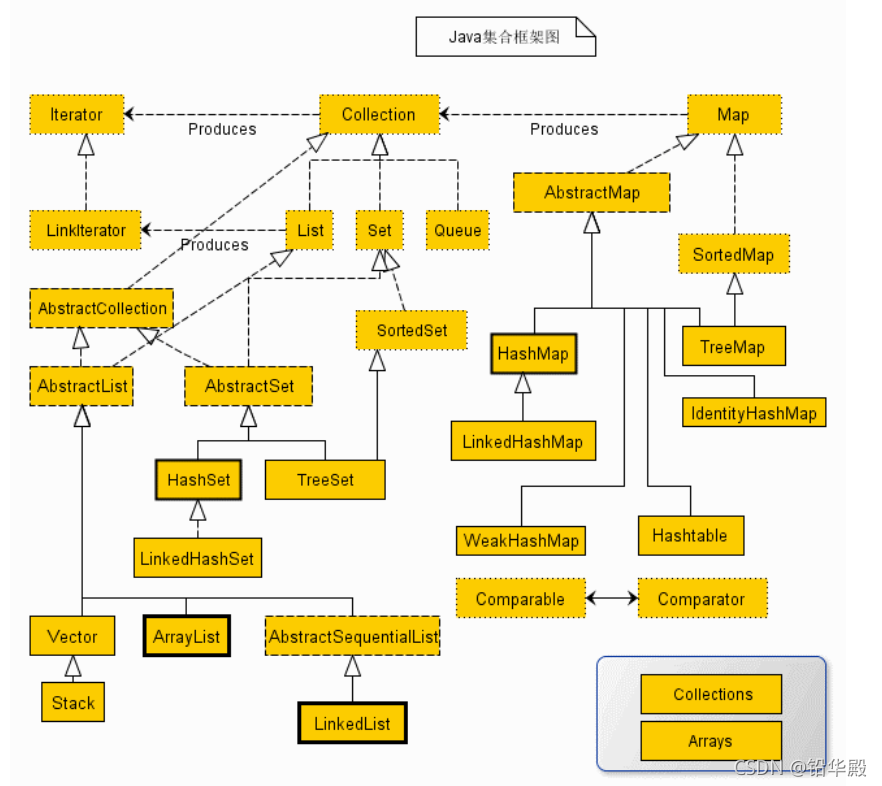
??������ļ��Ͽ��ͼ���Կ���,Java ���Ͽ����Ҫ�����������͵�����,һ���Ǽ���(Collection),�洢һ��Ԫ�ؼ���,��һ����ͼ(Map),�洢��/ֵ��ӳ�䡣Collection �ӿ����� 3 ��������,List��Set �� Queue,��������һЩ������,����Ǿ���ʵ����,���õ��� ArrayList��LinkedList��HashSet��LinkedHashSet��HashMap��LinkedHashMap �ȵȡ�
??���Ͽ����һ�����������Ͳ��ݼ��ϵ�ͳһ�ܹ������еļ��Ͽ�ܶ�������������:
??�ӿ�:�Ǵ������ϵij����������͡����� Collection��List��Set��Map �ȡ�֮���Զ������ӿ�,��Ϊ���Բ�ͬ�ķ�ʽ�������϶���
??ʵ��(��):�Ǽ��Ͻӿڵľ���ʵ�֡��ӱ����Ͻ�,�����ǿ��ظ�ʹ�õ����ݽṹ,����:ArrayList��LinkedList��HashSet��HashMap��
??�㷨:��ʵ�ּ��ϽӿڵĶ�����ķ���ִ�е�һЩ���õļ���,����:������������Щ�㷨����Ϊ��̬,������Ϊ��ͬ�ķ������������ƵĽӿ������Ų�ͬ��ʵ�֡�
??���˼���,�ÿ��Ҳ�����˼��� Map �ӿں��ࡣMap ��洢���Ǽ�/ֵ�ԡ����� Map ���Ǽ���,����������ȫ�����ڼ����С�
���Ͽ����ϵ��ͼ��ʾ
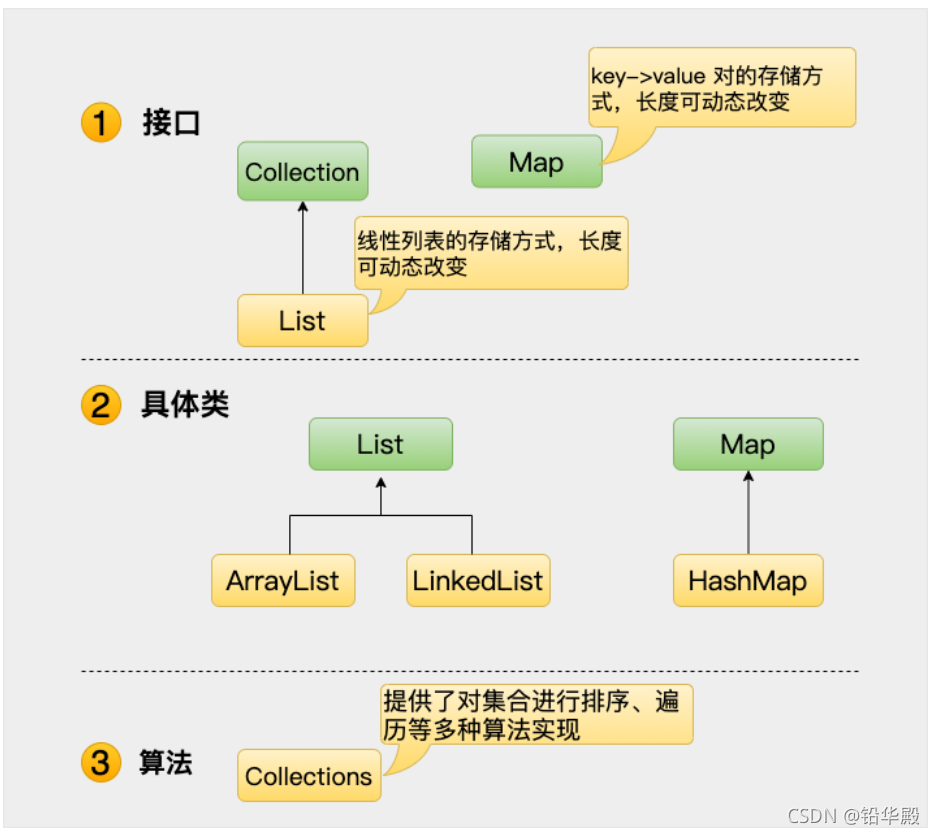
Collection����
??ͨ�������ͼ���ǿ����˽,�����е��кͶ���,���������˽ⵥ�м���Collection����
Collection���ϸ���
- �ǵ������ϵĶ���ӿ�,����ʾһ�����,��Щ����Ҳ��ΪCollection��Ԫ��
- JDK ���ṩ�˽ӿڵ��κ�ֱ��ʵ��,���ṩ��������ӽӿ�(��Set��List)ʵ��
Collection���ϵĻ���ʹ��:
public class CollectionDemo01 {
public static void main(String[] args) {
//����Collection���ϵĶ���
Collection<String> c = new ArrayList<String>();
//����Ԫ��:boolean add(E e)
c.add("hello");
c.add("world");
c.add("java");
//������϶���
System.out.println(c);
}
}
Collection���ϵij��÷���:
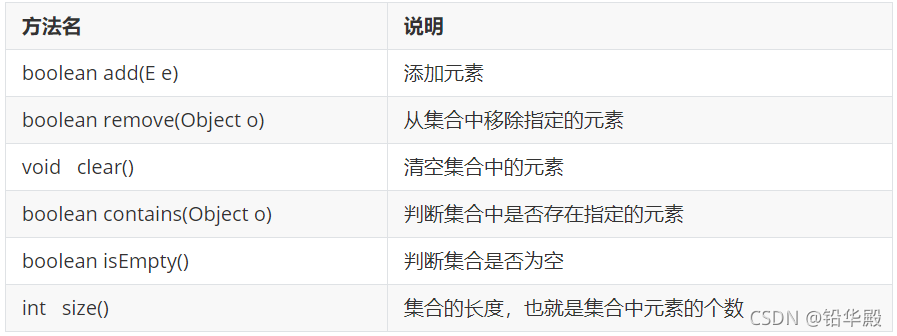
Collection���ϵı���:
����Collection���ϵı���,��������Ҫ����һ�ֵ������ķ�ʽ:
- ������,���ϵ�ר�ñ�����ʽ
- Iterator iterator():���ش˼�����Ԫ�صĵ�����,ͨ�����ϵ�iterator()�����õ�
- ��������ͨ�����ϵ�iterator()�����õ���,��������˵���������ڼ��϶����ڵ�
public class IteratorDemo {
public static void main(String[] args) {
//�������϶���
Collection<String> c = new ArrayList<>();
//����Ԫ��
c.add("hello");
c.add("world");
c.add("java");
c.add("javaee");
//Iterator<E> iterator():���ش˼�����Ԫ�صĵ�����,ͨ�����ϵ�iterator()�����õ�
Iterator<String> it = c.iterator();
//��whileѭ���Ľ�Ԫ�ص��жϺͻ�ȡ
while (it.hasNext()) {
String s = it.next();
System.out.println(s);
}
}
}
??��ǿforѭ������
| for(Ԫ���������� ������ : ����/���϶�����) { ѭ����;} |
List
List���ϵĸ������ص�
- List���ϸ���
- ����(Ҳ��Ϊ����),�û����Ծ�ȷ�����б���ÿ��Ԫ�صIJ���λ�á��û�����ͨ��������������Ԫ��,�������б��е�Ԫ��
- ��Set���ϲ�ͬ,�б�ͨ�������ظ���Ԫ��
- List�����ص�
- ������
- ���Դ洢�ظ�Ԫ��
- Ԫ�ش�ȡ����
List���ϵ����з���
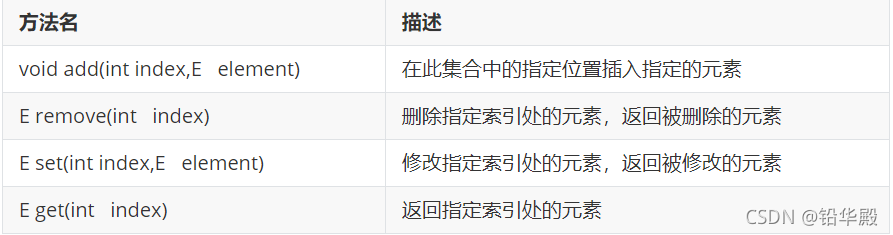
ArrayList��LinkedList
List����������ص�
-
ArrayList����
? �ײ�������ṹʵ��,��ѯ�졢��ɾ�� -
LinkedList����
? �ײ��������ṹʵ��,��ѯ������ɾ��
LinkedList���ϵ����й���:
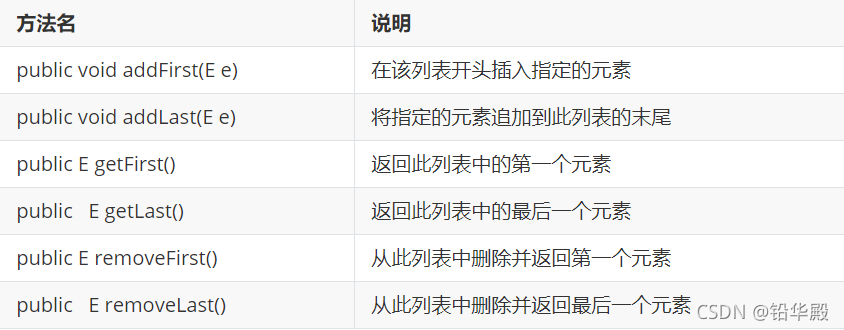
Set
Set���ϵĸ������ص�
- Set���ϵ��ص�
- Ԫ�ش�ȡ����
- û��������ֻ��ͨ������������ǿforѭ������
- ���ܴ洢�ظ�Ԫ��
- Set���ϵĻ���ʹ��
public class SetDemo {
public static void main(String[] args) {
//�������϶���
Set<String> set = new HashSet<String>();
//����Ԫ��
set.add("hello");
set.add("world");
set.add("java");
//�������ظ�Ԫ�صļ���
set.add("world");
//����
for(String s : set) {
System.out.println(s);
}
}
}
HashSet
��ϣֵ���
��ϣֵ��JDK���ݶ���ĵ�ַ�����ַ������������������int���͵���ֵ
- ��λ�ȡ��ϣֵ
? Object���е�public int hashCode():���ض���Ĺ�ϣ��ֵ - ��ϣֵ���ص�
- ͬһ�������ε���hashCode()�������صĹ�ϣֵ����ͬ��
- Ĭ�������,��ͬ����Ĺ�ϣֵ�Dz�ͬ�ġ�����дhashCode()����,����ʵ���ò�ͬ����Ĺ�ϣֵ��ͬ
HashSet���ϸ������ص�
HashSet���ϵ��ص�
- �ײ����ݽṹ�ǹ�ϣ��
- �Լ��ϵĵ���˳�����κα�֤,Ҳ����˵����֤�洢��ȡ����Ԫ��˳��һ��
- û�д������ķ���,���Բ���ʹ����ͨforѭ������
- ������Set����,�����Dz������ظ�Ԫ�صļ���
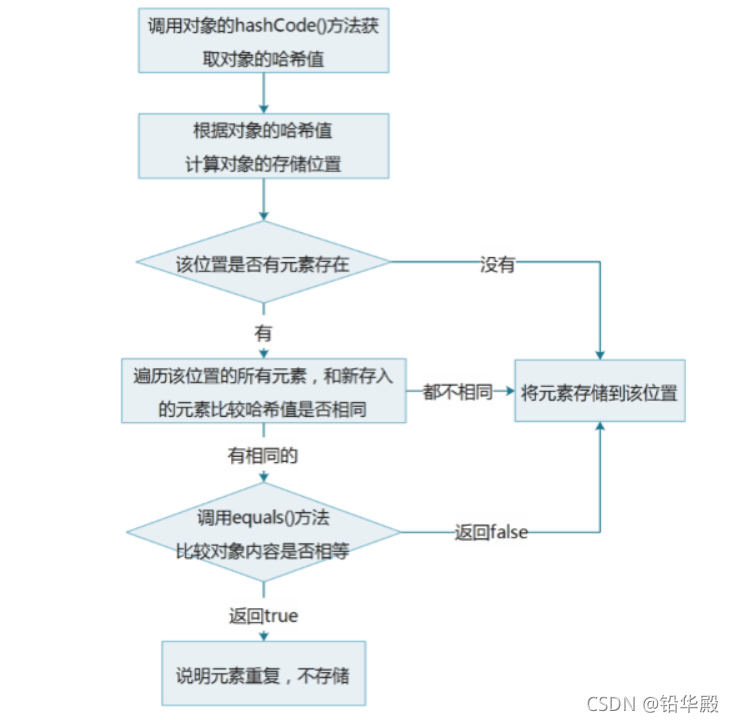
HashSet���ϱ�֤Ԫ��Ψһ��Դ�����
HashSet���ϱ�֤Ԫ��Ψһ�Ե�ԭ�� :
1.���ݶ���Ĺ�ϣֵ����洢λ��
????�����ǰλ��û��Ԫ����ֱ�Ӵ���
????�����ǰλ����Ԫ�ش���,�����ڶ���
?2.��ǰԪ�ص�Ԫ�غ��Ѿ����ڵ�Ԫ�رȽϹ�ϣֵ
????�����ϣֵ��ͬ,��ǰԪ�ؽ��д洢
????�����ϣֵ��ͬ,����������
3.ͨ��equals()�����Ƚ�����Ԫ�ص�����
????������ݲ���ͬ,��ǰԪ�ؽ��д洢
????���������ͬ,�洢��ǰԪ��
HashSet���ϱ�֤Ԫ��Ψһ�Ե�ͼ��:
LinkedHashSet�����ص�
- ��ϣ��������ʵ�ֵ�Set�ӿ�,���п�Ԥ��ĵ�������
- ��������֤Ԫ������,Ҳ����˵Ԫ�صĴ洢��ȡ��˳����һ�µ�
- �ɹ�ϣ����֤Ԫ��Ψһ,Ҳ����˵û���ظ���Ԫ��
TreeSet
TreeSet���ϵĸ������ص�
TreeSet���ϸ���:
- Ԫ������,������һ���Ĺ����������,��������ʽȡ���ڹ��췽��
- TreeSet():������Ԫ�ص���Ȼ�����������
- TreeSet(Comparator comparator) :����ָ���ıȽ�����������
- û�д������ķ���,���Բ���ʹ����ͨforѭ������
- ������Set����,���Բ������ظ�Ԫ�صļ���
��Ȼ����Comparable��ʹ��
- ��������
- �洢ѧ��������,����TreeSet����ʹ���ι��췽��
- Ҫ��:���������С��������,������ͬʱ,������������ĸ˳������
- ʵ�ֲ���
- ��TreeSet���ϴ洢�Զ������,�ι��췽��ʹ�õ�����Ȼ�����Ԫ�ؽ��������
- ��Ȼ����,������Ԫ����������ʵ��Comparable�ӿ�,��дcompareTo(T o)����
- ��д����ʱ,һ��Ҫע�����������밴��Ҫ�����Ҫ�����ʹ�Ҫ������д
ѧ����
public class Student implements Comparable<Student> {
private String name;
private int age;
public Student() {
}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public int compareTo(Student s) {
// return 0;
// return 1;
// return -1;
//�����������������
int num = this.age - s.age;
// int num = s.age - this.age;
//������ͬʱ,������������ĸ˳������
int num2 = num==0?this.name.compareTo(s.name):num;
return num2;
}
}
������
public class TreeSetDemo02 {
public static void main(String[] args) {
//�������϶���
TreeSet<Student> ts = new TreeSet<Student>();
//����ѧ������
Student s1 = new Student("xishi", 29);
Student s2 = new Student("wangzhaojun", 28);
Student s3 = new Student("diaochan", 30);
Student s4 = new Student("yangyuhuan", 33);
Student s5 = new Student("linqingxia",33);
Student s6 = new Student("linqingxia",33);
//��ѧ�����ӵ�����
ts.add(s1);
ts.add(s2);
ts.add(s3);
ts.add(s4);
ts.add(s5);
ts.add(s6);
//��������
for (Student s : ts) {
System.out.println(s.getName() + "," + s.getAge());
}
}
}
�Ƚ�������Comparator��ʹ��
- ��������
- �洢ѧ��������,����TreeSet����ʹ�ô��ι��췽��
- Ҫ��:���������С��������,������ͬʱ,������������ĸ˳������
- ʵ�ֲ���
- ��TreeSet���ϴ洢�Զ������,���ι��췽��ʹ�õ��DZȽ��������Ԫ�ؽ��������
- �Ƚ�������,�����ü��Ϲ��췽������Comparator��ʵ�������,��дcompare(T o1,T o2)����
- ��д����ʱ,һ��Ҫע�����������밴��Ҫ�����Ҫ�����ʹ�Ҫ������д
������
public class TreeSetDemo {
public static void main(String[] args) {
//�������϶���
TreeSet<Student> ts = new TreeSet<Student>(new Comparator<Student>() {
@Override
public int compare(Student s1, Student s2) {
//this.age - s.age
//s1,s2
int num = s1.getAge() - s2.getAge();
int num2 = num == 0 ? s1.getName().compareTo(s2.getName()) : num;
return num2;
}
});
//����ѧ������
Student s1 = new Student("xishi", 29);
Student s2 = new Student("wangzhaojun", 28);
Student s3 = new Student("diaochan", 30);
Student s4 = new Student("yangyuhuan", 33);
Student s5 = new Student("linqingxia",33);
Student s6 = new Student("linqingxia",33);
//��ѧ�����ӵ�����
ts.add(s1);
ts.add(s2);
ts.add(s3);
ts.add(s4);
ts.add(s5);
ts.add(s6);
//��������
for (Student s : ts) {
System.out.println(s.getName() + "," + s.getAge());
}
}
}
Queue
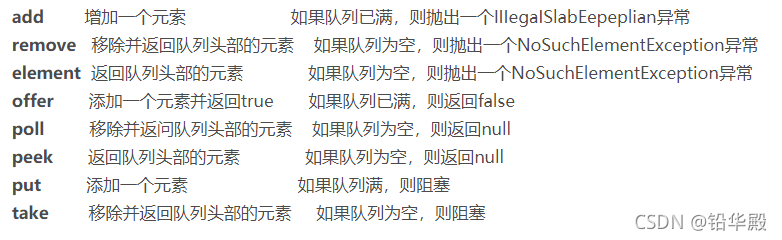
??Queue: ������,һ�����о���һ�������ȳ�(FIFO)�����ݽṹ
Queue�ӿ���List��Setͬһ����,���Ǽ̳���Collection�ӿڡ�LinkedListʵ����Queue�ӿڡ�
??��������:
Map����
Map���ϵĸ������ص�
-
Map���ϸ���
interface Map<K,V> K:��������;V:ֵ������ -
Map���ϵ��ص�
- ��ֵ��ӳ���ϵ
- һ������Ӧһ��ֵ
- �������ظ�,ֵ�����ظ�
- Ԫ�ش�ȡ����
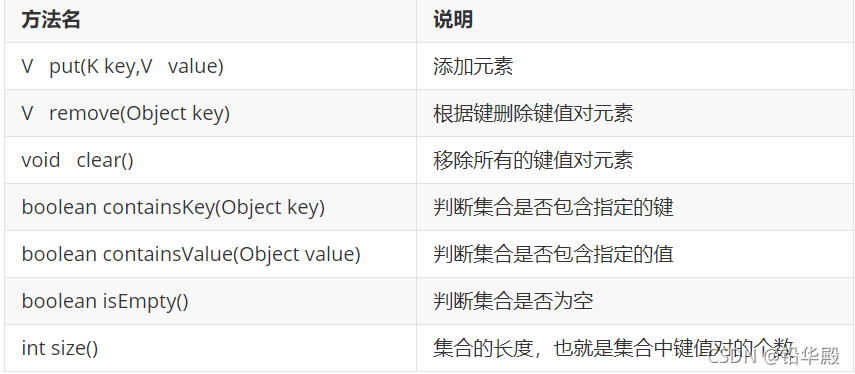
Map���ϵĻ�������
??��������:
??��ȡ����:
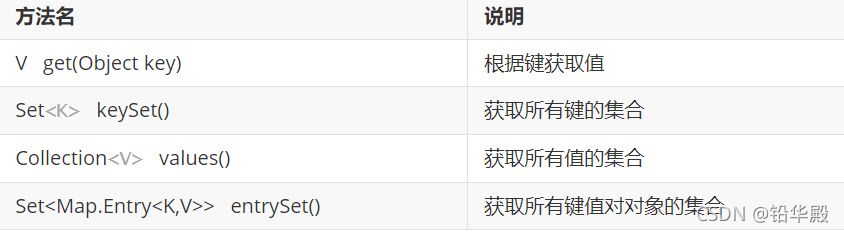
Map���ϵı�����ʽ
��ʽһ
- ����˼·
- ���ǸղŴ洢��Ԫ�ض��dzɶԳ��ֵ�,�������ǰ�Map������һ�����Եļ���
- �����е��ɷ����������
- �����ɷ�ļ���,��ȡ��ÿһ���ɷ�
- �����ɷ�ȥ�Ҷ�Ӧ������
- ���ǸղŴ洢��Ԫ�ض��dzɶԳ��ֵ�,�������ǰ�Map������һ�����Եļ���
- �������
- ��ȡ���м��ļ��ϡ���keySet()����ʵ��
- �������ļ���,��ȡ��ÿһ����������ǿforʵ��
- ���ݼ�ȥ��ֵ����get(Object key)����ʵ��
public class MapDemo01 {
public static void main(String[] args) {
//�������϶���
Map<String, String> map = new HashMap<String, String>();
//����Ԫ��
map.put("����", "����");
map.put("����", "����");
map.put("���", "С��Ů");
//��ȡ���м��ļ��ϡ���keySet()����ʵ��
Set<String> keySet = map.keySet();
//�������ļ���,��ȡ��ÿһ����������ǿforʵ��
for (String key : keySet) {
//���ݼ�ȥ��ֵ����get(Object key)����ʵ��
String value = map.get(key);
System.out.println(key + "," + value);
}
}
}
��ʽ��
- ����˼·
- ���ǸղŴ洢��Ԫ�ض��dzɶԳ��ֵ�,�������ǰ�Map������һ�����Եļ���
- ��ȡ���н��֤�ļ���
- �������֤�ļ���,�õ�ÿһ�����֤
- ���ݽ��֤��ȡ�ɷ������
- ���ǸղŴ洢��Ԫ�ض��dzɶԳ��ֵ�,�������ǰ�Map������һ�����Եļ���
- �������
- ��ȡ���м�ֵ�Զ���ļ���
- Set<Map.Entry<K,V>> entrySet():��ȡ���м�ֵ�Զ���ļ���
- ������ֵ�Զ���ļ���,�õ�ÿһ����ֵ�Զ���
- ����ǿforʵ��,�õ�ÿһ��Map.Entry
- ���ݼ�ֵ�Զ����ȡ����ֵ
- ��getKey()�õ���
- ��getValue()�õ�ֵ
- ��ȡ���м�ֵ�Զ���ļ���
public class MapDemo02 {
public static void main(String[] args) {
//�������϶���
Map<String, String> map = new HashMap<String, String>();
//����Ԫ��
map.put("����", "����");
map.put("����", "����");
map.put("���", "С��Ů");
//��ȡ���м�ֵ�Զ���ļ���
Set<Map.Entry<String, String>> entrySet = map.entrySet();
//������ֵ�Զ���ļ���,�õ�ÿһ����ֵ�Զ���
for (Map.Entry<String, String> me : entrySet) {
//���ݼ�ֵ�Զ����ȡ����ֵ
String key = me.getKey();
String value = me.getValue();
System.out.println(key + "," + value);
}
}
}
HashMap
??HashMap��ʵ��ԭ��:HashMap��������һ��Entry���顣Entry��HashMap�Ļ�����ɵ�Ԫ,ÿһ��Entry����һ��key-value��ֵ�ԡ�(��ʵ��νMap��ʵ���DZ�������������֮���ӳ���ϵ��һ�ּ���)
??����дequals�ķ�����ʱ��,����ע����дhashCode����,ͬʱ��Ҫ��֤ͨ��equals�ж���ȵ���������,����hashCode����Ҫ����ͬ��������ֵ�������equals�жϲ���ȵ���������,��hashCode������ͬ(ֻ�����ᷢ����ϣ��ͻ,Ӧ��������)��
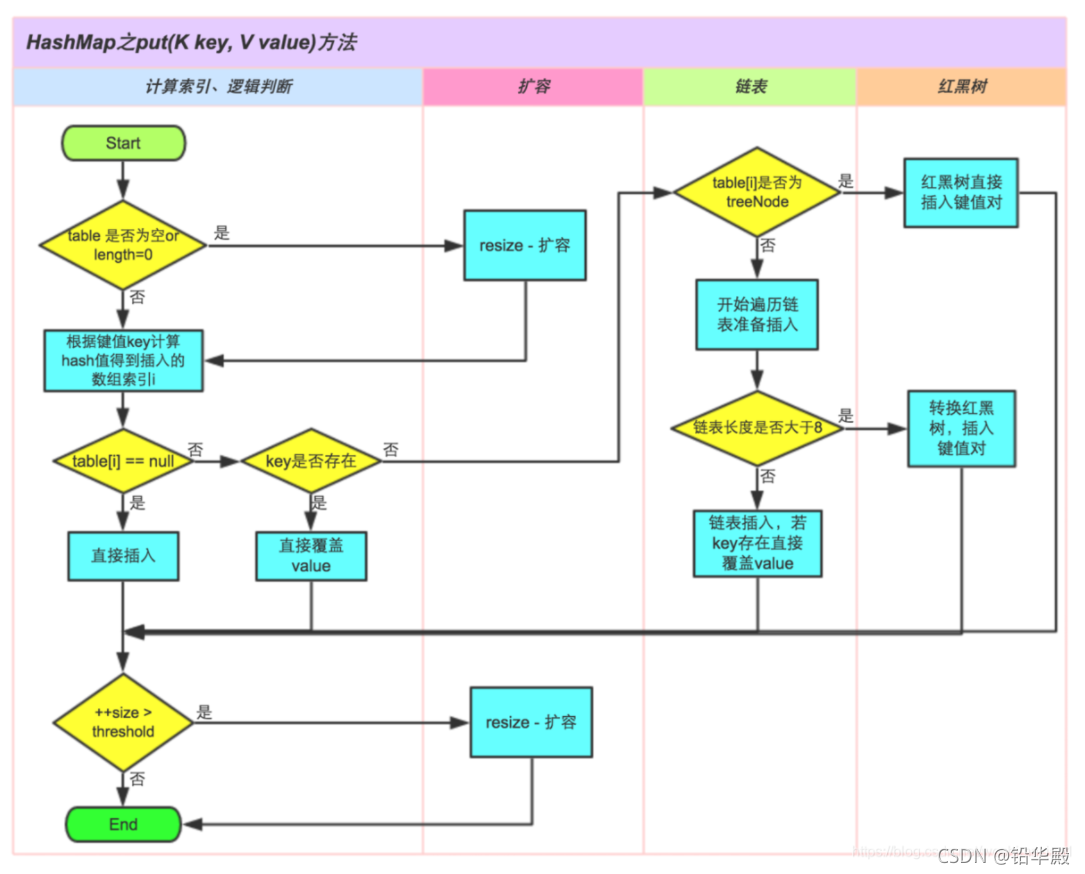
??�� HashMap put������ͼ(JDK1.8)
TreeMap
??��Map���Ͽ����,����HashMap����,TreeMapҲ�dz��õ��ļ��϶���֮һ��
??��HashMap���,TreeMap��һ���ܱȽ�Ԫ�ش�С��Map����,��Դ����key�����˴�С��������,����ʹ��Ԫ�ص���Ȼ˳��,Ҳ����ʹ�ü������Զ���ıȽ�������������;
??��ͬ��HashMap�Ĺ�ϣӳ��,TreeMapʵ���˺�����Ľṹ,�γ���һ�Ŷ�������
TreeMap����
(1)ʹ��Ԫ����Ȼ����
??��ʹ����Ȼ˳������ʱ��,��Ҫ�����������:һ����Jdk����Ķ���,һ�����Լ�����Ķ���;
(2)ʹ���Զ���Ƚ�������
??ʹ���Զ���Ƚ�������,��Ҫ�ڴ���TreeMap����ʱ,���Զ���Ƚ��������뵽TreeMap���췽����;
??�Զ���Ƚ�������,��Ҫʵ��Comparator�ӿ�,��ʵ�ֱȽϷ���compare(To1,To2);
??ʹ���Զ���Ƚ�������Ļ�,���ȽϵĶ���������ʵ��Comparable�ӿ���;
Java�����������������
���Ͽ�ܵײ����ݽṹ�ܽ�
- List
Arraylist:Object����
Vector: Object����
LinkedList: ˫������(JDK1.6֮ǰΪѭ������,JDK1.7ȡ����ѭ��) - Set
HashSet(����,Ψһ): ���� HashMap ʵ�ֵ�,�ײ���� HashMap ������Ԫ��
LinkedHashSet: LinkedHashSet �̳��� HashSet,�������ڲ���ͨ�� LinkedHashMap ��ʵ�ֵġ��е�����������֮ǰ˵��LinkedHashMap ���ڲ��ǻ��� Hashmap ʵ��һ��,����������һ�������ġ�
TreeSet(����,Ψһ): �����(��ƽ��������������) - Map
HashMap: JDK1.8֮ǰHashMap������+������ɵ�,������HashMap������,����������ҪΪ�˽����ϣ��ͻ�����ڵ�(���������������ͻ)��JDK1.8�Ժ��ڽ����ϣ��ͻʱ���˽ϴ�ı仯,���������ȴ�����ֵ(Ĭ��Ϊ8)ʱ,������ת��Ϊ�����,�Լ�������ʱ�䡣
LinkedHashMap: LinkedHashMap �̳��� HashMap,�������ĵײ���Ȼ�ǻ�������ʽɢ�нṹ���������������������ɡ�����,LinkedHashMap ������ṹ�Ļ�����,������һ��˫������,ʹ������Ľṹ���Ա��ּ�ֵ�ԵIJ���˳��ͬʱͨ��������������Ӧ�IJ���,ʵ���˷���˳���������
Hashtable: ����+������ɵ�,������ HashMap ������,����������ҪΪ�˽����ϣ��ͻ�����ڵ�
TreeMap: �����(��ƽ������������)
List��Set��Map�����ص�
1��List(�����ظ�)
??List���ŵĶ����������,ͬʱҲ�ǿ����ظ���,List��ע��������,ӵ��һϵ�к�������صķ���,��ѯ�ٶȿ졣��Ϊ��list����������ɾ������ʱ,������ź������ݵ��ƶ�,���в���ɾ�������ٶ�����
2��Set(�������ظ�)
??Set���ŵĶ���������,�����ظ���,�����еĶ����ض��ķ�ʽ����,ֻ�ǼذѶ�����뼯���С�
3��Map(��ֵ�ԡ���Ψһ��ֵ��Ψһ)
??Map�����д洢���Ǽ�ֵ��,�������ظ�,ֵ�����ظ������ݼ��õ�ֵ,��map���ϱ���ʱ�ȵõ�����set����,��set���Ͻ��б���,�õ���Ӧ��ֵ��
ArrayList��Vector�к���ͬ��?
ArrayList��Vector�ںܶ�ʱ������
(1)���߶��ǻ���������,�ڲ���һ������֧�֡�
(2)����ά�������˳��,���ǿ��Ը��ݲ���˳������ȡԪ�ء�
(3)ArrayList��Vector�ĵ�����ʵ�ֶ���fail-fast�ġ�
(4)ArrayList��Vector��������nullֵ,Ҳ����ʹ������ֵ��Ԫ�ؽ���������ʡ�
������ArrayList��Vector�IJ�ͬ��
(1)Vector��ͬ����,��ArrayList���ǡ�Ȼ��,�����Ѱ���ڵ�����ʱ����б����иı�,��Ӧ��ʹ��CopyOnWriteArrayList��
(2)ArrayList��Vector��,����Ϊ��ͬ��,������ء�
(3)ArrayList����ͨ��,��Ϊ���ǿ���ʹ��Collections���������ػ�ȡͬ���б���ֻ���б���
ArrayList��LinkedList�����?
ArrayList��LinkedList���߶�ʵ����List�ӿ�,��������֮����Щ��ͬ��
(1)ArrayList����Array��֧�ֵĻ���һ�����������ݽṹ,�������ṩ��Ԫ�ص��������,���Ӷ�ΪO(1),��LinkedList�洢һϵ�еĽڵ�����,ÿ���ڵ㶼��ǰһ������һ���ڵ������ӡ�����,������ʹ��������ȡԪ�صķ���,�ڲ�ʵ���Ǵ���ʼ�㿪ʼ����,�����������Ľڵ�Ȼ��Ԫ��,ʱ�临�Ӷ�ΪO(n),��ArrayListҪ����
(2)��ArrayList���,��LinkedList�в��롢���Ӻ�ɾ��һ��Ԫ�ػ����,��Ϊ��һ��Ԫ�ر����뵽�м��ʱ��,�����漰�ı�����Ĵ�С,�����������
(3)LinkedList��ArrayList���ĸ�����ڴ�,��ΪLinkedList�е�ÿ���ڵ�洢��ǰ��ڵ�����á�
HashMap��Hashtable��ʲô����?
???HashMap �� Hashtable ��ʵ���� Map �ӿ�,��˺ܶ����Էdz����ơ�����,���������²�ͬ��:
???HashMap ��������ֵ�� null,�� Hashtable ������������ֵ�� null��
???Hashtable ��ͬ����,�� HashMap ���ǡ����,HashMap ���ʺ��ڵ��̻߳���,�� Hashtable�ʺ��ڶ��̻߳�����
???HashMap �ṩ�˿ɹ�Ӧ�õ����ļ��ļ���,���,HashMap �ǿ���ʧ�ܵġ���һ����,Hashtable �ṩ�˶Լ����о�(Enumeration)��
һ����Ϊ Hashtable ��һ���������ࡣ
�ܽ�
???Java���Ͽ��Ϊ����Ա�ṩ��Ԥ�Ȱ�װ�����ݽṹ���㷨���������ǡ�
???������һ������,������������������á����Ͻӿ�������ÿһ�����͵ļ��Ͽ���ִ�еIJ�����
???���Ͽ�ܵ���ͽӿھ���java.util���С�
???�κζ�����뼯�����,�Զ�ת��ΪObject����,������ȡ����ʱ��,��Ҫ����ǿ������ת����
������Դ��
����:https://pan.baidu.com/s/1JuOyirPztuj9b78_ASDUQg
��ȡ��:yy52
������Դ��
