JVM往期文章
本文脑图
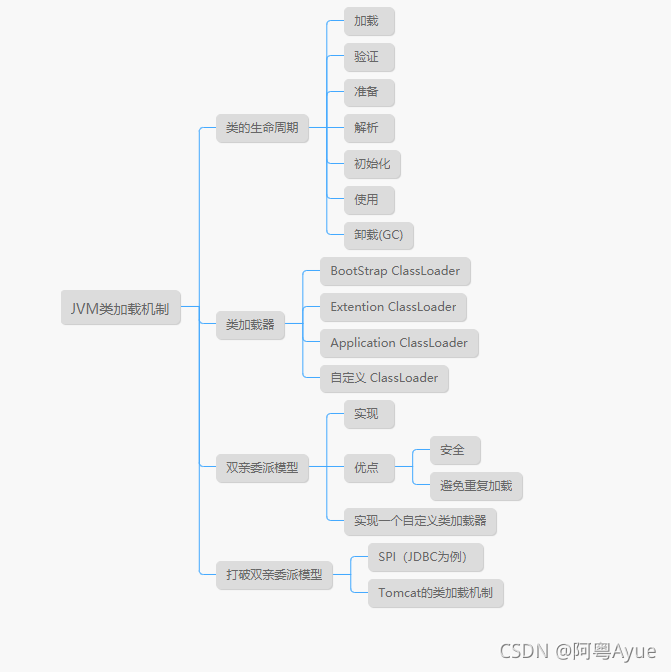
类的生命周期(类加载)
之前在JVM中的对象中讲过对象的创建过程第一步是需要检查这个类是否被类加载器加载,如果没有,那必须先执行相应的类加载过程,即把 class 加载到 JVM 的运行时数据区。
怎么加载?
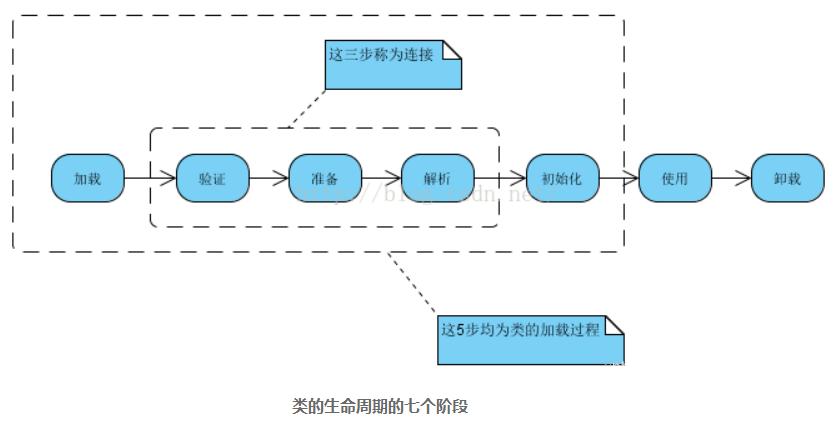
我们知道JVM是执行class文件的,而我们的Java程序是一个.java文件,实际上每个.java文件编译后(包括类或接口等)都对应一个 .class 文件。当Java 程序需要使用某个类时,JVM 会确保这个类已经被加载、连接(验证、准备和解析)和初始化。具体如下:
- 加载,类的加载是指把类的
.class文件中的数据读入到内存中,通常是创建一个字节数组读入.class文件,然后产生与所加载类对应的Class 对象。加载完成后,Class 对象还不完整,所以此时的类还不可用。 - 连接,当类被加载后就进入连接阶段,这一阶段包括验证、准备(为静态变量分配内存并设置默认的初始值)和解析(将符号引用替换为直接引用)三个步骤。
- 初始化,最后JVM 对类进行初始化,包括:如果类存在直接的父类并且这个类还没有被初始化,那么就先初始化父类;如果类中存在初始化语句,就依次执行这些初始化语句。
类加载完成之后,就是使用了,用完之后自然就是卸载。
怎么记住?
知道了加载过程其实还是不明白每一步具体是做什么的,不急我们慢慢来分析,但前提是为了方便记忆我们要记住这五个字:家宴准姐出。(因为少数国家的习俗就是比较大型的宴会是不允许女子出席的,所以可以通过这种方式来记)
家(加载)宴(验证)准(准备)姐(解析)出(初始化)
加载
加载阶段是整个类加载过程的一个阶段。 加载阶段虚拟机需要完成以下 3 件事情:
- 通过一个类的全限定名来获取定义此类的二进制字节流,即将class字节码文件加载到内存中。
- 将这个字节流所代表的静态存储结构(数据)转化为方法区的运行时数据结构(如静态变量,静态代码块,常量池等)。
- 在内存中(一般是堆)生成一个代表这个类的
java.lang.Class对象,作为方法区这个类的各种数据的访问入口。
注:第一点“通过一个类的全限定名来获取定义此类的二进制字节流”并不是说一定得从某个 class 文件中获取,我们可以从 zip 压缩包、从网络中获取、运行时计算生成、数据库中读取、或者从加密文件中获取等等。
验证
验证的目的是为了确保 Class 文件的字节流中的信息不会危害到虚拟机,在该阶段主要完成以下四种验证:
- 文件格式验证:验证字节流是否符合 Class 文件的规范,如主次版本号是否在当前虚拟机范围内,常量池中的常量是否有不被支持的类型。
- 元数据验证:对字节码描述的信息进行语义分析,如这个类是否有父类,是否集成了不被继承的类等。
- 字节码验证:是整个验证过程中最复杂的一个阶段,通过验证数据流和控制流的分析,确定程序语义是否正确,主要针对方法体的验证。如:方法中的类型转换是否正确,跳转指令是否正确等。
- 符号引用验证:这个动作在后面的解析过程中发生,主要是为了确保解析动作能正确执行。
准备
准备阶段是正式为类中定义的变量(被 static 修饰的变量)分配内存并设置类变量初始值的阶段,这些变量所使用的内存都将在方法区中进行分配。
这个阶段中有两个容易产生混淆的概念需要强调一下:
- 首先,这时候进行内存分配的仅包括类变量(被 static 修饰的变量),而不包括实例变量,实例变量将会在对象实例化时随着对象一起分配在 Java 堆中。
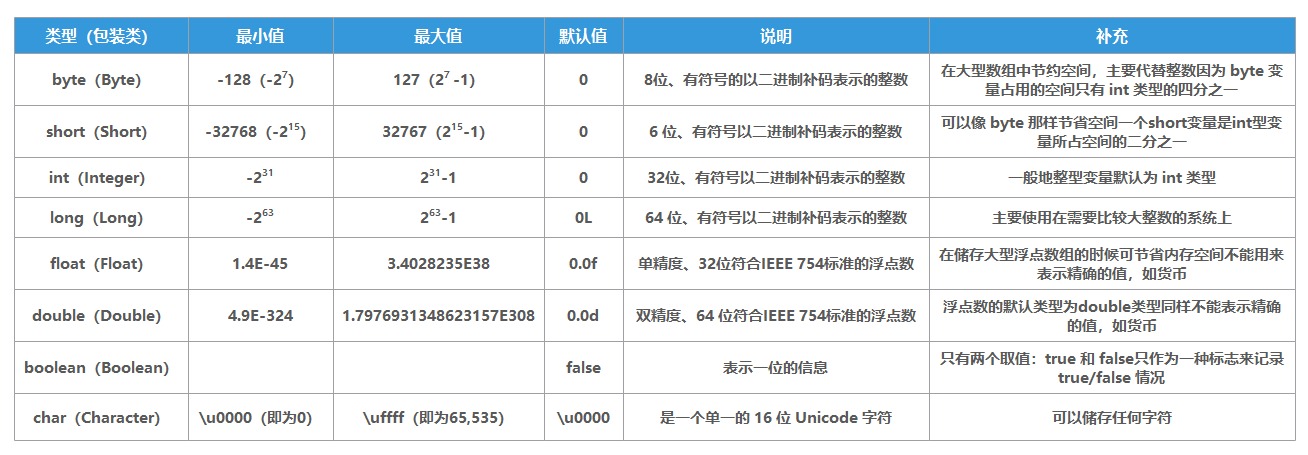
- 其次,这里所说的初始值通常情况下是数据类型的零值,假设一个类变量的定义为:
public static int value = 666,那变量 value 在准备阶段过后的初始值为 0 而不是 666,因为这时候尚未开始执行任何 Java 方法,而把 value 赋值为 666 是后续的初始化环节。
基本数据类型的零值表,来自八大基本数据类型
解析
解析阶段是 JVM 将常量池内的符号引用替换为直接引用的过程(这一步可选,解析动作并不一定在初始化动作完成之前,也有可能在初始化之后) 。
怎么理解符号引用和直接引用?
在编译的时候一个每个java类都会被编译成一个class文件,但在编译的时候虚拟机并不知道所引用类的地址,多以就用符号引用来代替,而在这个解析阶段就是为了把这个符号引用转化成为真正的地址的阶段。
我们可以这么理解:比如在在开会的时候,会上领导说会后要给小王发邮件,秘书于是就记录下来,会后秘书并不知道小王的邮箱地址具体是多少,只知道要给他发,于是就找小王要了邮箱地址。这里给小王发邮箱就相当于符号引用,而小王的邮箱地址就是直接引用。
解析大体可以分为:
- 类或接口的解析
- 字段解析
- 类方法解析
- 接口方法解析
我们了解几个经常发生的异常,就与这个阶段有关。
NoSuchFieldError:根据继承关系从下往上,找不到相关字段时的报错。(字段解析异常)IllegalAccessError:字段或者方法,访问权限不具备时的错误。(类或接口的解析异常)NoSuchMethodError:找不到相关方法时的错误。(类方法解析、接口方法解析时发生的异常)
初始化
初始化主要是对一个 class 中的 static{}语句进行操作(对应字节码就是 <clinit>() 方法)。
<clinit>()方法对于类或接口来说并不是必需的,如果一个类中没有静态语句块,也没有对变量的赋值操作,那么编译器可以不为这个类生成<clinit>()方法。
初始化阶段,虚拟机规范则是严格规定了有且只有 6 种情况必须立即对类进行初始化(而加载、验证、准备自然需要在此之前开始):
- 遇到
new、getstatic、putstatic或invokestatic这 4 条字节码指令时,如果类没有进行过初始化,则需要先触发其初始化。生成这 4 条指令的最常见的Java 代码场景是:- 使用
new关键字实例化对象的时候。 - 读取或设置一个类的静态字段(被 final 修饰、已在编译期把结果放入常量池的静态字段除外)的时候 。
- 调用一个类的静态方法的时候。
- 使用
- 使用
java.lang.reflect包的方法对类进行反射调用的时候,如果类没有进行过初始化,则需要先触发其初始化。 - 当初始化一个类的时候,如果发现其父类还没有进行过初始化,则需要先触发其父类的初始化。
- 当虚拟机启动时,用户需要指定一个要执行的主类(包含
main()方法的那个类),虚拟机会先初始化这个主类。 - 当使用 JDK 1.7 的动态语言支持时,如果一个
java.lang.invoke.MethodHandle实例最后的解析结果REF_getStatic、REF_putStatic、REF_invokeStatic的方法句柄,并且这个方法句柄所对应的类没有进行过初始化,则需要先触发其初始化。 - 当一个接口中定义了 JDK1.8 新加入的默认方法(被 default 关键字修饰的接口方法)时,如果这个接口的实现类发生了初始化,那该接口要在其之前被初始化。
通过下面的例子来了解初始化的一些场景:
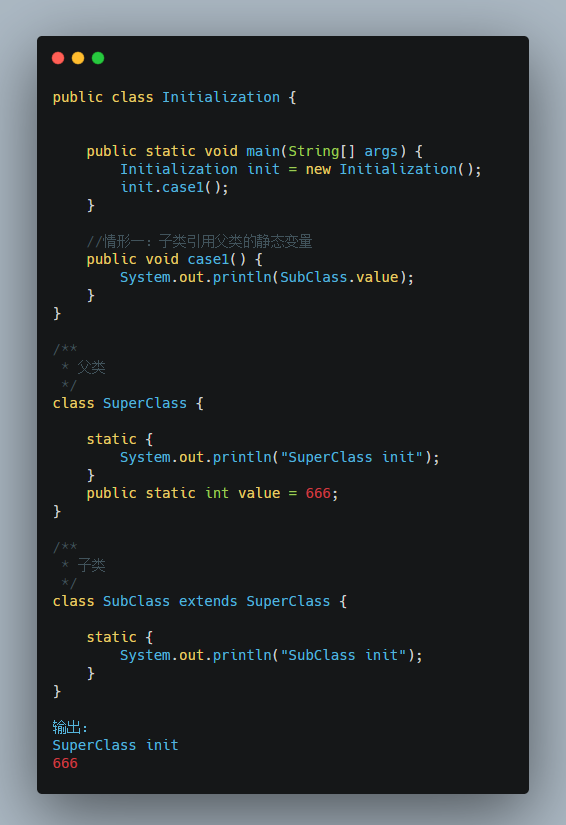
场景一
子类引用父类中的静态字段,只会触发父类的初始化,而不会触发子类的初始化。
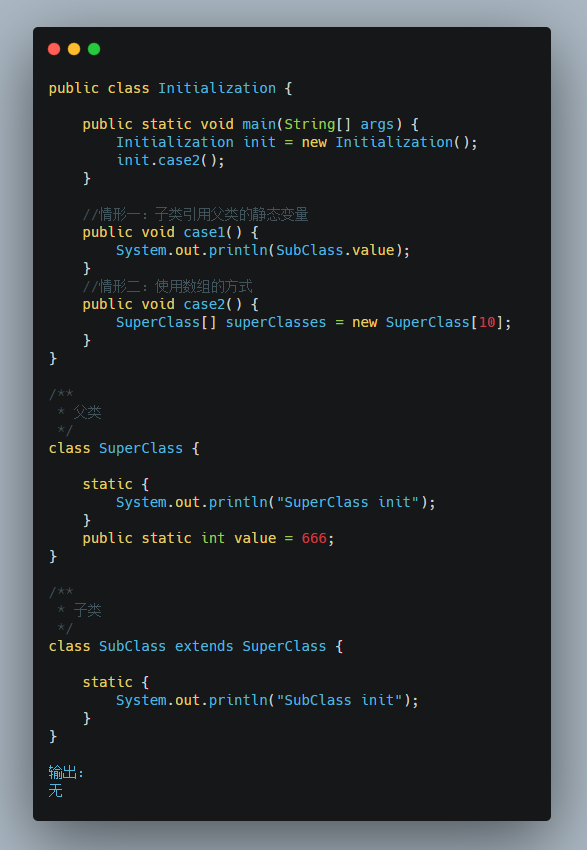
场景二
使用数组的方式, 不会触发初始化(触发父类加载,不会触发子类加载)
场景三
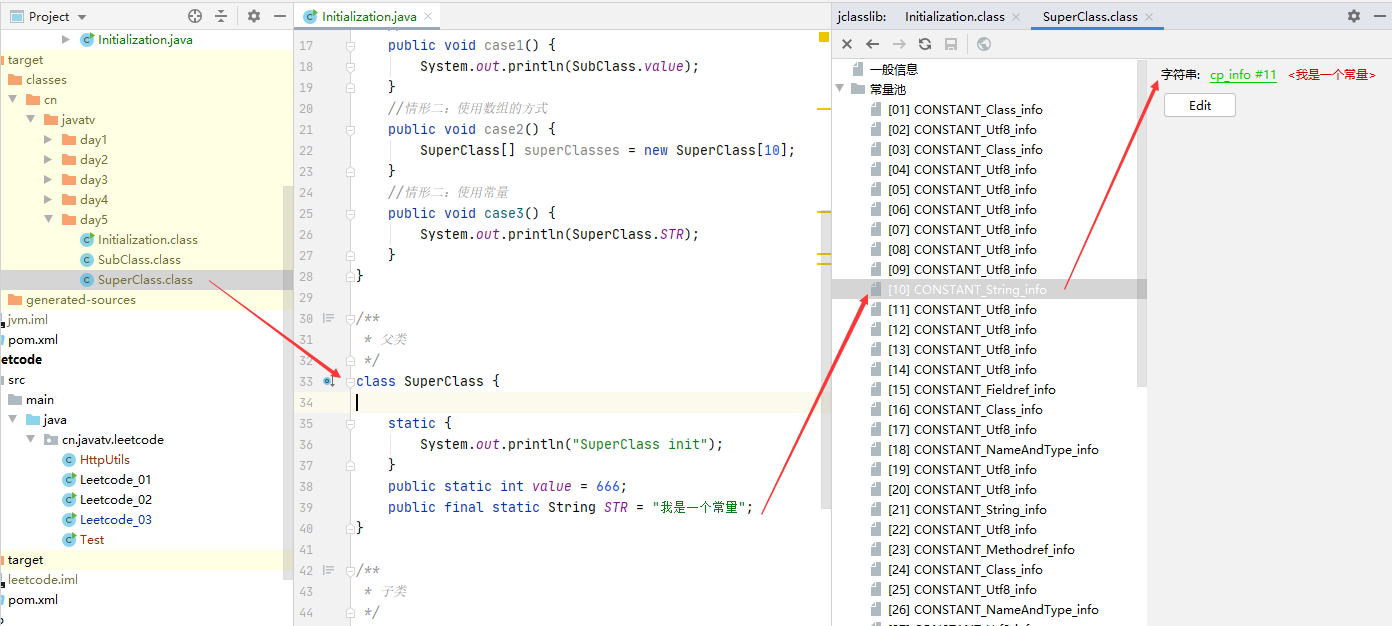
调用一个常量,不会触发初始化,也不会加载。
为什么不会加载? 因为在编译的过程中常量就已经加载到常量池中,如下,在还没有运行代码的情况下看常量池的数据(这里是通过jclasslib看的)
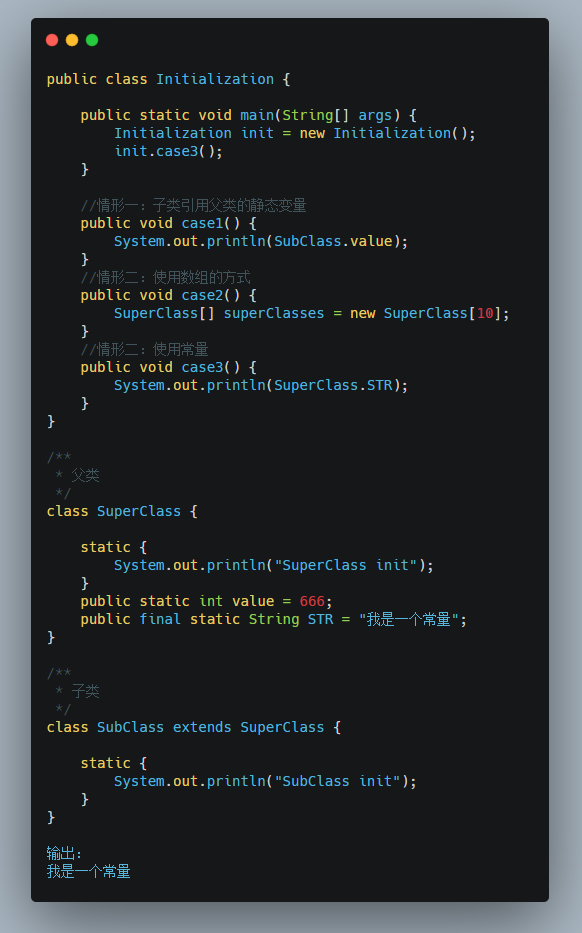
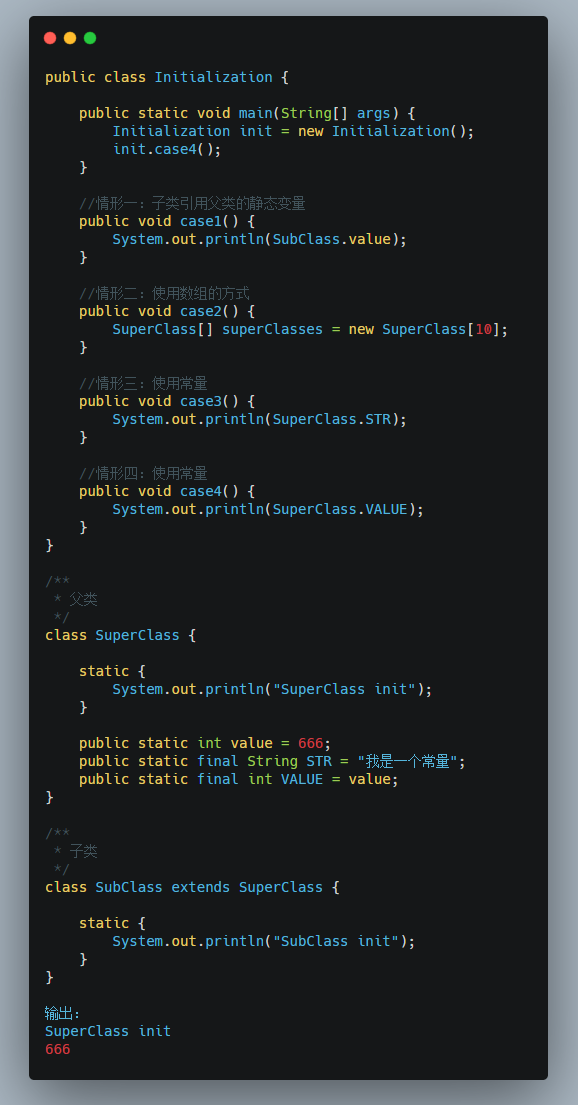
场景四
如果使用常量去引用另外一个常量(这个值编译时无法确定,所以必须要触发初始化)。
类加载器
可以看到,一个类的加载是比较复杂的,所以就有专门的加载器来负责,类加载器就是来做上面的事的(家宴准姐出这5个步骤)。而作为类加载器,JDK提供了三层类加载器,毕竟底层是它,所以他自己与自己的一套规则。
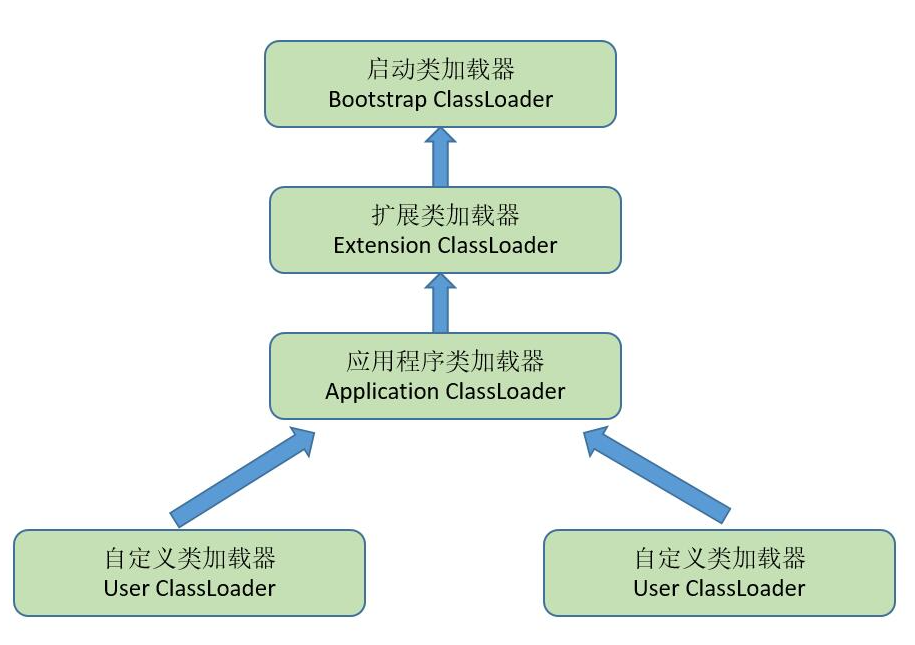
Bootstrap ClassLoader
这是加载器中的扛把子,任何类的加载行为,都要经它过问。它的作用是加载核心类库,也就是 rt.jar、resources.jar、charsets.jar 等。当然这些 jar 包的路径是可以指定的,-Xbootclasspath 参数可以完成指定操作。这个加载器是 C++ 编写的,随着 JVM 启动。
Extention ClassLoader
扩展类加载器,主要用于加载 lib/ext 目录下的 jar 包和 .class 文件。同样的,通过系统变量 java.ext.dirs 可以指定这个目录。这个加载器是个 Java 类,继承自 URLClassLoader。
在该类中获取class文件的时候,查看源代码是通过如下方式获取的:
private static File[] getExtDirs() {
String var0 = System.getProperty("java.ext.dirs");
File[] var1;
if (var0 != null) {
StringTokenizer var2 = new StringTokenizer(var0, File.pathSeparator);
int var3 = var2.countTokens();
var1 = new File[var3];
for (int var4 = 0; var4 < var3; ++var4) {
var1[var4] = new File(var2.nextToken());
}
} else {
var1 = new File[0];
}
return var1;
}
输出:
System.out.println(System.getProperty("java.ext.dirs"));
打印如下:
D:\jdk1.8\jre\lib\ext;C:\WINDOWS\Sun\Java\lib\ext
该ClassLoader就会在这些路径下面去查找class文件,如果有就加载进来,这里的加载不是所有的都加载,是用到才加载。
Application ClassLoader
这是我们写的 Java 类的默认加载器,有时候也叫作 System ClassLoader。一般用来加载 classpath 下的其他所有 jar 包和 .class 文件,我们写的代码,会首先尝试使用这个类加载器进行加载。
public static ClassLoader getAppClassLoader(final ClassLoader var0) throws IOException {
final String var1 = System.getProperty("java.class.path");
final File[] var2 = var1 == null ? new File[0] : Launcher.getClassPath(var1);
return (ClassLoader) AccessController.doPrivileged(new PrivilegedAction<Launcher.AppClassLoader>() {
public Launcher.AppClassLoader run() {
URL[] var1x = var1 == null ? new URL[0] : Launcher.pathToURLs(var2);
return new Launcher.AppClassLoader(var1x, var0);
}
});
}
输出:
System.out.println(System.getProperty("java.class.path"));
打印如下:
D:\jdk1.8\jre\lib\charsets.jar;
D:\jdk1.8\jre\lib\deploy.jar;
E:\production\javaweb;
...
其中E:\production\javaweb是项目生成class文件的路径
自定义 ClassLoader
自定义加载器,支持一些个性化的扩展功能,如何实现一个自己的类加载器,我们先看看双亲委派模型。
双亲委派模型
该模型要求除了顶层的启动类加载器外,其余的类加载器都应该有自己的父类加载器,而这种父子关系一般通过组合(Composition)关系来实现,而不是通过继承(Inheritance)。
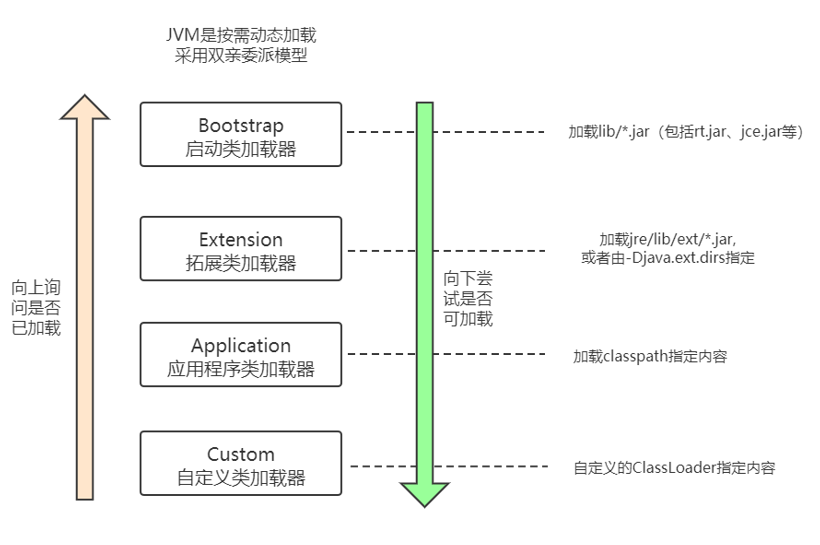
双亲委派模型的实现
我们来看看ClassLoader的源码,也就是双亲委派模型的实现过程,该类中有一个加载类的方法loadClass(),源码如下:
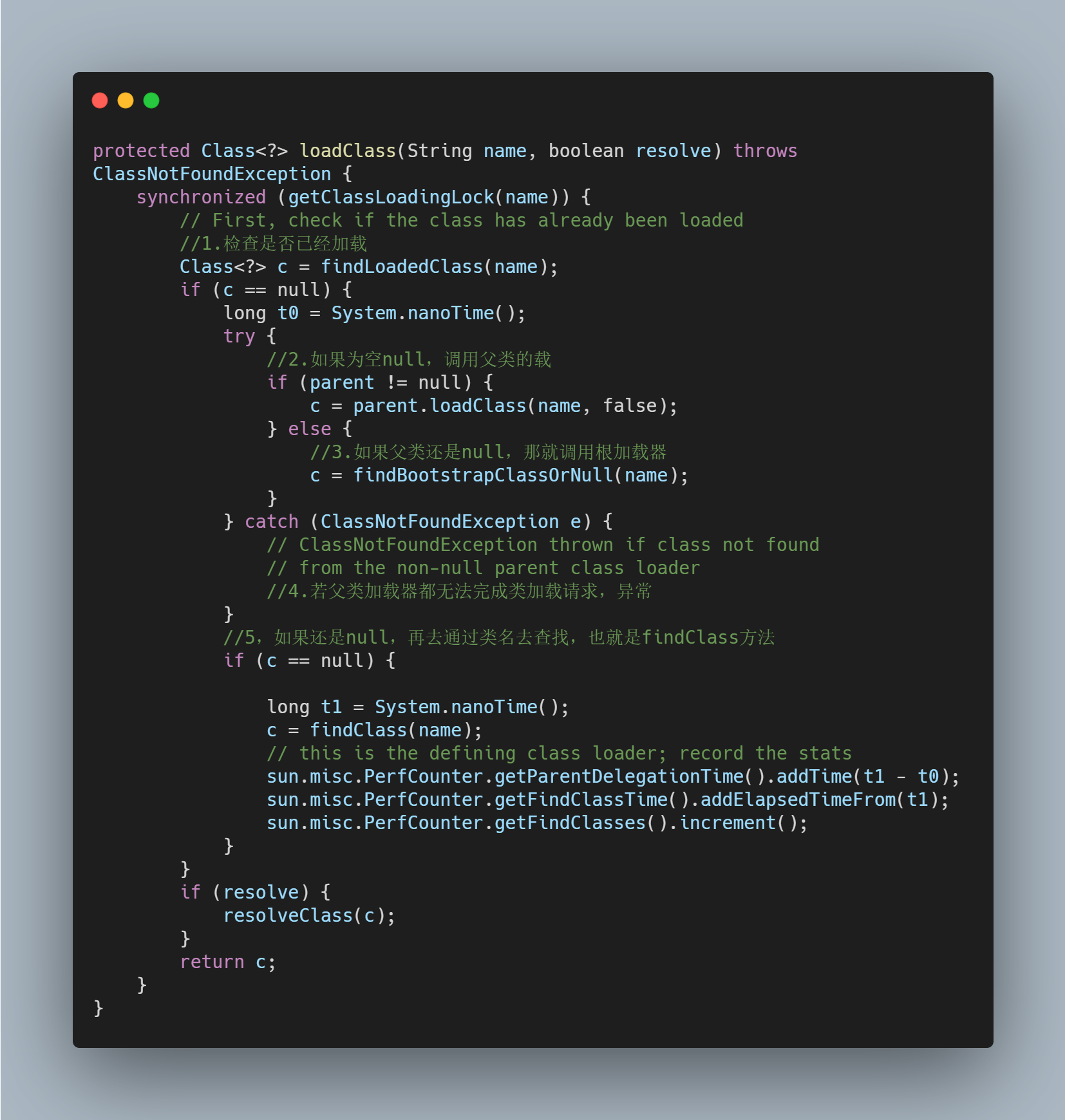
双亲委派模型的工作过程如下:
- 当前类加载器从自己已经加载的类中查询是否此类已经加载,如果已经加载则直接返回原来已经加载的类。
- 如果没有找到,就去委托父类加载器去加载(如代码
c = parent.loadClass(name, false)所示)。父类加载器也会采用同样的策略,查看自己已经加载过的类中是否包含这个类,有就返回,没有就委托父类的父类去加载,一直到启动类加载器。因为如果父加载器为空了,就代表使用启动类加载器作为父加载器去加载。 - 如果启动类加载器加载失败(例如在
$JAVA_HOME/jre/lib里未查找到该class),则会抛出一个异常ClassNotFoundException,然后再调用当前加载器的findClass()方法进行加载。
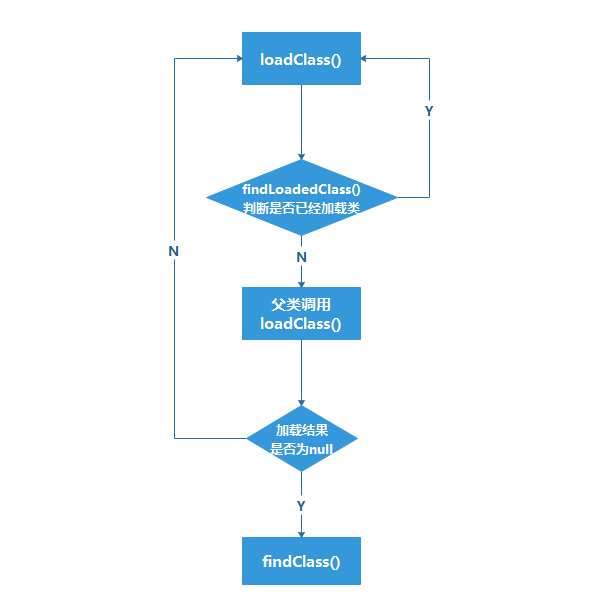
因此,我们可以得出一个结论,就是如果我们要自定义类加载器只需要重写findClass()方法即可,而不需要去重写loadClass()。
双亲委派模型的好处
-
安全性,避免用户自己编写的类动态替换 Java的一些核心类,防止Java核心api被篡改,比如 String。
如果用户自定义一个
java.lang.String类,该String类具有系统的String类一样的功能,只是在某个函数稍作修改。比如equals()函数,这个函数经常使用,如果在这这个函数中,黑客加入一些病毒代码。并且通过自定义类加载器加入到 JVM 中。此时,如果没有双亲委派模型,那么JVM就可能误以为黑客自定义的java.lang.String类是系统的String类,导致病毒代码被执行。而有了双亲委派模型,黑客自定义的
java.lang.String类永远都不会被加载进内存。因为首先是最顶端的类加载器加载系统的java.lang.String类,最终自定义的类加载器无法加载java.lang.String类。 -
避免重复加载,即避免多分同样字节码的加载。
这里需要注意的是,避免重复加载是针对同一个类加载器来说的,即要比较两个类是否相等,只有在这两个类是由同一个类加载器加载的前提下才有意义,否则,即使这两个类来源于同一个 Class 文件,被同一个虚拟机加载,只要加载它们的类加载器不同,那这两个类就必定不相等。
注:这里所指的相等,包括代表类的 Class 对象的 equals()方法、isAssignableFrom()方法、isInstance()方法的返回结果,也包括使用 instanceof 关键字做对象所属关系判定等情况。
再谈自定义类加载器
双亲委派模型的好处我们已经有所了解,那为什么我们还需要再去自定义类加载器呢?没事找事?
我们在开头在类的加载过程说的是二进制字节流,也就是说并不一定是class文件,对不对?万一是网络传输呢?为了安全我是不是得给这个字节码加密?
不仅如此,在一些情况下,比如软件租赁,给别人一个jar包,约定license,到期之后是需要在次购买才能使用的,但是如果别人直接反编译,拿到核心的代码,那不就是亏大了。
自定义类加载器的应用场景:
- 加密,Java代码可以轻易的被反编译,如果你需要把自己的代码进行加密以防止反编译,可以先将编译后的代码用某种加密算法加密,类加密后就不能再用Java的ClassLoader去加载类了,这时就需要自定义ClassLoader在加载类的时候先解密类,然后再加载。
- 从非标准的来源加载代码,如果你的字节码是放在数据库、甚至是在云端,就可以自定义类加载器,从指定的来源加载类。
- 以上两种情况在实际中的综合运用,比如你的应用需要通过网络来传输 Java 类的字节码,为了安全性,这些字节码经过了加密处理。这个时候你就需要自定义类加载器来从某个网络地址上读取加密后的字节代码,接着进行解密和验证,最后定义出在Java虚拟机中运行的类。
实现一个自定义类加载器
通过上面的分析,我们知道实现一个自定义类加载器主要有3个重要的方法:
| 方法 | 说明 |
|---|---|
| loadClass() | 调用父类加载器的loadClass,加载失败则调用自己的findClass方法 |
| findClass() | 根据名称读取文件存入字节数组 |
| defineClass() | 把一个字节数组转为Class对象 |
-
新建一个java文件
public class Hello{ static{ System.out.println("Hello World!!!"); } }直接在桌面上创建的(或者其他文件夹),不要有任何包名(package),如果在当前项目新建,编译之后会在classpath下面,由于双亲委派机制就不会走自定义类加载器了,而是
Application ClassLoader。 -
使用
javac Hello.java编译 -
定义
ClassLoaderimport java.io.ByteArrayOutputStream; import java.io.File; import java.io.FileInputStream; import java.io.InputStream; public class MyClassLoader extends ClassLoader { //路径 private String path; public MyClassLoader(String path) { this.path = path; } //用于寻找类文件 @Override public Class findClass(String name) { byte[] b = loadClassData(name); //defineClass把字节流转为Class对象 return defineClass(name, b, 0, b.length); } //用于加载类文件 private byte[] loadClassData(String name) { name = path + name + ".class"; InputStream in = null; ByteArrayOutputStream out = null; try { in = new FileInputStream(new File(name)); out = new ByteArrayOutputStream(); int i = 0; while ((i = in.read()) != -1) { out.write(i); } } catch (Exception e) { e.printStackTrace(); } finally { try { out.close(); in.close(); } catch (Exception e) { e.printStackTrace(); } } return out.toByteArray(); } } -
测试
public class ClassLoaderChecker { public static void main(String[] args) throws Exception { //我这里直接放在桌面编译 MyClassLoader classLoader = new MyClassLoader("C:\\Users\\Admin\\Desktop\\"); Class c = classLoader.loadClass("Hello"); System.out.println(c.getClassLoader()); System.out.println(c.getClassLoader().getParent()); System.out.println(c.getClassLoader().getParent().getParent()); System.out.println(c.getClassLoader().getParent().getParent().getParent()); //实例化 c.newInstance(); } } -
输出
cn.javatv.day5.MyClassLoader@135fbaa4 sun.misc.Launcher$AppClassLoader@18b4aac2 sun.misc.Launcher$ExtClassLoader@330bedb4 null Hello World!!!为什么有个
null?根据代码可以知道,应该打印根类加载器BootStrapClassLoader,因为BootStrapClassLoader是一个native方法,C++实现,没有对应的Java类。所以在Java中是取不到的。如果一个类的classloader是null。已经足可以证明他就是由BootStrapClassLoader加载的。
注:这个例子并没有破坏双亲委派模型,如果我们在项目中去编译,会发现类加载器是Application ClassLoader,具体可以看看这篇文章:如何破坏双亲委派模型
编译后移到桌面(或者自己指定一个目录)
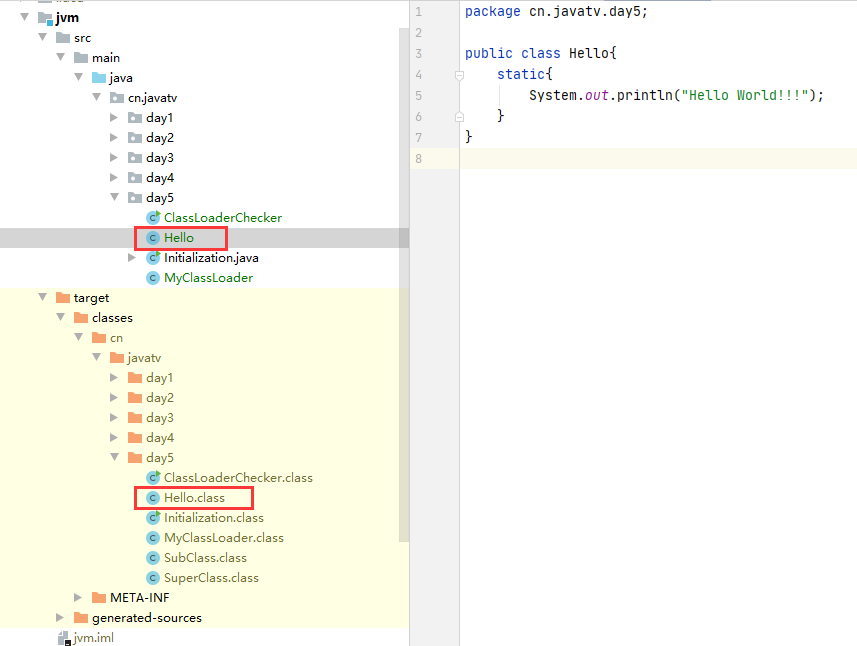
测试:
public class ClassLoaderChecker {
public static void main(String[] args) throws Exception {
MyClassLoader classLoader = new MyClassLoader("C:\\Users\\Admin\\Desktop\\");
Class c = classLoader.loadClass("cn.javatv.day5.Hello");
System.out.println(c.getClassLoader());
//实例化
c.newInstance();
}
}
输出:
sun.misc.Launcher$AppClassLoader@18b4aac2
Hello World!!!
通过上面的分析发现,自定义类加载器其实也遵循双亲委派模型,如果不想打破双亲委派模型,重写ClassLoader类中的findClass()方法即可,无法被父类加载器加载的类最终会通过这个方法被加载。而如果想打破双亲委派模型则需要重写loadClass()方法。
破坏双亲委派模型
上面也说到了,一般来说重写findClass()是无法破坏双亲委派模型的,但不是不能,如JAVA的SPI,还有tomcat等。下面介绍一下SPI是如何做的。
SPI(JDBC)
Java 中有一个 SPI 机制,全称是 Service Provider Interface,是 Java 提供的一套用来被第三方实现或者扩展的 API,它可以用来启用框架扩展和替换组件。
Class.forName()手动注册
这个说法可能比较晦涩,但是拿我们常用的数据库驱动加载来说(不管是Mybatis还是其他的都是需要用到JDBC的),就比较好理解了。在使用 JDBC 写程序之前,通常会调用这行代码Class.forName("com.mysql.jdbc.Driver")连接数据库,用于加载所需要的驱动类。
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class SPI_JDBC {
public static final String URL = "jdbc:mysql://localhost:3306/demo?serverTimezone=GMT%2b8";
public static final String USER = "root";
public static final String PASSWORD = "123456";
public static void main(String[] args) throws Exception {
//1.加载驱动程序
Class.forName("com.mysql.jdbc.Driver");
//2. 获得数据库连接
Connection conn = DriverManager.getConnection(URL, USER, PASSWORD);
//3.操作数据库,实现增删改查
Statement stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery("SELECT name FROM user"); //自己创建一个表
//4.如果有数据,rs.next()返回true
while (rs.next()) {
System.out.println("查询数据为:" + rs.getString("name"));
}
}
}
我们执行一下上面的代码:
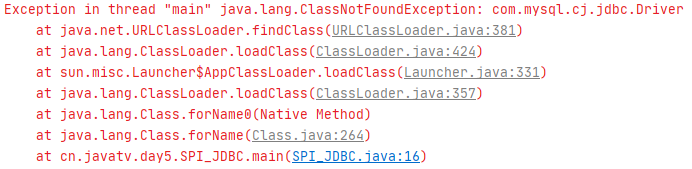
没错,报错了,但是我们的代码却能通过编译,我们看看导入这几个类:
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
当我们点进去发现是rt.jar包下面的
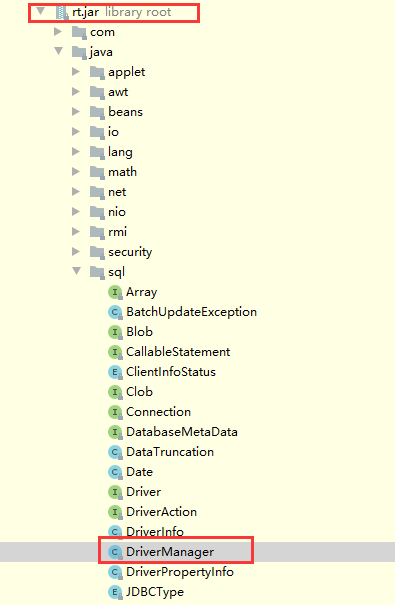
为什么报错?
因为JDK只定义了接口,并没有实现它,这需要不同厂商来实现,我们引入驱动mysql-connector-java-8.0.11.jar(提取码:smq9),再次运行上面的代码:
查询数据为:Jone
查询数据为:Jack
Class.forName()的作用是什么?
我们知道Class.forName() 方法要求JVM查找并加载指定的类到内存中,此时将com.mysql.jdbc.Driver当做参数传入,就是告诉JVM,去com.mysql.jdbc这个路径下找Driver类,将其加载到内存中。由于加载类文件时会执行其中的静态代码块,其中Driver类的源码如下:
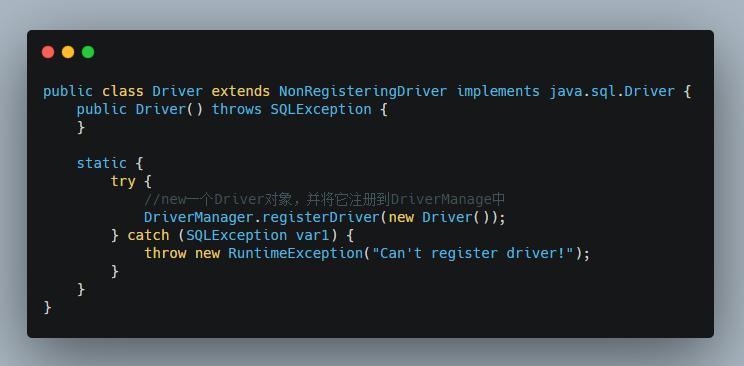
再看看这个DriverManager.registerDriver 方法:
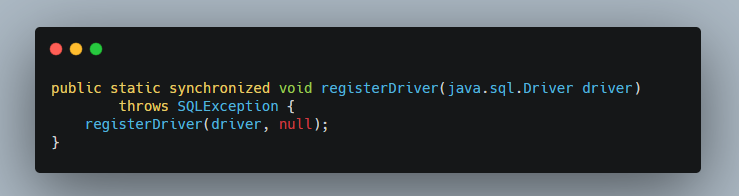
继续看这个registerDriver(driver, null) 方法
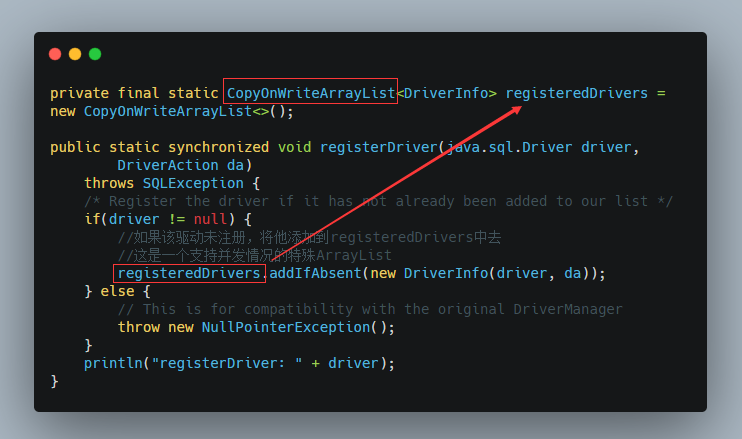
也就是说,Class.forName("com.mysql.jdbc.Driver")是一种初始化模式,通过 static 代码块显式地声明了驱动对象,然后把这些信息,保存到底层的一个 List 中,即将mysql驱动注册到DriverManager中去,然后通过DriverManager.getConnection使用。
自动注册JDBC驱动
做一个测试
我们把Class.forName("com.mysql.jdbc.Driver")注释后在运行上面代码,发现还是可以查询数据的。
所以问题来了,Class.forName("com.mysql.jdbc.Driver")这段代码是不是没什么用?
在路径mysql-connector-java-8.0.11.jar!\META-INF\services\java.sql.Driver下有这样一个文件:

通过在 META-INF/services 目录下,创建一个以接口全限定名为命名的文件(内容为实现类的全限定名),即可自动加载这一种实现,这就是 SPI。
在高版本的mysql驱动,如8.x版本已经把手动调用给去掉了(5.x的没有),如下:
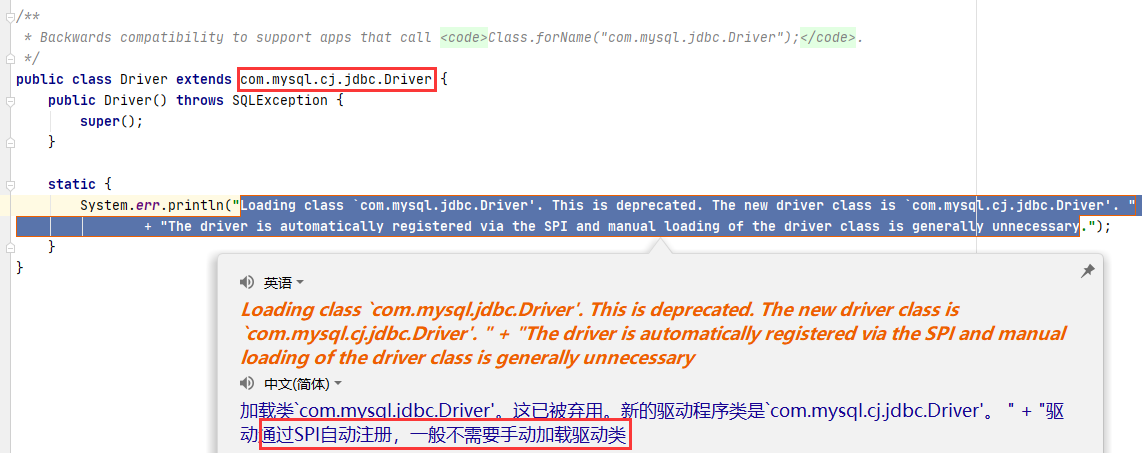
💥💥💥💥💥💥
看到这应该疑惑了,SPI和破坏双亲委派模型有什么关系?
我们看一下,就算通过SPI可以自动加载,那到底怎么实现的呢?进入DriverManager的源码中可以看到一个静态块:
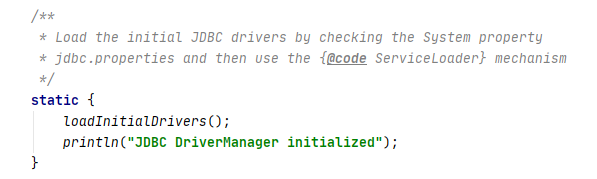
进入loadInitialDrivers()方法中看到以下一段代码:
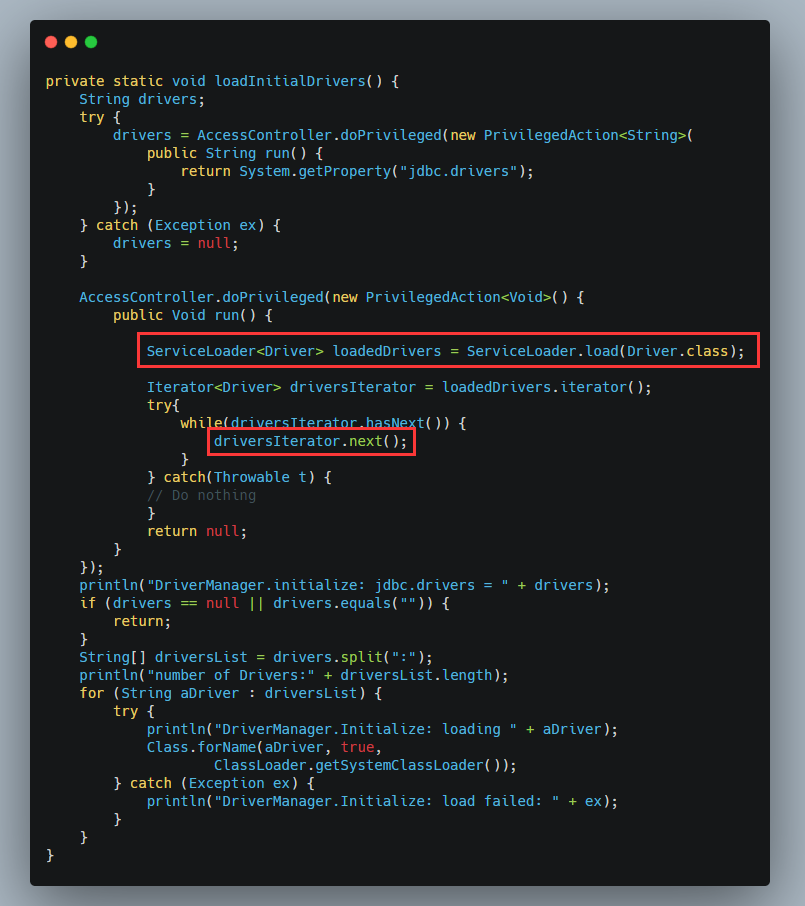
重点就是ServiceLoader.load(Driver.class),可以把类路径下所有jar包中META-INF/services/java.sql.Driver文件中定义的类加载上来,此类必须继承自java.sql.Driver。
我们再看看driversIterator.next()做了什么,在ServiceLoader类中查看:

看到了什么?大声告诉我,没错就是Class.forName(),也就是说SPI自动注册了,不需要手动注册。
🙄🙄🙄🙄🙄🙄
但是好像还是和破坏双亲委派模型没啥关系,因为我们还有一个方法没看ServiceLoader.load(Driver.class),我们进入load方法:

通过代码你可以发现它把当前的类加载器,设置成了线程的上下文类加载器。那么,对于一个刚刚启动的应用程序来说,它当前的加载器是谁呢?也就是说,启动 main 方法的那个加载器,到底是哪一个?
所以我们继续跟踪代码。找到 Launcher 类,就是 jre 中用于启动入口函数 main 的类。我们在 Launcher 中找到以下代码。
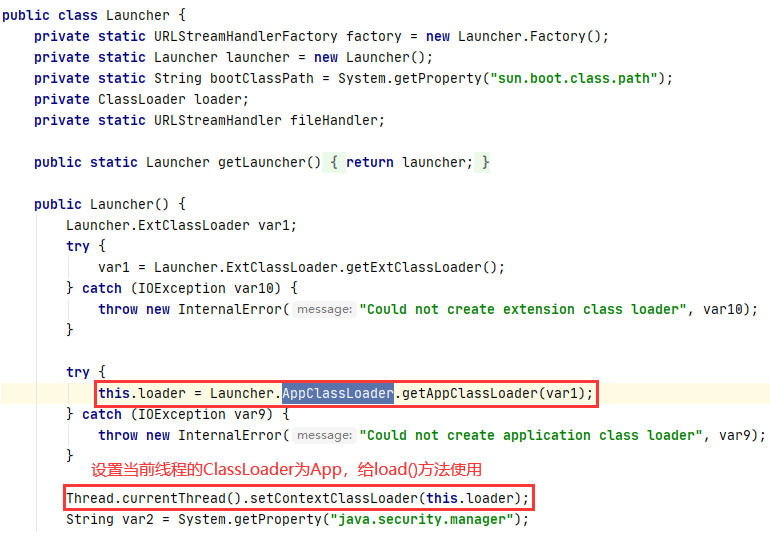
所以,在JVM启动的时候,就通过AppClassLoader去执行JAVA提供的接口的实现类,而不是去询问是否存在父类加载器,也就是说,SPI打破了双亲委派模型。
使用SPI
按照Mysql驱动的方式来使用一下SPI
- 在jar包的
META-INF/services目录下创建一个以"接口全限定名"为命名的文件,内容为实现类的全限定名。 - 接口实现类所在的jar包在classpath下。
- 主程序通过
java.util.ServiceLoader动态状态实现模块,它通过扫描META-INF/services目录下的配置文件找到实现类的全限定名,把类加载到JVM。 - SPI的实现类必须带一个无参构造方法。
一个栗子
首先定义一个SPIService,它是一个接口:
public interface SPIService {
public void hello();
}
两个实现类,分别为SPIServiceA,SPIServiceB
public class SPIServiceA implements SPIService{
@Override
public void hello() {
System.out.println("使用SPI_SPIServiceA");
}
}
public class SPIServiceB implements SPIService{
@Override
public void hello() {
System.out.println("使用SPI_SPIServiceB");
}
}
建一个META-INF/services的文件夹,里面建一个file,file的名字是接口的全限定名cn.xx.xx.SPIService:文件的内容是SPIService实现类SPIServiceA、SPIServiceB的全限定名:
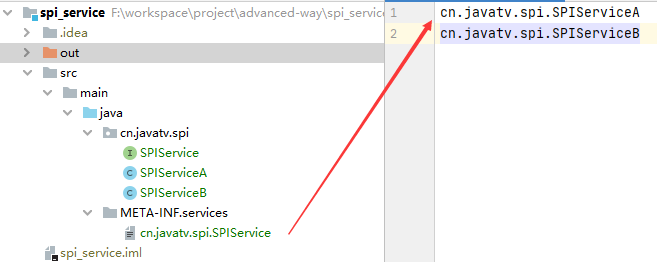
打成jar包测试:需要jar包可自行下载(链接:提取码:ckcr)
import cn.javatv.spi.SPIService;
import java.util.Iterator;
import java.util.ServiceLoader;
public class TestSPI {
public static void main(String[] args) {
ServiceLoader<SPIService> serviceLoader = ServiceLoader.load(SPIService.class);
Iterator<SPIService> iterator = serviceLoader.iterator();
while (iterator.hasNext()) {
SPIService spiService = iterator.next();
spiService.hello();
}
}
}
输出:
使用SPI_SPIServiceA
使用SPI_SPIServiceB
小结
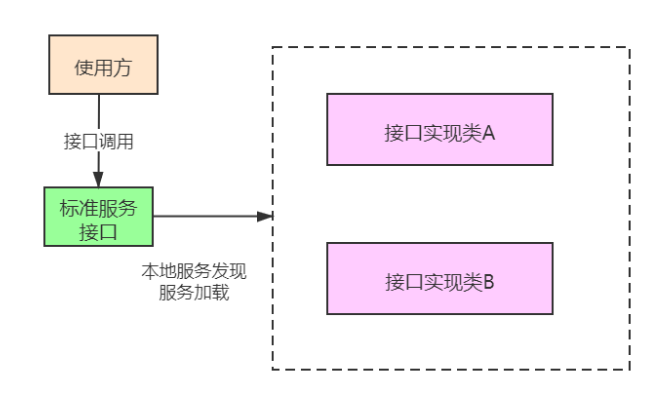
SPI 实际上是基于接口的编程+策略模式+配置文件组合实现的动态加载机制,主要使用java.util.ServiceLoader 类进行动态装载,大致流程如下:
Tomcat 类加载机制
Tomcat 的类加载也是也是差不多的,网上有很多优秀的讲解,这里推荐一篇