Ŀ¼
�����ַ���
�����ַ���һ�������ַ�ʽ:
��ʽ1
String str1= "abc";
System.out.println(str1);
//������
abc
��ʽ2
String str2= new String("abc");
System.out.println(str2);
//������
abc
��ʽ3
char[] value={'a','b','c'};
String str=new String(value);
System.out.println(str);
//������
abc
���ַ�ʽ���ڴ�ͼ
��ʽ1 ��ʽ2
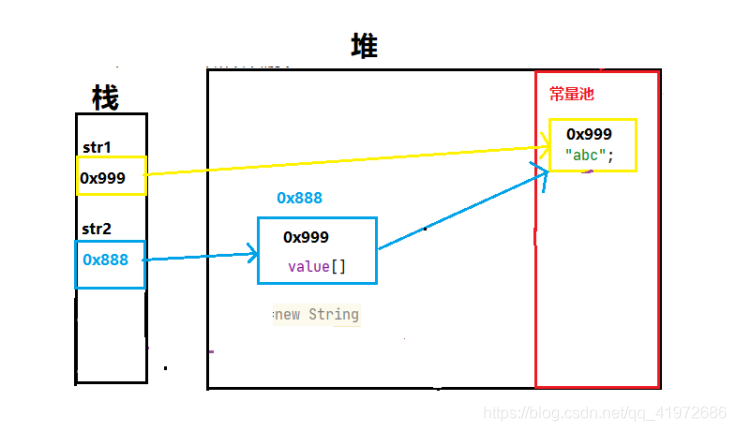
�������������Ƚ���һ���ַ����������ĸ���:
String������ʹ�����������ģʽ
��JVM�ײ�ʵ���ϻ��Զ�ά��һ�������,�������س�Ϊ�ַ���������
���ڷ�ʽ1�еĸ�ֵ��ʽ��˵,��Ϊ��ֱ�Ӹ�ֵ,���Ը�ֵ�����ݽ��Զ����浽�ַ��������ص���,��ʱabc�������ַ���������,����abc�õ�ַ0x999������str1�������
���ڷ�ʽ2�ĸ�ֵ��ʽ��˵,����ַ��������ص�����abc,��ֱ�ӽ�abc�ĵ�ַ0x999����value����,Ȼ���ٽ�String���ڶ���ʵ�����Ķ���ĵ�ַ0x888����str2����,����ַ��������ص���û��abc,��ô�Ͱ��¿��ٵ��ַ�������abc���볣���ص����Թ��´�ʹ��,Ȼ��Ѵ��ȥ��abc�ĵ�ַ����value����,Ȼ���ٽ�String���ڶ���ʵ�����Ķ���ĵ�ַ0x888����str2����,��������Ϊʲô������value����,��Ҫ��ϸ����:
- �������ǽ�����String�����Ķ����ʵ��������,����һ�����ڶ��Ͽ����ڴ�.
- ��ʱ������
String����вι��캯���в���Ϊ�ַ��������
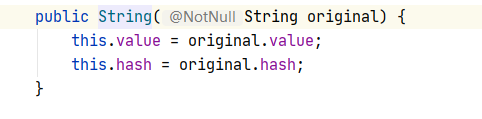
���Կ������ǽ�original��ֵ������value,������String����value�����Ա����������ʲô��?
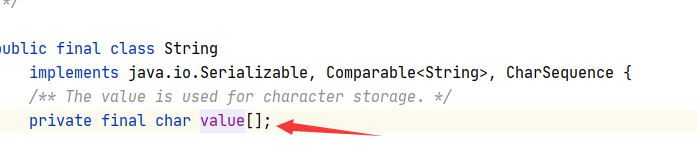
���Կ�����˽�е��ұ�final�����ε�char���͵�value����
ע��:��final�����εij�Ա������ʱ��String���в�û�н��г�ʼ��,������Ҫ�ڹ��췽���н��г�ʼ��,������Ҳ��Ϊʲôthis.value=original.val���ֵ�ԭ��.��Ϊvalue��������ʱ��û��ֱ�ӳ�ʼ��,����ͨ�����췽������ ���δӶ���value���������г�ʼ��.
��ʽ3
��ʽ3�ĸ�ֵ��ʽ���ڴ�ͼ����:

������������Ϊʲô����������:
����value��һ���ֲ�����,��������ջ�Ͽ����ڴ�,ͬʱ�ڶ��Ͽ����ڴ�洢��a��,��b��,��c��,��d��,'e�������Ԫ��,�������ټ�����ջ�Ͽ����ڴ�,�洢str3����ֲ�����.ͬʱ��ջ�Ͽ����ڴ�洢String������ʵ��������.
��������������String�������вι��캯���в���Ϊ����ʱ��Դ������:
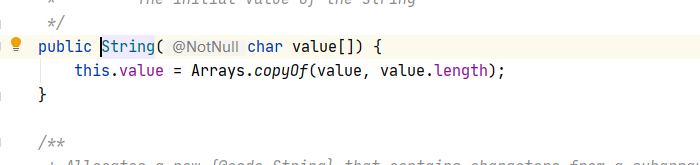
���ǻᷢ����ʹ����copyof����������һ���µ�����,���¿�����������ʵ�������ǵ�value����ĸ���Ʒ.�൱���ǽ�����������鸳ֵ����String�����������value����.
���Ծ���ͼ��������һ��,��ʱ�¿���������ĵ�ַΪ0x888,�������ַ��ֵ��String���еij�Ա����value����,Ȼ���ٽ�String���ڶ��ϵ�ʵ��������ĵ�ַ0x999��ֵ�����ǵ�str3�������.
�ܽ�
�����ִ����ַ��������ķ�ʽ,�ײ���ʵ����Դ���б�private��final�����ε�char���͵������й�
����صĸ���
���ء� �DZ���е�һ�ֳ�����, ��Ҫ������Ч�ʵķ�ʽ, ���ǻ���δ����ѧϰ���������� ���ڴ�ء�, ���̳߳ء�, �����ݿ����ӳء� ��
Ȼ���������ĸ���Ǽ��������, Ҳ��������������. �ٸ�����:
��ʵ��������һ��Ů��, ��Ϊ ���̲衱, �ں߸�˧̸�Ŷ����ͬʱ, �����ܺͱ�Č�˿������. ��ʱ�������˿����Ϊ ����̥��. ��ôΪɶҪ�б�̥? ��Ϊһ���߸�˧������, �Ϳ��������ұ�̥����, ���� Ч�ʱȽϸ�.
������Ů��, ͬʱ�ںͺܶ����˿������, ��ô��Щ��̥�ͳ�Ϊ ��̥��.
��������
���������ڽ������ʱ����ᵽ�����õĸ���.
���������� C �����е�ָ��, ֻ����ջ�Ͽ�����һС���ڴ�ռ䱣��һ����ַ. �������ú�ָ���ֲ�̫��ͬ, ָ���ܽ��и�����������(ָ��+1)֮���, �������ò���, ����һ�� ��û��ô�� ��ָ��.
����, Ҳ�������������һ����ǩ, ������ ��һ��������. һ�����������һ����ǩ, Ҳ���������. ���һ����������һ����ǩ��û��, ��ô�������ͻᱻ JVM ��������������յ�.
Java ������, String, �Լ��Զ���������������.
���� String ����������, ��˶������´���
String str1 = "Hello";
String str2 = str1;
�ڴ�ͼ������ʾ:
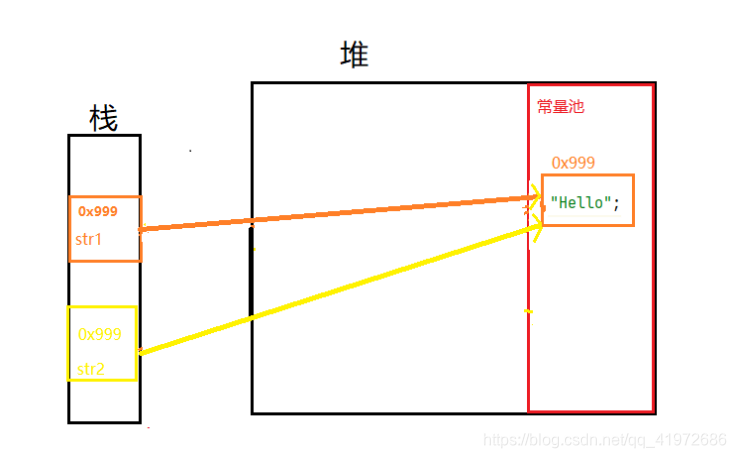
��ʱ��������ָ����ͬһ������
��ô��ͬѧ���ܻ�˵, �Dz����� str1 , str2 Ҳ����֮�仯��?��������һ�δ���:
String str1 = "Hello";
String str2 = str1;
str1 = "hello";
System.out.println(str2);
System.out.println(str1);
��ʵ��,�����Ĵ��벢���� ���ġ� �ַ���, ������ str1 �������ָ����һ���µ� String ����.
�ڴ�ͼ������ʾ:
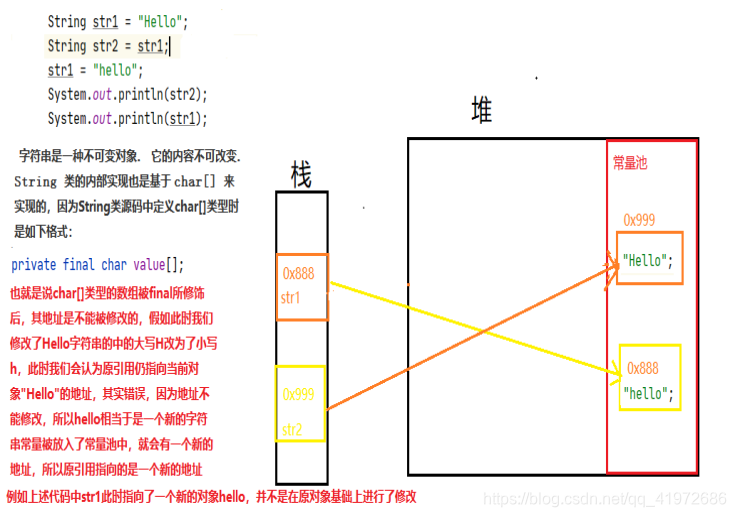
��Ϊ�ַ�����һ�ֲ��ɱ����(��������ϸ��),�������ݲ��ɱ�,Sting����ڲ�ʵ��Ҳ�ǻ���char[]��ʵ�ֵ�,��ΪString��Դ���ж���char[]����ʱ�����¸�ʽ:

Ҳ����˵char[]���͵����鱻final������ʱ,���ַ�Dz��ܱ��ĵ�,�������Ǵ�ʱ����Hello�ַ���������ĸH��ΪСдh,�൱�ڲ�����һ���µ��ַ�������hello,��ô�ڳ������Ͼ��൱�ڲ�����һ���µĶ���,��Ҫ�����µĵ�ַ,�Ͳ�������ԭ��Hello�ĵ�ַ�Ͻ����Ϊhello��,���Ծ�����ͼ��ʾ��
��ôҪ����ԭ��ַ��Ϊhello,��Ҫ�õ�����,�������ַ������ɱ���һ�½����ǻ���ܷ������������
�ַ����ж����
�ж��ַ��������Ƿ����
�������������int�ͱ���,�ж�����ȿ���ʹ�� == ��ɡ�
int x = 10 ;
int y = 10 ;
System.out.println(x == y);
// ִ�н��
true
���˵������String�������ʹ�� == ,�����ж������Ƿ����,�������漸�δ���,���ж��ַ����������Ƿ����
����1
String str1 = "Hello";
String str2 = "Hello";
System.out.println(str1 == str2);
// ִ�н��
true
����1�ڴ沼��:
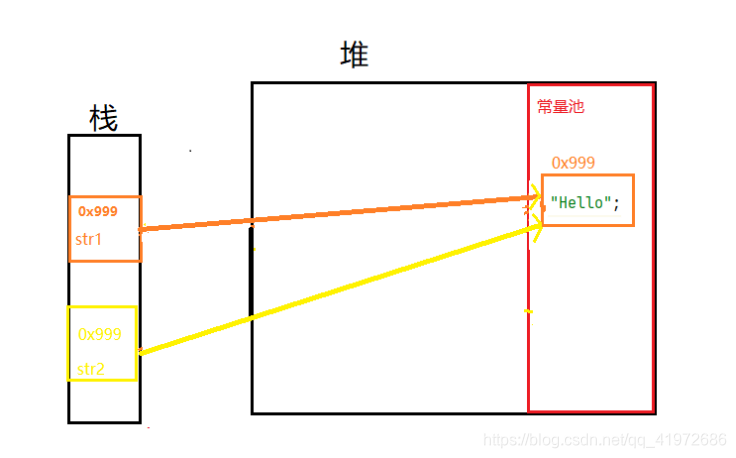
���Ƿ���, str1 �� str2 ��ָ��ͬһ�������. ��ʱ�� ��Hello�� �������ַ����������� �ַ��������� ��.
�� ��Hello�� �������ַ�������ֵ����, Ҳ����Ҫһ�����ڴ�ռ����洢��. �����ij�������һ���ص�, ���Dz���Ҫ��(������). ��������������ж���ط����ö���Ҫʹ�� ��Hello�� �Ļ�, ��ֱ�����õ������ص����λ�þ�����, ��û��Ҫ�� ��Hello�� ���ڴ��д洢����.Ҳ����˵����ÿ���ڴ����ַ�����ʱ���ῴ�����ص��е�����û�е�ǰ����Ҫ�������ַ���,����оͲ����ڳ��������ٴ���һ���ˡ�
����2
String str = "abc";
String str2 = new String("abc");
System.out.println(str1 == str2);
//������
false
����2 �ڴ�ͼ����
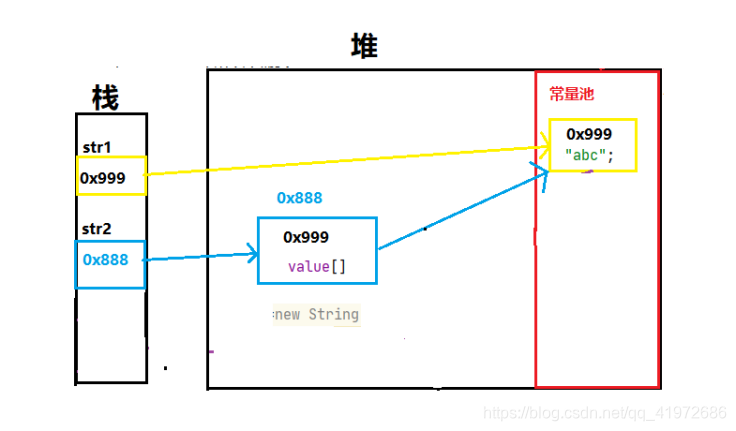
���ǻᷢ�ִ�ʱ���մ�����Ϊfalse.
ԭ����ͼ��ʾ:str1��str2������ָ��Ķ��������ͬ,������洢�ĵ�ַҲ�Dz���ͬ��,��ô���յıȽ�һ��Ϊfalse.
��ô������ط�������������str1��str2�������������洢�ĵ�ַ��ͬ�Ļ�,��ʱ��������һ����ĸ���:���ֹ����:����intern()����
������������:
String str1 = "hello" ;
String str2 = new String("hello") ;
System.out.println(str1 == str2);
// ִ�н��
False
---------------------------------------------------------------------
String str1 = "hello" ;
String str2 = new String("hello").intern() ;
System.out.println(str1 == str2);
// ִ�н��
true
������ݴ�����ڴ�ͼ:
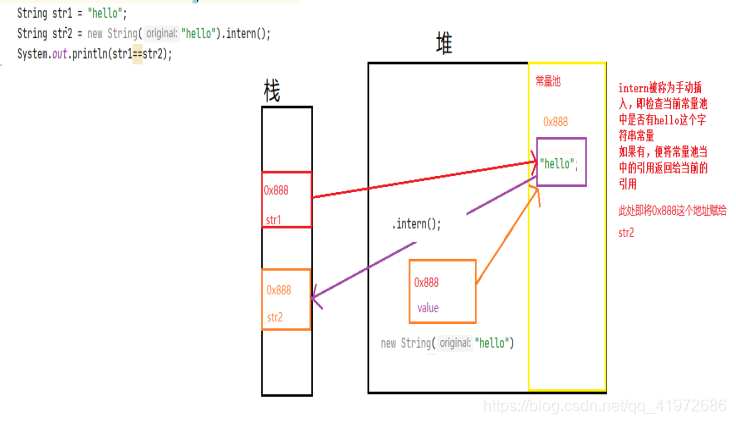
���ǿ��Կ�����ʱstr1��str2���õĵ�ַ��ͬ,����Ϊʲô��?
��:�����intern()�����Ĺ���,intern����Ϊ�ֹ���ش���,����
String str2 = new String(��hello��).intern() ; ��δ�����˵,�Ǽ���ʱ�ַ��������ص����Ƿ���hello����ַ�������,�����,�㽫�������е����÷��ظ���ǰ������,��������������˵,��ʱ������������hello����ַ���������,��ô�ͽ����ڳ����ص��еĵ�ַ��������str2,��str1��str2��ʱӵ����ͬ�ĵ�ַ��,����str1==str2���Ϊtrue.
����3
1.public static void main(String[] args) {
2. String str1 = "hello";
3. String str2 = "hel" + "lo";//�ַ��������ڱ���ʱ���Ѿ�������ַ�����ƴ��,���Դ˴��ȼ��� String str2= "hello";
4. String str3 = new String("hel") + "lo";
5. String str4 = new String("hel") + new String("lo");
6.
7. //true
8. System.out.println(str1 == str2);
9. //false
10. System.out.println(str3 == str1);
11. //false
12. System.out.println(str1 == str4);
13. //false
14. System.out.println(str3 == str4);
15.}
��������str1��str2,str3�ıȽ�:

��ʱ����str2�����ǻᷢ���������ַ������������,���������һ���ص�������ڱ���ʱ�ھ��Ѿ�ȷ����,���Դ�ʱ��������ַ���������ӵĻ��͵ȼ���ƴ�Ӻ���ַ���,��ôstr1==str2���Ľ����Ϊtrue
��������str3,��ʱ��һ��new String�����һ���ַ�������,���ڴ��п��Կ�����ʱString����������hel�ַ���,�ڳ������в�û��,����볣������,Ȼ���ַ�������loҲû��,Ҳ�Ž�ȥ,���ʱ���ϵĶ���ָ�����ص��е�hel
���ǵĴ���Ϊ���ߵ�ƴ��,��ô�ͻ��ڶ��Ͽ���һ���µ��ڴ�ȥ�洢����ƴ�Ӻ�����ַ���hello,Ȼ�������ƴ�ӵĶ���ĵ�ַ�������ǵ�str3����,����Ȼ���Ǹ�str1��ȫ��һ���ĵ�ַ,��������str1==str3��ֵΪfalse
������str1��str4�ıȽ�:
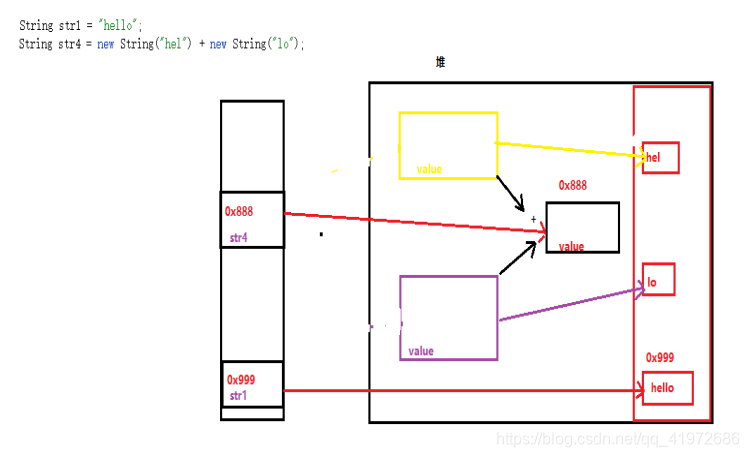
ͬ�����ǿ��Կ�����������ͬ�ĵ�ַ,�������ս��Ϊfalse
����4
1.public static void main(String[] args) {
2. String str1 = "hello";
3. String str2 = "world";
4. //st1�DZ���,�����ڳ�������ʱ��֪������洢������
5. String str3 = str1 + "world";
6. //�����ַ�����������ڱ���ʱ�ھ��Ѿ�ȷ����,���Եȼ�Ϊhelloworld
7. String str4 = "hello" + "world";
8. String str5 = "helloworld";
9. String str6=str1+str2;
10. //false
11. System.out.println(str3 == str5);
12. //true
13. System.out.println(str4 == str5);
14. //false
15. System.out.println(str5==str6);
16. }
��ʱ���ǿ��Կ���str3����һ�������ͳ������,������Ҫע��,str1�DZ���,������ֻ��������ʱ��֪������洢����ʲô���������DZ���ʱ�ھ��Ѿ�ȷ����,����str3==str5Ϊfalse��
Str4���������������,�������ڱ����ʱ����Ѿ�ȷ����,����str4�ȼ���str5,��str4==str5Ϊtrue
Str6ͬ��Ϊ�����������,������ֻ��������ʱ��֪������洢����ʲô,����str5str6, str6str4��Ϊfalse.
�ܽ�
String��ʹ��==�Ƚϵ�ʱ��ȽϵIJ��������ַ��������Ƿ����,���Ƚϵ��������������͵�ַ���Ƿ���ͬ,Ҳ�����ж������������Ƿ�ָ������ͬ�Ķ���,
�ж��ַ��������Ƿ����
���Ҫ�ж��ַ����������Ƿ����,��ʱ����Ҫʹ��equals�ؼ���
������������бȽ�
String str1 = new String("Hello");
String str2 = new String("Hello");
System.out.println(str1.equals(str2));
// System.out.println(str2.equals(str1)); // ��������дҲ��
// ִ�н��
true
�ַ���������������бȽ�
������Ҫ�Ƚ� str �� ��Hello�� �����ַ����Ƿ����, ���Ǹ������д��?
String str = new String("Hello");
// ��ʽһ
System.out.println(str.equals("Hello"));
// ��ʽ��
System.out.println("Hello".equals(str));
������Ĵ�����, ���ַ�ʽ������?
���Ǹ��Ƽ�ʹ�� "��ʽ��". һ�� str �� null, ��ʽһ�Ĵ�����׳���ָ���쳣, ����ʽ������.����:
String str = null;
// ��ʽһ
System.out.println(str.equals("Hello")); // ִ�н���׳� java.lang.NullPointerException �쳣
// ��ʽ��
System.out.println("Hello".equals(str)); // ִ�н�� false
�����ַ������ɱ�
�ַ�����һ�ֲ��ɱ����. �������ݲ��ɸı�.
String ����ڲ�ʵ��Ҳ�ǻ��� char[] ��ʵ�ֵ�, �������char[]������˽�е��ұ�final�����ε�����,String �ಢû���ṩ set ����֮����������char���͵��ַ�����.
����ԭ������˵�ַ�����һ�ֲ��ɱ�Ķ���,ÿ����һ���µ��ַ���������Ҫ���ַ��������ص������¿����ڴ�洢.
���������������Ĵ���:
String str = "hello" ;
str = str + " world" ;
str += "!!!" ;
System.out.println(str);
// ִ�н��
hello world!!!
���� += �����IJ���, �����Ϻ�������ԭ��ַ�����ַ���, ��ʵ����. �ڴ�仯����:
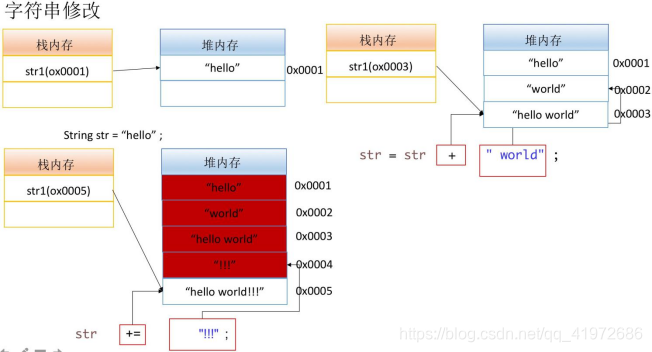
+= ֮�� str ��ӡ�Ľ����ȷ�DZ���, ����������str���õ�һ��ָ��Ķ���hello���ĵ�ַ��ԭ�ط���ƴ��, ����ÿ��ƴ����ɺ��Ҫ�ڳ������п�����ʱ�ڴ�ȥ�洢��ƴ�ӵ���ʱ����.��Ϊÿ���ַ������Dz��ɱ��,�൱������������������Ļ�ÿ��ƴ����ɺ�ʵ���϶���һ���µĶ���,�µĶ���ÿ�ΰ����洢�ڳ�������,str��������ָ�����һ����ʱ����.
��ô��������Ҫƴ��100��,��������Ĵ���,��ô�ͻ��ڶ��ڴ��е��ַ��������ز���99����ʱ����,���ַ����Dz���ȡ�ġ������Ĵ����Ժ�����Ҫ��������Ŀ����
1.public static void main(String[] args) {
2. String str1 = "abc";
3. for(int i = 0;i <= 100;i++) {
4. //Ҫ����99����ʱ����
5. str1 += i;
6. }
7. System.out.println(str1);
7.}
��ô������ѭ���н���ƴ�Ӳ���������ʱ����,����Ч�ʵ����,���Ǹ���������?
��ʱ��Ҫ�õ�
StringBuffer��StringBuilder������������ѭ��������ƴ�ӵ�����һ������(���߳�ʹ��StringBuilder,���߳�ʹ��StringBuffer),ʹ�����߹��е�append��������ƴ��,append������ƴ���Dz��������ʱ������,����������String��StringBuilder�� ����һ���л������ϸ���,��ҿ���ֱ��ͨ��Ŀ¼������ת,�ۿ����.
��������,���ǿ����˽,�ַ���������Ϊ�ײ�Դ��ʵ�ֵ�����,���Dz��ɱ��,ÿ�����������µ��ַ���ԭ�����Dz�����ԭ�ַ����Ͻ����ı䶯��,�����ڶ��ڴ��ϵ��ַ����������д����µ��ڴ����洢�䶯���ַ���,����java�еķ�����������һ����,��Ȼ��������Ҳ����ϸȥ���ⷴ��,�������Ǿ��������˽��·���,�Լ����ͨ�������������ַ������ɱ���һ����:
��������ַ������ɱ�
��������֮ǰ��һ�δ���:
֮ǰ�����뽫str1�ġ�Hello���ij�"hello"��ô������?
�����취:����ԭ�ַ���, �����µ��ַ���
String str = "Hello";
str = "h" + str.substring(1);
System.out.println(str);
// ִ�н��
hello
��ô���÷������ô����?
ʹ�� "����" �����IJ��������ƻ���װ, ����һ�����ڲ��� private ��Ա
IDEA �� ctrl + ��� ��ת�� String ��Ķ���, ���Կ����ڲ�������һ�� char[] , �������ַ���������.��private������,���Ǵ�ʱString���в�û���ṩ����������set����.

��������:
public static void main(String[] args) {
String str1 = "abc";
//Class����
Class c1 = String.class;
//getDeclaredField�������ܻ��׳�NoSuchFieldException�쳣,��Ҫ������
try {
// ��ȡ String ���е� value �ֶ�. ��� value �� String Դ���е� value ��ƥ���.
Field field = c1.getDeclaredField("value");
// ������ֶεķ���������Ϊ true
field.setAccessible(true);
//get�������ܻ��׳�IllegalAccessException�쳣,��Ҫ����.
try {
// �� str1 �е� value ���Ի�ȡ��.
char[] value = (char[]) field.get(str1);
//����ӡ�»�ȡ����value���Է����ǡ�a,b,c��
System.out.println(Arrays.toString(value));
//��ӡ����ǰ��str1��ֵ,Ϊabc
System.out.println(str1);
// �� value ��ֵ
value[0]='G';
//��ӡ�ĺ��str1��ֵ,ΪGbc
System.out.println(str1);
} catch (IllegalAccessException e) {
e.printStackTrace();
}
} catch (NoSuchFieldException e) {
e.printStackTrace();
}
}
�ַ����ַ���
�ַ����ڲ�����һ���ַ�����,String ���Ժ� char[] �ת��.
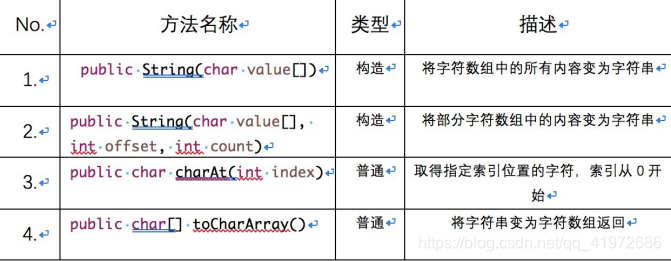
����ʾ��1:��ȡָ��λ�õ��ַ�
String str = "hello" ;
System.out.println(str.charAt(0)); // �±�� 0 ��ʼ
// ִ�н��
h
System.out.println(str.charAt(10));
// ִ�н����������±귶Χ,���� StringIndexOutOfBoundsException �쳣
����ʾ��2:���ַ������������ݱ�Ϊ�ַ����������
1.char[] value = {'a', 'b', 'c', 'd'};
2.String str = new String(value);
//������Ϊabcd
3.System.out.println(str);
����ʾ��3: ���ַ����鲿�����ݱ�Ϊ�ַ����������
1.char[] val = {'a', 'b', 'c', 'd'};
2.String str1 = new String(value, 1, 3);
3.//������Ϊbcd
4.System.out.println(str1);
offetΪƫ����,�Ǽ�����ĸ��±꿪ʼ(�±��0��ʼ����),����Ϊ1���Ǵӵڶ�������Ԫ�ؿ�ʼ,countΪ����Ҫ�ĸ���
�����ʱ��������������Ԫ�ػ���offset���������鳤��-1,��ô�ᷢ��StringIndexOutOfBoundsException�쳣
����ʾ��4: �ַ������ַ������ת��
String str = "helloworld" ;
// ���ַ�����Ϊ�ַ�����
char[] data = str.toCharArray() ;
for (int i = 0; i < data.length; i++) {
System.out.print(data[i]+" ");
}
С��ϰ:�ַ���������
����:��ʹ��toCharArray�������ַ���ת��Ϊ�ַ�����,Ȼ���ٽ�char��������ת��Ϊ�ַ�������(�������ַ�������).
public static String reverse(String string) {
//�ַ���תΪ����
char[] chars = string.toCharArray();
int i = 0;
int j = chars.length-1;
while (i < j) {
char tmp = chars[i];
chars[i] = chars[j];
chars[j] = tmp;
i++;
j--;
}
//����ת��Ϊ�ַ���(���ַ���)
//return new String(chars);
//return String.copyValueOf(chars);
return String.valueOf(chars);
}
�ֽ����ַ���
�ֽڳ��������ݴ����Լ�����ת���Ĵ���֮��,String Ҳ�ܷ���ĺ� byte[] �ת��.

����ʾ��1: �������ֽ�����ת��Ϊ�ַ���
ע�⽫�ֽ�����ת��Ϊ�ַ���ʱ,�ǰ���unicode��������ת����,����97���������unicode���ж�Ӧa�����ĸ
1.byte[] bytes={97,98,99,100,101,102};
2.String str=new String(bytes);
3.//������Ϊabcdef
4.System.out.println(str);
����ʾ��2: �������ֽ��������ݱ�Ϊ�ַ���
1.byte[] bytes1={97,98,99,100,101,102};
2.String str2=new String(bytes1,1,3);
3.//������Ϊbcd
4.System.out.println(str2);
����ʾ��3: ���ַ������ֽ�����ķ�ʽ����
1.String string="abcde";
2.byte[] bytes2=string.getBytes();
3.//������Ϊ[97, 98, 99, 100, 101]
4.System.out.println(Arrays.toString(bytes2));
����ʾ��4:����ת������
���1 ���ַ���ΪӢ��
String str3 = "gaobo";
try {
byte[] bytes3 = str3.getBytes("gbk");
System.out.println(Arrays.toString(bytes3));
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
//������
[103, 97, 111, 98, 111]
���ַ���ת��Ϊ�ֽ������ʱ��,��ʱ�����ַ���ΪӢ��,�������ñ����ʽ������gbk������utf8,���յ�����������һ����
���2 ���ַ���Ϊ����(�ֱ����ʽ��ͬ�����)
String str3 = "�߲�";
try {
byte[] bytes3 = str3.getBytes("gbk");
System.out.println(Arrays.toString(bytes3));
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
//������
[-72, -33, -78, -87]
���ַ���ת��Ϊ�ֽ������ʱ��,��ʱ�����ַ���Ϊ����,�������ñ����ʽ��ͬ,���յ����������Dz�һ����,���������������,gbk��������Ϊ[-72, -33, -78, -87].
String str3 = "�߲�";
try {
byte[] bytes3 = str3.getBytes("utf8");
System.out.println(Arrays.toString(bytes3));
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
//������
[-23, -85, -104, -27, -11, -102]
�������ʽΪutf8��ʱ��,������Ϊ[-23, -85, -104, -27, -115, -102]
�ܽ�
��ô��ʱʹ�� byte[], ��ʱʹ�� char[] ��?
- byte[] �ǰ� String ����һ���ֽ�һ���ֽڵķ�ʽ����,
�����ʺ������紫��, ���ݴ洢�����ij�����ʹ��. ���ʺ���Զ���������������. - char[] �ǰ� String ����һ���ַ�һ���ַ��ķ�ʽ����,
���ʺ�����ı�����������, �����ǰ������ĵ�ʱ��.
�������: �ı����� vs ����������
һ���ֱ������ַ�ʽ�����ü��±����ܲ��ܿ������������.
������Ķ�, �����ı�����(���� .java �ļ�), ���������, ���Ƕ���������(���� .class �ļ�).
�ַ����������
�ַ����Ƚ�
����ʹ�ù�String���ṩ��equals()����,�÷��������ǿ��Խ������ִ�Сд������жϡ������������֮��,String ��ṩ�����µıȽϲ���:

���ִ�Сд�Ƚ�
String str1 = "hello" ;
String str2 = "Hello" ;
System.out.println(str1.equals(str2));
// ������
false
�����ִ�Сд�Ƚ�
String str1 = "hello" ;
String str2 = "Hello" ;
System.out.println(str1.equalsIgnoreCase(str2));
// ������
true
�Ƚ������ַ�����С��ϵ(conpareTo����)
��String����compareTo()������һ���dz���Ҫ�ķ���,�÷�������һ������,�����ݻ���ݴ�С��ϵ������������:
1.���:����0.
2.��:����������0.
3.����:�������ݴ���0��
����:�۲�conpareTo�Ƚ�
System.out.println("A".compareTo("a")); // -32
System.out.println("a".compareTo("A")); // 32
System.out.println("A".compareTo("A")); // 0
System.out.println("AB".compareTo("AC")); // -1
System.out.println("��".compareTo("��")); //-5456
compareTo()��һ���������ִ�С��ϵ�ķ���,��String��������һ���dz���Ҫ�ķ�����
���ıȽϹ�������:
�ַ����ıȽϴ�С����:�ܽ�������� ���ֵ��� �൱���ж������ַ�����һ���ʵ��ǰ�滹�Ǻ���. �ȱȽϵ�һ���ַ��Ĵ�С(���� unicode ��ֵ���ж�), �������ʤ��, �����αȽϺ������������AB��AC��,һ��ʼ�ȱȽ�A��A,����������ͬ��Ϊ0,�������±�,B��C��unicode���ж�Ӧ�����ֱַ�Ϊ66,67,���Կ�����B��CҪС,���Է��ظ���,�������������Ϊ66-67=-1.
�ַ�������
��һ���������ַ���֮�п����ж�ָ�������Ƿ����,���ڲ��ҷ��������¶���

����ʾ��1:contains����
String str = "helloworld" ;
System.out.println(str.contains("world")); // true
contains�������ж���ʽ�Ǵ�JDK1.5֮��ʼ�ӵ�,��JDK1.5��ǰҪ��ʵ����֮���ƵĹ���,�ͱ��������indexOf()������ɡ�
����contains������Դ��:

�ײ���ʵ����index����
����ʾ��2:indexOf(String str)����
String str = "helloworld" ;
System.out.println(str.indexOf("world")); // ���Ϊ5,w��ʼ������System.out.println(str.indexOf("bit")); // ���Ϊ-1,û�в鵽
if (str.indexOf("hello") != -1) {
System.out.println("���Բ鵽ָ���ַ���!");
}
����ʾ��3:indexOf(String str,int fromIndex)����
fromIndex�Ǵ�ǰ����ȷ����λ��,����5���Ǵ�ǰ�������±�Ϊ5����ĸ,��˼���Ǵ������ĸ��ʼ�����Ƿ����str����ַ���,�з�������ַ����ĵ�һ����ĸ,û�з���-1.
String str = "helloworld" ;
//���Ϊ5
System.out.println(str.indexOf("world",5));
//���Ϊ-1
System.out.println(str.indexOf("world",6));
����ʾ��4:lastIndexOf(String str)����
lastIndexOf������Ȼ�ǴӺ��濪ʼ��ǰ����û��world�������,�����,�������ֵ�ʱ���Ƿ���world���������w���ڵ��±�,û�з���-1
String str = "helloworld" ;
//���Ϊ5
System.out.println(str.lastIndexOf("world"));
����ʾ��5:lastIndexOf(String str,int fromIndex)����
String str = "ababcfacd" ;
//���Ϊ2
System.out.println(str.lastIndexOf("ab",4));
�˶δ����൱�ڴ��±�Ϊ4������ĸ��ʼ�Ӻ���ǰѰ���Ƿ����ab,�����,ֱ�ӷ���2,û�з���-1.��ʱ��c��ʼ��ǰѰ��ab,�ҵ����Ժص�һ�γ���ab��a��ĸ���±�
����ʾ��6:startsWith(String prefix)����
String str = "ababcfacd" ;
//���Ϊtrue
System.out.println(str.startsWith("ab"));
����ʾ��7:startsWith(String prefix,int toffset)����
String str = "ababcfacd" ;
//���Ϊfalse
System.out.println(str.startsWith("ab",4));
����ʾ��8:endsWith����
String str = "ababcfacd" ;
//���Ϊfalse
System.out.println(str.endsWith("ab"));
�ַ����滻����
ʹ��һ��ָ�����µ��ַ����滻�����е��ַ�������,���õķ�������:
����ʾ��1:replaceAll����
String str = "helloworld" ;
//���Ϊhe__owor_d
System.out.println(str.replaceAll("l", "_"));
����ʾ��2:replaceFirst����
String str = "helloworld" ;
//���Ϊhe_loworld
System.out.println(str.replaceFirst("l", "_"));
����ʾ��3::replace����
String str = "helloworld" ;
//���Ϊhe__owor_d
System.out.println(str.replace("l", "_"));
���Է���replace������replaceAll������Ч��һ��
������replace������Դ���:

���Կ���replace�����ĵײ�����еIJ�����CharSequence����,���������Լ����ε�ʱ����string����,����Ϊʲô��?
��:����Ϊ����������ת��,String��ʵ����CharSequence����ӿ�,����ͼ��ʾ:

ע������:�����ַ����Dz��ɱ����, �滻���ĵ�ǰ�ַ���, ���Dz���һ���µ��ַ���
�ַ������(�õķdz���,��Ҫ��ע��)
���Խ�һ���������ַ�������ָ���ķָ�������Ϊ���ɸ����ַ�����
���÷�������:
����ʾ��1:split(String regex)����
split�������ص���һ��String���͵�����,��������β���Ĵ���,�Ժ�ᾭ������
String str = "username=zhangsan&password=123";
//�ԡ�&��������Ž����и�,�и�һ�κ�Ϊusername=zhangsan password=123
String[] strings = str.split("&");
for (int i = 0; i < strings.length; i++) {
//�����Ե�һ���и����ַ��������и�
String[] strings1 = strings[i].split("=");
for (int j = 0; j < strings1.length; j++) {
/*���ս��Ϊ:
username
zhangsan
password
123
*/
System.out.println(strings1[j]);
}
}
����ʾ��2:split(String regex,int limit)����
limit=1˵��ֻ����һ��
String str = "username=zhangsan&password=123";
String[] strings = str.split("&",1);
for (int i = 0; i < strings.length; i++) {
//������Ϊusername=zhangsan&password=123
System.out.println(strings[i]);
}
limit=2˵����Ϊ����
String str = "username=zhangsan&password=123";
String[] strings = str.split("&",2);
for (int i = 0; i < strings.length; i++) {
/*������Ϊ:
username=zhangsan
password=123
*/
System.out.println(strings[i]);
}
������ر��õIJ���. һ��Ҫ�ص�����. ������Щ�����ַ���Ϊ�ָ����������ȷ�з�, ��Ҫ����ת��
����ʾ��3:�������
���1:���ip��ַ����(�����ָ���)
String str = "192.168.1.1" ;
String[] result = str.split("\\.") ;
for(String s: result) {
/*������Ϊ
192
168
1
1
*/
System.out.println(s);
}
��ip��ַ���ֲ�ֵ�ʱ��,������õ��(.)���в�ֵĻ�,��Ҫ����ת��,��һ��ת����ת����,�ڶ���ת���DZ���ת����ŵ�����,��˼�����õ�һ��\��Ϊת�������ʹ��
���2:����ָ����IJ��(ʹ�����ַ���|��)
String str = "java-split#bit";
//��|��Ϊ���ַ�,��-��#�������ָ������в��
String[] strings = str.split("-|#");
for (int i = 0; i < strings.length; i++) {
/*������Ϊ:
java
split
bit
*/
System.out.println(strings[i]);
}
ע������:
�ַ�"
|","*","+�����ü���ת���ַ�,ǰ����ϡ�\"�������"",��ô�͵�д��"\\".
���һ���ַ�����
�ж���ָ���,������"|"��Ϊ���ַ�.
�ַ�����ȡ
��һ���������ַ���֮�н�ȡ���������ݡ����÷�������:

����ʾ��1:substring(int beginIndex)����
String str = "abcdefg";
String str1= str.substring(3);
//������Ϊ:defg
System.out.println(str1);
ע������:
������0��ʼ,3��������Ϊ3����Ӧ���Ǹ�����,Ҳ����d
����ʾ��2:substring(int beginIndex,int endIndex)
String str = "abcdefg";
String str1= str.substring(0,5);
//������Ϊ:abcde
System.out.println(str1);
��0�±꿪ʼ��ȡ,��ȡ��4���±�,������5���±�����Ӧ���ַ�
ע������:
ע��ǰ�պ������д��, substring(0, 5) ��ʾ���� 0 ���±���ַ�, ������ 5 ���±�
������������

trim����
trim ��ȥ���ַ�����ͷ�ͽ�β�Ŀհ��ַ�(
�ո�, ����, �Ʊ�����).
public class string {
public static void main(String[] args) {
String str = " abc de fg ";
//������Ϊ: abc de fg
System.out.println(str);
String str1=str.trim();
//������Ϊ:abc de fg
System.out.println(str1);
}
}
toUpperCase����
public class string {
public static void main(String[] args) {
String str = "abc";
String str1=str.toUpperCase();
//������Ϊ:ABC
System.out.println(str1);
}
}
toLowerCase����
public class string {
public static void main(String[] args) {
String str = "ABabc";
String str1=str.toLowerCase();
//������Ϊ:ababc
System.out.println(str1);
}
}
ע������:toUpperCase������toLowerCase��������������ֻת����ĸ,��ת�������ַ���
intern����(ǰ���Ѿ�����)
concat����(��������,����������)
length����
public class string {
public static void main(String[] args) {
String str = "abc";
int length=str.length();
//������Ϊ:3
System.out.println(length);
}
}
ע������:���鳤��ʹ����������.length����,��String��ʹ�õ���length()����
isEmpty����
public class string {
public static void main(String[] args) {
//����һ�����ַ���
String str = "";
boolean boolean1=str.isEmpty();
//������Ϊ:true
System.out.println(boolean1);
}
}
ע����
���ַ�ʽ������ʾ���ַ���
��һ�ַ�ʽ:String str="",���ַ�ʽ����ָ����ַ�������ʲô��û��.
�ڶ��ַ�ʽ:String str=null,���ַ�ʽ������ָ���κζ���
StringBu?er �� StringBuilder
�������ع���String����ص�:
�κε��ַ�����������String����,����String�ij���һ���������ɸı�,����ı��������,�ı���������õ�ָ����ѡ�
ͨ������String�IJ����Ƚϼ�,��������String�IJ��ɸ�������,Ϊ�˷����ַ�������,�ṩStringBu?er��StringBuilder����
StringBu?er �� StringBuilder �ֹ�������ͬ��,������Ҫ���� StringBu?er
��String��ʹ��"+"�������ַ�������,�������������StringBu?er������Ҫ����Ϊappend()����
ʹ����append��������ƴ�Ӻ�,�²������ַ������ַ��������ؾͲ��������ڴ���,��ֱ����ԭ�ڴ��ϵ��ַ�������ƴ��
����ʾ��
public class string {
public static void main(String[] args) {
//append�������ַ���ƴ������ԭ�ַ��������Ͻ���ƴ�ӵ�,�����������µ��ַ���
StringBuffer stringBuffer=new StringBuffer("abcd");
//������Ϊabcdefg
System.out.println(stringBuffer.append("efg"));
}
}
Ϊʲôappend��������ԭ�ַ����Ͻ���ƴ����?
����append������Դ��:
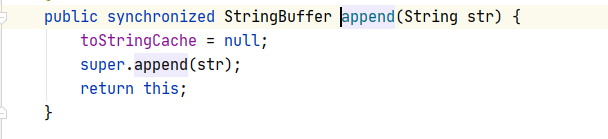
��ص��ǵ�ǰ���������,���Ծ�����ԭ�ַ����Ͻ���ƴ��.
String��StringBuffer(StringBuilder)��ת��
String��StringBu?er(StringBuilder)���ֱ��ת�������Ҫ�뻥��ת��,���Բ�������ԭ��:
String��ΪStringBu?er(StringBuilder):����StringBu?er(StringBuilder)�Ĺ��췽����append()���� (����)
StringBu?er(StringBuilder)��ΪString:����toString()������(����)
�ܽ�
String��StringBuffer,StringBuilder������(������)
-
StringBuffer,StringBuilder������һЩStringû�еķ��� ����reverse����
-
StringBuffer,StringBuilder�ǿɱ��,String�Dz��ɱ�ġ�String��ÿ��ƴ��,��������µĶ���
StringBuffer,StringBuilderÿ�ε�ƴ�Ӷ����ص���this,˵������ԭ�ַ����Ͻ���ƴ�ӵ�.
StringBuffer��StringBuilder����(������)
������StringBuffer,StringBuilder��append����:
StringBuffer���е�append�����DZ�synchronized���ε�,
����ؼ��ֿ��Ա�֤�̵߳İ�ȫ.
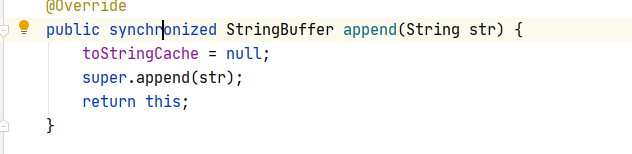

�ܽ�:
StringBuilder��String�����ڵ��߳������
StringBuffer��Ϊ��synchronized�ؼ���,����һ����ֶ��߳�����¡�
һ����˵�Ƕ��̵߳���������ʹ��StringBuilder,ԭ���� synchronized�ؼ����漰����������,ÿ�εĿ���������Ҫ������Դ
StringBu?er����ͬ������,�����̰߳�ȫ����;��StringBuilderδ����ͬ������,�����̲߳���ȫ����
String��StringBuilder����(������)
��Ȼ�������ڵ��̵߳������,��ô�����ߵ�����ʲô������?
1:String��ƴ�ӡ�+���ᱻ�Ż� �Ż�ΪStringBuilder�е�append����,��������:
���ǽ�������δ�����б���:
public class string {
public static void main(String[] args) {
String str="abc";
str=str+"de";
System.out.println(str);
}
}
�����õ�������ͼ��ʾ:
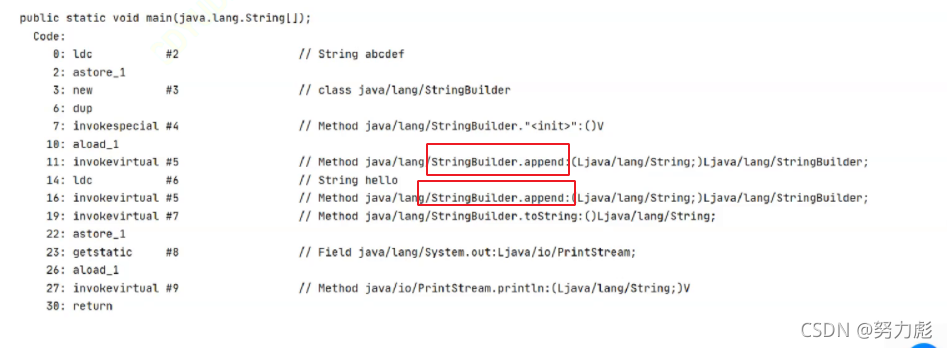
���Կ����ײ��������Ż�,��ô��������������˵��ʵ�ײ������е�ʱ��Ĵ���������ʾ:(�����ִ�з�ʽ��ͼ����һ����)
public class string {
public static void main(String[] args) {
String str="abc";
StringBuilder stringBuilder = new StringBuilder();
stringBuilder.append(str);
stringBuilder.append("hello");
String str1 = stringBuilder.toString();
System.out.println(str1);
}
}
����˵����String��ġ�+����ƴ��,�ײ���Ȼ��StringBuilder���append�������Ż�,��������Ȼ�������������ʱ�ռ�
������֮ǰ������һ������:
public static void main(String[] args) {
String str = "abc";
for(int i = 0;i < 10;i++) {
str += i;
}
System.out.println(str);
}
��������֮ǰ����˵��Ϊ���ڡ�+���ŵ�ƴ��,���»������������ʱ����,��ʱ������ʹ��StringBuilder��append�����������Ż�:
public class string {
public static void main(String[] args) {
String str = "abc";
//��ѭ���ⶨ��StringBuilder����
StringBuilder sb = new StringBuilder();
sb.append(str);
for (int i = 0; i < 10; i++) {
//ѭ���ڲ�ʹ��append����
str = sb.append(i).toString();
}
System.out.println(str);
}
}
2:��ѭ������ ������ʹ��Stringֱ�ӽ���ƴ�� �����������������ʱ����
�����Ż�֮���StringBuilder��������ÿ�ζ���StringBuilder�����ʱ����ѭ������ж���,Ȼ����ѭ���ڲ�ʹ��append����.
��
�ַ��������������Ժ����зdz����õIJ���. ʹ���������dz�����, һ��Ҫʹ������. ָ��ע��ĵ�:
1.�ַ����ıȽ�, ==, equals, compareTo ֮�������.
2.�˽��ַ���������, ��� ���ء� ��˼��.
3.�����ַ������ɱ�
4.split ��Ӧ�ó���
5.StringBu?er �� StringBuilder ����.