Zookeeper 是一个分布式协调服务,可用于服务发现,分布式锁,分布式领导选举,配置管理等。Zookeeper 提供了一个类似于 Linux 文件系统的树形结构(可认为是轻量级的内存文件系统,但只适合存少量信息,完全不适合存储大量文件或者大文件),同时提供了对于每个节点的监控通知机制。
Zookeeper 角色
Zookeeper 集群是一个基于主从复制的高可用集群,每个服务器承担如下三种角色中的一种
Leader
- 一个 Zookeeper 集群同一时间只会有一个实际工作的 Leader,它会发起并维护与各 Follwer及 Observer 间的心跳。
- 所有的写操作必须要通过 Leader 完成再由 Leader 将写操作广播给其它服务器。只要有超过半数节点(不包括 observeer 节点)写入成功,该写请求就会被提交(类 2PC 协议)。
Follower
- 一个 Zookeeper 集群可能同时存在多个 Follower,它会响应 Leader 的心跳,
- Follower 可直接处理并返回客户端的读请求,同时会将写请求转发给 Leader 处理,
- 并且负责在 Leader 处理写请求时对请求进行投票。
Observer
角色与 Follower 类似,但是无投票权。Zookeeper 需保证高可用和强一致性,为了支持更多的客户端,需要增加更多 Server;Server 增多,投票阶段延迟增大,影响性能;引入 Observer,Observer 不参与投票; Observers 接受客户端的连接,并将写请求转发给 leader 节点; 加入更多 Observer 节点,提高伸缩性,同时不影响吞吐率。
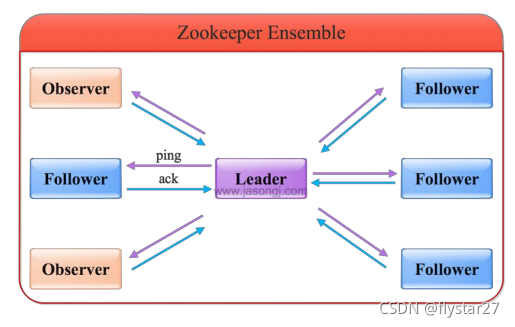
Zookeeper 工作原理(原子广播)
- Zookeeper 的核心是原子广播,这个机制保证了各个 server 之间的同步。实现这个机制的协议叫做 Zab 协议。Zab 协议有两种模式,它们分别是恢复模式和广播模式。
- 当服务启动或者在领导者崩溃后,Zab 就进入了恢复模式,当领导者被选举出来,且大多数 server 的完成了和 leader 的状态同步以后,恢复模式就结束了。
- 状态同步保证了 leader 和 server 具有相同的系统状态
- 一旦 leader 已经和多数的 follower 进行了状态同步后,他就可以开始广播消息了,即进入广播状态。这时候当一个 server 加入 zookeeper 服务中,它会在恢复模式下启动,发现 leader,并和 leader 进行状态同步。待到同步结束,它也参与消息广播。Zookeeper服务一直维持在 Broadcast 状态,直到 leader 崩溃了或者 leader 失去了大部分的followers 支持。
- 广播模式需要保证 proposal 被按顺序处理,因此 zk 采用了递增的事务 id 号(zxid)来保证。所有的提议(proposal)都在被提出的时候加上了 zxid。
- 实现中 zxid 是一个 64 为的数字,它高 32 位是 epoch 用来标识 leader 关系是否改变,每次一个 leader 被选出来,它都会有一个新的 epoch。低 32 位是个递增计数。
- 当 leader 崩溃或者 leader 失去大多数的 follower,这时候 zk 进入恢复模式,恢复模式需要重新选举出一个新的 leader,让所有的 server 都恢复到一个正确的状态。
Znode 四种形式的目录节点
- PERSISTENT:持久的节点。
- EPHEMERAL:暂时的节点。
- PERSISTENT_SEQUENTIAL:持久化顺序编号目录节点。
- EPHEMERAL_SEQUENTIAL:暂时化顺序编号目录节点。
ZooKeeper 安装和使用
- 使用 Docker 下载 ZooKeeper
docker pull zookeeper:3.5.8
- 运行 ZooKeeper
docker run -d --name zookeeper -p 2181:2181 zookeeper:3.5.8
- 连接 ZooKeeper 服务
先使用docker ps查看 ZooKeeper 的 ContainerID,然后使用docker exec -it ContainerID /bin/bash命令进入容器中。
进入 bin 目录,然后通过./zkCli.sh -server 127.0.0.1:2181命令连接ZooKeeper 服务
root@eaf70fc620cb:/apache-zookeeper-3.5.8-bin# cd bin
成功连接 ZooKeeper 服务后页面
常用命令
可通过 help 命令查看 ZooKeeper 常用命令
- 创建节点(create 命令)
通过create命令在根目录创建了 node1 节点,与它关联的字符串是"node1"
[zk: 127.0.0.1:2181(CONNECTED) 34] create /node1 “node1”
通过 create 命令在根目录创建了 node1 节点,与它关联的内容是数字 123
[zk: 127.0.0.1:2181(CONNECTED) 1] create /node1/node1.1 123
Created /node1/node1.1
- 更新节点数据内容(set 命令)
[zk: 127.0.0.1:2181(CONNECTED) 11] set /node1 "set node1"
- 获取节点的数据(get 命令)
get命令可以获取指定节点的数据内容和节点的状态,可以看出我们通过set命令已经将节点数据内容改为 “set node1”。
set node1
cZxid = 0x47
ctime = Sun Jan 20 10:22:59 CST 2019
mZxid = 0x4b
mtime = Sun Jan 20 10:41:10 CST 2019
pZxid = 0x4a
cversion = 1
dataVersion = 1
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 9
numChildren = 1
- 查看某个目录下的子节点(ls 命令)
通过ls命令查看根目录下的节点
[zk: 127.0.0.1:2181(CONNECTED) 37] ls /
[dubbo, ZooKeeper, node1]
通过 ls 命令查看 node1 目录下的节点
[zk: 127.0.0.1:2181(CONNECTED) 5] ls /node1
[node1.1]
ZooKeeper 中的 ls 命令和 linux 命令中的 ls 类似, 这个命令将列出绝对路径 path 下的所有子节点信息(列出 1 级,并不递归)
- 查看节点状态(stat 命令)
通过stat命令查看节点状态
[zk: 127.0.0.1:2181(CONNECTED) 10] stat /node1
cZxid = 0x47
ctime = Sun Jan 20 10:22:59 CST 2019
mZxid = 0x47
mtime = Sun Jan 20 10:22:59 CST 2019
pZxid = 0x4a
cversion = 1
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 11
numChildren = 1
- 查看节点信息和状态(ls2 命令)
ls2命令更像是ls命令和stat命令的结合。ls2命令返回的信息包括 2 部分:
- 子节点列表
- 当前节点的 stat 信息。
[zk: 127.0.0.1:2181(CONNECTED) 7] ls2 /node1
[node1.1]
cZxid = 0x47
ctime = Sun Jan 20 10:22:59 CST 2019
mZxid = 0x47
mtime = Sun Jan 20 10:22:59 CST 2019
pZxid = 0x4a
cversion = 1
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 11
numChildren = 1
- 删除节点(delete 命令)
这个命令很简单,但是需要注意的一点是如果你要删除某一个节点,那么这个节点必须无子节点才行。
[zk: 127.0.0.1:2181(CONNECTED) 3] delete /node1/node1.1