����Ŀ¼
1����ʲô
�� Java ��,�̲߳�����һ���ص�,��ƪ����˵�� JUC Ҳ�ǹ����̵߳ġ�JUC���� java.util .concurrent ���߰��ļ�ơ�����һ�������̵߳Ĺ��߰�,JDK1.5 ��ʼ���ֵġ�
1.1 �������߳�
����(Process) �Ǽ�����еij������ij���ݼ����ϵ�һ�����л,��ϵͳ������Դ����͵��ȵĻ�����λ,�Dz���ϵͳ�ṹ�Ļ����� �ڵ��������߳���Ƶļ�����ṹ��,�������̵߳�������������ָ����ݼ�����֯��ʽ������,�����dz����ʵ�塣�Ǽ�����еij������ij���ݼ����ϵ�һ�����л,��ϵͳ������Դ����͵��ȵĻ�����λ,�Dz���ϵͳ�ṹ�Ļ�����������ָ����ݼ�����֯��ʽ������,�����dz����ʵ�塣
�߳�(thread) �Dz���ϵͳ�ܹ�����������ȵ���С��λ�����������ڽ���֮��,�ǽ����е�ʵ��������λ��һ���߳�ָ���ǽ�����һ����һ˳��Ŀ�����,һ�������п��Բ�������߳�,ÿ���̲߳���ִ�в�ͬ������
�ܽ���˵:
����:ָ��ϵͳ���������е�һ��Ӧ�ó���;����һ�����о��ǽ���;���̡�
����Դ�������С��λ��
�߳�:ϵͳ���䴦����ʱ����Դ�Ļ�����Ԫ,����˵����֮�ڶ���ִ�е�һ��
��Ԫִ�������̡߳�������ִ�е���С��λ��
1.2 �̵߳�״̬
1���½�
2��������
3������
4������
5������
1.2.1 wait/sleep ������
(1)sleep �� Thread �ľ�̬����,wait �� Object �ķ���,�κζ���ʵ�����ܵ��á�
(2)sleep �����ͷ���,��Ҳ����Ҫռ������wait ���ͷ���,����������ǰ���ǵ�ǰ�߳�ռ����(������Ҫ�� synchronized ��)��
(3)���Ƕ����Ա� interrupted �����жϡ�
1.3 �����벢��
1.3.1 ����ģʽ
���б�ʾ��������һһ���Ⱥ�˳����С�������ζ�ű�����װ��һ��������������,ֻ�����͵���,����ж�����,����ֻ���������������������,���ܽ�����һ�����衣������һ��ֻ��ȡ��һ������,��ִ�����������
1.3.2 ����ģʽ
������ζ�ſ���ͬʱȡ�ö������,��ͬʱȥִ����ȡ�õ���Щ������ģʽ�൱�ڽ�������һ������,���ֳ��˶����̶���,���Բ���������������еij��ȡ����е�Ч�ʴӴ�������ǿ�����ڶ����/���̴߳���,��Ӳ���Ƕ����������ڶ�� CPU��
1.3.3 ����
����(concurrent)ָ���Ƕ���������ͬʱ���е�����,��ϸ�����Ƕ���̿�****��ͬʱ���л��߶�ָ�����ͬʱ���������ⲻ���ص�,������������ʱ��Ҳ����ȥ�����������Ƿ�ȷ,�������ص���������һ������, �����������Ƕ����ͬʱ���е���������ʵ����,���ڵ����� CPU ��˵,ͬһʱ��ֻ������һ���̡߳�����,�����"ͬʱ����"��ʾ�IJ������ͬһʱ���ж���߳����е�����,���Dz��еĸ���,�����ṩһ�ֹ������û������������ͬʱ����������,��ʵ������Щ�����еĽ��̲���һֱ��ռ CPU ��,����ִ��һ��ͣһ�ᡣ
Ҫ���������,ͨ���ǽ�������ֽ�ɶ��С����, ���ڲ���ϵͳ�Խ��̵ĵ����������,�����зֳɶ��С�����,���ܻ����һС����ִ�С�����ܻ����һЩ����:
? ���ܳ���һ��С����ִ���˶��,��û��ʼ�¸�������������ʱһ�����ö��л����Ƶ����ݽṹ����Ÿ���С����ijɹ�
? ���ܳ��ֻ�û���õ�һ����ִ�еڶ����Ŀ��ܡ���ʱ,һ����ö�·���û��첽�ķ�ʽ,����ֻ�����ò������¼�֪ͨ��ִ��ij������
? ���Զ����/���̵߳ķ�ʽ����ִ����ЩС����Ҳ���Ե�����/���߳�ִ����ЩС����,��ʱ�ܿ���Ҫ��϶�·���ò��ܴﵽ�ϸߵ�Ч��
1.3.4 ��
**����:**ͬһʱ�̶���߳��ڷ���ͬһ����Դ,����̶߳�һ����
����:������Ʊ ������ɱ��
**����:**�����һ��ִ��,֮���ٻ���
����:�ݷ�����,��ˮ����ˮ,һ��˺���ϵ���Ͱ��
1.4 �ܳ�
�ܳ�(monitor)�DZ�֤��ͬһʱ��ֻ��һ�������ڹܳ��ڻ,���ܳ��ڶ���IJ�����ͬһʱ��ֻ��һ�����̵���(�ɱ�����ʵ��).�������������ܱ�֤��������Ƶ�˳��ִ��JVM ��ͬ���ǻ��ڽ�����˳��ܳ�(monitor)����ʵ�ֵ�,ÿ��������һ���ܳ�(monitor)����,�ܳ�(monitor)������ java ����һͬ����������ִ���߳�����Ҫ���й̶ܳ���,Ȼ�����ִ�з���,���������֮����ͷŹܳ�,������ִ��ʱ�����йܳ�,�����߳����ٻ�ȡͬһ���ܳ�
1.5 �û��̺߳��ػ��߳�
�û��߳�:ƽʱ�õ�����ͨ�߳�,�Զ����߳�
�ػ��߳�:�����ں�̨,��һ��������߳�,������������
�����߳̽�����,�û��̻߳�������*,JVM ���
���û���û��߳������ػ��߳�,JVM ����
2��Lock�ӿ�
2.1 Synchronized�ؼ���
synchronized �� Java �еĹؼ���,��һ��ͬ�����������εĶ��������¼���:
1.����һ�������,�����εĴ�����Ϊͬ������,�����õķ�Χ�Ǵ�����{}�������Ĵ���,���õĶ����ǵ�����������Ķ���;
2.����һ������,�����εķ�����Ϊͬ������,�����õķ�Χ����������,���õĶ����ǵ�����������Ķ���;
��Ȼ����ʹ�� synchronized �����巽��,�� synchronized �������ڷ��������һ����,���,synchronized �ؼ��ֲ��ܱ��̳С�����ڸ����е�ij������ʹ���� synchronized �ؼ���,���������и������������,�������е��������Ĭ������²�����ͬ����,��������ʽ�����������������м���synchronized �ؼ��ֲſ��ԡ���Ȼ,��������������е��ø�������Ӧ�ķ���,������Ȼ�����еķ�������ͬ����,����������˸����ͬ������,���,����ķ���Ҳ���൱��ͬ���ˡ�
3.��һ����̬�ķ���,�����õķ�Χ��������̬����,���õĶ��������������ж���;
4.��һ����,�����õķ�Χ�� synchronized ���������������IJ���,�������Ķ��������������ж���
��Ʊ����
class Ticket{
private int numer=30;
public synchronized void sale(){
if (numer>0){
System.out.println(Thread.currentThread().getName()+":����:"+(numer--)+"ʣ��:"+numer);
}
}
}
���һ������鱻 synchronized ������,��һ���̻߳�ȡ�˶�Ӧ����,��ִ�иô����ʱ,�����̱߳�ֻ��һֱ�ȴ�,�ȴ���ȡ�����߳��ͷ���,�������ȡ�����߳��ͷ���ֻ�����������:
(1) ��ȡ�����߳�ִ�����˸ô����,Ȼ���߳��ͷŶ�����ռ��;
(2)�߳�ִ�з����쳣,��ʱ JVM �����߳��Զ��ͷ�����
��ô��������ȡ�����߳�����Ҫ�ȴ� IO ��������ԭ��(������� sleep����)��������,������û���ͷ���,�����̱߳�ֻ�ܸɰͰ͵صȴ�,����һ��,���ôӰ�����ִ��Ч�ʡ���˾���Ҫ��һ�ֻ��ƿ��Բ��õȴ����߳�һֱ�����صȴ���ȥ(����ֻ�ȴ�һ����ʱ������ܹ���Ӧ�ж�),ͨ�� Lock �Ϳ��쵽��
2.2 Lock
Lock ��ʵ���ṩ�˱�ʹ��ͬ�������������Ի�õĸ��㷺�����������������������Ľṹ,���ܾ��зdz���ͬ������,���ҿ���֧�ֶ����������������Lock �ṩ�˱� synchronized ����Ĺ��ܡ�
��Ʊ����:
class LTicket{
private int numer=20;
private final ReentrantLock lock=new ReentrantLock();
public void sale(){
lock.lock();
try {
if (numer>0){
System.out.println(Thread.currentThread().getName()+":����:"+(numer--)+"ʣ��:"+numer);
}
}finally {
lock.unlock();
}
}
2.3 newCondition
�ؼ��� synchronized �� wait()/notify()����������һ��ʹ�ÿ���ʵ�ֵȴ�/֪ͨģʽ, Lock ���� newContition()�������� Condition ����,Condition ��Ҳ����ʵ�ֵȴ�/֪ͨģʽ���� notify()֪ͨʱ,JVM ���������ij���ȴ����߳�, ʹ�� Condition ����Խ���ѡ����֪ͨ, Condition �Ƚϳ��õ���������:
1.await()��ʹ��ǰ�̵߳ȴ�,ͬʱ���ͷ���,�������̵߳��� signal()ʱ,�̻߳����»����������ִ�С�
2.signal()���ڻ���һ���ȴ����̡߳�
ע��:�ڵ��� Condition �� await()/signal()����ǰ,Ҳ��Ҫ�̳߳�����ص� Lock ��,���� await()���̻߳��ͷ������,�� singal()���ú��ӵ�ǰCondition ����ĵȴ�������,���� һ���߳�,���ѵ��̳߳��Ի����, һ��������ɹ��ͼ���ִ�С�
2.4 ��
Lock �� synchronized �����¼��㲻ͬ:
(1)Lock ��һ���ӿ�,�� synchronized �� Java �еĹؼ���,synchronized �����õ�����ʵ��;
(2)synchronized �ڷ����쳣ʱ,���Զ��ͷ��߳�ռ�е���,��˲��ᵼ������������;�� Lock �ڷ����쳣ʱ,���û������ͨ�� unLock()ȥ�ͷ���,��ܿ��������������,���ʹ�� Lock ʱ��Ҫ�� finally �����ͷ���;
(3)Lock �����õȴ������߳���Ӧ�ж�,�� synchronized ȴ����,ʹ��synchronized ʱ,�ȴ����̻߳�һֱ�ȴ���ȥ,���ܹ���Ӧ�ж�;
(4)ͨ�� Lock ����֪����û�гɹ���ȡ��,�� synchronized ȴ���쵽��
(5)Lock ������߶���߳̽��ж�������Ч�ʡ�����������˵,���������Դ������,���ߵ������Dz���,����������Դ�dz�����ʱ(���д����߳�ͬʱ����),��ʱ Lock ������ҪԶԶ����synchronized��
3���̼߳�ͨ��
�̼߳�ͨ�ŵ�ģ��������:�����ڴ����Ϣ����,���·�ʽ���ǻ���������ģ����ʵ�ֵġ�����������һ�����Գ�������Ŀ������
�����������߳�,һ���̶߳Ե�ǰ��ֵ�� 1,��һ���̶߳Ե�ǰ��ֵ�� 1,Ҫ��
���̼߳�ͨ��
3.1 synchronized����
class Share {
private int numer = 0;
public synchronized void incr() throws InterruptedException {
while (numer != 0) {
this.wait();
}
numer++;
System.out.println(Thread.currentThread().getName() + "::" + numer);
this.notifyAll();
}
public synchronized void decr() throws InterruptedException {
while (numer != 1) {
this.wait();
}
numer--;
System.out.println(Thread.currentThread().getName() + "::" + numer);
this.notifyAll();
}
}
public class ThreadDemo1 {
public static void main(String[] args) {
Share share = new Share();
new Thread(() -> {
for (int i = 0; i < 10; i++) {
try {
share.incr();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}, "AA").start();
new Thread(() -> {
for (int i = 0; i < 10; i++) {
try {
share.decr();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}, "BB").start();
}
}
3.2 lock����
class Share {
private int numer = 0;
private Lock lock=new ReentrantLock();
private Condition condition=lock.newCondition();
public void incr() throws InterruptedException {
lock.lock();
try {
while (numer != 0) {
condition.await();
}
numer++;
System.out.println(Thread.currentThread().getName() + "::" + numer);
condition.signalAll();
}finally {
lock.unlock();
}
}
public void decr() throws InterruptedException {
lock.lock();
try {
while (numer != 1) {
condition.await();
}
numer--;
System.out.println(Thread.currentThread().getName() + "::" + numer);
condition.signalAll();
}finally {
lock.unlock();
}
}
}
public class ThreadDemo2 {
public static void main(String[] args) {
Share share=new Share();
new Thread(()->{
for (int i=0;i<10;i++){
try {
share.incr();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
},"AA").start();
new Thread(()->{
for (int i=0;i<10;i++){
try {
share.decr();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
},"BB").start();
}
}
3.3 �̼߳䶨�ƻ�ͨ��
����: A �̴߳�ӡ 5 �� ,B �̴߳�ӡ 10 �� ,C �̴߳�ӡ 15 ��C,����
��˳��ѭ�� 10 ��==
class ShareResource{
private int flag=1;
private Lock lock =new ReentrantLock();
private Condition c1=lock.newCondition();
private Condition c2=lock.newCondition();
private Condition c3=lock.newCondition();
public void print5(int loop)throws InterruptedException{
lock.lock();
try {
while (flag!=1){
c1.await();
}
for (int i=1;i<=5;i++){
System.out.println(Thread.currentThread().getName()+"::"+i+":����:"+loop);
}
flag=2;
c2.signal();
} finally {
lock.unlock();
}
}
public void print10(int loop)throws InterruptedException{
lock.lock();
try {
while (flag!=2){
c2.await();
}
for (int i=1;i<=10;i++){
System.out.println(Thread.currentThread().getName()+"::"+i+":����:"+loop);
}
flag=3;
c3.signal();
} finally {
lock.unlock();
}
}
public void print15(int loop)throws InterruptedException{
lock.lock();
try {
while (flag!=3){
c3.await();
}
for (int i=1;i<=15;i++){
System.out.println(Thread.currentThread().getName()+"::"+i+":����:"+loop);
}
flag=1;
c1.signal();
} finally {
lock.unlock();
}
}
}
public class ThreadDemo3 {
public static void main(String[] args) {
ShareResource shareResource=new ShareResource();
new Thread(()->{
for (int i=1;i<=10;i++){
try {
shareResource.print5(i);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
},"AA").start();
new Thread(()->{
for (int i=1;i<=10;i++){
try {
shareResource.print10(i);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
},"BB").start();
new Thread(()->{
for (int i=1;i<=10;i++){
try {
shareResource.print15(i);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
},"CC").start();
}
4�����ϵ��̰߳�ȫ����
(1)ArrayList����һ���̰߳�ȫ�ļ���
public static void main(String[] args) {
List list = new ArrayList();
for (int i = 0; i < 100; i++) {
new Thread(() ->{
list.add(UUID.randomUUID().toString());
System.out.println(list);
}, "�߳�" + i).start();
}
}
�쳣����
java.util.ConcurrentModificationException
����취:
// Vector���
// List<String> list = new Vector<>();
//Collections���
// List<String> list = Collections.synchronizedList(new ArrayList<>());
// CopyOnWriteArrayList���
// List<String> list = new CopyOnWriteArrayList<>();
(2)Hashset����һ���̰߳�ȫ�ļ���
����취:
// Set<String> set = new CopyOnWriteArraySet<>();
(3)HashMap����һ���̰߳�ȫ�ļ���
����취:
Map<String,String> map = new ConcurrentHashMap<>();
for (int i = 0; i <30; i++) {
String key = String.valueOf(i);
new Thread(()->{
//����������
map.put(key,UUID.randomUUID().toString().substring(0,8));
//�Ӽ��ϻ�ȡ����
System.out.println(map);
},String.valueOf(i)).start();
}
}
4.1 Vector
Vector ��ʸ������,���� JDK1.0 �汾���ӵ��ࡣ�̳��� AbstractList,ʵ���� List, RandomAccess, Cloneable ��Щ�ӿڡ� Vector �̳��� AbstractList,ʵ���� List;����,����һ������,֧����ص����ӡ�ɾ�����ġ������ȹ��ܡ� Vector ʵ���� RandmoAccess �ӿ�,���ṩ��������ʹ�����RandmoAccess �� java �������� List ʵ��,Ϊ List �ṩ���ٷ��ʹ��ܵġ���Vector ��,���Ǽ�����ͨ��Ԫ�ص���ſ��ٻ�ȡԪ�ض���;����ǿ���������ʡ� Vector ʵ���� Cloneable �ӿ�,��ʵ�� clone()���������ܱ���¡��
�� ArrayList ��ͬ,Vector �еIJ������̰߳�ȫ�ġ�
�鿴 Vector �� add ����
public synchronized boolean add(E e) {
modCount++;
ensureCapacityHelper(elementCount + 1);
elementData[elementCount++] = e;
return true; }
add ������ synchronized ͬ����,�̰߳�ȫ!���û�в����쳣
4.2 Collections
Collections �ṩ�˷��� synchronizedList ��֤ list ��ͬ���̰߳�ȫ��
�鿴����Դ��
public static <T> List<T> synchronizedList(List<T> list) {
return (list instanceof RandomAccess ?
new SynchronizedRandomAccessList<>(list) :
new SynchronizedList<>(list));
}
4.3 CopyOnWriteArrayList(�ص�)
�������Ƕ� CopyOnWriteArrayList ����ѧϰ,���ص�����:
���൱���̰߳�ȫ�� ArrayList���� ArrayList һ��,���Ǹ��ɱ�����;���Ǻ�ArrayList ��ͬ��ʱ,��������������:
-
�����ʺ��ھ�������������Ӧ�ó���:List ��Сͨ�����ֺ�С,ֻ������Զ���ڿɱ����,��Ҫ�ڱ����ڼ��ֹ�̼߳�ij�ͻ��
-
�����̰߳�ȫ�ġ�
-
��Ϊͨ����Ҫ����������������,���Կɱ����(add()��set() �� remove() �ȵ�)�Ŀ����ܴ�
-
������֧�� hasNext(), next()�Ȳ��ɱ����,����֧�ֿɱ� remove()�Ȳ�����
-
ʹ�õ��������б������ٶȺܿ�,���Ҳ����������̷߳�����ͻ���ڹ��������ʱ,�����������ڲ����������ա�
1. ��ռ��Ч�ʵ�:���ö�д����˼����
2. д�̻߳�ȡ����,����д�߳�����
3. ����˼��:
��������һ����������Ԫ�ص�ʱ��,��ֱ������ǰ��������,�����Ƚ���ǰ�������� Copy,���Ƴ�һ���µ�����,Ȼ���µ�����������Ԫ��,������Ԫ��֮��,�ٽ�ԭ����������ָ���µ���������ʱ����׳���һ���µ�����,Ҳ�������ݲ�һ�µ����⡣���д�̻߳�û���ü�д���ڴ�,�������߳̾ͻ�����������ݡ�
����� CopyOnWriteArrayList ��˼���ԭ�������ǿ���һ�ݡ�
����ӡ���̬���顱�͡��̰߳�ȫ�����������һ����CopyOnWriteArrayList ��ԭ������˵����
����̬���顱����**
���ڲ��и���volatile ���顱(array)���������ݡ��ڡ�����/��/ɾ��������ʱ,�����½�һ������,�������º�����ݿ������½���������,����ٽ������鸳ֵ����volatile ���顱, ����������� CopyOnWriteArrayList ��ԭ��
�������ڡ�����/��/ɾ��������ʱ,�����½�����,�����漰�������ݵ�����,CopyOnWriteArrayList Ч�ʺܵ�;���ǵ���ֻ�ǽ��б������ҵĻ�,Ч�ʱȽϸߡ�
? ���̰߳�ȫ������
ͨ�� volatile �ͻ�������ʵ�ֵġ�
ͨ����volatile ���顱���������ݵġ�һ���̶߳�ȡ volatile ����ʱ,���ܿ��������̶߳Ը� volatile ��������д��;������,ͨ�� volatile �ṩ�ˡ���ȡ���������������µġ�������Ƶı�֤��
ͨ�����������������ݡ��ڡ�����/��/ɾ��������ʱ,���ȡ���ȡ��������,�������֮��,�Ƚ����ݸ��µ���volatile ���顱��,Ȼ���١��ͷŻ�������,�ʹﵽ�˱������ݵ�Ŀ�ġ�
4.4 ��
1.�̰߳�ȫ���̲߳���ȫ����
���������д����̰߳�ȫ���̲߳���ȫ������,��������:
ArrayList ----- Vector
HashMap -----HashTable
�������϶���ͨ�� synchronized �ؼ���ʵ��,Ч�ʽϵ�
2.Collections �������̰߳�ȫ����
3.java.util.concurrent ��������
CopyOnWriteArrayList CopyOnWriteArraySet ����,ͨ����̬�������̰߳�
ȫ�����汣֤�̰߳�ȫ
����**😗*
һ��������������ж�� synchronized ����,ijһ��ʱ����,ֻҪһ���߳�ȥ�������е�һ�� synchronized ������,�������̶߳�ֻ�ܵȴ�,���仰˵,ijһ��ʱ����,ֻ����Ψһһ���߳�ȥ������Щsynchronized ����,�����ǵ�ǰ���� this,��������,�������̶߳����ܽ��뵽��ǰ�����������synchronized ����,�Ӹ���ͨ�������ֺ�ͬ�����ػ������������,����ͬһ������,������̱仯��
synchronized ʵ��ͬ���Ļ���:Java �е�ÿһ����������Ϊ����
�������Ϊ���� 3 ����ʽ��
������ͨͬ������,���ǵ�ǰʵ������
���ھ�̬ͬ������,���ǵ�ǰ��� Class ����
����ͬ��������,���� Synchonized ���������õĶ���
��һ���߳���ͼ����ͬ�������ʱ,�����ȱ���õ���,�˳����׳��쳣ʱ�����ͷ�����Ҳ����˵���һ��ʵ������ķǾ�̬ͬ��������ȡ����,��ʵ������������Ǿ�̬ͬ����������ȴ���ȡ���ķ����ͷ�������ܻ�ȡ��,���DZ��ʵ������ķǾ�̬ͬ��������Ϊ����ʵ������ķǾ�̬ͬ�������õ��Dz�ͬ����,��������ȴ���ʵ�������ѻ�ȡ���ķǾ�̬ͬ�������ͷ����Ϳ��Ի�ȡ�����Լ�������
���еľ�̬ͬ�������õ�Ҳ��ͬһ���������������,����������������ͬ�Ķ���,���Ծ�̬ͬ��������Ǿ�̬ͬ������֮���Dz����о�̬�����ġ�����һ��һ����̬ͬ��������ȡ����,�����ľ�̬ͬ������������ȴ��÷����ͷ�������ܻ�ȡ��,��������ͬһ��ʵ������ľ�̬ͬ������֮��,���Dz�ͬ��ʵ������ľ�̬ͬ������֮��,ֻҪ����ͬһ�����ʵ������!
5�� Callable&Future�ӿ�
5.1 Callable�ӿ�
Ŀǰ����ѧϰ�������ִ����̵߳ķ���-һ����ͨ������ Thread ��,��һ����ͨ��ʹ�� Runnable �����̡߳�����,Runnable ȱ�ٵ�һ�����,���߳���ֹʱ(�� run()���ʱ),������ʹ�̷߳��ؽ����Ϊ��֧�ִ˹���,Java ���ṩ�� Callable �ӿڡ�
��������ѧϰ���Ǵ����̵߳ĵ����ַ�����Callable �ӿ�
Callable �ӿڵ��ص�����(�ص�)
? Ϊ��ʵ�� Runnable,��Ҫʵ�ֲ������κ����ݵ� run()����,������Callable,��Ҫʵ�������ʱ���ؽ���� call()������
? call()�������������쳣,�� run()���ܡ�
? Ϊʵ�� Callable ��������д call ����
? ����ֱ���滻 runnable,��Ϊ Thread ��Ĺ��췽������û�� Callable
5.2 Future �ӿ�
�� call()�������ʱ,�������洢�����߳���֪�Ķ�����,�Ա����߳̿���֪�����̷߳��صĽ����Ϊ��,����ʹ�� Future ����
�� Future ��Ϊ�������Ķ���C��������ʱ��������,�������ᱣ��(һ��Callable ����)��Future �����������߳̿��Ը��ٽ����Լ������̵߳Ľ����һ�ַ�ʽ��Ҫʵ�ִ˽ӿ�,������д 5 �ַ���,�����г�����Ҫ�ķ���,����:
? public boolean cancel(boolean mayInterrupt):����ֹͣ����
�����δ����,����ֹͣ�������������,����� mayInterrupt Ϊ trueʱ�Ż��ж�����
? **public Object get()�׳� InterruptedException,ExecutionException:**���ڻ�ȡ����Ľ����
==����������,�����������ؽ��,���ȴ��������,Ȼ�ؽ����
==? **public boolean isDone():**����������,�� true,���� false���Կ��� Callable �� Future ��������-Callable �� Runnable ����,��Ϊ����װ��Ҫ����һ���߳������е�����,�� Future ���ڴ洢����һ���̻߳�õĽ����ʵ����,future Ҳ������ Runnable һ��ʹ�á�
Ҫ�����߳�,��Ҫ Runnable��Ϊ�˻�ý��,��Ҫ future��
5.3 FutureTask
Java ����о���� FutureTask ����,������ʵ�� Runnable �� Future,������ؽ����ֹ��������һ�� ����ͨ��Ϊ�乹�캯���ṩ Callable ������FutureTask��Ȼ��,�� FutureTask �����ṩ�� Thread �Ĺ��캯���Դ���Thread �������,��ӵ�ʹ�� Callable �����̡߳�
����ԭ��:(�ص�)
�����߳�����Ҫִ�бȽϺ�ʱ�IJ���ʱ,���ֲ����������߳�ʱ,������Щ��ҵ���� Future �����ں�̨���
? �����߳̽�����Ҫʱ,�Ϳ���ͨ�� Future �����ú�̨��ҵ�ļ���������ִ��״̬
? һ�� FutureTask �����ں�ʱ�ļ���,���߳̿���������Լ��������,��ȥ��ȡ�����
? ���ڼ������ʱ���ܼ������;���������δ���,������ get ����
? һ���������,�Ͳ��������¿�ʼ��ȡ������
? get ��������ȡ���ֻ���ڼ������ʱ��ȡ,�����һֱ����ֱ������ת�����״̬,Ȼ��᷵�ؽ�������׳��쳣
? get ֻ����һ��,��� get �����ŵ����
5.4 ʹ�� Callable �� Future
CallableDemo ����
/**
* CallableDemo ����
*/
public class CallableDemo {
/**
* ʵ�� runnable �ӿ�
*/
static class MyThread1 implements Runnable{
/**
* run ����
*/
@Override
public void run() {
try {
System.out.println(Thread.currentThread().getName() + "�߳̽����� run
����");
}catch (Exception e){
e.printStackTrace();
}
}
}
/**
* ʵ�� callable �ӿ�
*/
static class MyThread2 implements Callable{
/**
* call ����
* @return
* @throws Exception
*/
@Override
public Long call() throws Exception {
try {
System.out.println(Thread.currentThread().getName() + "�߳̽����� call
����,��ʼ��˯��");
Thread.sleep(1000);
System.out.println(Thread.currentThread().getName() + "˯����");
}catch (Exception e){
e.printStackTrace();
}
return System.currentTimeMillis();
}
}
public static void main(String[] args) throws Exception{
//���� runable
Runnable runable = new MyThread1();
//���� callable
Callable callable = new MyThread2();
//future-callable
FutureTask<Long> futureTask2 = new FutureTask(callable);
//�̶߳�
new Thread(futureTask2, "�̶߳�").start();
for (int i = 0; i < 10; i++) {
Long result1 = futureTask2.get();
System.out.println(result1);
}
//�߳�һ
new Thread(runable,"�߳�һ").start();
} }
5.5 ��
? �����߳�����Ҫִ�бȽϺ�ʱ�IJ���ʱ,���ֲ����������߳�ʱ,������Щ��ҵ���� Future �����ں�̨���, �����߳̽�����Ҫʱ,�Ϳ���ͨ�� Future�����ú�̨��ҵ�ļ���������ִ��״̬
? һ�� FutureTask �����ں�ʱ�ļ���,���߳̿���������Լ��������,��ȥ��ȡ���
? ���ڼ������ʱ���ܼ������;���������δ���,������ get ������һ���������,�Ͳ��������¿�ʼ��ȡ�����㡣get ��������ȡ���ֻ���ڼ������ʱ��ȡ,�����һֱ����ֱ������ת�����״̬,Ȼ��᷵�ؽ�������׳��쳣��
? ֻ����һ��
6��JUC ��������
JUC ���ṩ�����ֳ��õĸ�����,ͨ����Щ��������ԺܺõĽ���߳���������ʱ Lock ����Ƶ�������������ָ�����Ϊ:
? CountDownLatch: ���ټ���
? CyclicBarrier: ѭ��դ��
? Semaphore: �źŵ�
�������Ƿֱ������ϸ�Ľ��ܺ�ѧϰ
6.1 ���ټ��� CountDownLatch
CountDownLatch ���������һ��������,Ȼ��ͨ�� countDown ���������м� 1 �IJ���,ʹ�� await �����ȴ������������� 0,Ȼ�����ִ�� await ����֮�����䡣
? CountDownLatch ��Ҫ����������,��һ�������̵߳��� await ����ʱ,��Щ�̻߳�����
? �����̵߳��� countDown �����Ὣ�������� 1(���� countDown �������̲߳�������)
? ����������ֵ��Ϊ 0 ʱ,�� await �����������̻߳ᱻ����,����ִ��
����: 6 ��ͬѧ½���뿪���Һ�ֵ��ͬѧ�ſ��Թ��š�
//��ʾ CountDownLatch
public class CountDownLatchDemo {
//6��ͬѧ½���뿪����֮��,�����
public static void main(String[] args) throws InterruptedException {
//����CountDownLatch����,���ó�ʼֵ
CountDownLatch countDownLatch = new CountDownLatch(6);
//6��ͬѧ½���뿪����֮��
for (int i = 1; i <=6; i++) {
new Thread(()->{
System.out.println(Thread.currentThread().getName()+" ��ͬѧ�뿪�˽���");
//���� -1
countDownLatch.countDown();
},String.valueOf(i)).start();
}
//�ȴ�
countDownLatch.await();
System.out.println(Thread.currentThread().getName()+" �����������");
}
}
6.2 ѭ��դ�� CyclicBarrier
CyclicBarrier ��Ӣ�ĵ��ʿ��Կ�����ž���ѭ����������˼,��ʹ����CyclicBarrier �Ĺ��췽����һ��������Ŀ���ϰ���,ÿ��ִ�� CyclicBarrier һ���ϰ������һ,����ﵽ��Ŀ���ϰ���,�Ż�ִ�� cyclicBarrier.await()֮�����䡣���Խ� CyclicBarrier ����Ϊ�� 1 ����
����: ���� 7 ������Ϳ����ٻ�����
//����7������Ϳ����ٻ�����
public class CyclicBarrierDemo {
//�����̶�ֵ
private static final int NUMBER = 7;
public static void main(String[] args) {
//����CyclicBarrier
CyclicBarrier cyclicBarrier =
new CyclicBarrier(NUMBER,()->{
System.out.println("*****����7������Ϳ����ٻ�����");
});
//�����߿��������
for (int i = 1; i <=7; i++) {
new Thread(()->{
try {
System.out.println(Thread.currentThread().getName()+" �������ռ�����");
//�ȴ�
cyclicBarrier.await();
} catch (Exception e) {
e.printStackTrace();
}
},String.valueOf(i)).start();
}
}
}
6.3 �źŵ� Semaphore
Semaphore �Ĺ��췽���д���ĵ�һ������������ź���(���Կ�������̳߳�),ÿ���ź�����ʼ��Ϊһ�����ֻ�ַܷ�һ������֤��ʹ�� acquire �����������֤,release �����ͷ����ɳ���: ����λ, 6 ������ 3 ��ͣ��λ
SemaphoreDemo
//6������,ͣ3����λ
public class SemaphoreDemo {
public static void main(String[] args) {
//����Semaphore,������������
Semaphore semaphore = new Semaphore(3);
//ģ��6������
for (int i = 1; i <=6; i++) {
new Thread(()->{
try {
//��ռ
semaphore.acquire();
System.out.println(Thread.currentThread().getName()+" �����˳�λ");
//�������ͣ��ʱ��
TimeUnit.SECONDS.sleep(new Random().nextInt(5));
System.out.println(Thread.currentThread().getName()+" ------�뿪�˳�λ");
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
//�ͷ�
semaphore.release();
}
},String.valueOf(i)).start();
}
}
}
7�����
7.1 ��ʲô
��ʵ��������һ�ֳ���:�Թ�����Դ�ж���д�IJ���,��д����û�ж�������ôƵ������û��д������ʱ��,����߳�ͬʱ��һ����Դû���κ�����,����Ӧ����������߳�ͬʱ��ȡ������Դ;�������һ���߳���ȥд��Щ������Դ,�Ͳ�Ӧ�����������̶߳Ը���Դ���ж���д�IJ����ˡ�
������ֳ���,JAVA �IJ������ṩ�˶�д�� ReentrantReadWriteLock,����ʾ������,һ���Ƕ�������ص���,��Ϊ������;һ����д��ص���,��Ϊ������
- �߳̽��������ǰ������:
? û�������̵߳�д��
? û��д����, ������д����,�������̺߳ͳ��������߳���ͬһ��(��������)��
- �߳̽���д����ǰ������:
? û�������̵߳Ķ���
? û�������̵߳�д��
����д��������������Ҫ������:
(1)��ƽѡ����:֧�ַǹ�ƽ(Ĭ��)��ƽ������ȡ��ʽ,���������Ƿǹ�ƽ���ڹ�ƽ��
(2)�ؽ���:������д����֧���߳��ؽ��롣
(3)������:��ѭ��ȡд������ȡ�������ͷ�д���Ĵ���,д���ܹ�������Ϊ������
7.2 ReentrantReadWriteLock
ReentrantReadWriteLock �������ṹ
public class ReentrantReadWriteLock implements ReadWriteLock,
java.io.Serializable {
/** ���� */
private final ReentrantReadWriteLock.ReadLock readerLock;
/** � */
private final ReentrantReadWriteLock.WriteLock writerLock;
final Sync sync;
/** ʹ��Ĭ��(�ǹ�ƽ)���������Դ���һ���µ�
ReentrantReadWriteLock */
public ReentrantReadWriteLock() {
this(false);
}
/** ʹ�ø����Ĺ�ƽ���Դ���һ���µ� ReentrantReadWriteLock */
public ReentrantReadWriteLock(boolean fair) {
sync = fair ? new FairSync() : new NonfairSync();
readerLock = new ReadLock(this);
writerLock = new WriteLock(this);
}
/** ���������������� */
public ReentrantReadWriteLock.WriteLock writeLock() { return
writerLock; }
/** �������ڶ�ȡ�������� */
public ReentrantReadWriteLock.ReadLock readLock() { return
readerLock; }
abstract static class Sync extends AbstractQueuedSynchronizer {}
static final class NonfairSync extends Sync {}
static final class FairSync extends Sync {}
public static class ReadLock implements Lock, java.io.Serializable {}
public static class WriteLock implements Lock, java.io.Serializable {}
}
���Կ���,ReentrantReadWriteLock ʵ���� ReadWriteLock �ӿ�,ReadWriteLock �ӿڶ����˻�ȡ������д���Ĺ淶,������Ҫʵ����ȥʵ��;ͬʱ�仹ʵ���� Serializable �ӿ�,��ʾ���Խ������л�,��Դ�����п��Կ��� ReentrantReadWriteLock ʵ�����Լ������л�����
7.3 ������
//��Դ��
class MyCache {
//����map����
private volatile Map<String,Object> map = new HashMap<>();
//�����������
private ReadWriteLock rwLock = new ReentrantReadWriteLock();
//������
public void put(String key,Object value) {
//�����
rwLock.writeLock().lock();
try {
System.out.println(Thread.currentThread().getName()+" �������"+key);
//��ͣһ��
TimeUnit.MICROSECONDS.sleep(300);
//������
map.put(key,value);
System.out.println(Thread.currentThread().getName()+" ���"+key);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
//�ͷ�д��
rwLock.writeLock().unlock();
}
}
//ȡ����
public Object get(String key) {
//���Ӷ���
rwLock.readLock().lock();
Object result = null;
try {
System.out.println(Thread.currentThread().getName()+" ���ڶ�ȡ����"+key);
//��ͣһ��
TimeUnit.MICROSECONDS.sleep(300);
result = map.get(key);
System.out.println(Thread.currentThread().getName()+" ȡ����"+key);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
//�ͷŶ���
rwLock.readLock().unlock();
}
return result;
}
}
public class ReadWriteLockDemo {
public static void main(String[] args) throws InterruptedException {
MyCache myCache = new MyCache();
//�����̷߳�����
for (int i = 1; i <=2; i++) {
final int num = i;
new Thread(()->{
myCache.put(num+"",num+"");
},String.valueOf(i)).start();
}
TimeUnit.MICROSECONDS.sleep(300);
//�����߳�ȡ����
for (int i = 1; i <=2; i++) {
final int num = i;
new Thread(()->{
myCache.get(num+"");
},String.valueOf(i)).start();
}
}
}

7.4 ��
? ���̳߳��ж����������,���̲߳���ȡ��д��(��Ϊ��ȡд����ʱ��,������ֵ�ǰ�Ķ�����ռ��,�����ϻ�ȡʧ��,���ܶ����Dz��DZ���ǰ�̳߳���)��
? ���̳߳���д���������,���߳̿��Լ�����ȡ����(��ȡ����ʱ�������д����ռ��,ֻ��д��û�б���ǰ�߳�ռ�õ�����Ż��ȡʧ��)��ԭ��: ���̻߳�ȡ������ʱ��,�����������߳�ͬʱҲ�ڳ��ж���,��˲��ܰѻ�ȡ�������̡߳�������Ϊд��;�����ڻ��д�����߳�,��һ����ռ�˶�д��,��˿��Լ���������ȡ����,����ͬʱ��ȡ��д���Ͷ�����,���������ͷ�д���������ж���,����һ��д���͡�������Ϊ�˶�����
8����������
8.1 BlockingQueue ���
Concurrent ����,BlockingQueue �ܺõĽ���˶��߳���,��θ�Ч��ȫ�����䡱���ݵ����⡣ͨ����Щ��Ч�����̰߳�ȫ�Ķ�����,Ϊ���ǿ��ٴ�������Ķ��̳߳����������ı�����������ϸ������ BlockingQueue ��ͥ�е����г�Ա,�������Ǹ��ԵĹ����Լ�����ʹ�ó�������������,����˼��,��������һ������, ͨ��һ�������Ķ���,����ʹ�������ɶ��е�һ������,������һ�����;
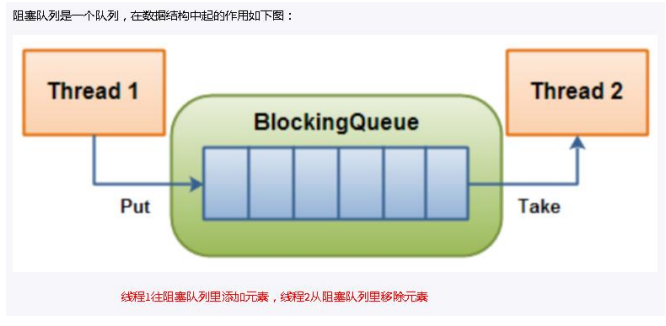
�������ǿյ�,�Ӷ����л�ȡԪ�صIJ������ᱻ����
������������,�Ӷ���������Ԫ�صIJ������ᱻ����
��ͼ�ӿյĶ����л�ȡԪ�ص��߳̽��ᱻ����,ֱ�������߳����յĶ��в����µ�Ԫ��
��ͼ�������Ķ�����������Ԫ�ص��߳̽��ᱻ����,ֱ�������̴߳Ӷ������Ƴ�һ������Ԫ�ػ�����ȫ���,ʹ���б�ÿ�����������������
���õĶ�����Ҫ����������:
? �Ƚ��ȳ�(FIFO):�Ȳ���Ķ��е�Ԫ��Ҳ���ȳ�����,�������ŶӵĹ��ܡ���ij�̶ֳ�����˵���ֶ���Ҳ������һ�ֹ�ƽ��
? ����ȳ�(LIFO):�������е�Ԫ�����ȳ�����,���ֶ������ȴ�������������¼�(ջ)
�ڶ��߳�����:��ν����,��ijЩ����»�����߳�(������),һ����������,��������߳��ֻ��Զ�������
Ϊʲô��Ҫ BlockingQueue
�ô������Dz���Ҫ����ʲôʱ����Ҫ�����߳�,ʲôʱ����Ҫ�����߳�,��Ϊ��һ��BlockingQueue ������һ�ְ�����
�� concurrent ��������ǰ,�ڶ��̻߳�����,����ÿ������Ա������ȥ�Լ�������Щϸ��,���仹Ҫ���Ч�ʺ��̰߳�ȫ,���������ǵij��������С�ĸ��Ӷȡ�
���̻߳�����,ͨ�����п��Ժ�����ʵ�����ݹ���,���羭��ġ������ߡ��� �������ߡ�ģ����,ͨ�����п��Ժܱ�����ʵ������֮������ݹ��������������������������߳�,�����������ɸ��������̡߳�����������߳���Ҫ�����õ����ݹ������������߳�,���ö��еķ�ʽ����������,�Ϳ��Ժܷ���ؽ������֮������ݹ������⡣����������ߺ���������ij��ʱ�����,��һ�������ݴ����ٶȲ�ƥ��������?���������,��������߲������ݵ��ٶȴ������������ѵ��ٶ�,���ҵ����������������ۻ���һ���̶ȵ�ʱ��,��ô�����߱�����ͣ�ȴ�һ��(�����������߳�),�Ա�ȴ��������̰߳��ۻ������ݴ������,��֮��Ȼ��
? ��������û�����ݵ������,�����߶˵������̶߳��ᱻ�Զ�����(����),ֱ�������ݷ������
? ���������������ݵ������,�����߶˵������̶߳��ᱻ�Զ�����(����),ֱ���������пյ�λ��,�̱߳��Զ�����
8.2 BlockingQueue ���ķ���
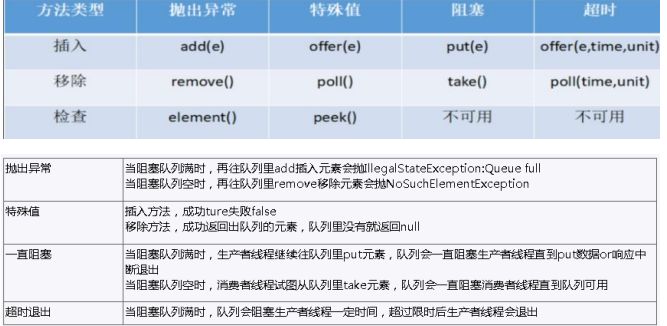
BlockingQueue �ĺ��ķ���:
1.��������
?
offer(anObject):��ʾ������ܵĻ�,�� anObject �ӵ� BlockingQueue ��,��
��� BlockingQueue ��������,�� true,���� false.(��������������
ǰִ�з������߳�)
?
offer(E o, long timeout, TimeUnit unit):�����趨�ȴ���ʱ��,�����ָ��
��ʱ����,�������������м��� BlockingQueue,��ʧ��
?
put(anObject):�� anObject �ӵ� BlockingQueue ��,��� BlockQueue û��
�ռ�,����ô˷������̱߳����ֱ�� BlockingQueue �����пռ��ټ���.
2.��ȡ����
? poll(time): ȡ�� BlockingQueue ��������λ�Ķ���,����������ȡ��,����Ե�time �����涨��ʱ��,ȡ����ʱ���� null
? poll(long timeout, TimeUnit unit):�� BlockingQueue ȡ��һ�����Ķ���,�����ָ��ʱ����,����һ�������ݿ�ȡ,���������ض����е����ݡ�����֪��ʱ�䳬ʱ��û�����ݿ�ȡ,����ʧ�ܡ�
? take(): ȡ�� BlockingQueue ��������λ�Ķ���,�� BlockingQueue Ϊ��,��Ͻ���ȴ�״ֱ̬�� BlockingQueue ���µ����ݱ�����;
? drainTo(): һ���Դ� BlockingQueue ��ȡ���п��õ����ݶ���(������ָ����ȡ���ݵĸ���),ͨ���÷���,����������ȡ����Ч��;����Ҫ��η�����
�����ͷ�����
8.3 ����
public static void main(String[] args) throws InterruptedException {
//������������
BlockingQueue<String> blockingQueue = new ArrayBlockingQueue<>(3);
//��һ��
// System.out.println(blockingQueue.add("a"));
System.out.println(blockingQueue.add("b"));
System.out.println(blockingQueue.add("c"));
//System.out.println(blockingQueue.element());
//System.out.println(blockingQueue.add("w"));
System.out.println(blockingQueue.remove());
System.out.println(blockingQueue.remove());
System.out.println(blockingQueue.remove());
System.out.println(blockingQueue.remove());
//�ڶ���
// System.out.println(blockingQueue.offer("a"));
// System.out.println(blockingQueue.offer("b"));
// System.out.println(blockingQueue.offer("c"));
// System.out.println(blockingQueue.offer("www"));
//
// System.out.println(blockingQueue.poll());
// System.out.println(blockingQueue.poll());
// System.out.println(blockingQueue.poll());
// System.out.println(blockingQueue.poll());
//������
// blockingQueue.put("a");
// blockingQueue.put("b");
// blockingQueue.put("c");
// //blockingQueue.put("w");
//
// System.out.println(blockingQueue.take());
// System.out.println(blockingQueue.take());
// System.out.println(blockingQueue.take());
// System.out.println(blockingQueue.take());
//������
System.out.println(blockingQueue.offer("a"));
System.out.println(blockingQueue.offer("b"));
System.out.println(blockingQueue.offer("c"));
System.out.println(blockingQueue.offer("w",3L, TimeUnit.SECONDS));
}
}
8.4 ���õ���������
8.4.1 ArrayBlockingQueue(����)
�����������������ʵ��,�� ArrayBlockingQueue �ڲ�,ά����һ����������,�Ա㻺������е����ݶ���,����һ�����õ���������,����һ������������,ArrayBlockingQueue �ڲ����������������α���,�ֱ��ʶ�Ŷ��е�ͷ����β���������е�λ�á�
ArrayBlockingQueue �������߷������ݺ�������ȡ����,���ǹ���ͬһ��������,�ɴ�Ҳ��ζ��������������������,������䲻ͬ��LinkedBlockingQueue;����ʵ��ԭ��������,ArrayBlockingQueue ��ȫ���Բ��÷�����,�Ӷ�ʵ�������ߺ������߲�������ȫ�������С�Doug Lea ֮����û����ȥ��,Ҳ������Ϊ ArrayBlockingQueue ������д��ͻ�ȡ�����Ѿ��㹻����,���������������������,���˸������������ĸ�������,������������ȫռ�����κα��ˡ� ArrayBlockingQueue ��LinkedBlockingQueue �仹��һ�����ԵIJ�֮ͬ������,ǰ���ڲ����ɾ��Ԫ��ʱ��������������κζ���Ķ���ʵ��,�������������һ�������Node �������ڳ�ʱ������Ҫ��Ч�����ش������������ݵ�ϵͳ��,�����GC ��Ӱ�컹�Ǵ���һ�������𡣶��ڴ��� ArrayBlockingQueue ʱ,���ǻ����Կ��ƶ�����ڲ����Ƿ���ù�ƽ��,Ĭ�ϲ��÷ǹ�ƽ����
һ�仰�ܽ�: ������ṹ��ɵ��н��������С�
8.4.2 LinkedBlockingQueue(����)
������������������,ͬ ArrayListBlockingQueue ����,���ڲ�Ҳά����һ�����ݻ������(�ö�����һ����������),���������������з���һ������ʱ,���л�����������л�ȡ����,�������ڶ����ڲ�,����������������;ֻ�е����л������ﵽ���ֵ��������ʱ(LinkedBlockingQueue ����ͨ�����캯��ָ����ֵ),�Ż����������߶���,ֱ�������ߴӶ��������ѵ�һ������,�������̻߳ᱻ����,��֮������������˵Ĵ���Ҳ����ͬ����ԭ������ LinkedBlockingQueue ֮�����ܹ���Ч�Ĵ�����������,����Ϊ����������߶˺������߶˷ֱ�����˶�����������������ͬ��,��Ҳ��ζ���ڸ߲���������������ߺ������߿��Բ��еز��������е�����,�Դ�������������еIJ������ܡ�
ArrayBlockingQueue �� LinkedBlockingQueue ����������ͨҲ����õ���������,һ�������,�ڴ������̼߳������������������,ʹ�������������ԡ�
һ�仰�ܽ�: �������ṹ��ɵ��н�(����СĬ��ֵΪinteger.MAX_VALUE)�������С�
8.4.3 DelayQueue
DelayQueue �е�Ԫ��ֻ�е���ָ�����ӳ�ʱ�䵽��,���ܹ��Ӷ����л�ȡ����Ԫ�ء�DelayQueue ��һ��û�д�С���ƵĶ���,����������в������ݵIJ���(������)��Զ���ᱻ����,��ֻ�л�ȡ���ݵIJ���(������)�Żᱻ������
һ�仰�ܽ�: ʹ�����ȼ�����ʵ�ֵ��ӳ����������С�
8.4.4 PriorityBlockingQueue
�������ȼ�����������(���ȼ����ж�ͨ�����캯������� Compator ����������),����Ҫע����� PriorityBlockingQueue ��������������������,��ֻ����û�п����ѵ�����ʱ,�������ݵ������������ʹ�õ�ʱ��Ҫ�ر�ע��,�������������ݵ��ٶȾ��Բ��ܿ�������������****���ݵ��ٶ�,����ʱ��һ��,�����պľ����еĿ��ö��ڴ�ռ䡣
��ʵ�� PriorityBlockingQueue ʱ,�ڲ������߳�ͬ���������õ�����ƽ����
һ�仰�ܽ�: ֧�����ȼ���������������С�
8.4.5 SynchronousQueue
һ������ĵȴ�����,���������н��ֱ�ӽ���,�е���ԭʼ����е������ߺ�������,���������Ų�Ʒȥ�������۸���Ʒ������������,�������߱�������ȥ�����ҵ���Ҫ��Ʒ��ֱ��������,���һ��û���ҵ����ʵ�Ŀ��,��ô�Բ���,��Ҷ��ڼ��еȴ���������л���� BlockingQueue ��˵,����һ���м侭���̵Ļ���(������),����о�����,������ֱ�ӰѲ�Ʒ������������,���������⾭�������ջὫ��Щ��Ʒ������Щ������,���ھ����̿��Կ��һ������Ʒ,��������ֱ�ӽ���ģʽ,������˵�����м侭���̵�ģʽ����������һЩ(������������);����һ����,����Ϊ�����̵�����,ʹ�ò�Ʒ�������ߵ��������м������˶���Ľ�����,������Ʒ�ļ�ʱ��Ӧ���ܿ��ܻή�͡�
����һ�� SynchronousQueue �����ֲ�ͬ�ķ�ʽ,����֮�����Ų�̫һ������Ϊ��
��ƽģʽ�ͷǹ�ƽģʽ������:
? ��ƽģʽ:SynchronousQueue ����ù�ƽ��,�����һ�� FIFO ��������������������ߺ�������,�Ӷ���ϵ����Ĺ�ƽ����;
? �ǹ�ƽģʽ(SynchronousQueue Ĭ��):SynchronousQueue ���÷ǹ�ƽ��,ͬʱ���һ�� LIFO ��������������������ߺ�������,����һ��ģʽ,��������ߺ������ߵĴ����ٶ��в��,������׳��ּ��ʵ����,��������ijЩ���������������ߵ�������Զ���ò���������
һ�仰�ܽ�: ���洢Ԫ�ص���������,Ҳ������Ԫ�صĶ��С�
8.4.6 LinkedTransferQueue
LinkedTransferQueue ��һ���������ṹ��ɵ������� TransferQueue ���С������������������,LinkedTransferQueue ���� tryTransfer ��transfer ������
LinkedTransferQueue ����һ��Ԥռģʽ����˼�����������߳�ȡԪ��ʱ,������в�Ϊ��,��ֱ��ȡ������,������Ϊ��,�Ǿ�����һ���ڵ�(�ڵ�Ԫ��Ϊ null)���,Ȼ���������̱߳��ȴ�������ڵ���,�����������߳����ʱ������һ��Ԫ��Ϊ null �Ľڵ�,�������߳̾Ͳ������,ֱ�Ӿͽ�Ԫ����䵽�ýڵ�,�����Ѹýڵ�ȴ����߳�,�����ѵ��������߳�ȡ��Ԫ��,�ӵ��õķ������ء�
һ�仰�ܽ�: ��������ɵ����������С�
8.4.7 LinkedBlockingDeque
LinkedBlockingDeque ��һ���������ṹ��ɵ�˫����������,�����ԴӶ��е����˲�����Ƴ�Ԫ�ء�
����һЩָ���IJ���,�ڲ������ȡ����Ԫ��ʱ�������״̬�������ò������ܻ�����ס���߳�ֱ������״̬���Ϊ��������,���������һ�����������
? ����Ԫ��ʱ: �����ǰ�������������������״̬,һֱ�ȵ������пյ�λ��ʱ�ٽ���Ԫ�ز���,�ò�������ͨ�����ó�ʱ����,��ʱ�� false ��ʾ����ʧ��,Ҳ���Բ����ó�ʱ����һֱ����,�жϺ��׳� InterruptedException �� ��
? ��ȡԪ��ʱ: �����ǰ����Ϊ�ջ�����סֱ�����в�Ϊ��Ȼ��Ԫ��,ͬ������ͨ�����ó�ʱ����
һ�仰�ܽ�: ��������ɵ�˫����������
8.5 ��
1. �ڶ��߳�����:��ν����,��ijЩ����»�����߳�(������),һ����������,��������߳��ֻ��Զ�������
2. Ϊʲô��Ҫ BlockingQueue? �� concurrent ��������ǰ,�ڶ��̻߳�����,����ÿ������Ա������ȥ�Լ�������Щϸ��,���仹Ҫ���Ч�ʺ��̰߳�ȫ,���������ǵij��������С�ĸ��Ӷȡ�ʹ�ú����Dz���Ҫ����ʲôʱ����Ҫ�����߳�,ʲôʱ����Ҫ�����߳�,��Ϊ��һ�� BlockingQueue ������һ�ְ�����
9��ThreadPool �̳߳�
9.1 ��ʲô
�̳߳�(Ӣ��:thread pool):һ���߳�ʹ��ģʽ���̹߳����������ȿ���,����Ӱ�컺��ֲ��Ժ��������ܡ����̳߳�ά���Ŷ���߳�,�ȴ��żල�����߷���ɲ���ִ�е�������������ڴ�����ʱ������ʱ�����������̵߳Ĵ��ۡ��̳߳ز����ܹ���֤�ں˵ij������,���ܷ�ֹ���ֵ��ȡ�����: 10 ��ǰ���� CPU ����,�ٵĶ��߳�,����Ϸ��С��������,CPU ��Ҫ�����л��� �����Ƕ�˵���,����̸߳������ڶ����� CPU ��,�����л�Ч�ʸߡ�
�̳߳ص�����: �̳߳����Ĺ���ֻҪ�ǿ������е��߳�����,���������н�����������,Ȼ�����̴߳�����������Щ����,����߳������������������,�����������߳��ŶӵȺ�,�������߳�ִ�����,�ٴӶ�����ȡ��������ִ�С�
������Ҫ�ص�Ϊ:
? ������Դ����: ͨ���ظ������Ѵ������߳̽����̴߳�����������ɵ����ġ�
? �����Ӧ�ٶ�: ������ʱ,������Բ���Ҫ�ȴ��̴߳�����������ִ�С�
? ����̵߳Ŀɹ�����: �߳���ϡȱ��Դ,��������ƵĴ���,����������ϵͳ��Դ,���ή��ϵͳ���ȶ���,ʹ���̳߳ؿ��Խ���ͳһ�ķ���,���źͼ�ء�
? Java �е��̳߳���ͨ�� Executor ���ʵ�ֵ�,�ÿ�����õ��� Executor,Executors,ExecutorService,ThreadPoolExecutor �⼸����
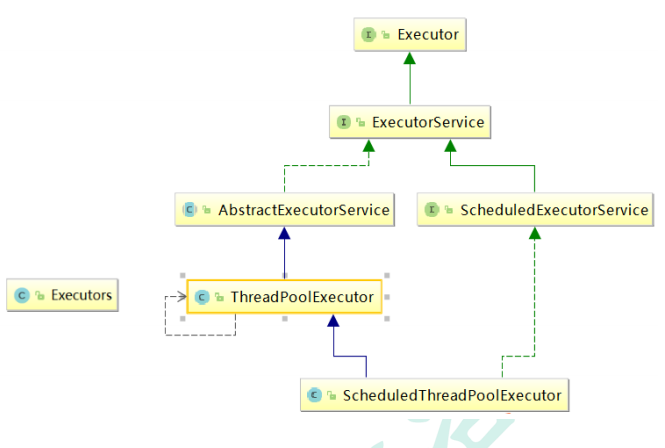
9.2 �̳߳ز���˵��
9.2.1 ���ò���(�ص�)
? corePoolSize �̳߳صĺ����߳���
? maximumPoolSize �����ɵ�����߳���
? keepAliveTime �����̴߳��ʱ��
? unit ����ʱ�䵥λ
? workQueue ����ύ��δִ������Ķ���
? threadFactory �����̵߳Ĺ�����
? handler �ȴ���������ľܾ�����
�̳߳���,��������Ҫ�IJ���,����Ӱ���˾ܾ�����:corePoolSize - �����߳���,Ҳ����С���߳�����workQueue - �������� �� maximumPoolSize -����߳���,���ύ���������� corePoolSize ��ʱ��,�����Ƚ�����ŵ� workQueue ���������С����������б��ͺ�,�������̳߳����߳���,ֱ���ﵽmaximumPoolSize ����߳������á���ʱ,�ٶ��������,��ᴥ���̳߳صľܾ������ˡ�
�ܽ�����,Ҳ����һ�仰,���ύ������������(workQueue.size() + maximumPoolSize ),�ͻᴥ���̳߳صľܾ�����**��
9.2.2 �ܾ�����(�ص�)
CallerRunsPolicy: �������ܾ�����,ֻҪ�̳߳�û�йرյĻ�,��ʹ�õ����߳�ֱ����������һ�㲢���Ƚ�С,����Ҫ��,������ʧ�ܡ�����,���ڵ������Լ���������,��������ύ�ٶȹ���,���ܵ��³�������,����Ч���ϱ�Ȼ����ʧ�ϴ�
AbortPolicy: ��������,���׳��ܾ�ִ�� RejectedExecutionException �쳣��Ϣ���̳߳�Ĭ�ϵľܾ����ԡ����봦�����׳����쳣,������ϵ�ǰ��ִ������,Ӱ�����������ִ�С�
DiscardPolicy: ֱ�Ӷ���,����ɶ��û��
DiscardOldestPolicy: �������ܾ�����,ֻҪ�̳߳�û�йرյĻ�,������������ workQueue �����ϵ�һ������,�������������
9.3 �̳߳ص������봴��
9.3.1 10.3.1 newCachedThreadPool(����)
����:����һ���ɻ����̳߳�,����̳߳س��ȳ���������Ҫ,�������տ����߳�,���ɻ���,���½��߳�.
�ص�:
? �̳߳�������û�й̶�,�ɴﵽ���ֵ(Interger. MAX_VALUE)
? �̳߳��е��߳̿ɽ��л����ظ����úͻ���(����Ĭ��ʱ��Ϊ 1 ����)
? ���̳߳���,û�п����߳�,�����´���һ���߳�
����: �����ڴ���һ��������������̳߳�,����������ѹ������,ִ��ʱ��϶�,�����ij���
9.3.2 newFixedThreadPool(����)
����:����һ�������ù̶��߳������̳߳�,�Թ���������з�ʽ��������Щ�̡߳��������,�ڴ�����̻߳ᴦ�ڴ�������Ļ״̬������������̴߳��ڻ״̬ʱ�ύ��������,�����п����߳�֮ǰ,���������ڶ����еȴ�������ڹر�ǰ��ִ���ڼ�����ʧ�ܶ������κ��߳���ֹ,��ôһ�����߳̽�������ִ�к���������(�����Ҫ)����ij���̱߳���ʽ�عر�֮ǰ,���е��߳̽�һֱ���ڡ�
����:
? �̳߳��е��̴߳���һ������,���ԺܺõĿ����̵߳IJ�����
? �߳̿����ظ���ʹ��,����ʾ�ر�֮ǰ,����һֱ����
? ����һ�������̱߳��ύʱ�����ڶ����еȴ�
����: �����ڿ���Ԥ���߳�������ҵ����,���߷��������ؽ���,���߳������ϸ����Ƶij���
9.3.3 newSingleThreadExecutor(����)
����:����һ��ʹ�õ��� worker �̵߳� Executor,������з�ʽ�����и��̡߳�(ע��,�����Ϊ�ڹر�ǰ��ִ���ڼ����ʧ�ܶ���ֹ�˴˵����߳�,��ô�����Ҫ,һ�����߳̽�������ִ�к���������)���ɱ�֤˳���ִ�и�������,���������������ʱ�䲻���ж���߳��ǻ�ġ���������Ч��newFixedThreadPool ��ͬ,�ɱ�֤�����������ô˷��������ص�ִ�г���ʹ���������̡߳�
����: �̳߳������ִ�� 1 ���߳�,֮���ύ���̻߳�������ڶ������Դ�ִ��
����: ��������Ҫ��֤˳��ִ�и�������,����������ʱ���,����ͬʱ�ж���̵߳ij���
9.3.4 newScheduleThreadPool(�˽�)
����: �̳߳�֧�ֶ�ʱ�Լ�������ִ������,����һ�� corePoolSize Ϊ�������,����߳���Ϊ���ε���������̳߳�**
����:
(1)�̳߳��о���ָ���������߳�,�����ǿ��߳�Ҳ������ (2)�ɶ�ʱ�����ӳ�ִ���̻߳
����: ��������Ҫ�����̨�߳�ִ����������ij���
9.3.5 newWorkStealingPool
jdk1.8 �ṩ���̳߳�,�ײ�ʹ�õ��� ForkJoinPool ʵ��,����һ��ӵ�ж��������е��̳߳�,���Լ���������,������ǰ���� cpu �������߳�������ִ������
����: �����ڴ��ʱ,�ɲ���ִ�еij���
9.4 ������
public class ThreadPoolDemo1 {
/**
* ��վ 3 ����Ʊ��, 10 ���û���Ʊ
* @param args
*/
public static void main(String[] args) {
//��ʱ�̴߳�:�߳�����Ϊ 3---������Ϊ 3
ExecutorService threadService = new ThreadPoolExecutor(3, 3,
60L,
TimeUnit.SECONDS,
new LinkedBlockingQueue<>(),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.DiscardOldestPolicy());
try {
//10 ������Ʊ
for (int i = 1; i <= 10; i++) {
threadService.execute(()->{
try {
System.out.println(Thread.currentThread().getName() + "
����,��ʼ��Ʊ");
Thread.sleep(5000);
System.out.println(Thread.currentThread().getName() + "
������Ʊ����");
}catch (Exception e){
e.printStackTrace();
}
});
} }catch (Exception e){
e.printStackTrace();
}finally {
//��ɺ����
threadService.shutdown();
} } }
9.5 �ײ�ԭ��
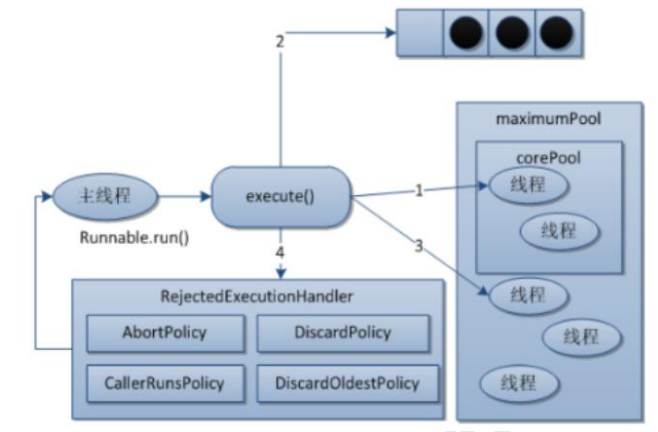
-
�ڴ������̳߳غ�,�̳߳��е��߳���Ϊ��
-
������ execute()��������һ����������ʱ,�̳߳ػ����������ж�:
2.1 ����������е��߳�����С�� corePoolSize,��ô���ϴ����߳������������;
2.2 ����������е��߳��������ڻ���� corePoolSize,��ô���������������; 2.3 ������ʱ������������������е��߳�������С��maximumPoolSize,��ô����Ҫ�����Ǻ����߳����������������; 2.4 ��������������������е��߳��������ڻ���� maximumPoolSize,��ô�̳߳ػ��������;ܾ�������ִ�С�
-
��һ���߳��������ʱ,����Ӷ�����ȡ��һ��������ִ��
-
��һ���߳����¿�������һ����ʱ��(keepAliveTime)ʱ,�̻߳��ж�:
4.1 �����ǰ���е��߳������� corePoolSize,��ô����߳̾ͱ�ͣ����
4.2 �����̳߳ص�����������ɺ�,�����ջ������� corePoolSize �Ĵ�С��

9.6 ע������
1.��Ŀ�д������߳�ʱ,ʹ�ó����������̳߳ش�����ʽ,��һ���ɱ䡢��������һ������,ԭ���� FixedThreadPool �� SingleThreadExecutor �ײ㶼����LinkedBlockingQueue ʵ�ֵ�,����������Ϊ Integer.MAX_VALUE,������ OOM������ʵ������һ���Լ�ͨ�� ThreadPoolExecutor �� 7 ������,�Զ����̳߳�
2.�����̳߳��Ƽ����� ThreadPoolExecutor ���� 7 �������ֶ�����
o corePoolSize �̳߳صĺ����߳���
o maximumPoolSize �����ɵ�����߳���
o keepAliveTime �����̴߳��ʱ��
o unit ����ʱ�䵥λ
o workQueue ����ύ��δִ������Ķ���
o threadFactory �����̵߳Ĺ�����
o handler �ȴ���������ľܾ�����
3.Ϊʲô������ʹ��Executors.�ķ�ʽ�ֶ������̳߳�,����ͼ

10��Fork/Join
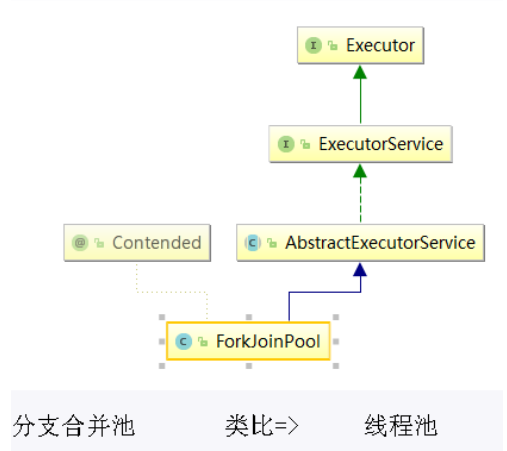
10.1 ��ʲô
Fork/Join �����Խ�һ����������ֳɶ����������в��д���,������������ϲ������ļ�����,�����������Fork/Join ���Ҫ�����������:
Fork:��һ������������зֲ�,���»�С
Join:�ѷֲ�����Ľ�����кϲ�
-
����ָ�:���� Fork/Join �����Ҫ�Ѵ������ָ���㹻С��������,���������Ƚϴ�Ļ���Ҫ����������м����ָ�
-
ִ�����ϲ����:�ָ��������ֱ�ŵ�˫�˶�����,Ȼ�������̷ֱ߳��˫�˶������ȡ����ִ�С�������ִ����Ľ������������һ��������,����һ���̴߳Ӷ�����ȡ����,Ȼ��ϲ���Щ���ݡ��� Java �� Fork/Join �����,ʹ�������������������
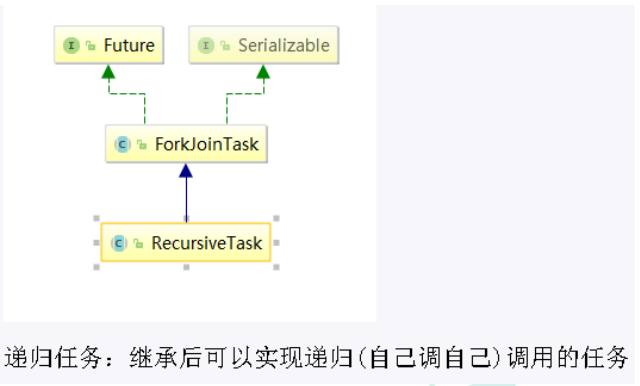
? ForkJoinTask:����Ҫʹ�� Fork/Join ���,������Ҫ����һ�� ForkJoin �������ṩ����������ִ�� fork �� join �Ļ��ơ�ͨ����������Dz���Ҫֱ�Ӽ��� ForkJoinTask ��,ֻ��Ҫ�̳���������,Fork/Join ����ṩ����������:
a.RecursiveAction:����û�з��ؽ��������
b.RecursiveTask:�����з��ؽ��������
? ForkJoinPool:ForkJoinTask ��Ҫͨ�� ForkJoinPool ��ִ��
? RecursiveTask: �̳к����ʵ�ֵݹ�(�Լ����Լ�)���õ�����
Fork/Join ��ܵ�ʵ��ԭ��
ForkJoinPool �� ForkJoinTask ����� ForkJoinWorkerThread �������,ForkJoinTask ���鸺����Լ��������ύ�� ForkJoinPool,��ForkJoinWorkerThread ����ִ����Щ����
10.2 Fork ����
Fork ������ʵ��ԭ��: �����ǵ��� ForkJoinTask �� fork ����ʱ,������������� ForkJoinWorkerThread �� pushTask �� workQueue ��,�첽��ִ���������,Ȼ���������ؽ��
public final ForkJoinTask<V> fork() {
Thread t;
if ((t = Thread.currentThread()) instanceof ForkJoinWorkerThread)
((ForkJoinWorkerThread)t).workQueue.push(this);
else
ForkJoinPool.common.externalPush(this);
return this;
}
pushTask �����ѵ�ǰ�������� ForkJoinTask ��������Ȼ���ٵ���ForkJoinPool �� signalWork()�������ѻ�һ�������߳���ִ������������:
final void push(ForkJoinTask<?> task) {
ForkJoinTask<?>[] a; ForkJoinPool p;
int b = base, s = top, n;
if ((a = array) != null) { // ignore if queue removed
int m = a.length - 1; // fenced write for task visibility
U.putOrderedObject(a, ((m & s) << ASHIFT) + ABASE, task);
U.putOrderedInt(this, QTOP, s + 1);
if ((n = s - b) <= 1) {
if ((p = pool) != null) p.signalWork(p.workQueues, this);//ִ��
}
else if (n >= m)
growArray();
} }
10.3 join ����
Join ��������Ҫ������������ǰ�̲߳��ȴ���ȡ�����������һ��ForkJoinTask �� join ������ʵ��,��������:
public final V join() {
int s;
if ((s = doJoin() & DONE_MASK) != NORMAL)
reportException(s);
return getRawResult();
}
�����ȵ��� doJoin ����,ͨ�� doJoin()�����õ���ǰ�����״̬���жϷ���ʲô���,����״̬�� 4 ��:
�����(NORMAL)����ȡ��(CANCELLED)���ź�(SIGNAL)�ͳ����쳣(EXCEPTIONAL)
? �������״̬�������,��ֱ�ӷ�����������
? �������״̬�DZ�ȡ��,��ֱ���׳� CancellationException
? �������״̬���׳��쳣,��ֱ���׳���Ӧ���쳣�����Ƿ���һ�� doJoin ������ʵ��
private int doJoin() {
int s; Thread t; ForkJoinWorkerThread wt; ForkJoinPool.WorkQueue
w;
return (s = status) < 0 ? s :
((t = Thread.currentThread()) instanceof ForkJoinWorkerThread) ? (w = (wt = (ForkJoinWorkerThread)t).workQueue).
tryUnpush(this) && (s = doExec()) < 0 ? s :
wt.pool.awaitJoin(w, this, 0L) :
externalAwaitDone();
}
final int doExec() {
int s; boolean completed;
if ((s = status) >= 0) {
try {
completed = exec();
} catch (Throwable rex) {
return setExceptionalCompletion(rex);
}
if (completed) s = setCompletion(NORMAL);
}
return s; }
�� doJoin()������������:
-
����ͨ���鿴�����״̬,�������Ƿ��Ѿ�ִ�����,���ִ�����,��ֱ�ӷ�������״̬;
-
���û��ִ����,�������������ȡ������ִ�С�
-
�������˳��ִ�����,����������״̬Ϊ NORMAL,��������쳣,���¼�쳣,��������״̬����Ϊ EXCEPTIONAL��
10.4 Fork/Join ��ܵ��쳣����
ForkJoinTask ��ִ�е�ʱ����ܻ��׳��쳣,��������û�취�����߳���ֱ�Ӳ����쳣,���� ForkJoinTask �ṩ�� isCompletedAbnormally()��������������Ƿ��Ѿ��׳��쳣���Ѿ���ȡ����,���ҿ���ͨ�� ForkJoinTask ��getException ������ȡ�쳣��getException �������� Throwable ����,�������ȡ������CancellationException���������û����ɻ���û���׳��쳣�� null��
10.5 ����
����: ����һ����������,���� 1+2+3��+100,ÿ 100�����з�һ��������
class MyTask extends RecursiveTask<Integer> {
//��ֲ�ֵ���ܳ���10,����10��������
private static final Integer VALUE = 10;
private int begin ;//��ֿ�ʼֵ
private int end;//��ֽ���ֵ
private int result ; //���ؽ��
//�����������
public MyTask(int begin,int end) {
this.begin = begin;
this.end = end;
}
//��ֺͺϲ�����
@Override
protected Integer compute() {
//�ж����������ֵ�Ƿ����10
if((end-begin)<=VALUE) {
//��Ӳ���
for (int i = begin; i <=end; i++) {
result = result+i;
}
} else {//��һ�����
//��ȡ�м�ֵ
int middle = (begin+end)/2;
//������
MyTask task01 = new MyTask(begin,middle);
//����ұ�
MyTask task02 = new MyTask(middle+1,end);
//���÷������
task01.fork();
task02.fork();
//�ϲ����
result = task01.join()+task02.join();
}
return result;
}
}
public class ForkJoinDemo {
public static void main(String[] args) throws ExecutionException, InterruptedException {
//����MyTask����
MyTask myTask = new MyTask(0,100);
//������֧�ϲ��ض���
ForkJoinPool forkJoinPool = new ForkJoinPool();
ForkJoinTask<Integer> forkJoinTask = forkJoinPool.submit(myTask);
//��ȡ���պϲ�֮����
Integer result = forkJoinTask.get();
System.out.println(result);
//�رճض���
forkJoinPool.shutdown();
}
}
11�� CompletableFuture
11.1 ��ʲô
CompletableFuture �� Java ���汻�����첽���,�첽ͨ����ζ�ŷ�����,����ʹ�����ǵ����������������̷߳���������߳���,����ͨ���ص����������߳��еõ��첽�����ִ��״̬,�Ƿ����,���Ƿ��쳣����Ϣ��CompletableFuture ʵ���� Future, CompletionStage �ӿ�,ʵ���� Future�ӿھͿ��Լ����������̳߳ؿ��,�� CompletionStage �ӿڲ����첽��̵Ľӿڳ���,���涨������첽����,ͨ����������,�Ӷ��������ǿ���ompletableFuture �ࡣ
11.2 ������
//�첽���ú�ͬ������
public class CompletableFutureDemo {
public static void main(String[] args) throws Exception {
//ͬ������
CompletableFuture<Void> completableFuture1 = CompletableFuture.runAsync(()->{
System.out.println(Thread.currentThread().getName()+" : CompletableFuture1");
});
completableFuture1.get();
//mq��Ϣ����
//�첽����
CompletableFuture<Integer> completableFuture2 = CompletableFuture.supplyAsync(()->{
System.out.println(Thread.currentThread().getName()+" : CompletableFuture2");
//ģ���쳣
int i = 10/0;
return 1024;
});
completableFuture2.whenComplete((t,u)->{
System.out.println("------t="+t);
System.out.println("------u="+u);
}).get();
}
}