1��ʲô��MyBatis?
Mybatis ��һ���� ORM(�����ϵӳ��)���,���ڲ���װ�� JDBC,����ʱֻ��Ҫ��ע SQL ��䱾��,����Ҫ���Ѿ���ȥ���������������������ӡ�����statement �ȷ��ӵĹ��̡�����Աֱ�ӱ�дԭ��̬ sql,�����ϸ���� sql ִ������,���ȸߡ�
MyBatis ����ʹ�� XML ��ע�������ú�ӳ��ԭ����Ϣ,�� POJO ӳ������ݿ��еļ�¼,�����˼������е� JDBC ������ֶ����ò����Լ���ȡ�������
2��Mybatis����ȱ��?
�ŵ�:
- ����SQL�����,�൱���,�����Ӧ�ó���������ݿ�������������κ�Ӱ��,SQLд��XML��,���sql������������,����ͳһ����;�ṩXML��ǩ,֧�ֱ�д��̬SQL���,��������
- ��JDBC���,������50%���ϵĴ�����,������JDBC��������Ĵ���,����Ҫ�ֶ���������
- �ܺõ���������ݿ����(��ΪMyBatisʹ��JDBC���������ݿ�,����ֻҪJDBC֧�ֵ����ݿ�MyBatis��֧��)
- �ṩӳ���ǩ,֧�ֶ��������ݿ��ORM�ֶι�ϵӳ��;�ṩ�����ϵӳ���ǩ,֧�ֶ����ϵ���ά��
- �ܹ���Spring�ܺõļ���
ȱ��:
- SQL���ı�д�������ϴ�,���䵱�ֶζࡢ��������ʱ,�Կ�����Ա��дSQL���Ĺ�����һ��Ҫ��
- SQL������������ݿ�,�������ݿ���ֲ�Բ�,��������������ݿ�
3��Hibernate �� MyBatis ������
��ͬ��:���Ƕ�jdbc�ķ�װ,���dz־ò�Ŀ��,������dao��Ŀ�����
��ͬ��:
- ӳ���ϵ
- MyBatis ��һ�����Զ�ӳ��Ŀ��,����Java������sql���ִ�н���Ķ�Ӧ��ϵ,���������ϵ���ü�
- Hibernate ��һ��ȫ��ӳ��Ŀ��,����Java���������ݿ���Ķ�Ӧ��ϵ,���������ϵ���ø���
- SQL�Ż�����ֲ��
- Hibernate ��SQL����װ,�ṩ����־�����桢����(������ MyBatis ǿ��)������,����ṩ HQL(Hibernate Query Language)�������ݿ�,���ݿ�����֧�ֺ�,������������ܡ������Ŀ��Ҫ֧�ֶ������ݿ�,���뿪������,��SQL����Ż����ѡ�
- MyBatis ��Ҫ�ֶ���д SQL,֧�ֶ�̬ SQL�������б�����̬���ɱ�����֧�ִ洢���̡�������������Դ�Щ��ֱ��ʹ��SQL���������ݿ�,��֧�����ݿ�����,��sql����Ż����ס�
ORM(Object Relational Mapping),�����ϵӳ��,��һ��Ϊ�˽����ϵ�����ݿ��������Java����(POJO)��ӳ���ϵ�ļ�������˵,ORM��ͨ��ʹ��������������ݿ�֮��ӳ���Ԫ����,�������еĶ����Զ��־û�����ϵ�����ݿ��С�
4��Ϊʲô˵Mybatis�ǰ��Զ�ORMӳ�乤��?����ȫ�Զ�������������?
Hibernate����ȫ�Զ�ORMӳ�乤��,ʹ��Hibernate��ѯ����������߹������϶���ʱ,���Ը��ݶ����ϵģ��ֱ�ӻ�ȡ,��������ȫ�Զ��ġ�
��Mybatis�ڲ�ѯ���������������϶���ʱ,��Ҫ�ֶ���дsql�����,����,��֮Ϊ���Զ�ORMӳ�乤�ߡ�
5����ͳJDBC��������ʲô����?
- Ƶ���������ݿ����Ӷ����ͷ�,�������ϵͳ��Դ�˷�,Ӱ��ϵͳ���ܡ�����ʹ�����ӳؽ��������⡣����ʹ��jdbc��Ҫ�Լ�ʵ�����ӳ�
- sql��䶨�塢�������á��������������Ӳ���롣ʵ����Ŀ��sql���仯�Ŀ����Խϴ�,һ�������仯,��Ҫ��java����,ϵͳ��Ҫ���±���,���·���������ά����
- ʹ��preparedStatement��ռ��λ���Ŵ���������Ӳ����,��Ϊsql����where������һ��,���ܶ�Ҳ������,��sql��Ҫ�Ĵ���,ϵͳ����ά����
- ��������������ظ�����,�����鷳���������ӳ���Java�����ȽϷ��㡣
6��JDBC�������Щ����֮��,MyBatis����ν����?
���5�ᵽ��4�㲻��,���εĽ����������:
- ��mybatis-config.xml�������������ӳ�,ʹ�����ӳع������ݿ����ӡ�
- ��Sql���������XXXXmapper.xml�ļ�����java������롣
- Mybatis�Զ���java����ӳ����sql��䡣
- Mybatis�Զ���sqlִ�н��ӳ����java����
7��MyBatis��̲�����ʲô����?
- ����SqlSessionFactory
- ͨ��SqlSessionFactory����SqlSession
- ͨ��sqlsessionִ�����ݿ����
- ����session.commit()�ύ����
- ����session.close()�رջỰ
8��˵˵MyBatis�Ĺ���ԭ��
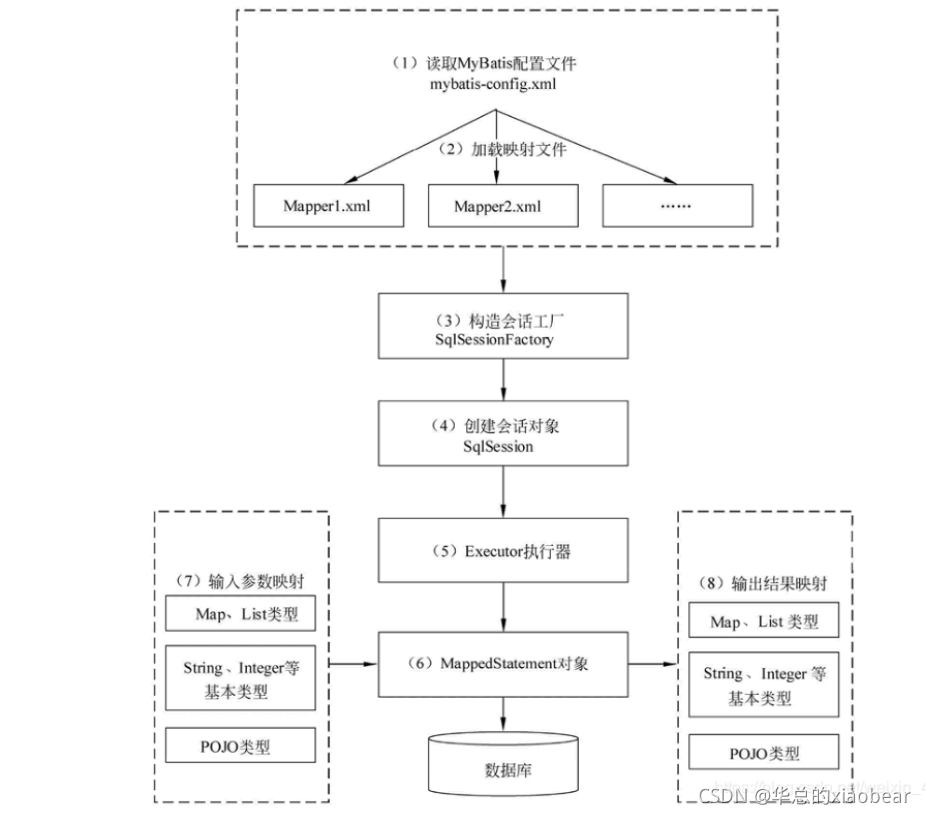
- ��ȡ MyBatis �����ļ�:mybatis-config.xml Ϊ MyBatis ��ȫ�������ļ�,������ MyBatis �����л�������Ϣ,�������ݿ�������Ϣ��
- ����ӳ���ļ���ӳ���ļ��� SQL ӳ���ļ�,���ļ��������˲������ݿ�� SQL ���,��Ҫ��MyBatis �����ļ� mybatis-config.xml �м��ء�mybatis-config.xml �ļ����Լ��ض��ӳ���ļ�,ÿ���ļ���Ӧ���ݿ��е�һ�ű���
- ����Ự����:ͨ�� MyBatis �Ļ�����������Ϣ�����Ự���� SqlSessionFactory��
- �����Ự����:�ɻỰ�������� SqlSession ����,�ö����а�����ִ�� SQL �������з�����
- Executor ִ����:MyBatis �ײ㶨����һ�� Executor �ӿ����������ݿ�,�������� SqlSession���ݵIJ�����̬��������Ҫִ�е� SQL ���,ͬʱ�����ѯ�����ά����
- MappedStatement ����:�� Executor �ӿڵ�ִ�з�������һ�� MappedStatement ���͵IJ���,�ò����Ƕ�ӳ����Ϣ�ķ�װ,���ڴ洢Ҫӳ��� SQL ���� id����������Ϣ��
- �������ӳ��:����������Ϳ����� Map��List �ȼ�������,Ҳ�����ǻ����������ͺ� POJO ���͡��������ӳ����������� JDBC �� preparedStatement �������ò����Ĺ��̡�
- ������ӳ��:���������Ϳ����� Map�� List �ȼ�������,Ҳ�����ǻ����������ͺ� POJO ���͡�������ӳ����������� JDBC �Խ�����Ľ������̡�
9��MyBatis�Ĺ��ܼܹ���������
���������ͼƬ����
���ǰ�Mybatis�Ĺ��ܼܹ���Ϊ����:
- API�ӿڲ�:�ṩ���ⲿʹ�õĽӿ�API,������Աͨ����Щ����API���������ݿ⡣�ӿڲ�һ���յ���������ͻ�������ݴ���������ɾ�������ݴ�����
- ���ݴ�����:��������SQL���ҡ�SQL������SQLִ�к�ִ�н��ӳ�䴦���ȡ�����Ҫ��Ŀ���Ǹ��ݵ��õ��������һ�����ݿ������
- ����֧�Ų�:����������Ĺ���֧��,�������ӹ�����������������ü��غͻ��洦��,��Щ���ǹ��õĶ���,�����dz�ȡ������Ϊ������������Ϊ�ϲ�����ݴ������ṩ�������֧�š�
10��ʲô��DBMS
DBMS:���ݿ����ϵͳ(database management system)��һ�ֲ��ݺ������ݿ�Ĵ�������,���ڽ�����ʹ�ú�ά������,���dbms���������ݿ����ͳһ�Ĺ����Ϳ���,�Ա�֤���ݿ�İ�ȫ�Ժ������ԡ��û�ͨ��dbms�������ݿ��е�����,���ݿ����ԱҲͨ��dbms�������ݿ��ά������������ʹ���Ӧ�ó�����û��ò�ͬ�ķ�����ͬʱ���ͬʱ��ȥ����,�ĺ�ѯ�����ݿ⡣
DBMS�ṩ���ݶ�������DDL(Data Definition Language)�����ݲ�������DML(DataManipulation Language),���û��������ݿ��ģʽ�ṹ��Ȩ��Լ��,ʵ�ֶ����ݵ���Ȩ��ɾ���Ȳ�����
11��Ϊʲô��ҪԤ����
����:SQL Ԥ����ָ�������ݿ������ڷ��� SQL ���Ͳ����� DBMS ֮ǰ�� SQL �����б���,���� DBMS ִ�� SQL ʱ,�Ͳ���Ҫ���±��롣
ԭ��:JDBC ��ʹ�ö��� PreparedStatement ������Ԥ�������,ʹ��Ԥ���롣Ԥ����ο����Ż� SQL ��ִ�С�Ԥ����֮��� SQL ��������¿���ֱ��ִ��,DBMS ����Ҫ�ٴα���,Խ���ӵ�SQL,����ĸ��ӶȽ�Խ��,Ԥ����ο��Ժϲ���β���Ϊһ��������ͬʱԤ��������������ظ����á���һ�� SQL Ԥ���������� PreparedStatement ��������,�´ζ���ͬһ��SQL,����ֱ��ʹ���������� PreparedState ����MybatisĬ�������,�������е� SQL ����Ԥ���롣����һ��ԭ����Ǹ���SQLע��
12��Mybatis������ЩExecutorִ����?����֮���������ʲô?
SimpleExecutor:ÿִ��һ��update��select,�Ϳ���һ��Statement����,�������̹ر�Statement����ReuseExecutor:ִ��update��select,��sql��Ϊkey����Statement����,���ھ�ʹ��,�����ھʹ���,�����,���ر�Statement����,���Ƿ�����Map<String, Statement>��,����һ��ʹ�á�����֮,�����ظ�ʹ��Statement����BatchExecutor:ִ��update(û��select,JDBC��������֧��select),������sql�����ӵ���������(addBatch()),�ȴ�ͳһִ��(executeBatch()),�������˶��Statement����,ÿ��Statement������addBatch()��Ϻ�,�ȴ���һִ��executeBatch()����������JDBC��������ͬ��
13��Mybatis�����ָ��ʹ����һ��Executorִ����?
��Mybatis�����ļ���,������(settings)����ָ��Ĭ�ϵ�ExecutorTypeִ��������,Ҳ�����ֶ���DefaultSqlSessionFactory�Ĵ���SqlSession�ķ�������ExecutorType���Ͳ���,��SqlSession openSession(ExecutorType execType)��
����Ĭ�ϵ�ִ������SIMPLE ������ͨ��ִ����;REUSE ִ����������Ԥ�������(preparedstatements); BATCH ִ������������䲢ִ���������¡�
<settings>
<setting name="defaultExecutorType" value="SIMPLE"/>
</settings>
14��Mybatis�Ƿ�֧���ӳټ���?���֧��,����ʵ��ԭ����ʲô?
Mybatis��֧��association���������collection�������϶�����ӳټ���,associationָ�ľ���һ��һ,collectionָ�ľ���һ�Զ��ѯ����Mybatis�����ļ���,���������Ƿ������ӳټ���lazyLoadingEnabled=true|false��
����ԭ����,ʹ��CGLIB����Ŀ�����Ĵ�������,������Ŀ�귽��ʱ,��������������,�������a.getB().getName(),������invoke()��������a.getB()��nullֵ,��ô�ͻᵥ���������ȱ���õIJ�ѯ����B�����sql,��B��ѯ����,Ȼ�����a.setB(b),����a�Ķ���b���Ծ���ֵ��,�������a.getB().getName()�����ĵ��á�������ӳټ��صĻ���ԭ����
15��#{}��${}������
- #{}��ռλ��,Ԥ���봦��;${}��ƴ�ӷ�,�ַ����滻,û��Ԥ���봦����
- Mybatis�ڴ���#{}ʱ,#{}������������ַ�������,�ὫSQL�е�#{}�滻Ϊ?��,����PreparedStatement��set��������ֵ��
- #{} ������Ч�ķ�ֹSQLע��,���ϵͳ��ȫ��;${} ���ܷ�ֹSQL ע��
- #{} �ı����滻����DBMS ��;${} �ı����滻���� DBMS ��
16��ģ����ѯlike������ôд
��%${question}%��:��������SQLע��,���Ƽ�"%"#{question}"%"ע��:��Ϊ#{��}������sql���ʱ��,���ڱ�������Զ��ӵ����š� ',�������� % ��Ҫʹ��˫����" ",����ʹ�õ����� �� ',��Ȼ��鲻���κν����CONCAT(��%��,#{question},��%��)ʹ��CONCAT()����,(�Ƽ�)- ʹ��bind��ǩ(���Ƽ�)
<select id="listUserLikeUsername" resultType="com.jourwon.pojo.User">
  <bind name="pattern" value="'%' + username + '%'" />
  select id,sex,age,username,password from person where username LIKE
#{pattern}
</select>
17����mapper����δ��ݶ������
����1:˳�η�
public User selectUser(String name, int deptId);
<select id="selectUser" resultMap="UserResultMap">
select * from user
where user_name = #{0} and dept_id = #{1}
</select>
- #{}��������ִ������������˳��
- ���ַ���������ʹ��,sql����ﲻֱ��,��һ��˳��������׳�����
����2:@Paramע��η�
public User selectUser(@Param("userName") String name, @Param("deptId")int deptId);
<select id="selectUser" resultMap="UserResultMap">
select * from user
where user_name = #{userName} and dept_id = #{deptId}
</select>
- #{}��������ƶ�Ӧ����ע��@Param�����������ε����ơ�
- ���ַ����ڲ��������������DZȽ�ֱ�۵�,(�Ƽ�ʹ��)��
����3:Map���η�
public User selectUser(Map<String, Object> params);
<select id="selectUser" parameterType="java.util.Map" resultMap="UserResultMap">
select * from user
where user_name = #{userName} and dept_id = #{deptId}
</select>
- #{}��������ƶ�Ӧ����Map�����key���ơ�
- ���ַ����ʺϴ��ݶ������,�Ҳ����ױ������ݵ������(�Ƽ�ʹ��)��
����4:Java Bean���η�
public User selectUser(User user);
<select id="selectUser" parameterType="com.jourwon.pojo.User" resultMap="UserResultMap">
select * from user
where user_name = #{userName} and dept_id = #{deptId}
</select>
- #{}��������ƶ�Ӧ����User������ij�Ա���ԡ�
- ���ַ���ֱ��,��Ҫ��һ��ʵ����,��չ������,��Ҫ������,������ɶ���ǿ,ҵ������������,�Ƽ�ʹ�á�(�Ƽ�ʹ��)��
18��Mybatis���ִ����������
ʹ��
foreach��ǩforeach����Ҫ���ڹ���in������,��������SQL����н��е���һ�����ϡ�foreach��ǩ��������Ҫ��item,index,collection,open,separator,close��
- item:��ʾ������ÿһ��Ԫ�ؽ��е���ʱ�ı���,�����ı�����;
- index:ָ��һ������,���ڱ�ʾ�ڵ���������,ÿ�ε�������λ��,������;
- open:��ʾ�������ʲô��ʼ,���á�(��;
- separator:��ʾ��ÿ�ν��е���֮����ʲô������Ϊ�ָ���,���á�,��;
- close:��ʾ��ʲô����,���á�)����
��ʹ��foreach��ʱ����ؼ���Ҳ�������׳����ľ���collection����,�������DZ���ָ����,�����ڲ�ͬ�����,�����Ե�ֵ�Dz�һ����,��Ҫ��һ��3�����:
- ���������ǵ������Ҳ���������һ��List��ʱ��,collection����ֵΪlist
- ���������ǵ������Ҳ���������һ��array�����ʱ��,collection������ֵΪarray
- �������IJ����Ƕ����ʱ��,���Ǿ���Ҫ�����Ƿ�װ��һ��Map��,��Ȼ������Ҳ���Է�װ��map,ʵ����������ڴ��������ʱ��,��MyBatis����Ҳ�ǻ������װ��һ��Map��,map��key���Dz�����,�������ʱ��collection����ֵ���Ǵ����List��array�������Լ���װ��map�����key
- ��һ��
<!-- ��������(foreach��������������ַ���)
int addEmpsBatch(@Param("emps") List<Employee> emps); -->
<!-- MySQL����������,����foreach���� mysql֧��values(),(),()� --> //�Ƽ�ʹ��
<insert id="addEmpsBatch">
INSERT INTO emp(ename,gender,email,did)
VALUES
<foreach collection="emps" item="emp" separator=",">
(#{emp.eName},#{emp.gender},#{emp.email},#{emp.dept.id})
</foreach>
</insert>
- �ڶ���
<!-- ���ַ�ʽ��Ҫ���ݿ���������allowMutiQueries=true��֧��
��jdbc.url=jdbc:mysql://localhost:3306/mybatis?allowMultiQueries=true -->
<insert id="addEmpsBatch">
<foreach collection="emps" item="emp" separator=";">
INSERT INTO emp(ename,gender,email,did)
VALUES(#{emp.eName},#{emp.gender},#{emp.email},#{emp.dept.id})
</foreach>
</insert>
- ������:ʹ��ExecutorType.BATCH
Mybatis���õ�ExecutorType��3��,Ĭ��Ϊsimple,��ģʽ����Ϊÿ������ִ�д���һ���µ�Ԥ�������,�����ύsql;��batchģʽ�ظ�ʹ���Ѿ�Ԥ���������,��������ִ�����и������,��Ȼbatch���ܽ�����; ��batchģʽҲ���Լ�������,������Insert����ʱ,������û���ύ֮ǰ,��û�а취��ȡ��������id,����ij���������Dz�����ҵ��Ҫ���
@Test
public void testBatch() throws IOException{
SqlSessionFactory sqlSessionFactory = getSqlSessionFactory();
//����ִ������������sqlSession
SqlSession openSession =
sqlSessionFactory.openSession(ExecutorType.BATCH);
//��������ִ��ǰʱ��
long start = System.currentTimeMillis();
try {
EmployeeMapper mapper =
openSession.getMapper(EmployeeMapper.class);
for (int i = 0; i < 1000; i++) {
mapper.addEmp(new
Employee(UUID.randomUUID().toString().substring(0, 5), "b", "1"));
}
openSession.commit();
long end = System.currentTimeMillis();
//��������ִ�к��ʱ��
System.out.println("ִ��ʱ��" + (end - start));
//���� Ԥ����sqlһ��==�����ò���==��10000��==��ִ��1�� 677
//������ (Ԥ����=���ò���=ִ�� )==��10000�� 1121
} finally {
openSession.close();
}
}
mapper��mapper.xml
public interface EmployeeMapper {
//��������Ա��
Long addEmp(Employee employee);
}
<mapper namespace="com.jourwon.mapper.EmployeeMapper"
<!--��������Ա�� -->
<insert id="addEmp">
insert into employee(lastName,email,gender)
values(#{lastName},#{email},#{gender})
</insert>
</mapper>
19����λ�ȡ���ɵ�����
������ǩ������:keyProperty=" ID " ����
<insert id="insert" useGeneratedKeys="true" keyProperty="userId" >
insert into user(
user_name, user_password, create_time)
values(#{userName}, #{userPassword} , #{createTime, jdbcType=
TIMESTAMP})
</insert>
20����ʵ�����е��������ͱ��е��ֶ�����һ�� ,��ô��
-
��һ��:ͨ���ڲ�ѯ��SQL����ж����ֶ����ı���,���ֶ����ı�����ʵ�����������һ�¡�
<select id="getOrder" parameterType="int" resultType="com.jourwon.pojo.Order"> select order_id id, order_no orderno ,order_price price form orders where order_id=#{id}; </select> -
��2��: ͨ�� ��ӳ���ֶ�����ʵ������������һһ��Ӧ�Ĺ�ϵ��
<select id="getOrder" parameterType="int" resultMap="orderResultMap"> select * from orders where order_id=#{id} </select> <resultMap type="com.jourwon.pojo.Order" id="orderResultMap"> <!�C��id������ӳ�������ֶΨC> <id property="id" column="order_id"> <!�C��result������ӳ��������ֶ�,propertyΪʵ����������,columnΪ���ݿ���е��� �ԨC> <result property ="orderno" column ="order_no"/> <result property="price" column="order_price" /> </reslutMap>
21��Mapper ��д���ļ��ַ�ʽ?
��һ��:�ӿ�ʵ����̳� SqlSessionDaoSupport:ʹ�ô��ַ�����Ҫ��дmapper �ӿ�,mapper �ӿ�ʵ���ࡢmapper.xml �ļ���
-
�� sqlMapConfig.xml ������ mapper.xml ���
<mappers> <mapper resource="mapper.xml �ļ��ĵ�ַ" /> <mapper resource="mapper.xml �ļ��ĵ�ַ" /> </mappers> -
���� mapper �ӿ�
-
ʵ���༯�� SqlSessionDaoSupport,mapper �����п��� this.getSqlSession()����������ɾ�IJ顣
-
spring ����
<bean id=" " class="mapper �ӿڵ�ʵ��"> <property name="sqlSessionFactory" ref="sqlSessionFactory"></property> </bean>
�ڶ���:ʹ�� org.mybatis.spring.mapper.MapperFactoryBean
-
�� sqlMapConfig.xml ������ mapper.xml ��λ��,��� mapper.xml ��mappre �ӿڵ�������ͬ����ͬһ��Ŀ¼,������Բ�������
-
���� mapper �ӿ�:
<mappers> <mapper resource="mapper.xml �ļ��ĵ�ַ" /> <mapper resource="mapper.xml �ļ��ĵ�ַ" /> </mappers> -
mapper.xml �е� namespace Ϊ mapper �ӿڵĵ�ַ
-
mapper �ӿ��еķ������� mapper.xml �еĶ���� statement �� id ����һ��
-
Spring ���
<bean id="" class="org.mybatis.spring.mapper.MapperFactoryBean"> <property name="mapperInterface" value="mapper �ӿڵ�ַ" /> <property name="sqlSessionFactory" ref="sqlSessionFactory" /> </bean>
������:ʹ�� mapper ɨ����
-
mapper.xml �ļ���д:
- mapper.xml �е� namespace Ϊ mapper �ӿڵĵ�ַ;
- mapper �ӿ��еķ������� mapper.xml �еĶ���� statement �� id ����һ��;
����� mapper.xml �� mapper �ӿڵ����Ʊ���һ�������� sqlMapConfig.xml�н������á�
-
���� mapper �ӿ�
ע�� mapper.xml ���ļ����� mapper �Ľӿ����Ʊ���һ��,�ҷ���ͬһ��Ŀ¼
-
���� mapper ɨ����
<bean class="org.mybatis.spring.mapper.MapperScannerConfigurer"> <property name="basePackage" value="mapper �ӿڰ���ַ"></property> <property name="sqlSessionFactoryBeanName"value="sqlSessionFactory"/> </bean> -
ʹ��ɨ������� spring �����л�ȡ mapper ��ʵ�ֶ���
22��ʲô��MyBatis�Ľӿڰ�?����Щʵ�ַ�ʽ?
�ӿڰ�:������MyBatis�����ⶨ��ӿ�,Ȼ��ѽӿ�����ķ�����SQL����,����ֱ�ӵ��ýӿڷ����Ϳ���,��������ԭ����SqlSession�ṩ�ķ������ǿ����и�������ѡ������á�
�ӿڰ�������ʵ�ַ�ʽ
- ͨ��ע���,�����ڽӿڵķ���������� @Select��@Update��ע��,�������Sql�������;
- ͨ��xml����дSQL����, �����������,Ҫָ��xmlӳ���ļ������namespace����Ϊ�ӿڵ�ȫ·��������Sql���Ƚϼ�ʱ��,��ע���, ��SQL���Ƚϸ���ʱ��,��xml��,һ����xml�ıȽ϶ࡣ
23��ʹ��MyBatis��mapper�ӿڵ���ʱ����ЩҪ��?
- Mapper�ӿڷ�������mapper.xml�ж����ÿ��sql��id��ͬ��
- Mapper�ӿڷ���������������ͺ�mapper.xml�ж����ÿ��sql ��parameterType��������ͬ��
- Mapper�ӿڷ���������������ͺ�mapper.xml�ж����ÿ��sql��resultType��������ͬ��
- Mapper.xml�ļ��е�namespace����mapper�ӿڵ���·����
24�����Dao�ӿڵĹ���ԭ����ʲô?Dao�ӿ���ķ���,������ͬʱ,������������
Dao�ӿڵĹ���ԭ����JDK��̬����,Mybatis����ʱ��ʹ��JDK��̬����ΪDao�ӿ����ɴ���proxy����,��������proxy�����ؽӿڷ���,ת��ִ��MappedStatement��������sql,Ȼ��sqlִ�н�����ء�
Dao�ӿ���ķ���,�Dz������ص�,��Ϊ��ȫ����+�������ı����Ѱ�Ҳ��ԡ�
25��Mybatis��Xmlӳ���ļ���,��ͬ��Xmlӳ���ļ�,id�Ƿ�����ظ�?
��ͬ��Xmlӳ���ļ�,���������namespace,��ôid�����ظ�;���û������namespace,��ôid�����ظ�;�Ͼ�namespace���DZ����,ֻ�����ʵ�����ѡ�
ԭ�����namespace+id����ΪMap<String, MappedStatement>��keyʹ�õ�,���û��namespace,��ʣ��id,��ô,id�ظ��ᵼ�����ݻ��า�ǡ�����namespace,��Ȼid�Ϳ����ظ�,namespace��ͬ,namespace+id��ȻҲ�Ͳ�ͬ��
26������Mybatis��Xmlӳ���ļ���Mybatis�ڲ����ݽṹ֮���ӳ���ϵ?
Mybatis������Xml������Ϣ����װ��All-In-One����������Configuration�ڲ�����Xmlӳ���ļ���, ��ǩ�ᱻ����ΪParameterMap����,��ÿ����Ԫ�ػᱻ����ΪParameterMapping���� ��ǩ�ᱻ����ΪResultMap����,��ÿ����Ԫ�ػᱻ����ΪResultMapping����ÿһ�� �� �� �� ��ǩ���ᱻ����ΪMappedStatement����,��ǩ�ڵ�sql�ᱻ����ΪBoundSql����
27��Mybatisӳ���ļ���,���A��ǩͨ��include������B��ǩ������,����,B��ǩ�ܷ�����A��ǩ�ĺ���,����˵���붨����A��ǩ��ǰ��?
��ȻMybatis����Xmlӳ���ļ��ǰ���˳�������,����,�����õ�B��ǩ��Ȼ���Զ������κεط�,Mybatis��������ȷʶ��
ԭ����,Mybatis����A��ǩ,����A��ǩ������B��ǩ,����B��ǩ��δ������,�в�����,��ʱ,Mybatis�ὫA��ǩ���Ϊδ����״̬,Ȼ������������µı�ǩ,����B��ǩ,�����б�ǩ�������,Mybatis�����½�����Щ�����Ϊδ�����ı�ǩ,��ʱ�ٽ���A��ǩʱ,B��ǩ�Ѿ�����,A��ǩҲ�Ϳ���������������ˡ�
28��Mybatis��ִ��һ�Զ�,һ��һ����ϵ��ѯ��,����Щʵ�ַ���
��,��ֹ����һ�Զ�,һ��һ�����Զ�Զ�,һ�Զ�
ʵ�ַ�ʽ:
- ��������һ��SQLȥ��ѯ��������,����������,Ȼ��������
- ʹ��Ƕ�ײ�ѯ,��JOIN��ѯ,һ������A���������ֵ,��һ�����ǹ����� �� B������ֵ,�ô���ֻҪ����һ������ֵ,�Ϳ��������������������
- �Ӳ�ѯ
29��Mybatis�Ƿ����ӳ��Enumö����?
- Mybatis����ӳ��ö����,��������ӳ��ö����,Mybatis����ӳ���κζ�����һ���ϡ�ӳ�䷽ʽΪ�Զ���һ��TypeHandler,ʵ��TypeHandler��setParameter()��getResult()�ӿڷ�����
- TypeHandler����������,һ����ɴ�javaType��jdbcType��ת��,�������jdbcType��javaType��ת��,����ΪsetParameter()��getResult()��������,�ֱ��������sql�ʺ�ռλ�������ͻ�ȡ�в�ѯ�����
30��Mybatis��̬sql����ʲô��?������Щ��̬sql?�ܼ���һ�¶�̬sql��ִ��ԭ����?
- Mybatis��̬sql������������Xmlӳ���ļ���,�Ա�ǩ����ʽ��д��̬sql,������жϺͶ�̬ƴ��sql�Ĺ���
- Mybatis�ṩ��9�ֶ�̬sql��ǩ trim|where|set|foreach|if|choose|when|otherwise|bind
- ��ִ��ԭ��Ϊ,ʹ��OGNL��sql���������м������ʽ��ֵ,���ݱ���ʽ��ֵ��̬ƴ��sql,�Դ�����ɶ�̬sql�Ĺ��ܡ�
31��Mybatis����ν��з�ҳ��?��ҳ�����ԭ����ʲô?
Mybatisʹ��RowBounds������з�ҳ,�������ResultSet�����ִ�е��ڴ��ҳ,����������ҳ,������sql��ֱ����д����������ҳ�IJ��������������ҳ����,Ҳ����ʹ�÷�ҳ��������������ҳ��
��ҳ����Ļ���ԭ����ʹ��Mybatis�ṩ�IJ���ӿ�,ʵ���Զ�����,�ڲ�������ط��������ش�ִ�е�sql,Ȼ����дsql,����dialect����,���Ӷ�Ӧ��������ҳ����������ҳ������
����:select * from student,����sql����дΪ:select t.* from (select * from student) t limit 0, 10
32������Mybatis�IJ������ԭ��,�Լ���α�дһ�������
Mybatis�����Ա�д���ParameterHandler��ResultSetHandler��StatementHandler��Executor��4�ֽӿڵIJ��,Mybatisʹ��JDK�Ķ�̬����,Ϊ��Ҫ���صĽӿ����ɴ���������ʵ�ֽӿڷ������ع���,ÿ��ִ����4�ֽӿڶ���ķ���ʱ,�ͻ�������ط���,�������InvocationHandler��invoke()����,��Ȼ,ֻ��������Щ��ָ����Ҫ���صķ�����
ʵ��Mybatis��Interceptor�ӿڲ���дintercept()����,Ȼ���ڸ������дע��,ָ��Ҫ������һ���ӿڵ���Щ��������,��ס,�������������ļ����������д�IJ����
33��Mybatis��һ������������
һ������: ���� PerpetualCache �� HashMap ���ػ���,��洢������Ϊ Session,�� Sessionflush �� close ֮��,�� Session �е����� Cache �ͽ����,Ĭ�ϴ�һ�����档
����������һ�������������ͬ,Ĭ��Ҳ�Dz��� PerpetualCache,HashMap �洢,��ͬ������洢������Ϊ Mapper(Namespace),���ҿ��Զ���洢Դ,�� Ehcache��Ĭ�ϲ���������,Ҫ������������,ʹ�ö���������������Ҫʵ��Serializable���л��ӿ�(��������������״̬),��������ӳ���ļ�������
���ڻ������ݸ��»���,��ijһ��������(һ������ Session/��������Namespaces)�Ľ�����C/U/D ������,Ĭ�ϸ������������� select �еĻ��潫�� clear��