springCloud������(Hystrix���ƽ̨��DashBoard��Turbine��ء��۶�����״̬����������Zuul))
���Ļع�
��������ʵ����hystrix���۶Ͻ���,����֪��,������ʧ��,���ܾ�,��ʱ��ʱ��,������뵽���������С������뽵������������ζ����·���Ѿ�������ô��β����˽��·���е�״̬��?
��������
��ĿԴ��gitee:gitee��ַ
һ��Hystrix�ļ��ƽ̨
����ʵ���ݴ�����,Hystrix���ṩ�˽���ʵʱ�ļ��,HystrixCommand��HystrixObservableCommand��ִ��ʱ,������ִ�н��������ָ�ꡣ����ÿ�����������,�ɹ������ȡ���Щ״̬�ᱩ¶��Actuator�ṩ��/health�˵��С�
ֻ��Ϊ��Ŀ���� spring-boot-actuator ����,������Ŀ,����http://localhost:9013/actuator/hystrix.stream ,���ɿ���ʵʱ�ļ�����ݡ�
�Hystrix���ƽ̨
����jar��
�����������Ļ�,��֮ǰ�������ʱ���Ѿ������ˡ�
��������
���ʲ���һ��
���ָ������ʲ���,������ʵ�и���,Ҫ��yml�ļ�������һ������
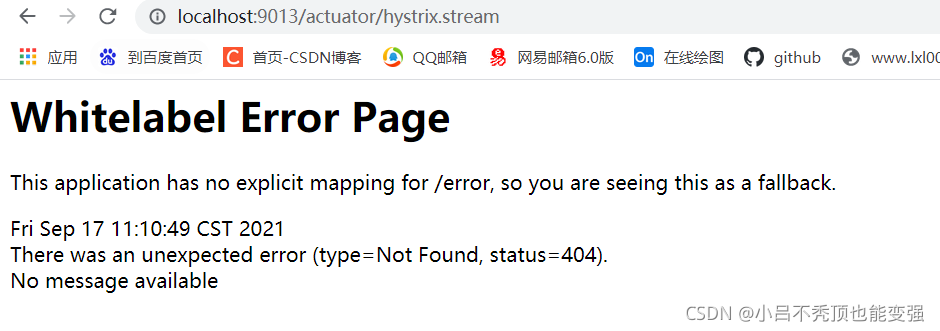
����yml�ļ�
management:
endpoints:
web:
exposure:
include: '*'
�ٴ���������
�ٴ�����
������һֱping,Ȼ������һ������
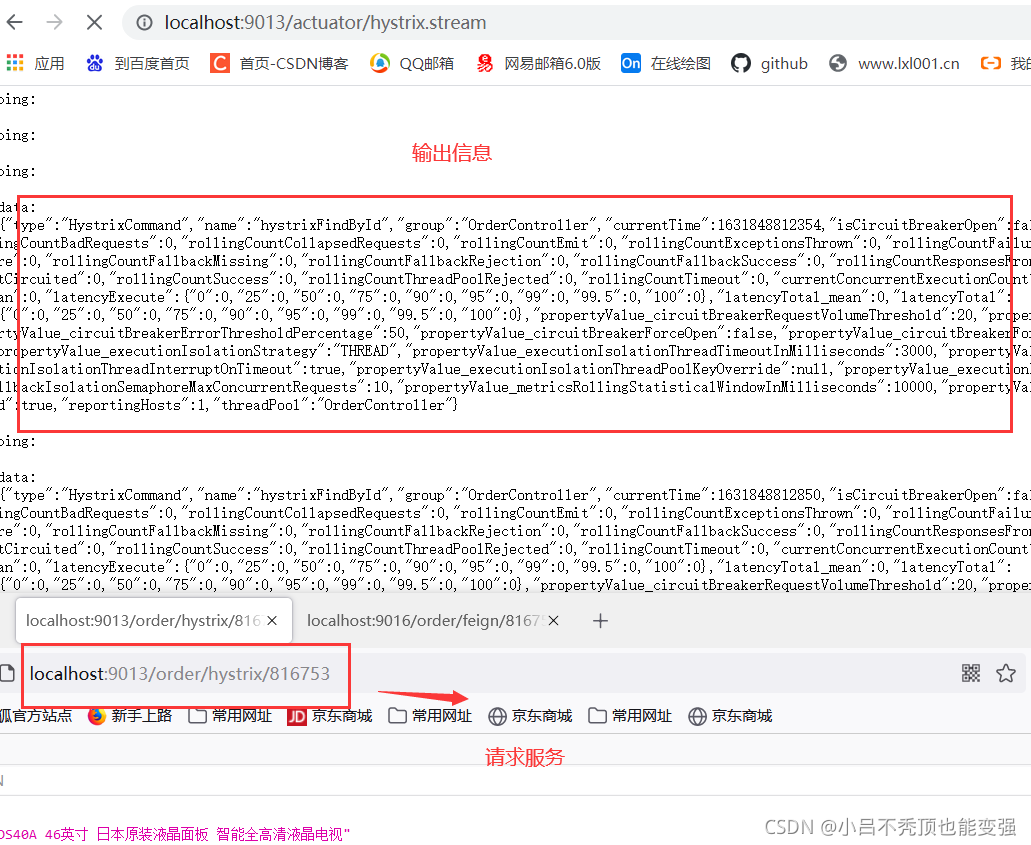
�Hystrix DashBoard���
�ո�������Hystrix�ļ��,������/hystrix.stream�ӿڻ�ȡ�Ķ�����������ʽչʾ����Ϣ������ͨ������ֱ����չʾϵͳ������״̬,����Hystrix�ٷ����ṩ������ͼ�λ���DashBoard(�DZ���)���ƽ̨��Hystrix�DZ��������ʾÿ����·��(��
@HystrixCommandע��ķ���)��״̬��
��������
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix-dashboard</artifactId>
</dependency>
����ע��
��������ʹ��@EnableHystrixDashboardע�⼤���DZ�����Ŀ
��������
��������,���ʲ���

��֮ǰ�ķ��ʵ��������뵽�����������,����ͼ
Ȼ������ť����
Ȼ����ʷ���һ������
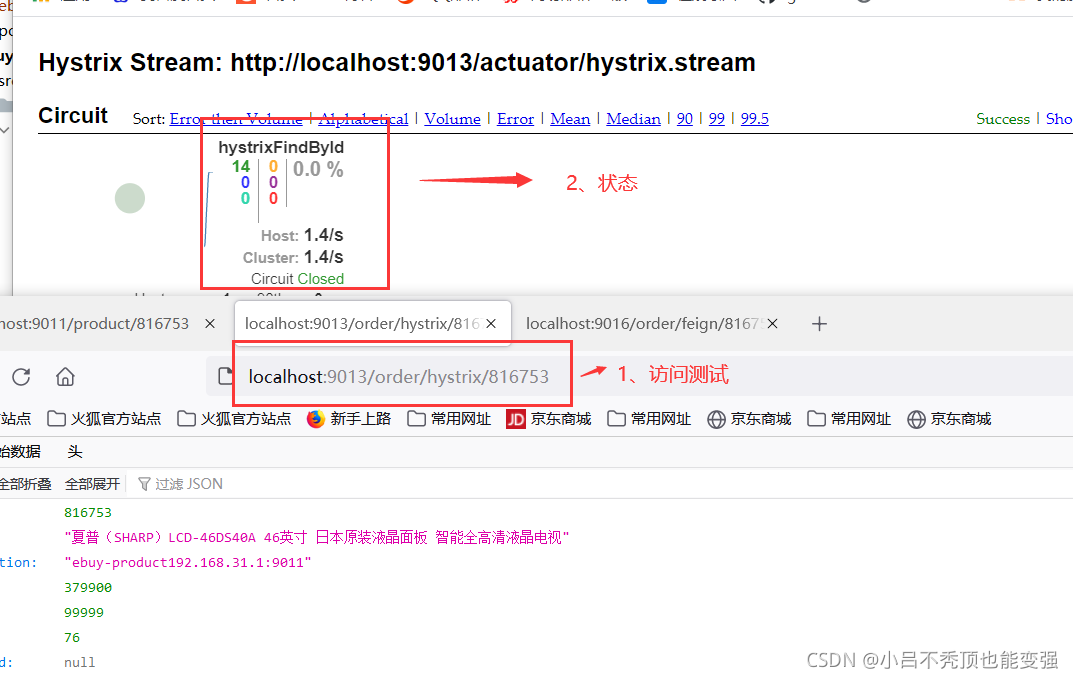
ע��:Hystrix�DZ��������ʾÿ����·��(��@HystrixCommandע��ķ���)��״̬,δ������ע��ķ�������ء�
������·���ۺϼ��Turbine
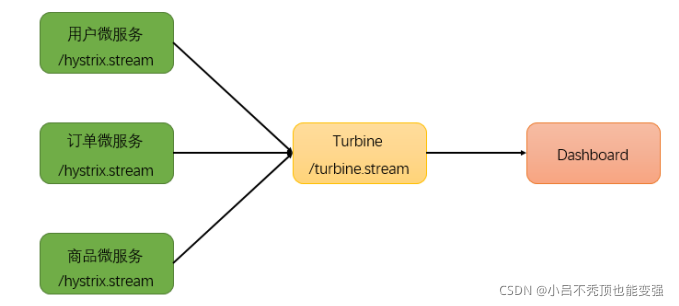
������ܹ���ϵ��,ÿ��������Ҫ����Hystrix DashBoard��������ÿ��ֻ�ܲ鿴����ʵ���ļ������,����Ҫ�����л���ص�ַ,����Ȼ�ܲ����㡣Ҫ�뿴���ϵͳ��Hystrix Dashboard���ݾ���Ҫ�õ�Hystrix
Turbine��Turbine��һ���ۺ�Hystrix ������ݵĹ���,�����Խ������������� Hystrix������ݾۺϵ�һ��,����ʹ�á�����Turbine��,�������ϵͳ�ܹ�����:
�ebuy-turbine
�½�һ��springboot��Ŀ
������
����jar��
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>Greenwich.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<!--turbine���ƽ̨-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-turbine</artifactId>
</dependency>
<!--hystrix�۶� (��Ϊ���ƽֻ̨���hystrix��صķ���)-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix</artifactId>
</dependency>
<!--��� �ı�������ʾ-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix-dashboard</artifactId>
</dependency>
���ö�������hystrix���
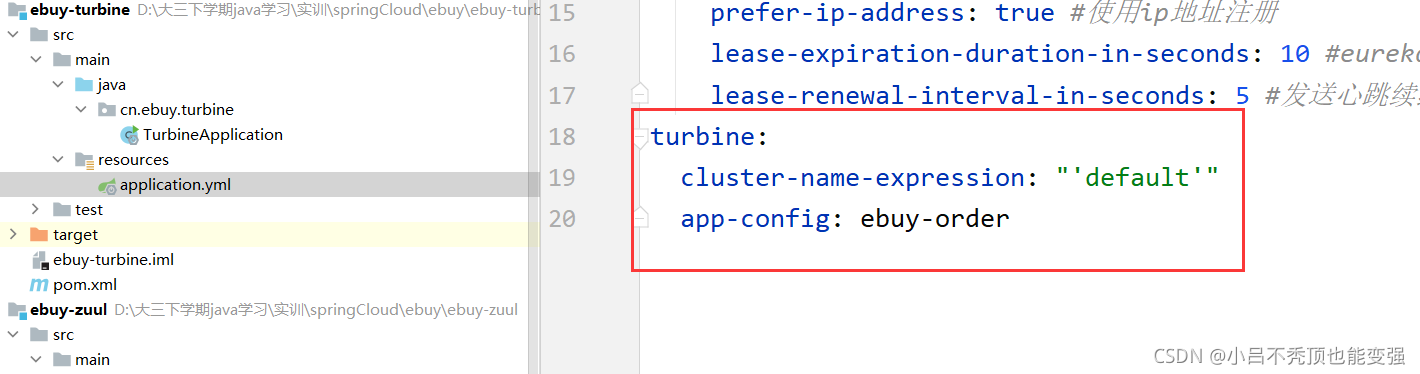
��application.yml�������ļ��п���turbine�������������
server:
port: 8031 #�˿�
spring:
application:
name: ebuy-turbine #��������
logging:
level:
cn.ebuy: DEBUG
eureka:
client:
service-url:
# ��Ⱥ���ö��,��������һ��
defaultZone: http://127.0.0.1:9880/eureka/,http://127.0.0.1:9890/eureka/
instance:
prefer-ip-address: true #ʹ��ip��ַע��
lease-expiration-duration-in-seconds: 10 #eureka client ����������server��,��Լ����ʱ��(Ĭ��90��)
lease-renewal-interval-in-seconds: 5 #����������Լʱ����
turbine:
cluster-name-expression: "'default'"
app-config: ebuy-order
ע:# Ҫ��ص������б�,�����,�ָ�
- eureka������� : ָ��ע�����ĵ�ַ
- turbine�������:ָ����Ҫ��ص������б�
turbine���Զ��Ĵ�ע�������л�ȡ��Ҫ��ص�����,���ۺ����������е� /hystrix.stream ����
����������
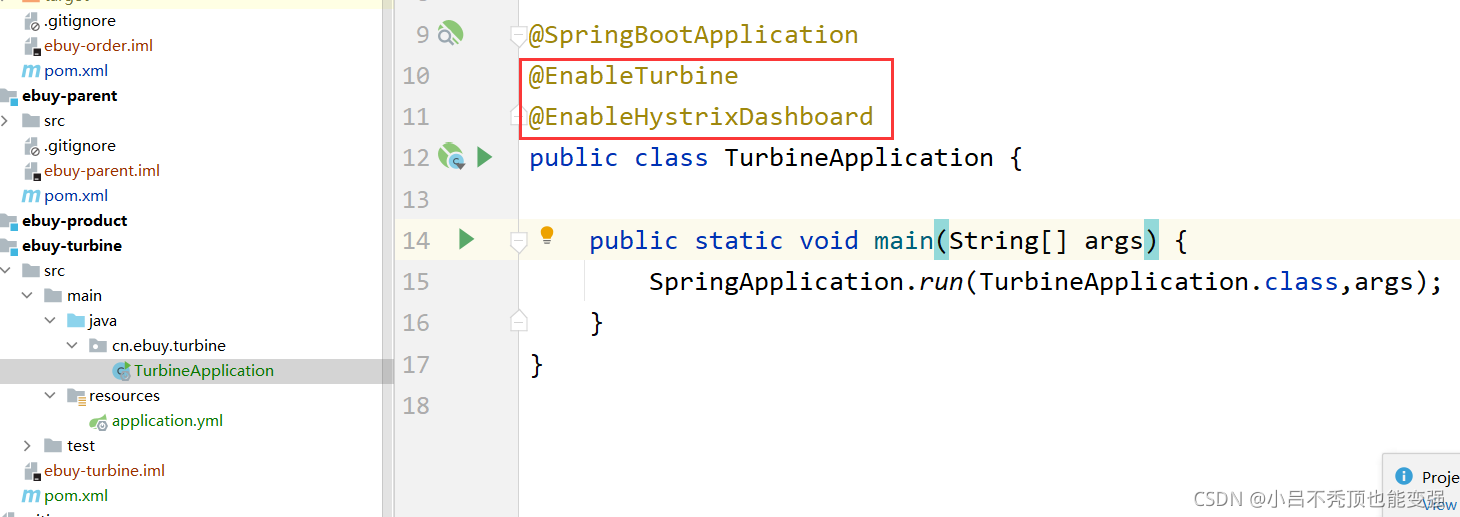
- ��Ϊһ�������ļ����Ŀ,��Ҫ����������,����HystrixDashboard���ƽ̨,������Turbine
����
��������� http://localhost:8031/hystrix չʾHystrixDashboard��
����urlλ������ http://localhost:8031/turbine.stream(�ı�����),http://localhost:8031/hystrix(���ƽ̨),��̬����turbine.stream����չʾ�������ļ������
������Ҫ��ص������ַ

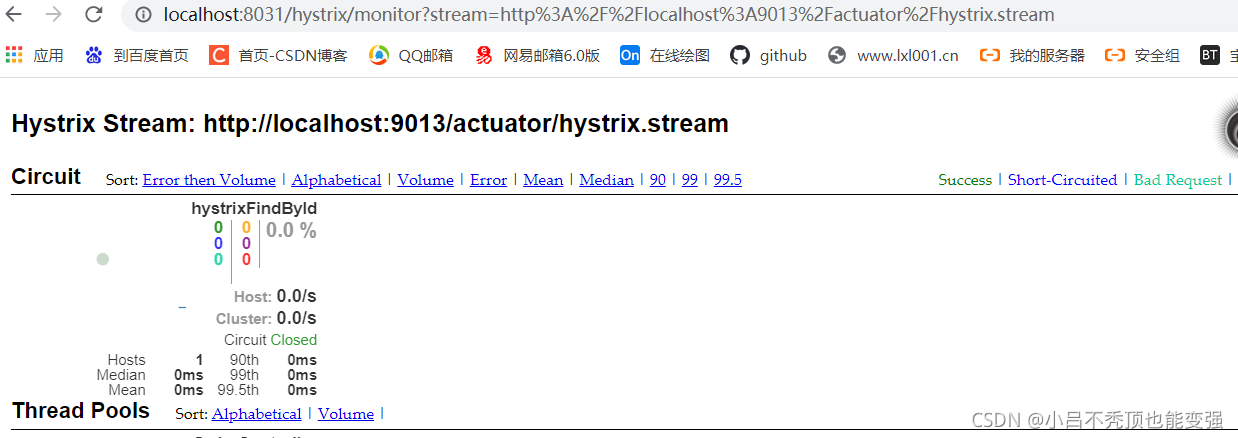
����turbine�������ƽ̨���Ǵ����ˡ�
�����۶�����״̬
�ع�һ��
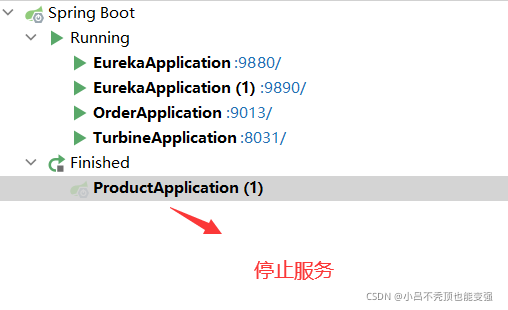
�ع�һ����������,��productֹͣ����ʱ,����order����,order��������product���۶�,����ͼ
����δֹͣproduct����ʱ:
ֹͣproduct����:
����order����,�����۶�
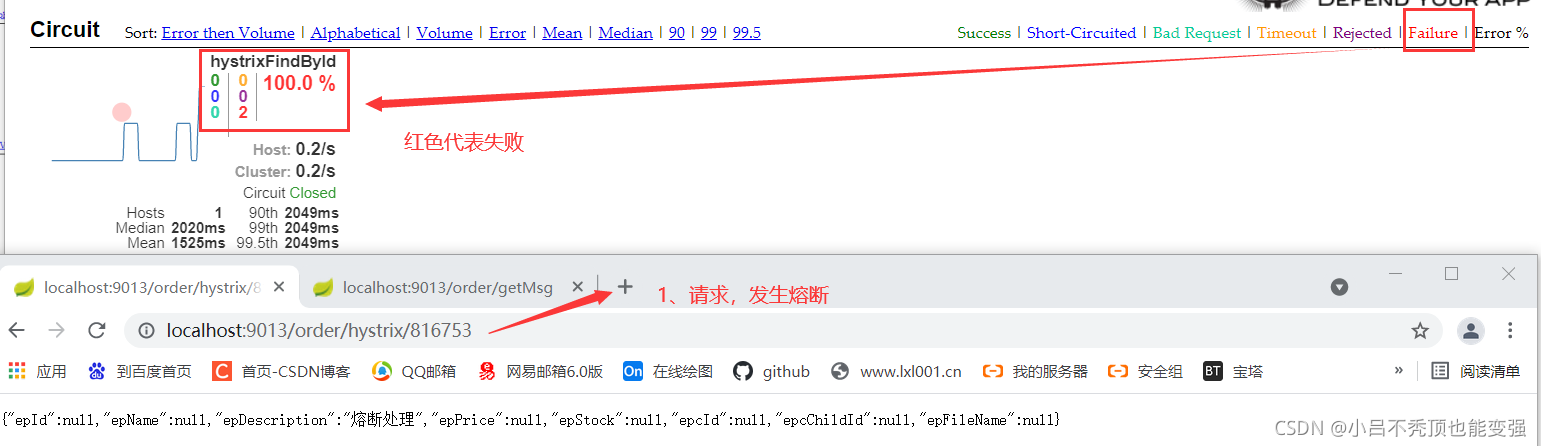
��ͼ���Կ������ƽ̨��ʾ����״̬��failureʧ��,����Short-Circuited�۶�,������Ϊʲô��???
�۶���״̬
�۶���������״̬
CLOSED��OPEN��HALF_OPEN�۶���Ĭ�Ϲر�״̬,�������۶Ϻ�״̬���ΪOPEN,�ڵȴ���ָ����ʱ��,Hystrix�������������Ƿ���,���ڼ��۶������Ϊ HALF_OPEN �뿪��״̬,�۶�̽����������������ΪCLOSED�ر��۶�����
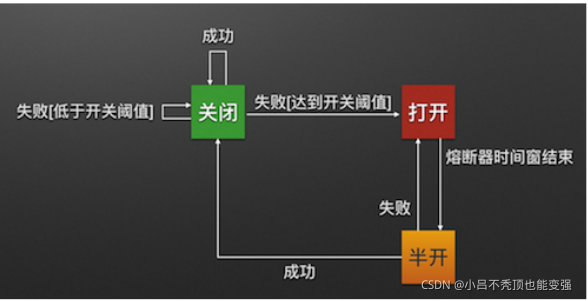
Closed:�ر�״̬(��·���ر�),���������������ʡ�������ά�����������ʧ�ܵĴ���,���ij�ε���ʧ��,��ʹʧ�ܴ�����1��������ʧ�ܴ����������ڸ���ʱ��������ʧ�ܵ���ֵ,��������л����Ͽ�(Open)״̬����ʱ����������һ����ʱʱ��,����ʱ�ӳ����˸�ʱ��,���л�����Ͽ�(Half-Open)״̬���ó�ʱʱ����趨�Ǹ���ϵͳһ�λ������������µ���ʧ�ܵĴ���
Open:��״̬(��·����),�������ᱻ����(�۶϶���)��Hystix��������������,��һ��ʱ��
��ʧ������ٷֱȴﵽ��ֵ,���۶�,��·������ȫ�رա�Ĭ��ʧ�ܱ�������ֵ��50%,����������ٲ�����20�Ρ�
Half Open:�뿪״̬,open״̬�������õ�,����������ʱ��(Ĭ����5S)������·�����Զ�����뿪״̬����ʱ���ͷ�1������ͨ��,����������ǽ�����,���رն�·��,����������ִ�,�ٴν���5������ʱ��
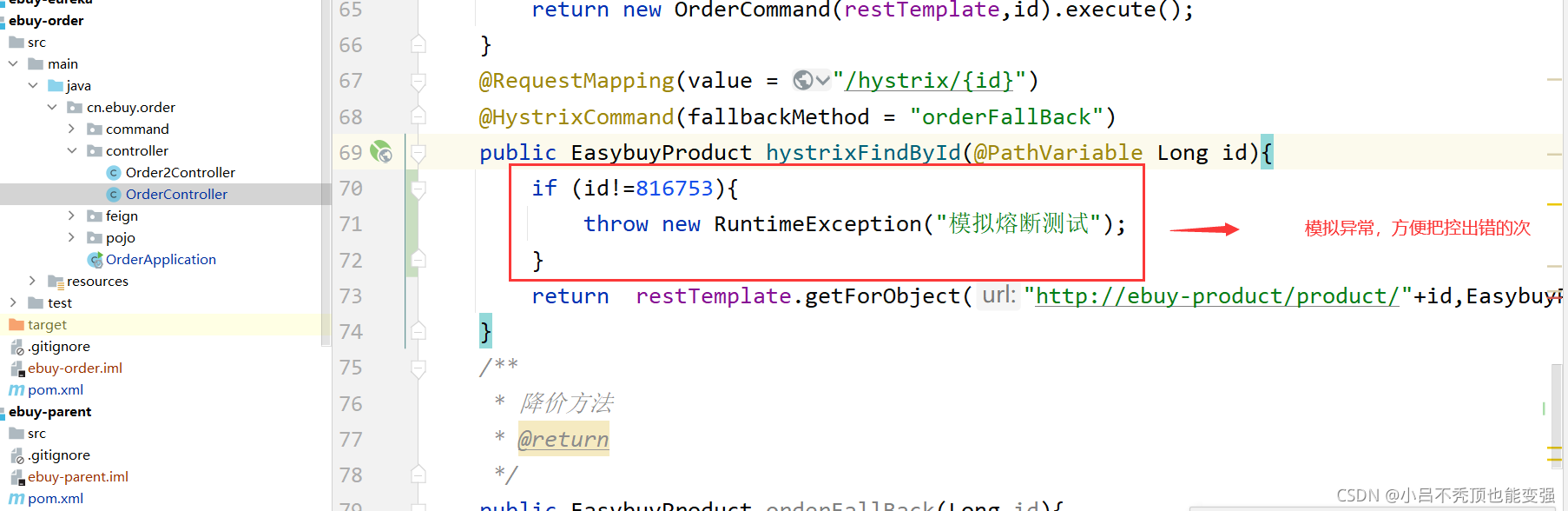
����֮ǰ����
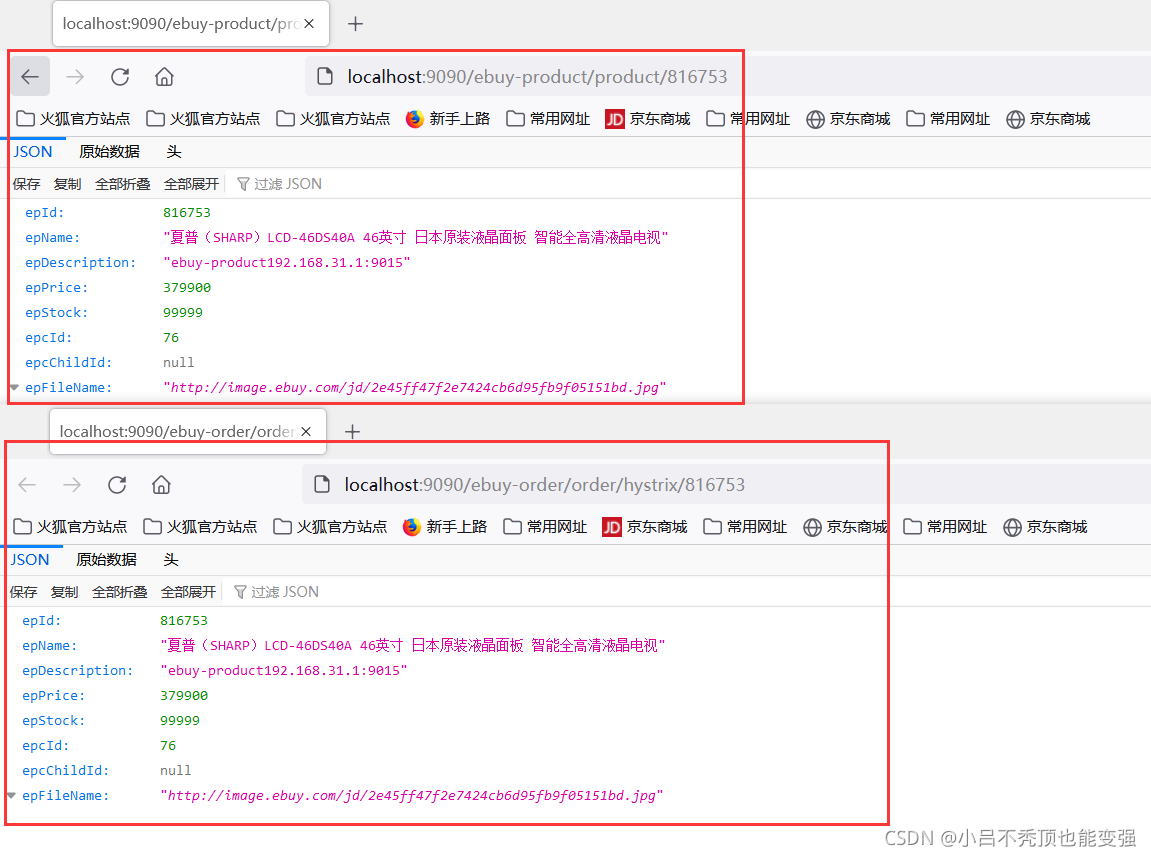
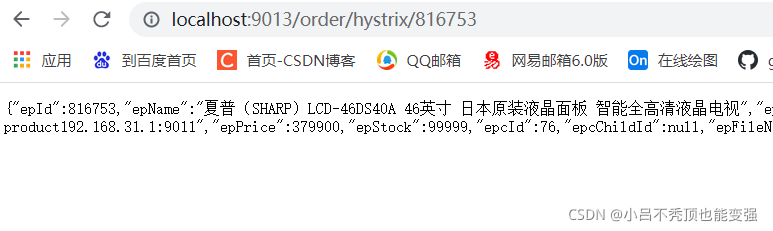
Ϊ���ܹ���ȷ��������ijɹ���ʧ��,������һ�´���������
ע:�������������idΪ816753,һ���ɹ�,���������ʧ�ܡ�
��������������:
- �ɹ�����:http://localhost:9013/order/hystrix/816753
- ���ɹ�����:http://localhost:9013/order/hystrix/1
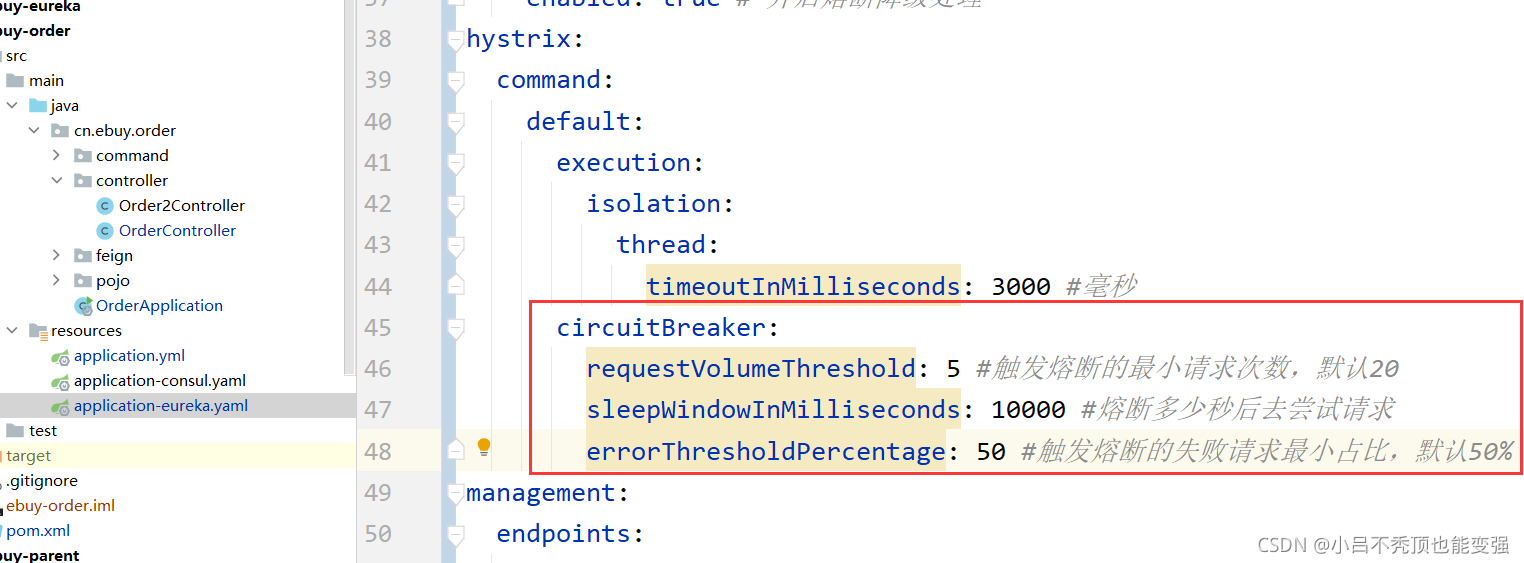
�۶�����Ĭ�ϴ�����ֵ��20������,���ô���������ʱ��ʱ5��,ʱ��̫��,���۲�,Ϊ�˲��Է���,���ǿ���ͨ���������۶ϲ���:
circuitBreaker.requestVolumeThreshold=5
circuitBreaker.sleepWindowInMilliseconds=10000
circuitBreaker.errorThresholdPercentage=50
- requestVolumeThreshold:�����۶ϵ���С�������,Ĭ��20
- errorThresholdPercentage:�����۶ϵ�ʧ��������Сռ��,Ĭ��50%
- sleepWindowInMilliseconds:�۶϶������ȥ��������
- Ȼ����������
��ʼ����
�۶������ڹر�״̬
- ������ȷ�ķ���
- �������ǹر�״̬
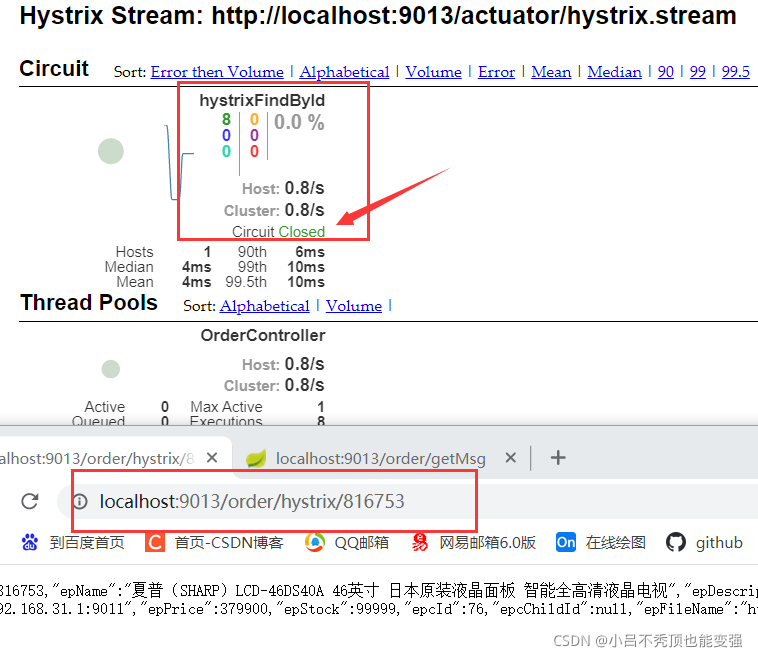
- �������ķ���,�����������С��5��
- �������ǹر�״̬
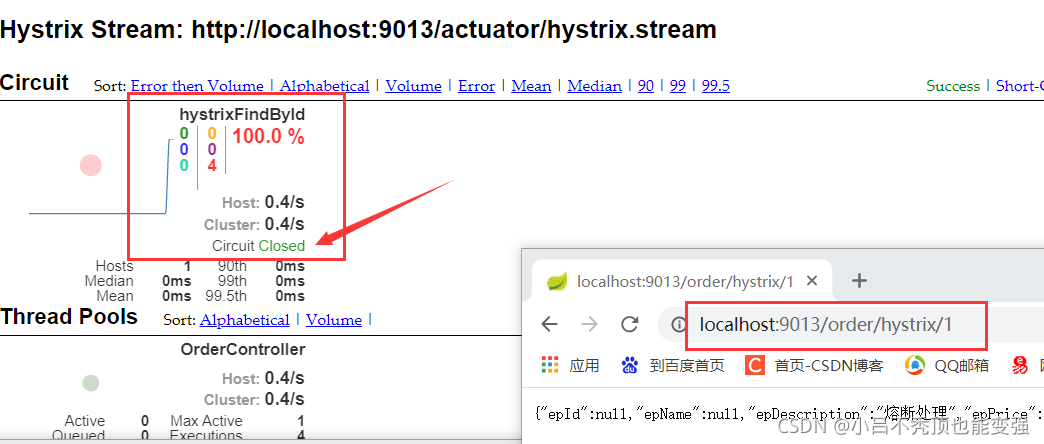
- �������ķ���,��������5��
- ��ʱ�۶�����״̬��Ϊ����״̬,��������ʱ��(5��)
�۶������ڴ�״̬
���۶������뿪��״̬֮��5s��������ȷ�ķ���
������ȷ�ķ���Ҳ���۶ϴ���
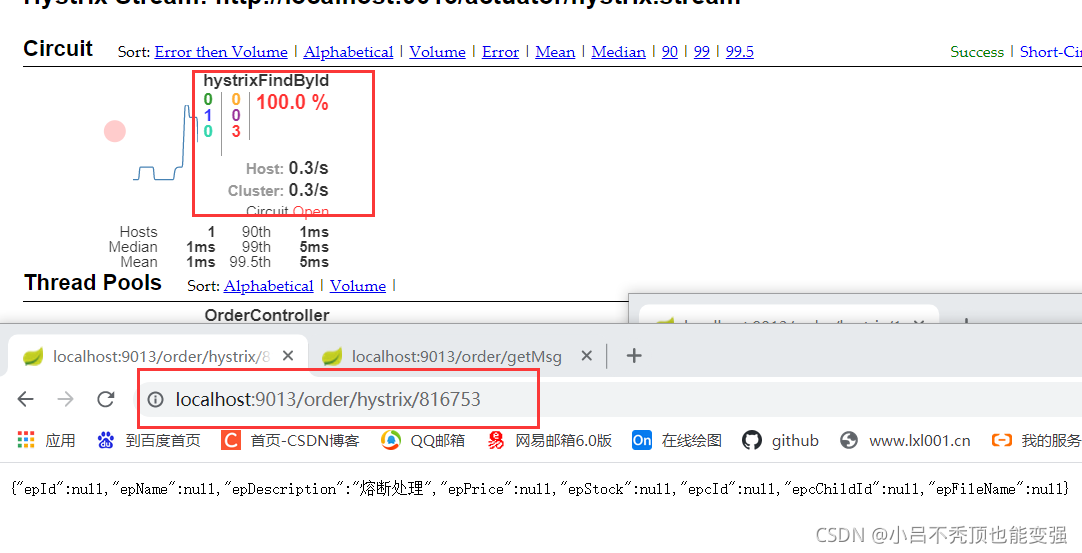
- ���۶������뿪��״̬֮��5s���������ķ���
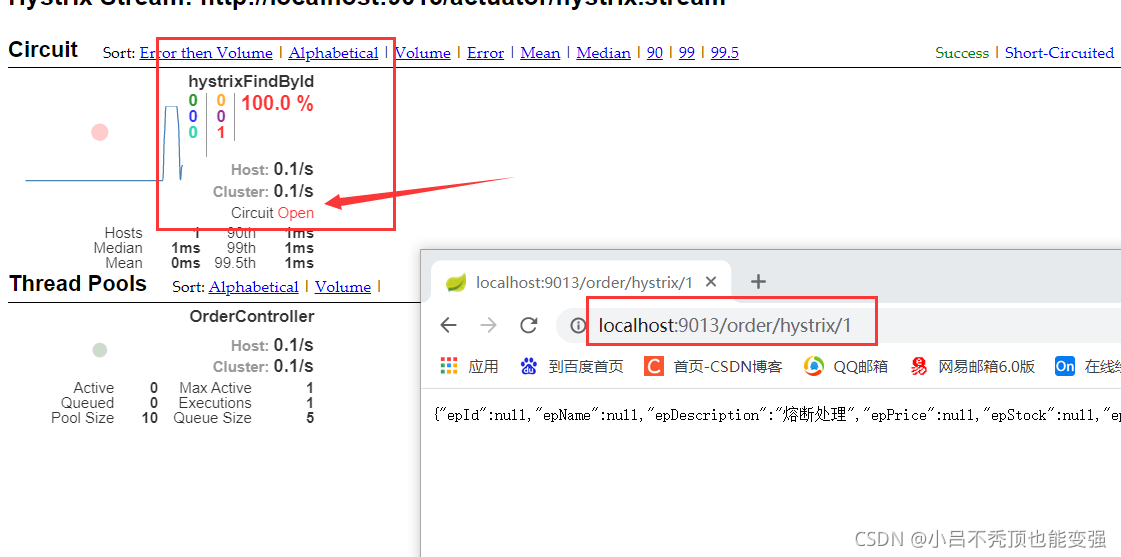
�ܽ�:�۶������ڿ���״̬��,���з��ᱻ����������
�۶������ڰ뿪״̬
- �۶������뿪��״̬֮��5s,����뿪״̬
- ��ʱ������ȷ�ķ���
- ������������,�����۶���״̬��Ϊ�ر�
- �۶������뿪��״̬֮��5s,����뿪״̬
- ��ʱ�������ķ���
- �۶���״̬��Ϊ����״̬,����5��������
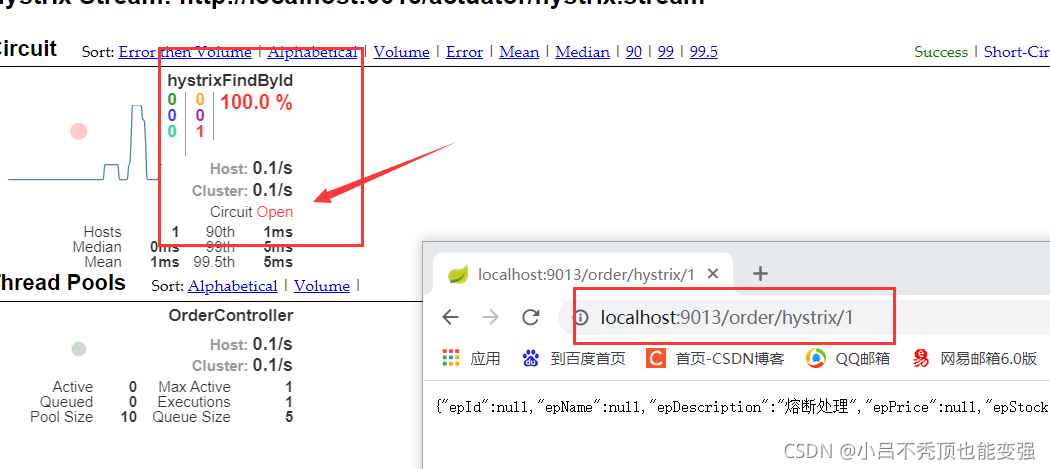
ע��:Ϊ�˷�������,���Ը����������۶���״̬����ͼ������
�ġ���������
��ѧϰ��ǰ���֪ʶ��,����ܹ��Ѿ����߳��Ρ�������һЩ����:��ͬ������һ����в�ͬ�������ַ,�ͻ����ڷ�����Щ����ʱ�����ס��ʮ�������ٸ���ַ,����ڿͻ��˷���˵̫����Ҳ����ά��������ͼ:
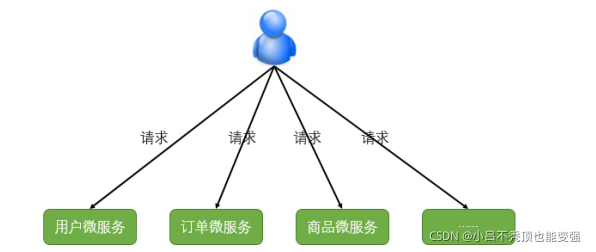
����ÿͻ���ֱ�����������ͨѶ,���ܻ��кܶ�����:
- �ͻ��˻���������ͬ�ķ���,��Ҫά����ͬ�������ַ,���ӿ����Ѷ�
- ��ijЩ�����´��ڿ������������
- �Ӵ�������֤���Ѷ�,ÿ��������Ҫ������֤
���,������Ҫһ����������,���ڿͻ����������֮����м��,���е��ⲿ�����Ⱦ����������ء��ͻ���ֻ��Ҫ�����ؽ���,ֻ֪��һ�����ص�ַ����,�������˿������������ŵ�:
- ���ڼ��
- ������֤
- �����˿ͻ������������֮��Ľ�������
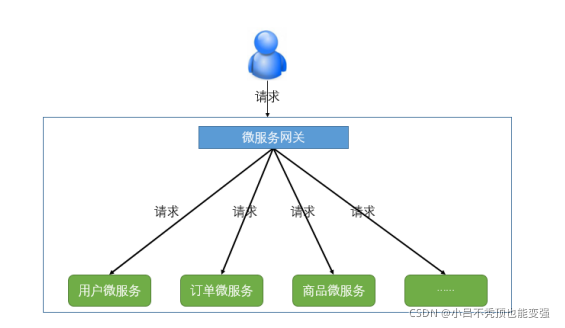
�������صĸ���
ʲô����������
API������һ��������,��ϵͳ�����Ψһ�����API���ط�װ��ϵͳ�ڲ��ܹ�,Ϊÿ���ͻ����ṩһ�����Ƶ�API��API���ط�ʽ�ĺ���Ҫ����,���еĿͻ��˺����Ѷ˶�ͨ��ͳһ�����ؽ�������,�����ز㴦�����еķ�ҵ���ܡ�ͨ��,����Ҳ���ṩREST/HTTP�ķ���API�������ͨ��API-GWע��� ��������
���ú�Ӧ���龰
���ؾ��е�ְ��,��������֤����ء����ؾ��⡢���桢�����Ƭ���������̬��Ӧ��������Ȼ,����Ҫ��ְ�����롰�����ϵ����
������API����ʵ�ַ�ʽ
- Kong
����Nginx+Lua����,���ܸ�,�ȶ�,�ж�����õIJ��(��������Ȩ�ȵ�)���Կ��伴�á�����:ֻ֧��HttpЭ��;���ο���,������չ����;�ṩ����API,ȱ�������õĹܿء����÷�ʽ��
- Zuul
Netflix��Դ,���ܷḻ,ʹ��JAVA����,���ڶ��ο���;��Ҫ������web������,��Tomcat������:ȱ���ܿ�,����̬����;��������϶�;����Http������������Web����,���ܲ���Nginx;
- Traefik
Go���Կ���;��������;�ṩ������Ĺ���:����·��,���ؾ���ȵ�;�ṩWebUI ����:�������ļ�����,���ο����Ѷȴ�;UI������Ǽ��,ȱ�����á���������;
- Spring Cloud Gateway
SpringCloud�ṩ�����ط���
- Nginx+luaʵ��
ʹ��Nginx�ķ���������ؾ����ʵ�ֶ�api�������ĸ��ؾ��⼰�߿��� ����:��ע�����������ر�������չ��
����Nginx������ʵ��
Nginx����

����/�������
�������

�������,�����������ǿͻ���,���ͻ��˷���������,��һ��λ�ڿͻ��˺�ԭʼ������(origin server)֮��ķ�����,Ϊ�˴�ԭʼ������ȡ������,�ͻ������������һ������ָ��Ŀ��(ԭʼ������),Ȼ�������ԭʼ������ת��������õ����ݷ��ظ��ͻ��ˡ��ͻ��˱���Ҫ����һЩ�ر�����ò���ʹ�����������
�������
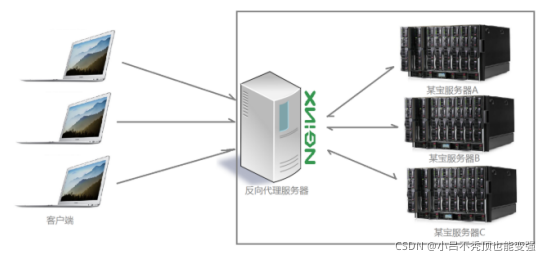
����ͻ��˸����������͵�����,Nginx���������յ�֮��,����һ���Ĺ���ַ����˺�˵�ҵ�������������д����ˡ���ʱ~�������ԴҲ���ǿͻ�������ȷ��,���������������̨�����������IJ�����ȷ��,Nginx���ݵľ���һ�����������ɫ���ͻ�������֪�����Ĵ��ڵ�,����������ⶼ������,�����߲���֪���Լ����ʵ���һ����������Ϊ�ͻ��˲���Ҫ�κ����þͿ��Է��ʡ��������,�����������Ƿ����,������˽���������,��Ҫ���ڷ�������Ⱥ�ֲ�ʽ����������,��������� ���˷���������Ϣ,���ֻ�ǵ�������Ҫһ��������ľ߱�ת�����ܵ�����,��ôʹ��Ngnix��һ��������ѡ����
��������Zuul
Zuul���
ZUUL��Netflix��Դ����������,�����Ժ�Eureka��Ribbon��Hystrix��������ʹ��,Zuul����ĺ�����һϵ�еĹ�����,��Щ����������������¹���:
- ��̬·��:��̬������·�ɵ���ͬ��˼�Ⱥ
- ѹ������:������ָ��Ⱥ������,���˽�����
- ���ط���:Ϊÿһ�ָ������ͷ����Ӧ����,�����ó�����ֵ������
- ��̬��Ӧ����:��Եλ�ý�����Ӧ,����ת�����ڲ���Ⱥ
- ������֤�Ͱ�ȫ: ʶ��ÿһ����Դ����֤Ҫ��,���ܾ���Щ����������Spring Cloud��Zuul����
�����Ϻ���ǿ��
�Zuul���ط�����
�������̵�������
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>Greenwich.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<!--zuul���ص�jar-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-zuul</artifactId>
<version>2.1.0.RELEASE</version>
</dependency>
�������
- @EnableZuulProxy : ͨ�� @EnableZuulProxy ע���Zuul���ܹ���
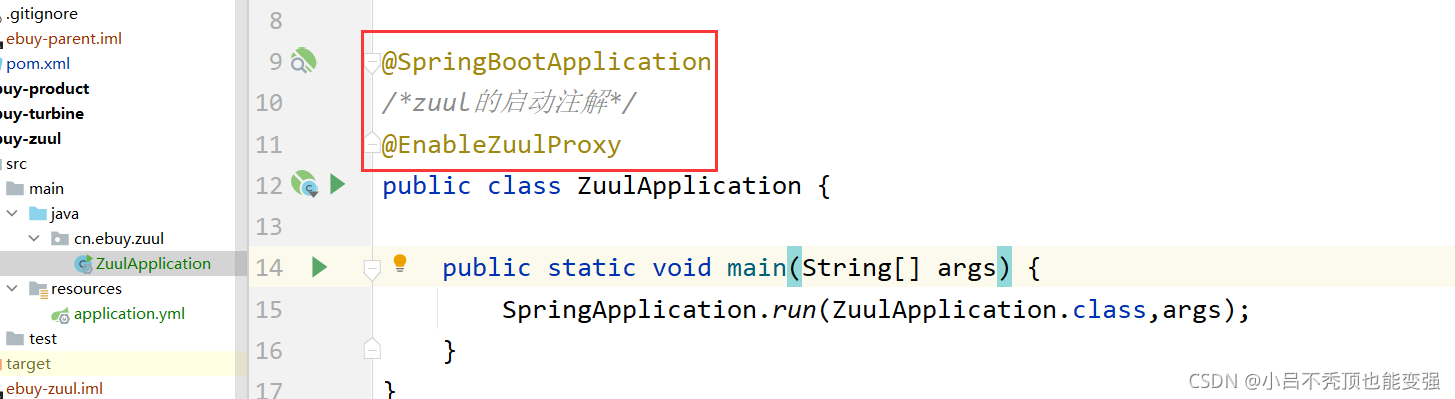
�����
- ���������ļ� application.yml ,��������Ӧ����
server:
port: 9090 #�˿�
spring:
application:
name: ebuy-zuul #��������
logging:
level:
cn.ebuy: DEBUG
Zuul�е�·��ת��
��ֱ�۵�����:��·�ɡ���ָ��������URL,��������䵽��Ӧ�Ĵ���������������ϵ��,Zuul����������е������ݲ�ͬ��URLƥ�����,����ͬ������ת������ͬ����������
��Ӧ������
zuul:
routes:
ebuy-order: #ֻ�Ǹ�����������ļ��еĽڵ�����������·��id,����д
path: /ebuy-order/** # ӳ��·��
url: http://127.0.0.1:9013/ # ӳ��·����Ӧ��ʵ��url��ַ
sensitive-Headers: #Ĭ��zuul������cookie,cookie���ᴫ�����η���,��������Ϊ����ȡ
��Ĭ�ϵĺ�����,��������˾����ͷ��Ϣ�ᴫ�����η���
ebuy-product:
path: /ebuy-product/**
url: http://127.0.0.1:9015/
sensitive-Headers:
����: path: /ebuy-order001/** # ӳ��·��
��ַ������ :http://localhost:9090/ebuy-order001/order/hystrix/816753
��������
��������
���ʲ���

��������·��
����һ�����ɼ�ʮ���ϰٸ��������,����һ��URL����,���ջ�ȷ��һ������ʵ�����д����������ÿ������ʵ���ֶ�ָ��һ��Ψһ���ʵ�ַ,Ȼ�����URLȥ�ֶ�ʵ������ƥ��,��������Ȼ�Ͳ�������
Zuul֧����Eureka���Ͽ���,����ServiceID�Զ��Ĵ�ע�������л�ȡ�����ַ��ת������,�������ĺô���������ͨ�������˵�������Ӧ�õ����з���,���������ӻ��Ƴ�����ʵ����ʱ������Zuul��·�����á�
����Eureka�ͻ�������
������������Ŀ
��������
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
����Eureka�ͻ��˷��ֹ���
����Eureka����,��ȡ������Ϣ
- Eureka����
# Eureka����
eureka:
client:
service-url:
defaultZone: http://127.0.0.1:9890/eureka/,http://127.0.0.1:9880/eureka
lease-expiration-duration-in-seconds: 10 #eureka client����������server�˺�,��Լ����ʱ��(Ĭ��90��)
lease-renewal-interval-in-seconds: 5 #����������Լʱ����
registry-fetch-interval-seconds: 5 # ��ȡ�����б�������:5s
instance:
prefer-ip-address: true # ʹ��ip��ַ�]��
- zuul��������·������
��Ϊ�Ѿ�����Eureka�ͻ���,���ǿ��Դ�Eureka��ȡ����ĵ�ַ��Ϣ,���ӳ��ʱ����ָ��IP��ַ,����ͨ����������������,����Zuul�Ѿ�������Ribbon�ĸ��ؾ���ܡ�
zuul:
routes:
ebuy-order:
path: /ebuy-order/**
serviceId: ebuy-order #����ת������������
ebuy-product:
path: /ebuy-product/**
serviceId: ebuy-product #����ת������������
ע:serviceId: ָ����Ҫת��������ʵ������
���ʲ���
- ��������,��ʼ����
- ���Կ���zuul�Ѿ�ʵ���˸��ؾ���
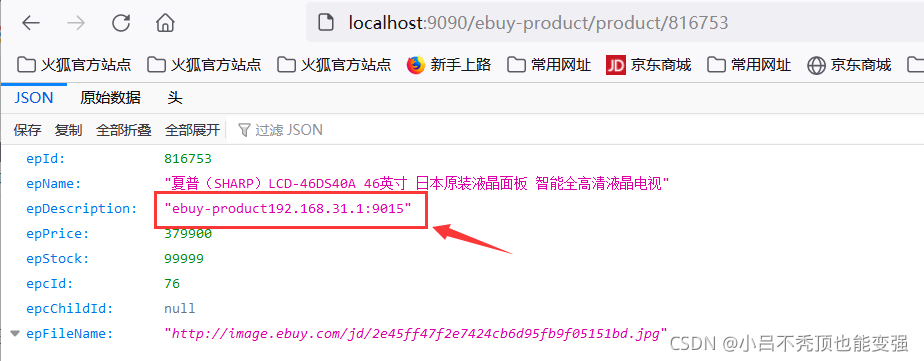
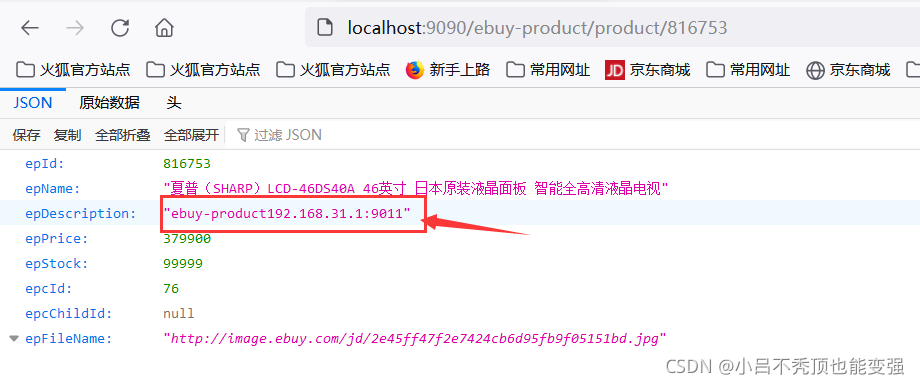
��·������
�ڸղŵ�������,���ǵĹ�����������:
zuul.routes.<route>.path=/xxx/**: ��ָ��ӳ��·����<route>���Զ����·������zuul.routes.<route>.serviceId=/product-service:��ָ����������
������������,���ǵ�<route>·�����������ͷ�������д��һ���ġ����Zuul���ṩ��һ�ּ������:zuul.routes.<serviceId>=<path>
��������ÿ��Լ�Ϊһ��:
zuul:
routes:
ebuy-product: /ebuy-product/** #��һ��ebuy-product��ָ������,�ڶ����ǵ�ַ��Ҫ�����ӳ��·��
ebuy-order: /ebuy-order/**
�����������
���ٽ�ͼչʾ
��������
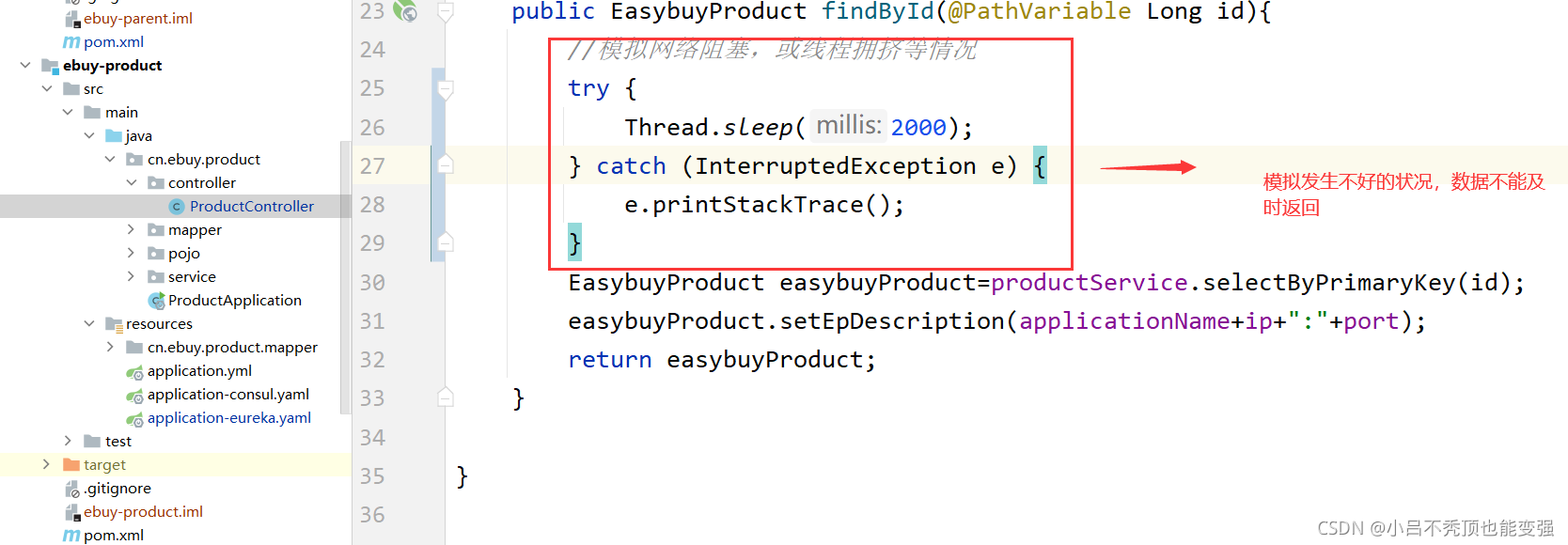
- ģ��߲�������µ�����
- ����,Ȼ���ٴ�ʹ��zuul��·�����ʷ���
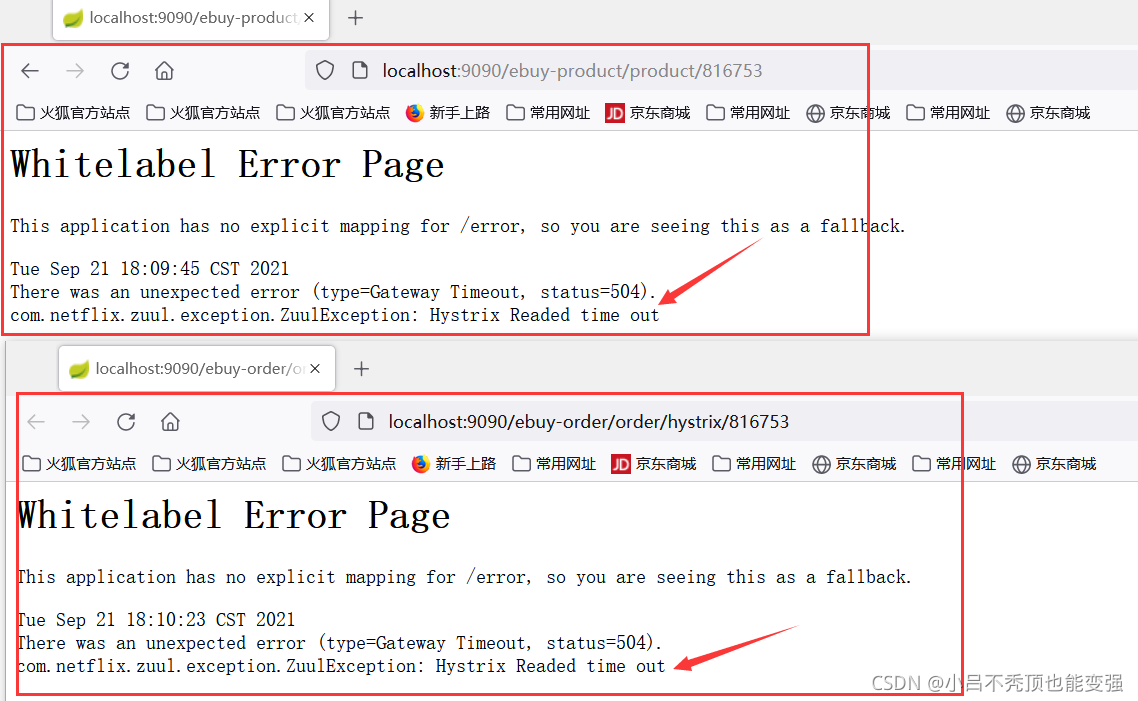
- ������ʾ
com.netflix.zuul.exception.ZuulException: Hystrix Readed time out
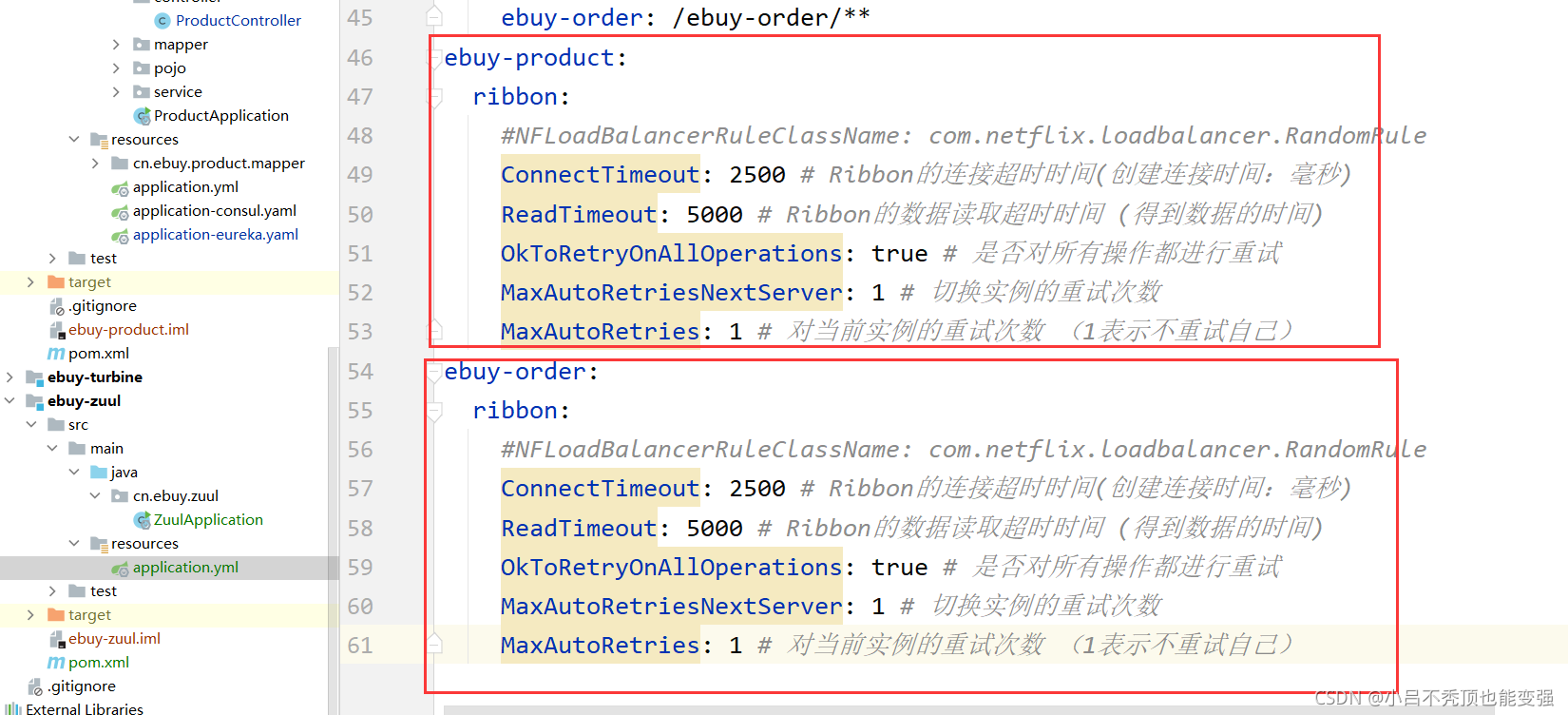
�ع�֮ǰ��������,���Ը�zuul��������(ע����ebuy-zuul��Ŀ)
ebuy-product:
ribbon:
#NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule
ConnectTimeout: 2500 # Ribbon�����ӳ�ʱʱ��(��������ʱ��:����)
ReadTimeout: 5000 # Ribbon�����ݶ�ȡ��ʱʱ�� (�õ����ݵ�ʱ��)
OkToRetryOnAllOperations: true # �Ƿ�����в�������������
MaxAutoRetriesNextServer: 1 # �л�ʵ�������Դ���
MaxAutoRetries: 1 # �Ե�ǰʵ�������Դ��� (1��ʾ�������Լ�)
ebuy-order:
ribbon:
#NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule
ConnectTimeout: 2500 # Ribbon�����ӳ�ʱʱ��(��������ʱ��:����)
ReadTimeout: 5000 # Ribbon�����ݶ�ȡ��ʱʱ�� (�õ����ݵ�ʱ��)
OkToRetryOnAllOperations: true # �Ƿ�����в�������������
MaxAutoRetriesNextServer: 1 # �л�ʵ�������Դ���
MaxAutoRetries: 1 # �Ե�ǰʵ�������Դ��� (1��ʾ�������Լ�)
- Ȼ����������
- ���·��ʲ���
- ������(����ebuy-product��ģ����д���߳�����ע�͵���)
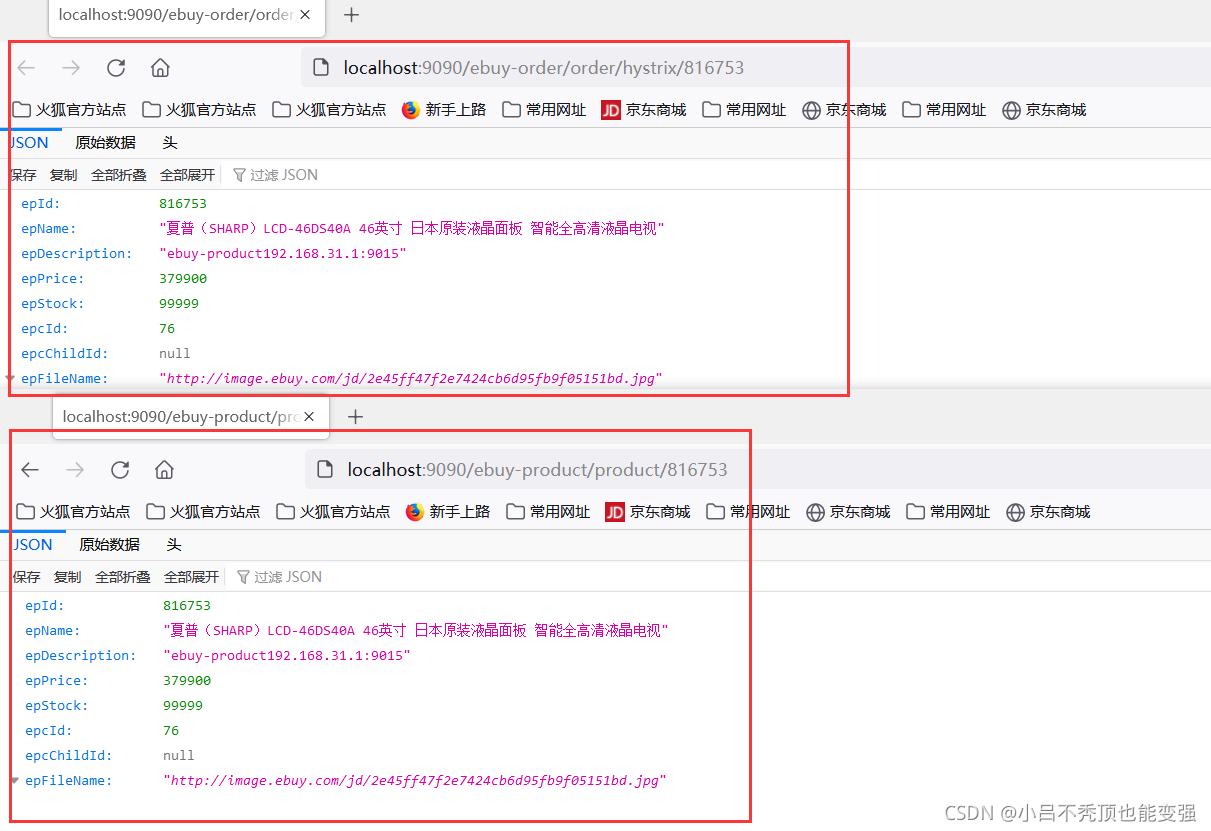
Ĭ�ϵ�·�ɹ���
��ʹ��Zuul�Ĺ�����,���潲���Ĺ����Ѿ����ļ�����������ǵ�����϶�ʱ,����Ҳ�DZȽϷ����ġ����Zuul��ָ����Ĭ�ϵ�·�ɹ���:
- Ĭ�������,һ�з����ӳ��·�����Ƿ�����������
- ���������Ϊ: ebuy-product ,��Ĭ�ϵ�ӳ��·������: /ebuy-product/**
��ô������ʲô��˼��?
��˼����˵������·����������ȫ����Ҫ��(��Ȼǰ������ķ���·����Ҫ��Ӧ����ͬ��)
- ע�͵�·����ص�����
- ���ʷ������
- ������ȫû����