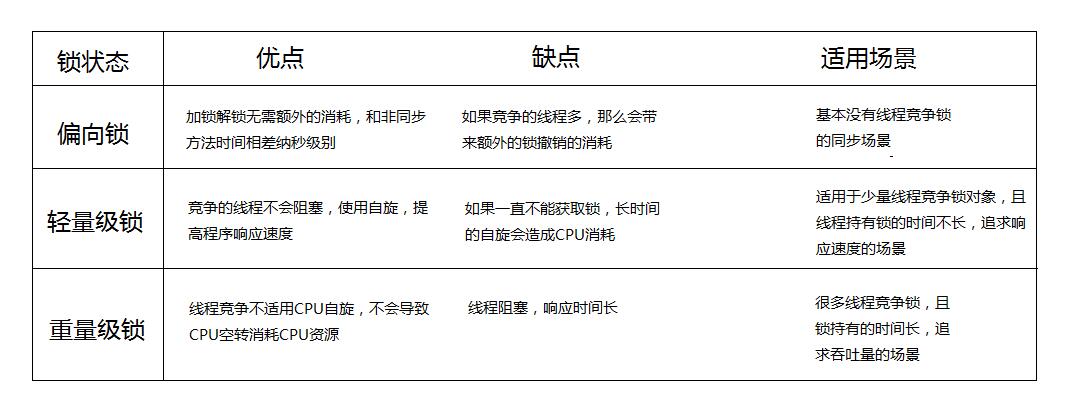
�ܾ�֮ǰд��һƪ����,���������·��������������IJ�����,�������ݺܳ�ֺܶ������dz��ڻ��۵����ɾ��,���߾�����ǰ��Ŀ����ɡ�Դ�벿�ֿɺ���
һ������ͷ
�� JVM ��,�������ڴ��з�Ϊ��������:
- ����ͷ:����ֶ�������ָ����һ�����
- ʵ������:�ⲿ����Ҫ�Ǵ�����������Ϣ,�������Ϣ��
- �������:���������Ҫ�������ʼ��ַ������8�ֽڵ�������,������ݲ��DZ�����ڵ�,������Ϊ���ֽڶ��롣
HotSpot�������,�����һ��OOP&Klass Model����������ʶһ�����������,ע�Ⲣ���������ǵ����ݡ�
- OOP(Ordinary Object Pointer)ָ������ͨ����ָ��������һ��������java����
- ��Klass������������ʵ���ľ������͡�
- ����ÿ���౻JVM���ص�ʱ��,ÿ�����Ӧһ��
instanceKlass,�����ڷ�����,������JVM���ʾ��Java�ࡣ
- ����ÿ���౻JVM���ص�ʱ��,ÿ�����Ӧһ��
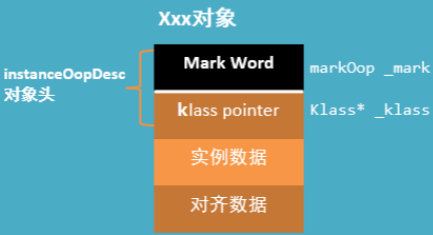
��������Java������,ʹ��new����һ�������ʱ��,JVM�ᴴ��һ��instanceOopDesc����,��������а����˶���ͷ�Լ�ʵ�����ݡ�
������һ�δ���Ϊ�����Ƿ������ǵĶ���ͷ
class Model {
public static int a = 1;
public int b;
public Model(int b) {
this.b = b;
}
}
public static void main(String[] args) {
int c = 10;
Model modelA = new Model(2); //��Ӧһ��instanceOopDesc
Model modelB = new Model(3);
}
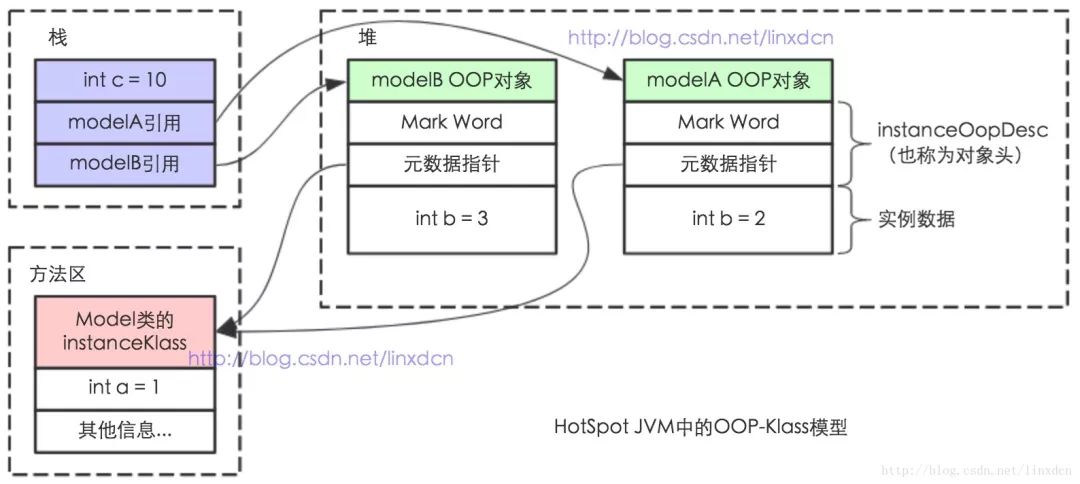
OOP������markWord+Klass+ʵ�����ݡ�
- markWord����synchronized��
- Kclassָ����ʵ�����ݰ�������
�����һ����Java�����OOP&Klassģ��,��Java����ģ�͡�
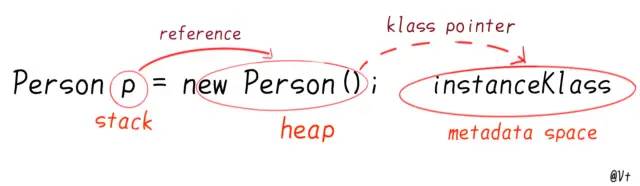
��ͼ��ʶ:
- p��
ջ�� - new Person()��
����,�������˶���ͷ��ʵ������ - �������ͷ���и�Kclass,����JVM���ص�java��,��ָ��
��������ͬһ���͵�java����ָ��ͬһ��Kclass
// ����ͷ,��������������Ļ���
class oopDesc {
friend class VMStructs;
private:
volatile markOop _mark; // mark word
union _metadata {
wideKlassOop _klass; // kclass
narrowOop _compressed_klass;
} _metadata; // Ԫ����
}
1.1 klass pointer
Klass Point���Ƕ���ָ��������Ԫ���ݵ�ָ��,�����ͨ�����ָ����ȷ������������ĸ����ʵ��,Mark Word���ڴ洢��������������ʱ���ݡ������������������,��ô����ͷռ��3���ֿ�(Word),��������Ƿ��������,��ô����ͷռ��2���ֿ���(1word = 2 Byte = 16 bit)
\1. ÿ��Class������ָ��(����̬����)
\2. ÿ�����������ָ��(���������)
\3. ��ͨ���������ÿ��Ԫ��ָ��
��Ȼ,Ҳ�������е�ָ�붼��ѹ��,һЩ�������͵�ָ��JVM�����Ż�,����ָ��PermGen��Class����ָ��( JDK8��ָ��Ԫ�ռ��Class����ָ��)�����ر�������ջԪ�ء���Ρ�����ֵ��NULLָ��ȡ�
������synchonized������ͷ
- ����ͬ������,JVM����
ACC_SYNCHRONIZED��Ƿ���ʵ��ͬ���� - ����ͬ������顣JVM����
monitorenter��monitorexit����ָ����ʵ��ͬ����
��������ͬ������ʽ�ġ�ͬ�������ij������л���һ��
ACC_SYNCHRONIZED��־����ij���߳�Ҫ����ij��������ʱ��,�����Ƿ���ACC_SYNCHRONIZED,���������,����Ҫ�Ȼ�ü�������,Ȼ��ʼִ�з���,����ִ��֮�����ͷż�����������ʱ��������߳�������ִ�з���,����Ϊ����ü��������������ס��ֵ��ע�����,����ڷ���ִ�й�����,�������쳣,���ҷ����ڲ���û�д������쳣,��ô���쳣������������֮ǰ���������ᱻ�Զ��ͷš�����ִ��
monitorenterָ������Ϊ����,ִ��monitorexit����Ϊ�ͷ����� ÿ������ά����һ����¼�ű��������ļ�������δ�������Ķ���ĸü�����Ϊ0,��һ���̻߳����(ִ��monitorenter)��,�ü�����������Ϊ 1 ,��ͬһ���߳��ٴλ�øö��������ʱ��,�������ٴ���������ͬһ���߳��ͷ���(ִ��monitorexitָ��)��ʱ��,���������Լ�����������Ϊ0��ʱ���������ͷ�,�����̱߳���Ի������
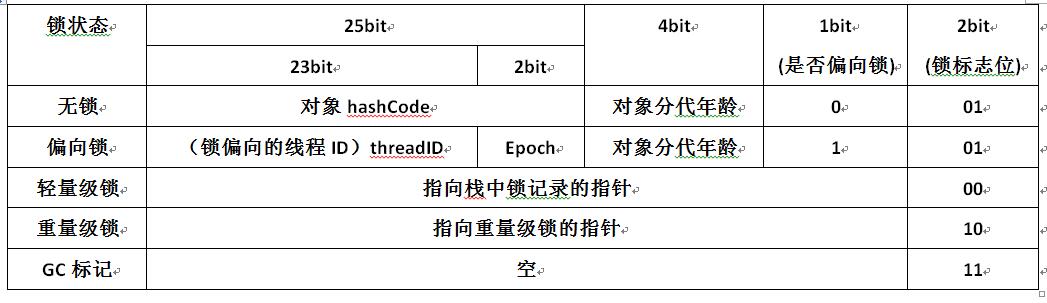
0��mark word
���ǵ�synchronized���������Ĺ���,����ԭ�����Dz�������ͷ��mark word��
mark wordһ����64bit(��64λ�������),��״̬��ÿ��bit�������ͼ
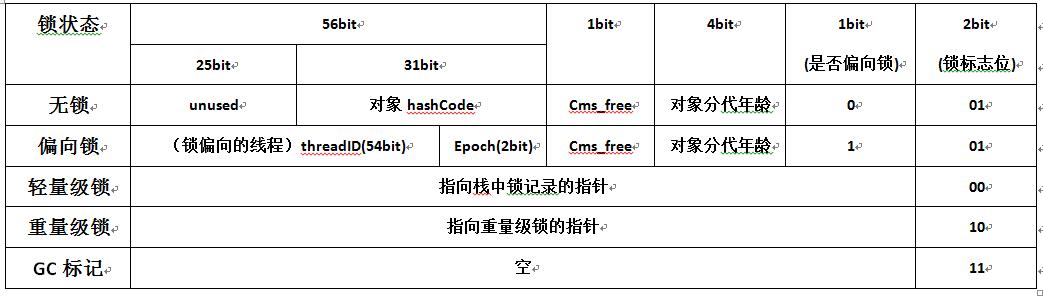
����ͼ,�ؼ��ֶηֱ�ָ�����
- �߳�id
- ջ������¼��ָ��
- ��������monitor��ָ��
��Դ���и��ֶε�bit:
// markOop.hpp
public:
// Constants
enum {
age_bits = 4, // Ϊʲô���������15,������Ϊֻ����1111
lock_bits = 2,
biased_lock_bits = 1,
max_hash_bits = BitsPerWord - age_bits - lock_bits - biased_lock_bits,
hash_bits = max_hash_bits > 31 ? 31 : max_hash_bits,
cms_bits = LP64_ONLY(1) NOT_LP64(0),
epoch_bits = 2
};
// ��״̬��ö��:
enum {
locked_value = 0,//�������� 000
unlocked_value = 1,// ���� 001
monitor_value = 2,//�������� 010
marked_value = 3,//GC��� 011
biased_lock_pattern = 5//��ƫ�� 101
};
��
32λ�������,Mark Word��32bit��С��
1 ����
����״̬�¾�����������ĵ�һ��,��ʱ����մ�����
����״̬λΪ0 01
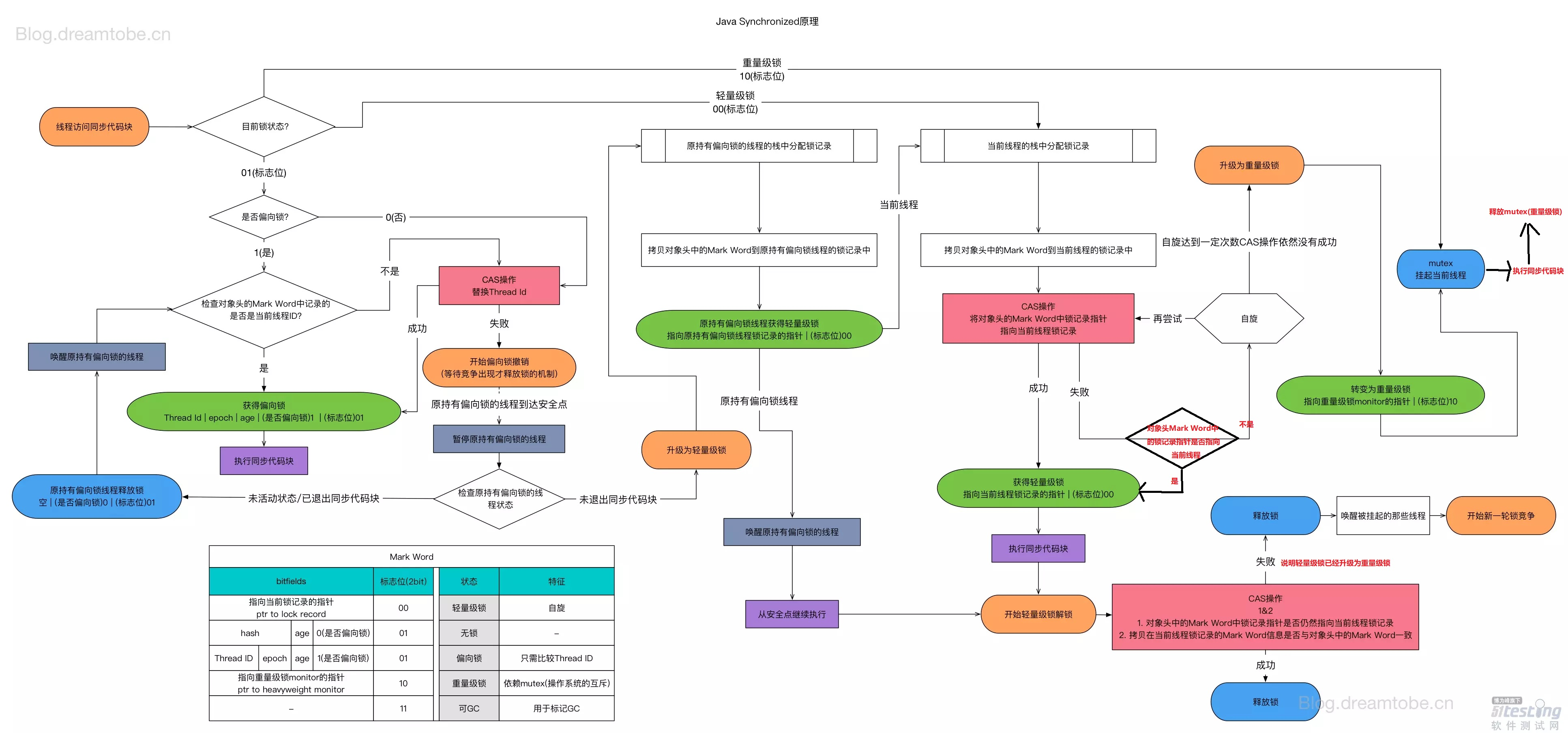
2 ƫ����
����״̬λΪ1 01
2.1 ��������ƫ����
ƫ�������һ��������֮��ʹ�ò���ͻ�����,���õȴ�
ΪʲôҪ����ƫ����?:�ڴ���������,�����������ڶ��߳̾���,����������ͬһ�̶߳�λ��,Ϊ�����̻߳�����Ĵ��۸���,������ƫ������
ƫ�����ġ�ƫ��,����ƫ�ĵġ�ƫ����ƫ̻�ġ�ƫ��,������˼���������ƫ���ڵ�һ����������߳�,���ڶ���ͷ�洢��ƫ����߳�ID,�Ժ���߳̽�����˳�ͬ����ʱֻ��Ҫ����Ƿ�Ϊƫ����������־λ�Լ�ThreadID���ɡ�
��ʼ��ȡ��:(�������ͼ��https://img-blog.csdnimg.cn/20190323140321501.png)
1)�ȿ�����λ:������λ�Ƿ�01(����������ƫ����),�ǵĻ�����������λ��ƫ����λ
2)�������:ƫ����λΪ0,��ֱ��ȥCAS�����������1�����ǵ�ǰ�߳�ID,��ôҲ��ȡ�ɹ���
3)����ʱ��CAS����ƫ����:ͨ��CAS��mark word��Thread ID��0��Ϊ��ǰ�̵߳ġ�
- ���CAS���߳�ID�ɹ�,���ƫ����,ִ��ͬ������
- ���ø��߳��´ν�����ʱ,��Ϊ���Լ����߳�ID,ֱ�ӻ�ȡ������(����,Ч�ʸ�)��
- ���CASʧ��,˵���Լ�ջ֡�ﱣ���mark word�����Ѿ��Ͷ���ͷ��mark word������,���������Ƿ���Ҫ����Ϊ��������(�ϸ��߳̿��������˵���û�в���(ƫ�������������ͷ���),�����ȿ�ǰ���߳��Ƿ���,������ȥ��ǰ�̵߳�ջ֡��Ϣ(��ջ֡����֪�����߳�ִ�е�����,ջ���Ƿ��и÷��������),)
- ��ͣ���������߳�,���ԭ�߳�����/�˳�ͬ����û��,
- �˳��˵Ļ��߳�IDλ����Ϊ0,������CAS��
- û���˳�,������������
- ��ͣ���������߳�,���ԭ�߳�����/�˳�ͬ����û��,
��:��ȡ��ƫ����,ִ�д���
��������λ��1(ƫ����)-���Thread ID�Ƿ����Լ�
��:CAS���Դ�0���Լ�,��Ȼʧ��,���dz���ƫ����,������������(����ʽ������֮ǰ������һ��ԭ�߳�״̬)
01
��������λ��0-CAS��0����ǰ�߳�
�ܵ���˵���ǿ��̺߳�ջ֡
2.2 ƫ����������
��֤ƫ�����Ƿ���
���߳�1���ʴ���鲢��ȡ������ʱ,����java����ͷ��ջ֡�м�¼ƫ�������threadID,��Ϊƫ�������������ͷ���,����Ժ��߳�1�ٴλ�ȡ����ʱ��,��Ҫ�Ƚϵ�ǰ�̵߳�threadID��Java����ͷ�е�threadID�Ƿ�һ��,���һ��(�����߳�1��ȡ������),������ʹ��CAS������������;�����һ��(�����߳�,���߳�2Ҫ����������,��ƫ�������������ͷ���˻��Ǵ洢���߳�1��threadID),��ô��Ҫ�鿴Java����ͷ�м�¼���߳�1�Ƿ���,���û�д��,��ô����������Ϊ����״̬,�����߳�(�߳�2)���Ծ�����������Ϊƫ����;������,��ô���̲��Ҹ��߳�(�߳�1)��ջ֡��Ϣ,���������Ҫ�����������������,��ô��ͣ��ǰ�߳�1,����ƫ����,����Ϊ��������,����߳�1 ����ʹ�ø�������,��ô��������״̬��Ϊ����״̬,����ƫ���µ��̡߳�
ƫ��������
��ʱ��ʹ�÷�����ײ��,��Ҫһ���ȴ������,�Ǿͽ������������IJ��衣
����ƫ������ײ��ʱ��,����Ҫ������������,������֮ǰ,Ҫ�Ƚ���ƫ�����ij���
������Ҫ��:
\1. ƫ�����ij�����������ȴ�ȫ�ְ�ȫ��
\2. ��ͣӵ��ƫ�������߳�,�ж��������Ƿ��ڱ�����״̬,���ƫ��λ��1�Ļ��ͱ��0
\3. ����ƫ����,�ָ�������(��־λΪ 01)����������(��־λΪ 00)��״̬
��ʱ˭��û��ƫ����
2.3 ƫ����������
ƫ��������ֻ��һ���߳�ִ��ͬ����ʱ��һ���������,������һ���̷߳������ͬһ���������ƫ����������ߴ���ͬ���������ij������ܡ�
��ͬ����һ������Ч��Ȩ�����ʵ��Ż�,Ҳ����˵,������һ�����ǶԳ�����������,��������д�����������DZ������ͬ���̷߳��ʱ����̳߳�,��ƫ��ģʽ���Ƕ���ġ�
- �ر�ƫ����:����ͨ��
-XX:-UseBiasedLocking = false������; - ƫ������1.6֮����Ĭ�Ͽ�����,����Ӧ�ó�������������֮��ż���,����ʹ��
-XX:BiasedLockingStartupDelay=0�����ر��ӳ�,���ȷ��Ӧ�ó�����������ͨ������´��ھ���״̬,���Թر�ƫ������ - 1.5���ǹرյ�,��Ҫ�ֶ�����������
xx:-UseBiasedLocking=true��
2.4 ����
| �߳�1�����Լ�ƫ��������� | ����ͷ-Mark word |
|---|---|
| ����ͬ���� A,��� Mark ���Ƿ����߳� ID | 101(������ƫ��) |
| ���Լ�ƫ���� | 101(������ƫ��)���� hashCode |
| �ɹ� | 101(������ƫ��)�߳�ID |
| ִ��ͬ���� A | 101(������ƫ��)�߳�ID |
| ����ͬ���� B,��� Mark ���Ƿ����߳� ID | 101(������ƫ��)�߳�ID |
| ���Լ����߳� ID,�����Լ���,������������� | 101(������ƫ��)�߳�ID |
| ִ��ͬ���� B | 101(������ƫ��)�߳�ID |
| ִ����� | 101(������ƫ��)���� hashCode |
3 ��������
������������ָ��ջ������¼��ָ���
ƫ����������������
�м�����������һ��:
����ͷ��Mark Word
�̵߳�����¼Lock Record��
��������ÿ���̶߳����Mark Word�����������߳���,��Ҫ����˭����MarkWord�е�ָ��ָ���Լ�
�����������ͷŸ�����,�������ͷ�ʱ��ÿ�����ͷ���Mark Word�Ƿ�ָ���Լ�(�����Ѿ�����������),���Ҫ�жϵ�ǰ�߳�Mark Word����Ϣ�����ͷ��Mark Word��Ϣ�Ƿ�һ��(��һ�������Ķ�������)
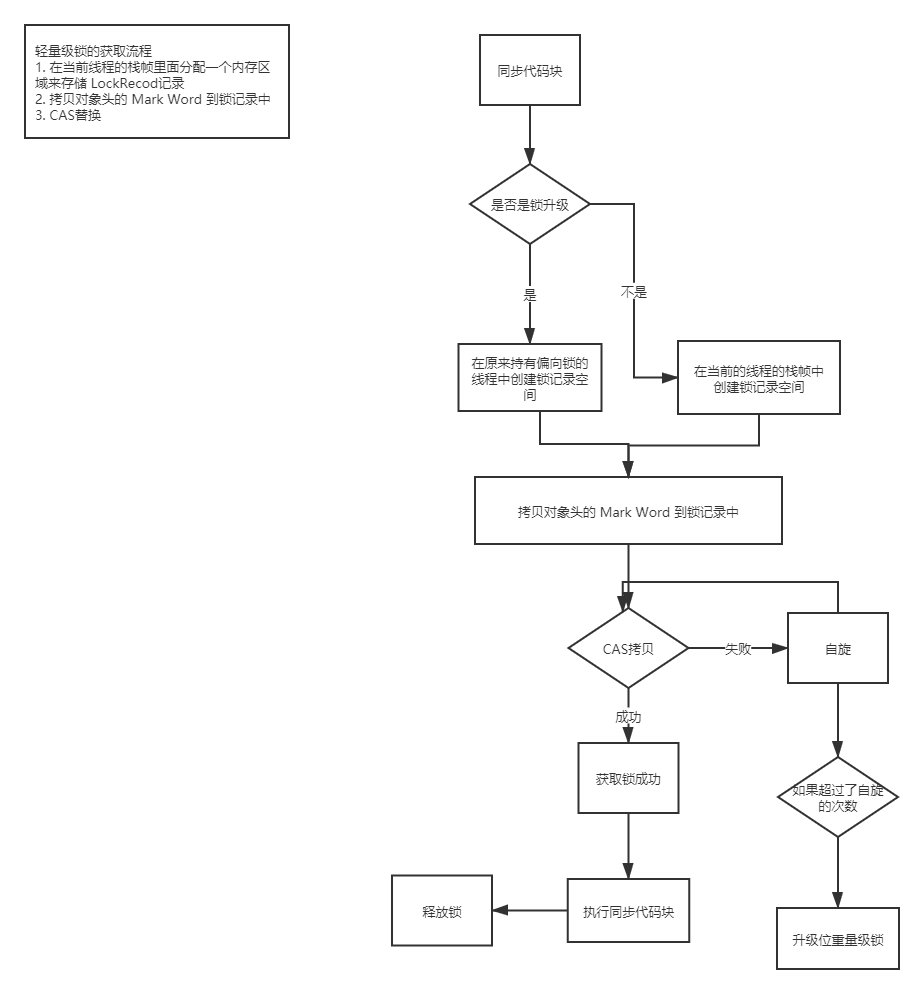
��(�ر�ƫ��������)����(����߳̾���ƫ��������ƫ��������Ϊ��������),��᳢�Ի�ȡ��������,�䲽������: ��ȡ��������
- 1���жϵ�ǰ�����Ƿ�������״̬(
hashcode...-0-01),���������,��JVM���Ƚ��ڵ�ǰ�̵߳�ջ֡�н���һ����Ϊ����¼(Lock Record)�Ŀռ�,���ڴ洢������Ŀǰ��Mark Word������(���ջ�еĿ�����Displaced Mark Word),�������Mark Word���Ƶ�ջ֡�е�Lock Record��,��Lock Record�е�ownerָ��ǰ����(��ջָ֡�����ͷ,object,Ҳ���ǻ���������,��������߳̾�֪���Dz����Լ���������)������ִ�в���(3);- Mark Word�ڶ���ͷ��,Displaced Mark Word��ջ֡��,Lock Record��Displaced Mark Word��,owner��Lock Record��
- 2��JVM����
CAS�������Խ�����ͷ��Mark Word(�ij���2λ��bit)����Ϊָ��Lock Record��ָ��(�Ӷ���ͷָ��ջ֡),����ɹ���ʾ��������,������־λ���00(��ʾ�˶�������������״̬),ִ��ͬ��������;���ʧ����ִ�в���(3); - 3�����ǰ��ִ�гɹ���,��ô��ȥִ��ҵ������ˡ����1��2��ʧ��,���жϵ�ǰ�����
Mark Word�Ƿ�ָ��ǰ�̵߳�ջ֡,��������ʾ��ǰ�߳��Ѿ����е�ǰ�������,��ֱ��ִ��ͬ�������;����ֻ��˵�����������Ѿ��������߳���ռ��,��ʱ����������Ҫ����Ϊ��������,����ͷ������־λ���10(������������),����ȴ����߳̽����������״̬��
����
�������������:
- �߳�1��ȡ��������ʱ���Ȱ�������Ķ���ͷMarkWord����һ�ݵ��߳�1��ջ֡�д��������ڴ洢����¼�Ŀռ�(��ΪDisplacedMarkWord),Ȼ��ʹ��CAS�Ѷ���ͷ�е������滻Ϊ�߳�1�洢������¼(DisplacedMarkWord)�ĵ�ַ;
- ������߳�1���ƶ���ͷ��ͬʱ(���߳�1CAS֮ǰ),�߳�2Ҳ����ȡ��,�����˶���ͷ���߳�2������¼�ռ���,�������߳�2CAS��ʱ��,�����߳�1�Ѿ��Ѷ���ͷ����,�߳�2��CASʧ��,��ô�߳�2�ͳ���ʹ�����������ȴ��߳�1�ͷ�����
- �������������ʱ��̫��Ҳ����,��Ϊ������Ҫ����CPU��,��������Ĵ����������Ƶ�,����10�λ���100��,����������������߳�1��û���ͷ���,�����߳�1����ִ��,�߳�2���������ȴ�,��ʱ����һ���߳�3�����������������,��ô���ʱ�����������ͻ�����Ϊ�������������������ѳ���ӵ�������̶߳�����,��ֹCPU��ת��

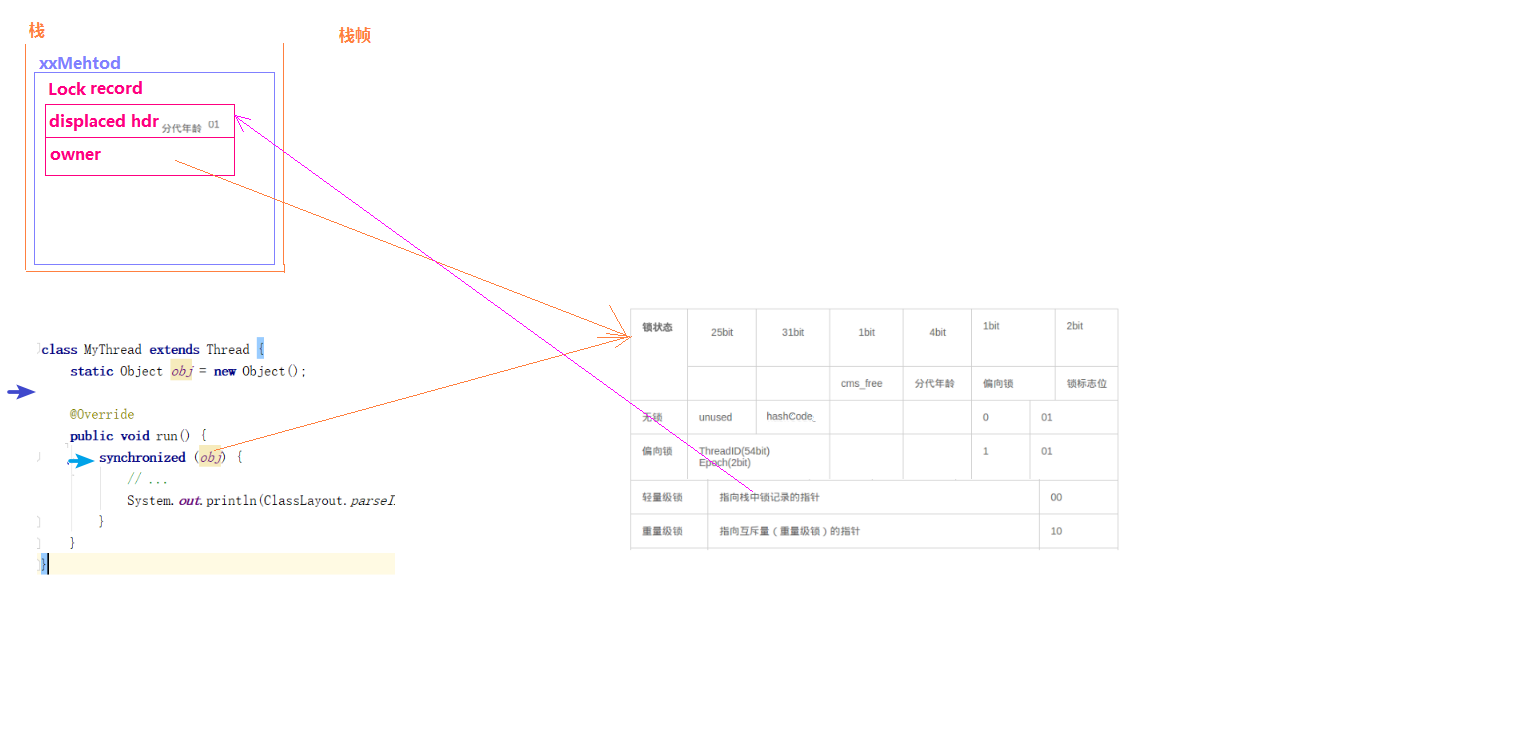
����
�龰:
����ȥѧУ,һ��·�Ƕ�·��·��,һ��·����·��·��(��һ��Զ),��ѡ�����ĸ�?
��:��һ��Զ�ıȽ�ʡʱʡ��,��Ϊ��������һ�����űȽϷ���
�����������ǵ���������������̲߳���,�����̳߳�������ʱ��Ҳ�������龰(��û����,�Ƿ�����ײ��,���ǵȻ�ͻ�ȡ����,��ת��������)����Ϊ�����߳���ҪCPU���û�̬ת���ں�̬,���۽ϴ�,����ո���������������ͱ��ͷ���,��������۾��е�ò���ʧ��,������ʱ��ɴ��������߳�,���������ŵȴ����ͷš�
����������:
- JDK1.6֮ǰ:����������������������ʱ�������Ϊ��������,���������������ܿ�����,����Ӧ�þ�����������Ϊ�������������Դ�����������Ϊ��������ʱ������һ��,��������Ϊ��������
- JDK1.6��:������ ������(Ĭ�Ͽ���,Ĭ����������Ϊ
10)����Ӧ���������������������ֻ���ƫ���������������ȼ����������������Ŀ�����
���������IJ���:
-XX:-UseSpinning�ر�������(1.6��Ĭ�Ͽ���)-XX:preBlockSpin:������������(Ĭ��10��)- ����Ӧ������:�������������Զ��ı���������
ΪʲôҪ����:��Ϊ�߳��л������ĺ�ʱ,�̵߳������ͻ�����ҪCPU���û�̬תΪ����̬�����cas������ֱ��������һ����߳�����ʱ��ܶ���,û��Ҫ����,��һ�ἴ�ɡ���ν��������������֮ǰѭ������cas����,ʵ��cas����������
java���߳���ӳ�䵽����ϵͳԭ���߳�֮�ϵ�,���Ҫ��������һ���߳̾���Ҫ����ϵͳ����,��Ҫ���û�̬�����̬֮���л�,�����л������Ĵ�����ϵͳ��Դ,��Ϊ�û�̬���ں�̬���и���ר�õ��ڴ�ռ�,ר�õļĴ�����,�û�̬�л����ں�̬��Ҫ���ݸ�����������������ں�,�ں�Ҳ��Ҫ�������û�̬���л�ʱ��һЩ�Ĵ���ֵ��������,�Ա��ں�̬���ý������л����û�̬����������
- ����߳�״̬�л���һ����Ƶ����ʱ,�⽫�����ĺܶ�CPU����ʱ��;
- ���������Щ��Ҫͬ���ļĴ����,��ȡ������ĺ�ʱ���û�����ִ�еĺ�ʱ��Ҫ��,����ͬ��������Ȼ�dz����ġ�
����Ӧ������
��JDK 6������������Ӧ��������������Ӧ��ζ��������ʱ�䲻�ٹ̶���,������ǰһ����ͬһ�����ϵ�����ʱ�估����ӵ���ߵ�״̬�������������ͬһ����������,�����ȴ��ոճɹ���ù���,���ҳ��������߳�����������,��ô������ͻ���Ϊ�������Ҳ���п����ٴγɹ�,�����������������ȴ�������Ը�����ʱ��,����100��ѭ��������,�������ij����,�������ٳɹ���ù�,�����Ժ�Ҫ��ȡ�����ʱ������ʡ�Ե���������,�Ա����˷Ѵ�������Դ����������Ӧ����,���ų������к����ܼ����Ϣ�IJ�������,������Գ�������״��Ԥ��ͻ�Խ��Խȷ,̓����ͻ���Խ��Խ���������ˡ�
- ���ƽ������С��CPUs��һֱ����
- ����г���(CPUs/2)���߳���������,������߳�ֱ������
- ��������������̷߳���Owner�����˱仯���ӳ�����ʱ��(��������)���������
- ���CPU���ڽڵ�ģʽ��ֹͣ����
- ����ʱ���������CPU�Ĵ洢�ӳ�(CPU A�洢��һ������,��CPU B��֪�������ֱ�ӵ�ʱ���)
- ����ʱ���ʵ������߳����ȼ�֮��IJ���
���ж������,������߳�һ�����ij�������������ʱ��,����������Ὣ��Щ�̴߳洢�ڲ�ͬ�������С�
- Contention List:��������,�������������߳����ȱ������������������;
- Entry List:Contention List����Щ���ʸ��Ϊ��ѡ��Դ���̱߳��ƶ���Entry List��;
- Wait Set:��Щ����wait�������������̱߳�����������;
- OnDeck:����ʱ��,���ֻ��һ���߳����ھ�������Դ,���̱߳���ΪOnDeck;
- Owner:��ǰ�Ѿ���ȡ������Դ���̱߳���ΪOwner;
- !Owner:��ǰ�ͷ������̡߳�
JVMÿ�δӶ��е�β��ȡ��һ������������������ѡ��(OnDeck),���Dz��������,ContentionList�ᱻ�����IJ����߳̽���CAS����,Ϊ�˽��Ͷ�β��Ԫ�صľ���,JVM�Ὣһ�����߳��ƶ���EntryList����Ϊ��ѡ�����̡߳�Owner�̻߳���unlockʱ,��ContentionList�еIJ����߳�Ǩ�Ƶ�EntryList��,��ָ��EntryList�е�ij���߳�ΪOnDeck�߳�(һ�������Ƚ�ȥ���Ǹ��߳�)��Owner�̲߳���ֱ�Ӱ������ݸ�OnDeck�߳�,���ǰ���������Ȩ������OnDeck,OnDeck��Ҫ���¾�������������Ȼ������һЩ��ƽ��,�����ܼ��������ϵͳ��������,��JVM��,Ҳ������ѡ����Ϊ��֮Ϊ�������л�����
OnDeck�̻߳�ȡ������Դ����ΪOwner�߳�,��û�еõ�����Դ����Ȼͣ����EntryList�С����Owner�̱߳�wait��������,��ת�Ƶ�WaitSet������,ֱ��ij��ʱ��ͨ��notify����notifyAll����,�����½�ȥEntryList�С�
����ContentionList��EntryList��WaitSet�е��̶߳���������״̬,���������ɲ���ϵͳ����ɵ�(Linux�ں��²���pthread_mutex_lock�ں˺���ʵ�ֵ�)��
- Java 6 ֮��������������Ӧ��
- Java 7 ֮���ܿ����Ƿ�����������
�����������ͷ�
�����������ͷ�Ҳ��ͨ��CAS���������е�,��Ҫ��������:
- ȡ���ڻ�ȡ��������������
Displaced Mark Word(�����Լ��߳�ջ֡�и��ƹ�mark word)�е����ݡ� - ��CAS������ȡ���������滻��ǰjava�����Mark Word��,����ɹ�,��˵���ͷ����ɹ�,����ִ��(3);
- ���CAS�����滻ʧ��,˵���������̳߳��Ի�ȡ����(�����˸�Ϊ
10��),����Ҫ������������Ҫ��������Ϊ����������
4����������
����������Mark Word�Ͳ�������,��Ҫ����monitor���γ�����������,�ڴ�ͬʱMark Word��Ӧ��λҲ��monitorָ����
����:�ñȵȺ��ʱ�����Dz���Ϩ��,��Ϩ���൱������(�ȴ�ʱ����˻���),Ϩ�����൱������(�ȴ�ʱ�䳤�˻���)
������ռ�� CPU ʱ��,���� CPU ���������˷�,��� CPU �������ܷ������ơ�����һֱ����Ҳ����,����Ҫ�����ͷ�CPU������
��������������������
monitor
monitor������������Ķ���
����������monitorʵ��,���߳̾�monitor��,�ò���monitor���Ļ���������ӵ��monitor�����߳��ͷŵ�ʱ��ỽ�������������߳�����������
synchronized�����ķ���������
{
monitorenter;
ҵ��;
monitorexit;
}
Synchronize��ʵ��ԭ��,������ͬ����������ͬ�������,������ACC_SYNCHRONIZED����monitorenter��monitorexit���ǻ���Monitorʵ�ֵ�
- ͬ�������:
monitorenterָ����뵽ͬ�������Ŀ�ʼλ��,monitorexitָ����뵽ͬ�������Ľ���λ��,JVM��Ҫ��֤ÿһ��monitorenter����һ��monitorexit��֮���Ӧ���κζ�����һ��monitor��֮�����,����һ��monitor������֮��,������������״̬���߳�ִ�е�monitorenterָ��ʱ,���᳢�Ի�ȡ��������Ӧ��monitor����Ȩ,�����Ի�ȡ�������; - ͬ������:�������Ƿ������η��ϵ�
ACC_SYNCHRONIZEDʵ�֡�synchronized������ᱻ�������ͨ�ķ������úͷ���ָ����:invokevirtual��areturnָ��,��VM�ֽ�����沢û���κ��ر��ָ����ʵ�ֱ�synchronized���εķ���,������Class�ļ��ķ������н��÷�����access_flags�ֶ��е�synchronized��־λ��1,��ʾ�÷�����ͬ��������ʹ�õ��ø÷����Ķ����÷���������Class��JVM���ڲ������ʾKlass��Ϊ������(ժ��:http://www.cnblogs.com/javaminer/p/3889023.html)
�̳߳��Ի�ȡmonitor������Ȩ,�����ȡʧ��˵��monitor�������߳�ռ��,���̼߳��뵽��ͬ��������,�ȴ������߳��ͷ�monitor,�������߳��ͷ�monitor��,�п��ܸպ����߳�����ȡmonitor������Ȩ,��ôϵͳ�Ὣmonitor������Ȩ������߳�,������ȥ����ͬ�����еĵ�һ���ڵ�ȥ��ȡ,����synchronized�Ƿǹ�ƽ��������̻߳�ȡmonitor�ɹ�����뵽monitor��,���ҽ��������+1��
����������,��һ���߳���Ҫִ��һ�α�synchronizedȦ������ͬ���������������ʱ,���̵߳��Ȼ�ȡ��synchronized���εĶ����Ӧ��monitor��
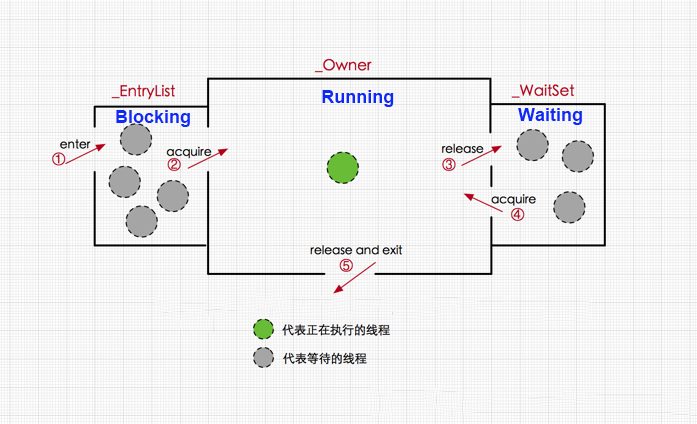
monitor���������Ŷ�������������������ͨ��synchronized���η�����JVM��ҪΪ���ǵ�ij������������monitor����ÿ���̶߳���������ObjectMonitor�����б�,�ֱ�Ϊfree��used�б���ͬʱJVM��Ҳά����global locklist�����߳���ҪObjectMonitor����ʱ,���ȴ��߳�������free��������,��������ʹ��,�����������global list�����롣
ObjectMonitor() {
_count = 0; //������¼�ö����̻߳�ȡ���Ĵ���
_waiters = 0;
_recursions = 0; //�����������
_owner = NULL; //ָ�����ObjectMonitor������߳�
_WaitSetLock = 0 ;
_WaitSet = NULL; // .wait()����//����wait״̬���߳�,�ᱻ���뵽_WaitSet
_EntryList = NULL ; // ���ڵȴ���block״̬���߳�,�ᱻ���뵽���б�
}
�Ŷ�����
- ������߳�ͬʱ���ʸ÷���,��ô��Щ�̻߳��ȱ��Ž�
_EntryList����,��ʱ�̴߳���blocking����״̬ - ��һ���̻߳�ȡ����ʵ������ļ�����(monitor)��,��ô�Ϳ��Խ���running״̬,ִ�з���,��ʱ,ObjectMonitor�����
_ownerָ��ǰ�߳�,_count��1��ʾ��ǰ��������һ���̻߳�ȡ - ��running״̬���̵߳���wait()����,��ô��ǰ�߳��ͷ�monitor����,����waiting״̬,ObjectMonitor�����
_owner��Ϊnull,_count��1,ͬʱ�߳̽���_WaitSet����,ֱ�����̵߳���notify()�������Ѹ��߳�,����߳����»�ȡmonitor�������_Owner�� - �����ǰ�߳�ִ�����,��ôҲ�ͷ�monitor����,����waiting״̬,ObjectMonitor�����
_owner��Ϊnull,_count��1
ͬʱ Entrylist���Ϻ� Waitsets�����е��̻߳��������״�������̻߳�����ں˵���״̬,��Ϊ����״̬��ͨ�� Linux�� pthread_ mutex_lock��ʵ�ֵ�,�����߳�Ҫ�������ͻᷢ���û�̬���ں�̬���л���ʱ������Ӱ������
lock����await��signal
synchronized��wait��notify
monitor����
��HotSpot�������,monitor����ObjectMonitorʵ�ֵġ���Դ������c++��ʵ�ֵ�
// `src/share/vm/runtime/objectMonitor.hpp`
ObjectMonitor() {
_header = NULL;
_count = 0;
_waiters = 0,
_recursions = 0; // �̵߳��������
_object = NULL;//�洢��monitor�Ķ��� //��java����������monitor,monitor��������java����
// _owner��ʼʱΪNULL�������߳�ռ�и�monitorʱ,owner���Ϊ���̵߳�Ψһ��ʶ�����߳��ͷ�monitorʱ,owner�ָֻ�ΪNULL��owner��һ���ٽ���Դ,JVM��ͨ��CAS��������֤���̰߳�ȫ�ġ�
_owner = NULL;//��ʶӵ�и�monitor���߳�
// ��Ϊ����wait���������������̻߳ᱻ���ڸö����С�
_WaitSet = NULL;//����wait״̬���߳�,�ᱻ���뵽waitSet
_WaitSetLock = 0 ;
_Responsible = NULL ;
_succ = NULL ;
// ��������,�������������߳����Ȼᱻ�������������(��������)��`_cxq`��һ���ٽ���Դ,JVMͨ��CASԭ��ָ������`_cxq`���С���ǰ`_cxq`�ľ�ֵ������node��next�ֶ�,`_cxq`ָ����ֵ(���߳�)�����`_cxq`��һ������ȳ���stack(ջ)��
_cxq = NULL ;//���߳̾�����ʱ�ĵ����б�
FreeNext = NULL ;
// _cxq���������ʸ��Ϊ��ѡ��Դ���̻߳ᱻ�ƶ����ö����С�
_EntryList = NULL ;//���ڵȴ�block״̬���߳�,�ᱻ���뵽���б� //��cxq�ƹ�����
_SpinFreq = 0 ;
_SpinClock = 0 ;
OwnerIsThread = 0 ;
_previous_owner_tid = 0;
}
5���ܽ�
���������ɹ���ʾ
������ʾ�����̲߳���ͻ�ػ�ȡ���Ĺ���,������������1��2���IJ���
| �߳� 1 | ���� Mark Word | �߳� 2 |
|---|---|---|
| ����ͬ���� A,�� Mark ���Ƶ��߳� 1 ������¼ | 01(����) | - |
| CAS �� Mark Ϊ�߳� 1 ����¼��ַ | 01(����) | - |
| 1 �ɹ�(����) | 00(������)�߳� 1 ����¼��ַ | - |
| ִ��ͬ���� A | 00(������)�߳� 1 ����¼��ַ | - |
| ����ͬ���� B,�� Mark ���Ƶ��߳� 1 ������¼ | 00(������)�߳� 1 ����¼��ַ | - |
| CAS �� Mark Ϊ�߳� 1 ����¼��ַ | 00(������)�߳� 1 ����¼��ַ | - |
| 2 ʧ��(���Ƿ������Լ�����) | 00(������)�߳� 1 ����¼��ַ | - |
| ������ | 00(������)�߳� 1 ����¼��ַ | - |
| ִ��ͬ���� B | 00(������)�߳� 1 ����¼��ַ | - |
| ͬ���� B ִ����� | 00(������)�߳� 1 ����¼��ַ | - |
| ͬ���� A ִ����� | 00(������)�߳� 1 ����¼��ַ | - |
| �ɹ�(����) | 01(����) | - |
| - | 01(����) | ����ͬ���� A,�� Mark ���Ƶ��߳� 2 ������¼ |
| - | 01(����) | CAS �� Mark Ϊ�߳� 2 ����¼��ַ |
| - | 00(������)�߳� 2 ����¼��ַ | �ɹ�(����) |
| - | �� | �� |
��������ʧ����ʾ:������(����->����)
������ʾ��������������,��00������10����
����ڳ��Լ����������Ĺ�����,CAS �������ɹ�,��ʱһ����������������߳�Ϊ�˶����������������(�о���),��ʱ��Ҫ����������,������������Ϊ����������
| �߳� 1 | ���� Mark | �߳� 2 |
|---|---|---|
| ����ͬ����,�� Mark ���Ƶ��߳� 1 ������¼ | 01(����) | - |
| CAS �� Mark Ϊ�߳� 1 ����¼��ַ | 01(����) | - |
| �ɹ�(����) | 00(������)�߳� 1 ����¼��ַ | - |
| ִ��ͬ���� | 00(������)�߳� 1 ����¼��ַ | - |
| ִ��ͬ���� | 00(������)�߳� 1 ����¼��ַ | ����ͬ����,�� Mark ���Ƶ��߳� 2 |
| ִ��ͬ���� | 00(������)�߳� 1 ����¼��ַ | CAS �� Mark Ϊ�߳� 2 ����¼��ַ |
| ִ��ͬ���� | 00(������)�߳� 1 ����¼��ַ | ʧ��(���ֱ����Ѿ�ռ����) |
| ִ��ͬ���� | 00(������)�߳� 1 ����¼��ַ | CAS �� Mark Ϊ������ |
| ִ��ͬ���� | 10(������)������ָ�� | ������ |
| ִ����� | 10(������)������ָ�� | ������ |
| ����(ʧ��) | 10(������)������ָ�� | ������ |
| �ͷ�������,���������߳̾��� | 01(����) | ������ |
| - | 10(������) | ���������� |
| - | 10(������) | �ɹ�(����) |
| - | �� | �� |
| �߳�1 (cpu 1 ��)�����������Գɹ������ | ����Mark | �߳�2 (cpu 2 ��) |
|---|---|---|
| - | 10(������) | - |
| ����ͬ����,��ȡ monitor | 10(������)������ָ�� | - |
| �ɹ�(����) | 10(������)������ָ�� | - |
| ִ��ͬ���� | 10(������)������ָ�� | - |
| ִ��ͬ���� | 10(������)������ָ�� | ����ͬ����,��ȡ monitor |
| ִ��ͬ���� | 10(������)������ָ�� | �������� |
| ִ����� | 10(������)������ָ�� | �������� |
| �ɹ�(����,�ѱ�־λ��Ϊ01) | 01(����) | �������� |
| - | 10(������)������ָ�� | �ɹ�(����) |
| - | 10(������)������ָ�� | ִ��ͬ���� |
| - | �� | �� |
| �߳� 1(cpu 1��)������������ʧ�ܵ���� | ����Mark | �߳�2(cpu 2 ��) |
|---|---|---|
| - | 10(������) | - |
| ����ͬ����,��ȡ monitor | 10(������)������ָ�� | - |
| �ɹ�(����) | 10(������)������ָ�� | - |
| ִ��ͬ���� | 10(������)������ָ�� | - |
| ִ��ͬ���� | 10(������)������ָ�� | ����ͬ����,��ȡ monitor |
| ִ��ͬ���� | 10(������)������ָ�� | �������� |
| ִ��ͬ���� | 10(������)������ָ�� | �������� |
| ִ��ͬ���� | 10(������)������ָ�� | �������� |
| ִ��ͬ���� | 10(������)������ָ�� | ���� |
| - | �� | �� |
6��jolʵս��֤
<dependency>
<groupId>org.openjdk.jol</groupId>
<artifactId>jol-core</artifactId>
<version>0.13</version>
</dependency>
����ͷ�Ĵ�С:Java����ͷһ��ռ������������(ע���ǻ����벻���ֽ��롣��32λ�������,1�����������4�ֽ�,Ҳ����32bit),
���������������������,����Ҫ����������,��ΪJVM���������ͨ��Java�����Ԫ������Ϣȷ��Java����Ĵ�С,�������������Ԫ������ȷ������Ĵ�С,������һ������¼���鳤�ȡ�
public static void main(String[] args) {
// ����һö����Ϊ3306������
int[] intArr = newint[3306];
// ʹ��jol��ClassLayout���߷�������
System.out.println(ClassLayout.parseInstance(intArr).toPrintable());
}
print:
------------���Ƕ���մ����õ�״̬-------------------------
[I object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01000000 (00000001000000000000000000000000) (1) // ���1��ƫ������־
4 4 (object header) 00000000 (00000000000000000000000000000000) (0)
8 4 (object header) 6d 0100 f8 (01101101000000010000000011111000) (-134217363) // ��������Ƿ����������û�е�
12 4 (object header) ea 0c 0000 (11101010000011000000000000000000) (3306)
1613224int [I.<elements> N/A
Instance size: 13240 bytes
Space losses: 0 bytes internal + 0 bytes external = 0 bytes total

import org.openjdk.jol.info.ClassLayout;
public class Main13 {
public static void main(String[] args) {
Main13 main13 = new Main13();
System.out.println(ClassLayout.parseInstance(main13).toPrintable());
}
}
//---------���------------------
Main13 object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 05 c1 00 20 (00000101 11000001 00000000 00100000) (536920325)
12 4 (loss due to the next object alignment)
// 0-11��16���ֽ�,��64λ��2=8��2
// ����Ӹ�int a��Ա����,���һ�и�Ϊ
/*
12 4 int Main13.a 0
*/
// ����Ӹ�boolean a,���һ�и�Ϊ����,�����ֽڶ���
/*
12 1 boolean Main13.a false
13 3 (loss due to the next object alignment)
*/
Instance size: 16 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes total
// �������:
������䲢���DZ�Ȼ���ڵ�,Ҳû��ʲô�ر������,����������ռλ��������,����HotSpot VM���Զ��ڴ����ϵͳҪ�������ʼ��ַ������8�ֽڵ�������,���仰˵,���Ƕ���Ĵ�С������8�ֽڵ���������������ͷ������8�ֽڵı���,���,������ʵ�����ݲ���û�ж���ʱ,����Ҫͨ�������������ȫ��
8��synchronizedʹ�ü���
������
Java�������JIT����ʱ(���Լ�����Ϊ��ij�δ��뼴����һ�α�ִ��ʱ���б���,�ֳƼ�ʱ����),ͨ�������������ĵ�ɨ��,�������ݷ���,ȥ�������ܴ��ڹ�����Դ��������,ͨ�����ַ�ʽ����û�б�Ҫ����,���Խ�ʡ���������������ʱ��
��������ָ�������ʱ������(JIT)������ʱ,��һЩ������Ҫ��ͬ��,���DZ��������ܴ��ڹ������ݾ���������������������������Ҫ�ж�������Դ�����ݷ���������֧��,����ж���һ�δ�����,���ϵ��������ݶ��������ݳ�ȥ�Ӷ��������̷߳��ʵ�,�ǾͿ������ǵ���ջ�����ݶԴ�,��Ϊ�������߳�˽�е�,ͬ��������Ȼ��������С������Ƿ�����,�����������˵��Ҫʹ��������������ȷ��,���dz���Ա�Լ�Ӧ���Ǻ������,��ô������֪���������������õ������Ҫ��ͬ����?ʵ����������ͬ����ʩ�����dz���Ա�Լ������,ͬ���Ĵ�����Java�����е��ձ�̶�Ҳ�������˴ֶ��ߵ�����������ηdz��Ĵ�����������3���ַ�����ӵĽ��,������Դ�������ϻ��dz��������϶�û��ͬ����
Ϊ�˱�֤���ݵ�������,�����ڽ��в���ʱ��Ҫ���ⲿ�ֲ�������ͬ������,��������Щ�����,JVM�������ܴ��ڹ������ݾ���,��ʱJVM�����Щͬ���������������������������������ݷ���������֧�֡� ��������ھ���,Ϊʲô����Ҫ������?�������������Խ�ʡ�����������������ʱ�䡣�����Ƿ�����,�����������˵��Ҫʹ��������������ȷ��,���Ƕ������dz���Ա��˵������ô?���ǻ�������֪�����������ݾ����Ĵ����ǰ����ͬ����?������ʱ��������������������?������Ȼû����ʾʹ����,����������ʹ��һЩJDK������APIʱ,��StringBuffer��Vector��HashTable��,���ʱ���������εļ�������������StringBuffer��append()����,Vector��add()����:
// ��������δ���ʱ,JVM�������Լ�����vectorû�����ݳ�����vectorTest()֮��,����JVM���Դؽ�vector�ڲ��ļ�������������
public static void vectorTest(){
Vector<String> vector = new Vector<String>();
for(int i = 0 ; i < 10 ; i++){
vector.add(i + "");
}
}
public static void main(){contactStr("aa", "bb", "cc");}
public static String contactStr(String s1, String s2, String s3) {
return new StringBuffer().append(s1)
.append(s2)
.append(s3)
.toString();
// StringBu?er��append()��һ��ͬ������,������thisҲ����(new StringBuilder())��������������Ķ�̬������������concatString( )�����ڲ���Ҳ����˵, new StringBuilder()�����������Զ���ᡰ���ݡ���concatString ( )����֮��,�����߳������ʵ���,���,��Ȼ��������,���ǿ��Ա���ȫ��������,�ڼ�ʱ����֮��,��δ���ͻ���Ե����е�ͬ����ֱ��ִ���ˡ�
}
���ֻ�
������˵,ͬ��������÷�ΧӦ�þ�����С,���ڹ������ݵ�ʵ���������вŽ���ͬ��,��������Ŀ����Ϊ��ʹ��Ҫͬ���IJ���������������С,��������ʱ��,�������������,��ô�ȴ������߳�Ҳ�ܾ����õ�����
���Ǽ�������Ҳ��Ҫ������Դ,�������һ���߳�һϵ�е�����������������,�������������dz�����ѭ�����е�,���ܻᵼ�²���Ҫ��������ġ�
���ֻ����ǽ���������ļ�������������������һ��,��չ��һ����Χ�������,����Ƶ���ļ�������������
ʲô�����ֻ�?JVM��̽�һ����ϸС�IJ�����ʹ��ͬһ���������,��ͬ�������ķ�Χ�Ŵ�,�ŵ������������,����ֻ��Ҫ��һ�������ɡ�
public class Demo01 {
public static void main(String[] args) {
StringBuffer sb = new StringBuffer();
for (int i = 0; i < 100; i++) {
//
b.append("aa");
}
System.out.println(sb.toString());
}
}
32�mark word
��32λ�������,Mark Word��32bit��С��,��洢�ṹ����:
Դ��
����ο�: http://openjdk.java.net/groups/hotspot/docs/HotSpotGlossary.html
JVMԴ������
http://openjdk.java.net/ --> Mercurial --> jdk8 --> hotspot --> zip
C++ IDE(Clion )���� https://www.jetbrains.com/
oop��ϵ:
��һ���̳߳��Է���synchronized���εĴ����ʱ,������Ҫ�����,��ô��������״���������?�Ǵ���������Ķ���ͷ�еġ�
HotSpot����instanceOopDesc��arrayOopDesc����������ͷ��arrayOopDesc�������������������͡�instanceOopDesc�Ķ������HotspotԴ��� instanceOop.hpp �ļ��С�arrayOopDesc�Ķ����Ӧ arrayOop.hpp ��
//
class instanceOopDesc : public oopDesc {
public:
// aligned header size.
static int header_size() { return sizeof(instanceOopDesc)/HeapWordSize; }
// If compressed, the offset of the fields of the instance may not be aligned.
static int base_offset_in_bytes() {
// offset computation code breaks if UseCompressedClassPointers
// only is true
return (UseCompressedOops && UseCompressedClassPointers) ?
klass_gap_offset_in_bytes() :
sizeof(instanceOopDesc);
}
static bool contains_field_offset(int offset, int nonstatic_field_size) {
int base_in_bytes = base_offset_in_bytes();
return (offset >= base_in_bytes &&
(offset-base_in_bytes) < nonstatic_field_size * heapOopSize);
}
};
�����г���������Oopsģ�����ɽṹ,���а��������ģ�顣ÿһ����ģ���Ӧһ������,ÿһ�����͵�OOP������һ����JVM�ڲ�ʹ�õ��ض���������͡�
//������oops��ͬ����
typedef class oopDesc* oop;
//��ʾһ��Java����ʵ��
typedef class instanceOopDesc* instanceOop;
//��ʾһ��Java����
typedef class methodOopDesc* methodOop;
//��ʾһ��Java�����еIJ�����Ϣ
typedef class constMethodOopDesc* constMethodOop;
//��¼������Ϣ�����ݽṹ
typedef class methodDataOopDesc* methodDataOop;
//����������OOPS�ij������
typedef class arrayOopDesc* arrayOop;
//��ʾ����һ��OOPS����
typedef class objArrayOopDesc* objArrayOop;
//��ʾ���ɻ������͵�����
typedef class typeArrayOopDesc* typeArrayOop;
//��ʾ��Class�ļ��������ij�����
typedef class constantPoolOopDesc* constantPoolOop;
//�����ظ�����
typedef class constantPoolCacheOopDesc* constantPoolCacheOop;
//����һ����Java��Եȵ�C++��
typedef class klassOopDesc* klassOop;
//��ʾ����ͷ
typedef class markOopDesc* markOop;
����
������Ĵ����п��Կ���,��һ������opp��������oppDesc ,OOPS��Ĺ�ͬ������ΪoopDesc��
// oop.hpp // instanceOopDesc�̳���oopDesc
class oopDesc {//����ͷ�ĸ���
friend class VMStructs;
private:
volatile markOop _mark;// Mark World
union _metadata { //��Ԫ��Ϣ,��Ԫ��Ϣ�洢���Ƕ���ָ��������Ԫ����(Klass)����ַ
Klass* _klass;// ����ָ�� Klass
narrowKlass _compressed_klass;// ѹ����ָ��
} _metadata;
// Fast access to barrier set. Must be initialized.
static BarrierSet* _bs;
// ʡ����������
};
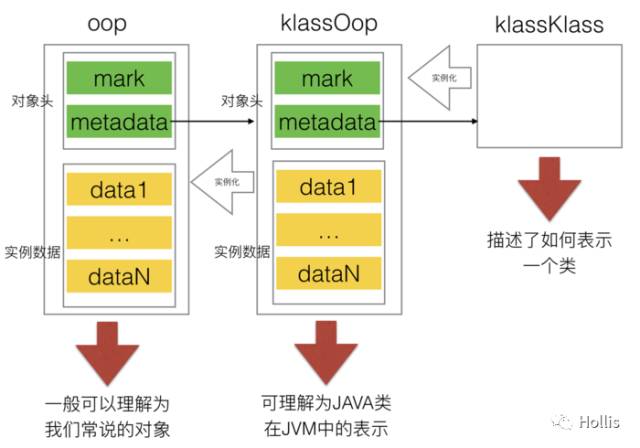
**��Java�������й�����,ÿ����һ���µĶ���,��JVM�ڲ��ͻ���Ӧ�ش���һ����Ӧ���͵�OOP����**��HotSpot��,����JVM�ڲ�ʹ�õĶ���ҵ������,���ж���oopDesc�����ࡣ����oppDesc������,opp��ϵ�л��кܶ�instanceOopDesc��arrayOopDesc �����͵�ʵ��,���Ƕ���oopDesc�����ࡣ
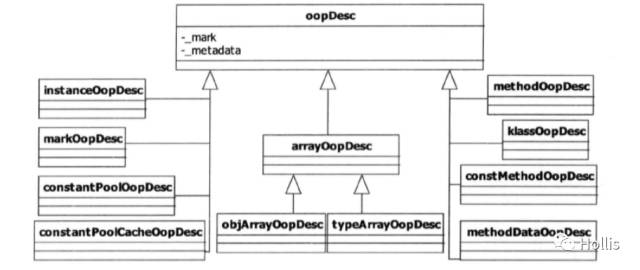
��ЩOOPS��JVM�ڲ����Ų�ͬ����;,����**,instanceOopDesc��ʾ��ʵ��,arrayOopDesc��ʾ���顣**Ҳ����˵,������ʹ��new����һ��Java����ʵ����ʱ��,JVM�ᴴ��һ��instanceOopDesc��������ʾ���Java����ͬ��,������ʹ��new����һ��Java����ʵ����ʱ��,JVM�ᴴ��һ��arrayOopDesc��������ʾ����������
��HotSpot��,oopDesc�ඨ����oop.hpp��,instanceOopDesc������instanceOop.hpp��,arrayOopDesc������arrayOop.hpp�С�
��һ����ض���:
class instanceOopDesc : public oopDesc {
}
class arrayOopDesc : public oopDesc {
}
ͨ�������Դ����Կ���,instanceOopDescʵ���Ͼ��Ǽ̳���oopDesc,��û���������������ݽṹ,Ҳ����˵**instanceOopDesc�а�������������:markOop _mark��union _metadata��**
�����markOop���������Ϥ��,�ⲻ����OOPS��ϵ�е�һ������,����ע�����Ѿ�˵��,����ʾ����ͷ�� _metadata��һ��������,����ֶα���ΪԪ����ָ�롣ָ����������Klass�����ָ�롣
HotSpot�������,�������ڴ��д洢�IJ��ֿ��Է�Ϊ��������:����ͷ��ʵ�����ݺͶ�����䡣��������ڲ�,һ��Java�����Ӧһ��instanceOopDesc�Ķ���,�ö������������ֶηֱ��ʾ�˶���ͷ��ʵ�����ݡ��Ǿ���_mark��_metadata��
���¿�ͷ���Ǿ�˵��,֮��������Ҫд��ƪ����,����Ϊ����ͷ���к�����ص�����ʱ����,��Щ����ʱ������synchronized�Լ��������͵���ʵ�ֵ���Ҫ��������Ϊ������Ҫ���ܵ�oop-klassģ��,��������ʱ���Զ���ͷ��չ��,��һƪ���½��ܡ�
ǰ����ܵ���_metadata��һ��������,����_klass����ָͨ��,_compressed_klass��ѹ����ָ�롣���������֮ǰ,��Ҫ����oop-Klass�е�����һ������klass�ˡ�
klass
ÿһ��Java��,�ڱ�JVM���ص�ʱ��,JVM�������ഴ��һ��instanceKlass,�����ڷ�����,������JVM���ʾ��Java�ࡣ��������Java������,ʹ��new����һ�������ʱ��,JVM�ᴴ��һ��instanceOopDesc����,��������а����˶���ͷ�Լ�ʵ�����ݡ�
klass��ϵ
//klassOop��һ����,�����������Բ������
class Klass;
//���������������һ��Java��
class instanceKlass;
//ר��instantKlass,��ʾjava.lang.Class��Klass
class instanceMirrorKlass;
//ר��instantKlass,��ʾjava.lang.ref.Reference�������Klass
class instanceRefKlass;
//��ʾmethodOop��Klass
class methodKlass;
//��ʾconstMethodOop��Klass
class constMethodKlass;
//��ʾmethodDataOop��Klass
class methodDataKlass;
//��Ϊklass���Ķ˵�,klassKlass��Klass����������
class klassKlass;
//��ʾinstanceKlass��Klass
class instanceKlassKlass;
//��ʾarrayKlass��Klass
class arrayKlassKlass;
//��ʾobjArrayKlass��Klass
class objArrayKlassKlass;
//��ʾtypeArrayKlass��Klass
class typeArrayKlassKlass;
//��ʾarray���͵ij������
class arrayKlass;
//��ʾobjArrayOop��Klass
class objArrayKlass;
//��ʾtypeArrayOop��Klass
class typeArrayKlass;
//��ʾconstantPoolOop��Klass
class constantPoolKlass;
//��ʾconstantPoolCacheOop��Klass
class constantPoolCacheKlass;
��oopDesc������oop���͵ĸ���һ��,Klass��������klass���͵ĸ��ࡣ
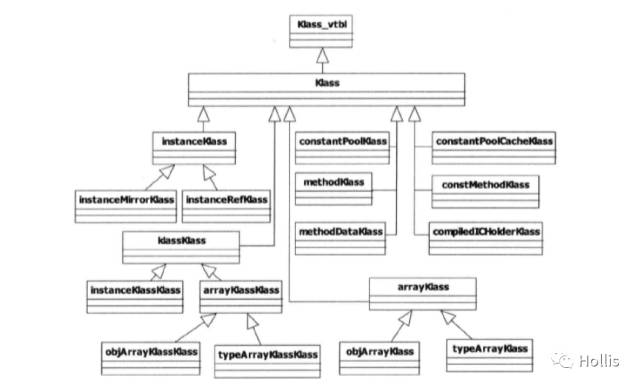
Klass��JVM�ṩ��������:
- ʵ�����Բ����Java��(��Klass�������Ѿ�ʵ��)
- ʵ��Java����ķַ�����(��Klass�������ṩ�麯��ʵ��)
���¿�ͷ��ʱ��˵��:֮�������oop-klassģ��,����ΪHotSopt JVM������߲�����ÿ�������ж�����һ���麯������
HotSopt JVM������߰Ѷ���һ��Ϊ��,��Ϊklass��oop,����oop��ְ����Ҫ���ڱ�ʾ�����ʵ������,�������в������κ��麯������klassΪ��ʵ���麯����̬,�����ṩ���麯����������,����Java�Ķ�̬,��ʵҲ���麯����Ӱ���ڡ�
_metadata��һ��������,����_klass����ָͨ��,_compressed_klass��ѹ����ָ�롣������ָ�붼ָ��**instanceKlass����,��������������ľ������͡�**
instanceKlass
JVM������ʱ,��Ҫһ��������ʶJava�ڲ����͵Ļ��ơ���HotSpot�еĽ��������:Ϊÿһ���Ѽ��ص�Java�ഴ��һ��instanceKlass����,������JVM���ʾJava�ࡣ
������instanceKlass���ڲ��ṹ:
//��ӵ�еķ����б�
objArrayOop _methods;
//��������˳��
typeArrayOop _method_ordering;
//ʵ�ֵĽӿ�
objArrayOop _local_interfaces;
//�̳еĽӿ�
objArrayOop _transitive_interfaces;
//��
typeArrayOop _fields;
//����
constantPoolOop _constants;
//�������
oop _class_loader;
//protected��
oop _protection_domain;
....
���Կ���,һ����þ��еĶ���,����������������ˡ�
���ﻹ�и�����Ҫ����һ�¡�
��JVM��,�������ڴ��еĻ���������ʽ����oop����ô,������������,��JVM��Ҳ��һ�ֶ���,�������ʵ����Ҳ�ᱻ��֯��һ��oop,��klassOop��ͬ����,����klassOop,Ҳ�ж�Ӧ��һ��klass������,������klassKlass,Ҳ��klass��һ�����ࡣklassKlass��Ϊoop��klass���Ķ˵㡣���ڶ���������klass����������ͼ:
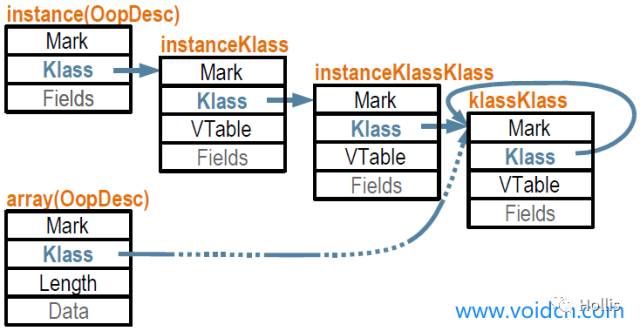
�����������,JVM���ڴ�ķ���ͻ���,�����Բ���ͳһ�ķ�ʽ��������oop-klass-klassKlass��ϵ��ͼ:
�ڴ�洢
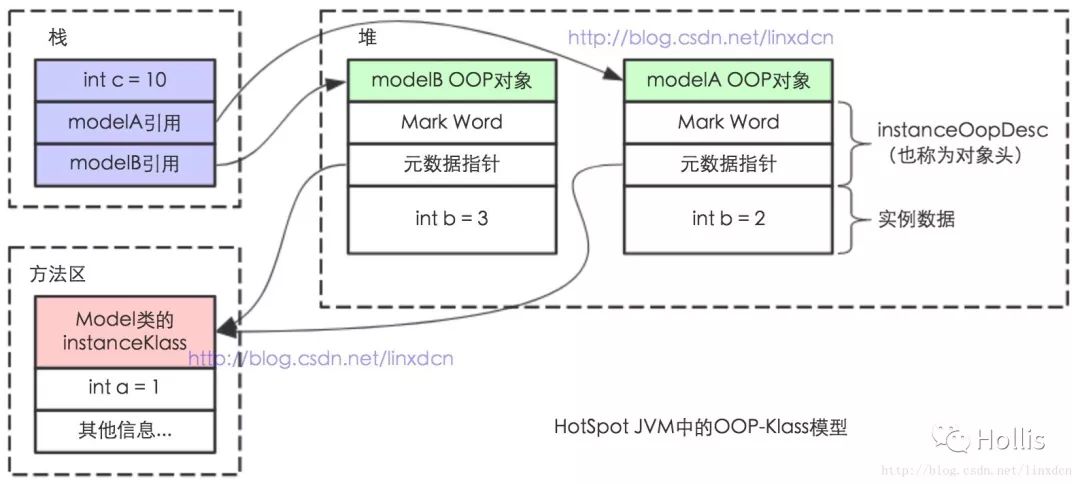
����һ��Java����,���Ĵ洢��������,һ��ܶ��˻�ش�:����洢�ڶ��ϡ�����һ����˻�ش�:����洢�ڶ���,��������ô洢��ջ�ϡ�����,�ٸ���һ�������Ե�ţ�ƵĻش�:
�����ʵ��(instantOopDesc)�����ڶ���,�����Ԫ����(instantKlass)�����ڷ�����,��������ñ�����ջ�ϡ�
��ʵ���ϸ���Ļ�,������仰�е������Ū����˼����Ϊ���Ƕ�֪�������������ڴ洢��������ص�����Ϣ����������̬��������ʱ�����������Ĵ�������ݡ� ��ν���ص�����Ϣ,��ʵ�����Ǹ�ÿһ�������ص��������һ�� instantKlass����ô��
talk is cheap ,show me the code :
class Model {
public static int a = 1;
public int b;
public Model(int b) {
this.b = b;
}
}
public static void main(String[] args) {
int c = 10;
Model modelA = new Model(2);
Model modelB = new Model(3);
}
�洢�ṹ����:
�ܽ�
ÿһ��Java��,�ڱ�JVM���ص�ʱ��,JVM�������ഴ��һ��instanceKlass,�����ڷ�����,������JVM���ʾ��Java�ࡣ��������Java������,ʹ��new����һ�������ʱ��,JVM�ᴴ��һ��instanceOopDesc����,��������а�������������Ϣ,����ͷ�Լ�Ԫ���ݡ�����ͷ����һЩ����ʱ����,���оͰ����Ͷ��߳���ص�������Ϣ��Ԫ������ʵά������ָ��,ָ����Ƕ������������instanceKlass��
��������Moniter��ʵ��ԭ��
����ϵͳ�еĹܳ�
������ڴ�ѧѧϰ������ϵͳ,����ܻ��ǵùܳ�(monitors)�ڲ���ϵͳ���Ǻ���Ҫ�ĸ��ͬ��Monitor��javaͬ��������Ҳ��ʹ�á�
�ܳ� (Ӣ��:Monitors,Ҳ��Ϊ������) ��һ�ֳ���ṹ,�ṹ�ڵĶ���ӳ���(�����ģ��)�γɵ���������̻߳�����ʹ�����Դ����Щ������Դһ����Ӳ���豸��һȺ�������ܳ�ʵ������һ��ʱ���,���ֻ��һ���߳���ִ�й̵ܳ�ij���ӳ�������Щͨ�������ݽṹʵ�ֻ�����ʵIJ�������������,�ܳ�ʵ�ֺܴ�̶��ϼ��˳�����ơ� �ܳ��ṩ��һ�ֻ���,�߳̿�����ʱ�����������,�ȴ�ijЩ�����õ������,���»��ִ��Ȩ�ָ����Ļ�����ʡ�
Moniter��ط���
�����
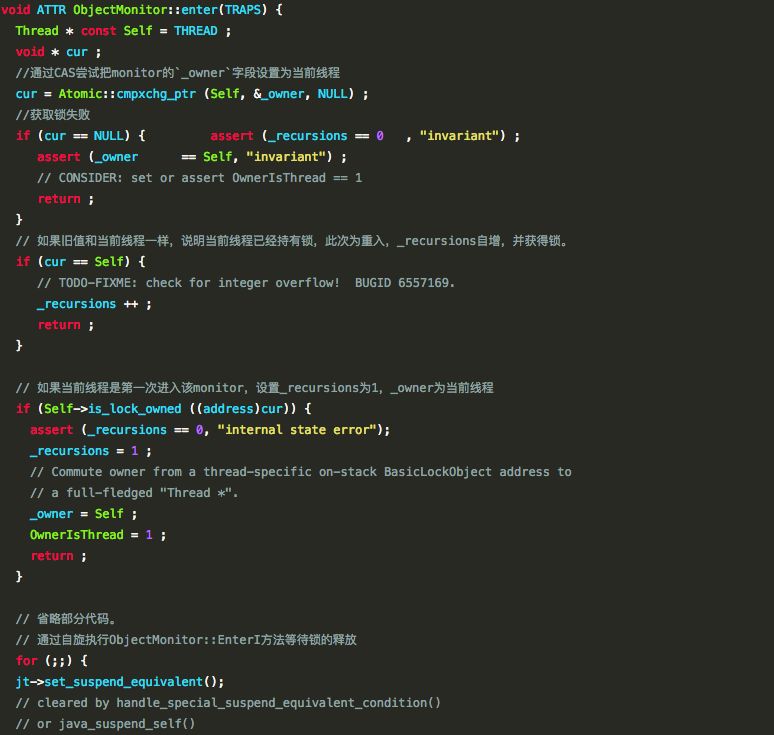
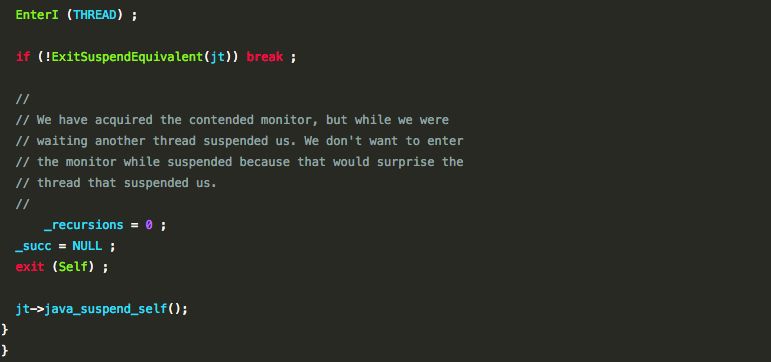
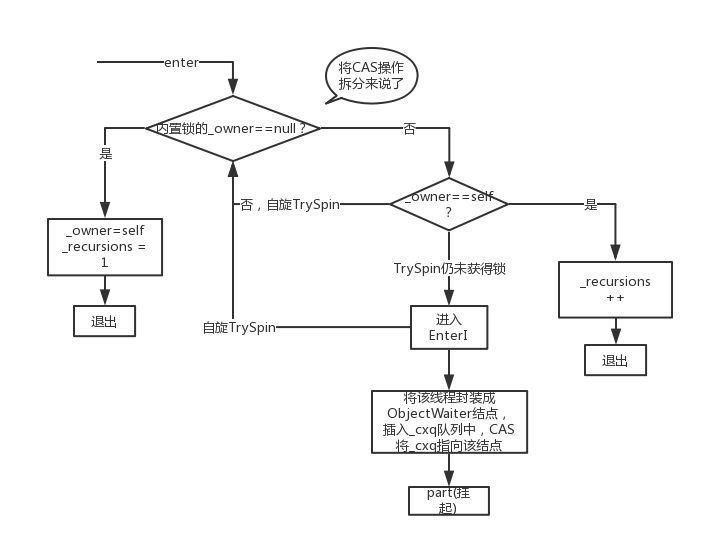
�ͷ���
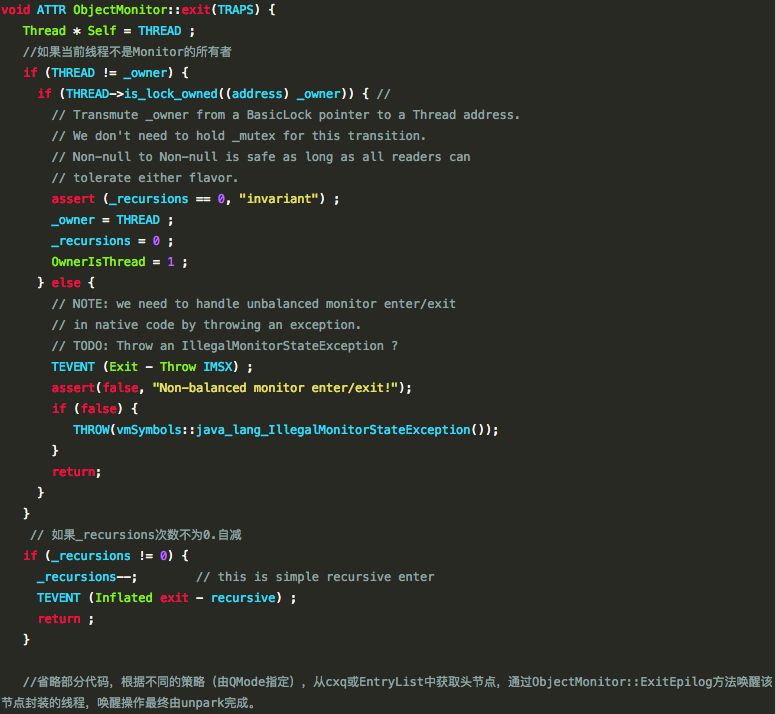
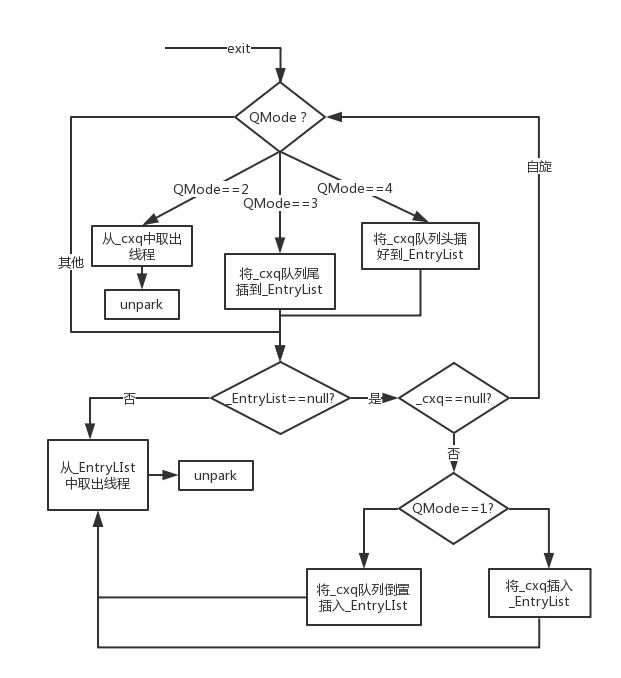
����enter��exit��������,objectMonitor.cpp���
void wait(jlong millis, bool interruptable, TRAPS);
void notify(TRAPS);
void notifyAll(TRAPS);
�ȷ�����