前提
本文章基础内容较少,需要读者具备下列基础知识
- 具有基本的java基础
- 具有简单的jvm的知识(最好,没有也行,但是看起来会比较吃力)
提要:
本文所有案例运行环境为jdk1.8;
本文较长,需要一定的耐心,文中会贴出面试题和简单讲解。
api底层实现
String类定义
-
String 类是被final修饰的类,我们知道,被final修饰的类有以下特点,不可被继承,也可以防止子类重写父类方法,类中的方法会隐式的定义为final 方法,查看java官方解释(最下面会给出链接,有兴趣的可以自取)得知,这样可以保证类的一致性,简单来说就是让我们只要用到了字符串,那么它一定是String类的实例,使用的方法也一定是String类的方法。
-
String用来存储字符串的结构是char数组,也是被final修饰,被final修饰的字段有以下作用:
(1).final修饰基本类型,会有下面特点,在java编译期间(编译器运行java文件生成字节码文件的过程)就被直接被确定好了值,不可更改,等到类加载时间在分配内存。
(2).final修饰引用类型,会有下面特点,变量永远指向初始化时的那个对象,不可更改,但是被指向的那个对象的属性域是可以改变的。
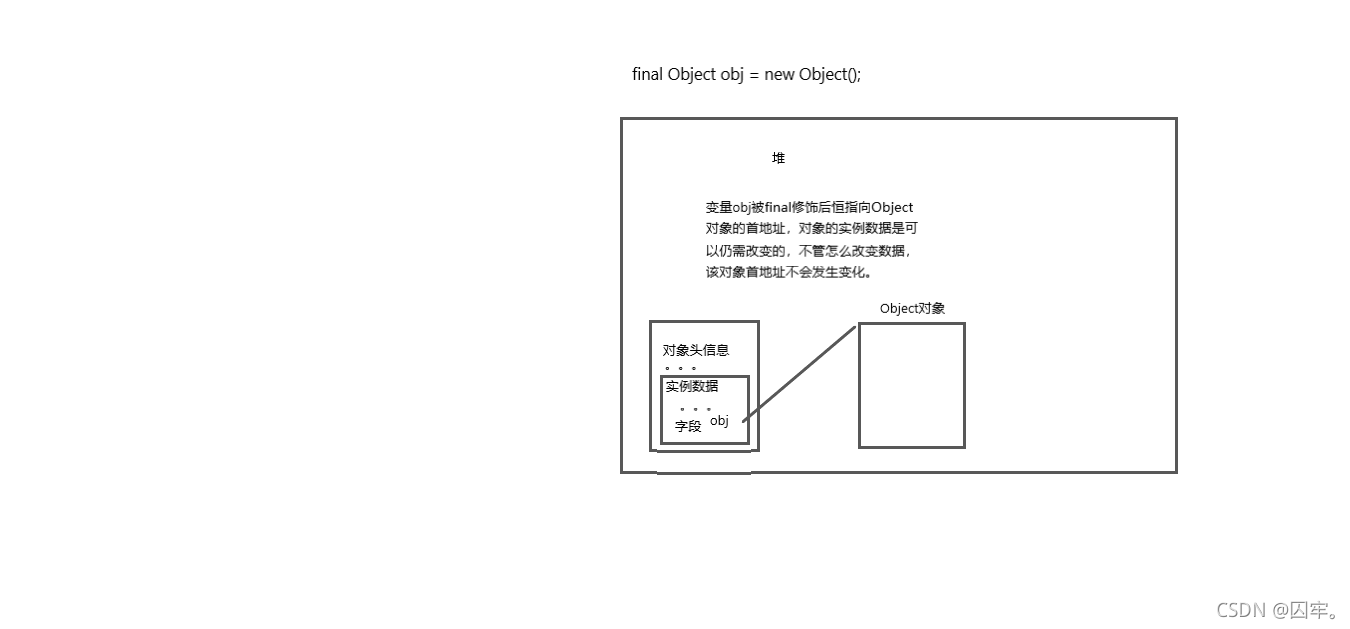
(3).被final修饰的变量在编译前会进行初始化检测,没有提供初始化方式会报编译错误。
那既然这样的话,String中的char【】数组内容不就可变了吗?的确是可以变化的,不过前提是String类提供底层数组访问方式,源码会给我们提供访问方法吗?并不会,api设计者们为了保证String的不变性,不仅不提供char数组访问方法,而且只要改变了字符串内容就会返回一个新的字符串对象。且听我娓娓道来。
String方法深入刨析
String类中的方法很多,可以简单的分为俩块。
-
未改变原先字符串内容
(1)intern方法:intern方法如果你没有了解过,可能会以为这只是一个普通的方法,其实不然,在学会适时使用intern可以提升代码的效率。
intern原理(可细分为1.6及以前,1.6以后)
jdk1.6及以前:jdk1.6 调用方法后,会检索字符串常量池,如果没有则会新建一个String对象(深拷贝),返回新地址,否则返回常量池中存在的地址。
为什么不直接用引用指向堆中对象呢?
原因:jdk1.6及以前,字符串常量池在方法区中,字符串常量池与堆中string对象在不在同一块地址区,找到目的地址耗时较久。这是用空间换时间。jdk1.6以后:调用方法后,会检索字符串常量池,如果没有则会新建一个String引用,指向堆区中的对象,返回String引用。
原因:字符串常量池与静态变量区在1.7时移动到了堆空间,字符串常量池与堆中string对象在同一块地址区,找到目的地址耗时较短。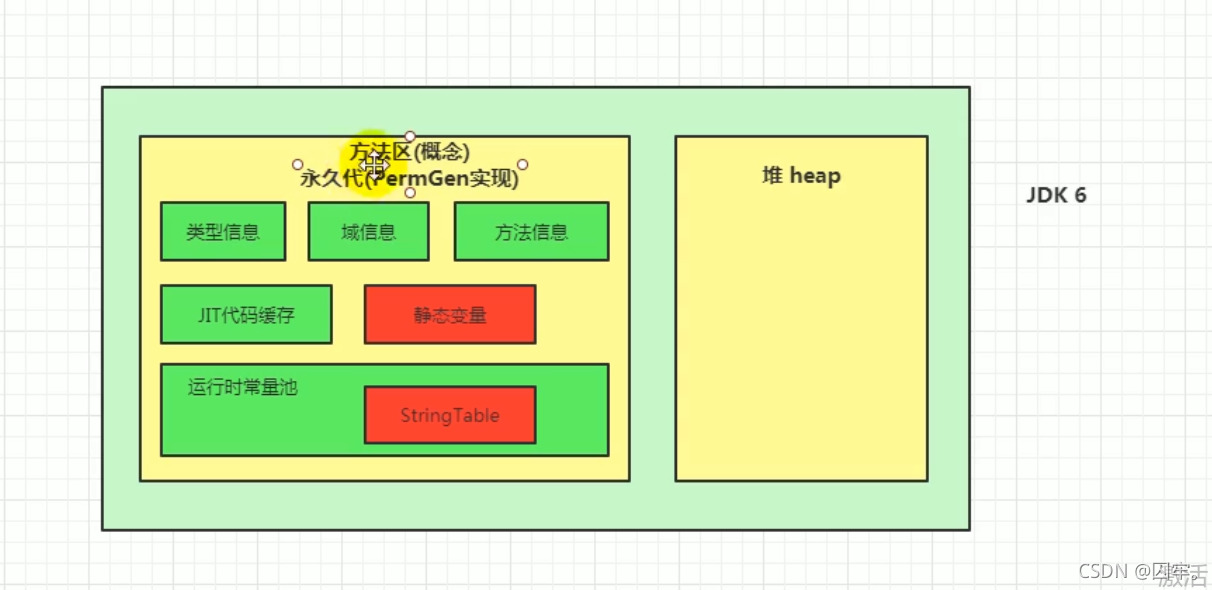
 intern方法版本变化原因:节省内存。
intern方法版本变化原因:节省内存。
常量池和静态变量区更改原因:这是因为在方法区中对这俩快的垃圾回收条件full gc太难触发了,而且触发full gc Stop the world 时间过于久,为了提升内存利用效率,把sum公司工程师从jdk1.7把他们放在了堆区。
(2)其他方法:返回原对象地址。 -
改变了原字符串内容
每次改变字符串内容后都会生成一个新的String对象,调用String(char【】数组参数…)构造器生成一个新的String对象。
new String(字面量) 构造器与String(char【】数组参数…)在jvm层面其实有很大的区别,下面细谈。
下面测试一下你的成果:
你可以想自己想一下,然后问问自己,自己可以说出个里面的细节吗?
String s1 = new String("1");
String s3 = s1.intern();
System.out.print(s1==s3);
String s2 = "1";
System.out.print(s1==s2);
System.out.print(s2==s3);
如果上面内容你吸收了的话,这是一道比较简单的题目:
jdk1.8 false false true
jdk1.6 false false true
原因:s1指向堆中String()对象,s2,s3指向常量池中的String对象。
上面那道只是开胃菜,进阶题
String s4 = new String("1")+new String("1");
String s5 = s4.intern();
System.out.print(s4==s5);
这一题你知道答案吗?为什么?
jdk1.8 true
jdk1.6 false
答案告诉你了,如果你现在一脸懵逼的话,就往下面看吧。看到下面的=,+=知识点你就了然了。如果你对了可以问问自己,自己能想到的细节过程有哪些?比如到底生成了几个String对象,jvm解析字节码时大概的流程是怎么样的。
String创建深入刨析
字符串创建有俩种方法:
1.字面量
2.new String(…)(俩种,可以分为参数有无字面量)
String s = "sd"; 1
String s1 = new String("a"); 2
char[] a = {'a','b','c','d'};
String ss = new String(a,0,4); 3
区别:(编号与代码编号一致)
1. 通过字面量创建字符串,会先在字符串常量池中搜索,如果没有改字符串对象,则在常量池新建一个String对象然后把常量池对象地址返回。
2. 方式二如果字符串常量池中没有“a”的话会创建俩个对象,常量池创建一个,堆区创建一个,然后把堆区中的String对象地址返回。
3. 方式三只会在堆区创建一个。
而在String api中的方法里面,只要你改变了字符串内容,返回的new String()使用的都是第三种构造器。
StringBuffer.toString,StringBuilder.toString等等也是第三种构造器,这是出于节省内存的角度考虑。
验证如下:
//我会在第一句添加断点
String s = new String("dd"); 语句1
char[] a = {'a','b','c','d'};
String ss = new String(a,0,4); 语句2
接下来我会通过debug模式查看jvm中的String对象数量,快来和我一起看看吧。
起始情况(注意右下):
 语句1执行后:
语句1执行后:
 可以看到String对象增加了俩个。
可以看到String对象增加了俩个。
语句3执行后:
 可以看到只生成了一个String对象。
可以看到只生成了一个String对象。
字面量验证留给你们,绝不是我漏掉了。
详解+,+=运算符
先看题:
final String x = "1";
final String x1 = "2";
String s = x+x1;
上面代码块运行生成了几个String对象? 答案:3
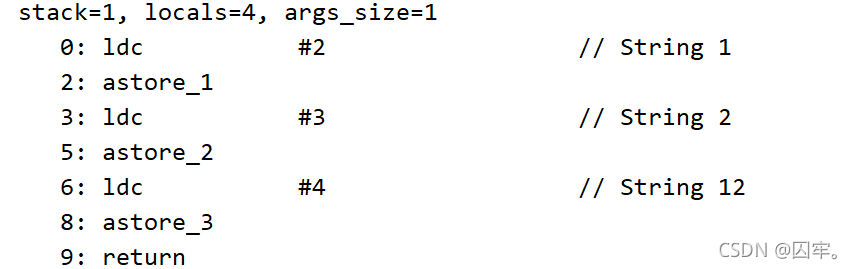
先把“1” “2”加到字符串常量池,然后在拼接为“12”加到常量池,然后赋值给s。
再看这个题:
String s = "1" + "2";
上面代码块运行生成了几个String对象? 答案:1
这是因为“1”+“2”,会触发编译器优化,没有变量指向“1”,“2”,所以编译器编译期间直接把他们拼接成一个字符串。
对应字节码:

再看题:
String x = "1"; 1
final String x1 = "2"; 2
String s = x+x1; 3
问题:上面代码会生成几个对象。
答案:4个
前面俩个语句生成俩个,而语句三,因为有变量参与运算,jvm会自动创建一个StringBuilder对象,然后调用append方法添加字符串,最后调用toString方法在堆区生成String对象,把地址返回赋值给s。
对应字节码:
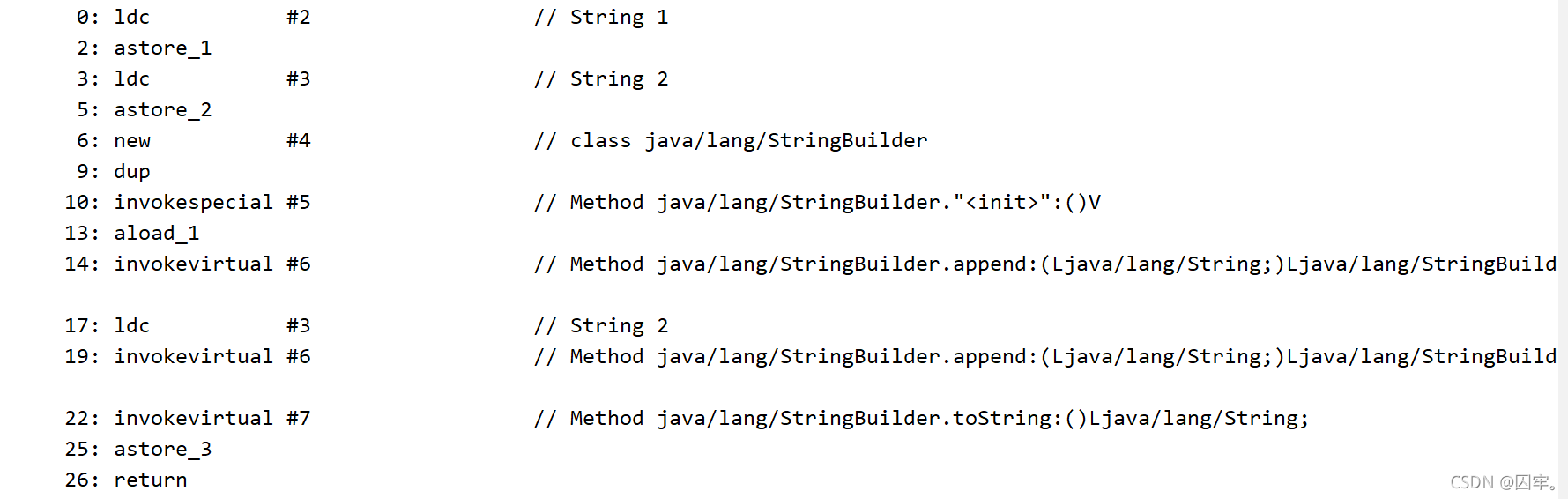
题目
再看上面那道题:
String s4 = new String("1")+new String("1");
String s5 = s4.intern();
System.out.print(s4==s5);
jdk1.8 true 共五个对象,一个StringBuilder对象,4个String对象,其中俩个“1”在堆区,一个“1”在字符串常量池,一个“11”在堆区通过StringBuillder.toString方法生成。
jdk1.6 false 共六个对象,一个StringBuilder对象,5个String对象,其中俩个“1”在堆区,一个“1”在字符串常量池,一个“11”在堆区通过StringBuillder.toString方法生成,一个“11”通过intern方法在常量池生成。
完毕,希望对你有所帮助。
参考文献:
java官方文档:https://docs.oracle.com/javase/specs/index.html
《深入理解java虚拟机》。
《java编程思想》
《宋红康jvm教程视频》https://www.bilibili.com/video/BV1PJ411n7xZ?p=71