多进程和多线程实现并发编程各自优势和劣势是什么?
**本人博客网站 **IT小神 www.itxiaoshen.com
-
多进程实现并发编程强调的是稳定性,每个进程有自己独立的地址空间,一个进程挂了不影响其他的进程,但进程间的通信方式实现还是比较麻烦的,比如管道、有名管道、信号量、消息队列、信号、共享内存、套接字等。
-
多线程实现并发编程主要是共享进程的地址空间,一个线程挂了或者写乱数据有可能影响其他线程甚至整个应用程序,也即是常说线程安全问题,多线程交换数据比较方便,线程之间的通信也可以直接通过内存来实现。多线程其实并不是多个线程一起执行,而是因为线程之间切换的速度非常的快,所以我们看起来像不间断的执行。
-
并发编程充分利用多核CPU或者多处理器的计算能力,从设计上方便进行业务拆分以提升应用程序性能。并发指的是多个事情,在同一时间段内同时发生了; 而并行指的是多个事情在同一时间点上同时发生了;并发的多个任务之间是互相抢占资源的; 并行的多个任务之间是不互相抢占资源的,只有在多CPU的情况中,才会发生并行;否则,看似同时发生的事情,其实都是并发执行的。
协程为什么能够实现更高的并发?
- 进程拥有自己独立的堆和栈,既不共享堆,亦不共享栈,进程由操作系统调度;线程拥有自己独立的栈和共享的堆,共享堆,不共享栈,线程亦由操作系统调度(标准线程是的);协程和线程一样共享堆,不共享栈,协程由程序员在协程的代码里显示调度;**因此进程和线程切换代价比较大,都是需要在内核态切换,协程在用户态切换,不用进入内核态里,所以上下文切换成本基本就没有了,**协程其实就是用户态的线程。协程避免了无意义的调度,由此可以提高性能,但也因此,程序员必须自己承担调度的责任。。
- 协程非常轻量,占用内存很小,一个协程内存通常只有几十kb,执行协程也只需要极少的栈内存(大概是4~5KB),可较为轻松创建和管理成千上万的并发协程任务。
- 协程大部分都是基于非阻塞API。
下面两种访问数据的方式那种更快,为什么?
#第一种
for(i=0;i++;i<n)
for(j=0;j++;j<n)
array[i][j] = 0;
#第二种
for(i=0;i++;i<n)
for(j=0;j++;j<n)
array[j][i] = 0;
经过测试,第一种比第二种的执行时间要快好几倍甚至几十倍
-
需要先确定下是属于行布局还是列布局的内存布局方式,二维数组内存是行布局,因为二维数组 array 所占用的内存是连续的,内存中的数组元素的布局顺序如下图所示

-
第一种方式缓存行批量读取优势。用 array【i】【j】访问数组元素的顺序,正是和内存中数组元素存放的顺序一致。当 CPU 访问 array[0][0] 时,由于该数据不在 Cache 中,于是会「顺序」把跟随其后的 3 个元素从内存中加载到 CPU Cache,这样当 CPU 访问后面的 3 个数组元素时,就能在 CPU Cache 中成功地找到数据,这意味着缓存命中率很高,缓存命中的数据不需要访问内存,这便大大提高了代码的性能
-
第一种方式充分利用缓存行大小64k的局部性原理。访问 array【i】【j】元素时,CPU 具体会一次从内存中加载多少元素到 CPU Cache 呢?这跟 CPU Cache Line 有关,它表示 CPU Cache 一次性能加载数据的大小,可以在 Linux 里通过 coherency_line_size 配置查看 它的大小,通常是 64 个字节。
Fibonacci数列F(n)=F(n-1)+F(n-2),实现F(n)函数?
定义:f ( 0 ) = f ( 1 ) = 1 , f ( n ) = f ( n ? 1 ) + f ( n ? 2 ) ( n ≥ 2 )
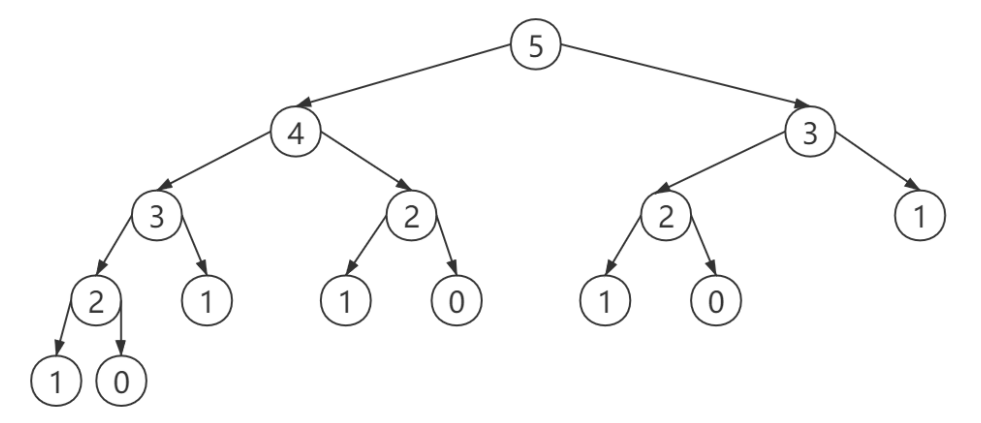
第一种:递归普通方法,能体现递归思维能力,算法时间复杂度是指数级增加,根据递归数而定。
int Fibnacci(int n)
{
if(n == 0){
return 1;
}else if(n == 1){
return 1;
}else {
return Fibnacci(n-1) + Fibnacci(n-2);
}
}
第二种: 记忆化搜索优化后的递归算法,开辟一块空间,利用-1赋值方式,采用记忆化搜索的功能,此外动态规划基础也是记忆化搜索。
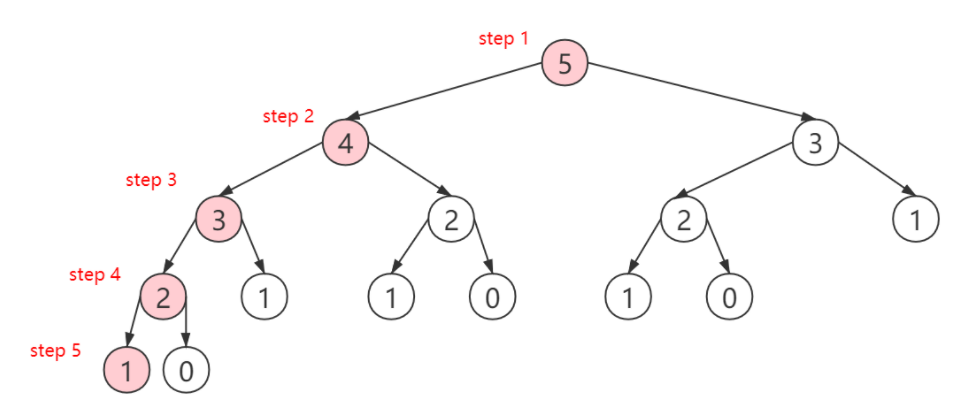
我们从节点5开始,依次来到节点4,节点3,节点2,节点1(上图红色节点)。并且在递归返回过程中,节点2,节点3的值被计算出。此时递归返回来到节点4,f ( 4 ) = f ( 3 ) + f ( 2 ) f(4)=f(3)+f(2)f(4)=f(3)+f(2),如果是一般的递归,此时还需要重新计算f ( 2 ) f(2)f(2);但在记忆化搜索中,f ( 2 ) f(2)f(2)的值已经被m e m o memomemo记录下来了,实际并不需要继续向下递归重复计算,函数可以直接返回。最后,递归返回来到了节点5,本应重复计算的f ( 3 ) f(3)f(3)由于m e m o memomemo的记录,也不需要重复计算了。所以,记忆化搜索可以起到剪枝的作用,对于已经保存的中间结果 ,由于其记忆能力,并不需要重新递归计算了。
int dp[] = new int[100];
int Fibnacci(int n)
{
if (n == 0 || n == 1)
return 1;
if (dp[n] != -1){
return dp[n];
}else{
dp[n] = Fibnacci(n-1) + Fibnacci(n-2);
return dp[n];
}
}
第三种:降低复杂度,o(n)复杂度,倒着去推,从0开始计算,记忆化
int dp[] = new int[100];
int Fibnacci(int n)
{
if (n == 1 || n == 2){
dp[n] = n;
}
else
{
if (dp[n] == -1){
dp[n] = Fibnacci(n-1) + Fibnacci(n-2);
}
}
return dp[n];
}
第四种:最优方法也即是数学公式计算,变成O(1)的时间复杂度:F(n)=(1/√5)*{[(1+√5)/2]^n - [(1-√5)/2]^n},如果能回答出这个那就非常不错了
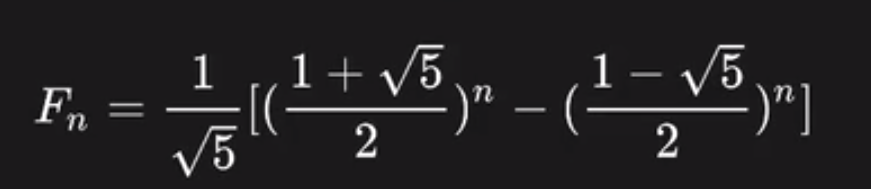
哈希表和二叉树相比,各自优缺点是什么?
- CRUD的复杂度上红黑树为O(logn),而哈希表为O(1)
- 哈希表做遍历性能就不太好,不能支持范围查询,关键字相邻但值却不一定相邻,而红黑树平衡比较麻烦,树的高度也可能高,通常使用B和B+树
解决哈希表冲突有哪些方法?各自优缺点是什么?
- 开散列哈希数组列表存放有冲突的元素也叫链表法,闭散列一组哈希函数;链表法简单,闭散列要求对哈希函数设计难些;闭散列持久化优势大,大存储和分布式系统容灾比较好。
- 哈希函数要尽量减少冲突,运算速度够快,考虑位运算和数学知识,从数学上模一个质数比如31,还要考虑业务的热度是否均匀;哈希表要考虑扩容,装载因子,哈希槽和存放元素比例,动态扩容,单机内还是跨服务器,只要是要标识数据是在老表还是新表可以解决动态扩容提供服务问题。
- 开放散列(open hashing)/ 拉链法(针对桶链结构)
- 优点
- 对于记录总数频繁可变的情况,处理的比较好(也就是避免了动态调整的开销)。
- 由于记录存储在结点中,而结点是动态分配,不会造成内存的浪费,所以尤其适合那种记录本身尺寸(size)很大的情况,因为此时指针的开销可以忽略不计了。
- 删除记录时,比较方便,直接通过指针操作即可。
- 缺点
- 存储的记录是随机分布在内存中的,这样在查询记录时,相比结构紧凑的数据类型(比如数组),哈希表的跳转访问会带来额外的时间开销。
- 如果所有的 key-value 对是可以提前预知,并之后不会发生变化时(即不允许插入和删除),可以人为创建一个不会产生冲突的完美哈希函数(perfect hash function),此时封闭散列的性能将远高于开放散列。
- 由于使用指针,记录不容易进行序列化(serialize)操作。
- 优点
- 封闭散列(closed hashing)/ 开放定址法
- 优点
- 记录更容易进行序列化(serialize)操作。
- 如果记录总数可以预知,可以创建完美哈希函数,此时处理数据的效率是非常高的。
- 缺点
- 存储记录的数目不能超过桶数组的长度,如果超过就需要扩容,而扩容会导致某次操作的时间成本飙升,这在实时或者交互式应用中可能会是一个严重的缺陷。
- 使用探测序列,有可能其计算的时间成本过高,导致哈希表的处理性能降低。
- 由于记录是存放在桶数组中的,而桶数组必然存在空槽,所以当记录本身尺寸(size)很大并且记录总数规模很大时,空槽占用的空间会导致明显的内存浪费。
- 删除记录时,比较麻烦。比如需要删除记录a,记录b是在a之后插入桶数组的,但是和记录a有冲突,是通过探测序列再次跳转找到的地址,所以如果直接删除a,a的位置变为空槽,而空槽是查询记录失败的终止条件,这样会导致记录b在a的位置重新插入数据前不可见,所以不能直接删除a,而是设置删除标记。这就需要额外的空间和操作。
- 优点
- 哈希表相对于其他数据结构的优缺点
- 优点
- 记录数据量很大的时候,处理记录的速度很快,平均操作时间是一个不太大的常数。
- 缺点
- 好的哈希函数(good hash function)的计算成本有可能会显著高于线性表或者搜索树在查找时的内部循环成本,所以当数据量非常小的时候,哈希表是低效的。
- 哈希表按照 key 对 value 有序枚举(ordered enumeration, 或者称有序遍历)是比较麻烦的(比如:相比于有序搜索树),需要先取出所有记录再进行额外的排序。
- 哈希表处理冲突的机制本身可能就是一个缺陷,攻击者可以通过精心构造数据,来实现处理冲突的最坏情况。即:每次都出现冲突,甚至每次都出现多次冲突(针对封闭散列的探测),以此来大幅度降低哈希表的性能。这种攻击也被称为基于哈希冲突的拒绝服务攻击(Hashtable collisions as DOS attack)。
- 优点
自旋锁有哪些特点,不适用于哪些场景?
- 特点
- 自旋锁顾名思义就是**「线程循环地去获取锁」**,一直占用 CPU 的时间片去循环获取锁,直到获取到为止。非自旋锁,也就是普通锁。获取不到锁,线程就进入阻塞状态。等待 CPU 唤醒,再去获取。
- 对性能要求较高的情况下,在多核cpu上,一般要求你锁住那段代码运行时间比较短,并发高,微观上有可能改一点时间片就切换出去了,互斥锁锁住时间长没有关系。自旋锁一直询问,互斥锁排队等待结果通知,自旋锁线程不会切换,互斥锁线程会切换,有代价。互斥锁休眠等待和自旋锁忙等待。
- 死循环然后利用cpu提供pause指令,可以省电。
- 阻塞 & 唤醒线程都是需要资源开销的,如果线程要执行的任务并不复杂。这种情况下,切换线程状态带来的开销比线程执行的任务要大;而很多时候,我们的任务往往比较简单,简单到线程都还没来得及切换状态就执行完毕。这时我们选择自旋锁明显是更加明智的。所以,自旋锁的好处就是**「用循环去不停地尝试获取锁,让线程始终处于 Runnable 状态,节省了线程状态切换带来的开销」**。
- 不适用场景
- 并发高,经常出现自旋不成功。
- 线程执行的同步任务过于复杂,耗时比较长
读写锁用于解决什么问题?读优先和写优先是指什么?
- 读写锁适合于对数据结构的读次数比写次数多得多的情况.因为,读模式锁定时可以共享,以写 模式锁住时意味着独占,所以读写锁又叫共享-独占锁.
- 读写锁是用来解决读者写者问题的,读操作可以共享,写操作是排他的,读可以有多个在读,写只有唯一个在写,同时写的时候不允许读
- 如果你能区分对于一个共享数据是读还是写就可以使用读写锁,分为两把锁,读锁共享锁,多个资源可以同时访问,写锁是独占锁,比较适合读多写少的场景。优先会导致其他饿死。ReentranctReadWriteLock公平读写锁。弄一个队列排队效率第一点但不会饿死。可以用互斥锁也可以用自旋锁。
- 读优先,即使写者发出了请求写的信号,但是只要还有读者在读取内容,就还允许其他读者继续读取内容,直到所有读者结束读取,才真正开始写。
- 写优先,如果有写者申请写文件,在申请之前已经开始读取文件的可以继续读取,但是如果再有读者申请读取文件,则不能够读取,只有在所有的写者写完之后才可以读取
怎样将文件快速发送客户端?
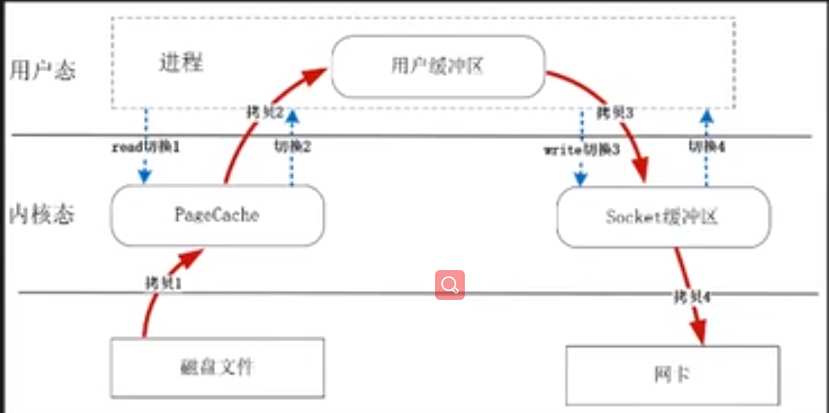
- 内存拷贝次数太多了,磁盘文件先拷贝操作系统高速缓冲区,再从高速缓冲区拷贝用户态的内存如32k的缓冲区,然后再拷贝操作系统内核socket缓冲区,然后再拷贝网卡上,四次拷贝。
- 切换次数多,掉一次read或者send都是两次切换。
- 零拷贝 sendfile ,拷贝次数减少了,切换次数也减少了,充分使用内核tcp缓冲区一般是1M多可配。
相比堆,为什么栈上分配的对象速度更快?
- 每个线程都有一个独立栈,都有函数在使用调用栈,栈是每个线程独立不需要加锁。栈中的数据占内存大小在编译时是确定的,比如一个int类型就占4B,所以变量地址好计算,所以分配和销毁和访问速度都比较快.
- 内存预分配,比如8M已经分配好了,栈的问题生命周期比较有限,函数退出就没有了,大小受限就比如递归函数递归多层会报栈溢出。
- 栈的优势是,存取速度比堆要快,仅次于寄存器,栈数据可以共享,基本数据类型存储在“栈”中,对象引用类型实际存储在“堆”中,在栈中只是保留了引用内存的地址值。栈里放的是地址,堆里可以放数据也可以放地址(想象下堆里的东西也有可能指向别的地方);但缺点是,存在栈中的数据大小与生存期必须是确定的,缺乏灵活性。