ЗНЪНвЛ:ЪЕЯжМЬГаThreadРр
ВНжш:
1:ЖЈвхвЛИіРрШЅМЬГаThreadРр,БШШчThreadDemo
2:жиаДrun()ЗНЗЈ
3:дкВтЪдРржаДДНЈThreadDemoРрЕФЖдЯѓ
4:ЦєЖЏЯпГЬ
ThreadDemoРр
public class ThreadDemo extends Thread {
@Override
public void run() {
for (int i = 0; i <100 ; i++) {
System.out.println("ЖрЯпГЬдЫаа..."+i);
}
}
}
ВтЪдРр
public class TestDemo {
public static void main(String[] args){
ThreadDemo threadDemo1 = new ThreadDemo();
ThreadDemo threadDemo2 = new ThreadDemo();
//ЯпГЬжДааЕФЗНЗЈ,ПЊЦєСЫСЉИіЯпГЬ
threadDemo1.start();
threadDemo2.start();
}
}
дЫааНсЙћ
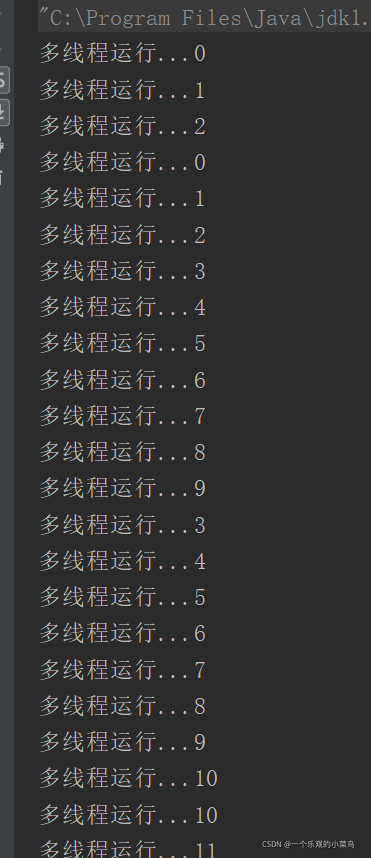
ПДСЫвЛЯТДњТы,ЦфЪЕетИіЗНЪНвВЪЧЭЈЙ§ЪЕЯжRunnableНгПкЭъГЩЕФ
ЗНЪНЖў:ЪЕЯжRunnableНгПк
ВНжш:
1:ЖЈвхвЛИіРр,ЪЕЯжRunnableНгПк,БШШчRunnableDemoРр
2:жиаДrun()ЗНЗЈ
3:ДДНЈВтЪдРр,ВЂДДНЈRunnableDemoРрЖдЯѓ
4:ДДНЈThreadЖдЯѓ,НЋRunnableDemeРрЖдЯѓзїЮЊЙЙдьЗНЗЈЕФВЮЪ§ДЋНјШЅ
5:ЦєЖЏЯпГЬ
RunableDemoРр
public class RunnableDemo implements Runnable {
@Override
public void run() {
for (int i = 0; i < 100; i++) {
System.out.println(Thread.currentThread().getName()+"-----"+i);
}
}
}
ВтЪдРр
public class TestDemo {
public static void main(String[] args){
RunnableDemo runnableDemo = new RunnableDemo();
Thread thread1 = new Thread(runnableDemo, "ЯпГЬ1");
Thread thread2 = new Thread(runnableDemo, "ЯпГЬ2");
thread1.setPriority(10);//етЪЧЩшжУЯпГЬгХЯШМЖЕФЗНЗЈ,10гХЯШМЖзюИп,1зюЕЭ
thread2.setPriority(1);
thread1.start();
thread2.start();
}
}
дЫааНсЙћ
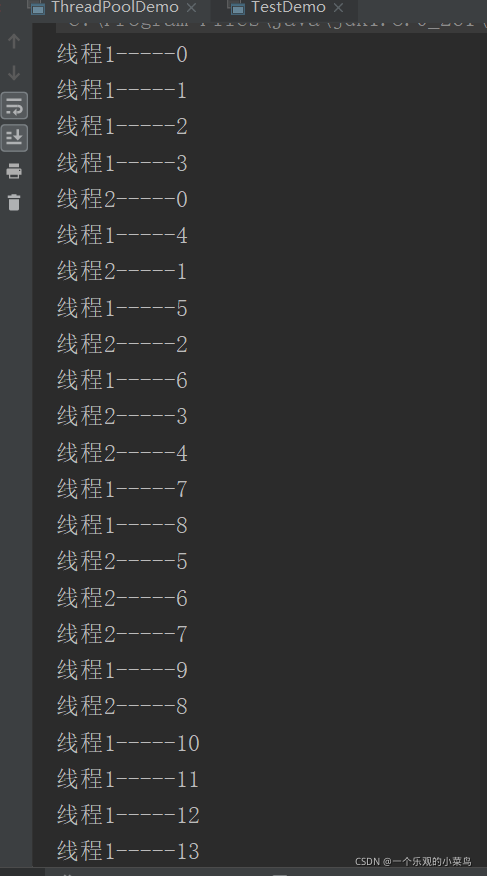
гыЕквЛжжЗНЪНПДЦ№РДЦфЪЕЧјБ№ВЛДѓЙў,ОЭЪЧЪЕЯжКЭМЬГаЕФЧјБ№,ЛЙгаДДНЈЯпГЬЪБашвЊНЋФЧИіЪЕЯжСЫRunnableНгПкЕФЖдЯѓДЋШыThreadжаЕБЙЙдьЗНЗЈЕФВЮЪ§
ЗНЪНШ§:ЪЕЯжCallableНгПк
ВНжш:
1:ЖЈвхвЛИіРрЪЕЯжCallableНгПк,ВЂжИЖЈЗЕЛижЕРраЭ,БШШчCallableDemo
2:жиаДcall()ЗНЗЈ
3:ДДНЈВтЪдРр,ДДНЈCallableDemoЖдЯѓ
4:ДДНЈFutureЕФЪЕЯжРрFutureTaskЖдЯѓ,ВЂНЋCallableDemoЖдЯѓзїЮЊЙЙдьЗНЗЈЕФВЮЪ§ДЋНјШЅ
5:ДДНЈThreadРрЕФЖдЯѓ,НЋFutureTaskЖдЯѓзїЮЊЙЙдьЗНЗЈЕФВЮЪ§ДЋНјШЅ
6:ЦєЖЏЯпГЬ
7:ПЩвдЭЈЙ§getЗНЗЈЛёШЁЯпГЬНсЪјКѓЕФНсЙћ
CallableDemo Рр
//ЗЕЛижЕЪЧstringРраЭ
public class CallableDemo implements Callable<String> {
@Override
public String call() throws Exception {
for (int i = 0; i < 100; i++) {
System.out.println("е§дкжДаа" + i);
}
//ЗЕЛижЕОЭБэЪОЯпГЬдЫааЭъБЯжЎКѓЕФНсЙћ
return "ХЖЛэ";
}
}
ВтЪдРр
public class Demo {
public static void main(String[] args) throws ExecutionException, InterruptedException {
//ЯпГЬПЊЦєжЎКѓашвЊжДааРяУцЕФcallЗНЗЈ
CallableDemo mc = new CallableDemo ();
FutureTask<String> ft = new FutureTask<>(mc);
//ДДНЈЯпГЬЖдЯѓ
Thread t1 = new Thread(ft);
String s = ft.get();
//ПЊЦєЯпГЬ
t1.start();
System.out.println(s);
}
}
етИіИњжЎЧАЕФВЛЭЌжЎДІОЭЪЧгаИіЗЕЛижЕ,ШЛКѓДДНЈЪБгаЫљВЛЭЌ
змНс:
1:дкАЂРяАЭАЭПЊЗЂЪжВсжаУїШЗЬсЕН,ВЛдЪаэЯдЪОДДНЈЯпГЬ,гІИУгУЯпГЬГиЕФЗНЪНЬсЙЉ
2:ЩЯУцШ§жжЪЕЯжЖрЯпГЬЕФЗНЪНЕквЛжжвђЮЊЪЧМЬГа,РЉеЙадШѕ,ВЛЭЦМіЪЙгУ,ЕкЖўжжКЭЕкШ§жжЕФЧјБ№ОЭЪЧгаЮоЗЕЛижЕ
3:ЗДе§ЖМВЛеІгУ,ПДПДСЫНтвЛЯТЕУСЫ,жиЕуЪЧЯТУцЕФЯпГЬГиДДНЈЯпГЬ
ЗНЪНШ§:гУЯпГЬГиЕФЗНЪНЪЕЯжЖрЯпГЬ
1:ЪВУДЪЧЯпГЬГи
МђЕЅРэНтОЭЪЧЯпГЬГиЪЧвЛИіДцДЂЯпГЬЕФГизг,РДСЫИіШЮЮёЮвВЛашвЊзЈУХШЅаТНЈ,жЎКѓгжЯњЛй,ЯпГЬГижагаДѓСПЕФПеЯаЯпГЬ,ЦєЖЏетИіЯпГЬзіШЮЮё,зіЭъжЎКѓвВВЛгУЯњЛй,ЯпГЬЛсМЬајБфГЩПеЯазДЬЌ
ОЭКУЯёЪЧвЛИіЫЎГи,ЮвУПДЮЯыКШЫЎВЛгУШЅЭкИіОЎ,КШЭъжЎКѓдйАбОЎЬюЩЯ,жБНгДгЫЎГиРяУцКШОЭааСЫ
2:ЯпГЬГиЕФДцдкЕФвтвх
вђЮЊДДНЈЯњЛйЯпГЬБШНЯЯћКФЯЕЭГзЪдД,ЮЊСЫБмУтЦЕЗБЕФШЅДДНЈВЂЯњЛйФЧаЉЖЬднЕФЯпГЬ;
МѕЩйдкДДНЈКЭЯњЛйЯпГЬЩЯЫљЛЈЕФЪБМфвдМАЯЕЭГзЪдДЕФПЊЯњ,
ШчЙћВЛЪЙгУЯпГЬГи,гаПЩФмдьГЩЯЕЭГДДНЈДѓСПЭЌРрЯпГЬЖјЕМжТЯћКФЭъФкДцЛђепЁАЙ§ЖШЧаЛЛЁБЕФЮЪЬтЁЃ
3:ШчКЮЪЙгУЯпГЬГи
ЯпГЬГигаМИжжДДНЈЗНЪН,БШШч
FixedThreadPool ЖЈГЄЯпГЬГи
ScheduledThreadPool,ЖЈЪБЯпГЬГи
CachedThreadPool ПЩЛКДцЯпГЬГи
SingleThreadExecutor ЕЅЯпГЬЛЏЯпГЬГи
ЕЋЪЧ,АЂРяЪжВсУїШЗвЊЧѓ,ВЛФмЪЙгУЫћУЧ

Ыљвд,ЯпГЬГиЕФЪЙгУжиЕуЪЧThreadPoolExecutor
ЙигкThreadPoolExecutorЕФДДНЈ
//ДДНЈЯпГЬГи
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(КЫаФЯпГЬЪ§СП,зюДѓЯпГЬЪ§СП,ПеЯаЯпГЬзюДѓДцЛюЪБМф,ШЮЮёЖгСа,ДДНЈЯпГЬЙЄГЇ,ШЮЮёЕФОмОјВпТд);
дкideaжаctrl+PВщПДДДНЈЯпГЬГиЕФВЮЪ§ШчЯТ

ЯТУцРДЯъЯИНтЪЭетаЉВЮЪ§
ВЮЪ§1(Биаш):int corePoolSize :КЫаФЯпГЬЪ§;КЫаФЯпГЬЛсвЛжБДцЛю,ШчЙћНЋ allowCoreThreadTimeout ЩшжУЮЊ true ЪБ,КЫаФЯпГЬвВЛсБЛГЌЪБЛиЪе;
ЩшжУДњТыШчЯТ
threadPoolExecutor.allowCoreThreadTimeOut(true);
ВЮЪ§2(Биаш):int maximumPoolSize:ЯпГЬГиЫљФмШнФЩЕФзюДѓЯпГЬЪ§ЁЃЕБЛюдОЯпГЬЪ§ДяЕНИУЪ§жЕКѓ,КѓајЕФаТШЮЮёНЋЛсзшШћЁЃШчЙћЯпГЬЪ§ГЌЙ§СЫКЫаФЯпГЬЪ§,ФЧУДЛсДДНЈаТЕФЯпГЬ,зюЖрОЭжЛФмДДНЈетУДЖр;
ВЮЪ§3(Биаш):long keepAliveTime :ЯпГЬЯажУГЌЪБЪБГЄЁЃШчЙћГЌЙ§ИУЪБГЄ,ЗЧКЫаФЯпГЬОЭЛсБЛЛиЪеЁЃШчЙћНЋ allowCoreThreadTimeout ЩшжУЮЊ true ЪБ,КЫаФЯпГЬвВЛсГЌЪБЛиЪеЁЃ
ВЮЪ§4(Биаш):TimeUnit unit:жИЖЈ keepAliveTime ВЮЪ§ЕФЪБМфЕЅЮЛЁЃГЃгУЕФга:TimeUnit.MILLISECONDS(КСУы)ЁЂTimeUnit.SECONDS(Уы)ЁЂTimeUnit.MINUTES(Зж)ЁЃ
ВЮЪ§5(Биаш):BlockingQueue workQueue : ШЮЮёЖгСаЁЃЭЈЙ§ЯпГЬГиЕФ execute() ЗНЗЈЬсНЛЕФ Runnable ЖдЯѓНЋДцДЂдкИУВЮЪ§жаЁЃЦфВЩгУзшШћЖгСаЪЕЯжЁЃ
гавдЯТМИжж
new ArrayBlockingQueue<Runnable>(20);
new LinkedBlockingDeque<Runnable>();
new PriorityBlockingQueue<>();
new SynchronousQueue<>();
new LinkedBlockingDeque<>();
new LinkedBlockingQueue<>();
new DelayQueue<DelayedЖдЯѓ>();
ВЮЪ§6(ПЩбЁ):ThreadFactory threadFactory:ЯпГЬЙЄГЇЁЃгУгкжИЖЈЮЊЯпГЬГиДДНЈаТЯпГЬЕФЗНЪНЁЃ
ВЮЪ§7(ПЩбЁ):RejectedExecutionHandler handler:ОмОјВпТдЁЃЕБДяЕНзюДѓЯпГЬЪ§ЪБашвЊжДааЕФБЅКЭВпТдЁЃФЌШЯЖЊЦњШЮЮёВЂХзГі RejectedExecutionException вьГЃЁЃ
ПЩбЁЕФетСЉИіВЮЪ§гаФЌШЯЬсЙЉЕФ
ЙигкЯпГЬГиЕФВПЗж,ВЮПМДѓРаЮФеТ
ГЙЕзИуЖЎЯпГЬГи