
?
?
?

?
?
?
�����˹�:
16:00����,16:08�ͳ����� ,�ʵ�ʵ����̫...
���̲߳���:
Spring
Spring��SpringBoot������
Spring��һ����̬��ϵ,������������,��springboot��springframework�ȡ�����Spring Framework������spring��̬�Ļ�ʯ��
Spring Framework��һ����������Java web�������,��IOC��AOPΪ����,Ȼ���ڴ����ߵĻ�����ʵ�������������Ʒ�ĸ����ܡ�������������,��SpringMVC��SpringJDBC���õ������ģʽ��:
-
����ģʽ:BeanFactory���Ǽ���ģʽ������,�������������ʵ��;
-
����ģʽ:BeanĬ��Ϊ����ģʽ��
-
����ģʽ:Spring��AOP�����õ���JDK�Ķ�̬������CGLIB�ֽ������ɼ���;
-
ģ�巽��:������������ظ������⡣����. RestTemplate, JmsTemplate, JpaTemplate��
-
�۲���ģʽ:��������һ��һ�Զ��������ϵ,��һ�������״̬�����ı�ʱ,�������������Ķ���õ�֪ͨ���ƶ�����,��Spring��listener��ʵ�֨CApplicationListener��
Spring Boot�ǻ���Spring Framework 4.0������,���ĵ�����Ϊ�˼� Spring ��ܳ�ʼ��Լ������Ĺ���,ʹ�������Բ������� Spring Ӧ�ó����е� XML ����,Ϊ���졢����Ч�Ŀ��� Spring �ṩ����������֧�֡������������������ص�:
-
������web����,��Tomcat��
-
ͨ��starter���Լ�������
-
xml����ͨ��ע����ʽʵ���Զ�����
-
���jar�����ֱ�Ӳ�������
����Ӧ�ó���������������,Spring֧�ִ�ͳ��web.xml������ʽ�Լ����µ�Servlet3+����,SpringBoot��ʹ�� Servlet3����������Ӧ�ó���
Spring Cloud��һ������Spring Boot����������������Ϊ�������ṩ�˺ܶ��,���ڿ��ٹ����ֲ�ʽϵͳ��һЩͨ��ģʽ,����:���ù�����ע�����ġ������֡����������ء���·�ٵȡ�
Spring Boot ����������
SpringBoot ����Щ�ŵ�?���� Spring ��ʲô����? - ����
1.������������ʱ�����
�˼�ʱ����Ϊ�˼�ز���¼ Spring Boot Ӧ��������ʱ���,�����¼��ǰ���������,Ȼ������ʱ����
2.����Ӧ�������Ķ�����쳣���漯��
�˹���������Ӧ�������Ķ����һ���쳣����� ArrayList ���ϡ�
3.����ϵͳ���� headless ��ֵ
���� Java.awt.headless = true,���� awt(Abstract Window Toolkit)�ĺ����dz��ڹ���������Ϊ true ��ʾ����һ�� headless ������,������������һЩ��ͼ������
4.�������� Spring ���м�����������Ӧ�������¼�
�˹������ڻ�ȡ���õļ��������Ʋ�ʵ�������е��ࡣ
5.��ʼ��Ĭ��Ӧ�õIJ�����
Ҳ����˵����������һ��Ӧ�ò�������
6.������
�������ò��Ұ���(ͨ�� property sources �� profiles �������ļ�)��
7.���� Banner �Ĵ�ӡ��
Spring Boot ����ʱ���ӡ Banner ͼƬ���� banner ��Ϣ���� SpringBootBanner ���ж����,���ǿ���ͨ��ʵ�� Banner �ӿ����Զ��� banner ��Ϣ,Ȼ��ͨ������ setBanner() �������� Spring Boot ��Ŀʹ���Լ��Զ��� Banner ��Ϣ,�������� resources ������һ�� banner.txt,�� banner ��Ϣ���ӵ����ļ���,�Ϳ���ʵ���Զ��� banner �Ĺ����ˡ�
8.����Ӧ��������
���ݲ�ͬ��Ӧ��������������ͬ�� ApplicationContext �����Ķ���
9.ʵ�����쳣������
�����õ��� getSpringFactoriesInstances() ��������ȡ�����쳣�������,��ʵ�������е��쳣�����ࡣ
10.��Ӧ��������
�˷�������Ҫ�����ǰ������Ѿ������õĶ���,���ݸ� prepareContext ����������,���罫�������� environment ������������С����� bean �������Լ���Դ����������¼������־�Ȳ�����
11.ˢ��Ӧ��������
�˷������ڽ��������ļ�,���� bean ����,�����������õ� web �����Ȳ�����
12.Ӧ��������ˢ��֮����¼�����
���������Դ���ǿյ�,������һЩ�Զ���ĺ��ô���������
13.ֹͣ��ʱ�����
ֹͣ�˹��̵�һ���еij����ʱ��,��ͳ�������ִ����Ϣ��
14.�����־��Ϣ
����صļ�¼��Ϣ,��������ʱ�����Ϣ���п���̨�����
15.����Ӧ����������������¼�
�������� SpringApplicationRunListener �������� started �¼�������
16.ִ������ Runner ������
ִ�����е� ApplicationRunner �� CommandLineRunner ��������
17.����Ӧ�������ľ����¼�
�������е� SpringApplicationRunListener �������� running �¼���
18.����Ӧ�������Ķ���
����Ϊֹ Spring Boot ����������ͽ�����,���ǾͿ���������ʹ�� Spring Boot ����ˡ�
SpringMVC ���������
-
DispatcherServlet ��������
-
HandlerMapping ������ɷ�,����������Ϳ���������һһ��Ӧ�Ĺ���
-
Controller �����Ĵ�����
-
ModelAndView ��װģ����Ϣ����ͼ��Ϣ
-
ViewResolver ��ͼ������,��λҳ��
SpringMVCִ������
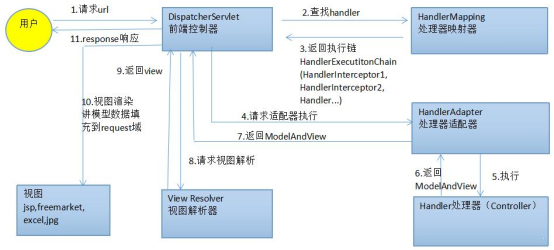
-
�ͻ�����������ǰ�˿�����DispatcherServlet
-
ǰ�˿������յ���������������ӳ����hanlderMapping
-
������ӳ�������ҵ�����Ĵ�����,��������������������������,��һ�ظ�ǰ�˿�����
-
ǰ�˿���������������������HandlerAdapter
-
����������������������þ����������Handler/Controller
-
������ִ����ɷ�����ͼ����modelAndView
-
����������������ͼ���ظ�ǰ�˿�����
-
ǰ�˿���������ͼ������ͼ������ViewReslover
-
��ͼ���������ؾ������ͼView
-
ǰ�˿�����������ͼ������Ⱦ
-
ǰ�˿�������Ӧ�û�
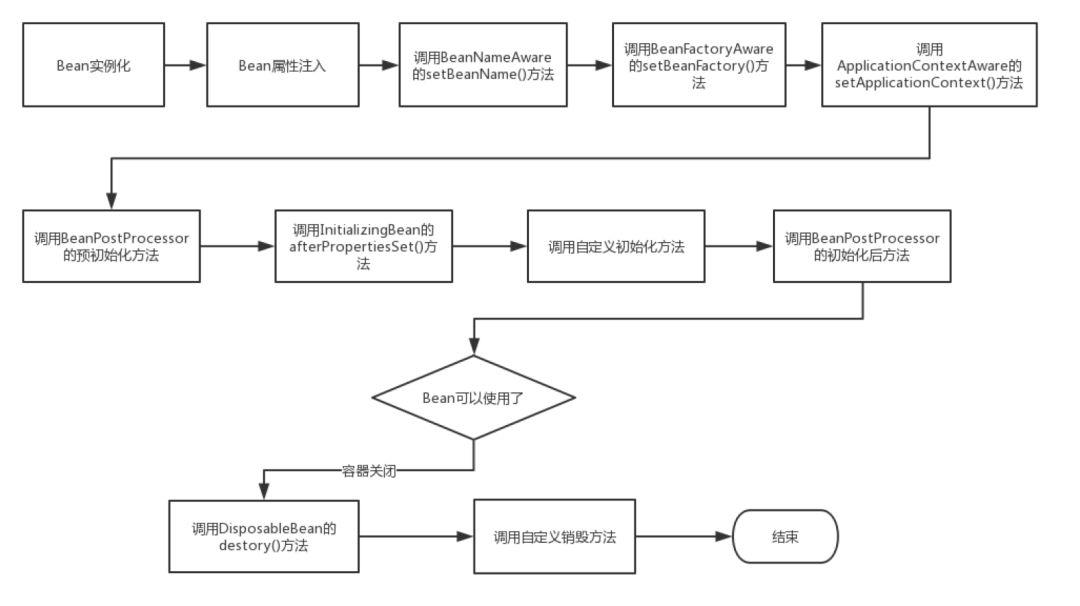
bean����������
1��ʵ����Bean����
2������Bean������
3��ע��Aware������
4��ִ��ǰ�ô�������,postProcessorBeforeInitialization()
5��ִ��afterPropertiesSet()����,
6��ִ��Bean�Զ���ij�ʼ������,����@PostConstructע���ע
7��ִ�к��ô�������,POSTProcessorAfterInitialization()
8���������
9��ִ�ж������ٷ���destory()
10��ִ���Զ�������ٷ���,����@PreDestoryע���ע
11�������������
springboot�ĺ��ļ���
����ע�롢�¼�����Դ��i18n����֤�����ݰ�����ת����SpEL��AOP
���Դ���tomcat
��pom.xmlȥ��tomcat��ص�����,������������servlet����
SpringMVC����ע��
-
@Controller:ʹ�ø�ע��ʱ����Ҫʵ��Controller�ӿ�,��ע�����������һ��������
-
@Repository:����ע��dao��,һ������DAO��ʵ������
-
@Service:���ڶ�ҵ���������ע��
-
@Component:ע��������,�ᱻspring����ʶ��,��תΪbean���൱��ͨ�õ�ע��
-
@RequestMapping:���������ַӳ��,������������ͷ�����,��ʾ��������÷���ʱ��url
-
@Resource:�Զ�ע��bean,Ĭ�ϰ���ByName�Զ�ע��,Ҳ����byTypeע��
-
@Autowired:�Զ�ע��bean,����byTypeע��
-
@ModelAttribute:���ڰѲ������浽model��,��ע�ⷽ�������
-
@PathVariable:���ڽ�����URL�е�ģ�����ӳ�䵽�����IJ�����,��ȡ��urlģ���еı�����Ϊ����
-
@requestParam:���ڻ�ȡ���������ֵ
-
@ResponseBody:�����ڷ�����,���Խ��������ؽ����ij�ָ�ʽ����,��json��xml��ʽ
@Component��@Bean������
-
@Component ע����������,��@Beanע��������������
-
@Component��������Զ�װ�䵽Spring������,��@Bean ע��ͨ�����ڱ��и�ע��ķ����ж��������� bean��(return���bean)
Spring����
JavaGuide/Spring�����ܽ�.md at master �� Snailclimb/JavaGuide �� GitHub
Spring ֧����������ķ�ʽ������:
-
���ʽ�������:ͨ��
TransactionTemplate����TransactionManager�ֶ���������,ʵ��Ӧ���к���ʹ�� -
����ʽ�������:ͨ�� AOP ʵ��(����
@Transactional��ȫע�ⷽʽʹ�����)��
@Transactional�����÷�Χ:
-
���� :�Ƽ���ע��ʹ���ڷ�����,������Ҫע�����:��ע��ֻ��Ӧ�õ� public ������,������Ч��
-
�� :������ע��ʹ�������ϵĻ�,������ע��Ը��������е� public ��������Ч��
-
�ӿ� :���Ƽ��ڽӿ���ʹ�á�
Spring���Զ�װ��
�Ա�һ��:��˵һ�� Spring Boot �Զ�װ��ԭ����?�� - JavaGuide - ����
����ע���setterע����ʱ��������ʱ�Ƚ��鷳�����Զ�װ�䡱ָ����spring��������ij�ֹ���,�Զ���������֮���������ϵ����spring���ʽĬ�ϲ�֧���Զ�װ���,Ҫ��ʹ���Զ�װ��,����Ҫ��spring�����ļ���<bean>��ǩ��autowire���ԡ�
�Զ�װ��Ĺ���:
-
no:��֧���Զ�װ�书��,springĬ�ϡ�
-
default:��ʾĬ�ϲ�����һ����ǩ���Զ�װ���ȡֵ��������ڶ�������ļ��Ļ�,��ôÿһ�������ļ����Զ�װ�䷽ʽ���Ƕ����ġ�
-
byName:
��һ��bean�ڵ���� autowire="byName" ������ʱ:
�ٽ������������������ԡ�
��ȥ�����ļ��в����Ƿ����id����������������ͬ��bean��
�������,��ȡ�ø�bean����,�����������������е�setter����,���ҵ���beanע��;�Ҳ���ע��null��
ע��:�������ҵ��������������bean(idΨһ)
-
byType:
��һ��bean�ڵ���� autowire="byType" ������ʱ:
�ٽ������������������ԡ�
��ȥ�����ļ��в����Ƿ����bean����������������ͬ��bean��
�������,��ȡ�ø�bean����,�����������������е�setter����,���ҵ���beanע��;�Ҳ���ע��null��
ע��:�ҵ��������������beanʱ�ᱨ����
-
constructor:
ʹ�ù��췽����ɶ���ע��,��ʵҲ�Ǹ��ݹ��췽���IJ������ͽ��ж������,�൱�ڲ���byType�ķ�ʽ����:���ݹ��췽���IJ�������������,���� byType ģʽ���Զ�װ�䡣
Springע�뷽ʽ
���õ�ע�뷽ʽ��Ҫ������:
-
���췽��ע��:�����ε����췽���С�
-
setterע��
-
����ע���ע��:@Autowired�Զ�װ��,Ĭ���Ǹ�������ע��,�����������������ֶΡ�����ע�롣
Springѭ������
����ѭ�����������ǰ������:Spring������BeanĬ�϶�������ģʽ��
���ѭ��������˼·:��������+��ǻ�����
Spring����������:
-
һ������:���������Ѿ�������ɵ�bean
-
��������:�������������е�bean(���ʵ����,����δ�������ע��)
-
��������:�������ObjectFactory���͵Ķ���Ĺ���,ͨ�������ķ������Ի�ȡ��Ŀ�����
-
��ǻ���:�������ڴ����еĶ������ơ�
ע��:���������澭��������װ���滻��,���뵽�ڶ������档
�����ѭ�������ij���:Spring�����������ͨ��������������ע���ѭ����������,���������ͨ�����췽������ע����ѭ������������
IOC��DI��AOP
-
IOC: Inversion of Control,���Ʒ�ת�� ��������Bean�Ŀ���Ȩ��Ӧ�ó���ת�Ƶ���ܡ�IOC��Ҫ����˴���ĸ߶�������⡣��Ҫ��3��ʵ�ַ�ʽ:set����ע�롢���췽��ע�롢ע��ע�롣
-
DI:Dependency Injection,����ע�롣��IOC�ľ���ʵ��,��������Ķ������,��Spring������(ע��)����������֮���������ϵ,��Щ������ϵҲֻ��ʹ��ʱ�ű�������
-
AOP:Aspect Oriented Programming,���������̡����ǽ��������е�Ƶ�����ֻ�������ҵ����������ضȲ��ߵĴ���������,ͨ�������̵ķ�ʽ����Ҫ���õ�ʱ��������õ�˼�롣����˼���ʵ�ֻ�����Spring�б���Ӧ����java����̬������java��������
Spring AOP ʵ��ԭ��
dz��Spring��AOP��ʵ��ԭ��������̬���� - �������� - ����
ͨ����̬����ʵ��,�ֱ���JDK�Ķ�̬������CGLib�Ķ�̬�������������ΪSpring��ij��bean����������,��ôSpring�ڴ������bean��ʱ��,ʵ���ϴ����������bean��һ����������,���Ǻ�����bean�з����ĵ���,ʵ���ϵ��õ��Ǵ�������д������������
SpringĬ��ʹ��JDK�Ķ�̬����ʵ��AOP,�����ʵ�����ӿ�,Spring�ͻ�ʹ�����ַ�ʽʵ�ֶ�̬������JDK�Ķ�̬�����ǻ�������ʵ�֡�
JDK�Ķ�̬������������,�Ǿ��DZ��������������һ��ʵ���˽ӿڵ���,��������Ҫʵ����ͬ�Ľӿ�,��ʵ�ִ����ӿ��������ķ���������Ҫ��������û��ʵ�ֽӿ�,��ʱJDK�Ķ�̬������û�а취ʹ��,����Spring��ʹ��CGLib�Ķ�̬���������ɴ�������CGLibֱ�Ӳ����ֽ���,�����������,��д��ķ�����ɴ�����
Java
��������������̵�����
������̵Ŀ�������������Ҫ���Ƕ��¼��Ĵ������̡������Ķ�����Ա�������ʽ����,���봦������֮�䲻����Լ����ϵ������������ʹ��������̷�����Ƶij���Ѵ����������봦���ķ����ֿ�,��˸��ֳɷִ��۸��ӵط���һ��,��������,�׳���,�������ڵ��ԡ�
�������Ŀ�����ʽ��,������Ϊ����,�����ݼ������ݵIJ�������һ��,�γɶ���ʹ�������̻����������ԵIJ�ͬ����,ʹ�ü̳�����������,ʹ�ýӿ����淶�����ݵIJ���,ʹ�ö�̬�ﵽ����������ԡ�
���������ά�������á�����չ���������������������װ���̳С���̬������,���Կ�����Ƴ�����ϵ�ϵͳ,ʹϵͳ��������������ά����
������ͽӿڵ�����
-
����������й��췽��,�ӿ��в����й��췽����
-
�������п�������ͨ��Ա����,�ӿ���û����ͨ��Ա����
-
�������п������dz������ͨ����,�ӿ��е����з������붼�dz����,�����зdz������ͨ������
-
�������еij����ķ������Ϳ����� public,protected ,���ӿ��еij���ֻ���� public ���͵�,����Ĭ�ϼ�Ϊ public abstract ���͡�
-
�������п�������̬����,�ӿ��в��ܰ�����̬����
-
������ͽӿ��ж���������̬��Ա����,�������еľ�̬��Ա�����ķ������Ϳ�������,���ӿ��ж���ı���ֻ��public static final ����,����Ĭ�ϼ�Ϊ public static final ���͡�
-
һ�������ʵ�ֶ���ӿ�,��ֻ�ܼ̳�һ�������ࡣ
-
���������ʵ�ִ���ĸ���;��������Դ���ʵ������;
-
�г�������һ���dz�����;�������еķ������Բ��dz����;
��ͳ����������
-
��������Ϊpublic����protected(��Ϊ���Ϊprivate,���ܱ�����̳�,�������ʵ�ָ÷���),ȱʡ�����Ĭ��Ϊpublic��
-
�������������������
-
���һ����̳���һ��������,���������ʵ�ָ���ij������������û��ʵ�ָ���ij���,����뽫����Ҳ����ΪΪabstract�ࡣ
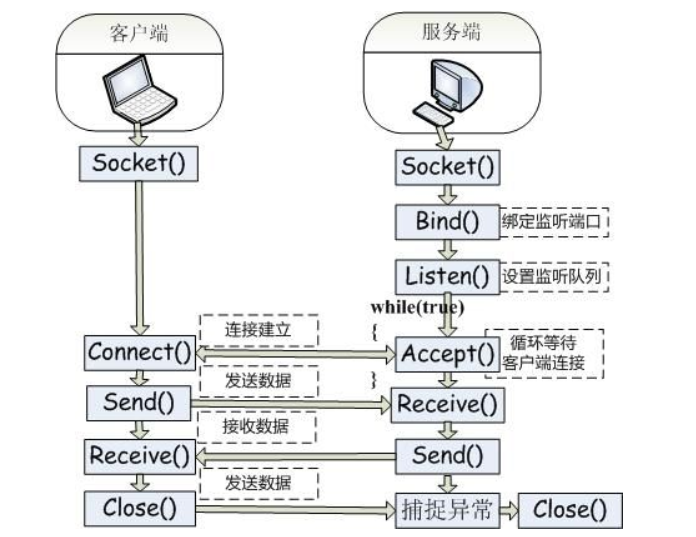
socket�������ӵĹ���
ͼ��Java�����Socket����ԭ��_һȺרҵ��ũ�ıʼDZ�-CSDN����_java�����socket
STW(Stop The World)
JVM STW(Stop The World)������ô����(��) | �����ѵIJ���
FullGC����������,����Ӧ�ó����̶߳��ᱻ��ͣ(native�������ִ��,��������JVM����),û���κ���Ӧ, �е������ĸо�����STW�жϵ�Ӧ�ó����̻߳������GC֮��ָ���STW��JVM�ں�̨�Զ�������Զ���ɵġ�
����ϵͳ��ͣ��ʱ��(STW)�������ռ��㷨 �ͷ����㷨_һ�������ֵij���YUAN�IJ���-CSDN����
����ϵͳ��ͣ��ʱ���������㷨:һ���������ռ��㷨,��һ���������㷨��
�����Ż���ע������
https://www.jb51.net/article/92453.htm
1�����������е�ʱ��ͷ�Χ
2����С��������,��������ΪС����,��ConcurrentHashMap������
3����/�����
4��������Ҫ���ַ�����������͵İ�װ��,��Ϊ�Ỻ��
��ɱ��������α�֤����һ����
�����Ʒֲ�ʽ��
�����ķֲ�ʽ��:MySql��Zk��Redis
JVM����
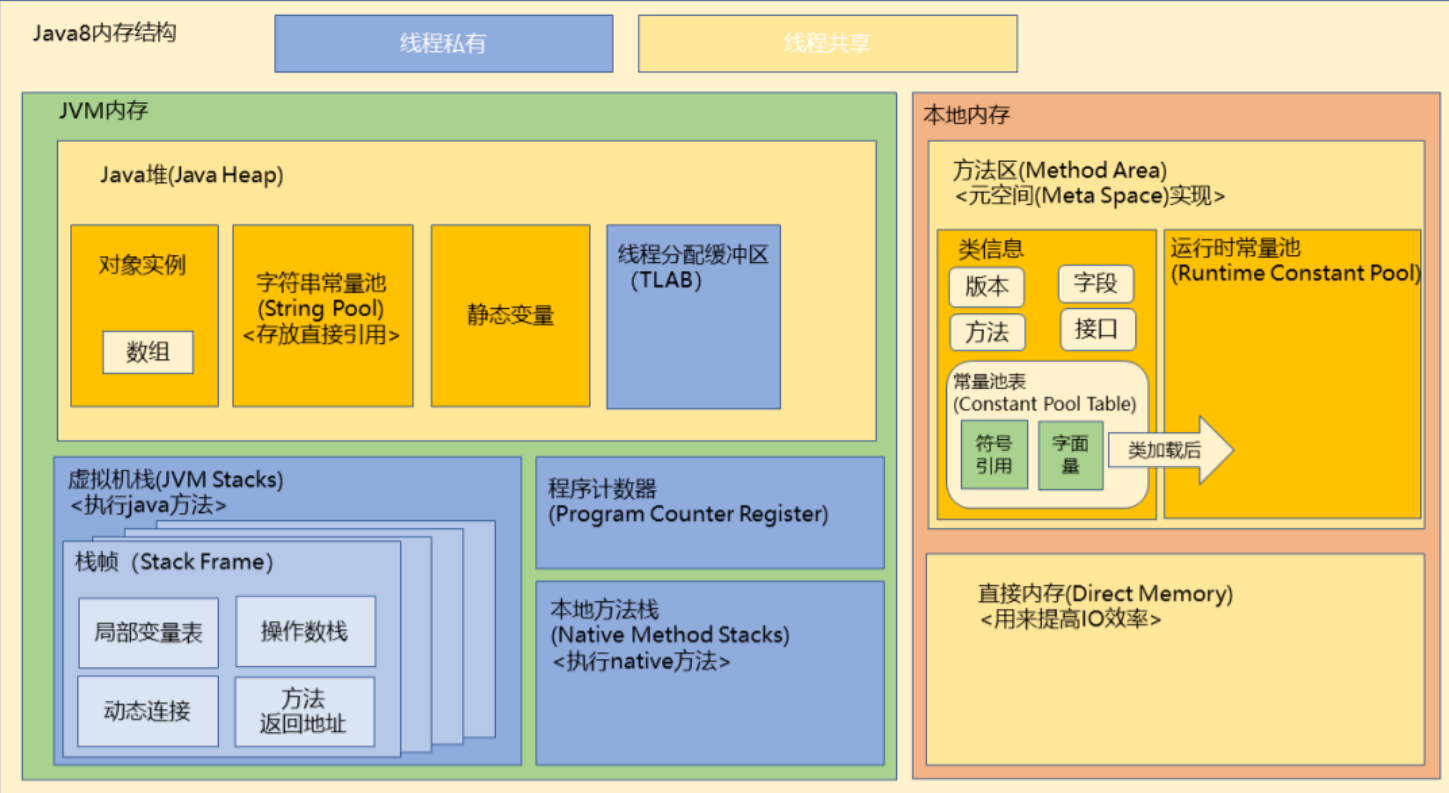
Java��������
������������:
| ������������ | boolean | byte | char | short | Int | long | float | double |
|---|---|---|---|---|---|---|---|---|
| � | 1 | 8 | 16 | 16 | 32 | 64 | 32 | 64 |
| ��װ���� | Boolean | Byte | Character | Short | Integer | Long | Float | Double |
������������:�ࡢ�ӿڡ����顢ö�١���ע
����
Java����
Java�ڱ���֮�������һ��class�ļ�,����ͨ���ֽ����ļ��ҵ������еķ��������Եȡ�
��ȡClass����ķ�ʽ:
-
Class.forName(�����·����);
-
����.class
-
������.getClass()
-
�������͵İ�װ��,���Ե��ð�װ���Type��������øð�װ���Class����
������Ƶ���ȱ��:
-
�ŵ�:
-
�ܹ�����ʱ��̬��ȡ���ʵ��,��������;
-
���붯̬������
-
-
ȱ��:
-
ʹ�÷������ܽϵ�,��Ҫ�����ֽ���,���ڴ��еĶ�����н�����
-
��Բ���ȫ,�ƻ��˷�װ��(��Ϊͨ��������Ի��˽�з���������)
-
����ײ�
https://segmentfault.com/a/1190000039302149
Java����ײ�ԭ���Լ�Ӧ��_WAXXD�IJ���-CSDN����
threadlocal
Java���Ա���:ThreadLocal�ռ�ƪ ��! - ���� - ����
https://segmentfault.com/a/1190000024438006
ThreadLocal��������Ҫ�������ݸ���,��������ֻ������ǰ�߳�,���������ݶԱ���̶߳�������Ը���ġ��ڶ��̻߳�����,���Է�ֹ�Լ��ı����������̴߳۸ġ�
Spring����Threadlocal�ķ�ʽ,����֤�����߳��е����ݿ����ʹ�õ���ͬһ�����ݿ�����,ͬʱ,�������ַ�ʽ����ʹҵ���ʹ������ʱ����Ҫ��֪������connection����,ͨ����������,����ع��������������֮����л�,����ͻָ���
�ڴ�й©���ڴ����
��221�ڡ����Թ�:̸̸�ڴ�й©���ڴ��������ϵ������-Java֪��
�����Ա�¼���ڴ�������ڴ�й© - ����
�ڴ�й©
�ڴ�й©��ָ�������Ѷ�̬����Ķ��ڴ�����ij��ԭ��δ�ͷŻ����ͷ�,���ϵͳ�ڴ���˷�,���³��������ٶȼ�������ϵͳ���������غ����
���ֵ��͵��ڴ�й©:
-
ȫ�ּ���
-
����
-
��װ����
�������ڴ�й©:
-
�Դ�������߲�ͷ���,�ҳ��ڴ�й©������λ��
-
ʹ��ר�ŵ��ڴ�й©���Թ��߽��в��ԡ�
�ڴ����
�ڴ����ָ�����������ڴ�ʱ,û���㹻���ڴ湩������ʹ�á�
�ڴ����ԭ��:
-
�ڴ��м��ص������������Ӵ�,��һ�δ����ݿ�ȡ����������;
-
���������жԶ��������,ʹ�����δ���,ʹ��JVM���ܻ���;
-
�����д�����ѭ����ѭ�����������ظ��Ķ���ʵ��;
-
ʹ�õĵ����������е�BUG;
-
���������ڴ�ֵ�趨�Ĺ�С
AIO��NIO
���Թ�����:�������BIO��NIO��AIO������?�Ҳ������! - ֪��
�����е�IO���ò�����¿��Է�Ϊ�����IJ�:
-
���������ϵͳ�������� ;
-
����ϵͳ���ⲿ���ݼ��ص��ں˵Ļ�������;
-
����ϵͳ���ں˵Ļ��������������̵Ļ����� ;
-
���̻����������Լ��Ĺ��� ;
������ϵͳ�ڰ��ⲿ���ݷŵ����̻����������ʱ��(�������ĵڶ�,����),���Ӧ�ý����ǹ���ȴ���,��ô����ͬ��IO,��֮,�����첽IO,Ҳ����AIO ��
nio��ʵ�ַ�ʽ
nio������ʵ�ַ�ʽ:select, poll, epoll_LuckyС���˵IJ���-CSDN����
select��poll��epoll
�㿽��
�㿽���ġ�������ָ�û�̬���ں�̬��copy���ݵ�����Ϊ�㡣�㿽����ȫ����������ϵͳ,������Java������
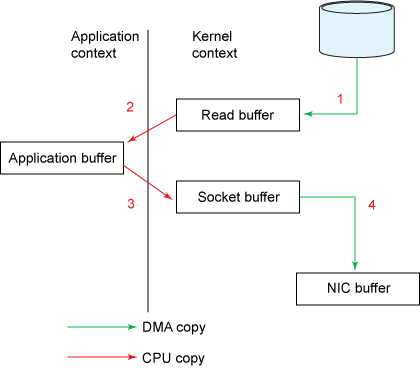
��ͳ������copy(�ļ����ļ���client��server��)�漰���Ĵ��û�̬���ں�̬�л����Ĵ�copy���Ĵ�copy��,�������û�̬���ں�̬��copy��ҪCPU���롢�������ں�̬��IO�豸��copyΪDMA��ʽ����ҪCPU���롣�㿽���������û�̬���ں�̬���copy(��2��)�������������û�̬�ں�̬����л�,������ݴ���Ч�ʸ�(4��4��2��2)��
�㿽������������ݴ���Ч��,��������Ҫ���û���������ж����ݽ��мӹ��ij���(�����)�����ʺ�ʹ���㿽����
Java NIO�е�FileChannelӵ��transferTo��transferFrom��������,��ֱ�Ӱ�FileChannel�е����ݿ���������һ��Channel
�ֲ�ʽ�����������
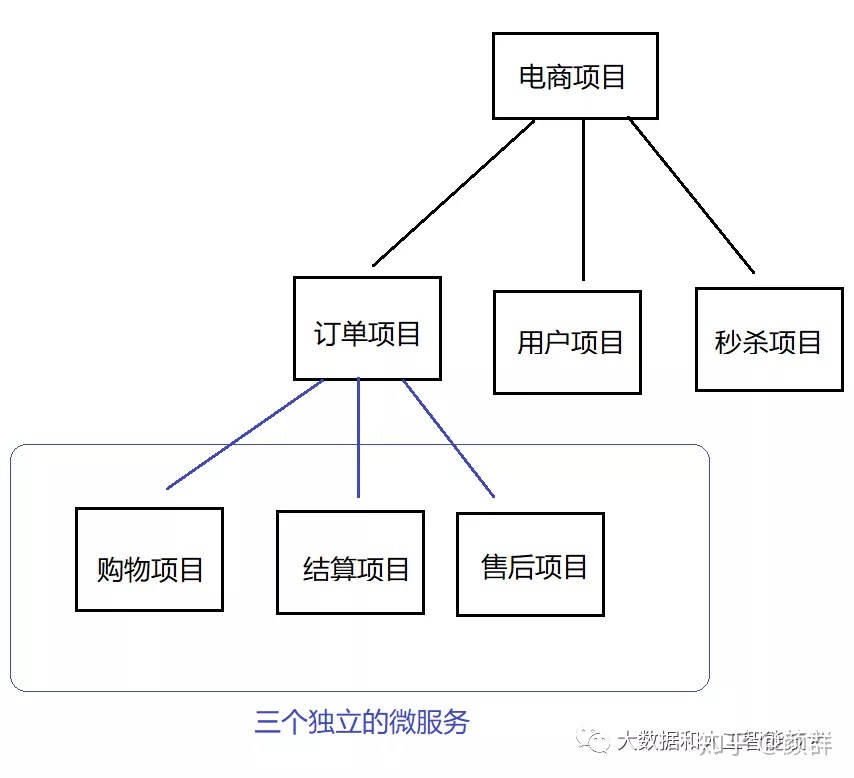
-
�ֲ�ʽ:��һ����Ŀ��ֳ��˶��ģ��,������Щģ��ֿ�����
-
ˮƽ���:���ݡ��ֲ㡱��˼����в�֡���һ����Ŀ���ݡ��ܹ�����ֳɶ����,�ٷֿ�����
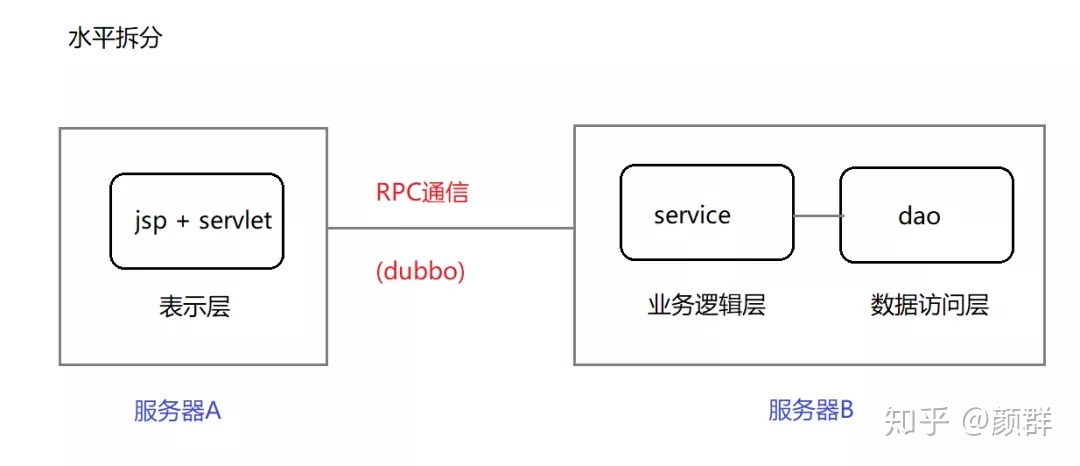
-
��ֱ���:����ҵ����в�֡���ֺ����Ŀ,��Ȼ������Ϊ��������Ŀʹ�á�
-
-
����:һ�ַdz�ϸ���ȵĴ�ֱ��֡�
����
HTTP 1.0/1.1
HTTP1.0��HTTP1.1��HTTPS_bian_qing_quan11�IJ���-CSDN����
HTTP�ǿͻ��˺ͷ�������֮�����ݴ������ʽ�淶,��ʽ���Ϊ�����ı�����Э��������һ��Ӧ�ò�Э��,����TCP/IPͨ��Э�顣
�� HTTP�������ӵ�:�����ӵĺ���������ÿ������ֻ�ܴ���һ������,������������ͻ��˵������յ��ظ�֮�����̶Ͽ���(��ʡ����ʱ��) ? �� HTTP��ý�������:ֻҪ�ͻ��˺ͷ����֪����δ�����������,�κ����͵����ݶ�����ͨ��HTTP����; ? �� HTTP����״̬Э��:��״̬Э��ָЭ���������û�м���������
| HTTP1.0 | HTTP1.1 | |
|---|---|---|
| ���� | GET��POST��HEAD | GET��POST��HEAD��PUT��DELETE��OPTIONS��CONNECT��TRACE |
| TCP���� | ������ | ������ |
| ������ˮ�� | ��֧�� | ֧�� |
| Host�ֶ� | ��֧�� | ֧�� |
| 100��Ӧ�� | ��֧�� | ֧�� |
HTTP2.0:
-
��Ӧ�ò�ʹ����֮��������һ�������Ʒ�֡��,�Ľ��˴������ܡ�
-
ÿһ��request��ʹ�������ӹ�������,���շ�ͨ��request��id���ֵ���ͬ���������
-
ͨ��encoder��,������ÿ�δ����header�е���Ϣ��
HTTP������
һ��TCP���ӿ��Դ�����request,������Ҫÿ��request����һ��TCP���ӡ�
HTTP1.0Ĭ�Ϲر�,��Ҫ��ͷ��Ϣ�м���Connection: Keep-Alive��������
HTTP1.1Ĭ���ǿ���״̬,����ʹ��Connection: close���رա�
�����ӿ��Ա������ӽ������ͷŵĿ���������ʱ���Tcp����������ϵͳ��Դ��Чռ��,�˷�ϵͳ��Դ��
��������һ������ʱ��,һ��http������tcp�����ڴ��������һ����Ӧ��,����Ҫholdסkeepalive_timeout���,�ſ�ʼ�ر�������ӡ�
TCP��Keep-Alive:����ÿ��һ��ʱ�䷢��һ������,���ж϶Է��Ƿ����ߡ���HTTP��Keep-Alive��һ����
HTTPЭ��ij����ӺͶ�����,ʵ������TCPЭ��ij����ӺͶ����ӡ�
HTTP������ʵ��ԭ��
HTTPЭ�鱾����OSI�߲�ο�ģ���е�Ӧ�ò�Э��,���������ͨ�ŵ�ʱ����ͨ���ϲ�Э���װͷ������Ϊ�²�Э������ݲ��ֽ��з�װ��,��ʵ�������Ǿ����Ӵ�����TCP/IPЭ���,Ҳ���Ǵ��������TCPЭ������������IPЭ�顣���HTTPЭ��ij����ӱ����Ͼ���TCP�ij�������
http��websocket��socket
������֮---http,websocket��socket��� - ����Ա��Ӫ
http:
http���������dz־�������Э�顣�����ֻ���ڿͻ��˷�������ʱ���ܷ������ݡ�
WebSocket:
WebSocket�ǻ���TCP��Ӧ�ò���˫��ͨ�����־û�Э�顣Э���ʶ����ws��wss���ڽ�������ʱ,ͨ�� HTTP/1.1 Э���101Э���л�״̬���������֡����ǽ���֮��,����������ʱ���Dz���ҪHTTPЭ���,����ʹ��TCPЭ��������������ͻ��˷�����Ϣ��
Websocketʹ�ú� HTTP ��ͬ�� TCP �˿�,�����ƹ����������ǽ�����ơ�
Socket:
Socket��ʵ������һ��Э��,����Ϊ�˷���ʹ��TCP��UDP�����������һ��,��λ��Ӧ�ò��������֮���һ��ӿ���
�ڳ����ڲ��ṩ�������ͨ�ŵĶ˿�,Ҳ�����˿�ͨ������ͨ������socket����,����Ϊͨ��˫�������ݴ����ṩһ��ͨ����
Socket��udp��scoket��tcp��socket,һ����õ���tcp��socket��
���������URL��
1����������:���������DNS���� -> PC������DNS���� -> host�ļ� -> �������������� -> ��������������
2��TCP3�����ֽ������ӡ�
3������HTTP����
4���������ӦHTTP����,������õ���������ݡ�
5�����������HTML����,��������Ҫ����Դ��
6���������ҳ�������Ⱦ,չ�ָ��û���
TCP��UDP
TCP��һ���������ӵġ��ɿ��ġ������ֽ����Ĵ����ͨ��Э�顣UDP��һ�������ӵġ����ɿ��ġ����ڱ��ĵĴ����ͨ��Э�顣
TCP�Ŀɿ�ͨ����ͨ��3������4�λ��֡��������ơ�ӵ�����ơ�ȷ��Ӧ���־�������ش��Ȼ��Ʊ�֤��,���Ҳ�����ʵʱ�Խϲ�,�����Ƚϴ�,�����ڿɿ���Ҫ��ߵij���,���ļ����䡣��UDP����֤�ɿ�ͨ��,��˿���С,������ʵʱ��Ҫ�ߵij���,����Ƶͨ����������Ϸ��
����,TCPֻ�ܵ�Ե�ͨ��,��UDP֧�ֶ�Զ�ͨ�š�
մ������
UDP �ǻ��ڱ��ķ��͵�,UDP�ײ������� 16bit ��ָʾ UDP ���ݱ��ĵij���,�����Ӧ�ò��ܺܺõĽ���ͬ�����ݱ������ֿ�,�Ӷ�����ճ���Ͳ�������⡣
�� TCP �ǻ����ֽ�����,�� TCP ���ײ�û�б�ʾ���ݳ��ȵ��ֶΡ����������ݳ���TCP���ʱ,�ͻᷢ�����;���������ݲ��� ʱ,���ȴ��ڻ�������,�ͻᷢ��մ����
����UDPЭ����˵,�����������Ϊ65535-IPͷ20-UDPͷ8;
����TCPЭ����˵,���������������������С(MSS)����,MSS����TCP���ݰ�ÿ���ܹ������������ݷֶ�������MSSΪ1460(1500-IPͷ20-TCPͷ20)��
RPC��HTTP��Feign
RPC (Remote Procedure Call)��Զ�̹��̵���,�Ƿֲ�ʽϵͳ������һ��ͨ�ŷ��������������������һ����ַ�ռ�(ͨ���ǹ����������һ̨������)�Ĺ��̻���,�����ó���Ա��ʽ�������Զ�̵��õ�ϸ�ڡ�
RPC �� HTTP ������û�о����м����,�������˵���ϵͳ��ֱ�����ݽ�����
������RPC�����:dubbo��dubbox��motan
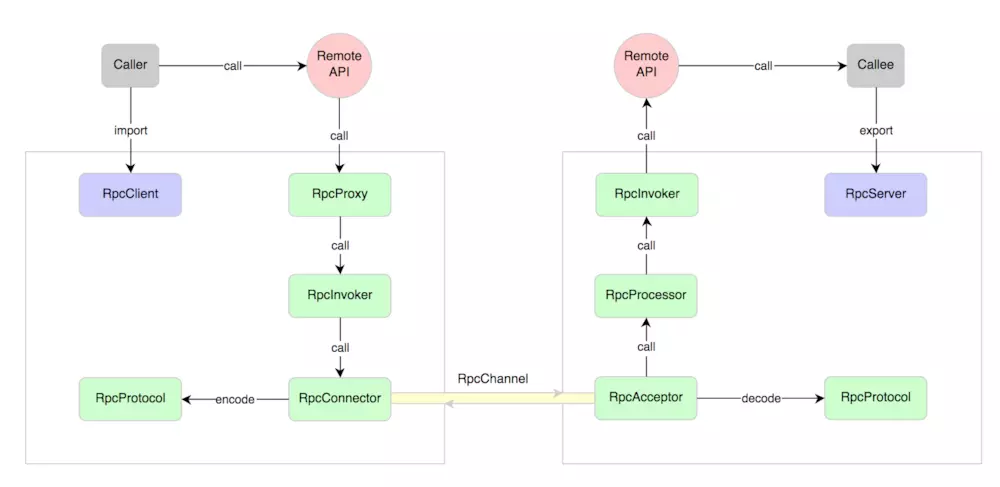
Feign�������������PRC���,Feign��װ�˸��ؾ���Ribbon�ͷ����۶ϱ���Hystrix,�ײ��õ���RestTemplate,Ҳ����HTTP����ʽ���е�Զ�̵���,����Ҳ�ơ�αHTTP�ͻ��ˡ�����ʹ�õ���Զ�̷��������ñ��ط���һ����,ֻ��Ҫ����һ���ӿڲ�����һ��ע�⼴�ɡ�
| HTTP | RPC | |
|---|---|---|
| ������ | HTTP | TCP��HTTP2 |
| ����Ч�� | 1.1�汾�����,2�汾��С | �����������С |
| �������� | ��ͨ��json,���Ĵ� | ����thriftʵ�ָ�Ч�����ƴ��� |
| ���ؾ��� | �����Nginx | �Դ� |
| ʹ�ó��� | ������칹���� | ��˾�ڲ��ķ����? |
MySQL
�����ӷ�ʽ
-
��������cross join,���ܸ�where��on
-
������inner join,���Ը�where��on
-
������left join
-
������right join
-
ȫ����full join
-
���ϲ�ѯunion/union all,���������������ֶθ���������ͬ��
����ʧЧ
������: MySQL ����ʧЧ��10��ԭ�� - ά����� - ����
-
��ѧ���㡢����������ת����,�ᵼ������ʧЧ��ת��ȫ��ɨ��
-
��ʹ�ò��Ⱥ�(!=��<>)ʱ��,��ʹ����������ȫ��ɨ��
-
is null,is not nullҲ��ʹ������
-
�� % ��ͷ�� like ��ѯ,�ᵼ��ȫ��ɨ��IJ���
-
�������� or ʱ,��ʹ�����в��������������ֶ�,Ҳ����ʹ������
�����Ż�
mysql�����Ż������� - hephec - ����
-
��Ƶ����Ϊ��ѯ�������ֶβ�ȥ��������
-
����Ƶ���ֶβ��ʺϴ�������
-
ʹ�ö�����
-
��������չ����,��Ҫ�½�����
-
���ڶ���Ϊtext��image��bit���������͵��в�Ҫ��������
-
��Ҫ�����Ͻ�������
-
�������������NULLֵ����
Redis
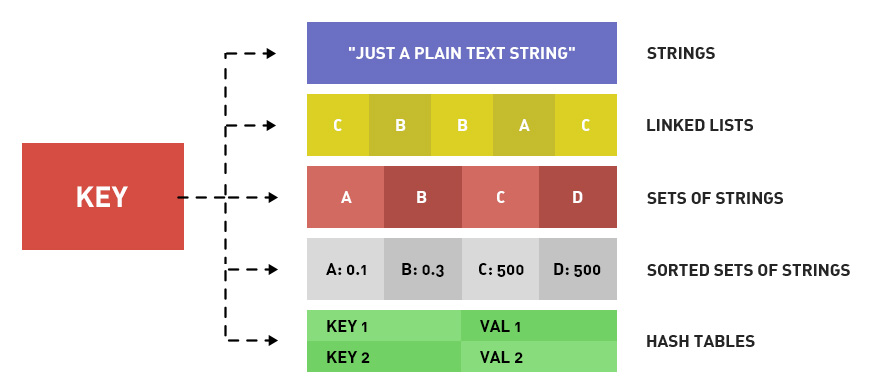
���ݽṹ
String:�ַ�������,�����ڻ��桢����session
List:�б�����,��������Ϣ���С����¡������б�
Set:��������,�����ں��ѡ���ǩ
SortedSet:��������,���������а�
Hash:��ϣ������,������ӳ���������
����һ����
���Թ�:��ô��֤��������ݿ�һ����?-����Ȧ
����ѩ�������洩���������
-
���洩
-
��������:��������ݿ��ж�û�е�����,���û����Ϸ�������,ÿ�ζ������ݿ���ȥȡ,�������ݿ�ѹ������
-
�������:�ӻ���ȡ����������,�����ݿ���Ҳû��ȡ��,��ʱҲ���Խ�key-value��дΪkey-null,������Чʱ��������ö̵�,��30��(����̫���ᵼ���������Ҳû��ʹ��)���������Է�ֹ�����û�������ͬһ��id��������
-
-
�������
-
��������:������ͬһ������,������û�е����ݿ�����(һ���ǻ���ʱ�䵽��),�������ݿ�ѹ��˲������,��ɹ���ѹ����
-
�������:�����ȵ�������Զ�����ڡ��ӻ�������
-
-
����ѩ��
-
��������:�����в�ͬ���ݴ�����������ʱ��,����ѯ��������,�������ݿ�ѹ����������崻���
-
�������:�����ȵ�������Զ�����ڡ��������ݵĹ���ʱ���������,��ֹͬһʱ��������ݹ�����������
-
���ݽṹ
�����
�������һ����ƽ��Ķ�����������
�����������������ص����κ�һ������ֵ�������������������н���ֵ,�κ�һ������ֵ��С���������������н���ֵ��
��ƽ�⡱���ǵ���������̶�ʱ,���������ĸ߶�Խ�ӽ�,��ö�����Խƽ��(�߶�Խ��)�����������ƽ�������ȫ������/��������,�߶���С�Ķ�������
����������������»��˻�Ϊ������
B����һ��ƽ������·��������
����
��ο������Թ���
�������¼-- �����������Ե�����,���Եĺ���,���Բ���_bingolina�IJ���-CSDN����_�Բ��Ե����� ����
���Ե���ҪĿ���DZ�֤����,ͬʱ���ڵ���������Ҳ�����������ٶȡ���������������ξ�Ӧ�ý���,������ϵ�ȱ��,���Ʒ���������������Լ����ⲻһ�µ����ⶼ�ҳ���,�����һ��,Ԥ���������ⲻһ�µ��µIJ���Ҫ��ȱ�ݵķ�����������Ա����Ҫ��������ҵ��
��ôд��������
�� �����Ǹ��ݲ�Ʒ���������������Ե�,Ȼ����ݲ��Ե���չд�ɲ�������,��ȼ��ࡢ�߽�ֵ���ַ�������Ʋ��������Ĺ������Ҿͻ�DZ��Ĭ�����õ��ˡ� ? �� ����д����������ʱ��,�ῼ�ǵ������ͷ���,��ʵ����д���Ե�Ľ��Ҿͻ�������ͷ�����dz�����,�Լ����ǵ����ȼ���(��������˵���������ȼ���������,�ڻع���Ե����������ǿ��Բ��������Ļع���Եġ������˵)�Ҿ���������ʵ�Ժ����Ĺ�����һ���ܴ�ļ����� ? �� �Ҿ��ò���������ƹ���Ӧ���и�����,����������������о�д��������С�(����һ��ע��ҳ��,10������,�������,��д����)����������������������ƹ�����, ����Ҫ���dz����е��û�����(Ҳ����˵,���û��ij���������ȫ��,������)
��������
->����ȷ��(��һ��ȷ���������ĵ�) ->��������ĵ�(������Ա�ڿ�ʼд����ǰ�����������ĵ�) ->��ò��Բ���,д���������� ->����������Ա�Ͳ��Ծ�������(����ʽ����������) ->�ӵ����汾 ->ִ�в�������(�м���ܻᲹ������) ->�ύbug(��Щbug��Ҫ������Ա��ȷ��(���ؼ����,��ͻȻ���ֵ��ڲ���������Χ֮���,�������ֵ�),��Щ����ֱ��¼�ƽ�TD) ->������Ա��(�����ڲ��Թ����п��ٵ���) ->�ع����(�����ֻᷢ��������,�ٰ����̿�ʼ��)��