黑马面试题并发篇
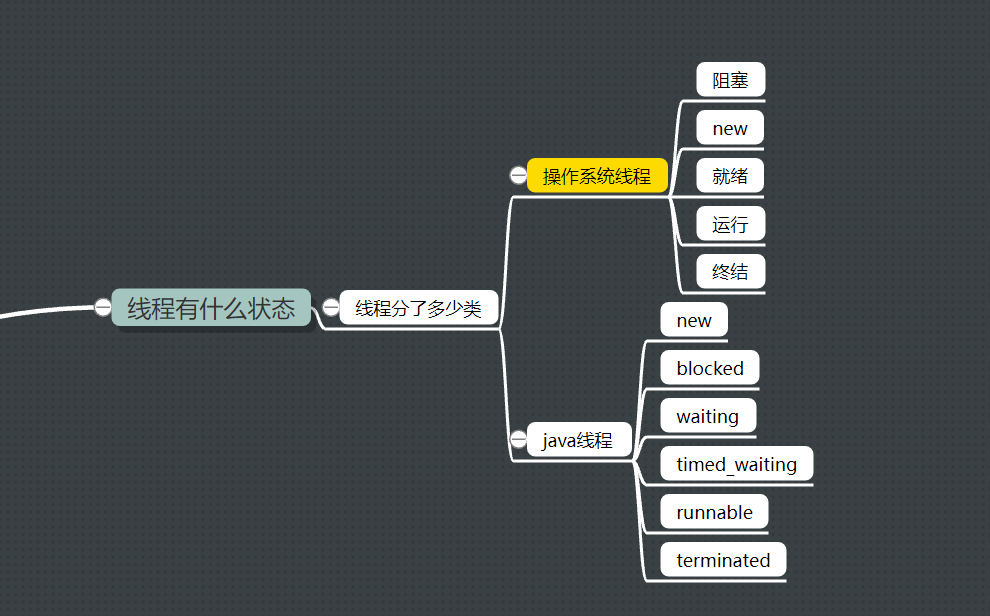
1.线程分成多少种状态?
java线程
- NEW :还没有和操作系统的线程关联,只是创建了对象
- RUNNABLE:开启了start,操作系统线程和当前java线程关联起来。
- BLOCKED:线程获取锁失败的时候
- WAITING:获取锁之后调用wait()释放锁进入阻塞
- TIMED_WAITING:获取锁之后调用wait()释放锁进入阻塞,或者是sleep过一段时间醒来。
- TERMINATED:终结
对应这个案例来说,t2获取锁之后通过wait释放,这个时候main线程获取锁执行,但是notify之后,t2从waiting变成blocked,原因就是因为main线程还在同步代码块内没有释放锁,即使唤醒了t2但是由于获取不到锁还是会进入阻塞状态,等待锁被释放。为什么阻塞之后还会被唤醒,原因就是他们使用同一把锁,连接了monitor,相当于阻塞线程进入了waitingList上面等待,如果monitor的线程用完就会唤醒所有线程重新竞争锁。
private static void testWaiting() {
Thread t2 = new Thread(() -> {
synchronized (LOCK) {
logger1.debug("before waiting"); // 1
try {
LOCK.wait(); // 3
} catch (InterruptedException e) {
e.printStackTrace();
}
}
},"t2");
t2.start();
main.debug("state: {}", t2.getState()); // 2
synchronized (LOCK) {
main.debug("state: {}", t2.getState()); // 4
LOCK.notify(); // 5
main.debug("state: {}", t2.getState()); // 6
}
main.debug("state: {}", t2.getState()); // 7
}
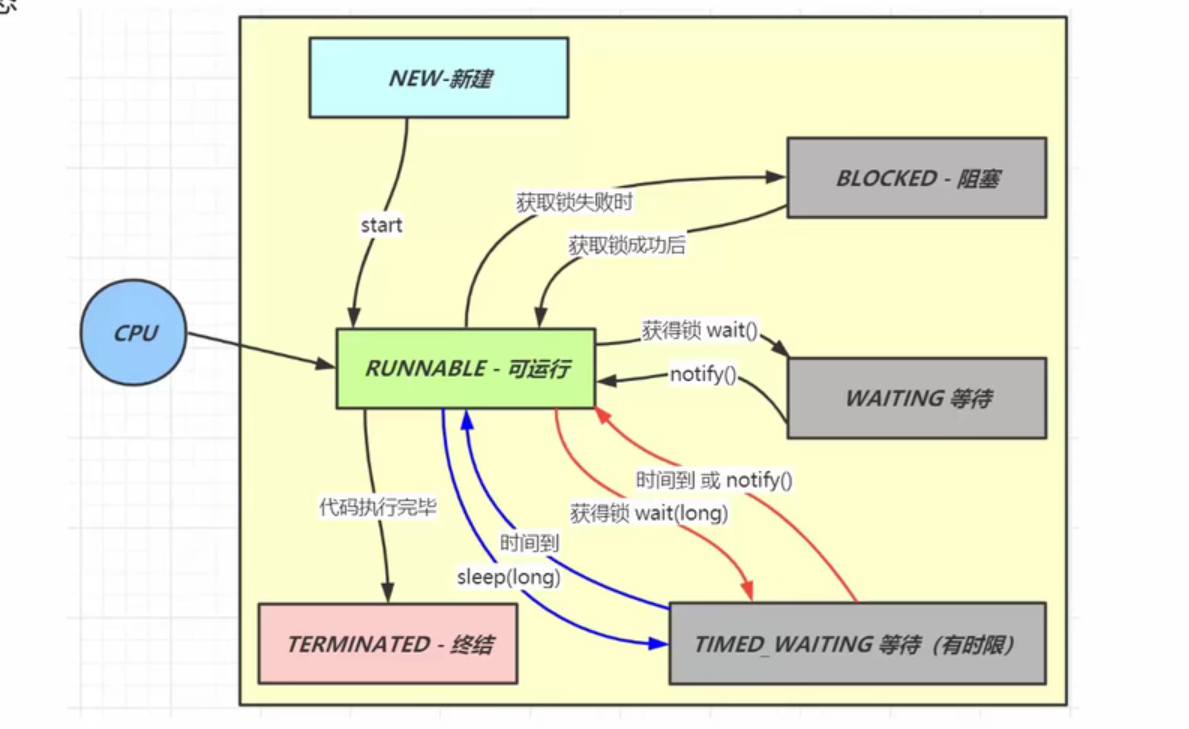
操作系统的线程
- NEW:新创建线程
- 就绪:可以分配到cpu时间
- 运行:分配到cpu时间
- 阻塞:不能被分配到cpu时间
- 终结:线程结束

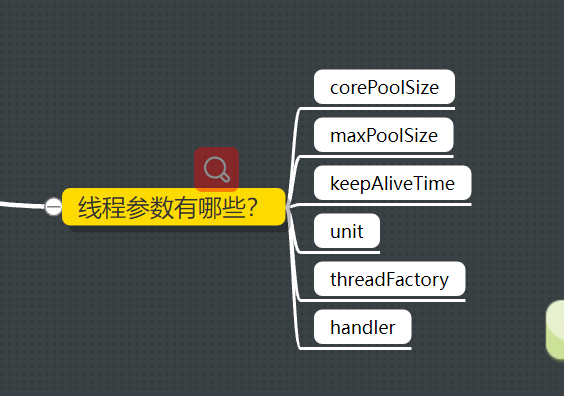
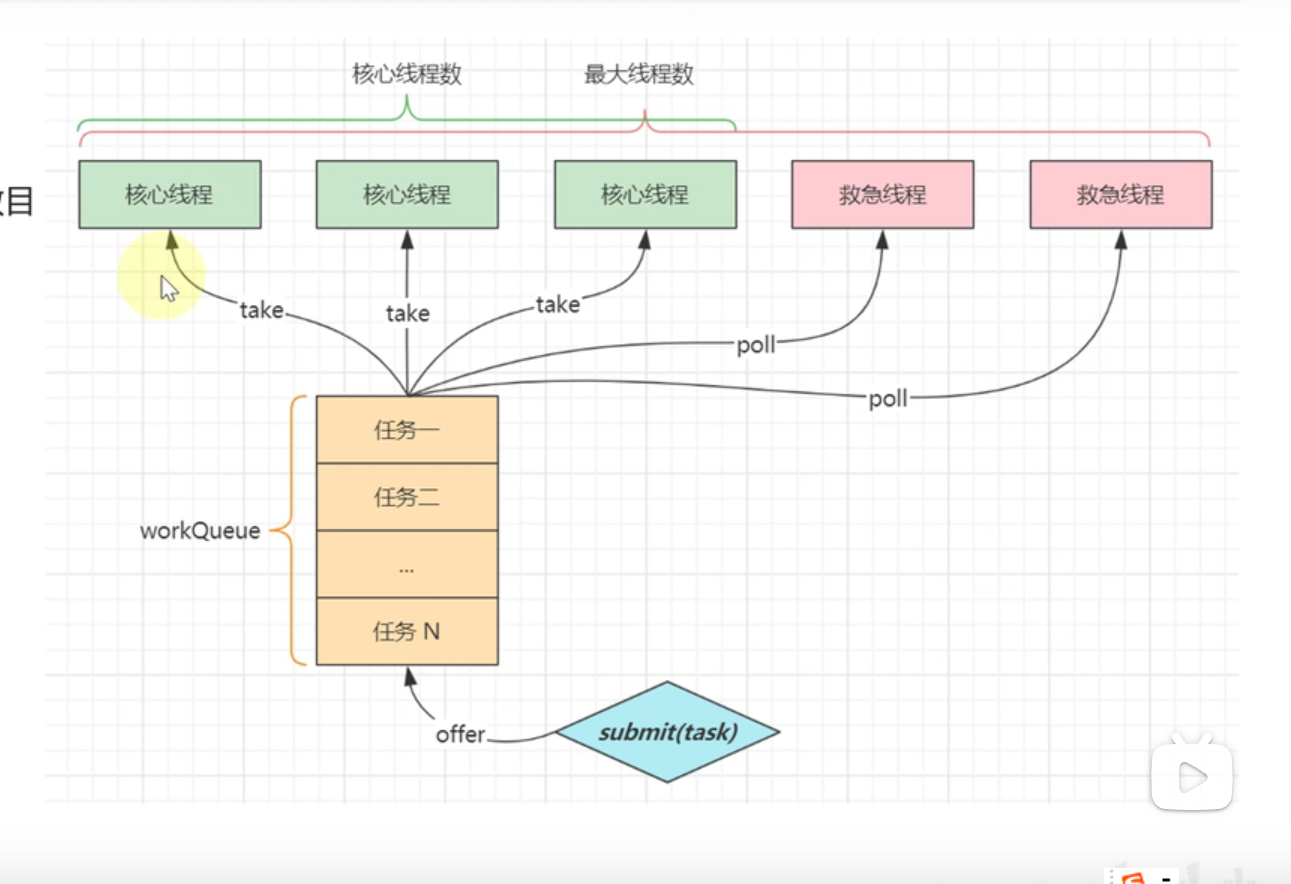
2.线程池的参数有哪些?
- corePoolSize:核心线程数量
- maximumPoolSize:最大线程数量
- keepAliveTime:救急线程生存的时间
- unit:时间单位
- workQueue:阻塞队列
- threadFactory:线程工厂
- handler:拒绝策略
策略有多少种?
- AbortPolicy()抛出异常
- CallerRunsPolicy()调用者执行
- DiscardPolicy()放弃这个任务
- DiscardOldestPolicy()放弃最早进入队列的那个
3.sleep和wait的区别?
归属
- sleep是Thread的静态方法
- wait是Object的成员方法
醒来的时机不同
- wait可以依靠notify来唤醒
- wait和sleep都可以被打断
锁特性
- wait有锁才能调用
- wait可以释放锁
- sleep不能释放锁
4.synchronized和Lock
语法层面
- synchronized在jvm源码实现,c++,自动完成锁和释放
- Lock是jdk的源码。手动lock和unlock
功能
- 都是悲观锁、同步、锁重入
- lock可中断、可超时、公平和非公平、条件变量
- lock应用在多个场景
性能
- 没有竞争的时候synchronized的锁优化,偏向、轻量级、锁膨胀
- 竞争激烈的时候lock更灵活
什么是公平和非公平?
- 其实就是多个线程竞争锁的时候,一个竞争到锁,其它线程进入阻塞队列。第一个线程快执行完的时候,这个时候又有一个新的线程准备进来,但是这个线程先tryLock尝试获取锁,而不是进入队列等待,相当于就是插队竞争。这个就是不公平。
- 如果是公平的话那么就是按照先进先出。
条件变量的原理?
通过ReentrantLock的newCondition来创建条件变量,相当于就是一个个小的waitSet,使用await来进行等待,然后signal唤醒,但是唤醒之后是重新去到entryList进行等待重新竞争锁。
5.volatile保证线程安全吗?
线程安全包括什么?
- 原子性:保证多行语句是一个整体执行,其它线程不能够插队
- 可视性:线程对共享变量修改,其它线程可见
- 有序性:保证语句的执行顺序
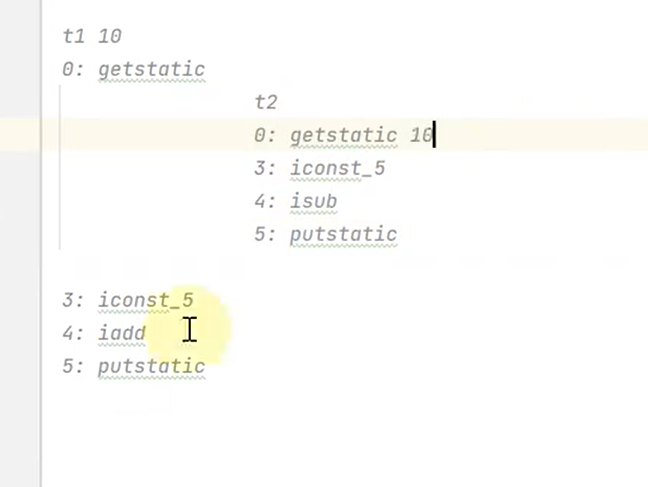
案例(原子性)
- 导致原子性问题的原因就是因为指令交错,同时两个线程,一个线程执行balance+=5,另一个线程执行balance-=5那么问题就是线程1获取共享变量之后,切换到线程2获取共享变量执行减5那么最后的答案可能是15。因为,线程1执行加5之后覆盖了线程2执行的减5,而且获取的共享变量是同一个。正常来说应该是线程1执行完10+5,再到线程2 的15-5得到10.但是由于交错导致线程2获取的共享数据是未经过线程1修改的。所以这里需要保证代码的原子性才能解决问题

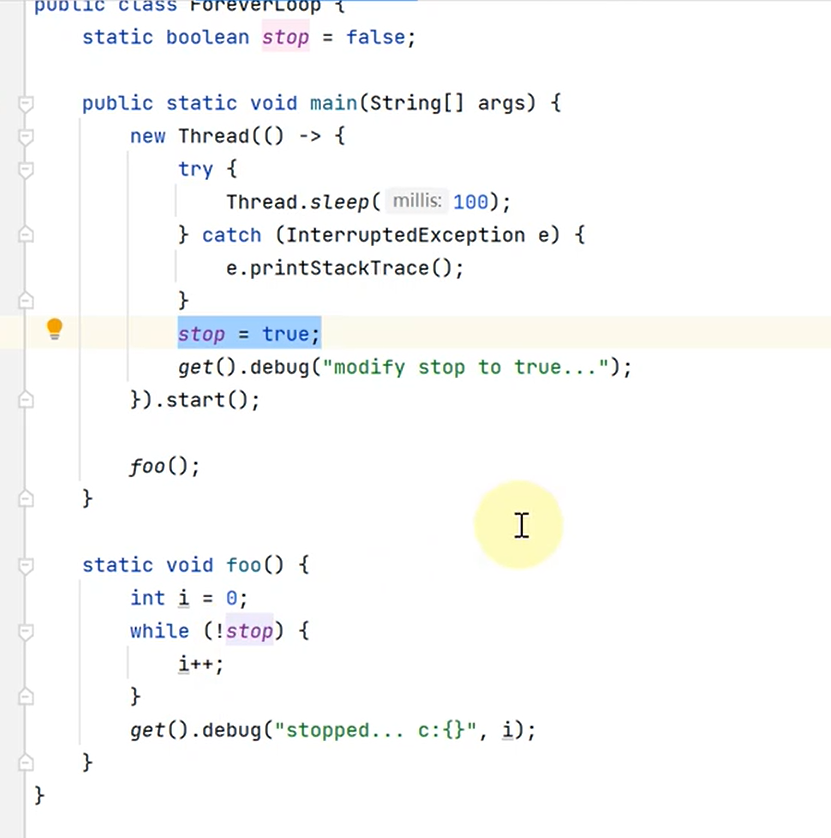
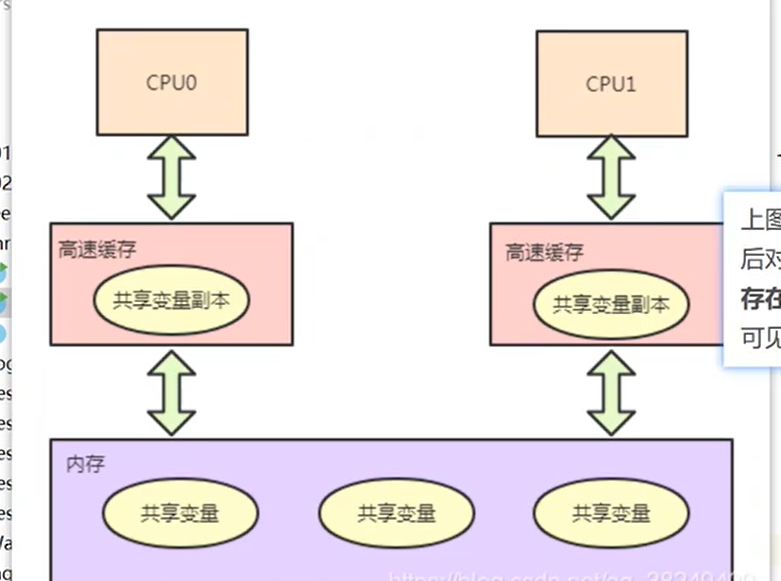
案例(可见性)
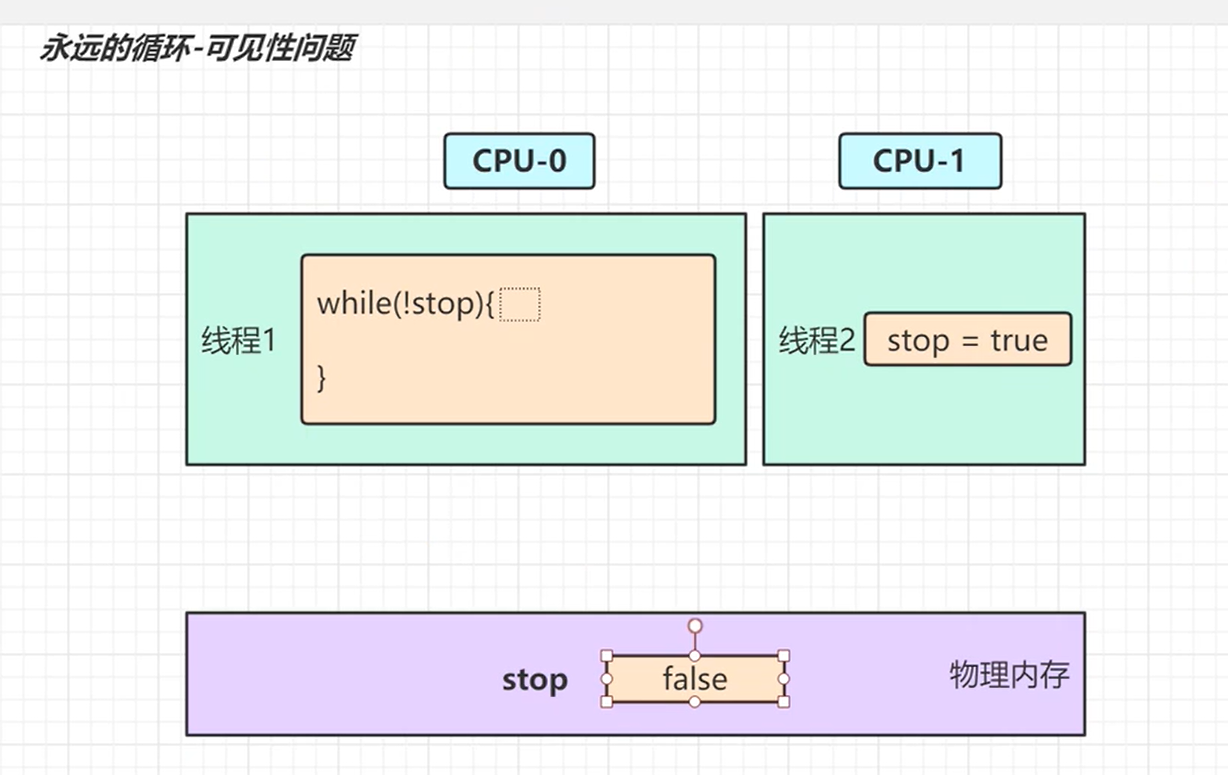
- 很明显程序main线程执行foo的时候已经把副本的stop拷贝,那么就算后面线程1把stop修改了,也不会影响main线程的缓存中的stop
可见性问题的根源
一开始的说法main线程while执行多次把对应的共享变量存入到cpu缓存中,导致别的线程对内存中共享变量修改之后,main线程无法读取到。但这种说法是错误的
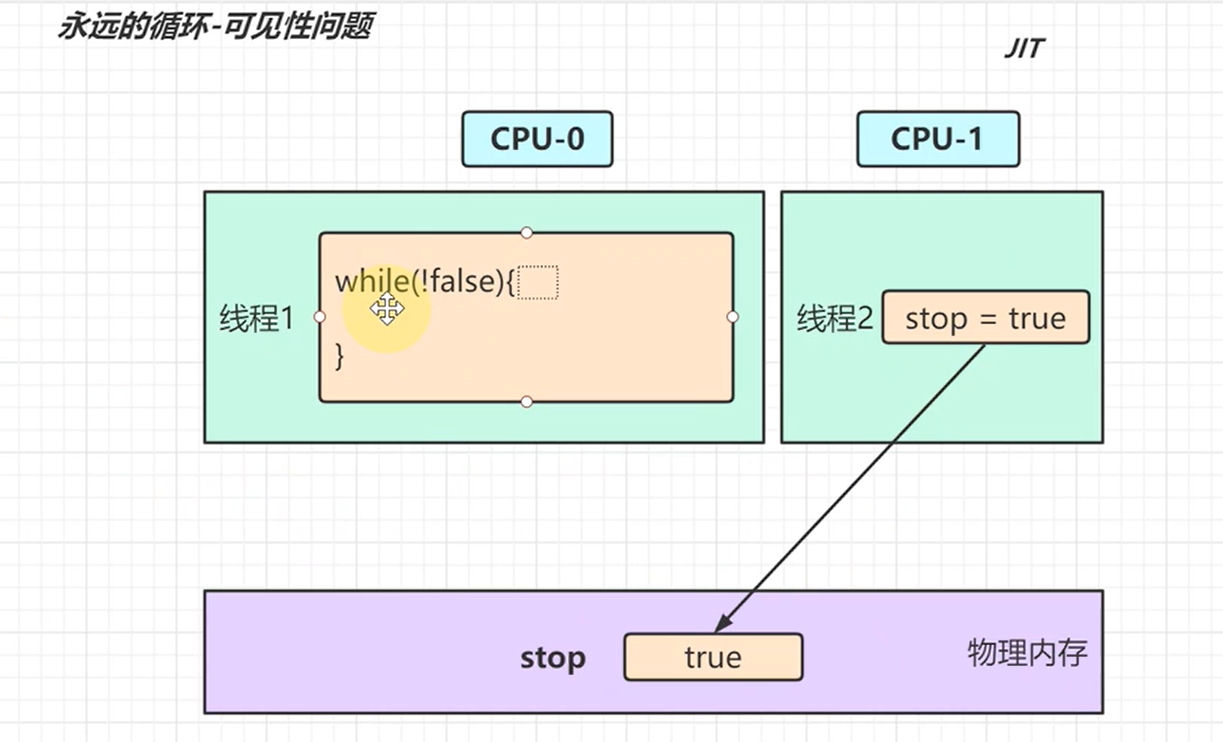
正确的说法是JIT发现while循环的语句执行太多次,每次都是解释器要把对应的while解释成机器码给其它平台执行浪费了时间,所以JIT就把while循环的代码解释之后的机器码存入缓存,并且把其中使用次数很多的共享变量而且每次都是false直接改成对应的常量值。减少了解释的过程。
解决方式就是volatile就算达到JIT的优化阈值也没有进行对代码优化和缓存。
public class ForeverLoop {
static boolean stop = false;
public static void main(String[] args) {
new Thread(() -> {
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
stop = true;
get().debug("modify stop to true...");
}).start();
new Thread(() -> {
try {
Thread.sleep(200);
} catch (InterruptedException e) {
e.printStackTrace();
}
get().debug("{}", stop);
}).start();
new Thread(() -> {
try {
Thread.sleep(200);
} catch (InterruptedException e) {
e.printStackTrace();
}
get().debug("{}", stop);
}).start();
foo();
}
static void foo() {
int i = 0;
while (!stop) {
i++;
}
get().debug("stopped... c:{}", i);
}
}
有序性
其实就是指令重排。
下面的案例会出现1,0的情况,原因是指令重排的时候把x=1和y=1调换了位置,导致线程在执行的过程中指令交错,导致线程1先把y先赋值1,后切换线程2,这个时候r的r1就被赋值为1,r2赋值0的时候然后才切换回第二个线程把x=1赋值。
加上volatile相当于就是加上了内存屏障,如果是写操作比如y=1那么就是在y=1之前的指令不可以越过y,如果是读比如result=y那么这条指令之下的指令不能往上面翻越,但是y=1的下面的指令可以越过它,result=y的之上的指令可以越过他。(屏障是写之前,读之后)
@JCStressTest
@Outcome(id = {"0, 0", "1, 1", "0, 1"}, expect = Expect.ACCEPTABLE, desc = "ACCEPTABLE")
@Outcome(id = "1, 0", expect = Expect.ACCEPTABLE_INTERESTING, desc = "INTERESTING")
@State
public static class Case1 {
int x;
int y;
@Actor
public void actor1() {
x = 1;
y = 1;
}
@Actor
public void actor2(II_Result r) {
r.r1 = y;
r.r2 = x;
}
}

拓展
Setting ->Runner设置运行插件的jdk版本
properties->java.version插件的jdk声明版本
6.悲观锁和乐观锁的区别?
悲观锁
- 占锁之后才能够进行操作,没有锁无法进行操作
- 阻塞唤醒需要上下文切换
- synchronized和lock都有自旋的优化
乐观锁(CAS)
- 循环尝试CAS
- 需要多核cpu因为线程一直在while循环找机会修改,没有赛道无法继续运行
- 不需要上下文切换
Unsafe完成修改是一个原子操作,是一个操作系统层面的指令。
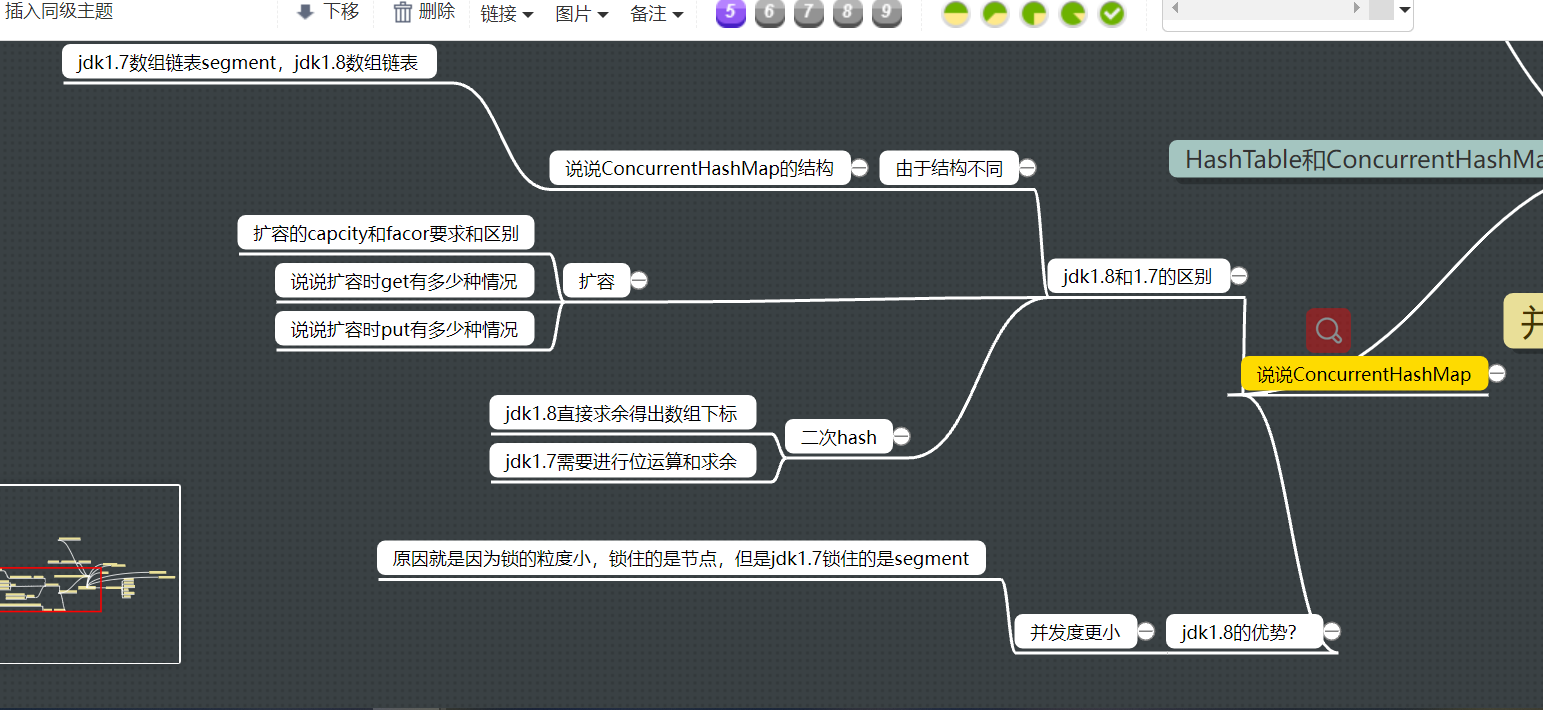
7.HashTable和ConcurrentHashMap的区别?
HashTable
- 只有一把锁并发度很低
ConcurrentHashMap
- jdk1.8之前是数组+链表+Segment,Segment相当于就是锁
- jdk1.8之后就是数组+链表,每次访问都是通过节点来进行绑定,大大增强了并发度
说说HashTable的put?
- 一个同步方法
- 而且hash是直接与数组长度求余,最后与最大的正数相与防止出现负数的情况
- 容量扩容是2*x+1
- 只需要进行一次hash不需要两次,但是ConcurrentHashMap需要进行两次hash操作,原因就是Hashable不需要对应segment,也就不需要压缩hash的范围。直接取余就是在数组的范围里面。
public synchronized V put(K key, V value) {
// Make sure the value is not null
if (value == null) {
throw new NullPointerException();
}
// Makes sure the key is not already in the hashtable.
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;//求正
@SuppressWarnings("unchecked")
Entry<K,V> entry = (Entry<K,V>)tab[index];
for(; entry != null ; entry = entry.next) {
if ((entry.hash == hash) && entry.key.equals(key)) {
V old = entry.value;
entry.value = value;
return old;
}
}
addEntry(hash, key, value, index);
return null;
}
谈谈ConcurrentHashMap的capcity和clevel的关系?
- capcity可以说就是元素的个数。
- clevel在jdk7中指的就是segment的个数,可以支持的并发度。默认是16
- 那么每个segment中的元素个数就等于capcity/clevel
谈谈jdk7ConcurrentHashMap的put?
- 首先是需要二次hash,然后高几位主要是取决于锁的clevel的2^n这n的几次方然后取出高位对应数组下标
- 如果是小hash那么也是二次hash与tab的大小相与,低几位相当于就是tab.length=2^n这里的n。
为什么并发度更高?
- put每次操作的是以一个segment为单位,相当于锁住了一个小hash相对HashTable并发度更高。
HashEntry是什么?
- HashEntry就是小哈希表的存储结构的节点。保存key和value,不能存入空
- 找到对应位置之后就会开始遍历链表
如何进行扩容?
- 而且扩容是各自扩自己的小hash表。也就是每个锁segment的扩容都是独立的。每个对象进来二次hash之后右移this.segmentShift = 32 - sshift(这里的sshift相当于就是clevel);然后就是与mask相与,由于hashcode每个对象都是固定的,所以最后计算出来的segment也是不变的,那么扩容就可以独立进行。数组大小发生改变,那么低几位肯定也会发生变化,节点位置发生迁移。
Segment[0]的作用?
- 作为原型模式,其它数组创建的时候都是参照Segment[0]的小哈希表。
private Segment<K,V> ensureSegment(int k) {
final Segment<K,V>[] ss = this.segments;
long u = (k << SSHIFT) + SBASE; // raw offset
Segment<K,V> seg;
if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null) {//如果是空segment就参照segment[0]进行创建
Segment<K,V> proto = ss[0]; // use segment 0 as prototype
int cap = proto.table.length;//proto就是segment[0]
float lf = proto.loadFactor;//负载因子参照
int threshold = (int)(cap * lf);//阈值参照
HashEntry<K,V>[] tab = (HashEntry<K,V>[])new HashEntry[cap];
if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u))
== null) { // recheck
Segment<K,V> s = new Segment<K,V>(lf, threshold, tab);//负载因子、阈值、table
while ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u))
== null) {
if (UNSAFE.compareAndSwapObject(ss, u, null, seg = s))
break;
}
}
}
return seg;
}
jdk8版本和jdk7版本的ConcurrentHashapMap的区别?
从初始化上看?
- jdk8懒汉式,jdk7饿汉式,先创建了数组
结构?
- jdk8数组+链表,jdk7数组+链表+segment
capcity含义?
-
jdk8中就是能够存放capcity个对象。也就是初始化需要是capcity*(1/factor)。这样才能存放这么多的对象,防止超过阈值不能存入capcity个
-
jdk7就是创建capcity个对象。
说说put的区别?
- jdk8的put是以节点为并发单位
- jdk7是以segment为并发单位
扩容?
- jkd8的扩容到factor就扩容,但是jdk7要超过factor才会扩容
jdk8的扩容时get有两种情况
- get到forwarding的节点,这个时候需要检查节点状态,发现是forwaring就去到nextTable上面去找(find方法)
- 如果是正在修改的节点,那么能够直接获取,原因是在扩容的时候迁移节点不是原节点而是创建新节点来送到新的数组。也就是旧的数组仍然可以取到这个节点。
扩容时put的情况?
- put到forwarding,那么就可以帮助扩容
- put到正在修改的节点
//ForwardingNode
Node<K,V> find(int h, Object k) {
// loop to avoid arbitrarily deep recursion on forwarding nodes
outer: for (Node<K,V>[] tab = nextTable;;) {//去到下一个表中寻找
Node<K,V> e; int n;
if (k == null || tab == null || (n = tab.length) == 0 ||
(e = tabAt(tab, (n - 1) & h)) == null)
return null;
for (;;) {
int eh; K ek;
if ((eh = e.hash) == h &&
((ek = e.key) == k || (ek != null && k.equals(ek))))
return e;
if (eh < 0) {
if (e instanceof ForwardingNode) {
tab = ((ForwardingNode<K,V>)e).nextTable;
continue outer;
}
else
return e.find(h, k);
}
if ((e = e.next) == null)
return null;
}
}
}

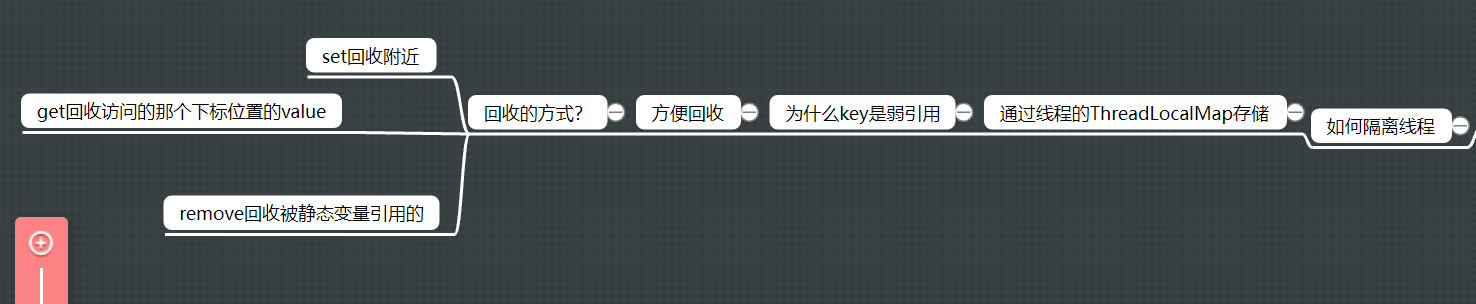
8.谈谈ThreadLocal
作用是什么?
- 实现线程内共享
- 线程外隔离
原理实现?
- 使用的是ThreadLocalMap存储,set就是用ThreadLocal作为key,资源作为value,get就是ThreadLocal作为key去取
关于扩容
- 扩容因子是2/3,而且哈希冲突的方法是开放寻址,就是直接找下一个位置。

为什么key要使用弱引用?
原因就是线程长时间使用积累了很多键值对,就算别的变量不引用map的内容,但是map自己的指向会导致键值对无法被回收。那么这个时候就需要把它设置为弱引用,内存不足的时候可以被回收。
什么时候释放资源?
- get的时候清理并且重新设置key
- set的时候清理附近的,因为清理全部效率太低,每次set都要遍历整个数组
- 如果静态变量引用这个threadLocal那么就需要自己去remove掉。