Java��ѧ�ʼ�19
- һ��Set�ӿ�
- ����HashSet��
- ����LinkedHashSet��
- �ġ�Map�ӿ�
- �塢HashTable��
- ����Hashtable�� HashMap�Ա�
- �ߡ�Properties��
- �ˡ����ѡ��ʵ����
- �š�TreeSet��
- ʮ��Collections������
- 1. ����
- 2. ����
- (1)reverse(List):��ת List ��Ԫ�ص�˳��
- (2)shuffle(List):�� List ����Ԫ�ؽ����������
- (3)sort(List):����Ԫ�ص���Ȼ˳���ָ�� List ����Ԫ�ذ�������
- (4)sort(List,Comparator):����ָ���� Comparator ������˳��� List ����Ԫ�ؽ�������
- (5)swap(List,int, int):��ָ�� list �����е� i ��Ԫ�غ� j ��Ԫ�ؽ���
- (6)Collections.max(list):����Ԫ�ص���Ȼ˳��,���ظ��������е����Ԫ��
- (7)max(Collection,Comparator):���� Comparator ָ����˳��,���ظ��������е����Ԫ��
- (8)Collections.frequency(list, "tom"):����ָ��������ָ��Ԫ�صij��ִ���
- (9)Collections.copy(dest, list):��������
- (10)Collections.replaceAll(list, "tom", "��ķ"):ʹ����ֵ�滻 List ��������о�ֵ
- ʮһ��������ϰ��
���ѵ㡿
1.���⼯�ϵĵײ����
2.�Ķ�ԭ��
3.��ʱʹ�ú��ּ���
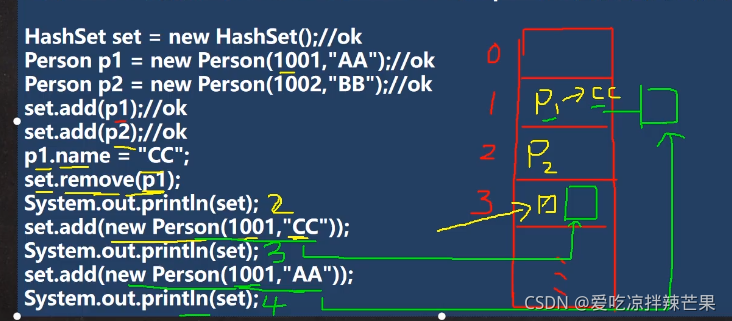
��Map������ݵ�key-valueʾ��ͼ2��
һ��Set�ӿ�
1. ����
(1)����(���Ӻ�ȡ�����ݵ�˳��һ��),û������,�����ü�for������,���õ�������
(2)�������ظ�Ԫ��,����������һ��null
(3)JDK API��Set�ӿڵ�ʵ������:
AbstractSet , ConcurrentHashMap.KeySetView , ConcurrentSkipListSet , CopyOnWriteArraySet , EnumSet , HashSet , JobStateReasons , LinkedHashSet , TreeSet
2. Set �ӿڵij��÷���
(��HashSet����)
(1)add(E e)
��ָ����Ԫ�����ӵ��˼���(�����δ����)
(2)contains(Object o)
����˼��ϰ���ָ����Ԫ��,�� true ��
(3)isEmpty()
����˼��ϲ�����Ԫ��,�� true ��
(4)iterator()
���ش˼�����Ԫ�صĵ�������
(5)remove(Object o)
�������,��Ӹü�����ɾ��ָ����Ԫ�ء�
����HashSet��
1. ����
(1)HashSet��ʵ����Set�ӿ�
(2)HashSetʵ������HashMap<E,Object> map = new HashMap<>();
(3)���Դ��nullֵ,����ֻ����һ��null
(4)HashSet����֤Ԫ���������,ȡ����hash��,��ȷ�������Ľ����(��,����֤���Ԫ�ص�˳���ȡ��˳��һ��)
(5)�������ظ�Ԫ��/����
2. HashSet�ײ����
(1)�Ͳ����:���� + ���� + �����
֮���Բ�������ȫ������������,�ǿ��ǵ�������������,��ȡЧ�ʻ����,���Խ��Ų��������ͺ������
(2)HashSet�ײ���:HashMap;
(3)����һ��Ԫ��ʱ,������ϣ�㷨,�ȵõ�hashֵ,����hashֵת���ɳ�����ֵ;
(4)�ҵ��洢���ݱ�table(table����),���������
λ���Ƿ��Ѿ������Ԫ��;
(5)���û��,ֱ�Ӽ����Ԫ��;
(6)�����,����equals�Ƚ�,�����ͬ,�ͷ�������,�������ͬ,�����ӵ����
(7)��JDK8��,���һ��������Ԫ�ظ������� TREEIFY THRESHOLD(Ĭ����8),����table����Ĵ�С>=MIN TREEIFY CAPACITY(Ĭ��64),�ͻ��������(��ɺ����)��
3. �ײ�Դ�����
-
��������ִ��

-
ִ��HashSet���еĹ�����HashSet()��
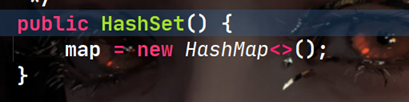
mapΪHashSet������һ������

-
ִ�����,��ʱsetΪ��null

-
��һ��ִ��add()����Ԫ��

-
���� add()����,��ʱ����IJ��� e Ϊ������������â����,PRESENTΪHashSet���е�һ����̬����(������)new Object()��


-
����put����,��ʱKeyΪ������������â����,valueΪ��new Object()��

-
ִ��hash()����,hash()�д����key Ϊ������������â������

-
hash()�����жϴ���Ķ����Ƿ�Ϊ��,��Ϊ��,���ɹ�ϣֵ����16λ������,���ؼ�����ֵ;�������Ϊ����0��

-
ִ��put�����������ʵ����,hashΪ�����Ĺ�ϣֵ,key Ϊ������������â������
(1)�ڷ������и�������:�ڵ�����tab Node [ ] tab ; �ڵ�P Node p ; int n ,i ;
(2)����table (��) ΪHashMap��һ������

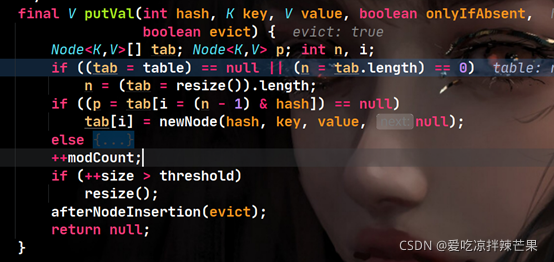
(3)tab = table Ϊ��,�����һ��if�ж����,����resize()����,�������ֵ��ͼ,���һ��16λ��С��table���顣ȫΪNull��
����,thresholdΪ���ݵ��ٽ�ֵ,��ʱΪ0.75 * 16 = 12��
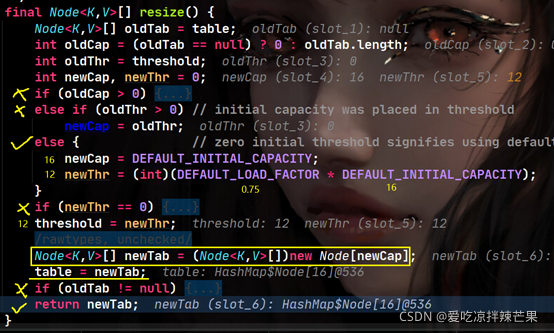
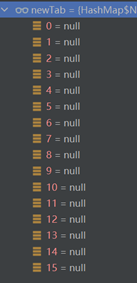
(4)tab����resize���ص�16λ������,n = 16
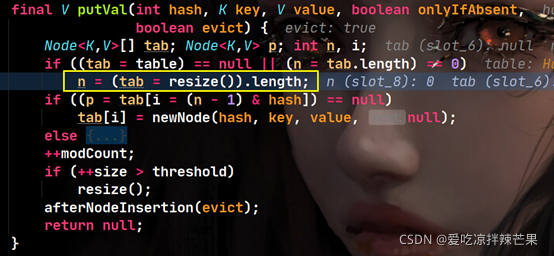
(5)����ϣֵת��Ϊtable�����һ������ֵ,���Ҳ鿴��������λ���Ƿ��нڵ㡣���û�нڵ�,��key������������â�������롣�ĵ�modCount++ ,�������null��
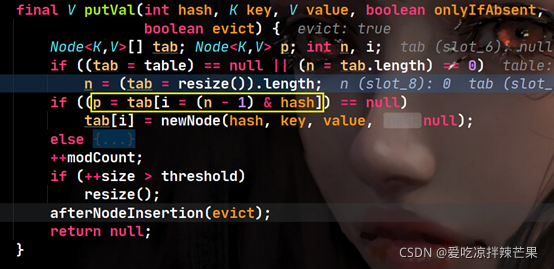
�ص����:
��1��������������λ�ô�,�ڵ�Ϊ��,��ֱ�������½ڵ㡣��ʱPָ��table���ĸ�����Ԫ�����ڴ���
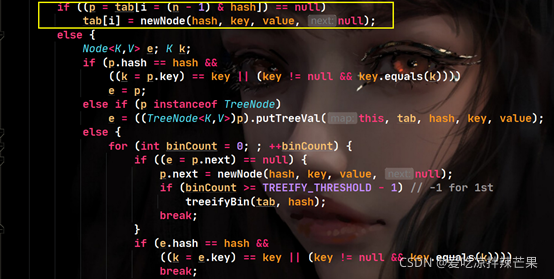
��2������Ϊ�յĻ�,��ʼ�Ƚ�
(1)�ȽϹ�ϣֵ�Ƿ����
(2)�Ƚϼ���Ԫ�ص�ֵ�Ƿ����,��ʱ���ؿ�equals��������,����ֱ�ӱȽ��ַ�������,Ҳ����ֱ�ӱȽ϶���,�Ϳ��Ƿ���д��equals�����������,��ڵ����ʧ�ܡ�

��3�����ڡ�2���ȽϺ�,��table���и�������Ԫ�ز����,��������������������,�ҵ����λ�ò����ȥ�½ڵ�,��������ѭ��;
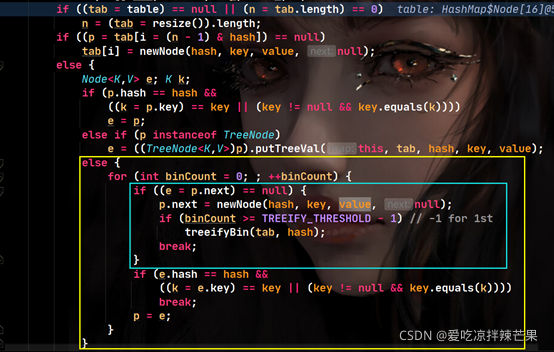
��4�����ڡ�3����,�������������ҵĹ�����,�����нڵ���֮���,����������ѭ��,�ڵ����ʧ�ܡ�
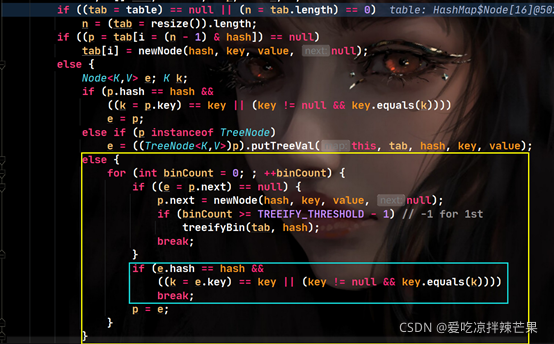
- ��ʱ������null,��add��������true,���ʾ����Ԫ�سɹ�������,����ʧ�ܡ�

����:
û��дequals��ʱ��,������������â����Ϊ��������,���õ�equals�̳и���equals,�Ƚϵ������������Ƿ�һ�������Բ�һ��,��������add�ˡ�
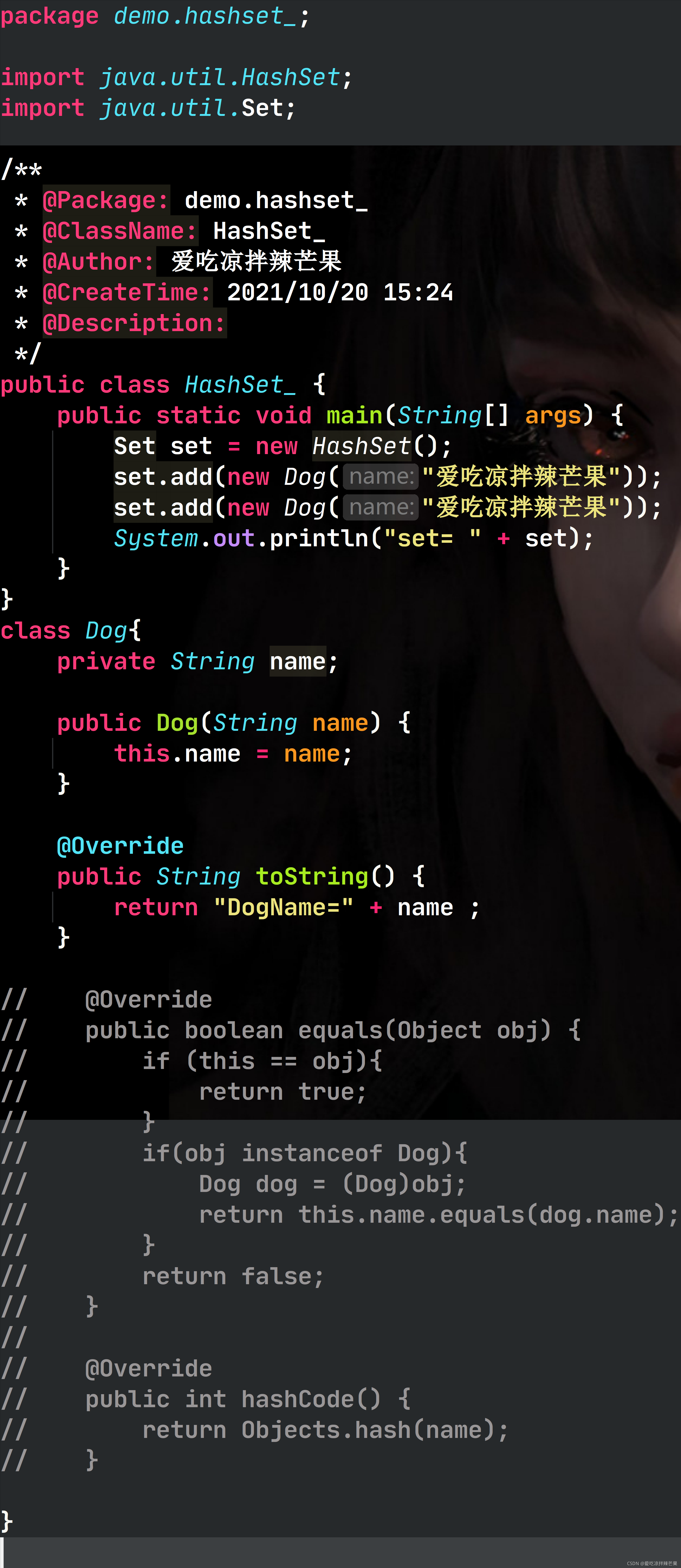
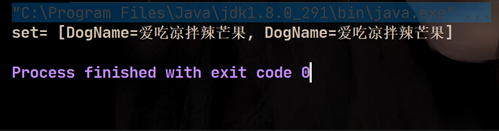
��дequals��ʱ��,������������â����Ϊ��������,���õ�equals,�Ƚϵ������������name�Ƿ�һ��������һ��,�ʵڶ���add����ʧ�ܡ�
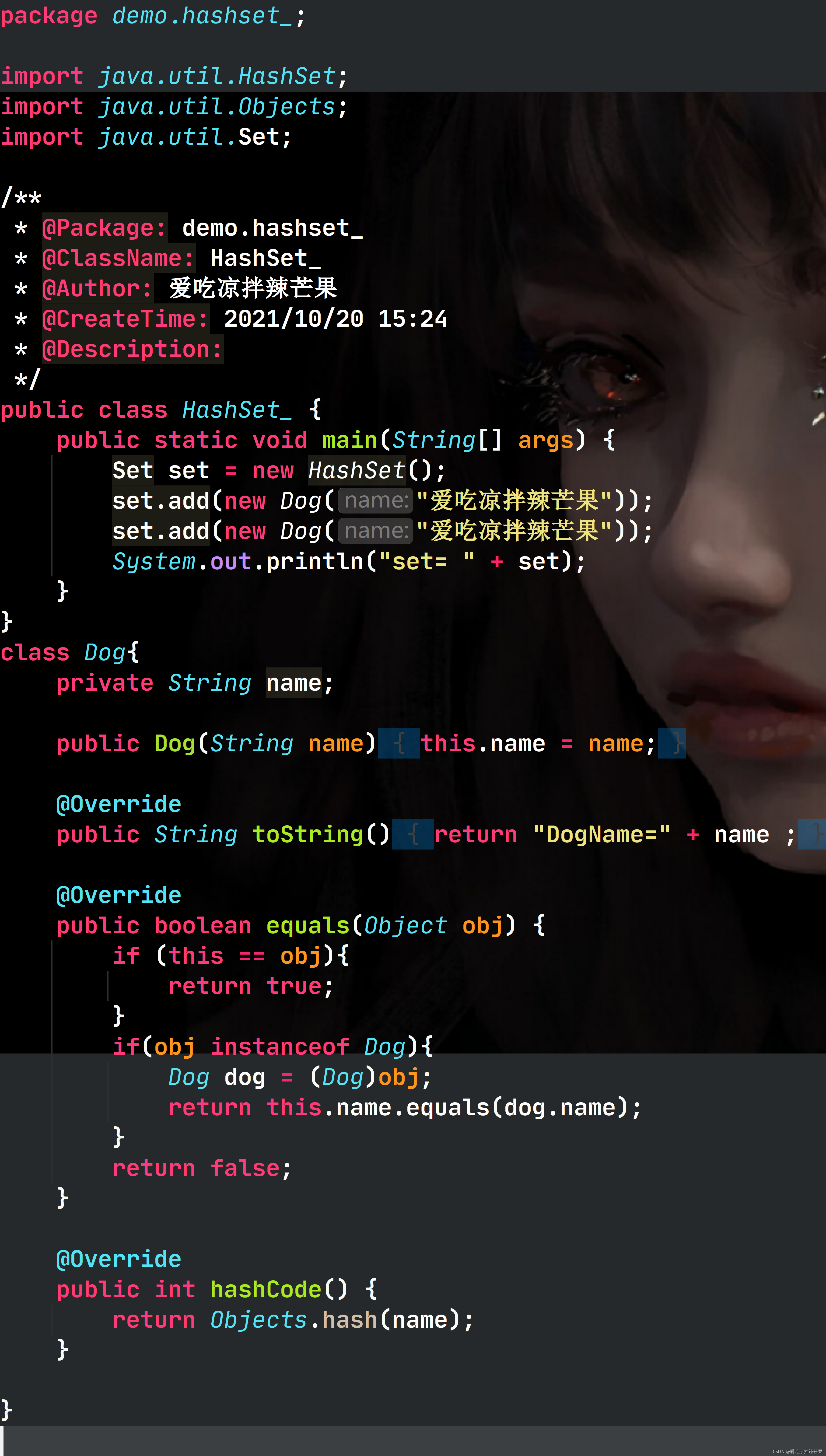
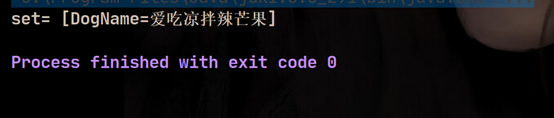
4. HashSet���ݻ��ƺ�ת�ɺ��������
(1)HashSet�ײ���HashMap,��һ������ʱ,table�������ݵ�16,�ٽ�ֵ(threshold)��16*��������(loadFactor)��0.75 = 12
(2)���table����ʹ�õ����ٽ�ֵ12,�ͻ�2�����ݵ�16��2=32,�µ��ٽ�ֵ����32��0.75 =24����������
(3)��Java8��,�����1��һ��������Ԫ�ظ�������TREEIFY_THRESHOLD(Ĭ����8).�����ҡ�2��table�Ĵ�С>=MIN TREEIFY CAPACITY(Ĭ��64),�ͻ��������(�����),������Ȼ�����������ݻ�����
5.��ϰ��


����LinkedHashSet��
1. ����
(1)LinkedHashSet ��HashSet������
(2)LinkedHashSet�ײ���һ�� LinkedHashMap,�ײ�ά����һ������+˫������
(3)LinkedHashSet����Ԫ�ص�hashCodeֵ������Ԫ�صĴ洢λ��,ͬʱʹ������ά��Ԫ�صĴ���,��ʹ��Ԫ�ؿ��������Բ���˳��ġ���,����ʱ��ȡ������Ԫ��˳��������˳����һ���ġ�
(4)LinkedHashSet���������ظ�Ԫ��
��LinkedHashSet��
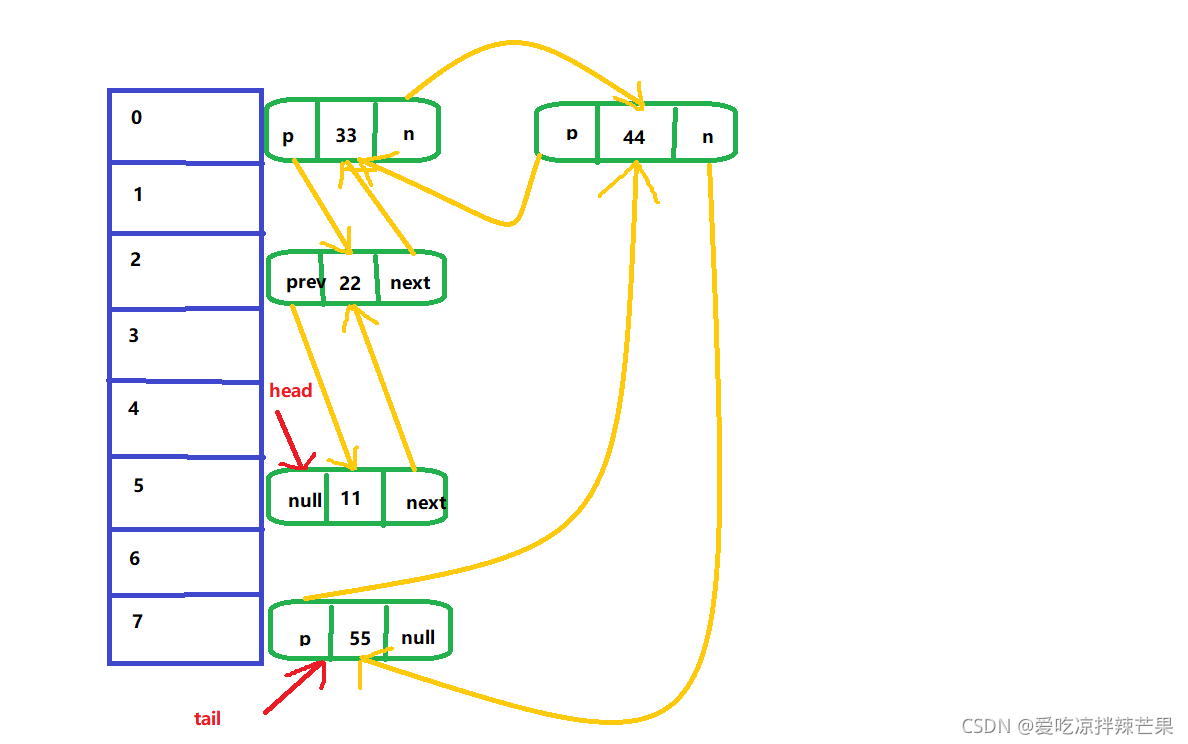
2. LinkedHashSet�ײ����
(1)�Ͳ����:���� + ˫����
(2)��LinkedHastSet��ά����һ��hash��(����)��˫������( LinkedHashSet��head��tail )
(3)ÿһ���ڵ���before��after����,���������γ�˫������
(4)������һ��Ԫ��ʱ,����hashֵ,��������,ȷ����Ԫ����table��λ��,Ȼ�����ӵ�Ԫ�ؼ��뵽˫������(����Ѿ�����,������,ԭ���hashsetһ��)
tail.next = newElement
newElement.pre = tail
tail = newEelment;
(5)�����Ļ�,���DZ���LinkedHashSetҲ��ȷ������˳��ͱ���˳��һ��
�ġ�Map�ӿ�
1. ����
(1)��Set�ӿڸ�ʵ�á�
(2)Map��Collection���д���,���߲���ϵ�����ڱ������ӳ���ϵ������:Key-Value��
(3)Map�е�key�� value�������κ��������͵�����,���װ��HashMap$Node�����С�����Set��,value��һ������ new Object()��
(4)Map�е�key�������ظ�,ԭ���HashSetһ�����������ظ�Ԫ��/��������ͬ��Key,�͵ȼ��ڱ���key����,�滻��value��
(5)Map �е�value�����ظ�
(6)Map ��key ����Ϊnull, valueҲ����Ϊnull,ע��keyΪnull,ֻ����һ��;valueΪnull ,���Զ����
(7)����String����ΪMap��key
(8) key�� value֮����ڵ���һ��һ��ϵ,��ͨ��ָ����key �����ҵ���Ӧ��value��
(9)Map������ݵ�key-value,һ��k-v�Ƿ���һ��Node�е�,����ΪNodeʵ����Entry �ӿڡ�
(10)HashMap�� Map �ӿ�ʹ��Ƶ����ߵ�ʵ���ࡣHashMap���� key-val�Եķ�ʽ���洢����(HashMap $Node����)��
(11)HashMap��HashSetһ��,����֤ӳ���˳��,��Ϊ�ײ�����hash���ķ�ʽ���洢�ġ�(jdk8��hashMap�ײ�����+����+�����)
(12)HashMapû��ʵ��ͬ��,������̲߳���ȫ��,����û����ͬ������IJ���,û��synchronized��
2. Map�ӿ�ʵ������ص�
(ʹ��ʵ���� HashMap��Ϊ��)
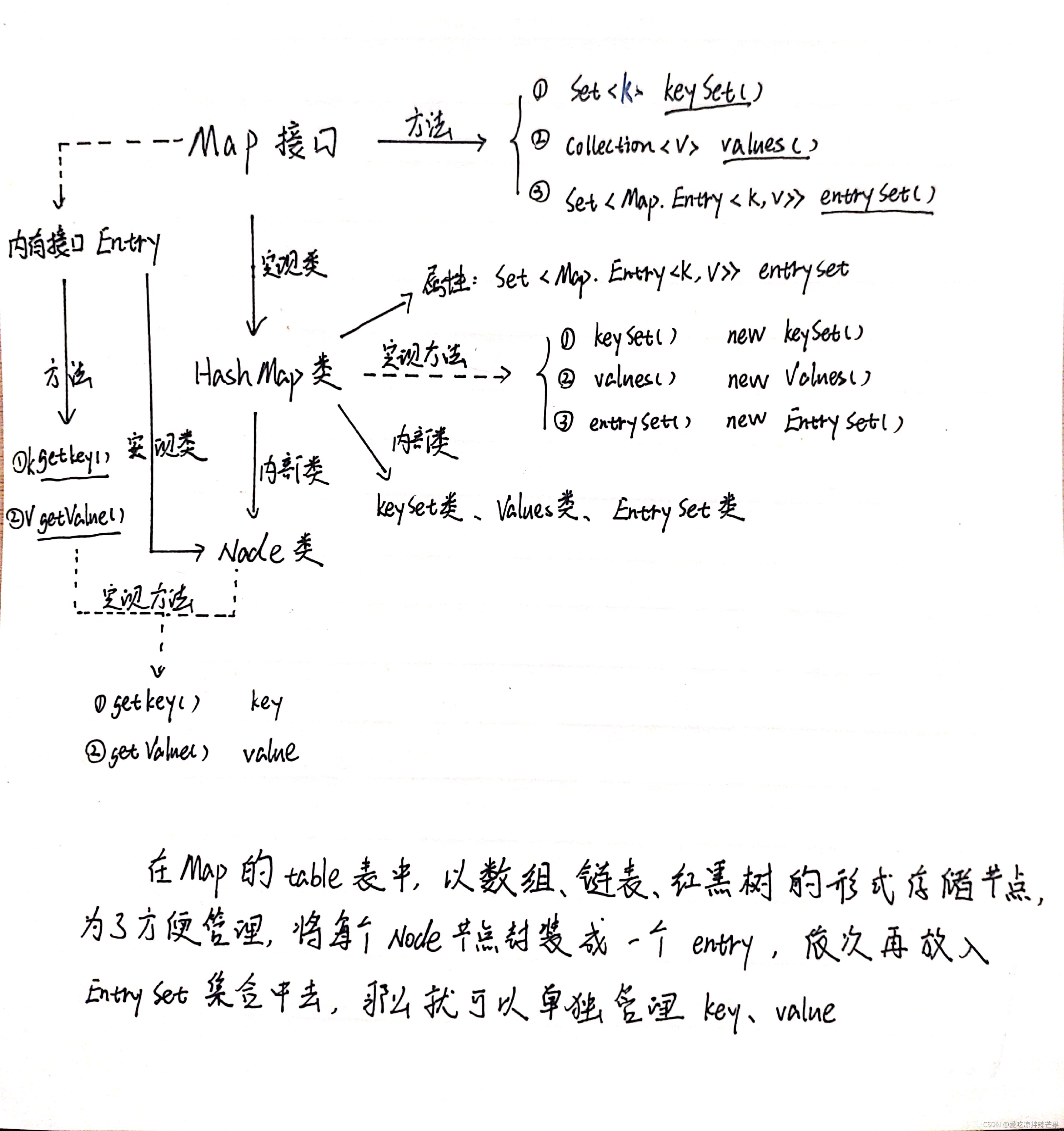
(1)Map�ӿ�����Entry<K,V>�ӿڡ�
Entry�ӿ����г��÷���:
��1��K getKey();��2��V getValue();��3��V setValue(V value);
��4��int hashCode();��5��boolean equals(Object o);;
(2)HashMap�������ڲ���Node<K,V>,����ʵ����Entry<K,V>�ӿ�,�Ҹ�������������:int hash;K key;V value;Node<K,V> next;��k-v����Ǵ�����Node<K,V>��Ķ����С�
(3)k-vΪ�˷������Ա�ı���,���ᴴ��EntrySet����,�ü��ϴ�ŵ�Ԫ�ص����� Entry,��һ��Entry�����������k ,v ��EntrySet<Entry<K , V>>��: transient Set<Map.Entry<K, V>> entrySet;
(3)entrySet ��,�����������Map.Entry ,����ʵ���ϴ�ŵĻ��� HashMap$Node��ʱ��Ϊ static class Node<K, V> implements Map.Entry<K, V>
(4)����HashHap $ Node�����ŵ�entrySet�ͷ������ǵı���,��Ϊ Map.Entrfy�ṩ����Ҫ����K getKey( ); v getValue( );
��Map������ݵ�key-valueʾ��ͼ��

��Map������ݵ�key-valueʾ��ͼ2��
3. Map�ӿڳ��÷���
Map map = new HashMap();
(1)put ����
map.put("�˳�", new Book("", 100));//OK
map.put("�˳�", "��ٳ"); //�滻-> һ�����Դ��
map.put("����ǿ", "����");//OK
map.put("�Ά�", "����");//OK
map.put("���", null);//OK
map.put(null, "�����");//OK
map.put("¹��", "����ͮ");//OK
map.put("��־", "С÷");
(2)remove:���ݼ�ɾ��ӳ���ϵ
map.remove(null);
(3)get:���ݼ���ȡֵ
Object val = map.get("¹��");
(4)size:��ȡԪ�ظ���
System.out.println("k-v=" + map.size());
(5)isEmpty:�жϸ����Ƿ�Ϊ 0
System.out.println(map.isEmpty());
(6)clear:��� k-v
map.clear();
(7)containsKey:���Ҽ��Ƿ����
System.out.println("���=" + map.containsKey("��־"));
4. Map������ʽ
(1)containsKey:���Ҽ��Ƿ����
(2)keySet:��ȡ���еļ�
(3)values:��ȡ���е�ֵ
(4)entrySet:��ȡ���й�ϵk-v
Map map = new HashMap();
map.put("�˳�", "��ٳ");
map.put("����ǿ", "����");
map.put("�Ά�", "����");
map.put("���", null);
map.put(null, "�����");
map.put("¹��", "����ͮ");
(1)��ʽһ:��ȡ�� ���е� Key , ͨ�� Key ȡ����Ӧ�� Value��
Set keyset = map.keySet();
��1����ǿ for
System.out.println("-----��һ�ַ�ʽ-------");
for (Object key : keyset) {
System.out.println(key + "-" + map.get(key));
}
��2�� ������
System.out.println("----�ڶ��ַ�ʽ--------");
Iterator iterator = keyset.iterator();
while (iterator.hasNext()) {
Object key = iterator.next();
System.out.println(key + "-" + map.get(key));
}
(2)��ʽ��:�����е� values ȡ��
Collection values = map.values();
�������ʹ�����е� Collections ʹ�õı�������
��1����ǿ for
System.out.println("---ȡ�����е� value ��ǿ for----");
for (Object value : values) {
System.out.println(value);
}
��2��������
System.out.println("---ȡ�����е� value ������----");
Iterator iterator2 = values.iterator();
while (iterator2.hasNext()) {
Object value = iterator2.next();
System.out.println(value);
}
(3)��ʽ��:ͨ�� EntrySet ����ȡ k-v
Set entrySet = map.entrySet();//EntrySet<Map.Entry<K,V>>
��1����ǿ for
System.out.println("----ʹ�� EntrySet �� for ��ǿ(�� 3 ��)----");
for (Object entry : entrySet) {
//�� entry ת�� Map.Entry
Map.Entry m = (Map.Entry) entry;
System.out.println(m.getKey() + "-" + m.getValue());
}
��2��������
System.out.println("----ʹ�� EntrySet �� ������(�� 4 ��)----");
Iterator iterator3 = entrySet.iterator();
while (iterator3.hasNext()) {
Object entry = iterator3.next();
//System.out.println(next.getClass());//HashMap$Node -ʵ��-> Map.Entry (getKey,getValue)
//����ת�� Map.Entry
Map.Entry m = (Map.Entry) entry;
System.out.println(m.getKey() + "-" + m.getValue());
}
5. Map���������ʽʾ��
package exercise.chapter14;
import java.util.*;
/**
* @Package: exercise.chapter14
* @ClassName: map02
* @Author: �����������
* @CreateTime: 2021/10/21 23:04
* @Description: HashMap��ϰ��
* ʹ��HashMap����3��Ա������, Ҫ���:Ա��id ֵ:Ա������
* ��������ʾ����>18000��Ա��(������ʽ��������)
* Ա����:���������ʡ�Ա��id
*/
public class map02 {
public static void main(String[] args) {
Map map = new HashMap();
map.put("001",new staff("��־", 15000, "001"));
map.put("002",new staff("�", 20000, "002"));
map.put("003",new staff("С÷", 25000, "003"));
//����/
}
}
class staff{
private String name;
private double salary;
private String id;
public staff(String name, double salary, String id) {
this.name = name;
this.salary = salary;
this.id = id;
}
@Override
public String toString() {
return "Ա��:" +
"name='" + name + '\'' +
", salary=" + salary +
", id='" + id + '\'' ;
}
public String getName() {
return name;
}
public double getSalary() {
return salary;
}
public String getId() {
return id;
}
}
����һ:KeySet
(1)ʹ�õ�����
Set set = map.keySet();
Iterator ite = set.iterator();
while (ite.hasNext()) {
Object next = ite.next();
staff sta = (staff) map.get(next);
if(sta.getSalary()>=18000){
System.out.println(map.get(next));
}
}
(2)ʹ����ǿforѭ��
//Set set = map.keySet();
for (Object obj : set) {
staff sta =(staff)map.get(obj);
if(sta.getSalary() >= 18000){
System.out.println(obj+"-"+map.get(obj));
}
}
������:values
(1)ʹ�õ�����
Collection values = map.values();
Iterator iterator = values.iterator();
while (iterator.hasNext()) {
staff sta = (staff)iterator.next();
if(sta.getSalary() >= 18000){
System.out.println(sta);
}
}
(2)ʹ����ǿforѭ��
//Collection values = map.values();
for (Object object : values) {
staff sta = (staff)object;
if(sta.getSalary() >= 18000){
System.out.println(sta);
}
}
������:entrySet
(1)ʹ�õ�����
Set set = map.entrySet();
Iterator iterator = set.iterator();
while (iterator.hasNext()) {
Map.Entry ne = (Map.Entry)iterator.next();
staff sta = (staff) ne.getValue();
if(sta.getSalary()>=18000){
System.out.println(sta);
}
}
(2)ʹ����ǿforѭ��
//Set set = map.entrySet();
for (Object object : set) {
Map.Entry ne = (Map.Entry)object; //�����neʵ�ʾ���һ��Node�ڵ�,��ΪNode��
staff sta = (staff) ne.getValue(); //��ΪNode��ʵ����Entry�ӿڡ�
if(sta.getSalary()>=18000){
System.out.println(sta);
}
}
6. HashMap�ײ����
��HashMap�ײ���ơ�
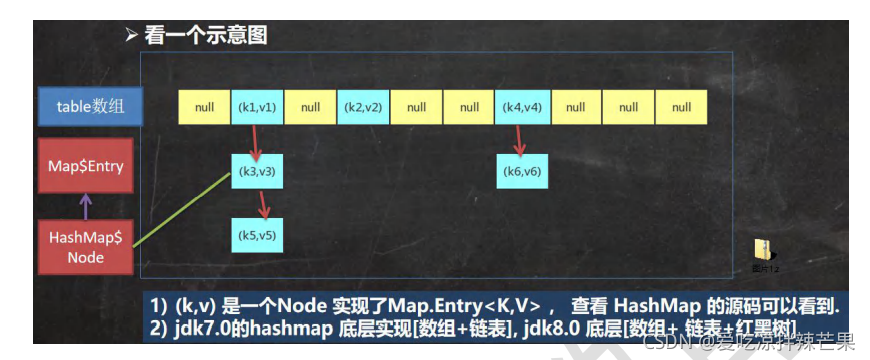
7. HashMap���ݻ���
(1)��HashSet��ͬ�� �ο�HashSet�ײ�Դ�������
(2)HashMap�ײ�ά����Node���͵�����table,Ĭ��Ϊnull
(3)����������ʱ,����������(loadfactor)��ʼ��Ϊ0.75.
(4)������key-valʱ,ͨ��key�Ĺ�ϣֵ�õ���table��������Ȼ���жϸ��������Ƿ���Ԫ��,���û��Ԫ��ֱ�����ӡ��������������Ԫ��,�����жϸ�Ԫ�ص�key���������key���Ƿ��,������,��ֱ���滻val;����������Ҫ�ж������ṹ���������ṹ,������Ӧ�������������ʱ������������,����Ҫ���ݡ�
(5)��1������,����Ҫ����table����Ϊ16,�ٽ�ֵ(threshold)Ϊ12(16*0.75)
(6)�Ժ�������,����Ҫ����table����Ϊԭ����2��(32),�ٽ�ֵΪ24,��������
(7)��Java8��,���һ��������Ԫ�ظ�������TREEIFY_THRESHOLD(Ĭ����8),�����ʱtable�Ĵ�С>= MIN_TREEIFY_CAPACITY(Ĭ��64),�ͻ��������(�����);���table�Ĵ�С������64,��table��������2�����ݡ�
�塢HashTable��
1. ����
(1)��ŵ�Ԫ���Ǽ�ֵ��:��K-V
(2)hashtable�ļ���ֵ������Ϊnull,������׳�NullPointerException
(3)hashTableʹ�÷��������Ϻ�HashMapһ��
(4)hashTable���̰߳�ȫ��(synchronized),hashMap���̲߳���ȫ�ġ�
2. �ײ����
(1)�ײ�������Hashtable$Entry[ ]����Žڵ�,��ʼ����СΪ11������EntryΪHashTable���ڲ��ࡣ
(2)�ٽ�ֵ threshold 8 = 11 * 0.75�������ٽ�ֵʱ������Ϊԭ����2����1
����Hashtable�� HashMap�Ա�

�ߡ�Properties��
1. ����
(1)Properties��̳���Hashtable�ಢ��ʵ����Map�ӿ�,Ҳ��ʹ��һ�ּ�ֵ�Ե���ʽ���������ݡ�
(2)����ʹ���ص��Hashtable����
(3)Properties���������ڴ� xxx.properties�����ļ���,�������ݵ�Properties�����,�����ж�ȡ����
(4)Properties �̳� Hashtable,����ͨ�� k-v �������,��Ȼ key �� value ����Ϊ null
2. ���÷���
Properties properties = new Properties();
(1)put ����
//properties.put(null, ��abc��);//�׳� ��ָ���쳣
//properties.put(��abc��, null); //�׳� ��ָ���쳣
properties.put(��john��, 100);//k-v
properties.put(��lucy��, 100);
properties.put(��lic��, 100);
properties.put(��lic��, 88);//�������ͬ�� key , value ���滻
(2)get ͨ�� k ��ȡ��Ӧֵ
System.out.println(properties.get(��lic��));//88
(3)remove ɾ��
properties.remove(��lic��);
System.out.println(��properties=�� + properties);
(4)��
properties.put(��john��, ��Լ����);
System.out.println(��properties=�� + properties);
�ˡ����ѡ��ʵ����

1. ���жϴ洢������(һ�����[����]��һ���ֵ��[˫��])
2. һ�����[����]:Collection�ӿ�
(1)�����ظ��ڵ�:List
��1����ɾ��:LinkedList [�ײ�ά����һ��˫������]
��2���IJ��:ArrayList [�ײ�ά��Object���͵Ŀɱ�����]
(2)�������ظ�:Set
��1�������ȡ��û��˳��:HashSet [�ײ���HashMap,ά����һ����ϣ��,������+����+�����]
��2����������:TreeSet
��3�������ȡ��˳��һ��:LinkedHashSet,ά������+˫������
3. һ���ֵ��[˫��]:Map�ӿ�
(1)������: HashMap [�ײ���:��ϣ�� jdk7:����+����,jdk8:����+����+�����]
(2)������:TreeMap
(3)�������ȡ��˳��һ��:LinkedHashMap
(4)��ȡ�ļ�:Properties
�š�TreeSet��
1. ����
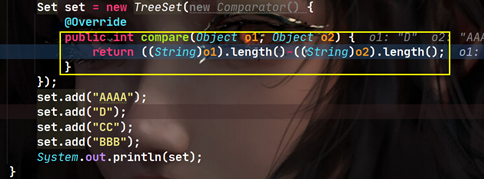
(1)�����ص�:��������
(2)��ʹ���ι�����û����������;��ʹ���вεĹ�����,���в���ʵ����comparator�ӿڵĶ���,�漰�������ڲ��ࡣ
2. �ײ����ΪTreeMap
(1)�������Ѵ���ıȽ�������,������ TreeSet �ĵײ�� TreeMap ������ this.comparator

(2)�ڵ��� treeSet.add(��AAA��), �ڵײ��ִ��,����cprΪ���Ǵ���������ڲ���
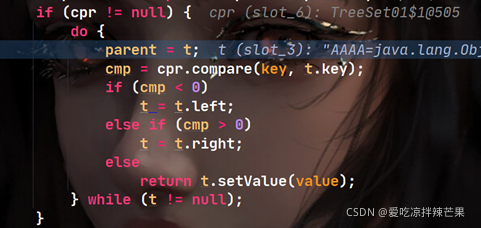
(3)�ɶ�̬����,���ص����Ǵ���������ڲ�����ִ��compare

ʮ��Collections������
1. ����
(1)Collections��һ������Set��List��Map�ȼ��ϵĹ�����,�����Լ��Ͻ��в����ķ�����
(2)Collections���ṩ��һϵ�о�̬�ķ����Լ���Ԫ�ؽ�������ѯ���ĵȲ���
(3)����ṩ�����ǵļ��ϻ������Ϊnull,�����ķ������׳�һ��NullPointerException
2. ����
List list = new ArrayList();
list.add("tom");
list.add("smith");
list.add("king");
list.add("milan");
list.add("tom");
(1)reverse(List):��ת List ��Ԫ�ص�˳��
Collections.reverse(list);
(2)shuffle(List):�� List ����Ԫ�ؽ����������
Collections.shuffle(list);
(3)sort(List):����Ԫ�ص���Ȼ˳���ָ�� List ����Ԫ�ذ�������
Collections.sort(list);
(4)sort(List,Comparator):����ָ���� Comparator ������˳��� List ����Ԫ�ؽ�������
Collections.sort(list, new Comparator() {
@Override
public int compare(Object o1, Object o2) {
//���Լ���У�����.
return ((String) o2).length() - ((String) o1).length();
}
});
(5)swap(List,int, int):��ָ�� list �����е� i ��Ԫ�غ� j ��Ԫ�ؽ���
Collections.swap(list, 0, 1);
(6)Collections.max(list):����Ԫ�ص���Ȼ˳��,���ظ��������е����Ԫ��
(7)max(Collection,Comparator):���� Comparator ָ����˳��,���ظ��������е����Ԫ��
����,����Ҫ���س�������Ԫ��
Object maxObject = Collections.max(list, new Comparator() {
@Override
public int compare(Object o1, Object o2) {
return ((String)o1).length() - ((String)o2).length();
}
});
(8)Collections.frequency(list, ��tom��):����ָ��������ָ��Ԫ�صij��ִ���
(9)Collections.copy(dest, list):��������
ǰ����dest����Ϊ��,�����׳��쳣
ArrayList dest = new ArrayList();
//Ϊ�����һ����������,������Ҫ�ȸ� dest ��ֵ,
//��С�� list.size()һ��
for(int i = 0; i < list.size(); i++) {
dest.add("");
}
Collections.copy(dest, list);
(10)Collections.replaceAll(list, ��tom��, ����ķ��):ʹ����ֵ�滻 List ��������о�ֵ
��� list ���� tom ���滻����ķ
Collections.replaceAll(list, "tom", "��ķ");