序列化 vs 反序列化
如果我们需要持久化 Java 对象比如将 Java 对象保存在文件中,或者在网络传输 Java 对象,这些场景都需要用到序列化。
简单来说:
- 序列化: 将数据结构或对象转换成二进制字节流的过程
- 反序列化:将在序列化过程中所生成的二进制字节流转换成数据结构或者对象的过程
对于 Java 这种面向对象编程语言来说,我们序列化的都是对象(Object)也就是实例化后的类(Class),但是在 C++这种半面向对象的语言中,struct(结构体)定义的是数据结构类型,而 class 对应的是对象类型。
维基百科是如是介绍序列化的:
序列化(serialization)在计算机科学的数据处理中,是指将数据结构或对象状态转换成可取用格式(例如存成文件,存于缓冲,或经由网络中发送),以留待后续在相同或另一台计算机环境中,能恢复原先状态的过程。依照序列化格式重新获取字节的结果时,可以利用它来产生与原始对象相同语义的副本。对于许多对象,像是使用大量引用的复杂对象,这种序列化重建的过程并不容易。面向对象中的对象序列化,并不概括之前原始对象所关系的函数。这种过程也称为对象编组(marshalling)。从一系列字节提取数据结构的反向操作,是反序列化(也称为解编组、deserialization、unmarshalling)。
综上:序列化的主要目的是通过网络传输对象或者说是将对象存储到文件系统、数据库、内存中。
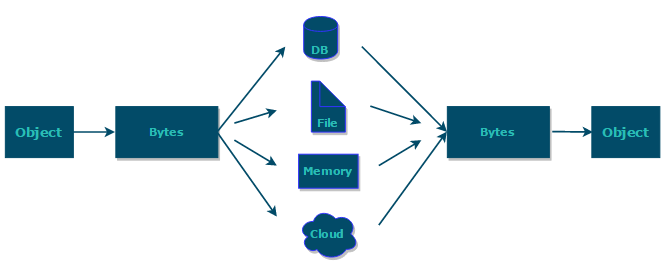
部分字段序列化
对于不想进行序列化的变量,使用 transient 关键字修饰。
transient 关键字的作用是:阻止实例中那些用此关键字修饰的的变量序列化;当对象被反序列化时,被 transient 修饰的变量值不会被持久化和恢复。
关于 transient 还有几点注意:
transient只能修饰变量,不能修饰类和方法。transient修饰的变量,在反序列化后变量值将会被置成类型的默认值。例如,如果是修饰int类型,那么反序列后结果就是0。static变量因为不属于任何对象(Object),所以无论有没有transient关键字修饰,均不会被序列化。
键盘输入
方法 1:通过 Scanner
Scanner input = new Scanner(System.in);
String s = input.nextLine();
input.close();
方法 2:通过 BufferedReader
BufferedReader input = new BufferedReader(new InputStreamReader(System.in));
String s = input.readLine();
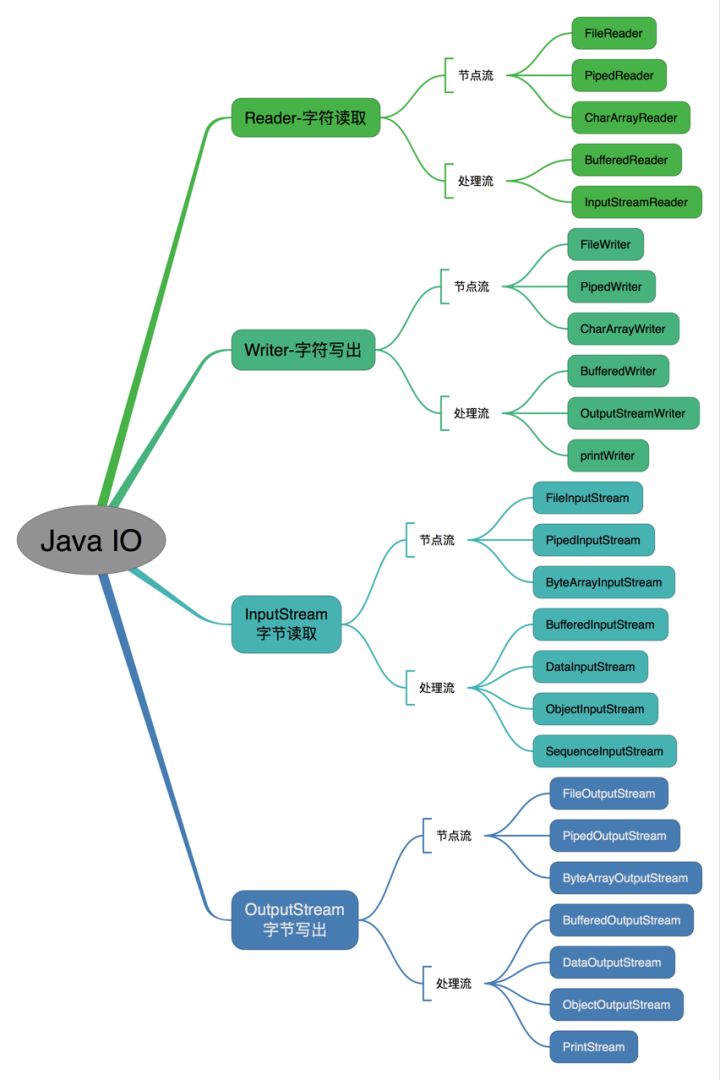
IO 流种类
- 按照流的流向分,可以分为输入流和输出流
- 按照操作单元划分,可以划分为字节流和字符流
- 按照流的角色划分为节点流和处理流
Java IO 流共涉及 40 多个类,这些类看上去很杂乱,但实际上很有规则,而且彼此之间存在非常紧密的联系, Java IO 流的 40 多个类都是从如下 4 个抽象类基类中派生出来的。
-
InputStream/Reader:
所有的输入流的基类,前者是字节输入流,后者是字符输入流。
-
OutputStream/Writer
所有输出流的基类,前者是字节输出流,后者是字符输出流。
按操作方式分类结构图:
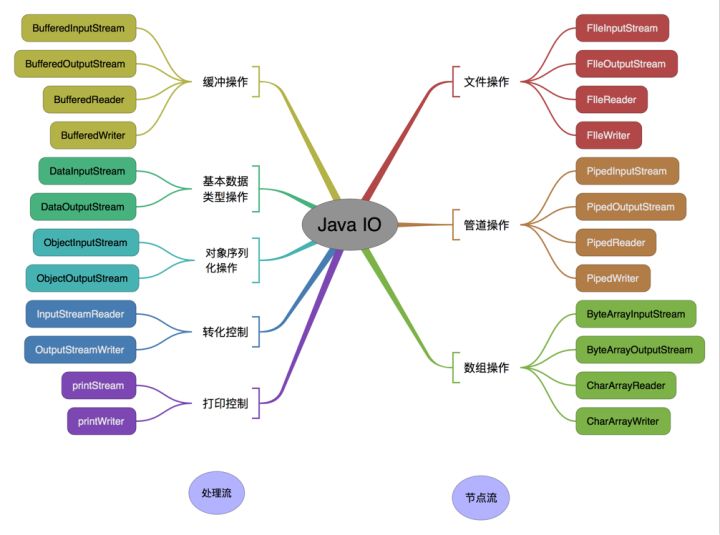
按操作对象分类结构图:
字节流 vs 字符流
问题本质想问:不管是文件读写还是网络发送接收,信息的最小存储单元都是字节,那为什么 I/O 流操作要分为字节流操作和字符流操作呢?
回答:字符流是由 Java 虚拟机将字节转换得到的,问题就出在这个过程还算是非常耗时,并且,如果我们不知道编码类型就很容易出现乱码问题。所以, I/O 流就干脆提供了一个直接操作字符的接口,方便我们平时对字符进行流操作。如果音频文件、图片等媒体文件用字节流比较好,如果涉及到字符的话使用字符流比较好。
Stream
二进制数据以byte为最小单位在InputStream/OutputStream中单向流动;
InputStream
Java标准库的java.io.InputStream定义了所有输入流的超类:
FileInputStream实现了文件流输入;ByteArrayInputStream在内存中模拟一个字节流输入。
总是使用try(resource)来保证InputStream正确关闭。
用try ... finally编写会比较复杂,更好的写法是利用Java 7引入的新的try(resource)的语法,只需要编写try语句,让编译器自动为我们关闭资源。推荐的写法如下:
public void readFile() throws IOException {
try (InputStream input = new FileInputStream("src/readme.txt")) {
int n;
while ((n = input.read()) != -1) {
System.out.println(n);
}
} // 编译器在此自动为我们写入finally并调用close()
}
编译器只看try(resource = ...)中的对象是否实现了java.lang.AutoCloseable接口,如果实现了,就自动加上finally语句并调用close()方法
缓冲
int read(byte[] b):读取若干字节并填充到byte[]数组,返回读取的字节数int read(byte[] b, int off, int len):指定byte[]数组的偏移量和最大填充数
public void readFile() throws IOException {
try (InputStream input = new FileInputStream("src/readme.txt")) {
// 定义1000个字节大小的缓冲区:
byte[] buffer = new byte[1000];
int n;
while ((n = input.read(buffer)) != -1) { // 读取到缓冲区
System.out.println("read " + n + " bytes.");
}
}
}
InputStream实现类
用FileInputStream可以从文件获取输入流,这是InputStream常用的一个实现类。
此外,ByteArrayInputStream可以在内存中模拟一个InputStream
public class Main {
public static void main(String[] args) throws IOException {
byte[] data = { 72, 101, 108, 108, 111, 33 };
try (InputStream input = new ByteArrayInputStream(data)) {
String s = readAsString(input);
System.out.println(s);
}
}
public static String readAsString(InputStream input) throws IOException {
int n;
StringBuilder sb = new StringBuilder();
while ((n = input.read()) != -1) {
sb.append((char) n);
}
return sb.toString();
}
}
OutputStream
Java标准库的java.io.OutputStream定义了所有输出流的超类:
FileOutputStream实现了文件流输出;ByteArrayOutputStream在内存中模拟一个字节流输出。
某些情况下需要手动调用OutputStream的flush()方法来强制输出缓冲区。
总是使用try(resource)来保证OutputStream正确关闭。
public void writeFile() throws IOException {
try (OutputStream output = new FileOutputStream("out/readme.txt")) {
output.write("Hello".getBytes("UTF-8")); // Hello
} // 编译器在此自动为我们写入finally并调用close()
}
OutputStream实现类
用FileOutputStream可以从文件获取输出流,这是OutputStream常用的一个实现类。此外,ByteArrayOutputStream可以在内存中模拟一个OutputStream:
public class Main {
public static void main(String[] args) throws IOException {
byte[] data;
try (ByteArrayOutputStream output = new ByteArrayOutputStream()) {
output.write("Hello ".getBytes("UTF-8"));
output.write("world!".getBytes("UTF-8"));
data = output.toByteArray();
}
System.out.println(new String(data, "UTF-8"));
}
}
Filter模式
Java的IO标准库使用Filter模式为InputStream和OutputStream增加功能:
- 可以把一个
InputStream和任意个FilterInputStream组合; - 可以把一个
OutputStream和任意个FilterOutputStream组合。
Filter模式可以在运行期动态增加功能(又称Decorator模式)
为了解决依赖继承会导致子类数量失控的问题,JDK首先将InputStream分为两大类:
一类是直接提供数据的基础InputStream,例如:
FileInputStream:从文件读取数据,是最终数据源;ServletInputStream:从HTTP请求读取数据,是最终数据源;Socket.getInputStream():从TCP连接读取数据,是最终数据源;
一类是提供额外附加功能的InputStream,例如:
BufferedInputStreamDigestInputStreamCipherInputStream
无论我们包装多少次,得到的对象始终是InputStream,我们直接用InputStream来引用它,就可以正常读取:
┌─────────────────────────┐
│GZIPInputStream │
│┌───────────────────────┐│
││BufferedFileInputStream││
││┌─────────────────────┐││
│││ FileInputStream │││
││└─────────────────────┘││
│└───────────────────────┘│
└─────────────────────────┘
上述这种通过一个“基础”组件再叠加各种“附加”功能组件的模式,称之为Filter模式(或者装饰器模式:Decorator)。它可以让我们通过少量的类来实现各种功能的组合:
┌─────────────┐
│ InputStream │
└─────────────┘
▲ ▲
┌────────────────────┐ │ │ ┌─────────────────┐
│ FileInputStream │─┤ └─│FilterInputStream│
└────────────────────┘ │ └─────────────────┘
┌────────────────────┐ │ ▲ ┌───────────────────┐
│ByteArrayInputStream│─┤ ├─│BufferedInputStream│
└────────────────────┘ │ │ └───────────────────┘
┌────────────────────┐ │ │ ┌───────────────────┐
│ ServletInputStream │─┘ ├─│ DataInputStream │
└────────────────────┘ │ └───────────────────┘
│ ┌───────────────────┐
└─│CheckedInputStream │
└───────────────────┘
类似的,OutputStream也是以这种模式来提供各种功能:
┌─────────────┐
│OutputStream │
└─────────────┘
▲ ▲
┌─────────────────────┐ │ │ ┌──────────────────┐
│ FileOutputStream │─┤ └─│FilterOutputStream│
└─────────────────────┘ │ └──────────────────┘
┌─────────────────────┐ │ ▲ ┌────────────────────┐
│ByteArrayOutputStream│─┤ ├─│BufferedOutputStream│
└─────────────────────┘ │ │ └────────────────────┘
┌─────────────────────┐ │ │ ┌────────────────────┐
│ ServletOutputStream │─┘ ├─│ DataOutputStream │
└─────────────────────┘ │ └────────────────────┘
│ ┌────────────────────┐
└─│CheckedOutputStream │
└────────────────────
编写FilterInputStream
public class Main {
public static void main(String[] args) throws IOException {
byte[] data = "hello, world!".getBytes("UTF-8");
try (CountInputStream input = new CountInputStream(new ByteArrayInputStream(data))) {
int n;
while ((n = input.read()) != -1) {
System.out.println((char)n);
}
System.out.println("Total read " + input.getBytesRead() + " bytes");
}
}
}
class CountInputStream extends FilterInputStream {
private int count = 0;
CountInputStream(InputStream in) {
super(in);
}
public int getBytesRead() {
return this.count;
}
public int read() throws IOException {
int n = in.read();
if (n != -1) {
this.count ++;
}
return n;
}
public int read(byte[] b, int off, int len) throws IOException {
int n = in.read(b, off, len);
this.count += n;
return n;
}
}
ZipInputStream
ZipInputStream可以读取zip格式的流,ZipOutputStream可以把多份数据写入zip包;
配合FileInputStream和FileOutputStream就可以读写zip文件。
┌───────────────────┐
│ InputStream │
└───────────────────┘
▲
│
┌───────────────────┐
│ FilterInputStream │
└───────────────────┘
▲
│
┌───────────────────┐
│InflaterInputStream│
└───────────────────┘
▲
│
┌───────────────────┐
│ ZipInputStream │
└───────────────────┘
▲
│
┌───────────────────┐
│ JarInputStream │
└───────────────────┘
JarInputStream是从ZipInputStream派生,它增加的主要功能是直接读取jar文件里面的MANIFEST.MF文件
**读取zip包 **
try (ZipInputStream zip = new ZipInputStream(new FileInputStream(...))) {
ZipEntry entry = null;
while ((entry = zip.getNextEntry()) != null) {
String name = entry.getName();
if (!entry.isDirectory()) {
int n;
while ((n = zip.read()) != -1) {
...
}
}
}
}
写入zip包
try (ZipOutputStream zip = new ZipOutputStream(new FileOutputStream(...))) {
File[] files = ...
for (File file : files) {
zip.putNextEntry(new ZipEntry(file.getName()));
zip.write(getFileDataAsBytes(file));
zip.closeEntry();
}
}
如果要实现目录层次结构,new ZipEntry(name)传入的name要用相对路径。
Reader Writer
字符数据以char为最小单位在Reader/Writer中单向流动。本质上是一个能自动编解码的InputStream和OutputStream。
Reader
Reader定义了所有字符输入流的超类:
FileReader实现了文件字符流输入,使用时需要指定编码;CharArrayReader和StringReader可以在内存中模拟一个字符流输入。
Reader是基于InputStream构造的:可以通过InputStreamReader在指定编码的同时将任何InputStream转换为Reader。
| InputStream | Reader |
|---|---|
字节流,以byte为单位 | 字符流,以char为单位 |
读取字节(-1,0~255):int read() | 读取字符(-1,0~65535):int read() |
读到字节数组:int read(byte[] b) | 读到字符数组:int read(char[] c) |
FileReader
public void readFile() throws IOException {
try (Reader reader = new FileReader("src/readme.txt", StandardCharsets.UTF_8)) {
int n;
char[] buffer = new char[1000];
while ((n = reader.read(buffer)) != -1) {
System.out.println("read " + n + " chars.");
}
}
}
CharArrayReader
CharArrayReader可以在内存中模拟一个Reader,它的作用实际上是把一个char[]数组变成一个Reader,这和ByteArrayInputStream非常类似:
try (Reader reader = new CharArrayReader("Hello".toCharArray())) {
}
StringReader
StringReader可以直接把String作为数据源,它和CharArrayReader几乎一样:
try (Reader reader = new StringReader("Hello")) {
}
InputStreamReader
try (Reader reader = new InputStreamReader(new FileInputStream("src/readme.txt"), "UTF-8")) {
// TODO:
}
Writer
Writer定义了所有字符输出流的超类:
FileWriter实现了文件字符流输出;CharArrayWriter和StringWriter在内存中模拟一个字符流输出。
Writer是基于OutputStream构造的,可以通过OutputStreamWriter将OutputStream转换为Writer,转换时需要指定编码。
| OutputStream | Writer |
|---|---|
字节流,以byte为单位 | 字符流,以char为单位 |
写入字节(0~255):void write(int b) | 写入字符(0~65535):void write(int c) |
写入字节数组:void write(byte[] b) | 写入字符数组:void write(char[] c) |
| 无对应方法 | 写入String:void write(String s) |
FileWriter
FileWriter就是向文件中写入字符流的Writer。它的使用方法和FileReader类似:
try (Writer writer = new FileWriter("readme.txt", StandardCharsets.UTF_8)) {
writer.write('H'); // 写入单个字符
writer.write("Hello".toCharArray()); // 写入char[]
writer.write("Hello"); // 写入String
}
CharArrayWriter
CharArrayWriter可以在内存中创建一个Writer,它的作用实际上是构造一个缓冲区,可以写入char,最后得到写入的char[]数组,这和ByteArrayOutputStream非常类似:
try (CharArrayWriter writer = new CharArrayWriter()) {
writer.write(65);
writer.write(66);
writer.write(67);
char[] data = writer.toCharArray(); // { 'A', 'B', 'C' }
}
StringWriter
StringWriter也是一个基于内存的Writer,它和CharArrayWriter类似。实际上,StringWriter在内部维护了一个StringBuffer,并对外提供了Writer接口。
OutputStreamWriter
除了CharArrayWriter和StringWriter外,普通的Writer实际上是基于OutputStream构造的,它接收char,然后在内部自动转换成一个或多个byte,并写入OutputStream。因此,OutputStreamWriter就是一个将任意的OutputStream转换为Writer的转换器:
try (Writer writer = new OutputStreamWriter(new FileOutputStream("readme.txt"), "UTF-8")) {
// TODO:
}
PrintStream是一种能接收各种数据类型的输出,打印数据时比较方便:
System.out是标准输出;System.err是标准错误输出。
PrintWriter是基于Writer的输出。
PrintStream
PrintStream是一种FilterOutputStream,它在OutputStream的接口上,额外提供了一些写入各种数据类型的方法:
- 写入
int:print(int) - 写入
boolean:print(boolean) - 写入
String:print(String) - 写入
Object:print(Object),实际上相当于print(object.toString())
它还有一个额外的优点,就是不会抛出IOException
PrintWriter
PrintStream最终输出的总是byte数据,而PrintWriter则是扩展了Writer接口,它的print()/println()方法最终输出的是char数据。
public class Main {
public static void main(String[] args) {
StringWriter buffer = new StringWriter();
try (PrintWriter pw = new PrintWriter(buffer)) {
pw.println("Hello");
pw.println(12345);
pw.println(true);
}
System.out.println(buffer.toString());
}
}
File
Java的标准库java.io提供了File对象来操作文件和目录
File对象有3种形式表示的路径:
getPath(),返回构造方法传入的路径getAbsolutePath(),返回绝对路径getCanonicalPath,它和绝对路径类似,但是返回的是规范路径。
绝对路径可以表示成C:\Windows\System32\..\notepad.exe,而规范路径就是把.和..转换成标准的绝对路径后的路径:C:\Windows\notepad.exe。
创建
File对象本身不涉及IO操作;
文件和目录
isFile(),判断该File对象是否是一个已存在的文件
isDirectory(),判断该File对象是否是一个已存在的目录
用File对象获取到一个文件时,还可以进一步判断文件的权限和大小:
boolean canRead():是否可读;boolean canWrite():是否可写;boolean canExecute():是否可执行;long length():文件字节大小。
对目录而言,是否可执行表示能否列出它包含的文件和子目录
创建和删除文件/目录
文件
当File对象表示一个文件时,可以通过createNewFile()创建一个新文件,用delete()删除该文件:
File对象提供了createTempFile()来创建一个临时文件,以及deleteOnExit()在JVM退出时自动删除该文件
目录
和文件操作类似,File对象如果表示一个目录,可以通过以下方法创建和删除目录:
boolean mkdir():创建当前File对象表示的目录;boolean mkdirs():创建当前File对象表示的目录,并在必要时将不存在的父目录也创建出来;boolean delete():删除当前File对象表示的目录,当前目录必须为空才能删除成功。
遍历文件和目录
可以获取目录的文件和子目录:list()/listFiles()
public class Main {
public static void main(String[] args) throws IOException {
File f = new File("C:\\Windows");
File[] fs1 = f.listFiles(); // 列出所有文件和子目录
printFiles(fs1);
File[] fs2 = f.listFiles(new FilenameFilter() { // 仅列出.exe文件
public boolean accept(File dir, String name) {
return name.endsWith(".exe"); // 返回true表示接受该文件
}
});
printFiles(fs2);
}
static void printFiles(File[] files) {
System.out.println("==========");
if (files != null) {
for (File f : files) {
System.out.println(f);
}
}
System.out.println("==========");
}
}
Path
Java标准库还提供了一个Path对象,它位于java.nio.file包。Path对象和File对象类似
Serialize
序列化是指把一个Java对象变成二进制内容,本质上就是一个byte[]数组。
-
可序列化的Java对象必须实现
java.io.Serializable接口,类似Serializable这样的空接口被称为“标记接口”(Marker Interface); -
反序列化时不调用构造方法,可设置
serialVersionUID作为版本号(非必需);
序列化
public class Main {
public static void main(String[] args) throws IOException {
ByteArrayOutputStream buffer = new ByteArrayOutputStream();
try (ObjectOutputStream output = new ObjectOutputStream(buffer)) {
// 写入int:
output.writeInt(12345);
// 写入String:
output.writeUTF("Hello");
// 写入Object:
output.writeObject(Double.valueOf(123.456));
}
System.out.println(Arrays.toString(buffer.toByteArray()));
}
}
反序列化
try (ObjectInputStream input = new ObjectInputStream(...)) {
int n = input.readInt();
String s = input.readUTF();
Double d = (Double) input.readObject();
}
readObject()可能抛出的异常有:
-
ClassNotFoundException这种情况常见于一台电脑上的Java程序把一个Java对象,例如,
Person对象序列化以后,通过网络传给另一台电脑上的另一个Java程序,但是这台电脑的Java程序并没有定义Person类,所以无法反序列化。 -
InvalidClassException对于
InvalidClassException,这种情况常见于序列化的Person对象定义了一个int类型的age字段,但是反序列化时,Person类定义的age字段被改成了long类型,所以导致class不兼容
为了避免这种class定义变动导致的不兼容,Java的序列化允许class定义一个特殊的serialVersionUID静态变量,用于标识Java类的序列化“版本”,通常可以由IDE自动生成。如果增加或修改了字段,可以改变serialVersionUID的值,这样就能自动阻止不匹配的class版本:
public class Person implements Serializable {
private static final long serialVersionUID = 2709425275741743919L;
}
安全性
因为Java的序列化机制可以导致一个实例能直接从byte[]数组创建,而不经过构造方法,因此,它存在一定的安全隐患。一个精心构造的byte[]数组被反序列化后可以执行特定的Java代码,从而导致严重的安全漏洞。同时也存在兼容性问题。
更好的序列化方法是通过JSON这样的通用数据结构来实现,只输出基本类型(包括String)的内容,而不存储任何与代码相关的信息。
google protobuf 性能非常高