1 ����һ��Java�е�IO��
���
IO(Input Output)����ʵ�ֶ����ݵ��������������,Java�Ѳ�ͬ������/���Դ(���̡��ļ��������)�������Ϊ��(Stream)�����Ǵ���Դ�����յ���������,����������Ϳ��Բ���ͬһ��ʽ���ʲ�ͬ������/���Դ��
������������,���Խ�����Ϊ�������������,����������ֻ�ܶ�ȡ���ݡ�����д������,�������ֻ��д�����ݡ����ܶ�ȡ���ݡ�
������������,���Խ�����Ϊ�ֽ������ַ���,�����ֽ������������ݵ�Ԫ��8λ���ֽ�,���ַ������������ݵ�Ԫ��16λ���ַ���
���մ�������,���Խ�����Ϊ�ڵ����ʹ�����,���нڵ�������ֱ�Ӵ�/��һ���ض���IO�豸(���̡������)��/д����,Ҳ��Ϊ�ͼ���,���������ǶԽڵ��������ӻ��װ,���ڼ����ݶ�/д���ܻ����Ч��,Ҳ��Ϊ������
Java�ṩ�˴���������֧��IO����,�±���������������бȽϳ��õ�һЩ�ࡣ����,��ɫ������dz������,�������е���̳������ǡ���ɫ������ǽڵ���,��ɫ������Ǵ�������
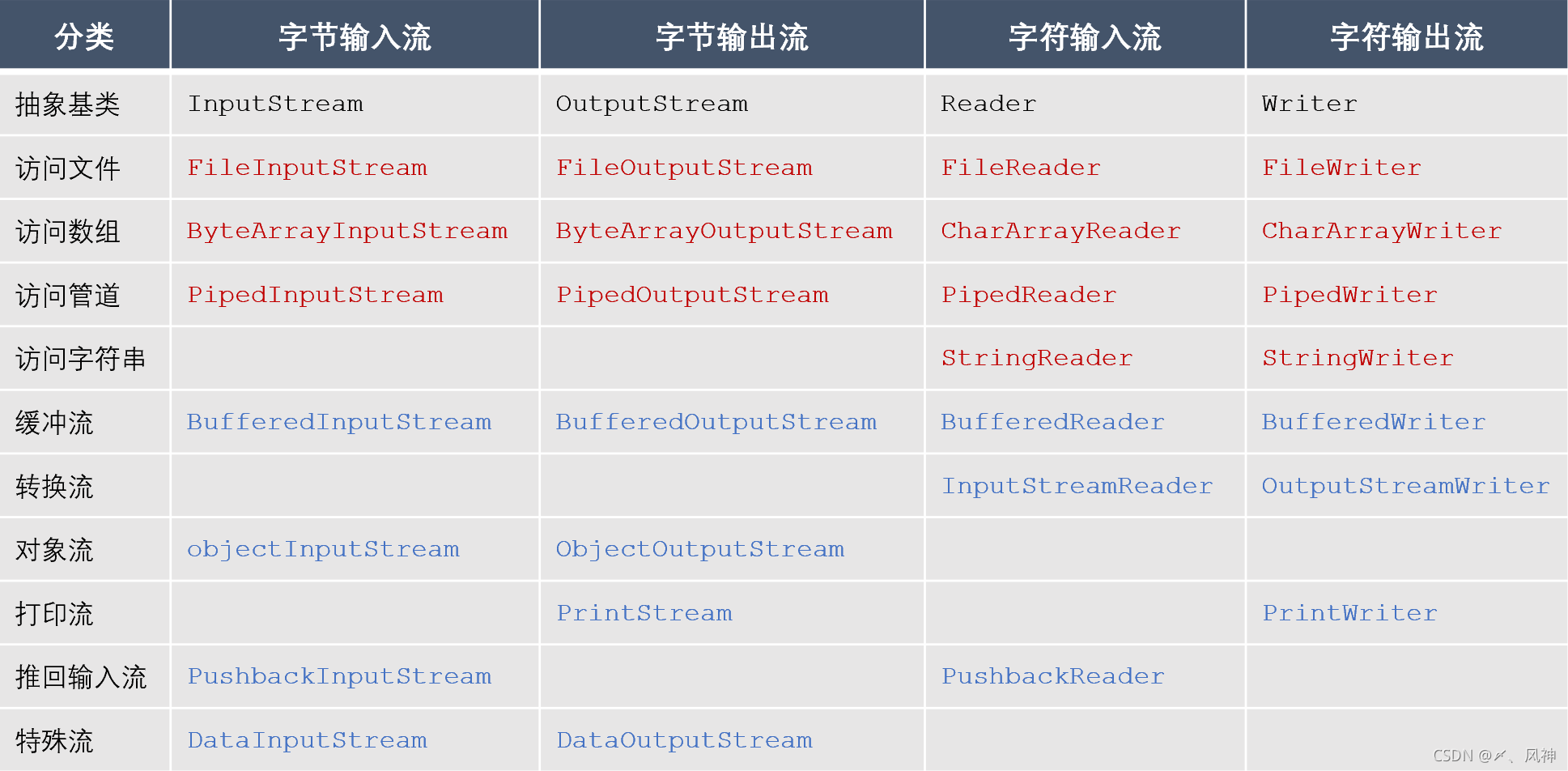
�����������������������������:
��File��ͷ���ļ������ڷ����ļ�;
��ByteArray/CharArray��ͷ�������ڷ����ڴ��е�����;
��Piped��ͷ�Ĺܵ������ڷ��ʹܵ�,ʵ�ֽ���֮���ͨ��;
��String��ͷ�������ڷ����ڴ��е��ַ���;
��Buffered��ͷ�Ļ�����,�����ڶ�д����ʱ�����ݽ��л���,�Լ���IO����;
InputStreamReader��InputStreamWriter��ת����,���ڽ��ֽ���ת��Ϊ�ַ���;
��Object��ͷ�����Ƕ�����,����ʵ�ֶ�������л�;
��Print��ͷ�����Ǵ�ӡ��,���ڼ�ӡ����;
��Pushback��ͷ�������ƻ�������,���ڽ��Ѷ���������ƻص�������,�Ӷ�ʵ���ٴζ�ȡ;
��Data��ͷ������������,���ڶ�дJava�������͵����ݡ�
2 ��ô������һ�����ļ�?
���
���ļ�,Ӧ����ֱ�ӽ��ļ��е�����ȫ����ȡ���ڴ���,���Բ��÷ִζ�ȡ�ķ�ʽ��
ʹ�û��������������ڲ�ά����һ��������,ͨ���뻺�����Ľ���,�������豸�Ľ���������ʹ�û���������ʱ,��ÿ�λ��ȡһ�����ݽ�����������,ÿ�ε��ö�ȡ����������ֱ�Ӵ��豸ȡֵ,���Ǵӻ�����ȡֵ,��������Ϊ��ʱ,������һ�ζ�ȡ����,��������������ʹ�û��������ʱ,ÿ�ε���д�뷽��������ֱ��д�뵽�豸,����д�뻺����,������������ʱ�����Զ�ˢ���豸��
ʹ��NIO��NIO�����ڴ�ӳ���ļ��ķ�ʽ����������/���,NIO���ļ����ļ���һ������ӳ�䵽�ڴ���,�����Ϳ���������ڴ�һ���������ļ���(���ַ�ʽģ���˲���ϵͳ�ϵ������ڴ�ĸ���),ͨ�����ַ�ʽ����������/����ȴ�ͳ������/���Ҫ��öࡣ
3 ˵˵NIO��ʵ��ԭ��
���
Java��NIO��Ҫ���������IJ������:Channel��Buffer��Selector��
������,���е�IO��NIO�ж���һ��Channel��ʼ,���ݿ��Դ�Channel����Buffer��,Ҳ���Դ�Bufferд��Channel�С�Channel�кü�������,���бȽϳ��õ���FileChannel��DatagramChannel��SocketChannel��ServerSocketChannel��,��Щͨ��������UDP��TCP����IO�Լ��ļ�IO��
Buffer��������һ�����д������,Ȼ����Դ��ж�ȡ���ݵ��ڴ档����ڴ汻��װ��NIO Buffer����,���ṩ��һ�鷽��,��������ķ��ʸÿ��ڴ档Java NIO��ؼ���Bufferʵ����CharBuffer��ByteBuffer��ShortBuffer��IntBuffer��LongBuffer��FloatBuffer��DoubleBuffer����ЩBuffer����������ͨ��IO���͵Ļ�����������,��byte��short��int��long��float��double��char��
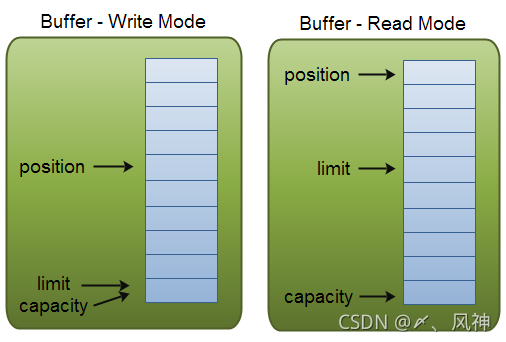
Buffer�������������Ҫ������,�ֱ���capacity��position��limit,����position��limit�ĺ���ȡ����Buffer���ڶ�ģʽ����дģʽ��������Buffer����ʲôģʽ,capacity�ĺ�������һ���ġ�
capacity:��Ϊһ���ڴ��,Buffer�и��̶������ֵ,����capacity��Bufferֻ��дcapacity������,һ��Buffer����,��Ҫ������ղ��ܼ���д��������д���ݡ�
position:��д���ݵ�Buffer��ʱ,position��ʾ��ǰ��λ�á���ʼ��positionֵΪ0����һ������д��Buffer��, position����ǰ�ƶ�����һ���ɲ������ݵ�Buffer��Ԫ��position����Ϊcapacity�C1������ȡ����ʱ,Ҳ�Ǵ�ij���ض�λ�ö�������Buffer��дģʽ�л�����ģʽ,position�ᱻ����Ϊ0������Buffer��position����ȡ����ʱ,position��ǰ�ƶ�����һ���ɶ���λ�á�
limit:��дģʽ��,Buffer��limit��ʾ�������Buffer��д��������,��ʱlimit����capacity�����л�Buffer����ģʽʱ, limit��ʾ������ܶ�����������,��ʱlimit�ᱻ���ó�дģʽ�µ�positionֵ��
��������֮��Ĺ�ϵ,����ͼ��ʾ:
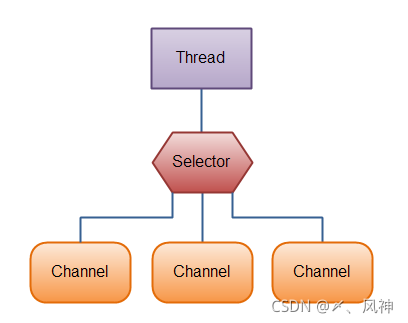
Selector�������̴߳������ Channel,������Ӧ�ô��˶������(ͨ��),��ÿ�����ӵ��������ܵ�,ʹ��Selector�ͻ�ܷ��㡣Ҫʹ��Selector,����Selectorע��Channel,Ȼ���������select()���������������һֱ������ij��ע���ͨ�����¼�������һ�������������,�߳̾Ϳ��Դ�����Щ�¼�,�¼������������ӽ���,���ݽ��յȡ�
������һ�����߳���ʹ��һ��Selector����3��Channel��ͼʾ:
��չ�Ķ�
Java NIO���ݲ���ϵͳ��ͬ, ���NIO�е�Selector�в�ͬ��ʵ��:
macosx:KQueueSelectorProvider
solaris:DevPollSelectorProvider
Linux:EPollSelectorProvider (Linux kernels >= 2.6)��PollSelectorProvider
windows:WindowsSelectorProvider
���Բ���Ҫ�ر�ָ��,Oracle JDK���Զ�ѡ����ʵ�Selector������������ض���Selector,������������,����: -Djava.nio.channels.spi.SelectorProvider=sun.nio.ch.EPollSelectorProvider��
JDK��Linux�Ѿ�Ĭ��ʹ��epoll��ʽ,����JDK��epoll���õ���ˮƽ����,����Netty��4.0.16��, NettyΪLinuxͨ��JNI�ķ�ʽ�ṩ��native socket transport��Netty����ʵ����epoll���ơ�
���ñ�Ե������ʽ;
netty epoll transport��¶�˸����nioû�е����ò���,�� TCP_CORK, SO_REUSEADDR�ȵ�;
C����,����GC,����synchronized��
4 ����һ��Java�����л��뷴���л�
���
���л����ƿ��Խ�����ת�����ֽ�����,��Щ�ֽ����п��Ա����ڴ�����,Ҳ�����������д���,������������Щ�ֽ������ٴλָ���ԭ���Ķ�������,��������л�(Serialize),��ָ��һ��Java����д��IO����,����ķ����л�(Deserialize),����ָ��IO���лָ���Java����
������Ҫ֧�����л�����,����������Ҫʵ��Serializable�ӿ�,�ýӿ���һ����ǽӿ�,��û���ṩ�κη���,ֻ�DZ��������ǿ������л���,Java�ĺܶ����Ѿ�ʵ����Serializable�ӿ�,���װ�ࡢString��Date�ȡ�
��Ҫʵ�����л�,����Ҫʹ�ö�����ObjectInputStream��ObjectOutputStream������,�����л�ʱ��Ҫ����ObjectOutputStream�����writeObject()����,������������С��ڷ����л�ʱ��Ҫ����ObjectInputStream�����readObject()����,���������лָ�Ϊ����
5 Serializable�ӿ�Ϊʲô��Ҫ����serialVersionUID����?
���
serialVersionUID�������л��İ汾,ͨ������������л��汾,�ڷ����л�ʱ,ֻҪ����������İ汾�͵�ǰ��İ汾һ��,���������ָ����ݵIJ���,�����׳����л��汾��һ�µĴ���
������������л��汾,�ڷ����л�ʱ���ܳ��ֳ�ͻ�����,����:
���������ʵ��,�������ʵ�����л�,�����ڴ�����;
���������,�������ӡ�ɾ�����������ij�Ա����;
�����л������ʵ��,���Ӵ����ϻָ���֮ǰ��������ݡ�
�ڵ�3���ָ����ݵ�ʱ��,��ǰ�����Ѿ������л������ݵĸ�ʽ�����˳�ͻ,���ܻᷢ���������벻�������⡣���������л��汾֮��,�����������������׳��쳣,����ʾ����ì�ܵĴ���,������ݵİ�ȫ�ԡ�
6 ����Java�Դ������л�֮��,�㻹�˽���Щ���л�����?
���
JSON:Ŀǰʹ�ñȽ�Ƶ���ĸ�ʽ�����ݹ���,��ֱ��,�ɶ��Ժ�,��jackson,gson,fastjson�ȵ�,�Ƚ������JSON�������ߵı��ֻ��DZȽϺõ�,��Щjson�������������ٶȳ�����һЩ�����Ƶ����л���ʽ��
Protobuf:һ���������л��ṹ�����ݵļ���,֧�ֶ�����������C++��Java�Լ�Python����,����ʹ�øü������־û����ݻ������л������紫������ݡ���Ƚ�һЩ������XML��������,�ü�����һ�������ص���Ǹ��ӽ�ʡ�ռ�(�Զ��������洢)���ٶȸ����Լ�����������Protobuf֧�ֵ�����������Խ���,��֧�ֳ������͡���������Ƶ������Ǵ����չ�ֲ�Э��(Presentation Layer),Ŀǰ��û��һ��ר��֧��Protobuf��RPC��ܡ�
Thrift:��Facebook��Դ�ṩ��һ��������,������RPC������,���������Ϊ�����㵱ǰ�����������ֲ�ʽ�������ԡ���ƽ̨����ͨѶ������ ����,Thrift�������������л�Э��,����һ��RPC��ܡ� �����JSON��XML����,Thrift�ڿռ俪���ͽ������������˱Ƚϴ������,���ڶ�����Ҫ��Ƚϸߵķֲ�ʽϵͳ,����һ�������RPC�����������������Thrift�����л���Ƕ�뵽Thrift�������, Thrift��ܱ�����û�������л��ͷ����л��ӿ�,�������Ѻ����������Э�鹲ͬʹ��(����HTTP)��
Avro:�ṩ�������л���ʽ,��JSON��ʽ����Binary��ʽ��Binary��ʽ�ڿռ俪���ͽ������ܷ�����Ժ�Protobuf����, JSON��ʽ������Խεĵ��ԡ� Avro֧�ֵ��������ͷdz��ḻ,����C++���������union���͡�Avro֧��JSON��ʽ��IDL��������Thrift��Protobuf��IDL(ʵ���),������֮����Ի�ת��Schema�����ڴ������ݵ�ͬʱ����,����JSON��������������,��ʹ��Avro�dz��ʺ϶�̬�������ԡ� Avro�����ļ��־û���ʱ��,һ����Schemaһ��洢,����Avro���л��ļ���������������������,���Էdz��ʺ�����Hive��Pig��MapReduce�ij־û����ݸ�ʽ�����ڲ�ͬ�汾��Schema,�ڽ���RPC���õ�ʱ��,����˺Ϳͻ��˿��������ֽζ�Schema���л���ȷ��,�����������յ����ݽ����ٶȡ�
7 �������JSON����,�����ʵ�ֶ�ʵ��������л�?
���
����ʹ��Javaԭ�������л�����,����Ч�ʱȽϵ�һЩ,�ʺ�С��Ŀ;
����ʹ��������һЩ���������,����Protobuf��Thrift��Avro�ȡ�