随着五周JAVA基础学习的结束,以及经历短暂的周考,周末两天的修整过后。本周就正式开始第二阶段的学习,本来课程的安排应该是先学习一到两周的前端。但是由于是和大数据班一起上的,所以课程有了些许的调整,先进行了数据库MYSQL的学习和JDBC。
JAVA中数据的存储问题:
- 变量,数组,对象,集合弊端:临时存储,存储数据的量级太小
- IO流弊端:存储的数据没有类型区分,没有安全措施,没有备份与恢复
数据库概念:
存储和管理数据仓库
数据库分类:
- 关系型数据库:Oracle、DB2、MySQL(重点)、SQL Server,特点:表与表建立关联关系 ?
- 非关系型数据库:ElastecSearch、MongoDB、Redis,一般使用哈希表,通过键值对存数据
数据库的基本操作:
#查询单个字段
SELECT COUNTRY_ID FROM t_countries;
#查询多个字段
select COUNTRY_ID,COUNTRY_NAME FROM t_countries;
#查询所有字段
select * FROM t_countries;
#查询所有字段
select * FROM t_employees;
#查询的字段设置别名
select COUNTRY_ID AS '国家' FROM t_countries;
#查询的字段去重
SELECT DISTINCT EMPLOYEE_ID FROM t_employees;
#查询的字段排序
SELECT DISTINCT EMPLOYEE_ID AS '编号' FROM t_employees ORDER BY EMPLOYEE_ID ASC;
#条件查询
SELECT EMPLOYEE_ID,FIRST_NAME,SALARY FROM t_employees WHERE SALARY=11000;
#查询薪资是11000并且提成是0.30的员工信息(编号、名字、薪资)
SELECT EMPLOYEE_ID,FIRST_NAME,SALARY FROM t_employees WHERE SALARY=11000 AND COMMISSION_PCT=0.3;
#查询员工的薪资在6000~10000之间的员工信息(编号,名字,薪资)
select EMPLOYEE_ID,FIRST_NAME,SALARY FROM t_employees WHERE SALARY>=6000 AND SALARY<=11000;
#查询员工的薪资在6000~10000之间的员工信息(编号,名字,薪资)
SELECT EMPLOYEE_ID,FIRST_NAME,SALARY from t_employees WHERE SALARY BETWEEN 6000 AND 10000;
#查询没有提成的员工信息(编号,名字,薪资 , 提成)
SELECT EMPLOYEE_ID,FIRST_NAME,SALARY,COMMISSION_PCT from t_employees WHERE COMMISSION_PCT is NULL;
#查询部门编号为70、80、90的员工信息(编号,名字,薪资 , 部门编号)
SELECT EMPLOYEE_ID,FIRST_NAME,SALARY,DEPARTMENT_ID FROM t_employees WHERE DEPARTMENT_ID in(70,80,90);
#查询名字以"L"开头的员工信息(编号,名字,薪资 , 部门编号)
SELECT EMPLOYEE_ID,FIRST_NAME,SALARY,DEPARTMENT_ID from t_employees WHERE FIRST_NAME LIKE 'L%';
#查询名字以"L"开头并且长度为4的员工信息(编号,名字,薪资 , 部门编号)
SELECT EMPLOYEE_ID,FIRST_NAME,SALARY,DEPARTMENT_ID from t_employees WHERE FIRST_NAME LIKE 'L___';
#查询员工信息(编号,名字,薪资 , 薪资级别<对应条件表达式生成>)
SELECT EMPLOYEE_ID,FIRST_NAME,SALARY,
(CASE
WHEN SALARY>=8000 THEN 'A'
WHEN SALARY>=6000 AND SALARY<8000 THEN 'B'
WHEN SALARY>=4000 AND SALARY<6000 THEN 'C'
WHEN SALARY>=3000 AND SALARY<4000 THEN 'D'
ELSE 'E'
END) AS '薪资级别'
FROM t_employees;
#查询当前时间
SELECT SYSDATE();
SELECT NOW();
SELECT CURDATE();
SELECT CURTIME();
#拼接内容
SELECT CONCAT('日期:',CURDATE(),' ',CURTIME()) as "当前日期";
#字符串替换
SELECT INSERT('这是一个数据库',3,2,'Mysql');
#指定内容转换为小写
SELECT LOWER('MYSQL');
#指定内容转换为大写
SELECT UPPER('mysql');
#指定内容截取
SELECT SUBSTRING('这是一个数据库' ,5,3);
#统计所有员工每月的工资总和
SELECT SUM(SALARY) from t_employees ;
#统计所有员工每月的平均工资
SELECT AVG(SALARY) FROM t_employees;
#统计所有员工中月薪最高的工资
SELECT MAX(SALARY) FROM t_employees;
#统计所有员工中月薪最低的工资
SELECT MIN(SALARY) FROM t_employees;
#统计员工总数
SELECT COUNT(*) FROM t_employees;
#统计有提成的员工人数
SELECT COUNT(COMMISSION_PCT) FROM t_employees;
#思路:
#1.按照部门编号进行分组(分组依据是 department_id)
#2.再针对各部门的人数进行统计(count)
SELECT DEPARTMENT_ID,COUNT(*) FROM t_employees GROUP BY DEPARTMENT_ID;
#思路:
#1.按照部门编号进行分组(分组依据department_id)。
#2.针对每个部门进行平均工资统计(avg)。
SELECT DEPARTMENT_ID,AVG(SALARY) FROM t_employees GROUP BY DEPARTMENT_ID;
#思路:
#1.按照部门编号进行分组(分组依据 department_id)。
#2.按照岗位名称进行分组(分组依据 job_id)。
#3.针对每个部门中的各个岗位进行人数统计(count)。
SELECT DEPARTMENT_ID,JOB_ID,COUNT(*) FROM t_employees GROUP BY DEPARTMENT_ID,JOB_ID;
#查询各个部门id、总人数、first_name
SELECT DEPARTMENT_ID,COUNT(*),FIRST_NAME FROM t_employees GROUP BY DEPARTMENT_ID;#ERRORS
#[注:分组查询中,select显示的列只能是分组依据列,或者聚合函数列,不能出现其他列。]
#统计60、70、90号部门的最高工资
#思路:
#1). 确定分组依据(department_id)
#2). 对分组后的数据,过滤出部门编号是60、70、90信息
#3). max()函数处理
SELECT DEPARTMENT_ID,MAX(SALARY) FROM t_employees GROUP BY DEPARTMENT_ID HAVING DEPARTMENT_ID in (60,70,90);
#查询表中前五名员工的所有信息
SELECT * FROM t_employees LIMIT 0,5;
#查询表中第2组五名员工的所有信息
SELECT * FROM t_employees LIMIT 5,5;
#查询表中从第四条开始,查询 10 行
SELECT * FROM t_employees LIMIT 4,10;
#分页查询:一页显示 10 条,一共查询三页
#思路:第一页是从 0开始,显示 10 条
SELECT * FROM t_employees LIMIT 0,10;
SELECT * FROM t_employees LIMIT 10,10;
SELECT * FROM t_employees LIMIT 20,10;今天上半天班里的同学都在捣鼓安装数据库,不是缺文件,就是环境配置的不对,折腾一上午,下午就说了一下的数据库中的基础查询操作。
今日份作业:
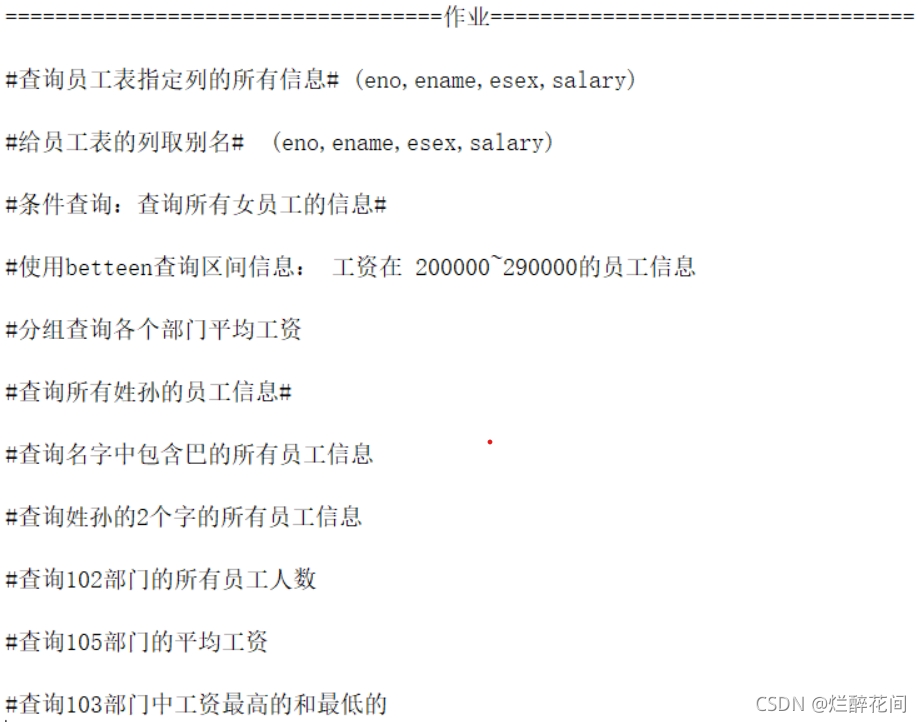
?