????????对于每个线程,存在成员current->bio_list来放置本线程发送的BIO。这里有三条路径发送IO到底层:
- 路径一,使能了plug/unplug机制,此时会等待plug池中存取足够的IO后统一往调度器插入IO,并选取IO下发;
- 路径二,没有使能plug/unplug机制,此时会将IO插入调度器中,并选取IO下发;
- 路径三,跳过调度层,直接下发IO;
 ?
?
????????简单来讲,这里有三条链:current->bio_list存储在当前线程的所有bio; plug->mq_list使能plug/unplug机制时存放在缓存池的bio;若定义IO调度层,IO请求会发送到scheduler list中;若没有定义IO调度层,IO请求会发送到ctx->rq_lists。
????????上述下发路径是IO提交下发的简述,代码流程如下:
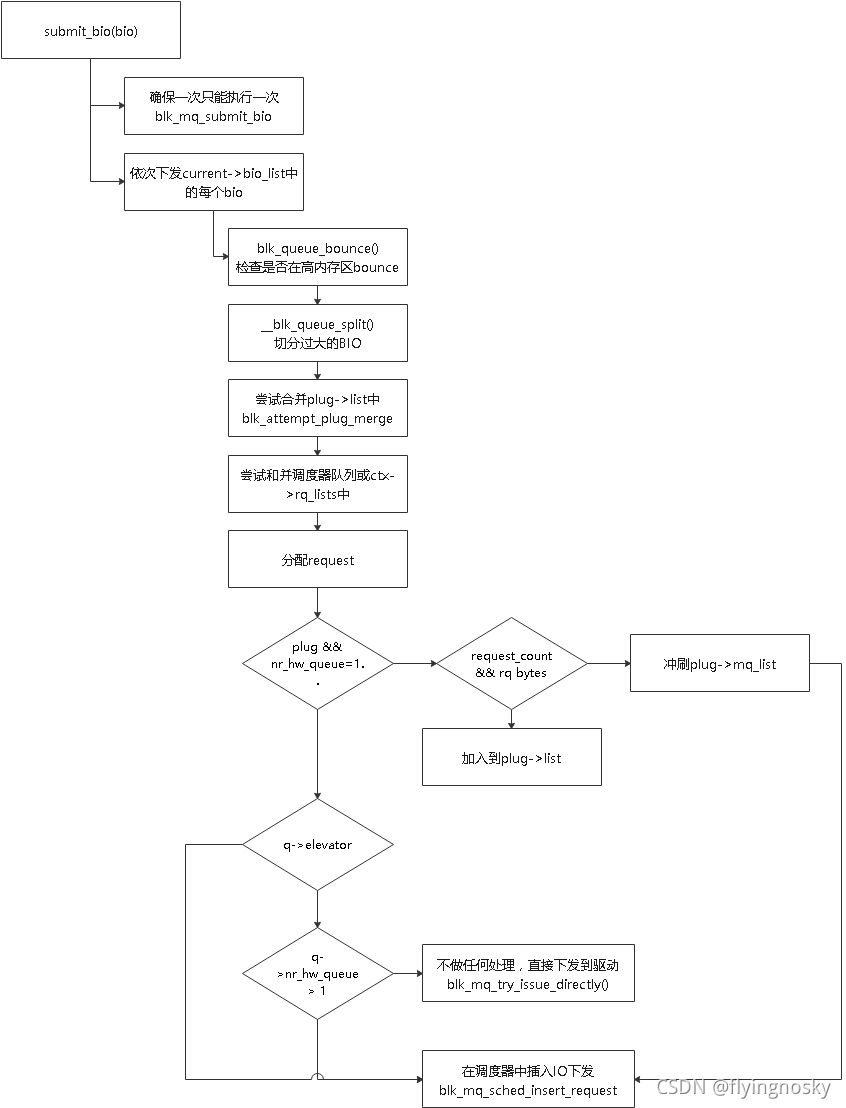
?
这里过程如下:
- 每个线程若已经在执行blk_mq_submit_bio(),将新下发BIO链入到线程current->bio_list;
- 依次处理current->list中的每个bio;
- 若bio中存在数据在高端内存区,在低端内存区分配内存,将高端内存区数据拷贝到新分配的内存区,称为bounce过程,后面单独一节介绍;
- 检查请求队列中的bio,若过大进行切分,称BIO的切分;
- 尝试将bio合并到plug->mq_list中,然后尝试合并到IO调度层链表或ctx->rq_lists中;
- 若没有合并,分配新的request;
- 若定义plug,且没达到冲刷数目,加入到plug->mq_list;若达到冲刷数目,将冲刷下发(plug/unplug机制);
- 若定义IO调度器,往IO调度器中插入新的request(对于机械硬盘,通过IO调度层座合并和排序,有利于提高性能);
- 若 没有定义IO调度器,可以直接下发(对于较快的硬盘如nvme盘,进入调度层可能会浪费时间,跳过IO调度层有利于性能提升);
?后续章节初步估计将上述过程分为以下几个部分做详细描述:
(1)bounce过程
(2)bio的切分和合并
(3)IO请求和tag的分配
(4)plug/unplug机制
(5)IO调度器
(4)其他
?