����Ŀ¼
??�������,���Ʋ�����������������(
1.ԭ������
2.�ɼ�����
3.������);Ҫ����������������������������,���ܺܶ���Ҳ֪������������
JMM �ڴ�ģ��,�����ж�����֪��
JMM �ڴ�ģ������ν����������������?���ľʹ�ԭ��������ϸϸ���⡣
??�ڡ�������̡����,�Ѿ��н��ܵ� 1.�����ԭ���ṹ ? 2.MESI����һ����Э��������ƪ���ݽ��ܵ�Ҳֻ����Ӳ��CPU�����ϵĽ���������� Java ��������,�������ǽ�����Ҫ���ܵ� JMM �ڴ�ģ��,JMM �ڴ�ģ�;��ǻ��� CPU �ײ�ܹ���һ��������(��:�ο�Ӳ�����������ͬ������)
1.JMM �ڴ�ģ��
??Java�ڴ�ģ��(Java Memory Model,���:JMM)��һ�ֳ���ĸ���,������ʵ������������Χ�ƶ��߳��е�ԭ����,�����ԡ��ɼ�����������չ������
??JMMģ��,��������һ������淶,ͨ������淶�����˳����и�������(����ʵ���ֶ�,��̬�ֶκ�����������Ԫ��)�ķ��ʷ�ʽ��JVM���г����ʵ�����߳�,��ÿ���̴߳���ʱJVM����Ϊ�䴴��һ�������ڴ�(��Щ�ط���Ϊջ�ռ�),���ڴ洢�߳�˽�е�����,��Java�ڴ�ģ���й涨���б������洢�����ڴ�,���ڴ��ǹ����ڴ�����,�����̶߳����Է���,���̶߳Ա����IJ���(��ȡ��ֵ��)�����ڹ����ڴ��н���,����Ҫ�����������ڴ��������Լ�(��ǰ�߳�)�Ĺ����ڴ��ռ�,Ȼ���ڹ����ڴ��жԱ������в���,������ɺ����������ӹ����ڴ�д�����ڴ�,����ֱ�Ӳ������ڴ��еı���,�����ڴ��д洢�����ڴ��еı�������������ǰ��˵��,�����ڴ���ÿ���̵߳�˽����������,��˲�ͬ���̼߳������ʶԷ��Ĺ����ڴ�,�̼߳��ͨ��(��ֵ)����ͨ�����ڴ�����ɡ�
��ʾ:JMM �ڴ�ģ��,��JVM�ڴ�����ģ�� û�а�ëǮ��ϵ,�˴���������
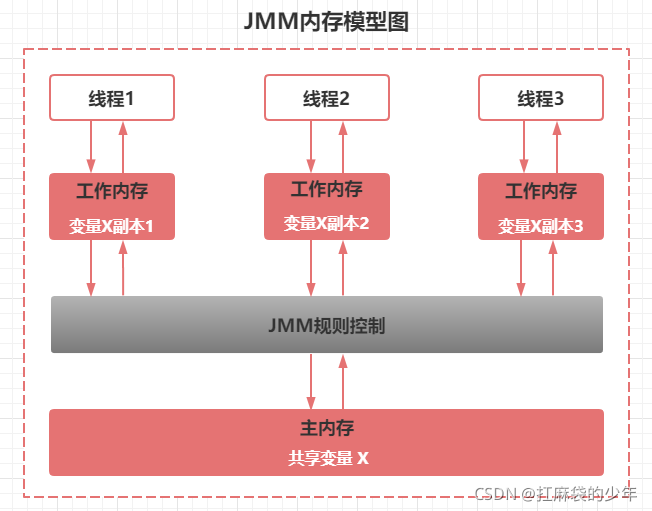
??�����ڴ��ԭ��,������CPU������ÿ���߳�������ʱ,�����Լ�������һ�������ڴ档
??��ͬ�汾JDK(Linux��Windows��Mac)�Ĵ���,����ʵ�� Java �ڸ�������ϵͳ�������С�һ����д,��������(Write Once,Run Anywhere),JMM �ڴ�ģ��Ҳ���Ź�����û�Ĺ�����JMMģ�ͱ�����Ҳ��Ϊ�����εײ�IJ���ϵͳ��Ӳ���ܹ���ͬ,��ͬ����ϵͳ,��������,���εײ�ľ���ʵ�ֵIJ�ͬ����Oracle��˾������ JVM�����ȥ����(JMM��һ��淶,����Ϊ�����εײ�IJ�ͬ)��
1.���ڴ�
??���ڴ���Ҫ�洢����Javaʵ������,�����̴߳�����ʵ������������ڴ���,���ܸ�ʵ�������dz�Ա�������Ƿ����еı��ر���(Ҳ�ƾֲ�����),��ȻҲ�����˹���������Ϣ����������̬�����������ǹ�����������,�����̶߳�ͬһ���������з��ʿ��ܻᷢ���̰߳�ȫ���⡣
2.�����ڴ�
??�����ڴ���Ҫ�洢��ǰ���������б��ر�����Ϣ(�����ڴ��д洢�����ڴ��еı�����������),ÿ���߳�ֻ�ܷ����Լ��Ĺ����ڴ�,���߳��еı��ر����������߳��Dz��ɼ���,�����������߳�ִ�е���ͬһ�δ���,����Ҳ��������Լ��Ĺ����ڴ��д������ڵ�ǰ�̵߳ı��ر���,��ȻҲ�������ֽ����к�ָʾ�������Native��������Ϣ��ע�����ڹ����ڴ���ÿ���̵߳�˽������,�̼߳�������ʹ����ڴ�,��˴洢�ڹ����ڴ�����ݲ������̰߳�ȫ���⡣
3.JMM �̲߳����ڴ�����������涨
- �����߳������ڴ�:�̶߳Թ������������в������������Լ��Ĺ����ڴ��н���,����ֱ�Ӵ����ڴ��ж�д;
- �����̼߳乤���ڴ�:��ͬ�߳�֮����ֱ�ӷ��������̹߳����ڴ��еı���,�̼߳����ֵ�Ĵ�����Ҫ�������ڴ�����ɡ�
??JMM �ڴ�ģ��,�ȼ��ܵ����������ν�����߳��е�ԭ�������ɼ���������������,�ڽ��������ܵ�����������,������ϸ����,������������˽���
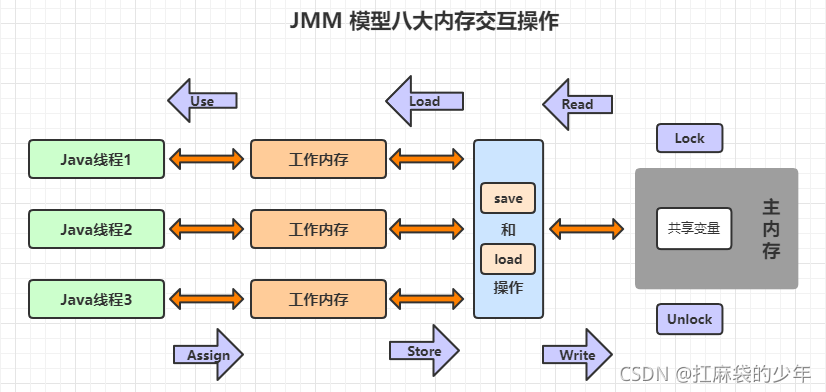
4.JMM ģ�Ͱ˴��ڴ潻��ָ��
??�� 8 ��ָ��,����ԭ�Ӳ���!!!
| ָ�� | ���� |
|---|---|
| lock(����) | ���������ڴ�ı���,��һ���������Ϊһ���̶߳�ռ״̬ |
| read(��ȡ) | ���������ڴ�ı���,��һ������ֵ�����ڴ洫�䵽�̵߳Ĺ����ڴ���,�Ա�����load����ʹ�� |
| load(����) | �����ڹ����ڴ�ı���,����read���������ڴ��еõ��ı���ֵ���빤���ڴ�ı��������� |
| use(ʹ��) | �����ڹ����ڴ�ı���,�ѹ����ڴ��е�һ������ֵ���ݸ�ִ������ |
| assign(��ֵ) | �����ڹ����ڴ�ı���,����һ����ִ��������յ���ֵ���������ڴ�ı��� |
| store(�洢) | �����ڹ����ڴ�ı���,�ѹ����ڴ��е�һ��������ֵ���͵����ڴ���,�Ա�����write�IJ��� |
| write(д��) | �����ڹ����ڴ�ı���,����store�����ӹ����ڴ��е�һ��������ֵ���͵����ڴ�ı����� |
| unlock(����) | ���������ڴ�ı���,��һ����������״̬�ı����ͷų���,�ͷź�ı����ſ��Ա������߳����� |
5.JMM ģ���ڴ潻������
??��һ�����������ڴ��и��Ƶ������ڴ���,����Ҫ��˳���ִ�� read �� load ����,����ѱ����ӹ����ڴ���ͬ�������ڴ���,����Ҫ��˳���ִ�� store �� write �������� JMM �ڴ�ģ��ֻҪ������8�����(ԭ�Ӳ���)���밴˳��ִ��,��û�б�֤����������ִ�С�
6.JMM ģ���ڴ�ͬ������
- ������һ���߳���ԭ���(û�з������κ� assign ����)�����ݴӹ����ڴ�ͬ�������ڴ���;
- һ���µı���ֻ�������ڴ��е���,�������ڹ����ڴ���ֱ��ʹ��һ��δ����ʼ��(load ���� assign)�ı����������Ƕ�һ������ʵʩuse �� store ����֮ǰ,���������� assign �� load ����;
- һ��������ͬһʱ��ֻ����һ���̶߳������ lock ����,�� lock �������Ա�ͬһ�߳��ظ�ִ�ж��,���ִ�� lock ��,ֻ��ִ����ͬ������ unlock ����,�����Żᱻ������lock �� unlock ����ɶԳ���;
- �����һ������ִ�� lock ����,������չ����ڴ��д˱�����ֵ,��ִ������ʹ���������֮ǰ��Ҫ����ִ�� load �� assign ������ʼ��������ֵ;
- ���һ����������û�б� lock ��������,����������ִ�� unlock ����;Ҳ������ȥ unlock һ���������߳������ı���;
- ��һ������ִ�� unlock ����֮ǰ,�����ȰѴ˱���ͬ�������ڴ���(ִ�� store �� write ����)��
2.���߳���������
??��������:ԭ�������ɼ����������������������,Ϊʲô���������,������Ϊ�߳����߳�֮��IJ���,��û�а취���֪,Ҫ�����֪,����Ҫ�õ� MESI ����һ����Э���ļӳ��ˡ�
??������Ӳ������,����������߳���������!!!
1.ԭ����
??ԭ����ָ����һ�������Dz����жϵ�,��ʹ���ڶ��̻߳�����,һ������һ����ʼ�Ͳ��ᱻ�����߳�Ӱ�졣
??��Java��,���������������ı�������ȡ����ֵ����,����ԭ���Բ�����
x=10; // ԭ���Բ���(�Ķ�ȡ�������ָ�ֵ������)
y = x; // ����֮������ֵ,����ԭ�Ӳ���
x++; // �Ա������м������,����ԭ�Ӳ���
x = x+1; // �Ա������м������,����ԭ�Ӳ���
??�е�Ҫע�����: ���� 32 λϵͳ����˵,long �������ݺ� double ��������(���ڻ����������� byte��short��int��float��boolean��char ��д��ԭ�Ӳ���),���ǵĶ�д����ԭ���Ե�,Ҳ����˵������������߳�ͬʱ�� long ���ͻ��� double ���͵����ݽ��ж�д,�Ǵ�������ŵġ���Ϊ���� 32 λ�������˵,ÿ��ԭ�Ӷ�д�� 32 λ��,�� long �� double ����64λ�Ĵ洢��Ԫ,�����ᵼ��һ���߳���дʱ,������ǰ 32 λ��ԭ�Ӳ�����,�ֵ� B �̶߳�ȡʱ,ǡ��ֻ��ȡ���˺� 32 λ������,�������ܻ��ȡ��һ���ȷ�ԭֵ�ֲ����߳���ֵ�ı���,�������ǡ��������������ֵ,�� 64 λ���ݱ������̷ֳ߳������ζ�ȡ����Ҳ����̫����,��Ϊ��ȡ�������������������Ƚ��ټ�,������Ŀǰ�����õ��������,��������64λ�����ݵĶ�д������Ϊԭ�Ӳ�����ִ��,��˶���������ⲻ��̫����,֪����ô���¼�������JDK 9 ��ʼ,Oracle�ٷ��Ѳ��ٷ��� 32 λ�汾,ֻ�� 64 λ������
1.ԭ��������
??һ����̬ȫ�ֱ��� int count,���� 10 ���߳�,ÿ���߳�ִ��1000�� count++����ʵ����,������ 10 ���߳��Ժ��ַ�ʽ,���ֲ�������,���� count ֵ��Ӧ��Ϊ 10000��
/**
* ԭ����
*/
public class AtomicTest {
// ��������:count
private static int count = 0;
public static void main(String[] args) {
for (int i = 0; i < 10; i++) {
new Thread(()->{
for (int j = 0; j < 1000; j++) {
count++;
}
}).start();
}
//��֤�����߳�ִ�����(��������1sҲ��)
while(Thread.activeCount()>2){
Thread.yield();
}
System.out.println("ִ�н��:"+count);
}
}
??����ʵ�������,count ֵ���ն���С��10000������ijЩ��Ե�ɺ�֮��,Ҳ����� count = 10000 �����,��������»�С��10000����
2.����ԭ��
??������Ϊ count++ �ڶ��̻߳�����,����һ��ԭ���Բ������µ�!!!count++ �ڴ���ִ�й����з�Ϊ2��: 1. �����ڴ���� count �����������ڴ�;?2. ִ�� +1 ������
??10���̼߳�����ɺ�,������������Լ��̵߳Ĺ����ڴ���,���߳�1д�뵽���ڴ��,�߳�2д��ʱ,���ܻὫ�߳�1д��ĸ��ǵ�,�Ӷ��������Ľ�� < 10000��
3.�������
??������:1. ʹ�� synchronized �����ƽ�� ?2. ʹ�� Lock �����ƽ�� ? 3.ʹ�� AtomicInteger ԭ�Ӳ������� ?4.(���Ƽ�)ʹ�� Unsafe ���е� monitorEnter �� monitorExit ����,�ֶ��ļ�����������
??1.�� synchronized ���������ƶ��߳̿����ij���,���̻߳�ִ��,�߳�1ֻ���ڻ������,����ִ��ҵ��������;�߳�2���߳�3 ֻ�ܵȴ��߳� t1 �����ͷ�,t1 �ͷź�,t2��t3��������,˭����˭ִ�С��������ܹ���֤��һʱ��ֻ��һ���̷߳��ʸô����(�� synchronized �ؼ��ּ�����,ʹ�� JUC �е� Lock ��Ҳ���Խ��ԭ����,JUC �ں���ϵ�����л��н���,��ַ:�����ڴ�,δ��д)
??2.�� Lock ����ͬ synchronized ���ؼ���ԭ����ͬ��(JUC �е� Lock ��Ҳ���Խ��ԭ����,JUC �ں���ϵ�����л��н���,��ַ:�����ڴ�,δ��д)
??3.ʹ�� Atomic ԭ������Atomic ԭ�Ӳ�����,Ҳ�� JUC ����Ϊ�����ṩ��һ�ֽ�����������ĵײ��ǻ��� Unsafe ħ����ʵ�ֵ�,Unsafe ħ������Կ�� JVM ֱ�Ӷ��ڴ���в�����Unsafe ��Ҳ���ں���ϵ�����н���,��ַ:�����ڴ�,δ��д��ԭ�Ӳ�����,��ֻ�� AtomicInteger ��,�� Atomic ����һ����12����,����ͼ��ʾ,���� Atomic ԭ�Ӳ�����,��������˽�һ�°�,��ַ:�����ڴ�,δ��д
??4.ʹ�� Unsafe ���е� monitorEnter �� monitorExit ����,�ֶ��ļ��������������ַ�ʽʹ�� Unsafe ħ������Ϊ�����ṩ�� monitorEnter �� monitorExit ����,�ƹ� JVM �����ֱ�Ӷ��ڴ���в�����Ҳ�ܽ��ԭ��������,���Dz�����ʹ��!!!��Ϊ Unsafe ��̫����ȫ,�㲻�÷��ջ�ܴ��!!!
1.synchronized ��
/**
* synchronized ������ ��� ԭ��������
*/
public class AtomicTest {
// ��������:count
private static int count = 0;
public static void main(String[] args) {
for (int i = 0; i < 10; i++) {
new Thread(()->{
for (int j = 0; j < 1000; j++) {
synchronized (AtomicTest.class) { // ���� synchronized
count++;
}
}
}).start();
}
//��֤�����߳�ִ�����(��������1sҲ��)
while(Thread.activeCount()>2){
Thread.yield();
}
System.out.println("ִ�н��:"+count);
}
}
2.Lock ��
/**
* Lock ������ ��� ԭ��������
*/
public class AtomicTest {
// ��������:count
private static int count = 0;
// ������
private static Lock lock = new ReentrantLock();
public static void main(String[] args) {
for (int i = 0; i < 10; i++) {
new Thread(()->{
for (int j = 0; j < 1000; j++) {
lock.lock(); // ����
count++;
lock.unlock(); // ����
}
}).start();
}
//��֤�����߳�ִ�����(��������1sҲ��)
while(Thread.activeCount()>2){
Thread.yield();
}
System.out.println("ִ�н��:"+count);
}
}
3.(�Ƽ�)Atomic ԭ����
/**
* Atomic ԭ�Ӳ����� ��� ԭ��������
*/
public class AtomicTest {
// ʹ��AtomicIntegerԭ����
private static AtomicInteger count = new AtomicInteger(0);
public static void main(String[] args) {
for (int i = 0; i < 10; i++) {
new Thread(()->{
for (int j = 0; j < 1000; j++) {
count.getAndIncrement(); // getAndIncrement():��ȡԭֵ,��+1
}
}).start();
}
//��֤�����߳�ִ�����(��������1sҲ��)
while(Thread.activeCount()>2){
Thread.yield();
}
System.out.println("ִ�н��:"+count);
}
}
4.(���Ƽ�)Unafe ���е� monitorEnter �� monitorExit ����,�ֶ�����������
/**
* ��ȡ Unsafe ʵ��(Unsafe���ȫ,����ͨ�� new �ķ�ʽ����,ֻ��ͨ������ķ�ʽ��ȡ)
*/
public class UnsafeInstance {
public static Unsafe reflectGetUnsafe() {
try {
Field field = Unsafe.class.getDeclaredField("theUnsafe");
field.setAccessible(true);
return (Unsafe) field.get(null);
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
}
/**
* Unsafe���ֶ����������� ��� ԭ��������
*/
public class AtomicTest {
// ��������:count
private static int count = 0;
private static Object lock = new Object();
public static void main(String[] args) {
for (int i = 0; i < 2; i++) {
new Thread(()->{
for (int j = 0; j < 1000; j++) {
// ����
UnsafeInstance.reflectGetUnsafe().monitorEnter(lock);
// ҵ��������
count++;
// ����
UnsafeInstance.reflectGetUnsafe().monitorExit(lock);
}
}).start();
}
//��֤�����߳�ִ�����(��������1sҲ��)
while(Thread.activeCount()>2){
Thread.yield();
}
System.out.println("ִ�н��:"+count);
}
}
4.���ܶԱ�
??(JDK 6��ǰ)ʹ�� synchronized ��,������������,���ڱ��������������,Ч�ʵ���;
??(JDK 6�Ժ�)Դ�벿�ֶ� synchronized �ؼ��ֽ����˱Ƚϴ���Ż�[�� synchronized ������������ƫ������������������������ 4����״̬],���ڼ��������,Ч�ʿ϶����ǻ����ۿ���JDK 6 �� synchronzied ��������Ż���?�������˽�:�����ڴ�,δ��д
??�����д���10���߳�,���ӵ� 2w ����5w����
??JDK 8 ������:synchronized ��ʱ 1129ms��2387ms,Atomicԭ������ʱ 949ms��2339ms ,��Ϊ JDK 6 �� synchronzied �����Ż�,��ʱ���;
??JDK 6������,ʹ�� synchronzied ��������������,synchronized ��ʱ 2235ms��4700ms,Atomicԭ������ʱ 949ms��2339ms��Atomic ԭ������ synchronzied Ч�ʿ� 50% ������
??���ԭ��������,JDK 6��ǰ�����Ƽ�ʹ��ԭ�Ӳ����� ,JDK6 ���Ժ�汾,Ч�ʾͲ����,����ѡ��ɡ�����������ҵ����õĶ��� JDK 8 ���ϰ汾�˰�,���Ա�ʵ���������ο�һ�°ɡ�
2.�ɼ���
??�ɼ���,ָ���ǵ�һ���߳�����ij������������ֵ,�����߳��Ƿ��ܹ����ϵ�֪����ĵ�ֵ�����ڴ��г�����˵,�ɼ����Dz����ڵ�,��Ϊ�������κ�һ������������ij��������ֵ,�����IJ����ж��ܶ�ȡ�������ֵ,�������Ĺ�����ֵ��
??���ڶ��̻߳����пɾͲ�һ����,ǰ�����Ƿ�����,�����̶߳Թ��������IJ��������߳̿��������ԵĹ����ڴ���в������д�ص����ڴ��е�,��Ϳ��ܴ���һ���߳� A ���˹������� x ��ֵ,��δд�����ڴ�ʱ,����һ���߳� B �ֶ����ڴ���ͬһ���������� x ���в���,����ʱ�߳� A �����ڴ��еĹ������� x ���߳� B ��˵�����ɼ�,���ֹ����ڴ������ڴ�ͬ���ӳ����������˿ɼ�������������ָ�������Լ��������Ż�Ҳ���ܵ��¿ɼ�������,ͨ��ǰ��ķ���,����֪�������DZ������Ż����Ǵ������Ż�����������,�ڶ��̻߳�����,ȷʵ�ᵼ�³�������ִ�е�����,�Ӷ�Ҳ�͵��¿ɼ������⡣
1.�ɼ�������
??�������� initFlag ,Ĭ��ֵΪ false������ 2 ���߳�,�߳�1��ִ��,���� 1s ��ִ���߳�2,��֤�߳�1�Ƚ��� while ѭ��,�߳�2 �Ĺ������� initFlag ֵ��,�߳�1��Ϊ����ʱ��֪�� initFlag ֵ�ı仯,�����߳� 1 ��������
/**
* �ɼ���
*/
public class VisibilityTest {
// ��������initFlag
private boolean initFlag = false;
// load()����
public void load() {
int i = 0;
while (!initFlag) {
i++;
}
System.out.println( Thread.currentThread().getName() + ":��̽��initFlag����ֵ�ı�,i=" + i);
}
// refresh()����
public void refresh() {
this.initFlag = true;
System.out.println(Thread.currentThread().getName() + ":����initFlagֵ");
}
public static void main(String[] args) throws InterruptedException {
VisibilityTest test = new VisibilityTest();
// �߳�1
new Thread(test::load, "�߳�1").start();
// ����1s,�����߳�1��ִ��
TimeUnit.SECONDS.sleep(1);
// �߳�2
new Thread(test::refresh, "�߳�2").start();
}
}
??�������к�,load �����ᴦ�� while ѭ����,˯�� 1s ���߳�2ִ��,���Ĺ������� initFlag ��ֵ,�ĺ��������dz�����뷨,�߳� 1 ���� initFlag ����ֵ�ı�,while() ѭ��������,Ӧ��ֹͣ������
??��������ԸΥ,��Ȼ�߳�2�������,�� initFlag �����ɹ�,�߳� 1 ȴ��������֪ initFlag �����ı仯,����Ҳ��û��ֹͣ��������
2.����ԭ��
??����� JMM �ڴ�ģ���й�ϵ���߳� 1 ���߳� 2 ���Ὣ�������� initFlag ��ֵ����һ�ݵ����ԵĹ����ڴ���,�߳�������ʱʹ�õĶ��Ǹ��Թ����ڴ��е�ֵ����Ȼ�߳� 2 �� initFlag ֵ������,��Ҳ�����ڽ��Լ������ڴ��е�ֵ��������,��û�н����д�����ڴ�,�����߳�1�����ܹ���ʱ���� initFlag ����ֵ�ı仯,�߳� 1 Ҳ�Ͳ���ֹͣ�����ˡ�
??ÿ���̹߳����ڴ��еı���,ֻ���Լ��߳̿ɼ�,�������̶߳����ɼ�,����Ƕ��̵߳Ŀɼ�����������ɶʱ��ֹͣ��?�Ϳ��߳� 2 �����ڴ��е� initFlag ����ֵ��ʱ�ܹ���д�����ڴ���,���ʱ��Ͳ��ǿɿص��ˡ�
3.�������
??������:1. ʹ�� synchronized �����ƽ�� ? 2.ʹ�� volatile �ؼ���
??�� synchronized ���������ƶ��߳̿����ij���,���̻߳�ִ��,�߳�1ֻ���ڻ������,����ִ��ҵ��������;�߳�2���߳�3 ֻ�ܵȴ��߳� t1 �����ͷ�,t1 �ͷź�,t2��t3��������,˭����˭ִ�С��������ܹ���֤��һʱ��ֻ��һ���̷߳��ʸô������
??2���߳����ڶԹ��������Ķ�ȡ����д�붼���м�������,��Ϊ�̶߳�Ӧ�Ķ���ͬһ��������,��������ų⡣���Ǿ���������Ҳ����˵���ڴ�ɼ��Ե�����ʵ����������������� JMM ģ���� synchronized �������涨:
- �߳̽���ǰ,����ѹ�������������ֵˢ�µ����ڴ���;
- �̼߳���ʱ,����չ����ڴ��й���������ֵ,�Ӷ���ʹ�ù�������ʱ,��Ҫ�����ڴ������¶�ȡ���µ�ֵ(�����������Ҫͳͬһ����)
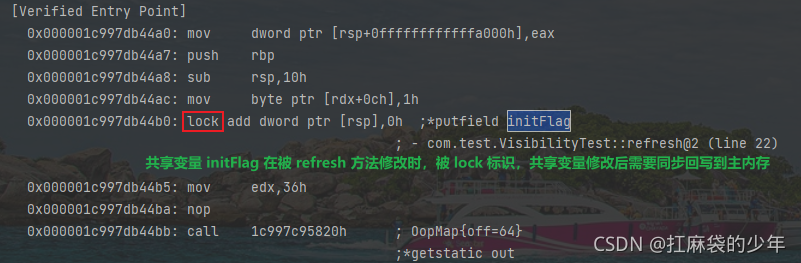
??�� volatile �ؼ�������:���������� volatile �ؼ������Ρ��� volatile �ؼ������εı���,�ڻ��ָ�����н�,���д���ᱻ lock ��ʶ���Ρ��涨���� lock ��ʶʱ,�ĺ���Ҫ��������ֵͬ����д�����ڴ�(����ͼ��ʾ,�������� initFlag �ڱ� refresh ������ʱ,�� lock ��ʶ)���߳� 2 �Ĺ�������ֵ��,���� MESI ����һ����Э��,�����߳�ͨ�� CPU ��̽����,���ܹ���ʱ���ֹ������� initFlag ֵ�ĸı䡣��̽��ֵ�ı仯��,�߳� 1 ��Ὣ�Լ������ڴ�Ĺ������� initFlag ״̬��Ϊ I(��Ч)״̬,����ȥ���ڴ��м��ع������� initFlag ��ֵ,��ʱ���ص��ľ����߳� 1 �ĺ��ֵ�ˡ�Ȼ��ִ�е� while() ѭ��ʱ,���ֲ���������,�߳� 1 ���ֹͣ���С�(�˴��ɽ��:MESI����һ����Э�� ����)
���ָ������:
??��β鿴���ָ��,�ο�:https://pan.baidu.com/s/1eVGFvZ7cvLciCFMqyCUtNw (��ȡ��:wjc7)
1.synchronized ��
/**
* synchronized ����� �ɼ��� ����
*/
public class VisibilityTest {
// ��������initFlag
private boolean initFlag = false;
// ����һ����(�����̹߳���ͬһ����)
private Object lock = new Object();
// load()����
public void load() {
int i = 0;
while (!initFlag) {
synchronized (lock) {
i++;
}
}
System.out.println( Thread.currentThread().getName() + ":��̽��initFlag����ֵ�ı�,i=" + i);
}
// refresh()����
public void refresh() {
synchronized (lock) {
this.initFlag = true;
}
System.out.println(Thread.currentThread().getName() + ":����initFlagֵ");
}
public static void main(String[] args) throws InterruptedException {
VisibilityTest test = new VisibilityTest();
// �߳�1
new Thread(test::load, "�߳�1").start();
// ����1s,�����߳�1��ִ��
TimeUnit.SECONDS.sleep(1);
// �߳�2
new Thread(test::refresh, "�߳�2").start();
}
}
����:
??�ڴ˴�����ܻ����ɻ�,�߳� 1 ����������while ѭ��,�����õ�����ͬһ����,�߳� 1 һֱ��ѭ��,�϶����ͷ���,�߳� 2 ��ô�ܹ���ȡ����?
?
??��ס:synchronized ��һ����������,ͬһ������Ļ����Զ�λ��ͬһ���������������߳�,����ͬһ�� test ����,�����߳� 2 Ҳ�ܹ���������߳� 2 �ĺ�,����ǰ,����ѹ�������������ֵˢ�µ����ڴ���,���� JMM ģ�淶,�߳� 1 ��̽�� initFlag �����ı��,�����ܹ�����ִ���ˡ���������ϵ�н���,�ں�������Ҳ���н��ܡ��������˽�:�����ڴ�,δ��д
?
�����ij�����,ʹ������������������߳�,�����궿����,һֱ��������,�����������ȥ����,����public static void main(String[] args) throws InterruptedException { VisibilityTest test = new VisibilityTest(); // ����1 VisibilityTest test2 = new VisibilityTest(); // ����2 // �߳�1 new Thread(test::load, "�߳�1").start(); // test // ����1s,�����߳�1��ִ�� TimeUnit.SECONDS.sleep(1); // �߳�2 new Thread(test2::refresh, "�߳�2").start(); // test2 }
2.(�Ƽ�)volatile �ؼ���
/**
* volatile �ؼ��� ��� �ɼ��� ����
*/
public class VisibilityTest {
// ��������initFlag
private volatile boolean initFlag = false; // ���������� volatile �ؼ�������
// load()����
public void load() {
int i = 0;
while (!initFlag) {
i++;
}
System.out.println( Thread.currentThread().getName() + ":��̽��initFlag����ֵ�ı�,i=" + i);
}
// refresh()����
public void refresh() {
this.initFlag = true;
System.out.println(Thread.currentThread().getName() + ":����initFlagֵ");
}
public static void main(String[] args) throws InterruptedException {
VisibilityTest test = new VisibilityTest();
// �߳�1
new Thread(test::load, "�߳�1").start();
// ����1s,�����߳�1��ִ��
TimeUnit.SECONDS.sleep(1);
// �߳�2
new Thread(test::refresh, "�߳�2").start();
}
}
4.volatile �ؼ��ֵ�����
?volatile��Java������ṩ����������ͬ��������volatile�ؼ�����������������:
- ��֤�� volatile ���εĹ��������������߳������ɼ���,Ҳ���ǵ�һ���߳�����һ����volatile���ι���������ֵ,��ֵ���ǿ��Ա������߳�������֪��
(����ɼ�������) - ��ָֹ���������Ż���
(�������������)
5.volatileΪ������֤ԭ����
??volatile ���Ա�֤�ɼ���,Ҳ���Խ�ָֹ�������Ż�(������),��������֤ԭ���ԡ�
��10���߳�Ϊ��,���� i++ ����
??volatile ���ڻ�������һ�� lock ָ��,��֧�� MESI Э���ǰ����,�ͻ�Ϊ�����ӻ��������������߳�ͬʱ�����ڴ�д������ʱ,��Ҫ lock ��ס������(lock���������10���߳�,Ҳֻ������һ���ɹ�),����߳�1 �����ɹ�,���� MESI ����״̬(M��E��S��I),����MESIЭ�鿪ʼ������
??�����߳�,����һֱ��̽��,�߳� 1 ���������߳�Ҳ���õ����ڴ��ַ,��ʱ�߳�1��Ϊ M ��״̬,Ȼ�������߷���һ����Ϣ,���������߳���̽�������������IJ���ʱ,���Ὣ�Լ������ڴ��еı�����Ϊ I ��Ч״̬��(�˴��ɽ��:MESI����һ����Э�� ����)
??��ô��һ��ѭ����,ֻ����һ��д�����ڴ�,���� 9 ���̵߳�������û��д�����ڴ��,�Ѿ�������Ч״̬���������ζ���Ѿ��ټ���9 �β���,����� volatile���ܽ��ԭ���Ե�ԭ��
3.������
??Java���Թ淶�涨 JVM �߳��ڲ�ά��˳�����塣��ֻҪ��������ս������˳������Ľ�����,��ôָ���ִ��˳����������˳��һ��,�˹��̽�ָ���������,ָ��������,�Ӷ����´���ִ�е�˳����ܺ����DZ�д�����˳��һ�¡�
??ָ�������������: JVM �ܸ��ݴ���������(CPU�༶����ϵͳ����˴�������)�ʵ��ĶԻ���ָ�����������,ʹ����ָ���ܸ�����CPU��ִ������,����ȵķ��ӻ������ܡ�
��ͼΪ��Դ�뵽����ִ�е�ָ������ʾ��ͼ

1.ԭ������
??�ڽ��� ������ ֮ǰ,�ȵ�������һ��:as-if-serial ���� �� happens-before ԭ����
1.as-if-serial ����
??as-if-serial �������˼��:������ô������(�������ʹ�����Ϊ����߲��ж�),(���߳�)�����ִ�н����Զ���ܱ��ı䡣��������runtime �ʹ��������������� as-if-serial ���塣
??Ϊ������ as-if-serial ����,�������ʹ���������Դ�������������ϵ�IJ�����������,��Ϊ�����������ı�ִ�н��������,�������֮�䲻��������������ϵ,��Щ�����Ϳ��ܱ��������ʹ�����������
??����,���̻߳�����,����ָ�����������,�� as-if-serial ����ļӳ���,�ڴ��Ľ��������ִ�еĽ��,��Զ��һ�µġ�ָ���������ڵ��̻߳�����,�����κ�Ӱ��!!!
2.happens-before ԭ��
??���DZ�д�ij���Ҫ�����Ż���(�������ʹ�����������ǵij�������Ż����������Ч��)�Żᱻ����,�Ż���Ϊ�ܶ���,������һ���Ż�����ָ��������,ָ����������Ҫ����happens-before����,����˵������ô�ž���ô�š�
??ֻ�� sychronized �� volatile �ؼ�������֤ԭ���ԡ��ɼ����Լ�������,��ô��д����������ܻ��Ե�ʮ���鷳,���˵���,��JDK 5��ʼ,Java ʹ���µ�JSR-133�ڴ�ģ��,�ṩ��happens-before ԭ����������֤����ִ�е�ԭ���ԡ��ɼ����Լ������Ե�������,�����ж������Ƿ���ھ������߳��Ƿ�ȫ�����ݡ�happens-before ԭ����������:
����˳��ԭ��:����һ���߳��ڱ��뱣֤���崮����,Ҳ����˵���մ���˳��ִ��������������: ����(unlock)������Ȼ�����ں�����ͬһ�����ļ���(lock)֮ǰ,Ҳ����˵,�������һ����������,�ټ���,��ô�����Ķ��������ڽ�������֮��(ͬһ����)��volatile��������:volatile ������д,�ȷ����ڶ�,�Ᵽ֤�� volatile �����Ŀɼ���,���������,volatile ������ÿ�α��̷߳���ʱ,��ǿ�ȴ����ڴ��ж��ñ�����ֵ,�����ñ��������仯ʱ,�ֻ�ǿ�Ƚ����µ�ֵˢ�µ����ڴ�,�κ�ʱ��,��ͬ���߳������ܹ������ñ���������ֵ���߳���������:�̵߳� start() ������������ÿһ������,������߳� A ��ִ���߳� B �� start ����֮ǰ���˹���������ֵ,��ô���߳� B ִ�� start ����ʱ,�߳� A �Թ����������Ķ��߳� B �ɼ�������: A ���� B ,B ���� C ��ô A ��Ȼ���� C�߳���ֹ����:�̵߳����в��������̵߳��ս�,Thread.join()�����������ǵȴ���ǰִ�е��߳���ֹ���������߳�B��ֹ֮ǰ,���˹�������,�߳� A ���߳� B �� join �����ɹ����غ�,�߳� B �Թ����������Ľ����߳� A �ɼ��߳��жϹ���:���߳� interrupt() �����ĵ������з����ڱ��ж��̵߳Ĵ�����ж��¼��ķ���,����ͨ�� Thread.interrupted() ��������߳��Ƿ��ж������ս����:����Ĺ��캯��ִ��,�������� finalize() ����
3.ָ�����ŷ�����ʲô��
- ������(�����ֽ���ָ�����������ɻ������,ͨ������ָ��˳��,�ڲ��ı���������ǰ����,�����ܼ��ټĴ����Ķ�ȡ���洢����,��ָ��üĴ����Ĵ洢ֵ)
- CPU ִ���ڼ�(�� class �ֽ����ļ�ת���ɻ��ָ���,CPU ��ִ�л�����ʱ,Ҳ�������������ָ��������)
4.DCL˫�ؼ�����,����volatile��ָֹ��������
??volatile �ؼ���,���˽���ɼ���������,��һ�����þ��ǽ�ָֹ�������Ż����Ӷ�������̻߳����³����������ִ�е�����,����ָ�������Ż�ǰ������ϸ������,������Ҫ��˵��һ�� volatile �����ʵ�ֽ�ָֹ�������Ż��ġ����˽�һ������:�ڴ�����(Memory Barrier)��
??�ڴ�����,�ֳ��ڴ�դ��,��һ�� CPU ָ��,��������������,һ�DZ�֤�ض�������ִ��˳��,���DZ�֤ijЩ�������ڴ�ɼ���(���ø�����ʵ�� volatile ���ڴ�ɼ���)�����ڱ������ʹ���������ִ��ָ�������Ż��������ָ������һ�� Memory Barrier �����߱������� CPU ,����ʲôָ����ܺ����� Memory Barrier ָ��������,Ҳ����˵ͨ�������ڴ����Ͻ�ֹ���ڴ�����ǰ���ָ��ִ���������Ż���Memory Barrier ������һ��������ǿ��ˢ������ CPU �Ļ�������,����κ� CPU �ϵ��̶߳��ܶ�ȡ����Щ���ݵ����°汾����֮,volatile ��������ͨ���ڴ�����ʵ�������ڴ��е�����,���ɼ��Ժͽ�ֹ�����Ż���
??���濴һ���dz����͵Ľ�ֹ�����Ż�������˫��У����(DCL,�� double-checked locking)����ģʽ����,����:(��δ���������̳�Ҳ��)
/**
* ˫��У���� ����ģʽ(������Ҫ�� singleton ����ǰ���� volatile �ؼ���,��ָֹ��������)
*/
public class Singleton {
private static Singleton instance;
private Singleton (){}
public static Singleton getInstance() {
// ��һ�μ��
if (instance== null) {
// ����ͬ��ִ��
synchronized (Singleton.class) {
if (instance== null) {
// ���̻߳����¿��ܻ��������ĵط�
instance= new Singleton();
}
}
}
return instance;
}
}
??��������һ������ĵ���ģʽ��˫�ؼ��Ĵ���(��Ϊȥ�� volatile ����),��δ����ڵ��̻߳����²�û��ʲô����,������ڶ��̻߳����¾Ϳ��ܳ����̰߳�ȫ���⡣ԭ������:ijһ���߳�ִ�е���һ�μ��,��ȡ���� instance ��Ϊ null ʱ,instance �����ö������û����ɳ�ʼ����
��Ϊ instance= new Singleton(); ���Է�Ϊ����3�����(α����)
memory = allocate(); // 1.��������ڴ�ռ�
instance(memory); // 2.��ʼ������
instance = memory; // 3.����instanceָ��շ�����ڴ��ַ,��ʱ instance != null
��Ϊ���� 2 �� ���� 3 ֮�䲢û��������ϵ,�����ڲ���2 �� ����3 ����ܻ�������,ִ��˳����ܾ����������:
memory=allocate(); // 1.��������ڴ�ռ�
instance = memory; // 2.����instanceָ��շ�����ڴ��ַ,��ʱ instance != null,���Ƕ���û�г�ʼ�����!
instance(memory); // 3.��ʼ������
??���ڲ��� 2 �Ͳ��� 3 ����������������ϵ,������������ǰ�������ź�����ִ�н���ڵ��߳��в�û�иı�,������������Ż��������ġ�����ָ������ֻ�ᱣ֤���������ִ�е�һ����(���߳�),����������Ķ��̼߳������һ������
??���Ե�һ���̷߳��� instance ��Ϊ null ʱ,���� instance ʵ��δ���ѳ�ʼ�����,Ҳ��������̰߳�ȫ���⡣��ô����ν����,�ܼ�, ����ʹ�� volatile ��ֹ instance ������ִ��ָ�������Ż����ɡ�
// ���� volatile �ؼ�������,��ֹ instance ������ִ��ָ�������Ż�
private volatile static Singleton instance;
5.volatile �ؼ��ֵ�����,�� JMM ģ���е�ʵ��
??ǰ���ᵽ���������Ϊ����������������������������Ϊ��ʵ��volatile�ڴ�����,JMM �ڴ�ģ�ͻ�ֱ��������������͵����������͡�
1.JMM ��Ա������ƶ��� volatile ���������
| �Ƿ��������� | �ڶ������� | ||
|---|---|---|---|
| ��һ������ | ��ͨ�� / д | volatile �� | volatile д |
| ��ͨ�� / д | NO | ||
| volatile �� | NO | NO | NO |
| volatile д | NO | NO | |
��ϱ���,����˵��:
??���������һ����Ԫ�����˼��:�ڳ�����,����һ������Ϊ��ͨ�����Ķ���дʱ,����ڶ�������Ϊ volatile д,�����������������������������
�ӱ����п��Կ���:
??���ڶ��������� volatile дʱ,���ܵ�һ��������ʲô,�������������������ȷ�� volatile д֮ǰ�IJ������ᱻ������������ volatile д֮��
??����һ�������� volatile ��ʱ,���ܵڶ���������ʲô,�������������������ȷ�� volatile ��֮��IJ������ᱻ������������ volatile ��֮ǰ��
??����һ�������� volatile д,�ڶ��������� volatile ��ʱ,����������
2.JMM ��Ա������ƶ��� volatile ������ʵ�ַ�ʽ
??Ϊ��ʵ�� volatile ���ڴ�����,�������������ֽ���ʱ,����ָ�������в����ڴ���������ֹ�ض����͵Ĵ����������������ڱ�������˵,����һ�����Ų�������С���������ϵ��������������ܡ�Ϊ��,JMM��ȡ���ز��ԡ������ǻ��ڱ��ز��Ե�JMM�ڴ����ϲ�����ԡ�
- ��ÿ�� volatile д������ǰ�����һ�� StoreStore ����
- ��ÿ�� volatile д�����ĺ������һ�� StoreLoad ����
- ��ÿ�� volatile �������ĺ������һ�� LoadLoad ����
- ��ÿ�� volatile �������ĺ������һ�� LoadStore ����
�����ڴ����ϲ�����Էdz�����,�������Ա�֤���������ƽ̨,����ij����ж��ܵõ���ȷ��volatile�ڴ����塣
3.volatileд ����������ʾ
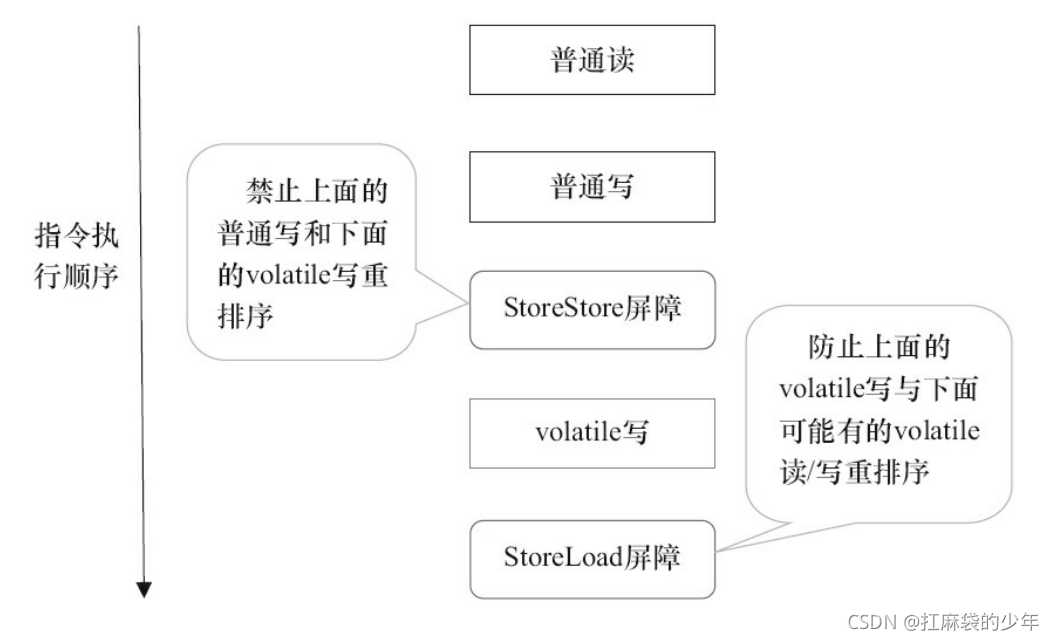
??��ͼ�� StoreStore ���Ͽ��Ա�֤�� volatile д֮ǰ,��ǰ���������ͨд�����Ѿ�����������ɼ��ˡ�������Ϊ StoreStore ���Ͻ������������е���ͨд�� volatile д֮ǰˢ�µ����ڴ档
??����Ƚ�����˼����,volatile д����� StoreLoad ���ϡ������ϵ������DZ��� volatile д���������е� volatile ��/д��������������Ϊ������������ȷ�ж���һ�� volatile д�ĺ��� �Ƿ���Ҫ����һ�� StoreLoad ����(����һ�� volatile д֮������ return)��Ϊ�˱�֤����ȷ ʵ�� volatile ���ڴ�����,JMM �ڲ�ȡ�˱��ز���:��ÿ�� volatile д�ĺ���,������ÿ�� volatile ����ǰ�����һ�� StoreLoad ���ϡ�������ִ��Ч�ʵĽǶȿ���,JMM ����ѡ������ÿ�� volatile д�ĺ������һ�� StoreLoad ���ϡ���Ϊ volatile д-���ڴ�����ij���ʹ��ģʽ��:һ��д�߳�д volatile ����,������̶߳�ͬһ�� volatile �����������̵߳��������д�߳�ʱ,ѡ���� volatile д֮����� StoreLoad ���Ͻ������ɹ۵�ִ��Ч�ʵ���������������Կ��� JMM ��ʵ���ϵ�һ���ص�:����ȷ����ȷ��,Ȼ����ȥ��ִ��Ч�ʡ�
4.volatile�� ����������ʾ
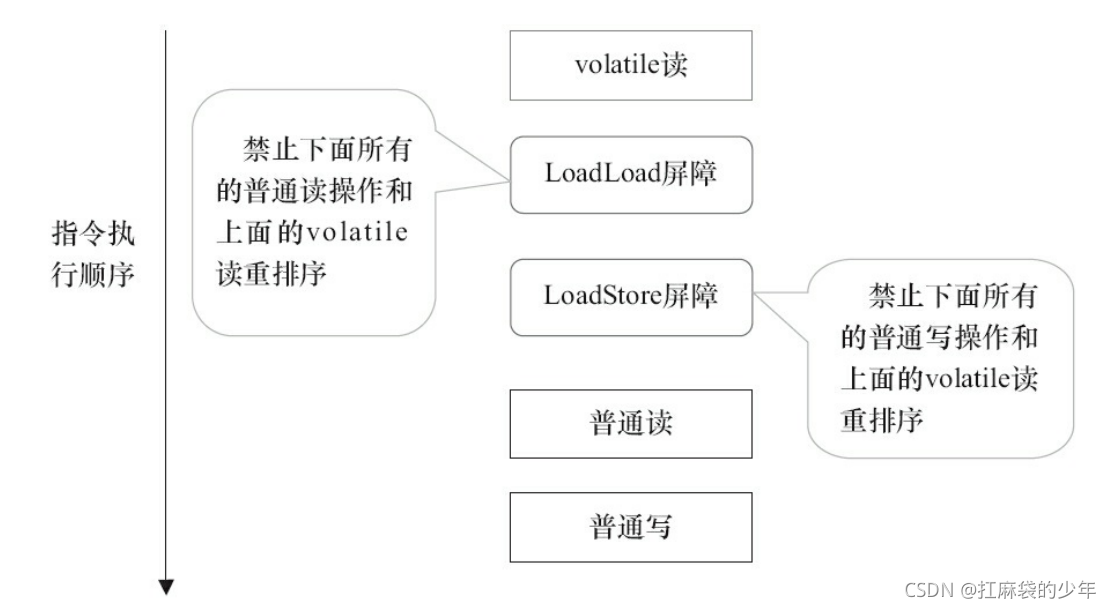
??��ͼ�� LoadLoad ����������ֹ������������� volatile �����������ͨ��������LoadStore ����������ֹ������������� volatile �����������ͨд������
??����volatileд��volatile�����ڴ����ϲ�����Էdz����ء���ʵ��ִ��ʱ,ֻҪ���ı� volatileд-�����ڴ�����,���������Ը��ݾ������ʡ�Բ���Ҫ������
5.volatile ��/д,���������ʾ
/**
* volatile��/д �ڴ����ϲ�����ʾ
*/
public class VolatileBarrierExample {
int a;
volatile int m1 = 1;
volatile int m2 = 2;
void readAndWrite() {
int i = m1; // ��һ��:volatile��
int j = m2; // �ڶ���:volatile��
a = i + j; // ��ͨд
m1 = i + 1; // ��һ��:volatileд
m2 = j * 2; // �ڶ���:volatileд
}
}
���� volatile ���εı���,���û�б� volatile ����,����Ϊ��ͨ�� / д��
int i = m1;?�� m1 ��ֵ,��� m1 ��˵,���� (volatile ��),int j = m2;?�� m2 ��ֵ,��� m2 ��˵,���� (volatile ��)a = i + j;? a = i + j,û�б� volatile ���εı���,���� (��ͨд)m1 = i + 1;?m1 = i + 1,��� m1 ��˵,���� (volatile д)m2 =j * 2;?m2 =j * 2,��� m2 ��˵,���� (volatile д)
??���� 3.JMM ��Ա������ƶ��� volatile ������ʵ�ַ�ʽ,��� readAndWrite() ����,�������������ֽ���ʱ���������µ��Ż������ղ�����������ͼ��ʾ:
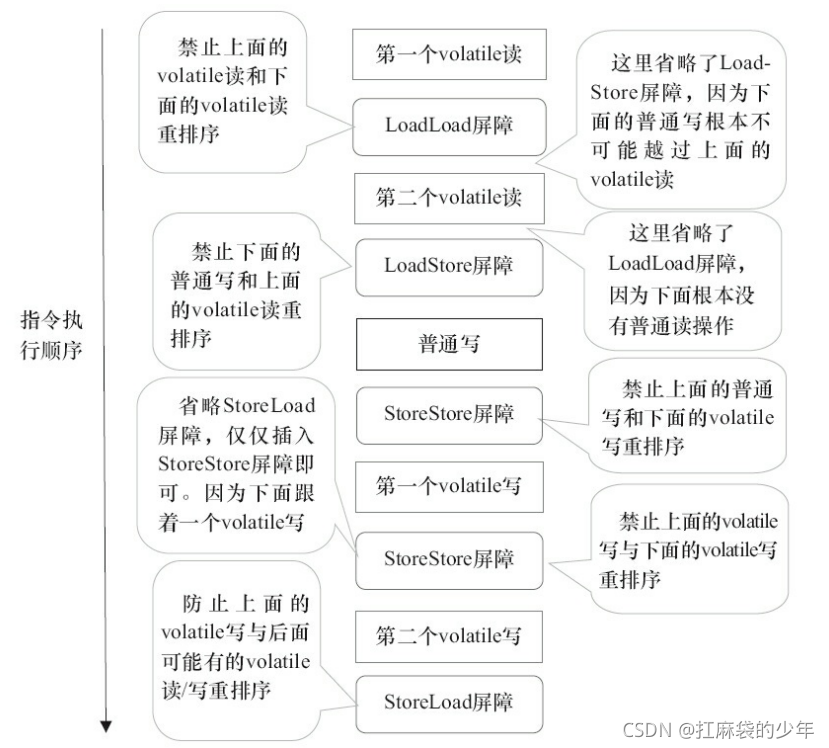
??ע��,���� StoreLoad ���ϲ���ʡ������Ϊ�ڶ��� volatile д֮��,�������� return����ʱ������������ȷ�϶������Ƿ���� volatile ����д,Ϊ�˰�ȫ���,������ͨ����������� ��һ�� StoreLoad ���ϡ�
6.��ͬ������ƽ̨,����ڴ����ϵ��Ż�
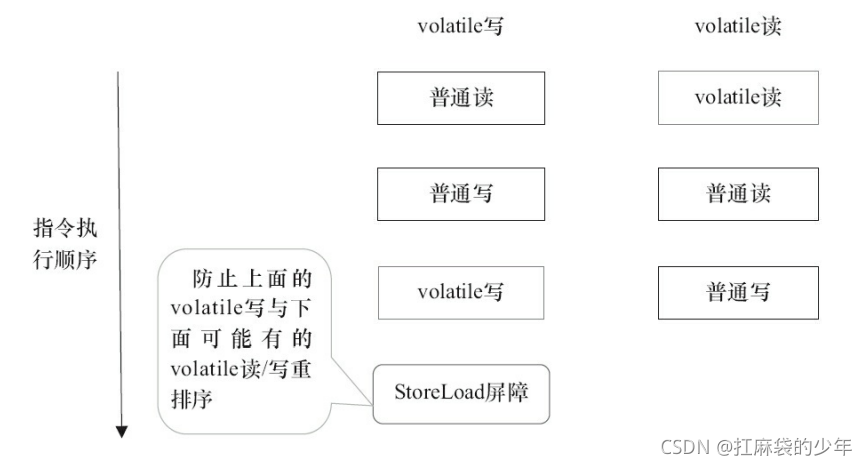
??��� 5.volatile ��/д,���������ʾ ���Ż�,������Ż���Ե����������ƽ̨,���ڲ�ͬ�Ĵ������в�ͬ���ɽ��ȡ��Ĵ������ڴ�ģ��,�ڴ����ϵIJ��뻹���Ը��ݾ���Ĵ������ڴ�ģ�ͼ����Ż����� X86 ������Ϊ��,��ͼ�г����� StoreLoad ������,���������϶��ᱻʡ����
??ǰ�汣�ز����µ� volatile ����д,�� X86 ������ƽ̨�����Ż�������ͼ��ʾ��ǰ���ᵽ��,X86 �����������д-��������������X86 ����Զ�-������-д��д-д������������,����� X86 �������л�ʡ�Ե��� 3 �ֲ������Ͷ�Ӧ���ڴ��������� X86 ��,JMM ������ volatile д�������һ�� StoreLoad ���ϼ�����ȷʵ�� volatile д-�����ڴ����塣����ζ���� X86 ��������,volatile д�Ŀ����� volatile ���Ŀ������ܶ�(��Ϊִ�� StoreLoad ���Ͽ�����Ƚϴ�)��
2.ʵ������
1.����������
??�����߳�,x = 0;y = 0;a = 0;b = 0;�ֱ�������¸�ֵ����,�����߳�����(Integer.MAX_VALUE)ѭ��,���ս������3�����:1.(x = 1,y = 1) ? 2.(x = 0,y = 1) ? 3.(x = 1,y = 0) ? �������ָ��������,�����ֵ�4����� 4.(x = 0,y = 0)
/**
* ������(ָ��������)
*/
public class ReOrderTest {
private static int x = 0;
private static int y = 0;
private static int a = 0;
private static int b = 0;
public static void main(String[] args) throws InterruptedException {
for (int i = 0; i < Integer.MAX_VALUE; i++) {
// (��һ��ѭ����)��������
x = 0; y = 0;
a = 0; b = 0;
// �߳�1
Thread t1 = new Thread(() -> {
a = 1; // 1
x = b; // 2
});
// �߳�2
Thread t2 = new Thread(() -> {
b = 1; // 3
y = a; // 4
});
t1.start();
t2.start();
t1.join();
t2.join();
String result = "��" + i + "�� (" + x + "," + y + ")";
if(x == 0 && y == 0) {
System.err.println(result);
break;
} else {
System.out.println(result);
}
}
}
}
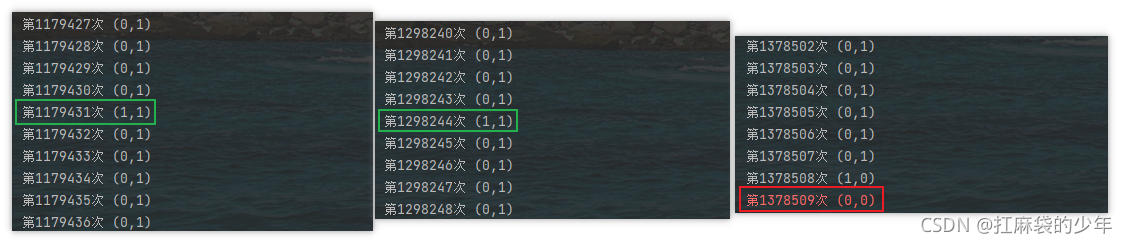
���ֽ������:(���½��������е�1��2��3��4 ,�ֱ��Ӧ���������߳��е�4��������)
- ��ִ�� t2 �� 3,��ִ�� t1 �� 2 ,��ִ�� t1 �� 1 ,���ִ�� t2 �� 4 ,���ս��Ϊ:
1,1(���ָ��ʽ���) - ��ִ�� t1 �� 1 �� 2 ,��ִ�� t2 �� 3 �� 4 ,���ս��Ϊ:
0,1 - ��ִ�� t2 �� 3 �� 4 ,��ִ�� t1 �� 1 �� 2 ,���ս��Ϊ:
1,0 (������������ָ������,���)��ִ�� t1 �� 2 ���� t2 �� 2 ,���ս��Ϊ:0,0
4�����,��ͼ��ʾ:
2.����ԭ��
??Ϊʲô����� 0,0 ���?
??ֻ�� x = b ������ a = 1 ִ��,y = a ������ b = 1 ִ��,�Ż���� 0,0 ���������������Ϊ CPU ���� JIT(��ʱ������)�����ǵĴ��������ָ��������,�ڶ��߳̿����е��µ�Ԥ�ڽ����ʵ�ʽ����ͬ�������
??�ڲ��������,�е�ָ���������Ӱ�쵽���Ǵ���Ԥ�ڵĽ��,������Ϊ a = 1;x = b;��β�û����ѭ happen-before ԭ��,���о��� CPU ��֪����ָ�����������������յĽ������Ӱ����(�������ԭ���)��Ϊ a = 1 �� x = b ����������,����֮��û���κε�������ϵ,CPU������Ϊ���ź��Ӱ����,���Ի��������ָ�����������
3.�������
??�� 3 ��:1.ʹ�� synchronized �����ƽ�� ? 2.ʹ�� volatile �ؼ��� ? 3.(���Ƽ�)ʹ�� Unsafe ���ֵ� loadFence��storeFence��fullFence ����,�ֶ��ڴ����������ڴ�����
??1.�� synchronized ���������ƶ��߳̿����ij���,���̻߳�ִ��,�߳�1ֻ���ڻ������,����ִ��ҵ��������;�߳�2���߳�3 ֻ�ܵȴ��߳� t1 �����ͷ�,t1 �ͷź�,t2��t3��������,˭����˭ִ�С��������ܹ���֤��һʱ��ֻ��һ���̷߳��ʸô���������̻߳�����,��ѭ as-if-serial ����,������ô������,�����ִ�н����Զ���ܱ��ı���
??2.ʹ�� volatile �ؼ�����volatile�ǿ��Խ�ֹ CPU/JIT ��������û��������ϵ�����д�����ָ�������Ż���volatile �ײ��ǻ����ڴ�������ʵ�ֵġ�JMM ģ���е��ڴ������� StoreStore��StoreLoad��LoadLoad��LoadStore���֡��������������ڴ�����ʱ,����������������������д�����ڴ�,��֤����������������Զ�����µ���
??3.ʹ�� Unsafe ���ֵ� loadFence��storeFence��fullFence ����,�ֶ��ڴ����������ڴ����������ַ�ʽʹ�� Unsafe ħ������Ϊ�����ṩ�� loadFence �� storeFence��fullFence ����,�ƹ� JVM �����ֱ�Ӷ��ڴ���в���,����Ҫ�Ĵ���֮���ֶ������ڴ�����,Ҳ�ܽ������������,���Dz�����ʹ��!!!��Ϊ Unsafe ��̫����ȫ,�㲻�÷��ջ�ܴ��!!!
1.synchronized ��
/**
* synchronized ����� ������ ����
*/
public class ReOrderTest {
private static int x = 0;
private static int y = 0;
private static int a = 0;
private static int b = 0;
// ����һ����
private static final Object lock = new Object();
public static void main(String[] args) throws InterruptedException {
for (int i = 0; i < Integer.MAX_VALUE; i++) {
// (��һ��ѭ����)��������
x = 0; y = 0;
a = 0; b = 0;
// �߳�1
Thread t1 = new Thread(() -> {
synchronized (lock) { // ����
a = 1;
x = b;
}
});
// �߳�2
Thread t2 = new Thread(() -> {
synchronized (lock) { // ����
b = 1;
y = a;
}
});
t1.start();
t2.start();
t1.join();
t2.join();
String result = "��" + i + "�� (" + x + "," + y + ")";
if(x == 0 && y == 0) {
System.err.println(result);
break;
} else {
System.out.println(result);
}
}
}
}
2.(�Ƽ�)volatile �ؼ���
??ʹ�� volatile ���α��� a �� b��
??Ϊʲô�������α��� x �� y ��? Ҫ��֤�߳� t1 �� a = 1 �� �߳� t2 ��b = 1 ��ִ��,���ͺ���Ĵ��뷢��ָ������,�϶�Ҫ���� a �� b,�� a = 1 �� x = b ֮����ڴ�����,��֤JMM ������δ������ָ�������Ż���
/**
* volatile �ؼ��ֽ�� ������ ����
*/
public class ReOrderTest {
private static int x = 0;
private static int y = 0;
// ʹ�� volatile ���� a �� b
private static volatile int a = 0;
private static volatile int b = 0;
// ����һ����
private static final Object lock = new Object();
public static void main(String[] args) throws InterruptedException {
for (int i = 0; i < Integer.MAX_VALUE; i++) {
// (��һ��ѭ����)��������
x = 0; y = 0;
a = 0; b = 0;
// �߳�1
Thread t1 = new Thread(() -> {
a = 1;
x = b;
});
// �߳�2
Thread t2 = new Thread(() -> {
b = 1;
y = a;
});
t1.start();
t2.start();
t1.join();
t2.join();
String result = "��" + i + "�� (" + x + "," + y + ")";
if(x == 0 && y == 0) {
System.err.println(result);
break;
} else {
System.out.println(result);
}
}
}
}
3.(���Ƽ�)ʹ�� Unsafe ���ֵ� loadFence��storeFence��fullFence ����,�ֶ��ڴ����������ڴ�����
Unsafe ����,һ���� 3 ���ڴ�����,�ֱ���:
- loadFence ? ������
- storeFence ? ���
- fullFence ? ��д����(�������϶����)
// �߳�1
Thread t1 = new Thread(() -> {
a = 1; // a = 1 ,��ֵд��a,�˴��� volatile д
x = b;
});
// �߳�2
Thread t2 = new Thread(() -> {
b = 1; // b = 1 ,��ֵд��b,�˴�Ҳ�� volatile д
y = a;
});
ͨ�� Unsafe ���ֶ�����д����,����������ʾ:
// �߳�1
Thread t1 = new Thread(() -> {
a = 1; // a = 1 ,��ֵд��a,�˴��� volatile д
UnsafeInstance.reflectGetUnsafe().storeFence();
x = b;
});
// �߳�2
Thread t2 = new Thread(() -> {
b = 1; // b = 1 ,��ֵд��b,�˴�Ҳ�� volatile д
UnsafeInstance.reflectGetUnsafe().storeFence();
y = a;
});
���մ���:
/**
* Unsafe���ֶ��������� ��� ������ ����
*/
public class ReOrderTest {
private static int x = 0;
private static int y = 0;
// ʹ�� volatile ���� a �� b
private static int a = 0;
private static int b = 0;
// ����һ����
private static final Object lock = new Object();
public static void main(String[] args) throws InterruptedException {
for (int i = 0; i < Integer.MAX_VALUE; i++) {
// (��һ��ѭ����)��������
x = 0; y = 0;
a = 0; b = 0;
// �߳�1
Thread t1 = new Thread(() -> {
a = 1; // volatileд
UnsafeInstance.reflectGetUnsafe().storeFence(); // ͨ��Unsafe��,�ֶ�����д����
x = b;
});
// �߳�2
Thread t2 = new Thread(() -> {
b = 1; // volatileд
UnsafeInstance.reflectGetUnsafe().storeFence(); // ͨ��Unsafe��,�ֶ�����д����
y = a;
});
t1.start();
t2.start();
t1.join();
t2.join();
String result = "��" + i + "�� (" + x + "," + y + ")";
if(x == 0 && y == 0) {
System.err.println(result);
break;
} else {
System.out.println(result);
}
}
}
}
??2021-11-19,��JMM�ڴ�ģ�� & ���߳��������ԡ��Ѹ���,������������: synchronized �ؼ��֡�JDK 6 �� synchronized �����Ż�,������Ҫ,�������ע��������̡����!!!
����д������,�Ӹ���ע��
���ע�������,�Ӹ���ע����· �d(?��?��?)ノ゙
�Ҳ��ܱ�֤��д�����ݶ���ȷ,���ǿ��Ա�֤�����ơ���ճ������֤ÿһ�仰��ÿһ�д��붼�������ù���,����Ҳ��ָ��,������ Thanks?(・��・)ノ