���ֵ�����Ŀ,�Ӷ������ij����˲�ƽ������,��Ϊ����Ա�бȽ�ִ�ŵ���,������IJ����ݡ�����,��������,��ʱ�������ڽ�����������ʵ������,��дƪ���¼�¼һ�¡�
�����в����ὲ��ʹ�ñ������ȵ��Ŀ�,�Լ�����������Ų������,ijЩ˼·�ͷ��������ܶԴ������������
�������Դ
��Ӫͬ��ʱ��ʱ��������˵��˵�����,ԭ��ܼ�,�˲�ƽ,���鲻�С�������й��������ϵͳ�Ĺ�������,��������ʼ�������ѹ��˵ġ�
��Ȼ�ս�����Ŀ,��Ȼ�ܶ�ҵ���������˽�,�����������ļ�����ս,����Ҫ������˵ġ�
��ʵ,���������ԭ��ܼ�:�ȵ��˻������ܶ������̲߳���ͬһ���û����˻�ʱ,�ͻ����һ�����°�����һ�����¸��ǵ��������
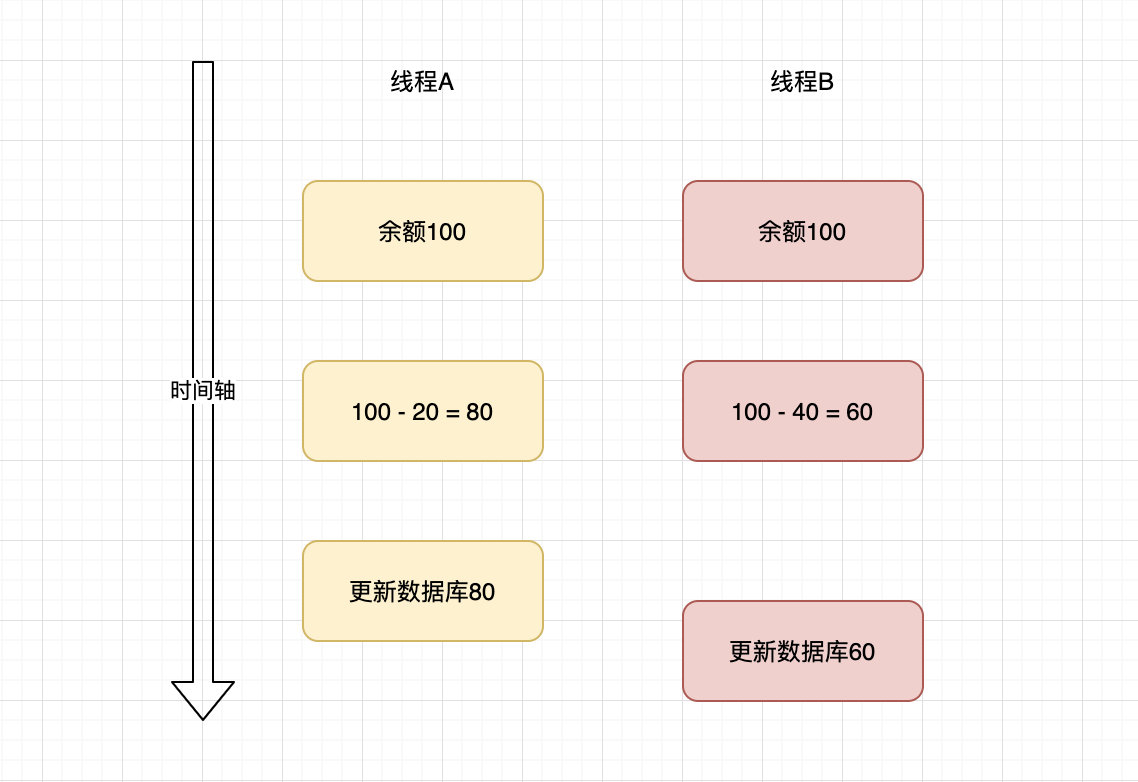
��ͼ��������,������������߳�ͬʱ��ѯ���ݿ��һ������(�ȵ��˻�),Ȼ���ڴ�������,�����µ����ݿ⡣������ֲ������,�����̶߳���ȡ��100,һ�������80,һ�������60,����µľ��п��ܽ�ǰ��ĸ��ǵ���
�������ͨ����:
- �������߳���;
- ��Ⱥ�ֲ�ʽ��;
- ��Ⱥ���ݿⱯ����;
��Ŀ���Ѳ����˱�����,�ͻ����������Ų���ԭ��
�������
���������ڶ����ݱ����ijֱ���̬��,���������ݴ��������лὫ����������
��������ʵ��,�����������ݿ��ṩ��������(Ҳֻ�����ݿ���ṩ�������Ʋ���������֤���ݷ��ʵ�������,����,��ʹ��Ӧ�ò���ʵ���˼�������,Ҳ����֤�ⲿϵͳ����������)��
ͨ����ʹ��select �� for update�����ʵ�ֶ����ݵļ�����
for update��������InnoDB,�ұ����������(BEGIN/COMMIT)�в�����Ч���ڽ����������ʱ,ͨ����for update�����,MySQL��Բ�ѯ�������ÿ�����ݶ�����������,�����̶߳Ըü�¼�ĸ�����ɾ��������������������������������������
����ʾ��չʾ�˱������Ļ���ʹ������:
set autocommit=0;����
//������autocommit��,ִ������ҵ��������:
//0.��ʼ����
begin;/begin work;/start transaction; (����ѡһ�Ϳ���)
//1.��ѯ����Ʒ��Ϣ
select status from t_goods where id=1 for update;
//2.������Ʒ��Ϣ���ɶ���
insert into t_orders (id,goods_id) values (null,1);
//3.����ƷstatusΪ2
update t_goods set status=2;
//4.�ύ����
commit;/commit work;
��Ϊ�ر������ݿ��Զ��ύ,����ͨ��begin/commit����������
ʹ��select��for update�ķ�ʽͨ�����ݿ�ʵ���˱�����������,idΪ1���������ݾͱ�����,�������������ȱ��������ύ֮�����ִ�С������ͱ�֤���ڲ����ڼ����ݲ��ᱻ���������ġ�
ԭ���������
���˽����˲�ƽ��ԭ��ͱ������Ļ���ԭ��֮��,�Ϳ��Խ���������Ų��ˡ���Ȼϵͳ�Ѿ�ʹ���˱�����,��Ȼ�����������,�ǿ϶�������©����ʲô��
����,�Ų��������˻�(account��)���µĵط�,�����ҵ�һ��bug��
������ط���ʹ���˱�����,��for update��ѯһ��,Ȼ������µ����,�ٽ��и������ݿ⡣����һ����Ȼ�Ȳ�ѯ���˼��������,Ȼ���ٽ��м���,�����¡�
������������:
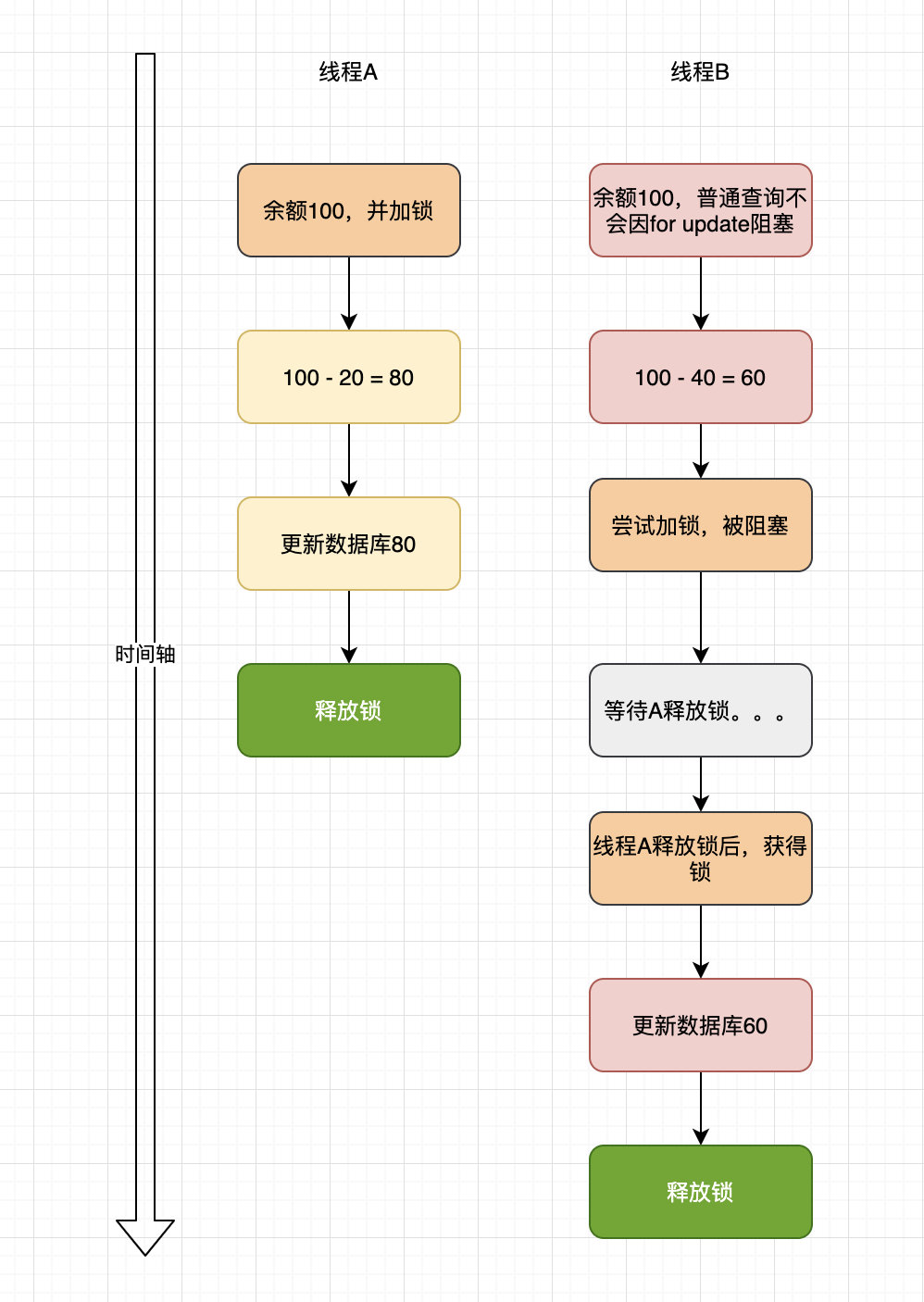
�����������,��Ȼ�߳�B�����˼�������,�����ڼ�������δ������,������Ȼʹ���˱�����,�����ɴ������⡣��ȷ��ʹ�÷�ʽ���ǽ������������������С�
��Ȼ,����߳�B��ȫ������������,Ҳ�����ͬ�������⡣
���Ų���������bug,�ҿ�ʼ�Nɪ��,��Ϊ��������˲�ƽ�����⡣
һ����֮��
���һ����֮��,��Ӫͬ����������,ż�����ɻ�����˲�ƽ�����⡣�տ�ʼ�һ���Ϊ�Dz��Ǹ����,��ʷ���˲�ƽ�����������յIJ�ƽ�������ջ����¶��������Ų�һ�Ρ�
��һ��,���˲�ƽ���˻���������ˮ���漰�����롢��־ȫ����һ�顣���ڼ仹�����˺ܶ�С����,����ע��˷���
����һ:���ݲ鲻��
�����¼������̫��,��ǧ�������,���������߲�û�д������������Ҫ��������,����ɸѡ���������鲻����������
������õ�SQL�Ż����������ܵ�:limit���Ʋ�ѯ������Ч�ķ�ҳ���ԡ�
����limit���Ʋ�ѯ������һ�������,���������˽����,������������������������֮����������ء�
��Ч�ķ�ҳ�������б�ҳ�ڲ�ѯ���ݾ�������,Ϊ�˱���һ���Է��ع��������Ӱ��ӿ�����,һ���Բ�ѯ�ӿ�����ҳ������
��Mysql�з�ҳһ���õ�limit�ؼ���:
select id,name,age from user limit 10,20;
��������ʱ,limit��ҳûɶ���⡣����������������ܶ�,�ͻ�����������⡣
�����ҳ���������:
select id,name,age from user limit 1000000,20;
Mysql��鵽1000020������,Ȼ����ǰ���1000000��,ֻ������20������,�dz��˷���Դ��
�Ż�sql:
select id,name,age from user where id > 1000000 limit 20;
��Ȼ������ʹ��between�Ż���ҳ:
select id,name,age
from user where id between 1000000 and 1000020;
ֵ�����ҵ������ű���ID��������,��������id���ڵ�����,ֻ��������Ľ���¼,����ǿ�����ݲ�ѯ������
���Ѷ�:��־����
����ϵͳ��־��ıȽ���ϸ,һ����Ŀÿ���ż���G����־��Ҫ�����м��ѯ�����õ���־,Ҳ��һ��������
�Ų�����ʱ,��ʹ����grep �����ҵ������⽻���˺���־:
grep 123 info.log
����Ŷ�λ�ĵ���־���ʱ����,������������С��־��Χ:
grep '2021-11-17 19:23:23' info.log > temp.log
����ͬ��ʹ��grep������Ҷ�Ӧʱ���������־,�������ҵ���־�����temp.log�ļ���,Ȼ��ͨ��sz����,���ص����ؽ���ɸѡ������
�����ҿ�������grep���ͬʱҲҪ������������ļ�,������ÿ�β鼸��G�����ݷ�����ˡ���Ȼ������ľ��ǰ�ɸѡ֮�����־���ر���,�ٴαȶԷ�����
����
���ڴ���ɸѡ���,û��ʲô����,���˴�ͷ��λ����һ��,û�б�ĺ÷��������������������IDE�������͡�Find usages�����ܼ��ɡ�
�����ջ�
���������Ų�,���������°�ʱ,��λ���������ԭ��:һ���߳̽�������֮��,����һ���߳̽��串���ˡ���������ˮ��¼�д��������ʽ���,�Ҽ���ǰ���һ���ļ�¼��
�ó����֮��,���Ų�������ͬ������ͷ������,����ɲ���group by�����п���ɸѡ:
select count(id) as num , balance from account group by balance having num > 1;
ͨ���������Ϳ��Կ��ٲ����ͬ������ǰ���ļ�¼����Ȼ,������仹�������������ͽ��ά�ȡ�
��Ȼ�ҵ������ⷢ���ĵط�,����δ��ȫ�ҵ������ԭ��
�����ε�Bug
����Ϊ�ҵ������ⷢ���ĵ�,���ܿ��ٽ�������,����ȷС�������Bug,����һ������Ų������ԭ��
ģ��߲���
�ҵ�������Ĵ���,����ʵ����,û���Ⱑ,Ҳ���˱�����,���ݿ�����ҲûʧЧ,Ҳû��ͬService�ķ������á���ô�ͻ����������?
��Ȼ���ۿ�������,�Ǿ��ó����ܡ�����,д��һ����Ԫ����,����һ���̳߳�,�����ö�Ӧ�������������,����û���⡣
�����ܵ��Dz��Կ�,�������õ����Ʒ���,���������ݿ�IJ���,������Navicat��֤�˱������Ƿ���Ч:
START transaction ;
select * from account where id = 1 for update;
Ȼ��������һ����ѯ����ִ��:
select * from account where id = 1 for update;
����,���ݿ������ȷ����Ч��,��û��ִ��commit����֮ǰ,�Dz鲻�����ݵġ�
������ϣ��
��ʱ,��ȫ���뽩�֡����ǾͿ�ʼ������������,����Ķ����롣
����,��һƪд�ú�ˮ,������һ��Hibernate javadoc�ĵ����ӵ�����,�������һ������,����˾��������
��javadoc����һ��sessionʵ�ֱ������ķ�������Ŀ�������Ѿ�������get����:
get
@Deprecated Object get(Class clazz, Serializable id, LockMode lockMode)**Deprecated.**LockMode parameter should be replaced with LockOptions
Return the persistent instance of the given entity class with the given identifier, or null if there is no such persistent instance. (If the instance is already associated with the session, return that instance. This method never returns an uninitialized instance.) Obtain the specified lock mode if the instance exists.
���еġ�If the instance is already associated with the session, return that instance��������ǰһ�����ѵ��ǻ���������?
������ص���:���session���Ѿ�������ô������ʵ��,��ֱ�ӷ������ʵ����
�о���ȥ������,�����ǵ�,α��������:
Account account = accountService.getAccount(type, userNo);
if(account == null){
//...
}
accountService.getAccountAndLock(account.getId());
// ...
������������ֵ�ÿ϶���������:��һ,�ڼ���֮ǰ�Ȳ���һ�ζ���,�����ܱ�����Ϊ������,��סȫ��;�ڶ�,������һ�����ݿ��¼ʱ��������id,��ȷ��λ������ļ�¼,������ס������¼�����ű���
��ô,�Dz�����Ϊǰ��IJ�ѯ���º���getAccountAndLock������ʵЧ��?������֤һ�¡�
����,�ڵ�Ԫ������������ǰ��IJ�ѯ,�ٴ�ִ�С�����,Bug���ڸ�����!
Ϊ�˽�һ��֤ʵ,�ڵײ�Ĺ���������������clear����:
public T findAndLock(Class cls, String primaryKey) throws DataAccessException {
Session session = getHibernateTemplate().getSessionFactory().getCurrentSession();
// ������֤�Ƿ�����
session.clear();
Object object = session.load(cls, primaryKey, LockOptions.UPGRADE);
return (T) object;
}
�ٴ�ִ�е�Ԫ����,����������������,Bug��λ��ϡ�
����Ľ��
��Ȼ�Ѿ���λ����,��������ͷdz������ˡ�����ʹ��session.clear()ֻ��Ϊ����֤,��ʵ����ʹ�����ַ���Ӱ��̫��,�������º�����
�������:������Hibernate����ͨ��ѯ,��Ϊ����ԭ��SQL�IJ�ѯ����Ϊǰ�����ͨ��ѯֻ��Ҫid,��ôֻ��һ��SQL��ѯID����,���idΪ��,����;���id�ǿ�,���ٽ�����һ��������
����,�������������
��
�ڽ����������Ĺ�����,����ֻ�Ǻܼı�����,�����Ų�Ĺ����л��õ����漰���˴���������֪ʶ,����@Transactional����ʧЧ�������Ų顢����ĸ��뼶��Hibernate�Ķ༶���桢Spring��������������̡߳�Linux������Navicat�ֶ�����SQL�Ż�����Ԫ���ԡ�Javadoc���ĵȡ�
����,�ڽ������֮��,����ʮ���б�Ҫ��������ҡ�ͨ���������,����ѧ����ʲô��?
�������:��SpringBoot������Ļ������ͼ������,�ᰮ���м���,д�����ɻ����¡�
���ں�:���������ӽ硹,�����Ĺ��ں�,��ӭ��ע~
��������:����ϵ�����ź�:zhuan2quan
