
�������ʿ���ʷ
������·��,���˶������� Zipkin��Jaeger��Skywalking ��Щ�Ѿ��Ƚϳ������·�ٿ�Դ�����Լ� Opentelemetry��OpenTracing��OpenCensus ��Щ��Դ������Ȼʵ�ָ��в���,����ʹ�ø�������������ʵ����ϴ�����IJ�ͬ����·��ϵͳ,ȴ�������������Ƶĵط���
������Щ��·��ϵͳ����Ҫ�ڵ�����·�ϴ���Ԫ���ݡ����Ƕ�Ԫ�������ݵĶ���Ҳ��ͬС��,��·Ψһ�� trace id, ��������·�� parent id,��ʶ������ span id ��Щ�����Ƕ����첽��ɢ�ϱ��ɼ�������Ϣ,���ߵľۺϾۺ�����·�����Ƕ�����·�����ȵȡ�
��·��ϵͳ�ܹ���ģ�͵���ƿ��Ŷ����������,�Ҳ��������һЩ����:�������������·�ٵ�ʱ��,�뷨������ôһ����?ΪʲôҪ�ڵ�����·����Ԫ����?Ԫ���ݵ���Щ��Ϣ���DZ�Ҫ����?�������Ĵ�����Խ��뵽��·��ϵͳ��?ΪʲôҪ�첽��ɢ�ϱ�,���߾ۺ�?������·������ʲô��?
���Ÿ��ָ���������,���ҵ���Щ�ڶ���·�����������֮Դ �C ��Google Dapper�� ����,���Ұݶ���ԭ���Լ���ص��������ġ���Щ������������е��ɻ�
�ں�ģʽ̽��
����ѧ����Էֲ�ʽϵͳ��·״̬����̽��,��һ�ɵ�������Ϊ�ֲ�ʽϵͳ�����ÿ��Ӧ�û����м��,Ӧ����һ�����ں���,��·��ⲻӦ�����뵽Ӧ��ϵͳ���档�Ǹ�ʱ�� Spring ��û����������,���Ʒ�ת�������̵ļ���Ҳ�����Ǻ�����,�����Ҫ���뵽Ӧ�ô�������,��Ҫ�漰����Ӧ�ô���,���ڹ���ʦ��˵��������ż�̫��,��������·���߾ͻ�����ƹ㿪����
�������������Ӧ�������Ĵ���,�Ǿ�ֻ�ܹ���Ӧ�õ��ⲿ���ֽ�,��ȡ����¼��·��Ϣ�ˡ������ںںе�����,��·��Ϣ������ɢ����������������ΰ���Щ��·��������������Ҫ��������⡣
��Performance Debugging for Distributed Systems of Black Boxes��
��ƪ���ķ����� 2003 ��,�ǶԺں�ģʽ�µĵ���������̽��,�������������Ѱ����·��Ϣ���㷨��
��һ���㷨��Ϊ��Ƕ���㷨��,������ͨ������Ψһ id �ķ�ʽ,��һ�ο������õ����� (1 call)��·�뷵��(11 return)��·������һ���γ���·�ԡ�Ȼ��������ʱ����Ⱥ�˳��,�Ѳ�ͬ������·����ƽ�����������¼�����(�ο�ͼ1)��
ͼ1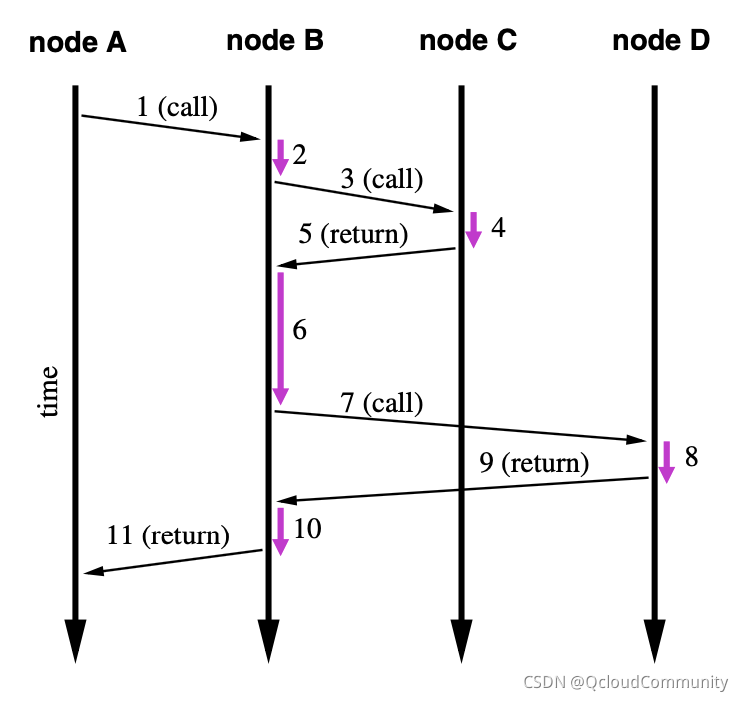
���Ӧ���ǵ��߳����,�����㷨����û��ʲô���⡣������Ӧ�������Ƕ��̵߳�,����ʹ�����ַ������ܺõ��ҵ���·���Ӧ��ϵ����Ȼ���������һ�ּǷְ�ͷ��ķ������Զ�һЩ�����������·��ϵ���г�Ȩ��,�������ַ�������һЩ�����첽 RPC ���õķ���,ȴ�����һЩ���⡣
����һ���㷨��Ϊ�������㷨��,��������·���ɶ�������·,Ȼ���ÿ��������·�Ե���һ��ʱ���ź�,ʹ���źŴ�������,�ҵ��ź�֮��Ĺ�����ϵ�������㷨�ô����ܹ���ʹ���ڻ����첽 RPC ���õķ����ϡ��������ʵ�ʵĵ�����·���ڻػ������,�����㷨�����ܹ��ó�ʵ�ʵĵ�����·,����ó�����������·�����������· A -> B -> C -> B -> A,�����㷨���˵ó��䱾��������·,����ó� A -> B -> A �ĵ�����·�����ij���ڵ���һ����·�ϳ��ִ������,��ô����㷨�ܿ��ܻ�ó����������ĵ�����·��
�ںں�ģʽ��,��·֮��Ĺ�ϵ��ͨ������ͳ�Ƶķ�ʽ�ж���·֮��Ĺ�����ϵ������ͳ��ʼ���Ǹ���,û�취��ȷ�ó���·֮��Ĺ�����ϵ��
��һ��˼·
��ô�����ܹ���ȷ�صó�������·֮��Ĺ�ϵ��?������ƪ���ľ�����һЩ˼·��ʵ����
Pinpoint: Problem Determination in Large, Dynamic Internet Services
ע:�� Pinpoint �� github �ϵ� pinpoint-apm
��ƪ���ĵ��о�������Ҫ��ӵ�в�ͬ����ĵ���Ӧ��,��Ȼ��Ӧ�ķ���Ҳ������չ���ֲ�ʽ��Ⱥ�С��������� Pinpoint �ܹ������Ҫ��Ϊ�����֡��ο� ͼ2,���� Tracing �� Trace Log Ϊ��һ����,��Ϊ�ͻ���������·��(Client Request Trace),��Ҫ�����ռ���·��־��Internal F/D ��External F/D �� Fault Log Ϊ�ڶ�����,�ǹ���̽����Ϣ(Failure Detection),��Ҫ�����ռ�������־��Statistical Analysis Ϊ��������,��Ϊ���ݾ������(Data Clustering Analysis),��Ҫ���ڷ����ռ���������־����,�ó����ϼ������
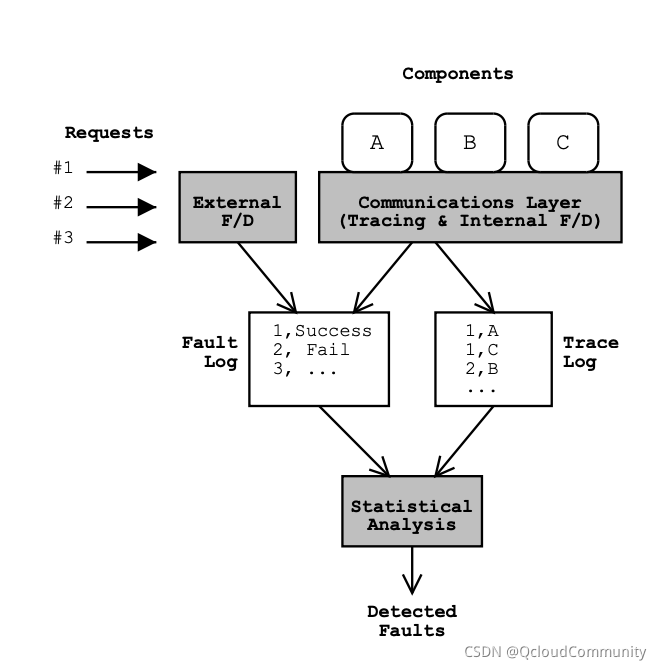
ͼ2
Pinpoint �ܹ���,�����һ���ܹ���Ч���������ھ�������������ݡ��� ͼ3 ��ʾ,ÿ��������·��Ϊһ����������,ʹ��Ψһ�ı�ʶ request id ���,���������Լ�¼�����������·�������ij������(Component)�Լ�����״̬(Failure)��
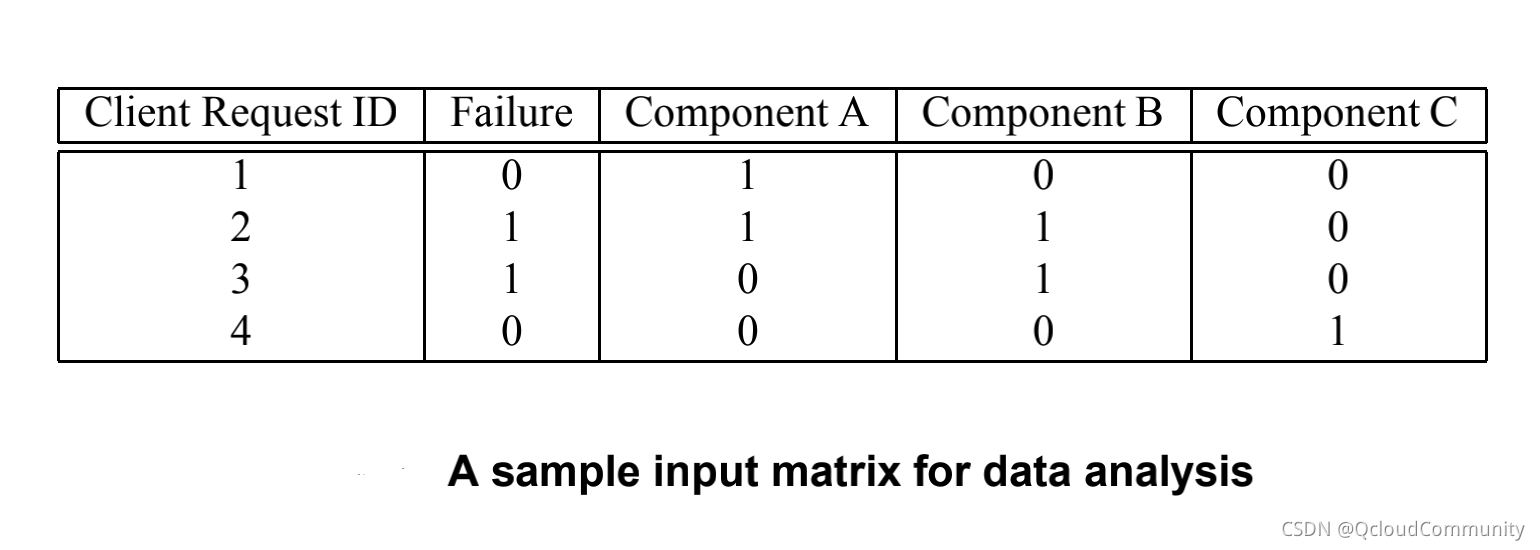
ͼ3
Ϊ���ܹ���ÿ�ε��õ���·��־ (Trace Logs) �� ������־ (Fault Logs) ����������,���ľ��� Java Ӧ��Ϊ����,����������ڴ�����ʵ����Щ��־�Ĺ����������� Pinpoint ʵ���½ڵ�һЩ�ؼ������:
��ҪΪÿһ���������һ�� component id
����ÿһ�� http ��������һ��Ψһ�� request id,����ͨ���ֲ߳̾�����(ThreadLocal)������ȥ
�������������������߳�,��Ҫ���̴߳�����,�� request id ����������ȥ
���������ڲ����� rpc ����,��Ҫ������˴���,�� request id ��Ϣ���� header,���ڽ��ն˽������ header ע�뵽�̱߳��ر���
ÿ�ε��õ�һ�����(component),��ʹ�� (request id, component id) ��ϼ�¼һ�� Trace Log
�� java Ӧ�ö���,�⼸���㼼��ʵ����,�����Ը�,Ϊ�ֽ���·��ϵͳʵ����·����,��·����(Propegation)�ṩ�˻���˼·��
��ƪ���ķ���ʱ���� 2002 ��,�Ǹ�ʱ�� java �汾�� 1.4,�Ѿ��߱����̱߳��ر���(ThreadLocal)������,���߳���Я����Ϣ�DZȽ����������ġ�������Ϊ���Ǹ�ʱ�������̻����Ǻ��ռ�(Spring ������ 2003��,javaagent ���� java 1.5 ���е�����,������2004��),���������ķ��������ܹ����㷺Ӧ�á������������,����������Ϊ��Щ�������ij���,��ʹ�� java ����������ļ���������
���¹���������·
X-Trace: A Pervasive Network Tracing Framework
��ƪ������Ҫ�о������Ƿֲ�ʽ��Ⱥ�����������·��X-Trace ������������չ�� Pinpoint ���ĵ�˼·,�����ܹ����¹�������������·�Ŀ�ܺ�ģ�͡�Ϊ�˴ﵽĿ��,���ж������������ԭ��:
�ڵ�����·��Я��Ԫ����(�ڵ�����·���ݵ�����Ҳ��֮Ϊ��������,in-bound data)
�ϱ�����·��Ϣ�������ڵ�����·��,�ռ���·��Ϣ�Ļ�����Ҫ��Ӧ�ñ�������(ע:���ڵ�����·�����������·����,Ҳ��֮Ϊ��������,out-of-bound data)
ע��Ԫ���ݵ�ʵ��Ӧ�����ռ������ʵ���ż
ԭ�� 1,2 ����������������ԭ��ԭ�� 1 ���Ƕ� Poinpont ˼·����չ,��·���ݴ�ԭ����request id ��չ�˸����Ԫ��,���� TaskID , ParentID , OpID ���� trace id , parent id, span id ��ǰ����span �������Ҳ�� X-Trace ���ĵ� Abstract �������,Ҳ���� Dapper ������ X-Trace ���������ǵ�һ���¾���
�����ٿ��� X-Trace ��Ԫ���ݵ����ݶ���:
Flags
һ��bit����,���ڱ�� TreeInfo ,Destination,Options �Ƿ�ʹ��
TaskID
ȫ��Ψһ��id,���ڱ�ʶΨһ�ĵ�����
TreeInfo
ParentID - ���ڵ�id,��������Ψһ
OpID - ��ǰ����id,��������Ψһ
EdgeType - NEXT ��ʾ�ֵܹ�ϵ,DOWN ��ʾ���ӹ�ϵ
Destination
����ָ���ϱ���ַ
Options
Ԥ���ֶ�,������չ
���˶�Ԫ���ݵĶ���,���Ļ�������������·�����IJ���,�ֱ��� pushDown() �� pushNext()��pushDown()��ʾ����Ԫ���ݵ���һ�㼶,pushNext() ���ʾ�ӵ�ǰ�ڵ㴫��Ԫ���ݵ���һ���ڵ㡣
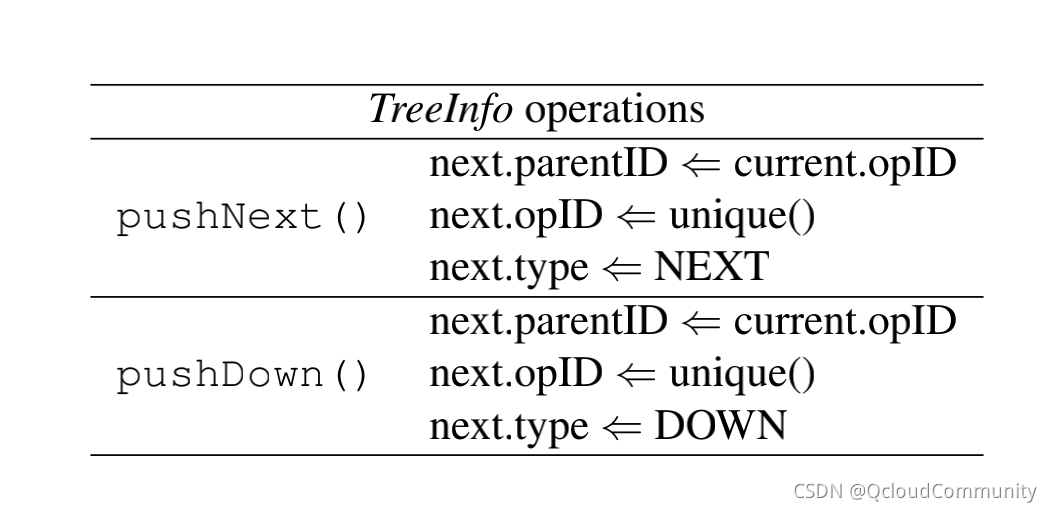
ͼ4 pushDown() �� pushNext() ��α����
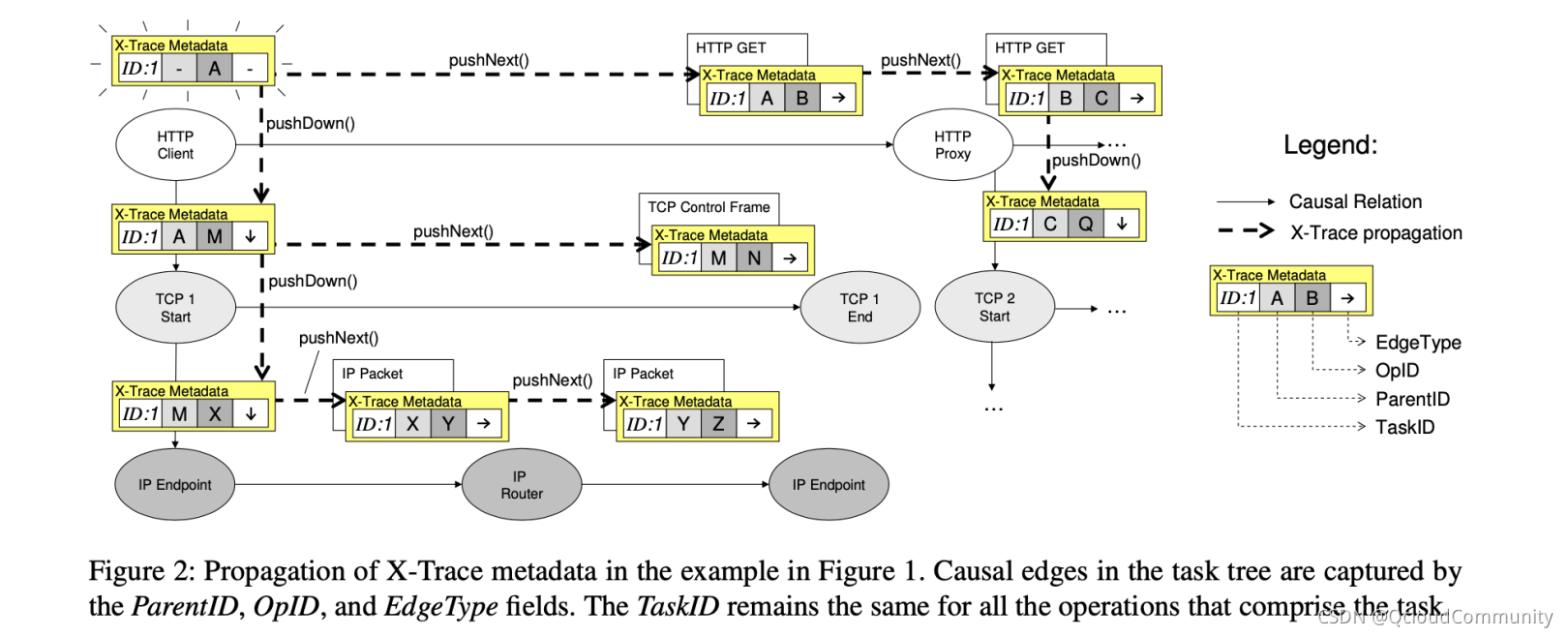
ͼ5 pushDown() �� pushNext() �����ڵ�����·�е�ִ�е�λ��
�� X-Trace �ϱ���·���ݵĽṹ�����,��ѭ�˵� 2 �����ԭ���� ͼ6 ��ʾ, X-Trace ΪӦ���ṩ��һ�������Ŀͻ��˰�,ʹ��Ӧ�ö˿���ת����·���ݵ�һ�����ص��ػ����̡������ص��ػ��������ǿ���һ�� UDP Э��˿�,���տͻ��˰�������������,�����뵽һ���������档���е�����һ���������·���ݵľ������������Ϣ,���͵���Ӧ�ĵط�ȥ,Ҳ����һ�����ݿ�,Ҳ����һ������ת�����������ռ�������������ݾۺϷ���
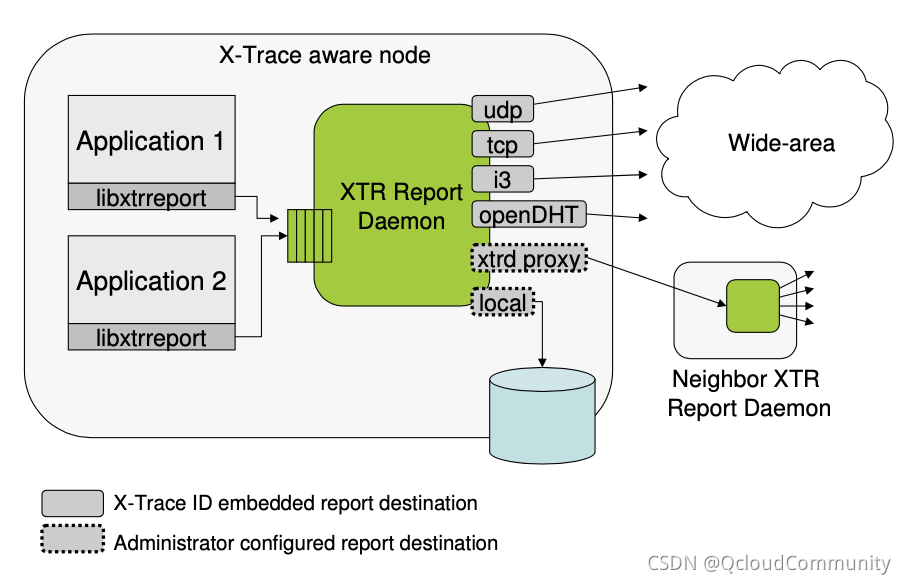
ͼ6
X-Trace �ϱ���·���ݵļܹ����,�����������ϵ���·��ʵ�����Ų�С��Ӱ�졣���� Zipkin �� collector �Լ� Jeager �� jaeger-agent,�����ܹ����� X-Trace ��Ӱ�ӡ�
X-Trace ���������ԭ���ڴ������ݵĶ��塢Ԫ���ݴ����������塢��·�����ϱ��ܹ���,�����ֽ���·��ϵͳ������������ݡ����� Zipkin �� collector �Լ� Jeager �� jaeger-agent,�Ͷ����ܹ����� X-Trace ��·�����ϱ��ܹ���Ӱ�ӡ�
���ģ����ʵ�� �C Dapper
Dapper, a Large-Scale Distributed Systems Tracing Infrastructure
Dapper �ǹȸ��ڲ����ڸ����������ṩ���ӷֲ�ʽϵͳ��Ϊ��Ϣ��ϵͳ��Dapper �������ǽ��ܹȸ������ֲ�ʽ��·�ٻ�����ʩ��ƺ�ʵ���ľ��顣Dapper ���ķ�����2010��,�������ĵı���,Dapper ϵͳ�Ѿ��ڹȸ��ڲ��������ʵ�������ˡ�
Dapper ϵͳ����ҪĿ���Ǹ��������ṩ�ṩ���ӷֲ�ʽϵͳ��Ϊ��Ϣ�����з���Ϊ��ʵ��������ϵͳ,��Ҫ���ʲô�������⡣��������Щ��������������������������:��Χ����ͳ����Եļ�ء�����������������Ҫ��,�����������������Ŀ��:
�Ϳ���(Low overhead):��·��ϵͳ��Ҫ��֤�����߷���ĵ�����Ӱ���������Բ��Ƶij̶ȡ���ʹ�Ǻ�С�ļ������Ҳ���һЩ�߶��Ż����ķ����пɾ����Ӱ��,������ʹ�����Ŷӹر���ϵͳ��
Ӧ�ü�����(Application-level transparecy):�����߲�Ӧ�ø�֪����·����ʩ�������·��ϵͳ��Ҫ����Ӧ�ü�������Э�����ܹ�����,��ô�����·����ʩ���÷dz�����,���Ҿ�������Ϊ bugs �������������������������Υ���˴�Χ������������
��������(Scalability):��·��ϵͳ��Ҫ�ܹ����� Google δ������ķ���ͼ�Ⱥ�Ĺ�ģ��
��Ȼ Dapper ����Ƹ����� Pinpoint�� Magpie�� X-Trace ����������ͨ��,���� Dapper Ҳ���Լ���һЩ��������ơ�����һ�����Ϊ�˴ﵽ�Ϳ��������Ŀ��,Dapper ��������·�����˲����ռ������� Dapper �ڹȸ��ʵ������,�������ೣ�õij���,��ʹ�� 1/1000 ��������в����ռ�,Ҳ�ܹ��õ��㹻����Ϣ��
����һ���������ص�������ʵ�ַdz��ߵ�Ӧ�����ȡ���������� Google Ӧ�ü�Ⱥ�����бȽϸߵ�ͬ�ʻ�,���ǿ�����·����ʩʵ�ִ��������������ĵײ������Ҫ��Ӧ���������Ӷ����ע����Ϣ���ٸ�����,��Ⱥ��Ӧ�����ʹ����ͬ�� http �⡢��Ϣ֪ͨ�⡢�̳߳ع����� RPC ��,��ô�Ϳ�����·����ʩ��������Щ����ģ�����档
��ζ�����·��Ϣ��?
�������Ⱦ���һ���ĵ���������,�� ͼ7 ,������Ϊ��һ���������ֲ�ʽ����Ҫ�ռ���Ϣ��ʶ�����Լ���Ϣ��Ӧ���¼���ʱ�䡣���ֻ���� RPC �����,������·��������Ϊ�� RPCs Ƕ��������Ȼ,�ȸ��ڲ�������ģ��Ҳ�������� RPCs ���á�
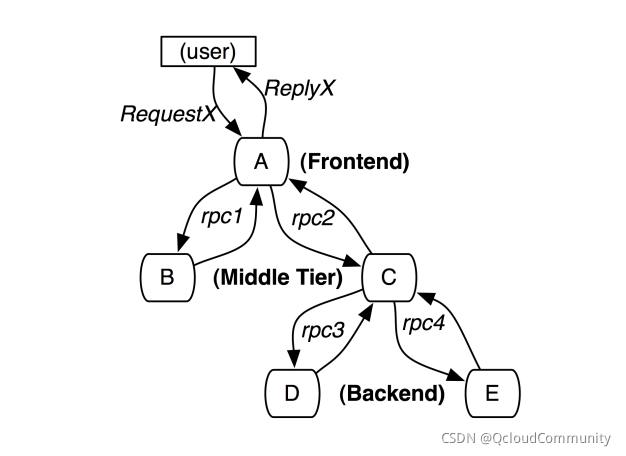
ͼ7
ͼ8 ������ Dapper �����Ľṹ,���Ľڵ�Ϊ������Ԫ,��֮Ϊ span������Ϊ���� span ֮������ӡ�һ�� span ���Ǽ�����ֹʱ�����RPC ��ʱ����Ӧ����ص�ע����Ϣ��Ϊ�����¹��� Dapper ����,span ����Ҫ����������Ϣ:
span name: �����Ķ�������,��ͼ8�е� Frontend.Request
span id: һ��64bit��Ψһ��ʶ��
parent id: �� span id

ͼ8
ͼ9 ��һ�� RPC span ����ϸ��Ϣ��ֵ��һ�����,һ����ͬ�� span ���ܰ��������������Ϣ��ʵ����,ÿһ�� RPC span �������˿ͻ��˺ͷ���˴�����ע�͡����ڿͻ��˵�ʱ����ͷ���˵�ʱ������Բ�ͬ������,������Ҫ�쳣��ע��Щʱ����쳣�����ͼ9 ��һ�� span ����ϸ��Ϣ

ͼ9
���ʵ��Ӧ�ü�����?
Dapper ͨ����һЩͨ�ð����Ӳ�����,��Ӧ�ÿ�����������ŵ������ʵ���˷ֲ�ʽ��·��,��Ҫ������ʵ��:
��һ���߳��ڴ�����·��·����ʱ,Dapper ����������Ĺ������̱߳��ش洢������������һ��С���������Ƶ� span ��Ϣ���ס�
�������������ӳٵĻ���һ����,���ȸ迪����ʹ��ͨ�ÿ�������������ص�����,��ʹ���̳߳��̳߳ػ�������ִ���������ȡ����� Dapper �Ϳ��Ա�֤���еĻص��������ڴ�����ʱ��洢��������,�ڻص�������ִ�е�ʱ���������Ĺ�������ȷ�߳����档
Google �������е��߳���ͨ�Ŷ��ǽ�����һ�� RPC ��ܹ�����,���� C++ �� Java ��ʵ�֡�����������˲���,���ڶ������� RPC ������� span���ڱ����ٵ� RPC,span �� trace �� id ��ӿͻ��˴��ݵ�����ˡ��� Google ����Ƿdz���Ҫ�IJ����㡣
��β
Dapper ���ĸ����������Ķ������������ⶨλ������ģ����ơ�Ӧ�ü����IJ���ʵ���Լ��Ϳ�������Ʒ���,Ϊ��·���ڹ�ҵ��Ӧ�õ�ʹ������˲����ϰ�,Ҳ�����˲��ٿ����ߵ���С��Դ� Google Dapper ���ij���֮��,���ٿ������ܵ����ĵ�����,�������˸�ʽ��������·��,2012 �����ؿ�Դ Zipkin��Naver ��Դ Pinpoint,2015 �����ɿ�Դ Skywalking,Uber ��Դ Jaeger �ȡ��Ӵ���·�ٽ����˰ټ�������ʱ����

��ӭ���һ�����ġ��Ƽ���ר��,��ȡ���ྫƷ���ݡ�
���ƶ˼�������,����ָ���Խ�