һ���ܽ�
�Ȿ��ͦ�õ�,���Ƕ�ˢ�˰�,���濴��һ��,Ȼ��д��ƪ�����ִ�ͷ����һ��,��һЩ��Ҫ��֪ʶ���¼������
ԭ������ͦ��,�������ݺ����ǿ�״��,�������⼸�´��Ž���,��������Ϊvloatile������CAS��JMM��Щ��ϵ�ȽϽ���, ���䲻���Ǿ���,�Ƽ����������ȥ����Java�������ʵս��,��Ϊ�DZ�����û����ôϸ,ƫ������
�漰
- ������̵���ս
- �������Ƶĵײ�ʵ��
- ����������Ա�
- Java�ڴ�ģ��
- Java��������
- Java���������Ϳ��
- Java�е�13��ԭ�Ӳ�����
- Java�е��̳߳�
- Executor���
��������
1��������̵���ս
�������л�
- ��ʹ�ǵ��˴�����Ҳ֧�ֶ��̴߳�������,��Ϊcpu���ÿ���̷߳���ʱ��Ƭ,��ͣ���л��߳�,�����Ǹо��߳�����ͬʱִ�е�
- ���߳��л���ǰ,��Ҫ������һ���߳������״̬,�Ա���һ�������л����������,��������ӱ��浽�ڼ��صĹ��̾��������������л�
��α����������л�
- �������:���߳̾�������ʱ��,���������л�,��˿���ʹ�ò��ñ������ķ������ж��̴߳�������,�罫���ݵ�ID����hash֮��ֶ�,��ͬ���̴߳�����ͬ�ֶε�����
- CAS�㷨:����������CompareAndSwap
- ʹ�������߳�:��������̫�ٴ������߳�̫��,����ʹ��jstack����鿴WAITTING״̬���߳�
- ʹ��Э��:�ڵ��߳���ʵ�ֶ��������,���ڵ��߳���ά�ֶ���������л�
ʵ������
package henu.soft.xiaosi.third.test;
public class DeadLock {
private static String A = "xiaosi";
private static String B = "henu";
public static void main(String[] args) {
new DeadLock().deadLock();
}
public void deadLock(){
Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
synchronized (A){
try {
System.out.println(Thread.currentThread().getName() + "�õ�A");
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (B){
System.out.println(Thread.currentThread().getName() + "�õ�A���Ի�ȡB");
}
}
}
},"t1");
Thread t2 = new Thread(new Runnable() {
@Override
public void run() {
synchronized (B){
try {
System.out.println(Thread.currentThread().getName() + "�õ�B");
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (A){
System.out.println(Thread.currentThread().getName() + "�õ�B���Ի�ȡA");
}
}
}
},"t2");
t1.start();
t2.start();
}
}
2���������Ƶײ�ʵ��ԭ��
����
- Java�����ڱ�������Java�ֽ���,�ֽ��뱻����������ص�JVM��,JVMִ���ֽ���,������Ҫת��Ϊ���ָ����CPUִ��
- Java����ʹ�õIJ�������������JVM��ʵ�ֺ�CPU��ָ��
volatile�Ķ���
- ��Java���Թ淶�������ж�volatile�Ķ�������:Java������������̷߳��ʹ�������,Ϊ��ȷ������������ȷ��һ�µĸ���,�߳�ȷ��ͨ��������������ȡ���������������˼���ǵ�����valatile����Ӧ��������������,���ڶ���߳�д,Ӧ�ü�������������(synchronized��Lock��)
- volatile����������synchronized,��֤�ɼ���,��ָֹ������,����֤ԭ����(�Ե���������˵��֤����дԭ����,���ǶԸ��ϲ�������volatile++����֤)
- ����ʹ�����synchronized���Խ��ͳɱ�,��Ϊ�����������������л��͵���
volatile�ɼ��Ե�ʵ��ԭ��
- ����ĵ�cpu,ÿ�������ڲ������Լ��� ������(��������Ϊ�Ĵ���,������ȥ�ڴ������,����֮����ͬ�������ڴ�)
- ��volatile���εĹ��������ڽ���д����ʱ�����ֵڶ��л�����,��
lock add xxx,���ָ���ڶ�˴������ᴥ��������,Ҳ���DZ�֤�������ĵĻ���һ���� - 1������ǰ���������������� ��д��ϵͳ�ڴ�
- 2�����д���ڴ�IJ�����ʹ������CPU�ﻺ��ĸ��ڴ��ַ��������Ч,ÿ�����Ļ�ϵ���̽�����ϴ���������,����Լ��Ļ���ֵ�Dz��ǹ�����,�����˾�Ҫ���´��ڴ���ȥ
ע��
- ��������������ٽ�������ִ�о���ԭ����,����ζ�ż�ʹ��64λ��long��double���ͱ���,ֻҪ����volatile����,�Ըñ����Ķ���д�;���ԭ����,����ǶԶ��volatile������������volatile++�ĸ��ϲ���,��Щ���������ϲ�����ԭ����
- �����֮,volatile���пɼ���(�����������,���������һ���߳�д֮��)��ԭ����(���������Ķ���д,�����漰���ϲ���)
synchronized����
- ������ͨͬ������,�����ǵ�ǰʵ������
- ���ھ�̬ͬ������,���������Class����
- ����ͬ��������,������Synchronized���������õĶ���
��һ���̷߳���ͬ�������ʱ��,�����ȵõ���,�˳������׳��쳣ʱ�����ͷ���,���洢������?��������Щ��Ϣ?
- JVM���ڽ�����˳�Monitor������ʵ�ַ���ͬ���ʹ����ͬ��,�������ߵ�ʵ��ϸ�ڲ�һ��
- �����ͬ��ʹ�õ���monitorenter��monitorexitָ��ʵ�ֵ�,monitorenterָ�����ڱ�������ͬ�������Ŀ�ʼλ��,��monitorexit�Dz��ڷ����������쳣��,������ָ�������Գ���
- ����ͬ����ʹ������һ�ַ�ʽʵ�ֵ�,JVM�淶��û��˵��,���Ƿ�����ͬ����Ҳ����ʹ��������ָ��ʵ��,ÿ��������һ��monitor��֮����,����һ��monitor�����к�,������������״̬,�߳�ִ�е�monitorenterָ���ʱ��,���᳢�Ի�ȥ��������Ӧ��monitor������Ȩ,���Ի�ȡ������
Java����ͷ
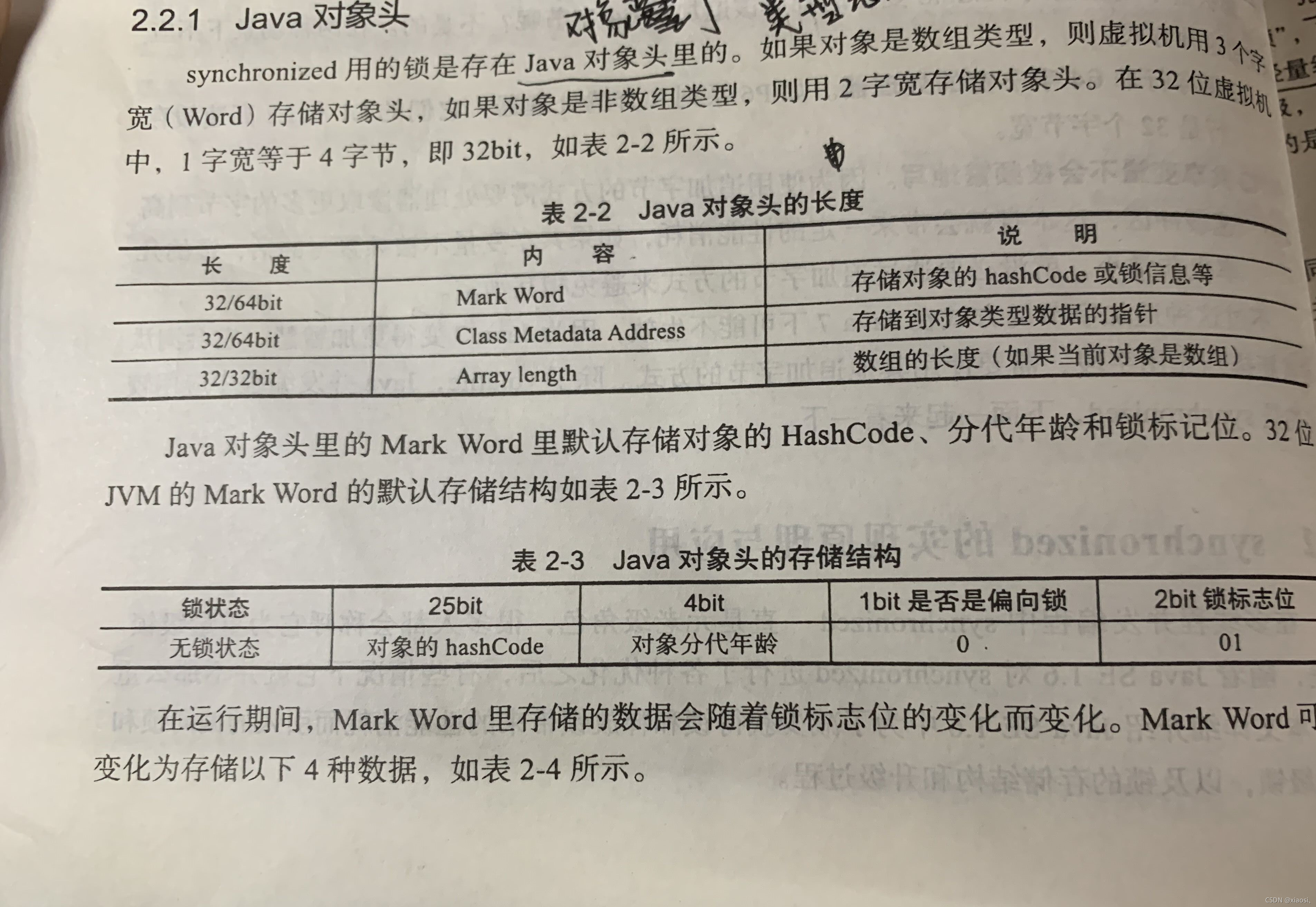
- ����ͷ�Ĵ洢������:Mark Word��Class Metadata Address ��Array length(���������)
- synchronized�õ����Ǵ���Java����ͷ���Mark Word�����,Ҳ�����ڶ����Ķ���ʵ���ڴ���ַ�ռ�,�洢����Ϣ��hashCode���ִ����䡢����Ϣ��
- �������ڼ�,Mark Word����洢�����ݻ���������־λ�ı仯���仯
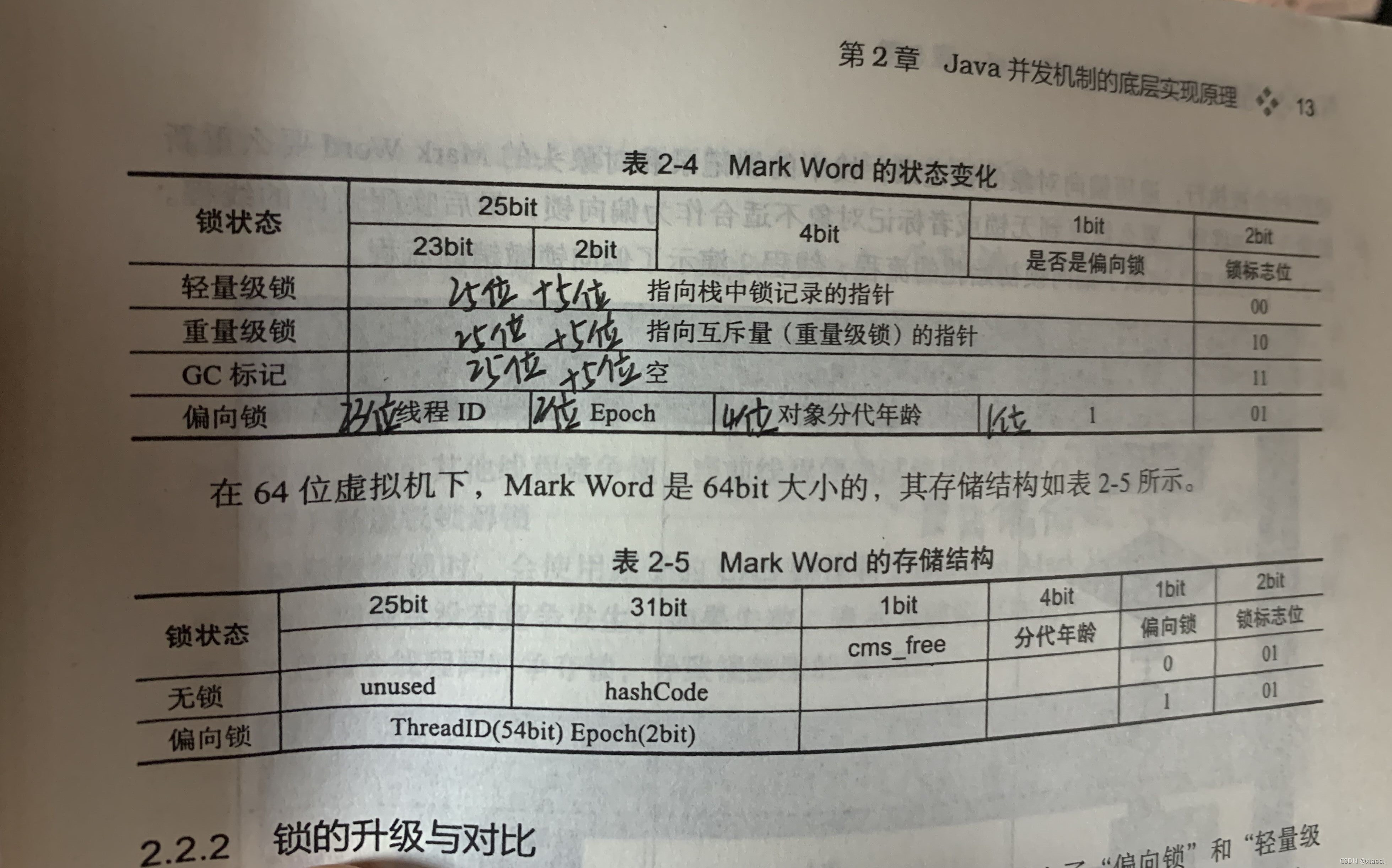
3������������Ա�
ƫ����
- HotSpot�������о�����,����������,���������ڶ��߳̾���,����������һ���̶߳�λ��,Ϊ�����̻߳�����Ĵ��۸��ʹӶ�������ƫ����,ע��ƫ����ֻ��������־λΪ
01,Ҳ��������������²Ż������á� - ��һ���̷߳���ͬ���鲢�����(��ʼΪ����״̬,
����־λΪ01,�߳̽�����ƫ����,��ƫ������־λ0Ϊ1),��������ͷ��ջ֡������¼����CAS�洢ƫ����߳�ID,�Ժ��߳̽�����˳�ͬ���鲻��Ҫ����CAS�����������ͽ���,ֻҪ�IJ���һ�¶���ͷ��Mark Word���Ƿ�洢��ǰ�̵߳�ƫ����(�ȶ�Mark Word �� ջ֡����¼���߳�ID�Ƿ�һ��,Ҳ�����Ƿ����Լ��õ�����)- ���Գɹ�,��ʾ��ǰ�̻߳�ȡ����
- �������ʧ��,CAS�����滻Mark Word ʧ�ܺ�,(Ҳ�����Լ���Ϊ�µ��߳̾�����,Mark Word��ƫ����ƫ����߳�IDָ�IJ����Լ�),����Ҫ�ڲ���һ��Mark Word��ƫ�����ı�־�Ƿ����ó�1(Ҳ���DZ�ʾ��ǰ��ƫ����)
- 1��ƫ������־λ�����0,֤�������̻߳��ڳ���ƫ����,֤������ƫ���������߳���Ҫ����ƫ����,��֮ͣǰ����ƫ�������߳�,��Mark Word��Ϊ��ƫ����״̬
0,֮����Ҫʹ��CAS����; - 2��ƫ������־λ�����1,֤����֮ǰ����ƫ�����߳��Ѿ��������,���ĵ�ǰƫ���߳�,��Mark Word���߳�ID��Ϊ�µ��߳�(��ʱ֮ǰ�������߳̿����Ѿ�ִ�����,�Ӷ�����Ҫƫ����,�Լ����̻߳��ƫ����)
ƫ�����ij���(����)
- ƫ����ʹ�õ��ǵȴ����־����Ż��ͷ����Ļ���,���Ե������̳߳��Ծ���ƫ������,����ƫ�������̲߳Ż��ͷ���,����־Ϊ����Ϊ0,�����:A�߳��Ƚ�ȥͬ����,���ƫ����,���ǻ�ûִ����,��ʱB�߳̽��뾺����
- �̳߳��־���,�߳�A��Ҫ�ȵ�ȫ�ְ�ȫ��(���ʱ��û������ִ�е��ֽ���)������������ͣӵ��ƫ�������߳�A,Ȼ�������ƫ�������߳�A�Ƿ�����
- ��������,����ͷ����Ϊ����״̬,���֮ǰ��ƫ���߳�A��ID,������־Ϊ
01,ƫ������־Ϊ1,��ǰ�߳�A�������������Dz���������,�����߳�B�����»��ƫ������ - ������,ӵ��ƫ������ջ�ᱻִ��,����ƫ����������¼,ջ�е�����¼ �� Mark Word
- 1��ƫ����ƫ�������߳�:A�߳��Ƚ�ȥͬ����,���ƫ����,���ǻ�ûִ����,��ʱB�߳̽��뾺��,����Aʣ�µ�ִ���Ѿ�����Ҫ��,������ͬ�����Ѿ�ִ�����,����B�̻߳�ȡƫ����
- 2��Ҫô����ƫ����������:A�̺߳�B�̶߳�����,��Ҫ����ƫ����,���������,����Ϊ��������
- ��������,����ͷ����Ϊ����״̬,���֮ǰ��ƫ���߳�A��ID,������־Ϊ
�ر�ƫ����
- ƫ������Java 6 �� Java7 ��Ĭ�������õ�,�������ڳ�������������֮��ż���
- ����б�Ҫ����ʹ��JVM�������ر��ӳ�
--XX:BiasedLockingStartupDelay=0 - �����ͨ������¶����ھ���״̬,��ô���Թر�ƫ����
-XX:-UseBiasedLicking=false,��ô�����Ĭ�Ͻ�������������
��������
-
�߳���ִ��ͬ�������֮ǰ,JVM�������ڵ�ǰ�̵߳�ջ֡�д������ڴ洢������¼�Ŀռ�,��������ͷ�е�Mark Word���Ƶ�ջ֡������¼��,�ٷ���ΪDisplaced Mark Word��
-
�̻߳�ȡ��������:Ȼ���̳߳���ʹ��CAS������ͷ�е�Mark Word �滻Ϊָ�� ��ǰ�߳�ջ֡����¼�� ָ��(��ַ),����־λ��������
01��Ϊ����������00- 1������ɹ�,��ʾû�о���,��ǰ�̻߳����
- 2�����ʧ��,��ʾ��ǰ�����ھ���,���ҳ��������������̻߳�û����,��ǰ�߳�����CAS����(Ҳ��������һ��ʱ��ȴ������ͷ�)�����,����ʧ��֮��,�ͻ���Mark Word��
����־λ00-->10,������Ϊ��������,Ȼ��ǰ�߳̾ͻ�����
-
���������������߳�CAS����:ʹ��ԭ��CAS������Displaced Mark Word�滻������ͷ
- 1������ɹ�,��ʾû�о���,˳������
- 2�����ʧ��,��ʾ��ǰ�����ھ���,������������ʧ�ܵ��߳��Ѿ�����Mark Word,��ʱ�Ѿ�����������,�ͷ���,�������������߳�
����
- 0��Mark Word��ʼ��ʶ����״̬
- 1���߳�A��B�̷߳���ͬ����(��Ϊһ��ʼ�ʹ��ھ���,ƫ�����ܿ�����Ϊ��������,A��B�̷߳���ջ�ռ䲢����Mark Word)
- 2��A�߳�����B�߳�CAS�ɹ�����Mark Word,Ҳ���ǻ�ȡ����������,��־������Mark Word����Ϊָ���߳�ջA֡����¼��ָ��(��ַ)
- 3��B�߳̽��Ž���CASҲ���滻Mark Wordָ���Լ��߳�B��ָ��(��ַ),Ҳ����Ҳ������������,����A�߳��Ѿ�����Mark Word,����B�߳�CASʧ��(������10��,����A�̻߳���ռ����,�ͻ�����ʧ��)
- 4�����ʱ���߳�B����ʧ�ܷ��ִ��ھ���,�������߳�A��û�ͷ���,���ͽ�������,��Ϊ��������,��־����B�߳���Mark Word������Ϊָ������������־,Ȼ��B�߳̽�������
- 5����ʱ�߳�Aִ����ͬ�������CAS�ͷ���������ʱ����ȻҲ��ʧ��,��Ϊ�߳�B�Ѿ�����Mark Word,Ȼ���߳�A���ͷ���,���������������߳�B,��ʼ���¾�����������
- Ϊ�˱������õ�����(�����ȡ�����̱߳�������),һ��������Ϊ��������,�Ͳ����ٻָ�����������,����������������״̬,�����߳���ͼ��ȡ����ʱ��,���ᱻ����ס,�����������߳��ͷ���֮��,�ỽ�������������¾�����������
������ȱ��Ա�
- ƫ����
- �ŵ�:�����ͽ�������Ҫ���������,�൱��ִ�з�ͬ���ķ���
- ȱ��:����̼߳����������,����������������������(���ھ����ͳ�����)
- ���ó���:������ֻ��һ���̷߳���ͬ����ij���
- ��������
- �ŵ�:�������̲߳��ᱻ����,����˳������Ӧ�ٶ�
- ȱ��:���ʼ�յò������������߳�,ʹ������������cpu
- ���ó���:����Ӧʱ��,ͬ����ִ���ٶȷdz���
- ��������
- �ŵ�:�߳̾�����ʹ������,��������CPU
- ȱ��:�߳�����,��Ӧʱ�仺��
- ���ó���:��������,ͬ����ִ��ʱ��ϳ�
�ο�:https://segmentfault.com/a/1190000022904663
Java���ʵ��ԭ�Ӳ���
- ʹ����:�����Ʊ�֤��ֻ�л���������̲߳��ܹ������������ڴ�����,JVM�ڲ�ʵ���˺ܶ���������,��ƫ���������������ͻ�����������ƫ����,JVMʵ�����ķ�ʽ��������ѭ��CAS,����һ���߳������ͬ�����ʱ��ʹ��ѭ��CAS����ȡ��,�˳�ͬ�����ʱ��,ʹ��CAS�ͷ���
- ʹ��ѭ��CAS:��Java1.5ʱ��,JDK�IJ��������ṩһЩ����֧��ԭ�Ӳ���,��AtomicBoolean��AtomicInteger��AtomicLong��
CASʵ��ԭ�Ӳ�������������
- ABA����:
- 1����ΪCAS��Ҫ�ڲ���֮��ʱ��,���ֵ�Ƿ�仯,���û�з����仯�����,�������һ��ֵ�仯A�C>B�C>A,��ʱ��ʹ��CAS���м���ʱ��ᷢ������ֵû�б�,����ʵ����ȴ���ˡ�
- 2�����:ʹ�ð汾��,�ڱ���ǰ�����ϰ汾��,ÿ�θ��¶��Ѱ汾�ż�1,��ôA�C>B�C>A�ͻ���1A�C>2B�C>3C,��Java1.5��ʼ,JDK��Atomic�������ṩ��һ����AtomicStampedReference�����ABA����,������compareAndSet���������������ȼ�鵱ǰ�����Ƿ����Ԥ������,����鵱ǰ��־�Ƕ�����Ԥ�ڱ�־,���ȫ�����,����ԭ�ӷ�ʽ�������úñ�־��ֵ����Ϊ�����ĸ���ֵ
- ѭ��ʱ�䳤������
- 1������CAS�����ʱ�䲻�ɹ�,���CPU�����dz�����,���JVM�ܹ�֧�ִ������ṩ��pauseָ��,��ô�����ӳ���ˮ��ִ��ָ��,���ҿ��Ա������˳�ѭ����ʱ�����ڴ�˳���ͻ������CPU��ˮ�߱����,�Ӷ����CPU��Ч�ʡ�
- ֻ�ܱ�֤һ������������ԭ�Ӳ���
- 1�����ڶ��������������ʱ,���ʱ��Ϳ�������,����һ�ּ���ֵ����������ϳ�һ����������,��JDK1.5֮��,�ṩ��AtomicReference������֤���ö���֮���ԭ����,�Ϳ��Ѷ����������һ���������CAS����
4��Java�ڴ�ģ��
�������ģ�͵������ؼ�����
- �߳�֮�����ͨ��:�����ڴ�(��ʽͨ��)����Ϣ����(��ʾͨ��)
- �߳�֮�����ͬ��:���Ʋ�ͬ�̼߳����������ԵĻ���
Java�IJ������õ��ǹ����ڴ�ģ��,ͨ��������ʽ���е�,�ڴ�ģ�͵ij���ṹ
- ���е�ʵ����̬�������Ԫ�ض����ڶ��ڴ���,���̹߳���
- �߳�֮���ͨ����JMM����,�������߳�����֮��ij����ϵ
- �ӳ���ĽǶȿ�,JMM�������̺߳����ڴ�֮��ij����ϵ:�߳�֮��Ĺ��������洢�����ڴ���,ÿ���̶߳���һ��˽�б����ڴ�,�����ڴ�洢�˸��߳��Զ���д���������ĸ���,�����ڴ���JMM��һ���������,��������ʵ����,�������˻��桢д���������Ĵ����Լ�������Ӳ���ͱ������Ż�
������:��ִ�г���ʱ,Ϊ���������,�������ʹ�����������ָ����������,��Ϊ����
- (������)�������Ż���������:�������ڲ��ı䵥�̳߳���������ǰ����,�������°�������ִ��˳��
- (������)ָ����е�������:�ִ�����������������ָ����м�����������ָ���ص�ִ�С��������������������,���������Ըı�����Ӧ����ָ���ִ��˳��
- (������)�ڴ�ϵͳ��������:���ڴ�����ʹ�û���Ͷ���д������,��ʹ�ü��غʹ洢��������ȥ������������ִ��
���������:Դ���롪>1���������Ż���>2��ָ�����������>3���ڴ�ϵͳ������>����ִ�е�ָ������,��Щ��������ܻᵼ�³�������ڴ�ɼ�������
- 1�����ڱ�����,JMM�ı����������������ֹ�ض����͵ı�����������(�������еı�����������Ҫ��ֹ,���Ǵ������������Ե�һ��Ҫ��ֹ)
- 2�����ڴ�����,JMM�Ĵ���������������Ҫ��Java������������ָ������ʱ,�����ض����͵��ڴ�����(Memory Barriesָ��),ͨ���ڴ�����ָ������ֹ�ض����͵Ĵ�����������
������������������(�ӵ��������������ǵ������ڵĻᱻ����������������������������)
- ��
- д��д
- ����д
as-if-serial����(������ô������,���̳߳����ִ�н�����ܱ��ı�)
- ����������������runtime����������as-if-serial����
- �����������ı���������������runtimeΪ���̵߳ij���Ա����һ���þ�:���̳߳����ǰ��ճ����˳����ִ�е�,���������߲�����������Խ����Ӱ��
- as-if-serial��֤�����̳߳����������,happens-before��֤��ȷͬ���Ķ��߳�ִ�н������ı�
�ڶ��߳���,�Դ��ڿ��������IJ���������,Ҳ���ܻ�ı�����ִ�н��
- ˳��һ����ģ��:���뻯��ģ��
- 1��ͬ�������(ʹ��һ�Ѽ�������),�ϸ���ִ��A1��>A2��>A3��>B1��>B2��>B3
- 2��δͬ���������,����ΪB1��>A1��>A2��>B2��>A3��>B3,���е��߳����忴�����������,�����ܿ���һ��һ�µ�����ִ��˳��,֮�����ܵõ������ı�֤,��Ϊ˳��һ�����ڴ�ģ���е�ÿ�����������������߳̿ɼ�
- ������JMM�о�û�������֤,
- 1��δͬ���ij�����JMM�в��������ִ��˳���������,���������߳̿����IJ���ִ��˳��Ҳ���ܲ�һ�¡����統ǰ�߳�д���ݵ�������,��ûˢ������,��ô�Ͷ������̲߳��ɼ���
- 2��ͬ���ij���(����synchronized),�����ٽ������ڵĴ������������(���Dz������ٽ����Ĵ��� ���ݳ� �ٽ���֮��,�������ƻ�������������),JMM�����˳��ٽ����������ٽ����������ؼ�ʱ�����һЩ�����,ʹ���߳���������ʱ��������˳��һ����ģ����ͬ���ڴ���ͼ
����δͬ���Ķ��̳߳���,JMMֻ�ṩ��С�İ�ȫ��:
- �߳�ִ��ʱ��ȡ����ֵ,Ҫô��֮ǰij���߳�д���ֵ,Ҫô����Ĭ��ֵ(0,null,False),������ֶ�ȡ����ֵ������������(Out Of Thin Air)��ð����
- Ϊ��ʵ����С�İ�ȫ��,JVM�ڶ��Ϸ������ʱ��,���Ȼ���ڴ�ռ��������,Ȼ���������������
- JMM����֤��64λ��long�ͺ�double�͵ı���д��������ԭ����,��32λ�Ĵ�������,64λ��д�����ᱻ���Ϊ����32λ��д����,��������32λ��д�����ᱻ���䵽��ͬ��д������ִ��,��64λ���ݵĶ�����ȷ��һ��������,������ɶ�����嵽����д����֮�����ֻ�������˸�32λ����Ч���ݡ�
- ��ͬ�� ˳��һ����ģ�������ٲ÷�ʽͬʱֻ����һ������������д���ݵ��ڴ档�����32λ�Ĵ�������,Ҫ���64λ���ݲ�������ԭ������Ҫ�Ŀ����dz���,���JVM�������Dz�ǿ���64λ�ͱ�����д��������ԭ����
- ��JSR-133֮��,Ҳ����JDK1.5֮��,����ֻ������һ��64λ��long��double�ͱ�����д�������Ϊ����д����,����������Ҫ��ԭ����
ע��
- JMM�������Լ�����ڴ�ģ��,��ȷ����ͬ�ı������Ͳ�ͬ�Ĵ�����ƽ̨֮��,ͨ����ֹ�ض����͵ı�������������������,Ϊ����Ա�ṩһ�µ��ڴ�ɼ��Ա�֤
- �ִ��Ĵ�����ʹ��д��������ʱ���������ڴ�д�������,д���������Ա�ָ֤����ˮ�ߵij�������,�����Ա������ڴ������ȴ����ڴ�д�����ݲ������ӳ�(��Ϊ�������ٶȿ�),ͬʱ�������������ķ�ʽˢ�»�����,�Լ��ϲ�д�������ж�ͬһ��ַ�Ķ��д��
- ����ÿ���������ϵ�д������,���Ե�ǰ�������Լ��ɼ�,�����������ڴ������ִ��˳�������Ҫ��Ӱ��:���������ڴ�Ķ���д������ִ��˳��,��һ�����ڴ�ʵ�ʷ����Ķ���д˳��һ��,Ҳ���Ƿ���������
����
����������ͬʱִ��:
������ A B
a = 1; b = 2;
x = b; y = a;
����:
��ʼ״̬:a = b = 0;
ִ��֮��:x = y = 0;
ԭ��:
��Ϊ������ִ��д������ʱ��,��a = 1,b = 2;�Ȼ�д���Լ���д������
Ȼ���ʱ�ڴ��е� a = 0;b = 0;��ʱִ��x = b;y = a�Ķ�����,��ȡ��Ϊ0
����Ǵ��������ڴ��������������,������(��ǰ�������Ķ�����)�ŵ���д����(����һ����������д����)��ǰ��
- ��֧�ֵ�������:�ִ���ÿ����������֧��д-����������������
- �ض����͵�������:һ�㴦��������֧�ֶԴ������������ԵIJ�������������(ͨ�������ڴ�����ʵ��)
Ϊ�˱�֤�ڴ�Ŀɼ���,Java������������ָ�����е� ����λ�û�����ڴ�����ָ�� ����ֹ�ض����͵�ָ��������,JMM���ڴ����Ϸ�Ϊ4��

happens-beforeԭ��
- ��JDK1.5��ʼ,Javaʹ�õ����µ�JSR-133�ڴ�ģ��,���ڴ�ģ��ʹ��happens-before�ĸ����������֮����ڴ�ɼ���
- ��JMM��,���һ������ִ�еĽ����Ҫ����һ�������ɼ�,��ô����������֮�����Ҫ����happens-before��ϵ(�ȿ�����һ���߳�֮��,Ҳ�����ڲ�ͬ���߳�֮��)
- ��������֮�����happens-before��ϵ,������ζ��ǰһ����������Ҫ�ں�һ������֮ǰִ��,��ֻ��Ҫ��ǰһ������(ִ�еĽ��)�Ժ�һ�������ɼ���ǰһ��������˳�����ڵڶ�������֮ǰ��
- һ��happens-before�����Ӧһ�����������������������������,���ڳ���Ա����,happens-before�������,������ȥ�˽��ڴ�ɼ����漰�ĸ��ӵ������������ײ�ʵ��ԭ��
��������
- ����˳��ԭ��:һ���߳��е�ÿ������,(���з���)happens-before����߳��е���һ��������
- ������������:��һ�����Ľ���,(���з���)happends-before������������ļ���
- volatile��������:��һ��volatile���д(���з���)happens-before��������������volatile��Ķ�
- ������:���A(���з���)happens-before B,��B happens-before�� C ,��ôA happens-before C��
- start()����:����߳�Aִ�в���ThreadB.start()�����߳�B,��ôA�̵߳�ThreadB.start()����happends-before���߳�B�е��������
- join()����:����߳�Aִ�в���ThreadB.join()���ɹ�����,��ô�߳�B������IJ���happens-before���߳�A��ThreadB.join()�����ɹ�����
JMMʵ��volatile���ڴ�����
- JMM�����Ʊ�������������������,�����ڱ������������ֽ���ʱ,�����ڴ����Ͻ�������
- JSR-133��ǿ��volatile���ڴ�����,֮ǰ������ͨ������volatile����������,���������������ͨ�����ڶ��߳��µĶ���д�ڴ治�ɼ���,Ҳ�����ھɵ�������û�������ͷ�-��ȡ���е��ڴ�����,Ϊ���ṩһ�ֱ��������������߳�֮��ͨ�ŵĻ���,JSR-133ר���������ǿvolatile������:�ϸ���ʾ����������������volatile��������ͨ������������,ȷ����volatie��д�����������ͷš���ȡ������ͬ������
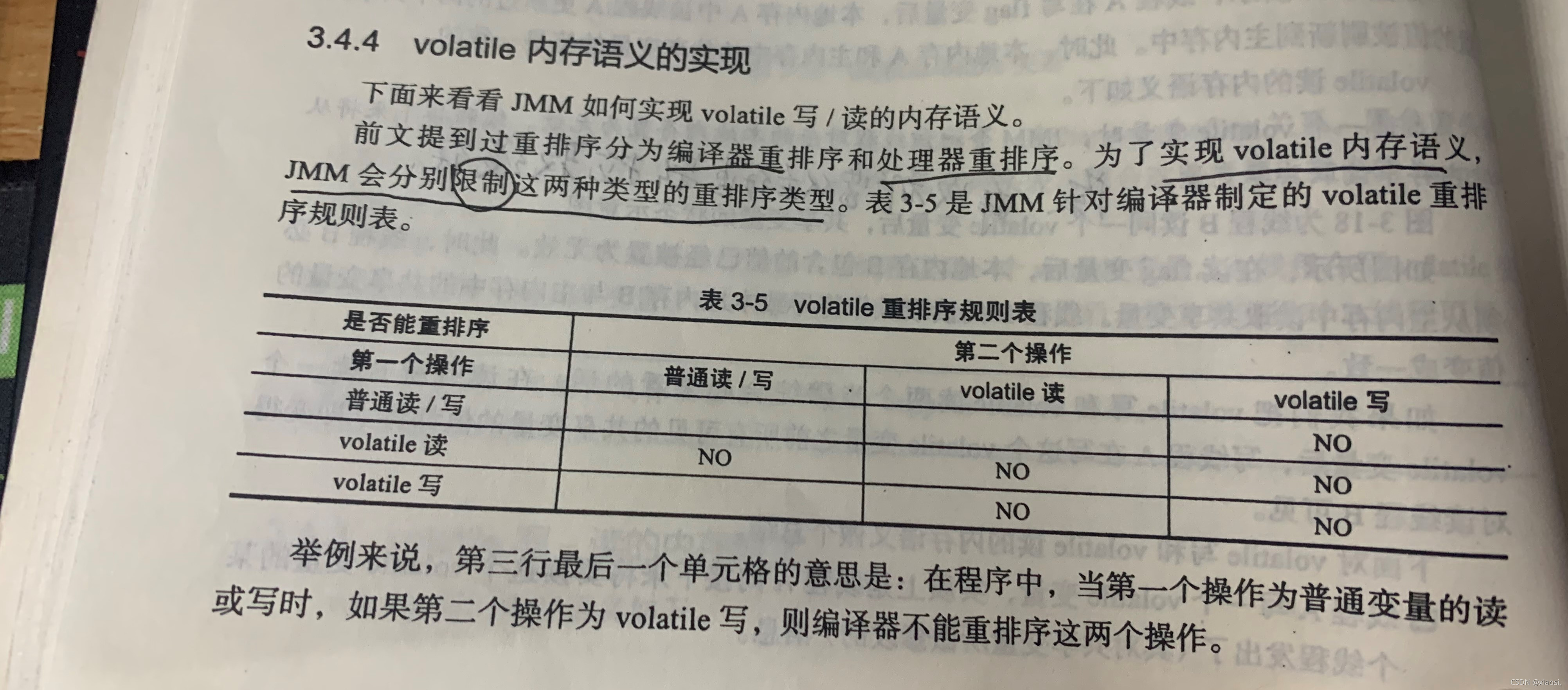

JMMʵ�������ڴ�����
- ���߳��ͷ�����ʱ��,JMM��Ѹ��̶߳�Ӧ�ı����ڴ��еĹ�������ˢ�µ����ڴ���
- ���̻߳�ȡ����ʱ��,JMM��Ѹ��̵߳ı����ڴ���λ��Ч
����ȡ��volatile��������ͬ���ڴ�����,��ReentrantLock��Ϊ��
- ʵ��������Javaͬ�����AbstractQueuedSynchronizer(AQS),AQSʹ�õ���һ�����ε�volatile����(state,���ƼƲٵ��ٽ�����Դ)��ά��ͬ��״̬,�ڻ�ȡ�������ȶ�ȡAQS��volatile��state����,�ͷŵ�ʱ������д�������
- ��Ϊ��ƽ���ͷǹ�ƽ��,Ĭ��Ϊ�ǹ�ƽ��,�̳���ϵ����Դ��
Lock�ӿ�
/**
locked
* the thread. An implementation should document this behavior.
*
* @see ReentrantLock
* @see Condition
* @see ReadWriteLock
*
* @since 1.5
* @author Doug Lea
*/
public interface Lock {
void lock();
void lockInterruptibly() throws InterruptedException;
boolean tryLock();
boolean tryLock(long time, TimeUnit unit) throws InterruptedException;
void unlock();
Condition newCondition();
}
ʹ�ù�ƽ�����ù���
ʹ�÷ǹ�ƽ���������ù���
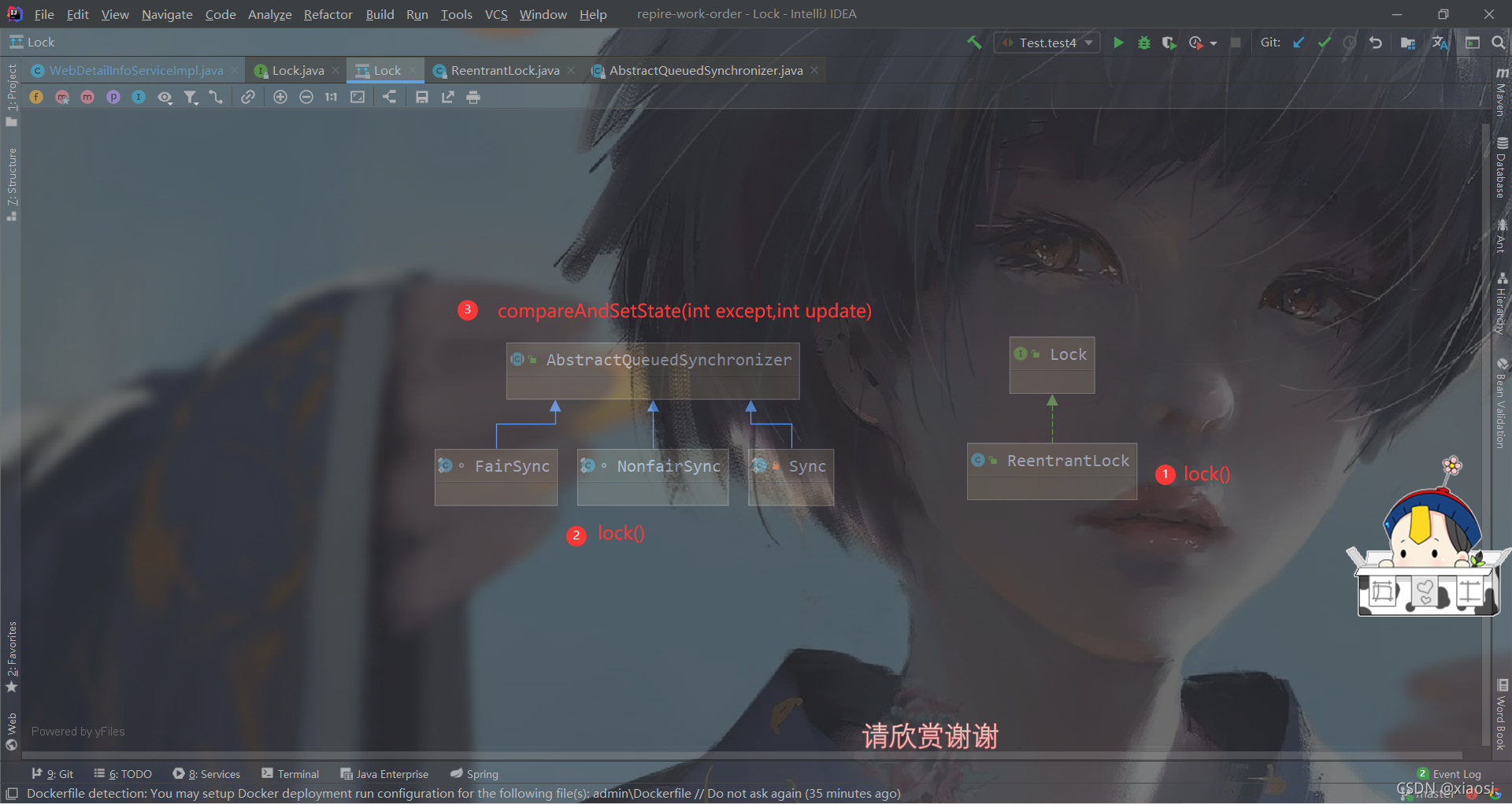
AQSͬ������CAS���õ��DZ��ص�Unsafe������compareAndSetState(int except,int update)
concurrent��������ʵ��ģʽ( AQS�����������ݽṹ��ԭ�ӱ�����ȶ�������ģʽʵ�ֵ�)
- ����,������������Ϊvolatie
- Ȼ��,ʹ��CAS��ԭ������������ʵ���̼߳��ͬ��
- ͬʱ,�����volatile�Ķ���д��CAS�����е�volatile����д���ڴ�������ʵ���߳�֮���ͨ��
final����ڴ�����,����final��,�������ʹ�����Ҫ�����������������
- final���������д:�ڹ��캯���ڶ�һ��final���д��,����������������������ø�ֵ��һ�����ñ���,��������������������,Ҳ���ǽ�ֹ��final���д�������캯��֮��,ԭ�����DZ���������final��д֮��,���캯��return֮ǰ,����һ��StoreStore����,Ҳ����ȷ���ڶ�������Ϊ�����߳̿ɼ�֮ǰ,�����final���Ѿ�����ȷ�ij�ʼ��֮����,����ͨ���������֤,
- final��������Ͷ�:���ζ�ȡһ������final��Ķ�������,�������ζ������final��,����������֮�䲻��������,����������final�������ǰ���һ��LoadLoad����
- final��Ϊ��������:�ڹ��캯���ڶ�һ��final���õĶ���ij�Ա��д��,������ڹ��캯���������������������ø�ֵ������һ����Ӵ���ñ���,����������֮�䲻��������,Ҳ����final���ò��ܴӹ��캯��"����"
JSR-133ΪʲôҪ��ǿfinal������
- �ھɵ�JMM��,һ�������ص�ȱ�ݾ����߳̿��ܿ���final���ֵ��仯,��һ���̵߳�ǰ����һ������final���ֵΪ0(��δ��ʼ��֮ǰ��Ĭ��ֵ),��һ��ʱ��,����߳���ȥ�����final���ֵʱ,�����߳���ɳ�ʼ������Ϊ1��,�����ľ���String��ֵ���ܻ�ı�
- Ϊ�������©��,JSR-133ר������ǿ��final������,ͨ��Ϊfinal������д�Ͷ������������,����Ҫʹ��lock��volatile���ܱ�֤�����̶߳��ܿ������final���ڹ��캯���б���ʼ����ֵ��
DCL��������ģʽ
- ʹ��synchronized�ӵ�geiInstance()������,�ڷ����ڼ���һ���жϿ��Ա�֤��ȷ����,��������̫��,ʹ��DCL˫��������Ϊ�˽�������Ƶ������synchronized�������������ܿ�����
- ����������DCL:��ʹ��synchronized��������,������ ��һ��if�ж� ʵ����û���� ֮��,��סxxxx.class,�ڲ��ټ�һ���ж�ʵ���Ƿ�,û�д����ٴ�������Ҳ�ͱ����˶�����֮��,ִ��getInstance()������Ҫ��ȡ��,��Ϊֱ�ӽ���ȥ ��һ��if�ж��ˡ�
- ����volatile��ֹ������:���ǻ�������,��Ϊ���������ԭ�Ӳ���,��Ϊ,��������ڴ�ռ䡢��ʼ���������ö������ָ���ڴ�ռ�,���к����������ǿ����������,��˲��ܱ�֤����,���Բο����ڲ���:Java������ѧϰƪ6_����ģʽ������CAS��ԭ�����ý��ABA����
���ʼ����ʱ��,��ʼ��һ����,����ִ�������ľ�̬��ʼ���ͳ�ʼ����������������ľ�̬�ֶ�
- ���ʵ��������
- ��������ľ�̬����������
- ��������ľ�̬�ֶα���ֵ,���߱�ʹ��
- ����һ��������,����һ���������Ƕ����T�ڲ���ִ��
���ڶ��߳������ʼ�����ڴ�ɼ���,��Ҫ��Ϊ4����
- 1����һ��,ͨ����Class������ͬ��(���Class����ij�ʼ����),��������ͽӿڵij�ʼ��,�����ȡ�����̻߳�һֱ�ȴ�,ֱ����ǰ�߳��ܻ�ȡ�������ʼ����
- 2���ڶ���,�߳�Aִ����ij�ʼ��,ͬʱ�߳�B�ڳ�ʼ������Ӧ��condition�ϵȴ�
- 3��������,�߳�A����state = initalized ,Ȼ������condition�еȴ����߳�,��ʼ�����
- 4�����Ľ�,�߳�B������ij�ʼ������
5��Java��������
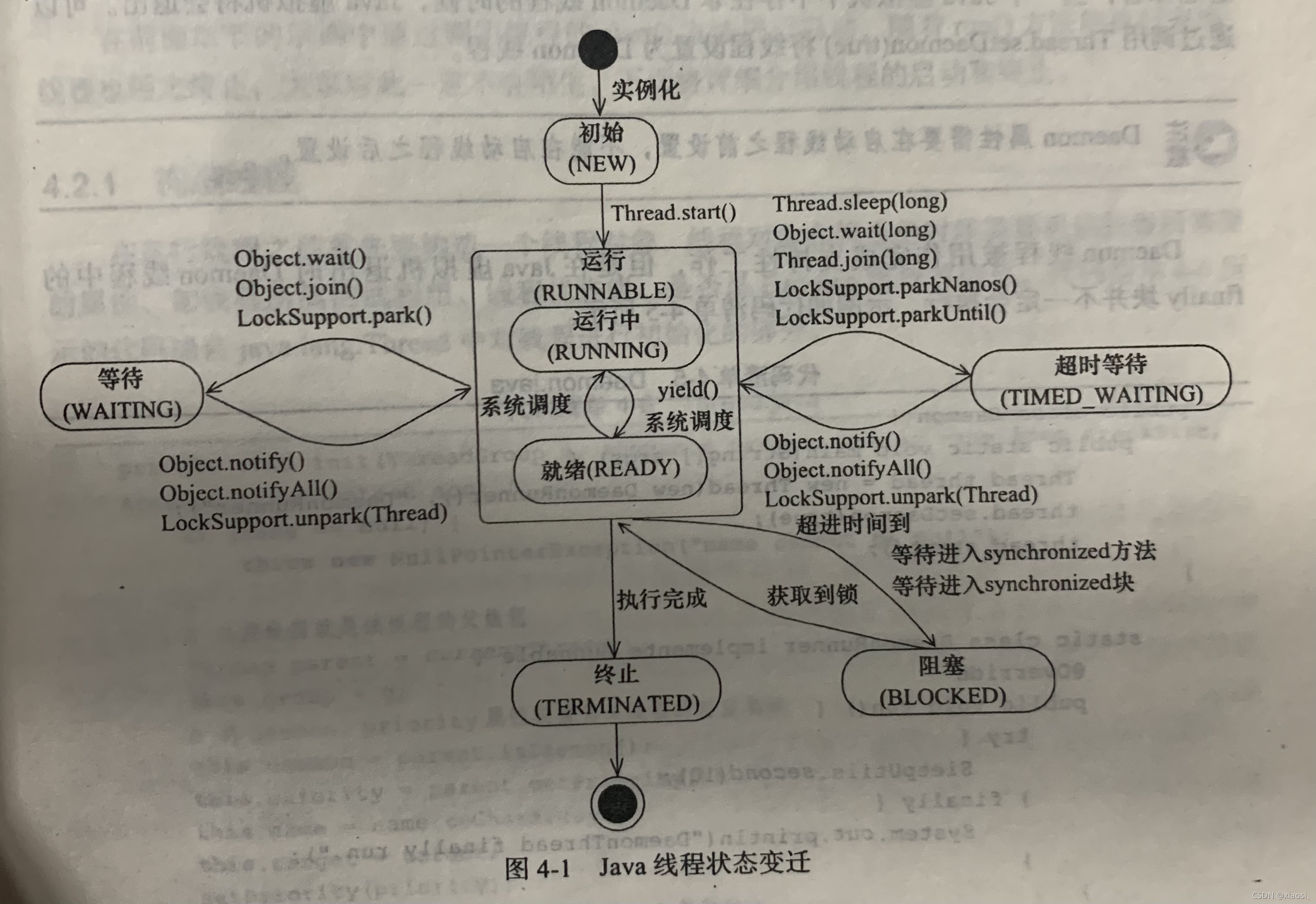
�̵߳�6��״̬
�����ж�
- �жϿ�������Ϊ�̵߳�һ����ʶλ����,����ʾһ�������е��߳��Ƿ������߳̽������ж�
- �жϺñ������̶߳Ը��̴߳��˸��к�,�����߳�ͨ�����ø��̵߳�interrupt()������������жϲ���
���ڵ��߳�ֹͣ����
- suspend()�ڵ���֮��,�����ͷ���,����ռ����Դ����˯��״̬,�����������
- stop()�ڵ���֮��,���ᱣ֤��Դ�����ͷ�,ͨ����û�и��߳��ͷ���Դ�Ļ���,�������̴߳��ڲ�ȷ��״̬
- ��ȫ����ֹ��������ʹ���ж�,����������volatile boolean����������Ҫֹͣ������
�߳�֮��ͨ��wait()��notify()
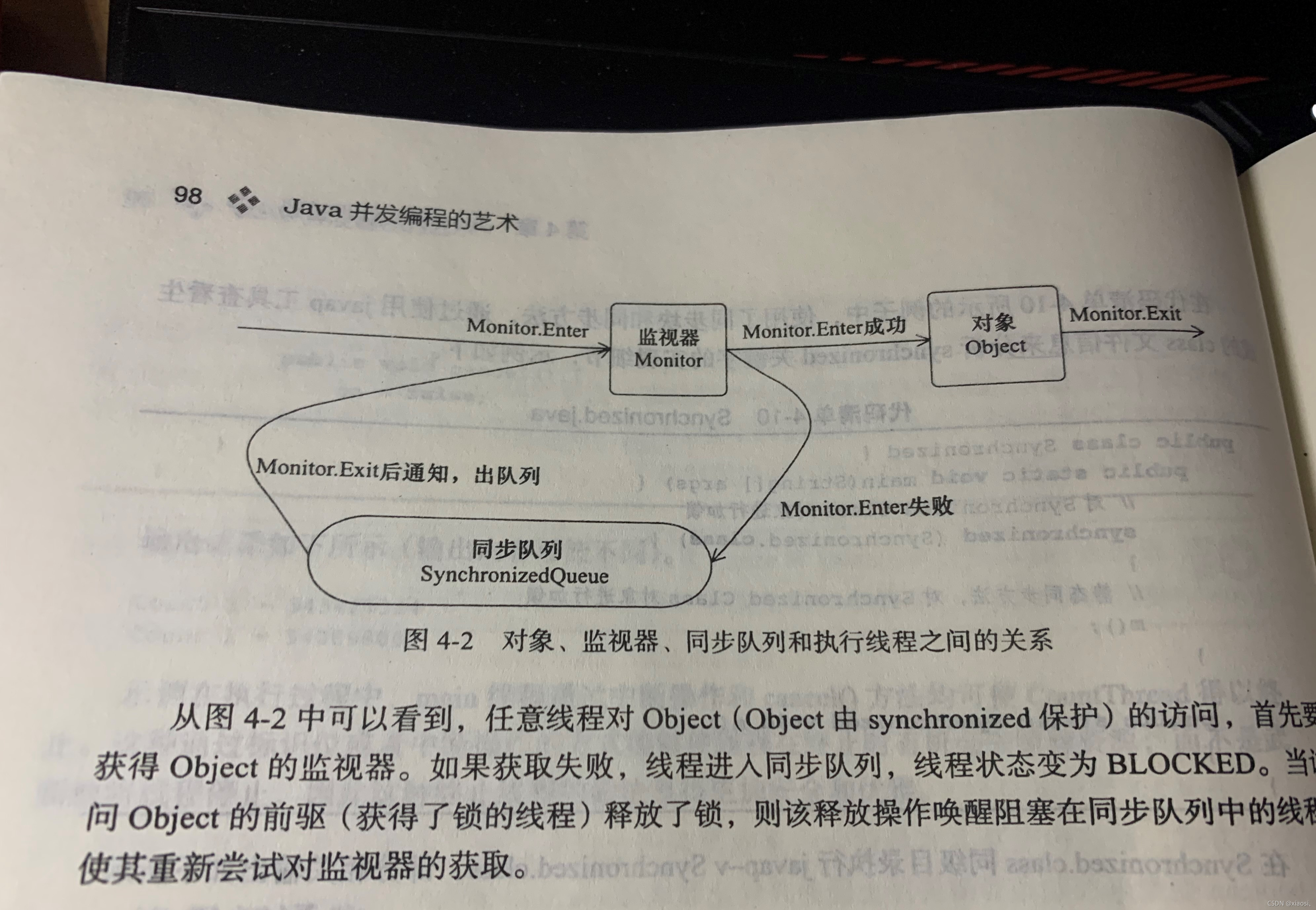

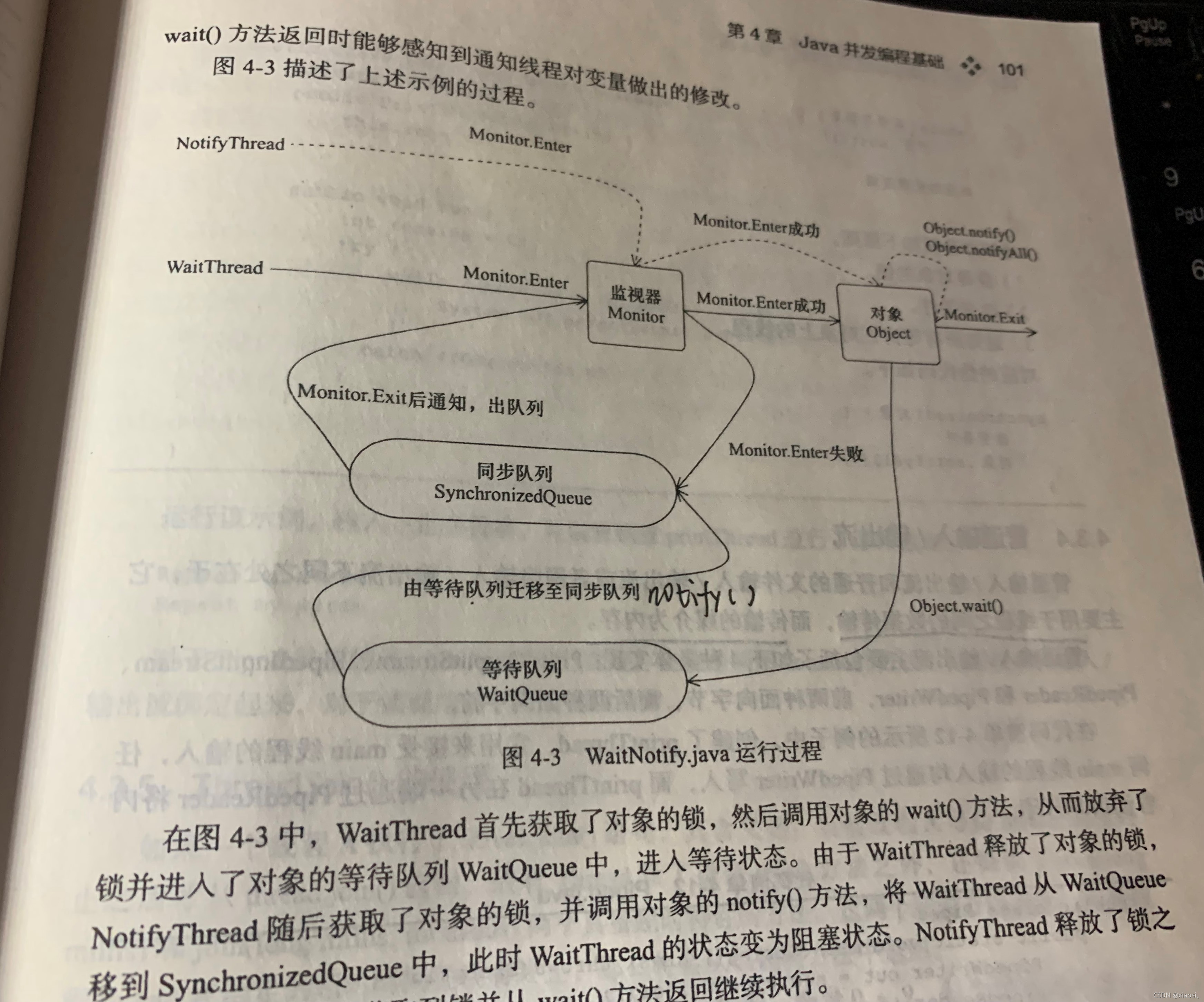
6��Java���
Lock��JDK1.5�����Ľӿ�,���synchronizedȱ������ʽ�ͷ���,�����ŵ���
- �ɲ�����
- ���жϵĻ�ȡ��:�ܹ���Ӧ�ж�,�����׳��ж��쳣,ͬʱ�ͷ���
- ��ʱ��ȡ��
- ���Է������Ļ�ȡ��
����ͬ����AQS,����������������ͬ������Ļ������,
- ͨ��ʹ��int���͵ij�Ա����state��ʾͬ��״̬,ͨ�����õ�FIFO���������Դ��ȡ�̵߳��Ŷӹ���
- ͬ������Ҫ��ʹ�÷�ʽ�Ǽ̳�,����ͨ��ʵ�����ij�������ͬ��״̬,ͬ��������û��ʵ���κνӿ�,������������(getState��setState��compareAndSetState)�������������Զ���ͬ�����������ʹ��,��ReentrantLock��ReentrantReadWriteLock��countDowmLatch
- ����������ʵ�ַ�ʽ,������ͬ��״̬���������̵߳��Ŷӡ��ȴ��ͻ��ѵȵײ����,����ģ�巽��ģʽ��Ƶ�
�ɹ���������Զ�����д�ķ���(������Ƕ�ռ�����ǹ�����)
- tryAcquire(int arg)
- tryRelease(int arg)
- tryAcquireShared(int arg)
- tryReleaseShared(int arg)
- isHeldExclusively()
Ȼ�����AQS��ģ�巽��(Ҳ���ǹ��Զ������Ĭ�ϵ��õĵײ㷽��,���Բ���д)
- acquire(int arg)
- acquireInterruptibly(int arg)
- tryAcquireNanos(int arg,long nanos)
- acquireShared(int arg)
- acquireSharedInterruptibly(int arg)
- tryAcquireSharedNanos(int arg,long nanos)
- release()
- releaseShared()
- getQueueThreads():��ȡ��ͬ�������ϵ��̼߳���
�Լ�дһ�����װ�Lock������
- 1���½�MyLock��ʵ��Lock�ӿ�
- 2���½���̬�ڲ���Syncʵ��AbstractQueuedSynchronizer,Ȼ������Լ�����Ƶ�����д��3������д�ķ���
- 3��������MyLock�����½�Syncʵ������
- 4��������MyLock�����½�ϵ�м���lock()��tryLock()������unlock()�ȷ���,�����ڲ�����ʹ��Syncʵ��ȥ����ʵ����д����Щ��������AQS��ģ�巽��
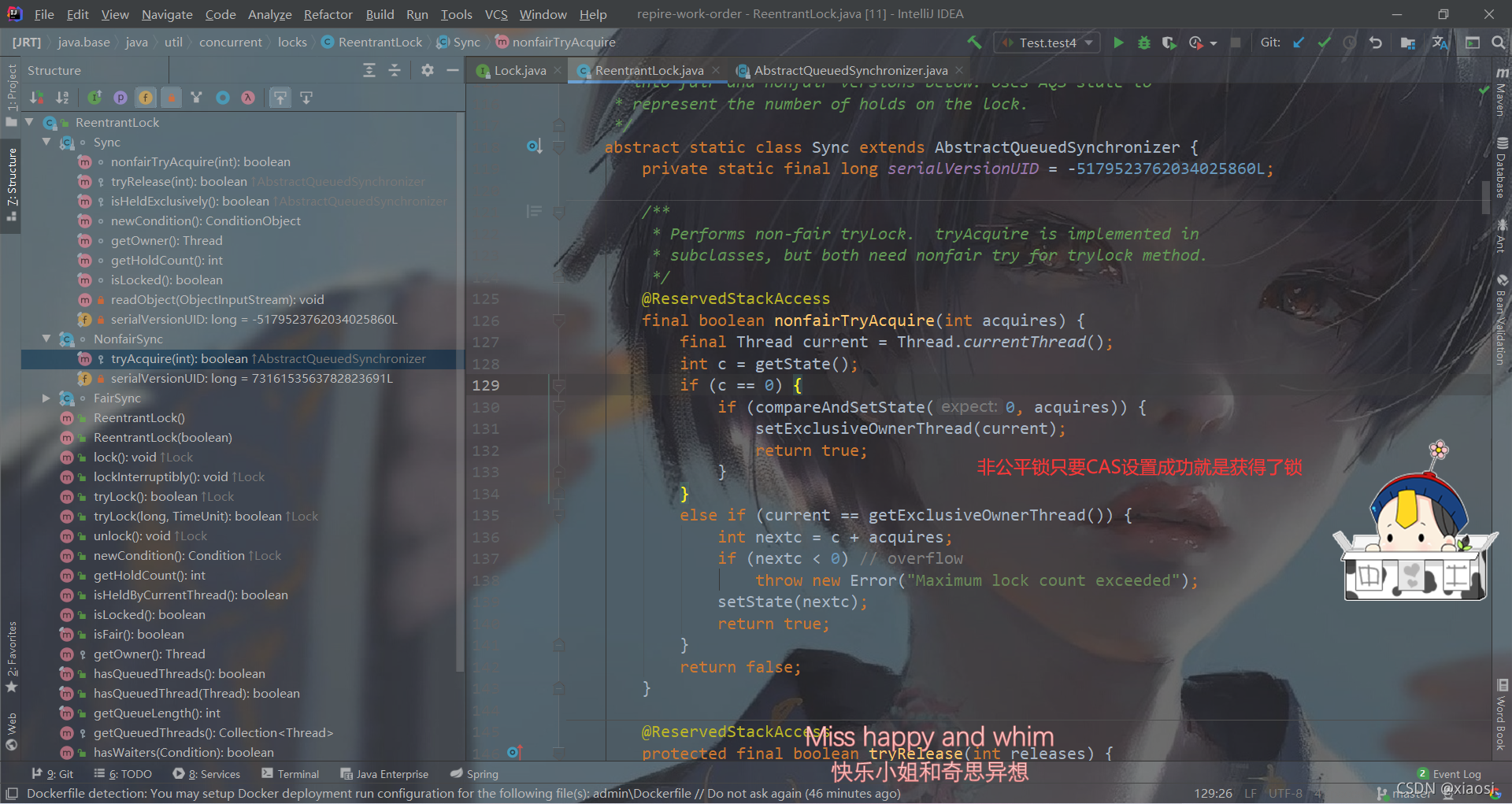
����ԭ��(��ReentrantLockΪ��)
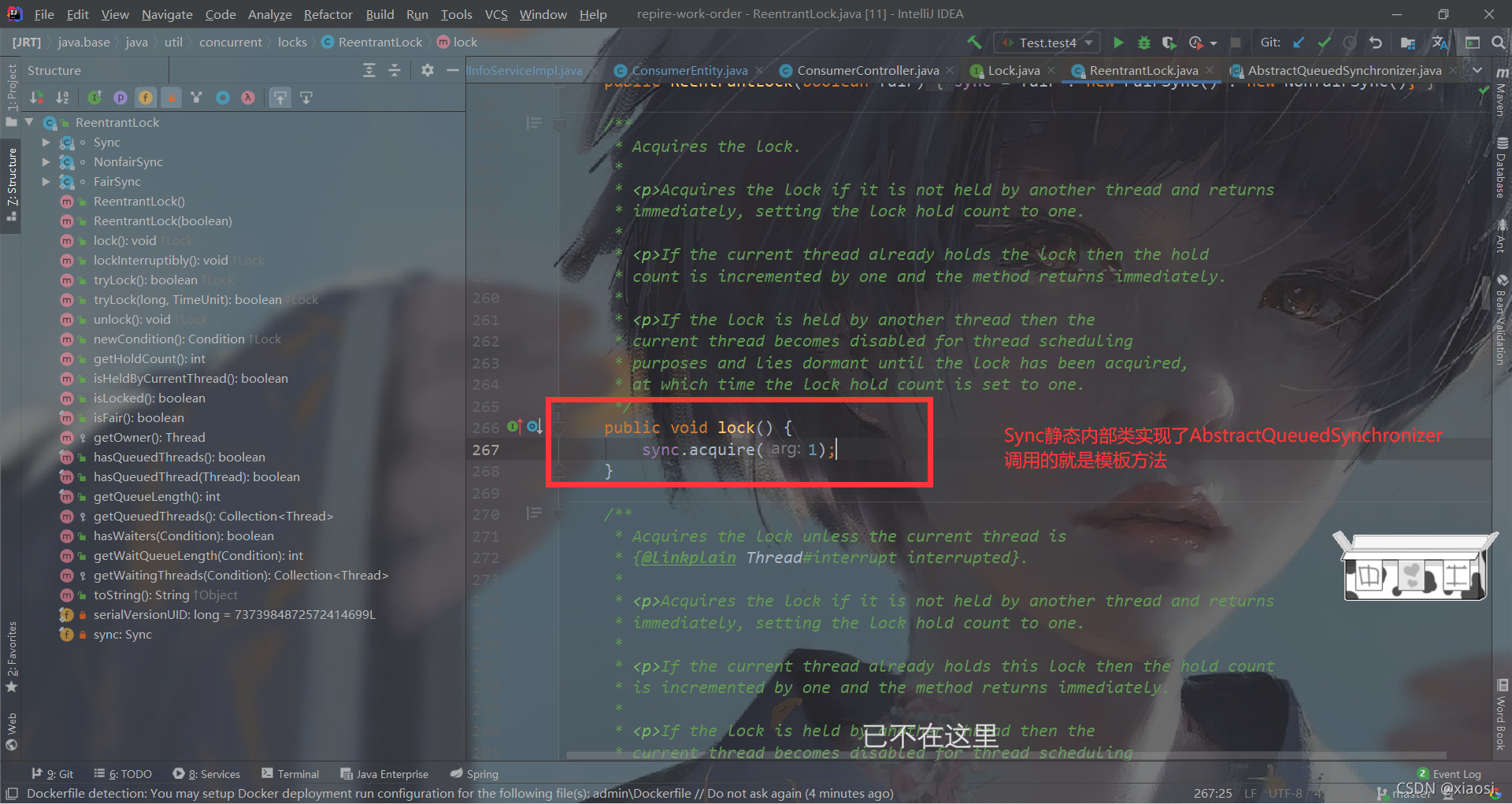
Sync���õ���AQS��acquire(),if�жϵ��������Ƿ��ܻ����
- 1��Ҳ���ǵ���Sync��д�ķ���tryAcquire(),�����Ƿ����õ���
- 2�����ò�������ǰ����,�������Լ��߳��½����,CAS�������ӵ�ͬͬ�����е�β��,����ѭ�����Ի�ȡ��,�ȴ���ȡ��֮����ܴӵ�ǰ��������
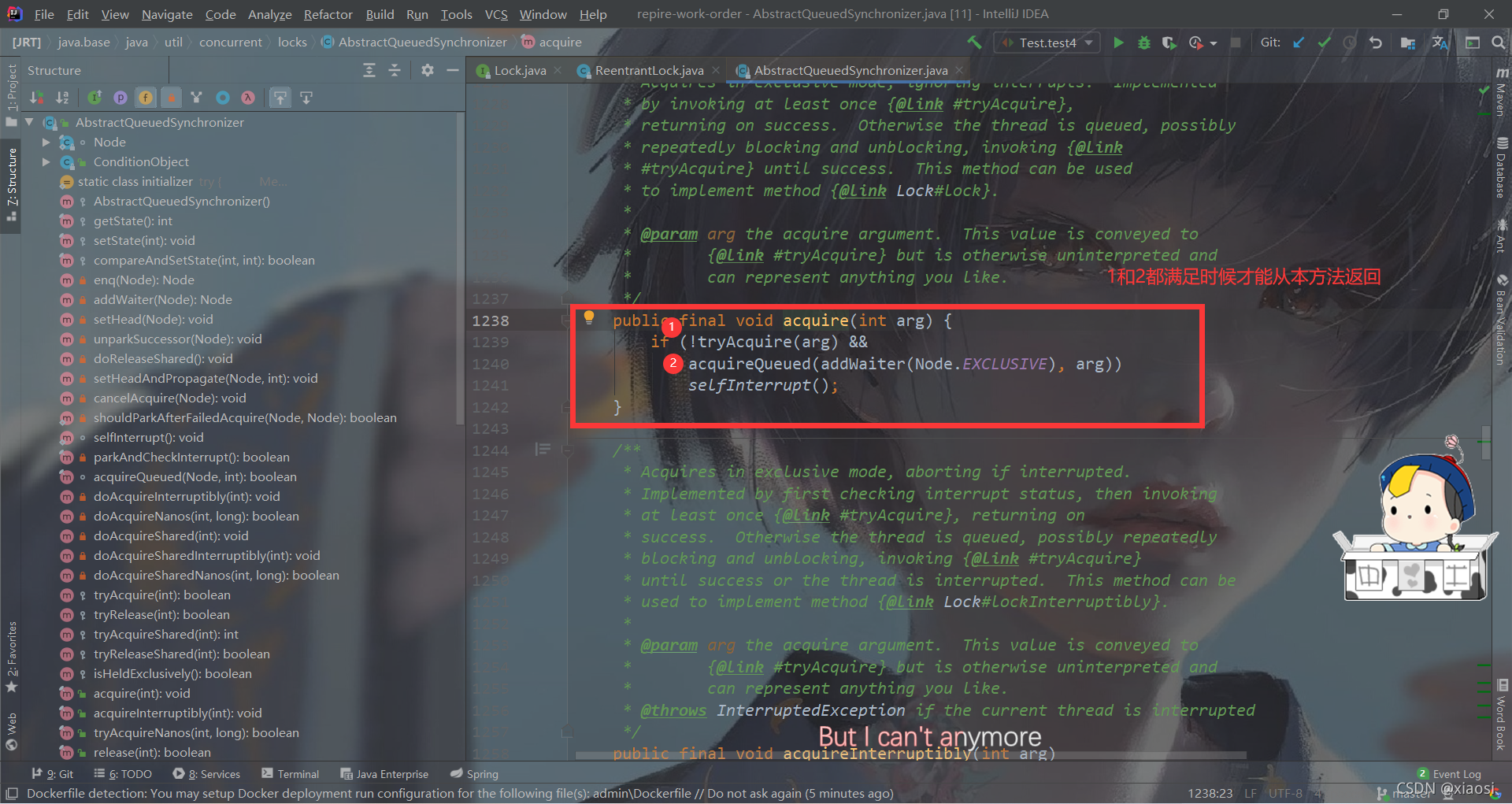
����1,���ǵ���Sync��д�ķ���,�����Ƿ��Ѿ�������,���еĻ�ֱ�ӴӸ÷�������
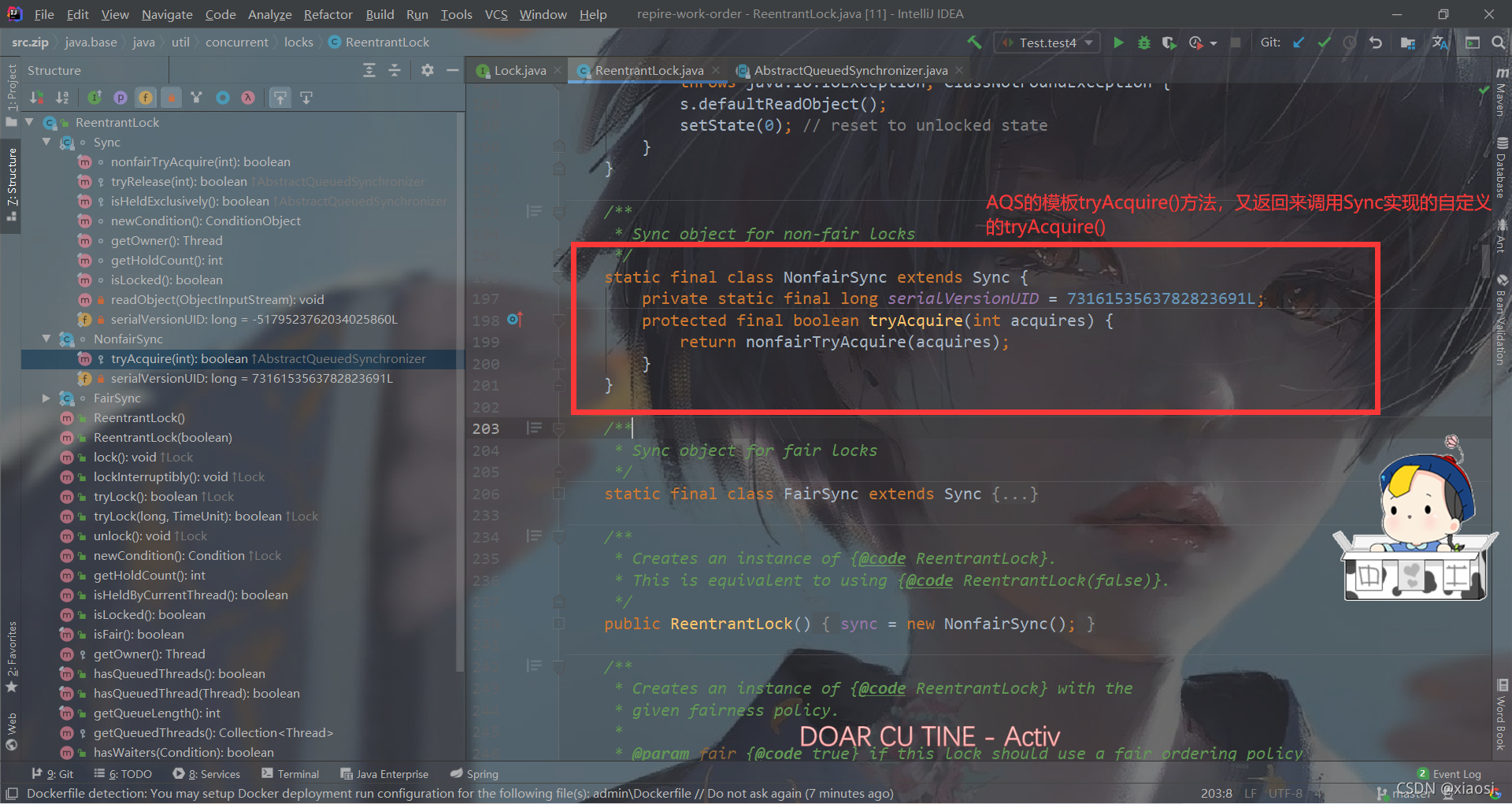
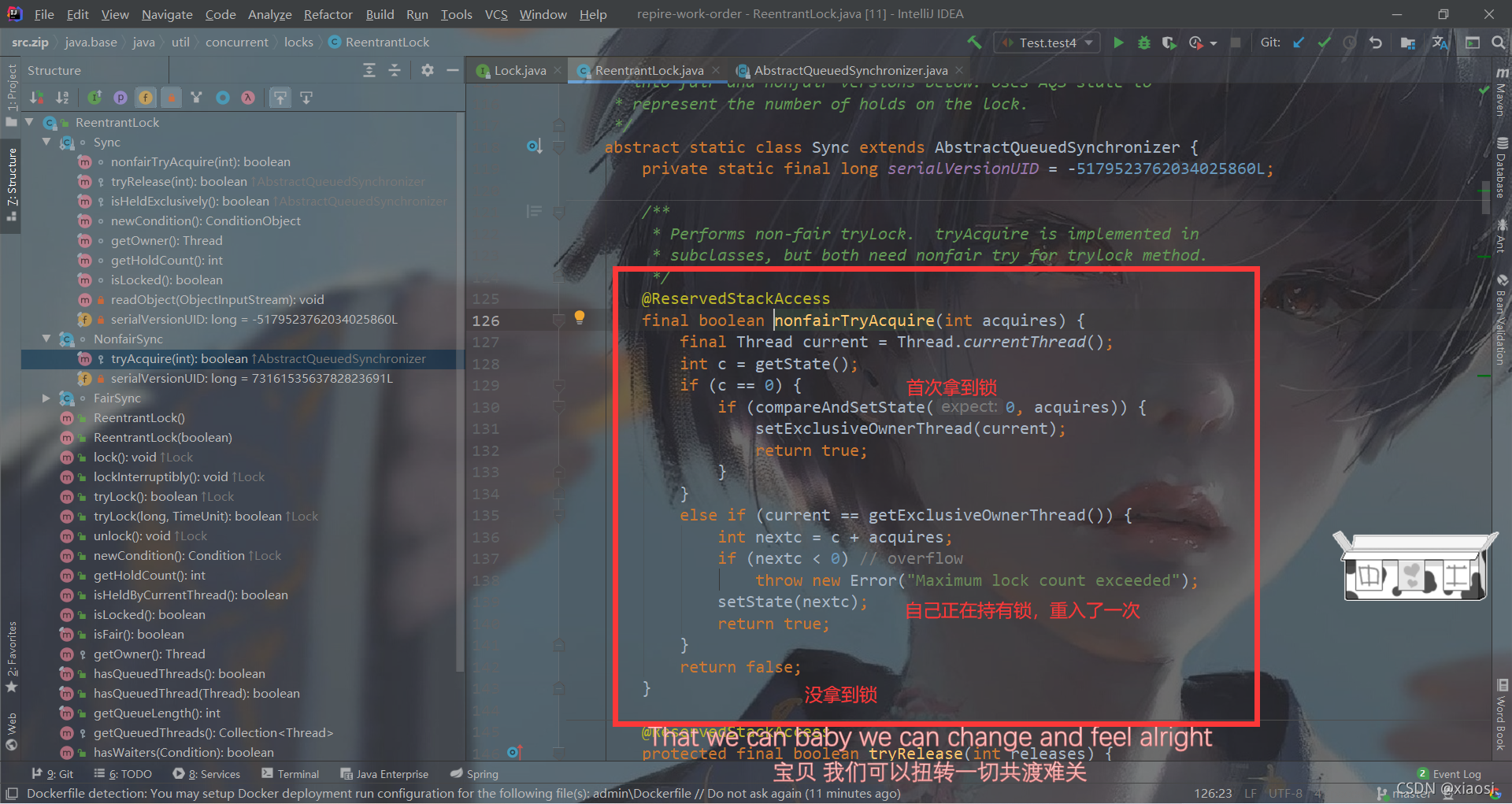
����2,��ѭ����ȡ��(ֻ�е�ǰ���ڵ����ڵ�����ʸ��ȡ��),tryAcquire()���ǵ��õ�Sync��д�ķ���
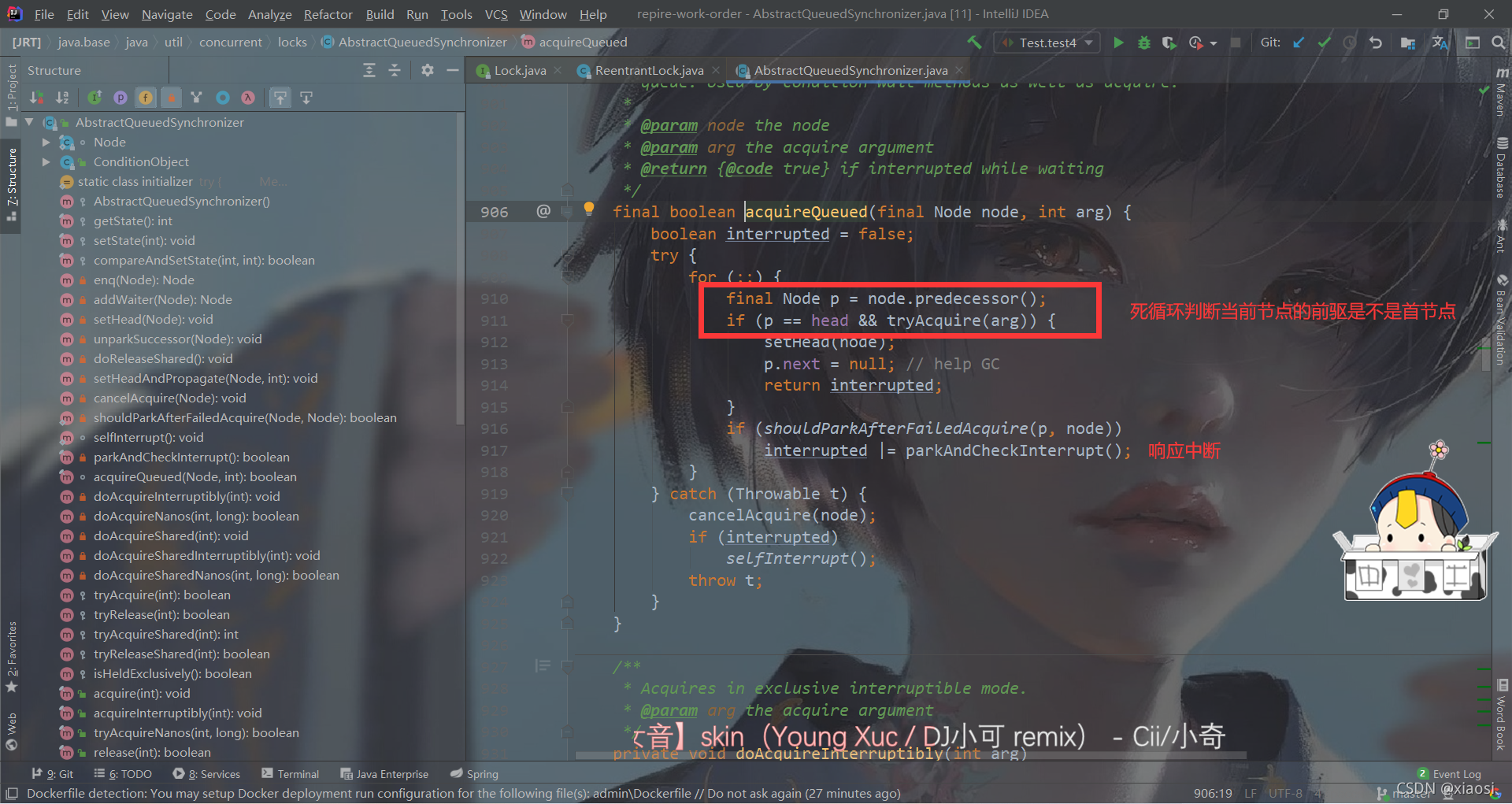
AQS�ײ�ʵ��
- ͬ��˫�˶���:��ѭFIFO,��ǰ�̻߳�ȡͬ��״̬ʧ��֮��,�ͻᵱǰ�̼߳���ȴ�״̬����Ϣ ����һ�� ��㡣������ͬ������,ͬʱ�������߳�,��ǰ����ͬ��״̬���߳��ͷ�ͬ��״̬��,���ͬ�����е��ڵ��̻߳���,ʹ���ٴγ��Ի�ȡͬ��״̬��
- ͬ�����нڵ�:����ͬ��״̬��ȡʧ���̵߳����á��ȴ�״̬��ǰ��ڵ��ָ�롢�ڵ�����Ժ�����������
- ����β���:ͬ�����ṩһ��CAS����β���ķ���compareAndSetTail(),ͬ����ͨ����ѭ�� ����֤�ڵ����ȷ����,ֻ�гɹ����ӵ�β���֮��,��ǰ�̲߳��ܴӸ÷�������,���ϵij�������,������ͻ����̳߳����Լ����ӵ�β����ô��л���
- �����ڵ�:ͨ����ǰ��ȡͬ��״̬�ɹ����߳�����ɵ�,��Ϊͬʱֻ��һ���߳��ܻ�ȡͬ��״̬,��˲���ҪCAS����,ֻ��Ҫ���ڵ����ó�ԭ�ڵ�ĺ�̽ڵ㲢�Ͽ�ԭ�ڵ��next����
- �ڵ����ͬ������:����֮��,ÿ���ڵ��һֱ��ѭ���ж�ǰ���ڵ��Dz���ͷ���,������ǰ�ڵ���߳�,ֱ�����ͬ��״̬���߱������߳��ж�,�Ӹ÷������ز�������
ֻ��ǰ���ڵ���ͷ�����ܳ��Ի�ȡͬ��״̬,�ڵ�ͽڵ���ѭ�����Ĺ����в�ͨ��,����ֻ����ǰ���ڵ��Dz���ͷ����ж�,�����ͷ���FIFOԭ��,����Ҳ���ڶ�֪ͨ�����֪ͨ�Ĵ���(����֪ͨ������ǰ���ڵ㲻��ͷ�����߳������ն˶�������)
- ͷ����dzɹ���ȡͬ��״̬�Ľڵ�
- ά��ͬ�����е�FIFOԭ��
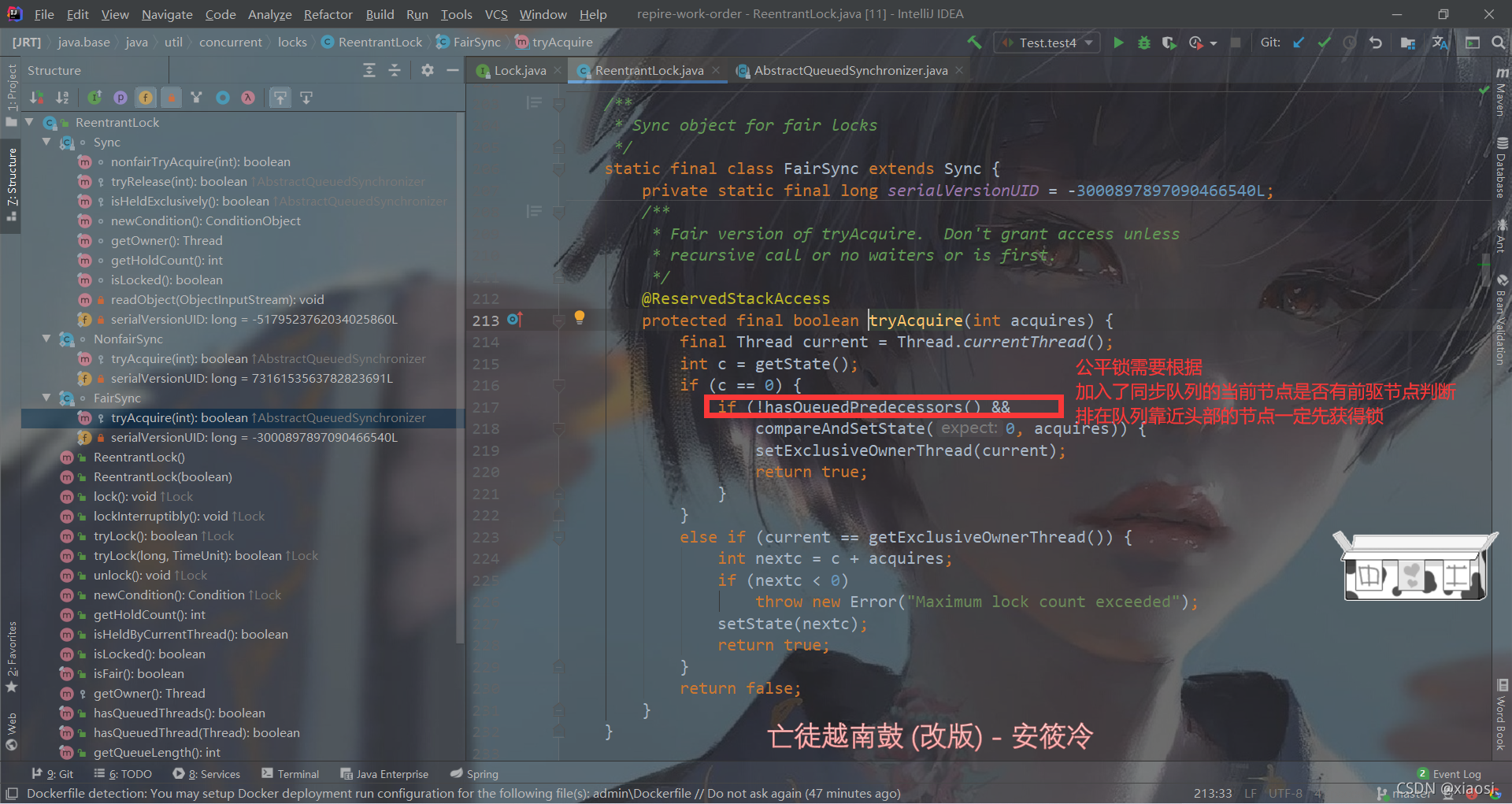
�������빫ƽ��
- ֧������,����֧��һ���̶߳�ͬһ����Դ���ظ�����
- synchronized�ؼ�����ʽ���֧���ؽ���,ReentrantLockҲ֧������
- synchronized�ؼ���֧�ֵ��Ƿǹ�ƽ��,ReentrantLockͨ�����캯�����ο���ָ����ƽ���ǹ�ƽ��
���ReentrantReadWriteLock
- ά��һ����,һ������,һ��д��,�����Ա�����������Ҫ��
- ֧�ֹ�ƽ���ǹ�ƽ,�����롢������(��ѭ��ȡд������ȡ�������ͷ�д���Ĵ���,д���ܽ���Ϊ����)
- �����Զ���ͬ����ʵ�ֹ���,��Ҫ��һ��ͬ��״̬����state��ά��������̺߳�һ��д�̵߳�״̬,�������� ��λ�и�ʹ��,��16λ��ʾ��,��16λ��ʾд,��Ϊ0ʱ,��ʾ���Ѿ����̻߳�ȡ
- �����,��������
������ָ����д����Ϊ����
- �����ǰ�̳߳���д��,�ͷ�֮��,�ڻ�ȡ����,���ֶַε�������ܳ�֮Ϊ������
- �������� �ѳ�ס��ǰӵ�е�д��,�ڻ�ȡ������,����ͷ�ӵ�е�д���Ĺ���(��ʵ���������Ϊ�˷�ʽ��ǰ�ͷ�д�����û���϶���,���������̼߳�����д��,Ŀ�ľ���Ϊ�����ö�����ֹ�����̼߳�д��)
LockSupport����,����һ�鹫����̬����,֧��������������
- park()
- parkNanos()
- parkUntil()
- unpark()
Condition�ӿ�,����Lock����
- ֧�ֶ���ȴ�����
- ֧�ֵȴ�״̬��Ӧ�ж�
- ֧�ֳ�ʱ�ȴ�
����������ʵ�ַ���
- ÿ��Conditio������һ���ȴ�����,�������condition.await()����,��ǰ�߳̾ͻ��ͷ���,����ɽڵ����ȴ����в�����ȴ�״̬
- �����ȴ�����β��㲻��ҪCAS,��Ϊֻ�е�ǰ���������̲߳���ִ��await(),���������֤�̰߳�ȫ
- �����ͬ�����С��ȴ����еĽǶȿ�����await,����ͬ�����е��ڵ�(��ȡ�����Ľڵ�)�ƶ���Condition�ĵȴ�������,ͬ������signal��֮
7��Java���������Ϳ��
ConcurrentHashMap��ʵ��ԭ��
-
JDK1.7ʹ�õ��Ƿֶ���,JDK1.8֮���ΪNode����
-
�ο�JavaGuide,ͦ��ϸ��:https://javaguide.cn/
ConcurrentLinkedQueue�̰߳�ȫ�Ķ���
- ʹ�������㷨
- ʹ�÷������㷨
Java���������,7��
- ArrayBlockingQueue
- LinkedBlockingQueue
- PriorityBlockingQueue
- DelayQueue
- SynchronousQueue
- LinkedTransferQueue
- LinkedBlockingDeque
Fork/join���
- ����ִ������Ŀ��,������ȡ�㷨
8��Java�е�13��ԭ�Ӳ�����
��JDK1.5֮���ڿ�ʼ�ṩAtomic��,������µ�ԭ�Ӳ������ṩһ���÷������ܸ�Ч���̰߳�ȫ�ĸ���һ�������ķ�ʽ,����ʵ�ַ�ʽ����Unsafe���CAS����,ֻ����������ΪUnsafe��ֻ�ṩ������,�������ڴ˻�����ʵ��
����������
- AtomicBoolean
- AtomicInteger
- AtomicLong
ԭ�Ӹ�������
- AtomicIntegerArray
- AtomicLongArray
- AtomicReferenceArray
ԭ�Ӹ�����������
- AtomicReference
- AtomicReferenceFieldUpdater
- AtomicMarkableReference
9��Java�еIJ���������
��Ҫ��
- 1���ȴ����߳���ɵ�CountDownLatch:
- ����һ������̵߳ȴ������߳���ɲ���֮��,�ٽ���ִ��,����join()�Ĺ���,����main�̵߳���t1.join()�Ϳ���ʹt1�߳�ִ����֮��,�Ž���ִ��main�̡߳���CountLatch���ܸ�ǿ��,ͨ�������������һ������������,����CountLatch.countDown()���¼�������ֵ�ͻ��1,ֱ��Ϊ0��ǰmain�߳�ִ�С�
- ��Ҫע����Dz������³�ʼ�����ļ�������ֵ��
- Ӧ�ó���������Ҫ�����������������,�����Ҫ�����������ϲ�
- 2��ͬ������CyclicBarrier:
- ��ѭ�����õ�����,��Ҫ������������һ���̵߳���һ������(������),ֱ�����һ���̵߳�������ʱ,���ϲŻῪ��,���б����������ص��̲߳���ִ�С�
- ��֧��һ�����Ĺ������,���������Ͽ��ŵ�����֮��,����ִ��ָ����Runnable
- Ӧ�ó�������������
- ��Ҫע����Ǻ�CountDownLatch��ͬ���Ǽ���������ʹ�ö��,����㷢������������ü�����
- 3�����Ʋ����߳�����Semaphore
- Э�������߳�,��֤������ʹ�ù�����Դ
- Ӧ�ó��������������ơ����ݿ�����
- 4���̼߳佻�����ݵ�Exchanger
- �̼߳�Э��,�ṩһ��ͬ����,�����ͬ����,�����߳̿��Ա˴˽�������
10��Java�е��̳߳�
ʹ���̳߳صĺô�
- ������Դ����:�����Ѵ������߳���Դ�����̴߳�����������ɵ�����
- �����Ӧ�ٶ�:������Բ���Ҫ�ȴ��ߴ�������ִ��
- ����̵߳Ŀɹ�����:�߳���ϡȱ��Դ,���������ƵĴ���,�ή��ϵͳ���ȶ���,ʹ���̳߳ؿ��Խ���ͳһ���䡢���š����
ʵ��ԭ��
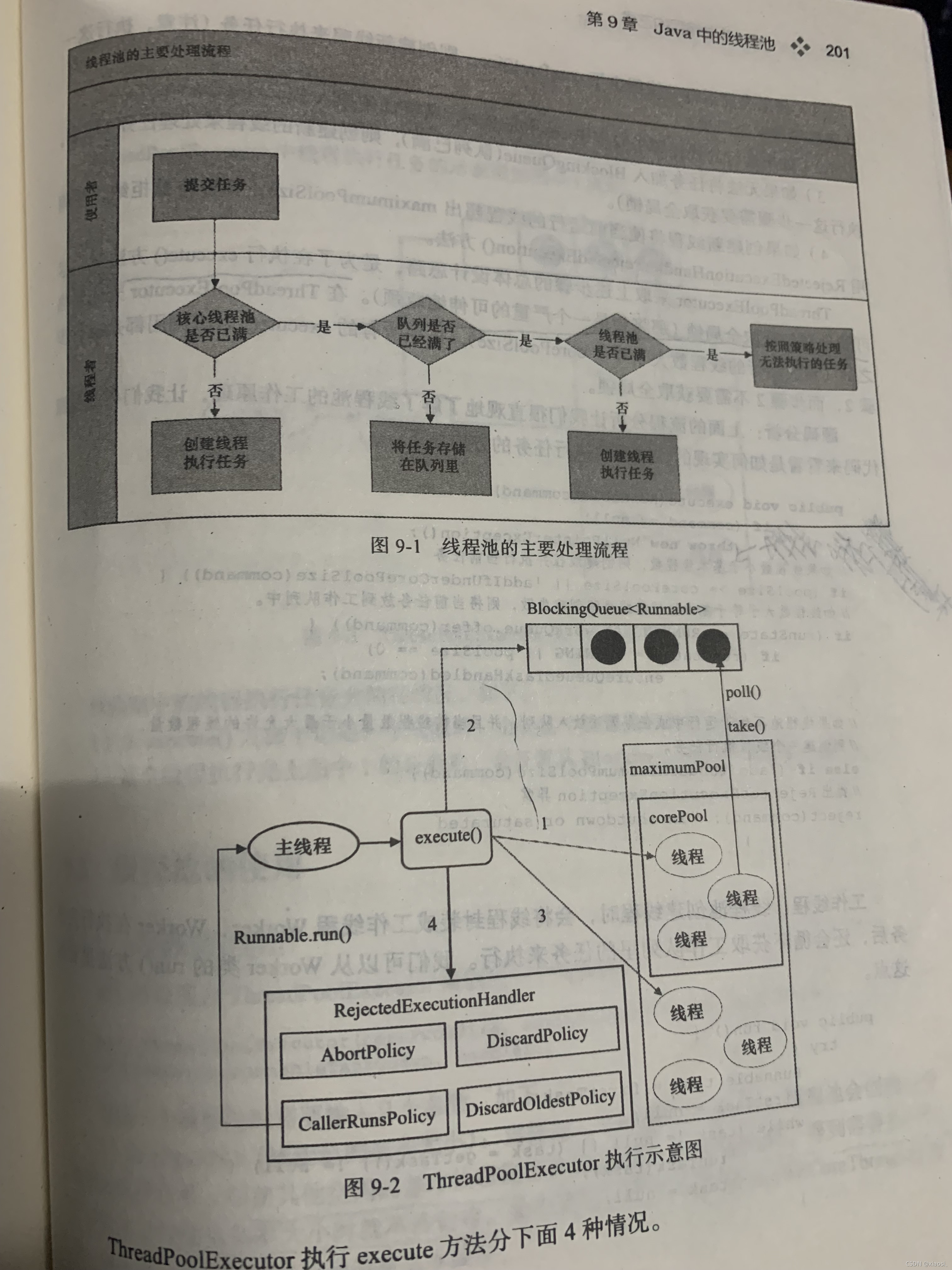
��������������������˼·��Ϊ��ִ��execute()������ʱ��,�����ܱ���ʹ��ȫ����,���̳߳�Ԥ��֮��(��ǰ���е��߳������ڵ���corePoolSize�����߳���),�������е�execute()�������ǽ����������������,�����̲���Ҫ��ȡȫ����
��
�̳߳صĴ���
- ����ʹ�þ�̬������Excutors.newXXX����,��������淶���Ƽ����ַ�ʽ,��Ϊ��̬����CPU��IO�ܼ��������̳߳ظ�����Ч
- ����ʹ��ThreadPoolExcutor�Ĺ����������,��Ҫָ��5������
- 1��corePoolSize:�����߳�����С,ע����Ԥ��,���ύһ�������̳߳�ʱ��,ֻҪ��ǰ�߳���������corePoolSize,�ͻ��½�һ���߳�ִ�и�����,��ʹ���������е��߳�,�ȵ��ﵽcorePoolSize�Ͳ��ڴ���
- 2��runnableTaskQueue�������
- ArrayBlockingQueue:��������ṹ���н���������,FIFO
- LinkedBlockingQueue:���������ṹ����������,FIFO,��������������,��̬��������Excutors.newFixedThreadPool()ʹ�����������
- SynchronousQueue:һ�����洢Ԫ�ص���������,ÿ���������ȴ���һ���̵߳����Ƴ�����,����һֱ����,��������������,��̬����Excutors.newCacheThreadPoolʹ�����������
- PriorityBlockingQueue:һ���������ȼ���������������,�п���һЩ�����ȼ�������һֱ��ִ��
- 3��ThreadFactory�����̵߳Ĺ���
- 4��maximumPoolSize����߳���
- 5��RejectExecutionHandler�ܾ�����
- AbortPolicy:ֱ���׳��쳣
- CallerRunsPolicy:ֻ�õ����������߳�����������
- DiscardPolicy:������,������,Ҳ���Ը���Ӧ�û����Ǹ���ʵ��RejectExecutionHandler�ӿ��Զ������,���¼��־���߳־û����ܴ���������
- keepAliveTime:�̻߳����ʱ��,�̳߳صĹ����߳̿��к�,����ʱ��,�����������ܶ�,����ÿ������ִ�е�ʱ��Ƚ϶�,���Ե���ʱ��,����̵߳�������
- TimeUnit:�̻߳����ʱ��ĵ�λ
�ύ����
- pool.execute():����Ҫ����ֵ������,��Runnable
- pool.submit():��Ҫ����ֵ������,�̳߳ػ᷵��Fature���͵Ķ���,����future.get()���Ի��ִ�н��
�ر��̳߳�,ԭ�����DZ���ÿ���߳�,����interrupt�����ж��߳�
- shutdown:�ж�û������ִ��������߳�
- shutdownNow:�ж������߳�
����̳߳ص�����
- taskCount:�̳߳���Ҫִ�е���������
- completedTaskCount:����ɵ���������
- largestPoolSize:�̳߳�����������������߳�����
- getPoolSize:�̳߳ص��߳�����
- getActiveCount:��ȡ����߳���
11��Executor���
Java�̼߳��ǹ�����λ,Ҳ��ִ�л���,��JDK1.5֮��,������Ԫ����Runnable��Callable,��ִ�л�����Excutor����ṩ,��HotSpot VMģ����,
- Java�̱߳�һ��һ��ӳ��Ϊ���ز���ϵͳ���߳�,Java�߳�����ʱ�ᴴ��һ�����ز���ϵͳ�߳�,�߳���ֹʱ,����߳�Ҳ�ᱻ����ϵͳ����
- �ϲ�ģ�;����û�����ĵ�������Executor��ܽ�����ӳ��Ϊ�̶��������߳�,�²�ģ�;����ɲ���ϵͳ�ں˿���
Excutor��ܵĽṹ��Ҫ��3�������
- 1������:Runnable����Callable�ӿ�
- 2�������ִ��:���Ľӿ�Executor �� ExecutorService implements Excutor�ӿ�,�ؼ���ThreadPoolExecutor��ScheduledThreadPoolExecutorʵ����ExcutorService�ӿ�
- 3���첽����Ľ��:����Future�ӿں�Future�ӿڵ�ʵ����FutureTask
��������ͽӿڼ̳й�ϵ
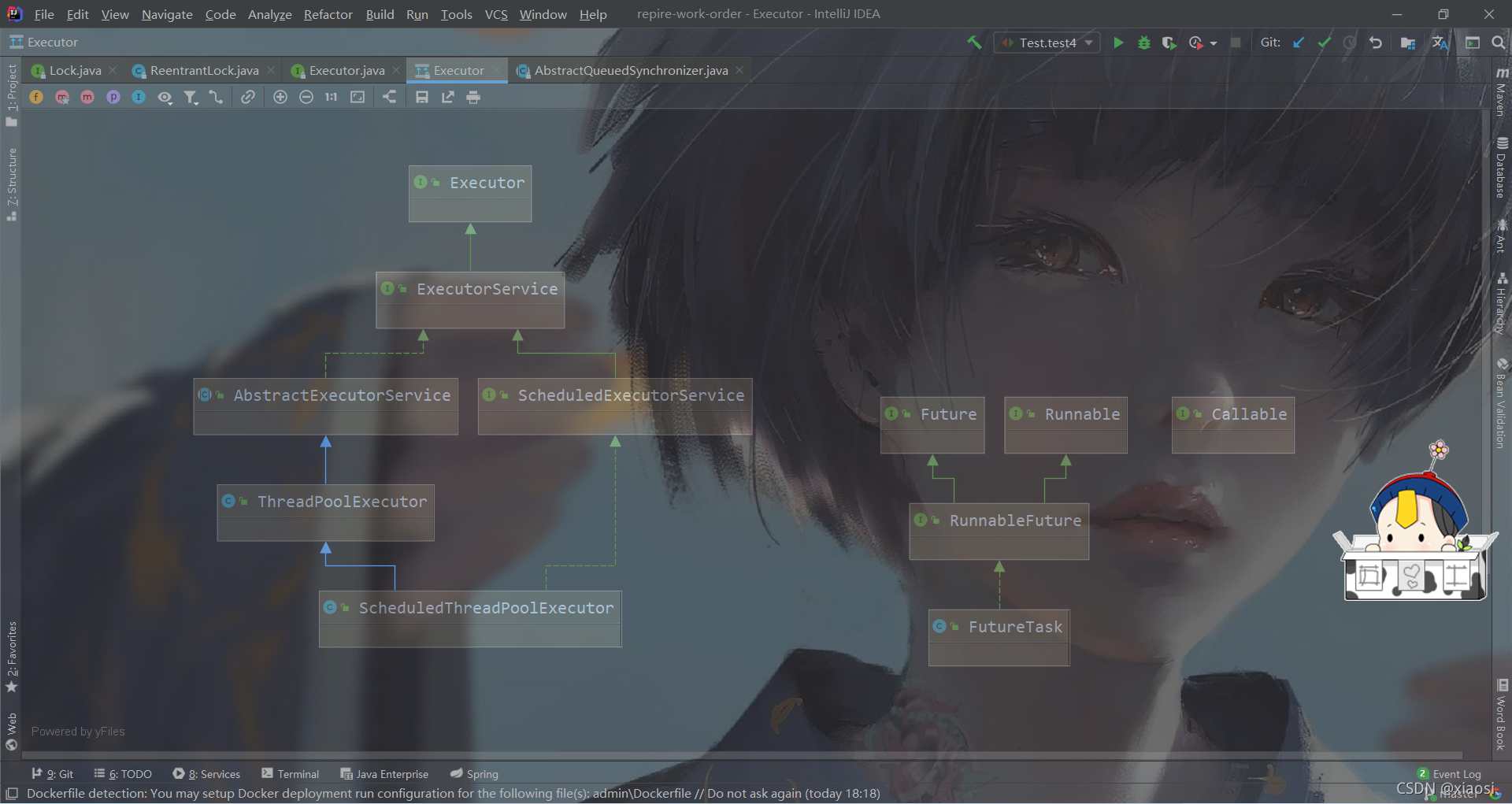
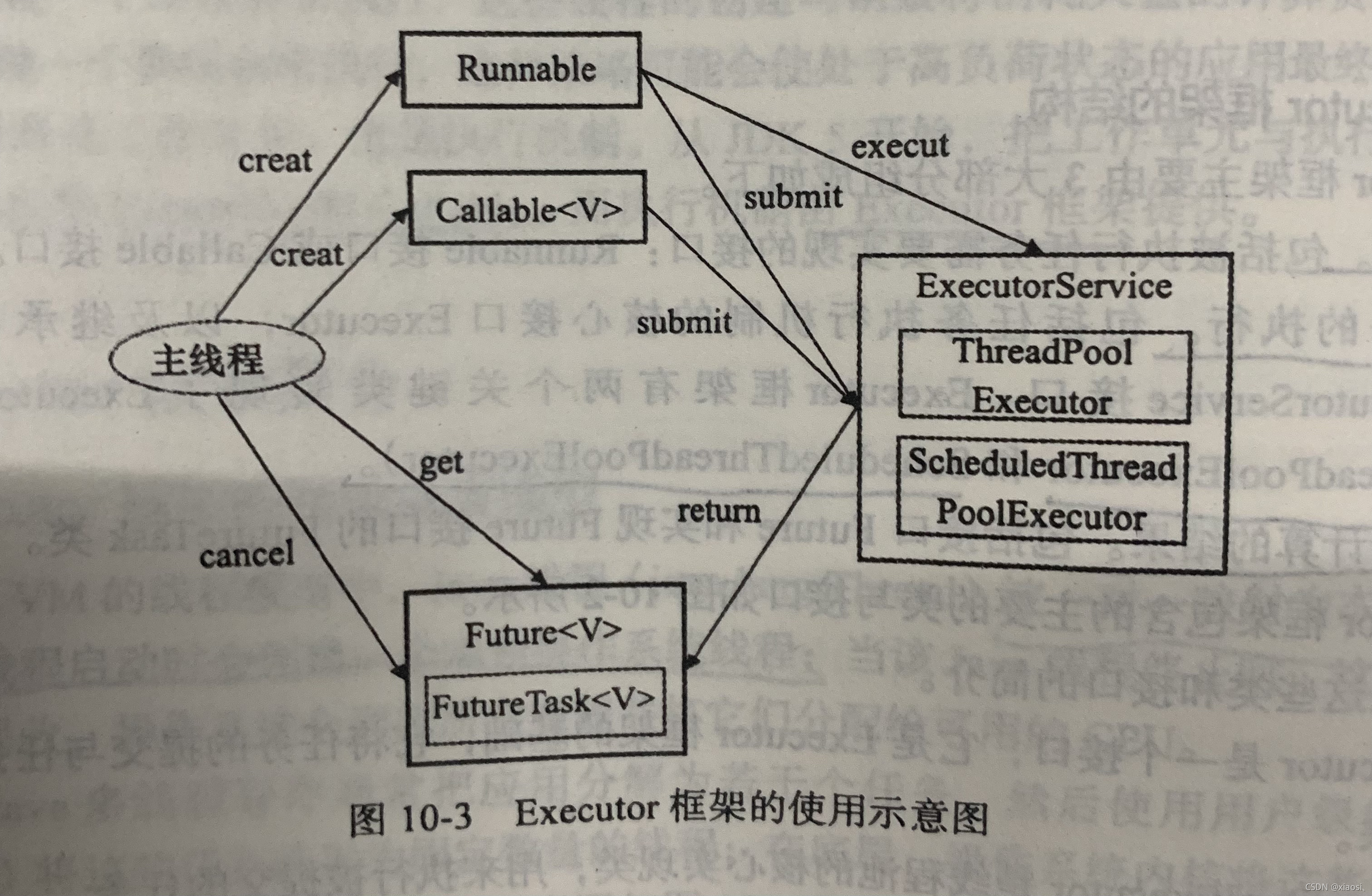
���߳���Ҫ�ȴ���Runnable����Callable�ӿڵ��������,������Executors����һ��Runnable�����װΪһ��Callable����
- Executors.callable(Runnable xxx)
- Executors.callable(Runnable xxx,Object result)
Ȼ�����Runnable�ӿڽ���ExecutorServiceִ��,�������submit(),��һ��Future,��Ŀǰ��JDK���ص�������FutureTask
ExecutorService.execute(Runnable xxx)ExecutorService.submit(Runnable xxx)ExecutorService.submit(Callable<T> xxx)
ע��,����FutureTaskʵ����Runnable,Ҳ����ֱ�Ӵ���FutureTask�������ִ��
Executor��Ա
- 1��ThreadPoolExecutor
- FixedThreadPoolExecutor:ʹ�������LinkedBlockingQueue��Ϊ��������,�������ΪInteger.MAX_VALUE,����߳������ᳬ��corePoolSize,maximumPoolSize�������ò���,keepAliveTime�������ò���,�ܾ����Բ���������
- SingleThreadPoolExecutor:ֻ��һ���̹߳���,Ҳ�������LinkedBlockingQueue
- CachedThreadPoolExecutor:û�������Ķ���,���������Ҫ����һ���߳�,�����´����̹߳��������CPU���ڴ���Դ�ľ�
- 2��ScheduledThreadPoolExecutor:�������ӳ�֮��ִ������,��Timer����,���ǹ��ܸ�ǿ���������ڹ��캯����ָ�������Ӧ�ĺ�̨�߳�,����DelayQueue��ʱ����
- SingleThreadScheduledExecutor
- 3��Future
- 4��Runnable��Callable�ӿ�