今天我们就来说说关于Java网络爬虫的介绍。在本文中,我们以虎扑榜的新闻标题和详情页为例。我们需要提取的内容如下:

我们需要提取带圆圈的文本及其对应的链接。在提取的过程中,我们会使用两种方式提取,一种是Jsoup,一种是httpclient+正则表达式。这也是Java网络爬虫常用的两种方式。你不知道这两种方式是无关紧要的。后面会有相应的手册。在正式编写提取程序之前,先讲解一下Java爬虫系列博文的环境。本系列博文中的所有demo都是使用SpringBoot搭建的。无论您使用什么环境,您只需要正确导入相应的包即可。
基于Jsoup的信息抽取
首先创建一个随机名称的Springboot项目,并在pom.xml中引入Jsoup依赖
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.12.1</version>
</dependency>
好的,我们一起来分析一下页面。你还没有浏览它。在列表页面中,我们使用 F12 评论元素来查看页面结构。经过我们的分析,我们发现列表新闻在<div class="news-list">标签下,每条新闻都是一个li标签。分析结果如下:
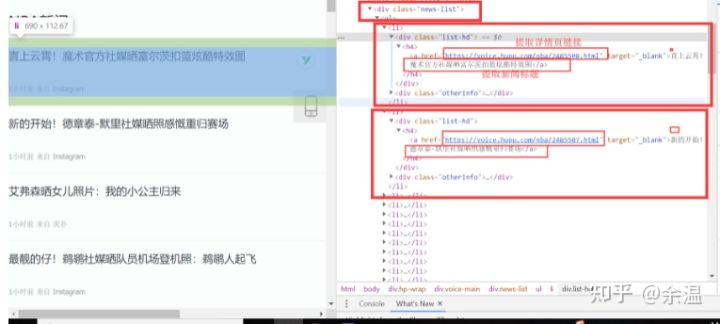
因为之前我们已经知道了css选择器,所以我们编译了我们a标签的css选择器的代码:Div。新闻列表 > UL > Li > Div. list-hd > H4 > a,结合浏览器的opy功能。全部都准备好了。我们一起编译了Jsoup模式提取信息的代码:
/**
* jsoup Ways to Get Tiger Pop News List Page
* @param url Hupu News List page url
*/
public void jsoupList(String url){
try {
Document document = Jsoup.connect(url).get();
// Using css selector to extract list news a tag
// <a href= "https://voice.hupu.com/nba/2484553.html" target="_blank">Howard: I had a 30-day diet during the summer break, which tested my mind and body.</a>
Elements elements = document.select("div.news-list > ul > li > div.list-hd > h4 > a");
for (Element element:elements){
// System.out.println(element);
// Get Details Page Links
String d_url = element.attr("href");
// Get the title
String title = element.ownText();
System.out.println("Details page links:"+d_url+" ,Details page title:"+title);
}
} catch (IOException e) {
e.printStackTrace();
}
}
使用Jsoup提取信息还是很简单的。只需5或6行代码即可完成。更多关于Jsoup是如何提取节点信息的,可以参考jsoup的官网教程。下面我们编写main方法来执行jsoupList方法,看看jsoupList方法是否正确。
public static void main(String[] args) {
String url = "https://voice.hupu.com/nba";
CrawlerBase crawlerBase = new CrawlerBase();
crawlerBase.jsoupList(url);
}
执行main方法,得到如下结果:

从结果中,我们可以看到我们正确提取了我们想要的信息。如果要采集详情页的信息,只需要写一个采集详情页的方法,在方法中提取详情页对应的节点信息,然后把从列表页中提取的链接传入到提取详情页的方法中页。
httpclient+正则表达式
上面,我们使用Jsoup正确提取了老虎池列表消息。接下来,我们使用httpclient+正则表达式来提取老虎池列表消息。使用这种方法会涉及哪些问题?httpclient+正则表达式的方式涉及到很多知识点。它涉及到正则表达式、Java正则表达式和httpclient。如果你还不知道,你可以点击下面的链接进行简单的了解。
正则表达式:正则表达式
Java正则表达式:Java正则表达式
httpclient:httpclient
在pom.xml文件中,我们引入了httpclient相关的Jar包
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.10</version>
</dependency>
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpcore</artifactId>
<version>4.4.10</version>
</dependency>
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpmime</artifactId>
<version>4.5.10</version>
</dependency>
关于Tiger Pop List的新闻页面,我们在使用Jsoup模式时做了一个简单的分析。这里我们不再重复分析。对于正则表达式提取,我们需要找到可以表示列表新闻的结构,例如<div class="list-hd"> <h4> <a href="https://voice.hupu.com/nba/2485508。 html" target="_blank"> 直上天空!魔术官媒曝光富尔茨扣篮炫酷特效图</a> </h4> </div> 这种结构,每个榜单新闻只有链接和标题不同,其余都一样,而且<div class="list-hd "> 是列出新闻所独有的。最好不要定期匹配标签,因为标签在其他地方也存在,所以我们需要做其他处理来增加我们的难度。
/**
* httpclient + Regular Expressions Get Tiger Pop News List Pages
* @param url Hupu News List page url
*/
public void httpClientList(String url){
try {
CloseableHttpClient httpclient = HttpClients.createDefault();
HttpGet httpGet = new HttpGet(url);
CloseableHttpResponse response = httpclient.execute(httpGet);
if (response.getStatusLine().getStatusCode() == 200) {
HttpEntity entity = response.getEntity();
String body = EntityUtils.toString(entity,"utf-8");
if (body!=null) {
/*
* Replace line breaks, tabs, carriage returns, and remove these symbols. Regular representations are simpler to write.
* Only space symbols and other normal fonts
*/
Pattern p = Pattern.compile("\t|\r|\n");
Matcher m = p.matcher(body);
body = m.replaceAll("");
/*
* Extracting regular expressions from list pages
* li after line breaks are removed
* <div class="list-hd"> <h4> <a href="https://voice.hupu.com/nba/2485167.html" target="_blank">Interaction with fans! Celtic Official Sunshine Team Open Training Day Photos </a> </h4> </div>
*/
Pattern pattern = Pattern
.compile("<div class=\"list-hd\">\\s* <h4>\\s* <a href=\"(.*?)\"\\s* target=\"_blank\">(.*?)</a>\\s* </h4>\\s* </div>" );
Matcher matcher = pattern.matcher(body);
// Match all data that conforms to regular expressions
while (matcher.find()){
// String info = matcher.group(0);
// System.out.println(info);
// Extract links and titles
System.out.println("Details page links:"+matcher.group(1)+" ,Details page title:"+matcher.group(2));
}
}else {
System.out.println("Handling failure!!! Get the text empty");
}
} else {
System.out.println("Handling failure!!! Return status code:" + response.getStatusLine().getStatusCode());
}
}catch (Exception e){
e.printStackTrace();
}
}
从代码行数可以看出,比Jsource模式多很多。虽然代码很多,但整体来说还是比较简单的。在上面的方法中,我做了一个特殊的处理。首先,我替换了httpclient获取到的字符串体中的换行符、制表符和回车符,因为这样的处理可以减少编写正则表达式时的一些额外干扰。接下来,我们修改main方法以运行httpClientList方法。
public static void main(String[] args) {
String url = "https://voice.hupu.com/nba";
CrawlerBase crawlerBase = new CrawlerBase();
// crawlerBase.jsoupList(url);
crawlerBase.httpClientList(url);
}
操作结果如下:

使用httpclient+正则表达式,也正确获取了列表新闻的标题和详情页链接。这是Java爬虫系列的第一篇。本文主要介绍Java网络爬虫。我们使用jsource和httpclient+定期提取新闻标题和链接到Hupu List新闻的详细页面。当然还有很多不完整的,比如收集详情页信息入数据库。
推荐学习视频课程:
Java基础视频教程_java从入门到精通_java300集新手必看教程
【尚学堂】Java300集零基础适合初学者视频教程_Java300集零基础教程_Java初学入门视频基础巩固教程_Java语言入门到精通