目录
引言:
世事万物有盛衰,人生安得常少年

连接池概念
-
数据库连接池的基本思想:就是为数据库连接建立一个“缓冲池”。预先在缓冲池中放入一定数量的连接,当需要建立数据库连接时,只需从“缓冲池”中取出一个,使用完毕之后再放回去。
-
数据库连接池负责分配、管理和释放数据库连接,它允许应用程序重复使用一个现有的数据库连接,而不是重新建立一个。
-
数据库连接池在初始化时将创建一定数量的数据库连接放到连接池中,这些数据库连接的数量是由最小数据库连接数来设定的。无论这些数据库连接是否被使用,连接池都将一直保证至少拥有这么多的连接数量。连接池的最大数据库连接数量限定了这个连接池能占有的最大连接数,当应用程序向连接池请求的连接数超过最大连接数量时,这些请求将被加入到等待队列中。
传统连接的缺点
???? ? ?1.普通的JDBC数据库连接使用DriverManager来获取,每次向数据库建立连接的时候都要将Connection加载到内存中,再验证用户名和密码(得花费0.05s~1s的时间)。需要数据库连接的时候,就向数据库要求一个,执行完成后再断开连接。这样的方式将会消耗大量的资源和时间。数据库的连接资源并没有得到很好的重复利用。若同时有几百人甚至几千人在线,频繁的进行数据库连接操作将占用很多的系统资源,严重的甚至会造成服务器的崩溃。
? ? ? ? 2.对于每一次数据库连接,使用完后都得断开。否则,如果程序出现异常而未能关闭,将会导致数据库系统中的内存泄漏,最终将导致重启数据库。(回忆∶何为Java的内存泄漏?)
???????3.这种开发不能控制被创建的连接对象数,系统资源会被毫无顾及的分配出去,如连接过多,中可能导致空存泄漏,服务器崩溃。
数据库连接池的优点
- 提高程序的响应速度(减少创建连接相应的时间)
- 减低资源的消耗(可以重复使用以及提供好的连接)
- 便于连接的管理
实现方法
DBCP 是Apache提供的数据库连接池。tomcat 服务器自带dbcp数据库连接池。速度相对c3p0较快,但因自身存在BUG,Hibernate3已不再提供支持。
C3P0 是一个开源组织提供的一个数据库连接池,速度相对较慢,稳定性还可以。hibernate官方推荐使用
Proxool 是sourceforge下的一个开源项目数据库连接池,有监控连接池状态的功能,稳定性较c3p0差一点
BoneCP 是一个开源组织提供的数据库连接池,速度快
Druid 是阿里提供的数据库连接池,据说是集DBCP 、C3P0 、Proxool 优点于一身的数据库连接池,但是速度不确定是否有BoneCP快
演示Druid连接
连接步骤:①导入jar包,②测试连接代码,③写配置文件
????????Druid是阿里巴巴开源平台上一个数据库连接池实现,它结合了C3P0、DBCP、Proxool等DB池的优点,同时加入了日志监控,可以很好的监控DB池连接和SQL的执行情况,可以说是针对监控而生的DB连接池,**可以说是目前最好的连接池之一。
DRUID
①导包
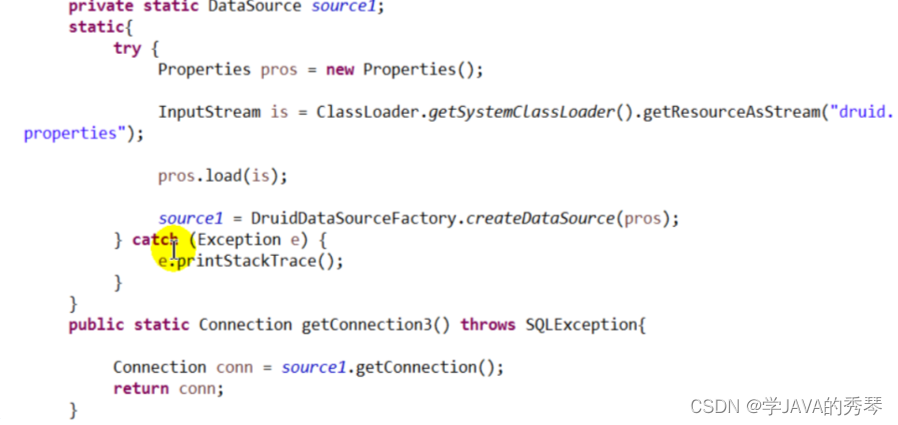
②测试连接代码
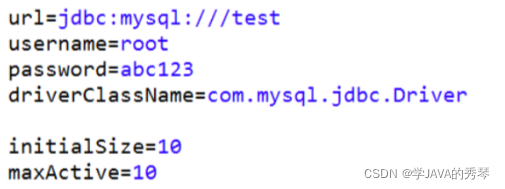
③写配置文件
QueryRunner插入操作
public static void testInsert() {
Connection conn = null;
try {
QueryRunner runner = new QueryRunner();
conn = JDBCUtils.getConnection3();
String sql = "insert into customers(name,email,bitrh)values(?,?,?)";
int insertCount = runner.update(conn, sql, "陈子宏", "chenzihong@123", "1994-09-09");
System.out.println("添加了" + insertCount + "条记录");
} catch (SQLException e) {
e.printStackTrace();
} finally {
JDBCUtils.colseResource(conn, null);
}
}QueryRunner查询操作
//测试查询:BeanHander:是ResultSetHandler接口的实现类,用于封装表中的一条记录
public static void testQuery1() {
Connection conn = null;
try {
QueryRunner runner = new QueryRunner();
conn = JDBCUtils.getConnection3();
String sql = "select id,name,email,birth from customers where id =?";
BeanHandler<Customer> handler = new BeanHandler<>(Customer.class);
Customer customer = runner.query(conn, sql, handler, 21);
System.out.println(customer);
} catch (SQLException e) {
e.printStackTrace();
} finally {
JDBCUtils.colseResource(conn, null);
}
}