1 ����
1.1 ���͵ĸ���
���͵ı��ʾ��ǡ��������͵IJ������������ǿ��ѡ����͡�����Ϊ�������͵�һ��ռλ��(��ʽ����),�����߱�����,�ڵ��÷���ʱ���봫��ʵ�����͡�
����,�����List�ķ���ΪPerson ,��ʾList�ڴ洢��Ԫ��ΪPerson�Ķ���:
public class TestGerner {
public static void main(String[] args) {
List<Person> persons = new ArrayList<>();
persons.add(new Person("AA",12));
persons.add(new Person("BB",12));
persons.add(new Person("CC",12));
Person person = persons.get(0); //get�ķ���ֵ����Person����
}
}
2 Collection�ӿ�
2.1 ���ϼܹ�
? Collection �ӿڴ洢һ�鲻Ψһ,����Ķ���
? List �ӿڴ洢һ�鲻Ψһ,����(����˳��)�Ķ���
? Set �ӿڴ洢һ��Ψһ,����Ķ���
? Map�ӿڴ洢һ���ֵ����,�ṩkey��value��ӳ��
? Key Ψһ ����
? value ��Ψһ ����

2.2 List
List�������ض���������
����:List��ÿ��Ԫ�ض���������ǡ����Ը���Ԫ�ص��������(��List�е�λ��)����Ԫ��,�Ӷ���ȷ������ЩԪ�ء�
���ظ�: List���������ظ���Ԫ�ء���ȷ�еؽ�,Listͨ����������e1.equals(e2)��Ԫ���ظ�����������
List�ӿڳ��õ�ʵ������3��:ArrayList��LinkedList��Vector��
ArrayList�ײ�ʹ������ʵ�ֵĴ洢���ص�:��ѯЧ�ʸ�,��ɾЧ�ʵ�,�̲߳���ȫ���鳤��������,��ArrayList�ǿ��Դ�����������Ķ���,���Ȳ������ơ�
2.3 Map�ӿ�
? �ص� key-valueӳ��
? HashMap
? Key���� Ψһ (Set)
? Value ���� ��Ψһ (Collection)
? LinkedHashMap
? �����HashMap �ٶȿ�
? TreeMap
? ���� �ٶ�û��hash��
? ����:Set��Map�й�ϵ��?
? ��������ͬ�����ݽṹ,ֻ����map��key�洢����,��Set��
Map�г��õķ���:
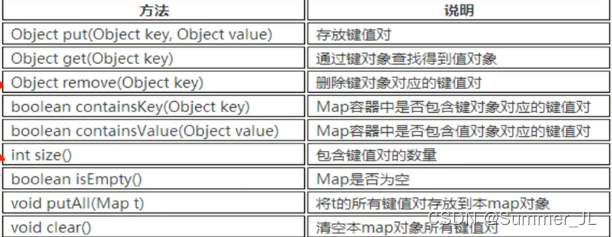
2.3.1 HashMap�洢��ֵ�Եײ����
HashMap�ײ�ʵ�ֲ����˹�ϣ��,����һ�ַdz���Ҫ�����ݽṹ��
��ϣ���Ļ����ṹ���ǡ�����+��������
���ݽṹ���������������ʵ�ֶ����ݵĴ洢,���Ǹ����ص㡣
(1)����Uռ�ÿռ�������Ѱַ����,��ѯ�ٶȿ졣����,���Ӻ�ɾ��Ч�ʷdz��͡�
(2)�����Uռ�ÿռ䲻������Ѱַ����,��ѯ�ٶ���������,���Ӻ�ɾ��Ч�ʷdz��ߡ�
��ô,�����ܲ��ܽ��������������ŵ�(����ѯ��,��ɾЧ��Ҳ��)��?�𰸾��ǡ���ϣ������
��ϣ���ı��ʾ��ǡ�����+��������
����Entry[] table����HashMap�ĺ������ݽṹ,����Ҳ��֮Ϊ��λͰ���顱��
һ��Entry����洢��:
1.key:������value:��ֵ��
2.next:��һ���ڵ�
3.hash:�������hashֵ
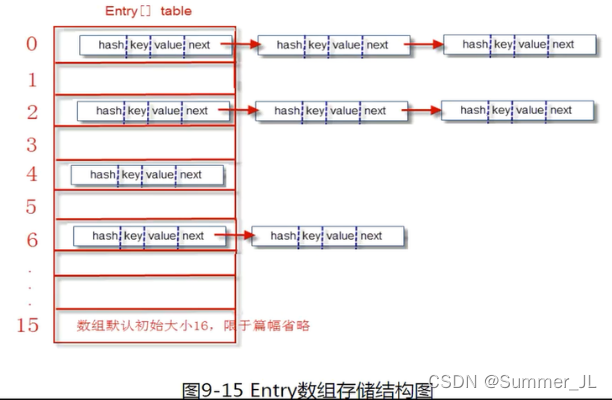

2.3.2 HashMap���Ҽ�ֵ�Եײ����
ȡ���ݹ���get(key)
������Ҫͨ��key�����á���ֵ�ԡ�����,��������value���������˴洢���ݹ���,ȡ���ݾͱȽϼ���,�μ����²���U
(1)���key��hashcode,ͨ��hash()ɢ���㷨�õ�hashֵ,������λ�������λ�á�
(2)�������ϰ����Ƚ�key������equals()����,��key��������������нڵ��key�������
�Ƚ�,ֱ����������true�Ľڵ����Ϊֹ��
(3)����equals()Ϊtrue�Ľڵ�����value����
�����˴�ȡ���ݵĹ���,����������һ��hashcode()��equals�����Ĺ�ϵ�U
Java�й涨,����������ͬ(equals()Ϊtrue)�Ķ�����������ȵ�hashCode����Ϊ���equals()Ϊtrue�����������hashcode��ͬ;���������洢�����оͷ�������ۡ�
��������
HashMap��λͰ����,��ʼ��СΪ16��ʵ��ʹ��ʱ,��Ȼ��С�ǿɱ�ġ����λͰ�����е�Ԫ�شﵽ(0.75*����length),�����µ��������С��Ϊԭ��2����С��
���ݺܺ�ʱ�����ݵı����Ƕ����µĸ��������,�������������ݰ����������������С�
2.3.3 TreeMap��ʹ�ú͵ײ�ʵ��
TreeMap�Ǻ�ڶ������ľ���ʵ�֡�
2.3.4 HashMap��HashTable������
(1)HashMap:�̲߳���ȫ,Ч�ʸߡ�����key��valueΪnull��
(2)HashTable:�̰߳�ȫ,Ч�ʵ͡�������key��valueΪnull��
3 Set�ӿ�
Set�ӿڼ̳���Collection, Set�ӿ���û����������,������Collection������ȫһ�¡�������ǰ��ͨ��Listѧϰ�ķ���,��Set����Ȼ���á����,ѧϰSet��ʹ�ý�û���κ��Ѷȡ�
Set�����ص���������ظ�������ָSet�е�Ԫ��û������,����ֻ�ܱ�������;�����ظ�ָ�����������ظ���Ԫ�ء���ȷ�еؽ�,��Ԫ�������Set��ij��Ԫ��ͨ��equals()�����Ա�Ϊtrue,���ܼ���;����,Set��Ҳֻ�ܷ���һ��nullԪ��,���ܶ����
Set���õ�ʵ������:HashSet��TreeSet��,һ��ʹ��HashSet��
3.1 TreeSet��ʹ�ú͵ײ�ʵ��
ͬHashSet��ʹ�ô���һ��,����Ϊ����,�����ظ���
4. ʹ��Iterator��������������Ԫ��(List/Set/Map)
���м������δ�ṩ��Ӧ�ı�������,���ǰѰѱ���������������ɡ�������Ϊ���϶���,ר��ʵ�ּ��ϱ����� Iterator�ǵ��������ģʽ�ľ���ʵ�֡�
? Iterator����
? boolean hasNext(): �ж��Ƿ������һ���ɷ��ʵ�Ԫ��
? Object next(): ����Ҫ���ʵ���һ��Ԫ��
? void remove(): ɾ���ϴη��ʷ��صĶ���
4 ���ϵı���
4.1 Iterator����List
public static void main(String[] args) {
testIteraterList();
}
public static void testIteraterList(){
List<String> list = new ArrayList<>();
list.add("aa");
list.add("bb");
list.add("cc");
//ʹ��Iterater����������
for (Iterator<String> iter = list.iterator();iter.hasNext();){
String temp = iter.next();
System.out.println(temp);
}
}
4.2 Iterator����Map
(1)��һ�ַ�ʽ
public static void main(String[] args) {
testIteraterList();
}
public static void testIteraterList(){
Map<Integer, String> map = new HashMap<>();
map.put(100,"aaa");
map.put(200,"bbb");
map.put(300,"ccc");
Set<Map.Entry<Integer, String>> entries = map.entrySet();
//ʹ��Iterater����������
for (Iterator<Map.Entry<Integer, String>> iter = entries.iterator();iter.hasNext();){
Map.Entry<Integer, String> entry= iter.next();
System.out.println(entry);
}
}
(2)�ڶ��ַ�ʽ
Set<Integer> set = map.keySet();
for ( Iterator<Integer> iter = set.iterator();iter.hasNext();){
Integer key = iter.next();
System.out.println(key+"---"+map.get(key));
}
5.�����ܽ�
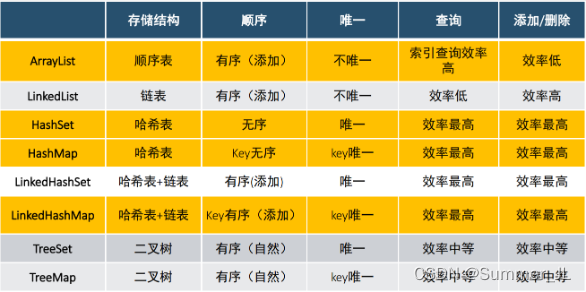
5.1 ���Ϻ�����ıȽ�
? ���鲻����������,�������Ե�ȱ��,������ȫ�ֲ��������һЩȱ��,�����������ʵ��,�ɴ����������Ŀ���Ч�ʶ��Ҳ�ͬ�ļ��Ͽ����������ڲ�ͬ���ϡ���������:
? 1 : ���������̶�������̬�ı�,������������̬�ı䡣
? 2:�����ܴ�Ż����������ͺ������������͵�����,����������ֻ�ܷ������������͵����ݡ�
? 3:�������ж�����ʵ�ʴ��ж���Ԫ��,lengthֻ������array����;���Ͽ����ж�ʵ�ʴ��ж���Ԫ��,�����ܵ����������ġ�
? 4:�����ж������ݽṹ(˳�������������ϣ��������)����������(�Ƿ�����,�Ƿ�Ψһ)����ͬ���ó���(��ѯ��,����ɾ��������),�������������˳�����ʽ��
? 5:�����������ʽ����,���з�װ���̳С���̬���������,ͨ���ķ��������Ե��ü���ʵ�ָ��ָ��Ӳ���,�����������Ŀ���Ч�ʡ�
5.2 ArrayList��LinkedList ����ϵ������
? ��ϵ:
? ��ʵ����List�ӿ�
? ���� ��Ψһ(���ظ�)
? ArrayList
? ���ڴ��з��������Ŀռ�,ʵ���˳��ȿɱ������
? �ŵ�:����Ԫ�غ��������Ԫ�ص�Ч�ʱȽϸ�
? ȱ��:���Ӻ�ɾ��������ƶ�Ԫ��Ч�ʵ�,�������ݲ�ѯЧ�ʵ�
? LinkedList
? ���������洢��ʽ��
? ȱ��:�������������Ԫ��Ч�ʵ���
? �ŵ�:���롢ɾ��Ԫ��Ч�ʱȽϸ�(����ǰ��Ҳ�DZ����ȵ�Ч�ʲ�ѯ�ſɡ��������ɾ��������ͷβ���Լ��ٲ�ѯ����)��
5.3 Vector��ArrayList����ϵ������
? Vector��ArrayList����ϵ������
? ʵ��ԭ����ͬ,������ͬ,���dz��ȿɱ������ṹ,�ܶ�����¿��Ի���
? ���ߵ���Ҫ��������
? Vector������JDK�ӿ�,ArrayList�����Vector���½ӿ�
? Vector�̰߳�ȫ,Ч�ʵ���;ArrayList���ٶ��ᰲȫ,�̷߳ǰ�ȫ
? ����������ʱ,VectorĬ������һ��,ArrayList����50%
5.4 HashMap��Hashtable����ϵ������
? ʵ��ԭ����ͬ,������ͬ,�ײ㶼�ǹ�ϣ���ṹ,��ѯ�ٶȿ�,�ںܶ�����¿��Ի���
? ���ߵ���Ҫ��������
? Hashtable������JDK�ṩ�Ľӿ�,HashMap���°�JDK�ṩ�Ľӿ�
? Hashtable�̳�Dictionary��,HashMapʵ��Map�ӿ�
? Hashtable�̰߳�ȫ,HashMap�̷߳ǰ�ȫ
? Hashtable������nullֵ,HashMap����nullֵ
5.5 Collection��Collections������
? Collection��Java�ṩ�ļ��Ͻӿ�,�洢һ�鲻Ψһ,����Ķ������������ӽӿ� List��Set��
? Java�л���һ��Collections��,ר���������������� ,���ṩһϵ�о�̬����ʵ�ֶԸ��ּ��ϵ������������̰߳�ȫ���Ȳ�����
6 Collections������
��java.util.Collections �ṩ�˶�Set��List��Map����������䡢����Ԫ�صĸ���������
1.void sort(List) //��List�����ڵ�Ԫ������,����Ĺ����ǰ��������������
2. void shuffle(List) //��List�����ڵ�Ԫ�ؽ���������С�
3.void reverse(List) //��List�����ڵ�Ԫ�ؽ����������С�4.void fill(List, Object)//��һ���ض��Ķ�����д����List������
5. int binarySearch(List,object) //����˳���List����,�����۰���ҵķ��������ض�����,���ҳɹ��ظö������ڵ�λ�á�
7 ʹ�������洢��������
7.1 map��list��ϴ洢���ű�
ʹ�����״洢��������:
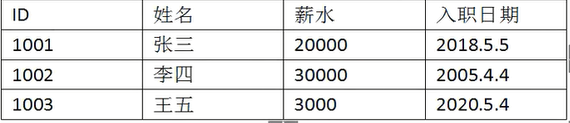
�洢����ʽ:
ÿһ������ʹ��һ��:Map
��������ʹ��һ��:List
ORM˼��:�����ϵӳ�䡣
���˼��:map��ʾһ������,���������Ƕ��map;�����map�ŵ�list�С�
public class TestStoreData {
public static void main(String[] args) {
Map<String, Object> row1 = new HashMap<>();
//�洢��һ������
row1.put("id", 1001);
row1.put("����", "����");
row1.put("нˮ", 2000);
row1.put("��ְ����", "2018.5.5");
//�ڶ���
Map<String, Object> row2 = new HashMap<>();
row2.put("id", 1002);
row2.put("����", "����");
row2.put("нˮ", 30000);
row2.put("��ְ����", "2005.5.5");
//������
Map<String, Object> row3 = new HashMap<>();
row3.put("id", 1003);
row3.put("����", "����");
row3.put("нˮ", 3000);
row3.put("��ְ����", "2020.5.4");
List<Map<String, Object>> table1 = new ArrayList<>();
table1.add(row1);
table1.add(row2);
table1.add(row3);
for (Map<String, Object> row : table1) {
Set<String> keySet = row.keySet();
for (String key : keySet){
System.out.print(key+":"+row.get(key)+" ");
}
System.out.println();
}
}
}
7.2 javaBean��list��ϴ洢���ű�
���˼��:
ÿһ����ʹ��һ��:javabean����;
��������ʹ��һ��Map��List��
public class TestStoreData2 {
public static void main(String[] args) {
User user1 = new User(1001,"����",20000,"2018.5.5");
User user2 = new User(1002,"����",30000,"2005.4.5");
User user3 = new User(1003,"����",3000,"2020.5.4");
//����һ:��user����list
List<User> table = new ArrayList<>();
table.add(user1);
table.add(user2);
table.add(user3);
for (User user:table){
System.out.print(user.getId()+":"+user.getName()+":"+" "+user.getSalary()+":"+" "+user.getData());
System.out.println();
}
//������:��user����Map
Map<Integer,User> map = new HashMap<>();
map.put(1,user1);
map.put(2,user2);
map.put(3,user3);
Set<Integer> keySet = map.keySet();
for (Integer key:keySet){
System.out.print(map.get(key).getId()+" "
+map.get(key).getName()+" "
+map.get(key).getSalary()+""
+map.get(key).getData());
System.out.println();
}
}
}
class User{
private int id;
private String name;
private double salary;
private String data;
public User() {
}
public User(int id, String name, double salary, String data) {
this.id = id;
this.name = name;
this.salary = salary;
this.data = data;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public double getSalary() {
return salary;
}
public void setSalary(double salary) {
this.salary = salary;
}
public String getData() {
return data;
}
public void setData(String data) {
this.data = data;
}
}