ǰ��
�����ܶ༼���ĵ�,Ҳ������ܶ��ּ�������,Ҳʵ���ϼ��˽����ֺ����ٹ�����������������,����һֱû��һ����������һ����¼,JVM����,һ���������ܸߴ���,����һ�����������ڵ�Java����ʦ����Ҫ���պ����Ա���Ҫ������һ������,��ʵ�������ڹ�˾������������ȥ���ֵ��ŵĻ�����֮����,�ܶ��˿���̸����JVM,��������,����ʵ����һ����,�Ϳ��ܻ�С¹��ײ,�������ϵ�ϵͳ,ʵ�����Դ��ʼ���Ϊ0,���������Ļ���,�ڴ��ͻ�����,�����ǻ�������˾,��ѹ�����������������ȥ����jvm�Ļ����,��η���һ���������ϵ�����,�����Լ���������JVM��һ�����ǰ������Ļ���,��Ƭ���ͽ�Ϊ�����ͼ�¼,���˲�����һ��רҵ����ά��Ա,����JVM���յ�Ҳ�������
1. ���ϻ���ͻȻ��������,��������ϵͳ���ܽ�������������,Ϊʲô?�����ܱȽφ���,������ϣ����¼һ�������ļ�¼��
1.1:�ǵøոս����¹�˾��ʱ��,�ϴ��˵������ϵͳ��jvm������,����ϵͳҲ������˵�������õ��������,��������ϵͳ��һ���Ƚϴ��͵�ERPϵͳ,����ÿ��������ʮ�ּ��ٵ�,���´�����ܾ�" �㶮�� ",�ܴ�һ����ԭ��Ҳ��ÿ���˶���æ,����Ҳ�Dz��п���,���������ֶ�������(�пͷ�������,�����ϵ�bug,�в��������,������Ҫ�ع�,��֯�ܹ��ĵȵ�����),ÿ���˶��Ǹ���æµ�Լ��Ĺ���,Ҳ����һ��< code review>�����Ҫ�Ļ���,��ž���ı�ɵ����ϴ��Ե� ��
ǧ����Ҵ�����,����ʵ���Ϻܴ�һ����ԭ��Ҳ���������IJ��淶�Ͳ�������д�뵼�µ�,����ѹ��û��ʱ��ȥ����gc������ϵͳ��jvm����,һֱʹ�õĶ���Ĭ�ϵ�jvm����,ʵ��������ȫ��������,ͻȻ��һ��,Ҳ������ǰ���ƴ�Լһ������,ϵͳ��Ҫ12��Сʱ��������һ��,������˵,ϵͳ��������,����һЩ���ܻ�ֱ�ӳ�ʱ,�ڼ�֮ǰ�����¹�����ϵͳ��OOM���������,�����ܹ�����̨������,�������ֹ�崻�������������������������һ�����,�ٽ��ܾ�û�й���������ˡ�
2.����ϵͳ��JVM�Ų����,����������ͼ,ʱ���,����,2������������ϻ���,��:��һ����ר�Ÿ�������ϵͳ��������,ֻ��Ƶ��������!
���������һ������ͬʱҲ����̴���,ȥ��ȡȡ��,����һ�´����ǵĽ������,������·,���Ǿ�������ǰ����˵,������������ϵͳ�ļ�����Ա����,����ȷʵ�ܶ����Ҳ����һЩ����,����,Ҳ����ͻ����һ������,���ٴ���ܴ�ʲô�ط�����,����,ƨ������˵,��ս!
3. �����˽��¼���JVM���õ�һЩ����۲�����GC��һЩ��������,�����ϻ����ķ������������
1�����������õ���Linux��һЩ��������(��gc):
- jstat -gc PID ��gc��־��
- jmap -heap PID ���ڴ���������ʹ����,ʵ�������������Ҳ�ܿ���,���ǿ���û��jmap�ۿ�������ô���㡿
- java -XX:+PrintCommandLineFlags-version ���鿴����ʹ�õ�������������
- free -m ��������������,��������Ǻ�������ȥ��,�������ھ�������ι۲��,���Լ�Ҳ�����о�,û������,���˷���һ��������
���������ŵĹ�����Ҳ��ֻ���õ������ϵ��������
2����Ȼ,jstat���кܶ�����,�����ֱ����������,������������Ҳֻ���������еļ�������,��ž�������:(��Щ�����ǰٶ��ϵ�,�����ϰٶ�һ�¾�����)
jstat -gccapacity PID:���ڴ����
jstat -gcnewcapacity PID:������ڴ����
jstat -gcold PID:�����GC����
jstat -gcoldcapacity PID:������ڴ����
jstat -gcmetacapacity PID:Ԫ�������ڴ����
jstat -gcnew PID:�����GC����,�����TT��MTT,���Կ����������������������ʹ����������
3��ǰ�������������,��Ȼ֮ǰ���������������бȽ����ֵ�һЩ�������˽������������,���������Ƿ�ʹ��,Ҳ�Ǹ������ϻ�������,������Ҳ��ǰ�˽����,���뵽���Լ��ı����ı��ĵ�����,������Ե�ʱ��,����ѡ���ʱ����ӵ��������,�������Լ��ۿ�,������һ�ָ���ϰ��,���������λ����������:
Serial:��ʮ��
PS:�ϰ��� ~ 4G
CMS:4G ~ 10G
G1:10G~�ϰ�G (G1)
ZGC: 4T - 16T(JDK13)
4���������ϻ����������������:
1��ɳ�价���ķ�����:4�� * 16G;
2����ʽ�����ķ�����:��̨,�ֱ�Ϊ:4�� * 16G ��̨,8 * 32G һ̨��
������ܴ�ԼҲ���������,��������Ȼ��������,����Ҳ���������ǽ������Թ����ˡ�
4. ��Ҳװ����,���͵������ˡ������顿
1��java -XX:+PrintCommandLineFlags-version �������ҾͿ�������Ĭ�ϵ�����������ʹ�õ����Ǹ�����������,��������������,��ʱ���п�ר������һ��,һֱû����������ʱ��ȥ����,ʵ���Ϻ���֮ǰ���Ѿ�������˽����һЩ,���ǿ���û����ô����,���Խ��,��д�������˴���
������־����:�����¾��ܿ���ʹ�õ������ִ�ʱ���õ�������������������
-XX:InitialHeapSize=515083264 -XX:MaxHeapSize=8241332224 -XX:+PrintCommandLineFlags -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseParallelGC java version ��1.8.0_261�� Java? SE Runtime Environment (build 1.8.0_261-b12) Java HotSpot?
64-Bit Server VM (build 25.261-b12, mixed mode)
2��jstat -gc PID �������������,���ֵľ���һ�����������һЩ�����ˡ�
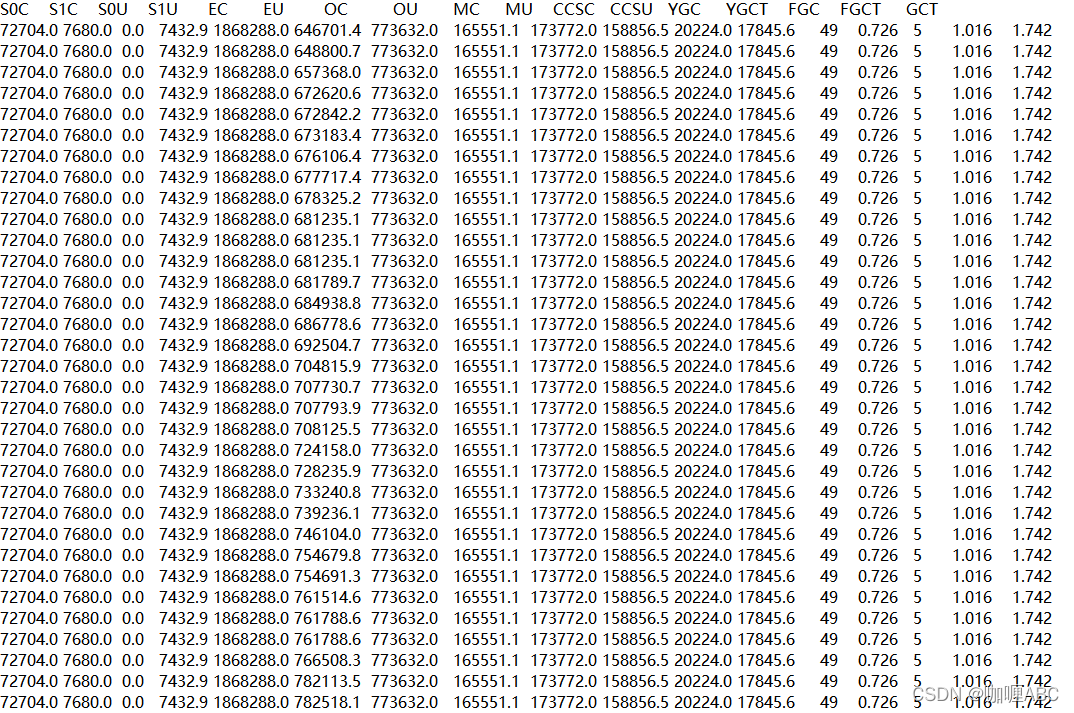
ǰ��:��Ҫ��jvm�и�����˽��,���ܿ���ƪ����û����˵ķѾ�,��ô���ٴνظ�ͼ,��Ǽ�����Ҫ�Ķ������ص�۲��λ�á�

������Ȧ����,��ע��һ����,���Ǽķ���һ��,���ȼ���һ����Щ����ŵ���ֵ,���Ǿ���MBΪ��λ��
1.72704KB �� 71 MB S-From��
2.7680KB �� 7MB S-To ��
�Բ�,�ⲻһ�¾Ϳ�����������,��ֱ����һ����ϲѽ,��һ�δ���־�ͳ���������,Ѹ�ٷ�תһ��,Ϊʲôһ�¾Ϳ���������,��������gc�й������˽��,��֪��,���ڴ�������������Լ��������,�Ҽ�̻���ͼ,������ô�ݽ���,��ҿ���ȥ�ҵ�JVMר��ȥ��һ�ۡ�
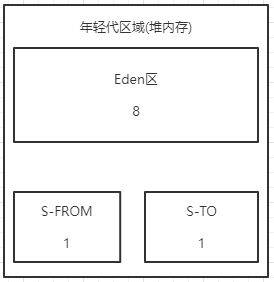
Ҳ���������,�Ľ���һ��,��Ŀǰ�������õĻ����㷨���Ǹ����㷨,������������㷨���Ϊ����,�������ݽ����,Ҳ���DZ���8:1:1,�ݽ�֮ǰ����5:5��,Ϊʲô����,����Ҳֻ�Ǽ���һ��,��Ϊֻ��ʵս����,�����Ǽ�������,���Բ��������,Ϊ�˾�����������ռ����ı���������,��ôΪʲô˵��һ�۾Ϳ���������,��Ϊһ���������մ�Լ�������ġ�
��ʱ����һ��gc,�Ӵ�ӡ��־��gc�������,Eden����Ϊ:1868288KB �� 1868MB Ҳ���ǵ�����ռ��һ�����ڴ�,�ͻᷢ��һ���������GC,Ҳ����YOUNG GC������˵��MINOR GC,������˵���������GC,��ô��ʱ�ᷢ�����������,s0���Ὣ�Լ�����������ŵĶ���ȫ�����뵽s1��,��������gc���Ķ���ȫ������s1��,��ô�ͻ����s0��,�������ƺ���յĺô����Ƿ�ֹ�ڴ���Ƭ����������������,��ʱs1���Ŀռ�ֻ��7MB,����S0���Ŀռ���71MB,����ƶ�,�Ʋ�,s1������װ����,90%���ϵļ��ʻ�ֱ�ӽ��뵽���������,��ô����˳������,ֱ�ӽ�������Ŀռ������� 773632 KB �� 773MB ����һ�������������װһЩ�����,��ô����˳��˼·������
��,�����е�����,�Ƽ�һ����,�Ͼ����� ��������ҹ��ÿ��5��,�Ӱ�����,��ҹ��˯���õ�
���Ϸ���,�������773MB,��������ͣ�Ų�,����һ��Eden����һ�������ٶ�,Ҳ����new XXX()����������¶�����ٶ�,����ע����:���и߷��ں͵���,����ȡ��������Ҳ���Ǹ߷���ȥ����,Ȼ�����ռ��gcƵ�ʵ��� ����ǰ:708125.5KB��708MB ������:724158.0 KB �� 724MB,������������(724MB - 708MB)= 16MB,��ô�����ټ���һ��Eden������ܴ�СΪ:1868288.0 KB �� 1868MB,����һ������1868MB / 16MB ��
116.75��,Ȼ���ٳ��� 60 ,��ô��ԼҲ����2�������Ҿ���һ���������gc���������Ǿ���������������gc��һ��Ƶ�ʺ�ʱ�䡣
������,д�˺ܾ���,ҲҪ�°���·��,ף����ʥ���ڿ���,��Ҫȥ��ʥ������,�ȸ��µ����