目录
整合jdbc
项目创建时,要添加JDBC API、MySQL Driver、spring web这三个依赖
在application.yml中,配置数据源的信息
spring:
datasource:
username: ***
password: ***
url: jdbc:mysql://localhost:3306/db_7?useUnicode=true&characterEncoding=UTF-8&serverTimezone=UTC
driver-class-name: com.mysql.cj.jdbc.Driver
注意:
- SpringBoot 使用的是MySQL8.x.x版本,所以url、driver的书写方式与之前不一样
- 我们配置好这四个基本信息后,SpringBoot 自动帮我们配置了数据源(DataSource),它还将其封装进一款jdbc轻量级框架(JdbcTemplate)
- SpringBoot 底层默认调用的数据库连接池是HikariDataSource,特点就是速度快
控制层代码
原理:从ioc中获取JdbcTemplate,对数据库进行增删改查,将结果回显至页面
@RestController
//@RestController=@Controller + @ResponseBody
public class jdbcTemConteoller {
@Autowired
private JdbcTemplate jdbcTemplate;
// 增加
@GetMapping("/user_add")
public String insert(){
String sql="insert into user (username,password,tel,email,balance) values ('tom','123','12345678998','123@qq.cn','34') ";
int update = jdbcTemplate.update(sql);
return "ok";
}
// 删除
@GetMapping("/user_del/{id}")
public String delete(@PathVariable int id){
// sql:字符串拼接的方式
String sql="delete from user where id="+id;
int update = jdbcTemplate.update(sql);
return "ok";
}
// 修改
@GetMapping("/user_upate/{id}")
public String update(@PathVariable int id){
// sql:预编译的方式
String sql="update user set username='ttt',password='123',tel='123',email='423@q.cm',balance=12 where id=?";
jdbcTemplate.update(sql,id);
return "ok";
}
// 查询
@GetMapping("/user_findall")
public List<Map<String, Object>> findAll(){
String sql="select * from user";
List<Map<String, Object>> maps = jdbcTemplate.queryForList(sql);
return maps;
}
}访问页面(查询所有的路径)

?整合Druid
Druid 是阿里巴巴开源平台上一个数据库连接池实现,结合了 C3P0、DBCP 等 DB 池的优点,同时加入了日志监控。
添加依赖
<!-- druid-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.0.9</version>
</dependency>
<!-- log4j-->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>在application.yml中,配置Druid的信息
spring:
datasource:
username: ***
password: ***
url: jdbc:mysql://localhost:3306/db_7?useUnicode=true&characterEncoding=UTF-8&serverTimezone=UTC
driver-class-name: com.mysql.cj.jdbc.Driver
type: com.alibaba.druid.pool.DruidDataSource
#Spring Boot 默认是不注入这些属性值的,需要自己绑定
#druid 数据源专有配置
initialSize: 5
minIdle: 5
maxActive: 20
maxWait: 60000
timeBetweenEvictionRunsMillis: 60000
minEvictableIdleTimeMillis: 300000
validationQuery: SELECT 1 FROM DUAL
testWhileIdle: true
testOnBorrow: false
testOnReturn: false
poolPreparedStatements: true
#配置监控统计拦截的filters,stat:监控统计、log4j:日志记录、wall:防御sql注入
#如果允许时报错 java.lang.ClassNotFoundException: org.apache.log4j.Priority
#则导入 log4j 依赖即可,Maven 地址:https://mvnrepository.com/artifact/log4j/log4j
filters: stat,wall,log4j
maxPoolPreparedStatementPerConnectionSize: 20
useGlobalDataSourceStat: true
connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=500
编写配置类DruidConfig:SpringBoot的扩展配置 全部使用配置类来实现
@Configuration
public class DruidConfig {
/**
* 通过ConfigurationProperties注解 获取到yml中的数据
* 在将数据源的数据注入dataSource()中
* 并且将返回值放入ioc容器中
*
*/
@ConfigurationProperties(prefix = "spring.datasource")
@Bean
public DataSource dataSource(){
return new DruidDataSource();
}
// 配置后台监控
@Bean
public ServletRegistrationBean<StatViewServlet> servletRegistrationBean(){
//配置的访问路径是/druid/*
ServletRegistrationBean<StatViewServlet> bean = new ServletRegistrationBean<>(new StatViewServlet(), "/druid/*");
HashMap<String, String> hashMap = new HashMap<>();
hashMap.put("loginUsername","user");
hashMap.put("loginPassword","123");
hashMap.put("allow","");//允许所有访问
bean.setInitParameters(hashMap);
return bean;
}
// 过滤器
@Bean
public FilterRegistrationBean webStatFilter(){
FilterRegistrationBean bean = new FilterRegistrationBean();
bean.setFilter(new WebStatFilter());//添加过滤器 :springweb自带的过滤器
HashMap<String, String> hashMap = new HashMap<>();
//这些路径不进行统计
hashMap.put("exclusions","*.js,*.css,/druid/*");
bean.setInitParameters(hashMap);
return bean;
}
}
注意:
- hashMap中的key值均是不能变化的!
- 不编写过滤器,不影响后台监控
进行访问
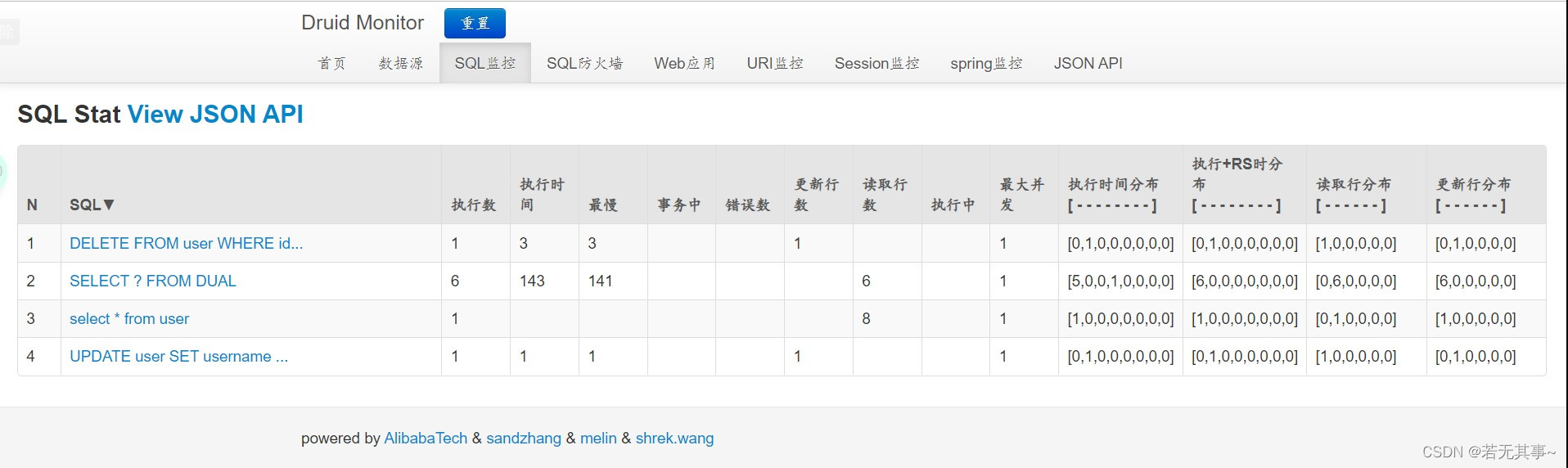
?登录成功后,进入sql监控页面,再运行几次之前增删改查的路径,就会有如下效果