1、LongAdder 由来
LongAdder 类是JDK 1.8新增的一个原子性操作类。AtomicLong 通过 CAS 算法提供了非阻塞的原子性操作,相比使用阻塞算法的同步器来说性能已经是很好了,但是 JDK 开发者并不满足于此,因为经常搞并发的请求下 AtomicLong 的性能是不能让人接受的。
如下 AtomicLong 的 getAndIncrement 的代码,虽然 AtomicLong 使用 CAS 算法,但是在高并发的情况下, CAS 只能有一个线程操作成功,其他线程失败后还是通过无限循环的自旋锁不断地尝试,这就是高并发下 CAS 性能低下地原因所在。源码如下:
public final long incrementAndGet() {
return unsafe.getAndAddLong(this, valueOffset, 1L) + 1L;
}
// 位于 Unsafe 类下
public final long getAndAddLong(Object var1, long var2, long var4) {
long var6;
do {
// 获取当前对象地值作为期望值
var6 = this.getLongVolatile(var1, var2);
} while(!this.compareAndSwapLong(var1, var2, var6, var6 + var4));
return var6;
}
高并发下 N 多线程同时去操作一个变量会造成大量线程地 CAS 失败,然后处于自旋状态,导致严重浪费 CPU 资源,降低了并发性。
2、LongAdder 与 AtomicLong 的简单介绍
- 我们知道,
volatile关键字是轻量级锁,可以解决多线程内存不可见问题。对于一写多读的情况(CopyOnWriteArrayList),可以解决变量同步问题,但是如果是多写的话,volatile无法解决线程安全问题。 - 例如:
count ++操作,就应该使用如下方式:AtomicInteger count = new AtomicInteger();、count.addAndGet(1);- 而如果是 JDK 1.8 以上,推荐使用
LongAdder对象替代,因为它的性能比AtomicLong更好(减少乐观锁的重试次数)。
LongAdder 其他应用场景:
对于 JAVA 项目中 计数统计得一些需求,如果是 JDK1.8,推荐使用 LongAdder 对象,比AtomicLong 新跟那个更好(减少乐观锁的重试次数)
在大多数项目以及开源组件中,计数统计使用最多的仍然还是 AtomicLong,虽然是阿里巴巴这样说,但是我们仍然要根据使用场景来决定是否使用 LongAdder。
今天主要是来讲讲 LongAdder 的实现原理,还是老方式,通过图文一步步揭开 LongAdder 神秘的面纱,通过此篇文章你会了解到:
- 为什么 AtomicLong 在高并发的场景下性能急剧下降?
- LongAdder 为什么在高并发场景下快?
- LongAdder 的实现原理(图文分析)
- AtomicLong 是否可以被遗弃或者替换?
3、AtomicLong
当我们进行计数统计的时候,通常会使用 AtomicLOng 来实现,AtomicLong 能后保证并发情况下计数的准确性,其内部通过 CAS 来解决并发安全性的问题。
3.1、AtomicLong 实现原理
说到线程安全的计数统计工具类,肯定少不了 Atomic 下的几个原子类。AtomicLong 就是 juc 包 下重要的 原子类,在并发情况下可以对长整型类型的数据进行原子操作,保证并发情况下数据的安全性。
public class AtomicLong extends Number implements java.io.Serializable {
public final long getAndIncrement() {
return unsafe.getAndAddLong(this, valueOffset, 1L);
}
public final long getAndDecrement() {
return unsafe.getAndAddLong(this, valueOffset, -1L);
}
}
我们在计数的过程中,一般使用 getAndIncrement() 和 getAndDecrement() 进行加 1 和 减 1 操作,这里调用了 Unsafe 类中的 getAndAddLong() 方法进行操作。
接着看看 getAndAddLong() 方法:
public final long getAndAddLong(Object var1, long var2, long var4) {
long var6;
do {
var6 = this.getLongVolatile(var1, var2);
} while(!this.compareAndSwapLong(var1, var2, var6, var6 + var4));
return var6;
}
这里直接进行 CAS + 自旋 操作更新的 AtomicLong 中的 value 值,进而保证 value 值的原子性更新。
3.2、AtomicLong 的瓶颈分析
如上代码所示,我们在使用 CAS + 自旋 的过程中,在高并发的环境下,N 个线程同时进行自旋操作,会出现大量失败并不断自旋的情况,此时 AtomicLong 的自旋会成为瓶颈。
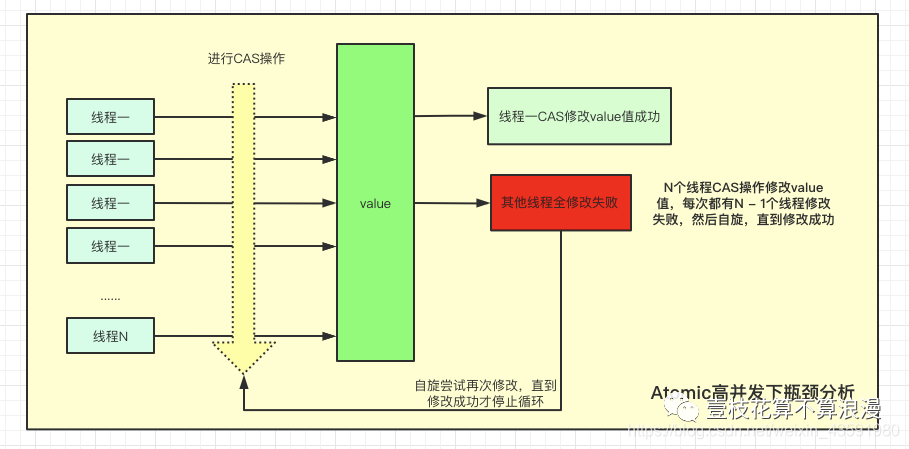
如上图所示,高并发场景下 AtomicLong 性能会急剧下降,我们后面也会举例说明。
那么高并发下计数的需求有没有更好的替代方案呢?在 JDK8 中 Doug Lea 大神新写了一个 LongAdder 来解决此问题,我们后面来看看 LongAdder 是如何优化的?
4、LongAdder
4.1、LongAdder 和 AtomicLong 性能测试
我们说了很多 LongAdder 在高并发情况下性能优于 AtomicLong ,到底是不是呢?
/**
* @author wcc
* @date 2022/1/6 19:56
* LongAdder 和 AtomicLong 在高并发情况下的计数性能测试
*/
public class AtomicLongAdderTest {
public static void main(String[] args) throws Exception{
testAtomicLongAdder(1, 10000000);
testAtomicLongAdder(10, 10000000);
testAtomicLongAdder(100, 10000000);
}
public static void testAtomicLongAdder(int threadCount, int times) throws Exception {
System.out.println("threadCount: " + threadCount + ", times: " + times);
long start = System.currentTimeMillis();
testLongAdder(threadCount, times);
System.out.println("LongAdder 耗时:" + (System.currentTimeMillis() - start) + "ms");
System.out.println("threadCount: " + threadCount + ", times: " + times);
long atomicStart = System.currentTimeMillis();
testAtomicLong(threadCount, times);
System.out.println("AtomicLong 耗时:" + (System.currentTimeMillis() - atomicStart) + "ms");
System.out.println("----------------------------------------");
}
public static void testAtomicLong(int threadCount, int times) throws InterruptedException {
AtomicLong atomicLong = new AtomicLong();
List<Thread> list = new ArrayList<>();
for (int i = 0; i < threadCount; i++) {
list.add(new Thread(()->{
for (int j = 0; j < times; j++) {
atomicLong.getAndIncrement();
}
}));
}
for (Thread thread : list){
thread.start();
}
for (Thread thread : list){
thread.join(); // 挂起main线程的执行
}
}
public static void testLongAdder(int threadCount, int times) throws InterruptedException {
LongAdder longAdder = new LongAdder();
List<Thread> list = new ArrayList<>();
for (int i = 0; i < threadCount; i++) {
list.add(new Thread(()->{
for (int j = 0; j < times; j++) {
longAdder.increment();
}
}));
}
for (Thread thread : list){
thread.start();
}
for (Thread thread : list){
thread.join(); // 挂起main线程的执行
}
}
}
执行结果如下:
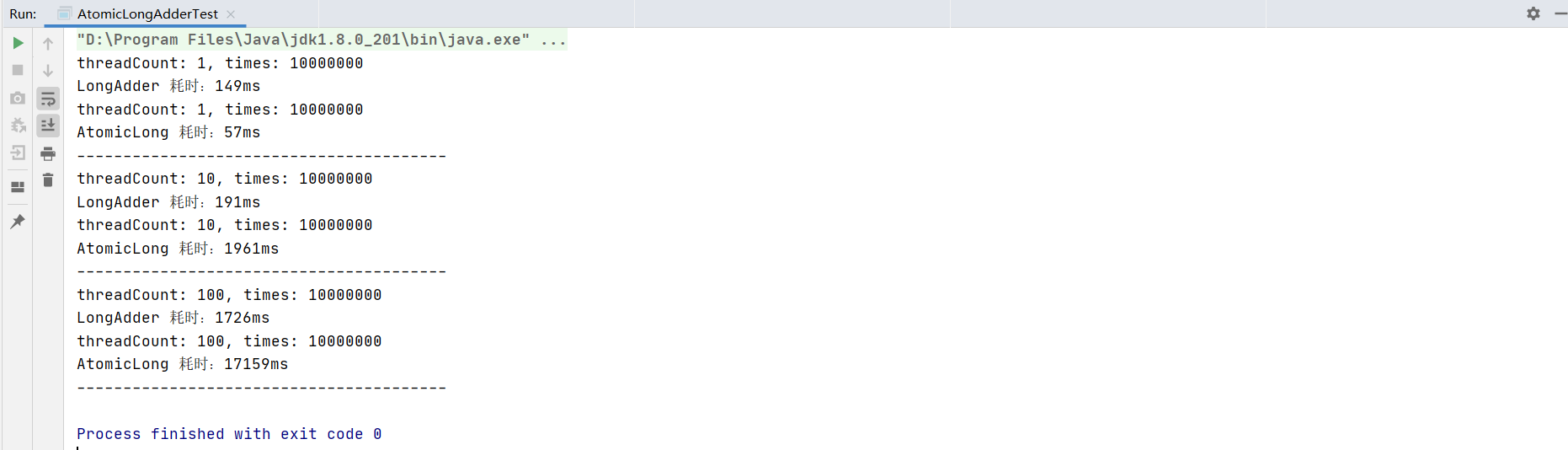
这里可以看到随着并发的增加,Atomiclong 性能是急剧下降的,耗时是 LongAdder 的数倍。至于原因我们还是接着往后看。
4.2、LongAdder 为什么这么快?
先看下 LongAdder 的操作原理图:
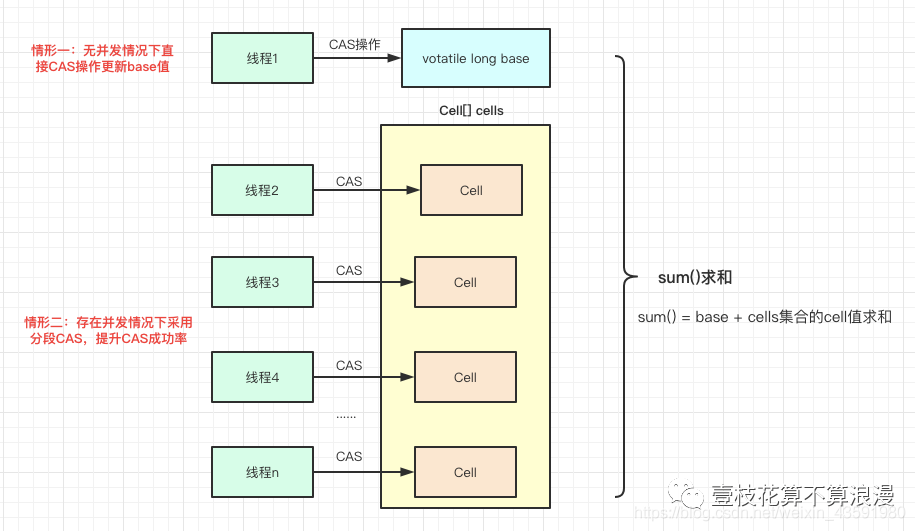
既然说到 LongAdder 可以显著提升高并发环境下的性能,那么它是如何做到的呢?
1、设计思想上,LongAdder 采用 “分段” 的方式降低 CAS 失败的频次
这里先简单的说下 LongAdder 的思路,后面还会讲述 LongAdder 的原理。
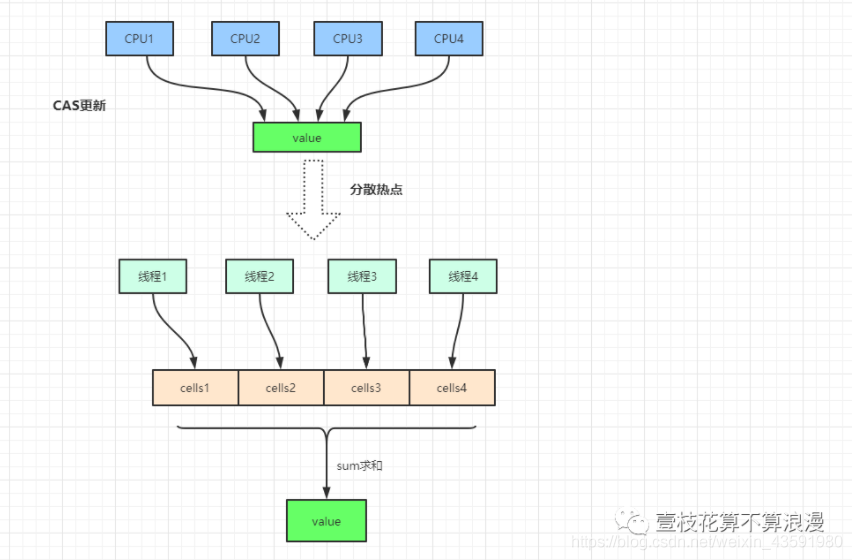
我们知道,AtomicLong 中有个内部变量 value 保存着实际的 long 值,所有的操作都是针对该变量进行的。也就是说,高斌发噶环境下,value 其实是一个 热点数据,也就是N 个线程竞争一个热点。
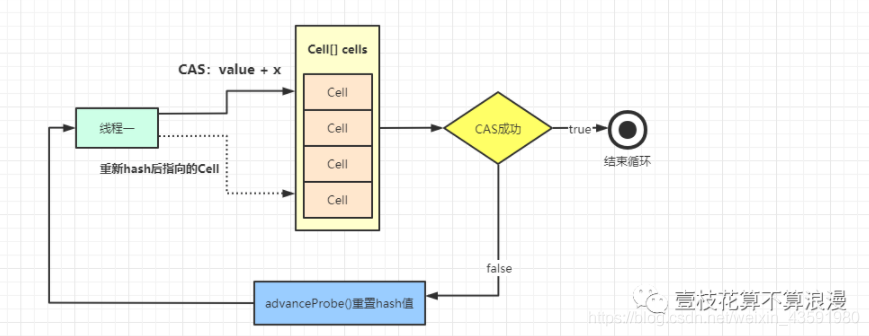
LongAdder 的基本思路就是分散热点,将 value 值的新增操作分散到一个数组中,不同的线程会命中到数组的不同槽位中,各个线程只对自己槽位中的那个 value 值进行 CAS 操作,这样热点就被分散了,冲突的概率就小很多。
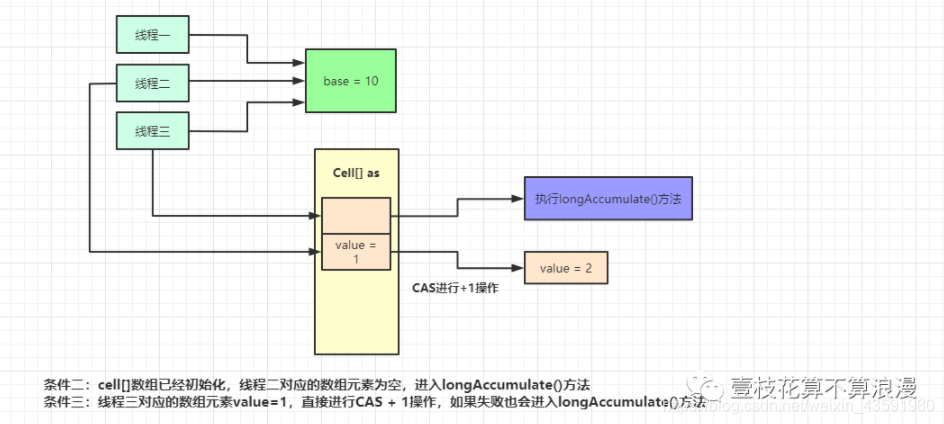
LongAdder 有一个全局变量 volatile long base 值,当并发不高的情况下都是通过 CAS 操作来直接操作 base 值,如果 CAS 失败,则针对 LongAdder 中的 Cell[] 数组中的 Cell 进行 CAS 操作,减少失败的概率。
例如当前类中 base = 10,有三个线程进行 CAS 原子性的**+1 操作**,线程一执行成功,此时 base = 11,线程 二、线程三执行失败后 开始针对于 CELL[] 数组中的 Cell 元素进行 +1操作,同样也是 CAS 操作,此时数组 index = 1 和 index = 2 中的 CELL 的 value 都被设置为了1
执行完成后,统计累加数据:sum = 11 + 1 + 1 = 13,利用 LongAdder 进行累加的操作就执行完了,流程图如下:
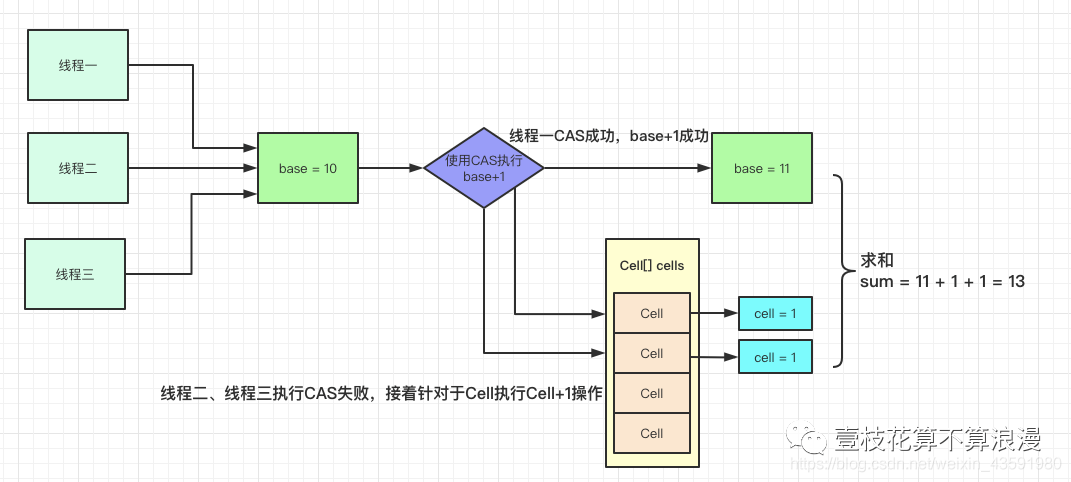
如果要获取真正的 long 值,只要将各个槽中的变量值累加返回。这种分段的做法类似于 JDK7 中 ConcurrentHashMap 的分段锁。
2、使用 Contended 注解来消除伪共享
在 LongAdder 的父类 Strip64 中存在一个 volatile Cell[] cells 数组,其长度是 2 的幂次方,每个 cell 都使用 @Contended 注解进行修饰,而 @Contended 注解可以进行 缓存填充,从而解决伪共享问题。伪共享会导致缓存失效,缓存一致性开销增大。
@sun.misc.Contended static final class Cell {
}
伪共享指的是多个线程同时读写同一个缓存行下不同变量导致的 CPU 缓存失效。尽管这些变量之间没有任何关系,但是由于在主内存中邻近,存在于同一个缓存行之中,它们的相互覆盖会导致频繁的缓存未命中,引发性能下降。这里对于伪共享只是提一下概念,并不会深入去讲解,大家可以自行去查阅一些资料。
解决伪共享的方法一般都是使用 直接填充,我们只需要保证不同线程的变量存在于不同的 CacheLine 即可,使用多余的字节来填充可以做到这一点,这样就不会出现伪共享问题。例如在 Disruptor 队列的设计中就有类似的设计。
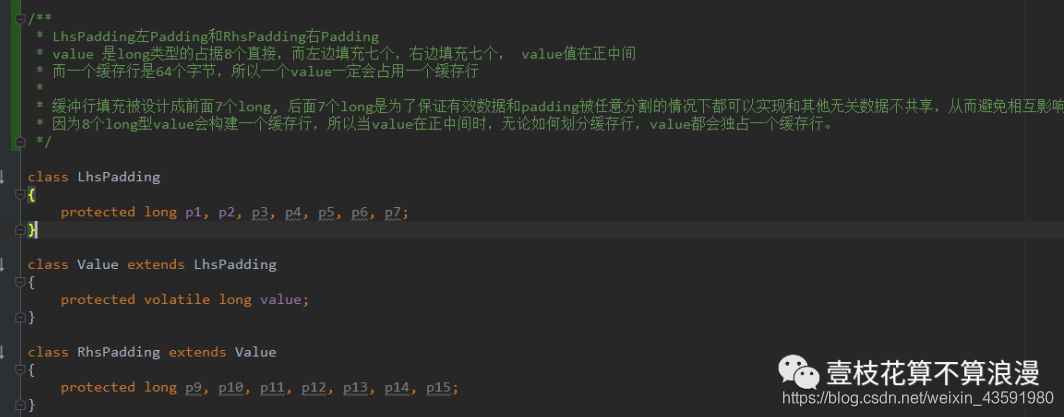

在 Triped64 类中我们可以看到 Doug Lea 在 Cell 上加的注释也有说明这一点:
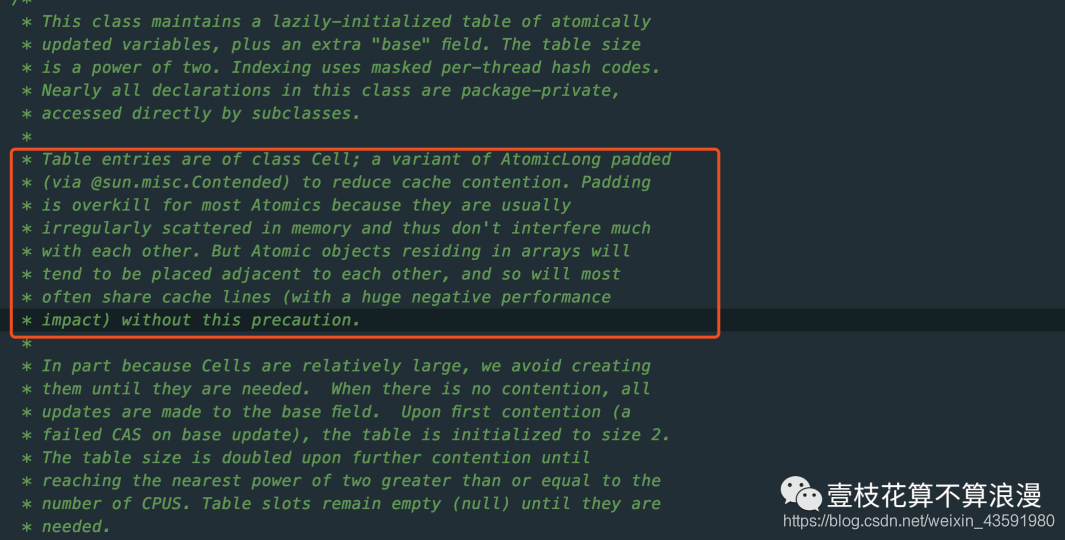
框中的翻译如下:
Cell 类 是AtomicLong 添加了 padded(via@sun.misc.compended) 来消除伪共享的变种版本。缓存行填充对于大多数原子来说是繁琐的,因为它们通常是不规则的分散在内存中,因此彼此之间不会有太大的干扰。但是,驻留在数组中的原子对象往往彼此相邻,因此在没有这种预防措施的情况下,通常会共享缓存行数据(对性能有巨大的负面影响)。
3、惰性求值
LongAdder 只有在使用 longValue() 获取当前累加值的时候才会去真正的去结算计数的数据,longValue() 方法底层就是调用 sum() 方法,对 base 和 Cell数组 的数据累加然后返回,做到数据写入和读取分离。
而AtomicLong 使用 incrementAndGet() 每次都会返回 long 类型的计数值,每次递增后还会伴随着数据返回,增加了额外的开销。
4.3、LongAdder 实现原理
之前说了,AdderLong 是多个线程针对单个热点值 value 进行原子操作。而LongAdder 是每个线程拥有自己的槽位,各个线程一般只对自己槽位中的那个值进行 CAS 操作。
比如有三个线程同时对 value 增加1,那么 value = 1+1+1=3。
但是对于 LongAdder 来说,内部有一个base 变量,一个 Cell 数组
base 变量:非竞争条件下,直接累加到该变量上
cell 数组:竞争条件下,累加到各个线程自己的槽位cell[i] 中
最终计算结果是下面这个形式:
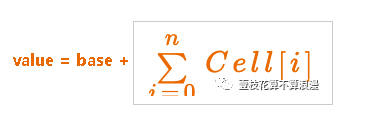
4.4、LongAdder 源码剖析
成员变量
// 表示当前计算机CPU数量,什么用?控制cells数组长度的一个关键条件
static final int NCPU = Runtime.getRuntime().availableProcessors();
/**
* Table of cells. When non-null, size is a power of 2.
*/
transient volatile Cell[] cells;
// 没有发生过竞争的时候数据会累加到base上,或者当cells扩容的时候,需要将数据写入到base中
transient volatile long base;
// 初始化cells或者扩容cells都需要获取锁,0表示无锁状态 1表示其他线程已经持有该锁了
transient volatile int cellsBusy;
前面已经用图分析了 LongAdder 高性能的原理,我们继续看下 LongAdder 实现的源码:
public void add(long x) {
// as:表示 cells的引用
// b:表示获取的base值
// v:表示期望值
// m:表示cells 数组的长度
// a:表示当前线程命中的cell单元格
Cell[] as; long b, v; int m; Cell a;
// 条件一:true -> 表示cells已经初始化过了,当前线程应该将数据写入到对应的cell中
// false -> 表示cells未初始化,当前线程应该将数据写入到base变量中
// 条件二:因为是|| 的关系,所以一定是条件一为false的时候才会执行条件二,也就是将数据写入到base中
// 条件二:true -> 当前线程cas 替换数据成功 false -> 表示替换失败,表示发生竞争了,可能需要重试或者扩容
if ((as = cells) != null || !casBase(b = base, b + x)) {
// 什么时候会进来?
// 条件一:true -> 表示cells已经初始化过了,当前线程应该将数据写入到对应的cell中
// 条件二:false -> 表示替换失败,表示发生竞争了,可能需要重试或者扩容
// uncontended:true,表示未发生竞争,false表示发生竞争,默认为true
boolean uncontended = true;
// 条件一:true -> 说明cells未初始化,也就是多线程写base发生竞争了
// false -> 说明cells已经初始化了,说明当前线程应该是找自己的cell写值
// 条件二:getProbe() 获取当前线程的hash值,m表示cells长度-1 cells数组的长度一定为2的次方数
// true -> 说明当前线程hash值对应下标的cell为空,需要创建
// false -> 说明当前线程hash值对应下标的cell不为空,说明下一步想要将x值添加到对应的cell中
// 条件三:true -> 表示cas失败,意味着当前线程对应的cell有竞争
// false -> 表示cas成功,则方法结束
if (as == null || (m = as.length - 1) < 0 ||
(a = as[getProbe() & m]) == null ||
!(uncontended = a.cas(v = a.value, v + x)))
// 都有哪些情况会调用该方法:
// true -> 说明cells未初始化,也就是多线程写base发生竞争了[重试或者初始化celles数组]
// true -> 说明当前线程hash值对应下标的cell为空,需要创建
// true -> 表示cas失败,意味着当前线程对应的cell有竞争[重试或者扩容]
longAccumulate(x, null, uncontended);
}
}
一般我们进行计数的时候都会使用 increment() 方法,每次进行 +1 操作,increment() 会直接调用 add(1.0F) 方法。
条件一:as == null || (m = as.length - 1) < 0
此条件成立说明 cells 数组未初始化。如果不成立则说明 cells 数组已经初始化完成,对应的线程需要找到cell 数组中的元素去写值。
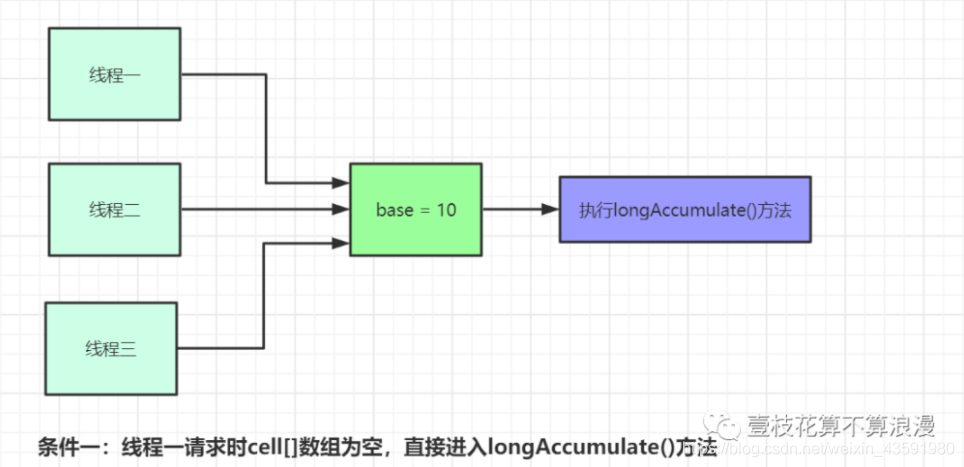
条件二:a = as[getProbe() & m]) == null
getProbe() 获取当前线程的 hash 值,m 表示 cells长度 -1 ,cells 长度是 2 的幂次方数,原因之前也讲到过,与数组产嘀咕取模可以转化为按位与运算,提升计算性能。
当条件成立的时候说明当前线程通过 hash 计算出来数组位置处的 cell为空,进一步去执行 longAccumulate() 方法。如果不成立则说明对应的 cell 不为空,下一步要将 x 值通过 CAS 操作添加到 cell中。
条件三:!(uncontended = a.cas(v = a.value, v + x)
主要看 a.cas(v = a.value, v + x),接着条件二,说明当前线程 hash 与数组长度取模计算出的位置的cell有值,此时直接尝试一次CAS 操作,如果成功则退出 if 条件,失败则继续往下执行 longAccumulate()方法。
接着往下看核心的 longAccumulate() 方法,代码很长,后面回一步步分析,先上代码:
``java.util.concurrent.atomic.Striped64.:
// 都有哪些情况会调用该方法:
// true -> 说明cells未初始化,也就是多线程写base发生竞争了[初始化celles数组]
// true -> 说明当前线程hash值对应下标的cell为空,需要创建
// true -> 表示cas失败,意味着当前线程对应的cell有竞争[重试或者扩容]
/**
*
* @param x add方法的增量
* @param fn 操作算法的接口,可以操作它来扩展自己的算法,这里传null,不做实现
* @param wasUncontended 表示是否发生了竞争 false表示发生了竞争,true表示未发生竞争
* 只有当cells初始化之后,并且当前线程发生了竞争的情况下且竞争修改失败的时候才会为false
*/
final void longAccumulate(long x, LongBinaryOperator fn,
boolean wasUncontended) {
// h:表示线程的hash值
int h;
//条件成立:说明当前线程还未分配hash值
if ((h = getProbe()) == 0) {
// 给当前线程分配hash值
ThreadLocalRandom.current(); // force initialization
// 取出当前线程的hash值赋值给h
h = getProbe();
// 为什么强制设置为true?
// 因为默认情况下当前线程肯定是写入到了cells[0]位置,不把它当作一次真正的竞争
wasUncontended = true;
}
// 表示扩容意向 false 一定不会扩容 true 可能会扩容
boolean collide = false; // True if last slot nonempty
// 自旋操作
for (;;) {
// as:表示cells引用
// a:表示当前线程命中的cell
// n:表示cells数组长度
// v:表示期望值
Cell[] as; Cell a; int n; long v;
// true -> 说明当前线程hash值对应下标的cell为空,需要创建
// true -> 表示cas失败,意味着当前线程对应的cell有竞争[重试或者扩容]
// CASE1:表示cells已经初始化了,当前线程应该将数据写入到对应的cell中
if ((as = cells) != null && (n = as.length) > 0) {
// CASE1.1:条件true:表示当前线程对应下标位置的cell为null,需要创建cell对象
if ((a = as[(n - 1) & h]) == null) {
// true -> 表示当前是无锁状态,锁未被占用 fasle -> 表示锁被占用
if (cellsBusy == 0) { // Try to attach new Cell
// 拿当前的x创建cell
Cell r = new Cell(x); // Optimistically create
// 条件一:true -> 表示当前是无锁状态,锁未被占用 fasle -> 表示锁被占用
// 条件二:true -> 表示当前线程获取锁成功 false -> 表示当前线程获取锁失败
if (cellsBusy == 0 && casCellsBusy()) {
// 是否创建成功的标记
boolean created = false;
try { // Recheck under lock
// rs:表示当前cells引用
// m:表示cells数组的长度
// j:表示当前线程命中的cells中的下标
Cell[] rs; int m, j;
// 条件一和条件二恒成立
// 条件三:rs[j = (m - 1) & h] == null
// 为了防止其他线程初始化过该位置然后当前线程再次初始化该位置,导致丢失数据
if ((rs = cells) != null &&
(m = rs.length) > 0 &&
rs[j = (m - 1) & h] == null) {
rs[j] = r;
created = true;
}
} finally {
cellsBusy = 0;
}
if (created)
break;
continue; // Slot is now non-empty
}
}
// 扩容意向强制改为了false,因为当前命中的cell为空,可以添加,所以不需要扩容
collide = false;
}
// CASE1.2:只有一种情况,只有当cells初始化之后,并且当前线程发生了竞争的情况下且竞争修改失败的时候才会为false
else if (!wasUncontended) // CAS already known to fail
// 重置当前线程hash值并继续自旋操作
wasUncontended = true; // Continue after rehash
// CASE1.3:当前线程rehash过,并且新命中的cell不为空
// true -> 写成功,退出自旋操作
// false -> 表示rehash之后命中的新的cell也有竞争并且竞争失败,重试一次
else if (a.cas(v = a.value, ((fn == null) ? v + x :
fn.applyAsLong(v, x))))
break;
// CASE1.4:
// 条件一:如果cells的数组长度n大于等于NCPU true -> 扩容意向改为false,不再进行扩容
// false:说明数组cells还可以进行扩容
// 条件二:true -> 其他线程已经扩容过了,当前线程rehash之后重试即可 扩容意向改为false,不再进行扩容
else if (n >= NCPU || cells != as)
// 扩容意向改为false,不再进行扩容
collide = false; // At max size or stale
// CASE1.5:
// 条件成立:表示需要扩容,设置扩容意向为true,但是不一定真的发生扩容
else if (!collide)
collide = true;
// CASE1.6:真正扩容代码
// 条件一:cellsBusy == 0 表示当前无锁状态,可以获取锁进行扩容
// casCellsBusy() 并且当前线程获取锁成功 false:表示有其它线程正在进行扩容操作
else if (cellsBusy == 0 && casCellsBusy()) {
try {
// 同上 CASE1.1,防止CPU时间片轮转导致重复扩容
if (cells == as) { // Expand table unless stale
// 扩容为原来的二倍
Cell[] rs = new Cell[n << 1];
for (int i = 0; i < n; ++i)
rs[i] = as[i];
cells = rs;
}
} finally {
cellsBusy = 0;
}
collide = false;
continue; // Retry with expanded table
}
// 重置当前线程的hash值
h = advanceProbe(h);
}
// CASE2:前置条件 -> cells还未初始化,as为null
// 条件一:cellbusy == 0 -> 表示当前未加锁
// 条件二:cells == as 防止当前线程走到这个else-if的时候,有其他的线程已经将cells初始化过了
// 条件三:true 表示获取锁成功 把cellsBusy改为1 失败表示其他线程正在持有这把锁
// 只有持有锁才可以对cells进行初始化或者扩容
else if (cellsBusy == 0 && cells == as && casCellsBusy()) {
boolean init = false;
try { // Initialize table
// cells == as:为什么还要进行一次判断?
// 因为当两个线程同时来到这个else-if的时候,当一个线程刚刚执行完外层的cells==as的时候让出了CPU执行权
// 这时另一个线程就会拿到锁来初始化cells,当初始化完成以后又让出CPU执行权,该线程抢占到了执行权继续执行casCellsBusy()
// 然后获取锁进入方法中,但是此时的cells已经被初始化过了,如果不加这个cells==as判断的时候,就会导致丢失数据
// 加了判断以后才会发现已经初始化过了,保证了数据的不丢失
if (cells == as) {
Cell[] rs = new Cell[2];
rs[h & 1] = new Cell(x);
cells = rs;
init = true;
}
} finally {
cellsBusy = 0;
}
if (init)
break;
}
// CASE3:
// 1.当前cellsbusy加锁状态,表示其他线程正在初始化cells,所以当前线程将值累加到base
// 2.cells被其他线程初始化后,当前线程需要将数据累加到base
else if (casBase(v = base, ((fn == null) ? v + x :
fn.applyAsLong(v, x))))
break; // Fall back on using base
}
}
我们首先要看执行这个方法的前置条件,它们的条件已经在代码中声明了。
然后再看一下 Striped64 中一些变量或者方法的定义:
- base:类似于 AtomicLong 中全局的 value 值。在没有竞争情况下数据直接累加到 base 上,或者 cells 扩容的时候,也需要将数据写入到 base 上
- collide:表示扩容意向,false 一定不会扩容,true 可能会扩容
- cellsBusy:初始化 cells 或者扩容 cells 需要获取锁,0:表示无锁状态,1:表示其他线程已经持有了锁
- caseCellsBusy():通过 CAS 操作修改 cellsBusy 的值,CAS 成功表示获取锁,返回true
- NCPU:当前计算机的CPU数量,CELL 数组扩容的时候会使用到
- getProbe():获取当前线程的 hash 值。
- advanceProbe():重置当前线程的 hash 值
接着开始正式解析 longAccumulate() 源码:
private static final long PROBE;
if ((h = getProbe()) == 0) {
ThreadLocalRandom.current();
h = getProbe();
wasUncontended = true;
}
static final int getProbe() {
return UNSAFE.getInt(Thread.currentThread(), PROBE);
}
我们上面说过 getProbe() 方法是为了获取当前线程的 hash值,具体实现是通过 UNSAFE.getInt()实现的,PROBE 是在初始化的时候获取当前线程的 threadLocalRandomProbe 的值。
注意:
Unsafe.getInt()有三个重载方法getInt(Onject o, long offset)、getInt(long address)和getIntVolatile(long address),都是从指定的位置获取变量的值,只不过第一个的 offset 是相对于 对象 O 的内存地址的相对偏移量,第二个 address 是绝对地址偏移量。如果第一个方法中 o 为 null,offset 也会被作为绝对偏移量。第三个则是带有 volatile 语义的load 读操作。
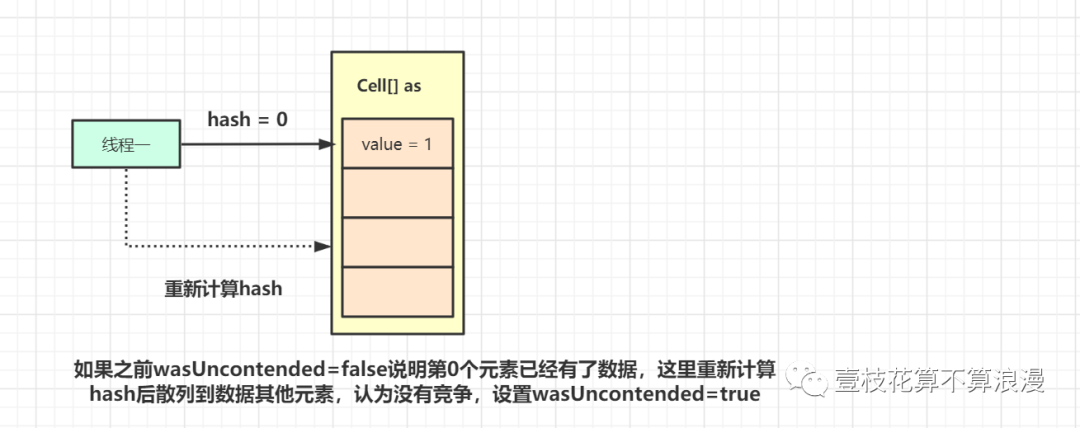
如果当前线程的 hash值 h = getProbe() 为 0,0 与任何数取模都是 0,会固定到数组的第一个位置,所以这里做了优化,使用 ThreadLocalRandom 为当前线程重新计算一个 hash 值。最后设置 wasUncontended = true,这里含义是重新计算了当前线程的 hash 后认为此次不算是一次竞争。hash 值被重置就好比一个全新的线程一样,所以设置了竞争状态为 true 。
可以画图理解为:
接着执行 for 循环,我们可以把 for循环 代码拆分一下,每个 if 条件算作一个 CASE 来分析:
final void longAccumulate(long x, LongBinaryOperator fn, boolean wasUncontended) {
for (;;) {
Cell[] as; Cell a; int n; long v;
if ((as = cells) != null && (n = as.length) > 0) {
}
else if (cellsBusy == 0 && cells == as && casCellsBusy()) {
}
else if (casBase(v = base, ((fn == null) ? v + x : fn.applyAsLong(v, x))))
}
}
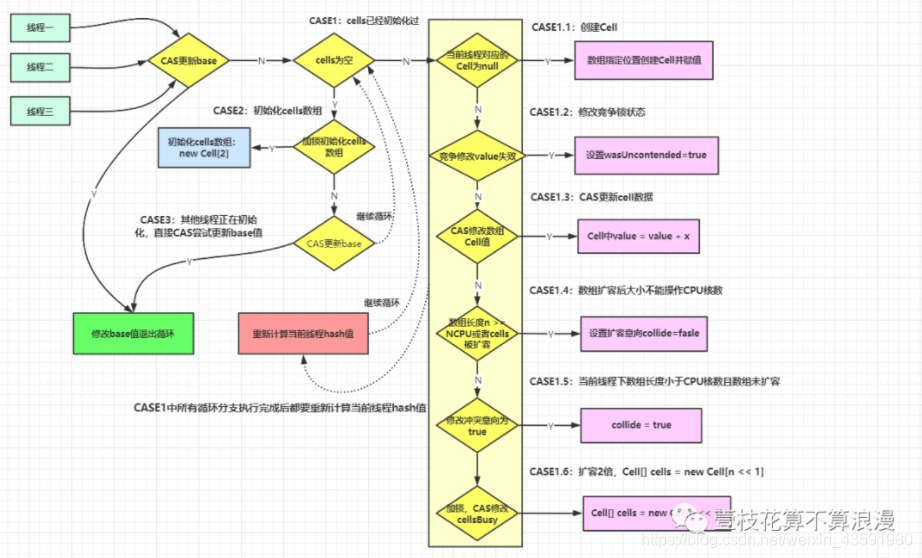
如上所示,第一个if 语句代表CASE1,里面会再有 if判断 会以 CASE1.1 这种形式来讲解,下面接着 else if为 CASE2,最后一个为CASE3
CASE1 执行条件:
if ((as = cells) != null && (n = as.length) > 0) {
}
cells 数组不为空,且数组长度大于 0 的情况会执行 CASE1,CASE1 的实现细节代码比较多,放到最后面讲解。
CASE2 执行条件和实现原理:
else if (cellsBusy == 0 && cells == as && casCellsBusy()) {
boolean init = false;
try {
if (cells == as) {
Cell[] rs = new Cell[2];
rs[h & 1] = new Cell(x);
cells = rs;
init = true;
}
} finally {
cellsBusy = 0;
}
if (init)
break;
}
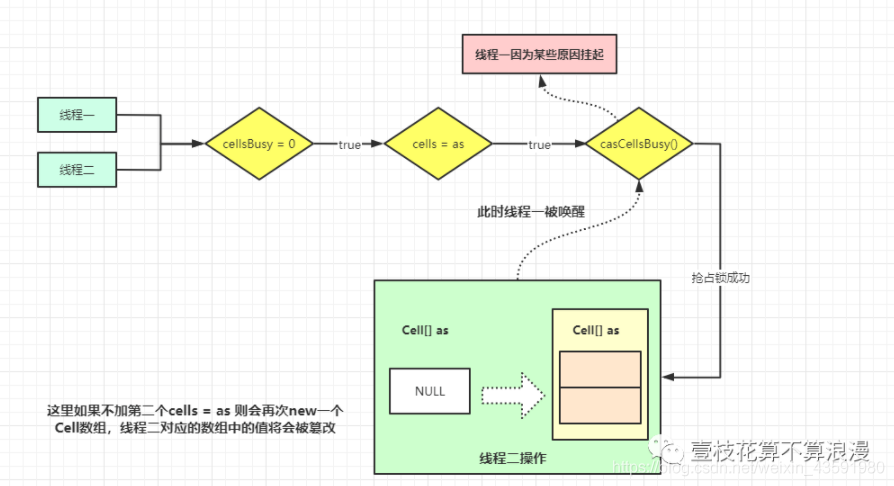
CASE2 标识 cells 数组还未初始化,因为判断 cells == as,这个代表当前线程倒了这里获取的cells 还和之前的一致,我们可以先看这个 case,最后在回头看最为麻烦的 CASE1 的实现逻辑。
cellsBusy 上面说了是加锁的状态,初始化 cells 数组和扩容的时候都要获取加锁的状态,这个是通过 CAS来实现的,为 0 的话代表无锁状态,为 1代表其他线程已经持有锁了。cells == as 代表当前线程持有的数组未进行修改过,caseCellsBusy() 通过CAS操作去获取锁。但是里面的 if 条件又再次判断了 cells == as,这一点是不是很奇怪,通过画图来说明下问题:
如果上面条件都执行成功就会执行数组的初始化及赋值操作,Cell[] rs = new Cell[2] 表示数组的长度为 2,rs [h & 1] = new Cell[x] 表示创建一个新的 Cell 元素,value 是 x值,默认为1。
h & 1 类似于我们之前的HashMap 或者 ThreadLocal 里面经常用到的计算散列桶 index 的算法,通常都是 hash & (table.len - 1),这里就不做过多解释了。执行完成后直接退出 for 循环。
CASE3 执行条件和实现原理
else if (casBase(v = base, ((fn == null) ? v + x : fn.applyAsLong(v, x))))
break;
进入到这里说明 cells 正在或者已经初始化过了,执行 caseBase() 方法,通过 CAS操作来修改 base 的值,如果修改成功则跳出循环,这个 CASE 只有在初始化 cells 数组的时候,多个线程尝试 CAS 修改 cellsBusy 加锁的时候,失败的线程才会走到这个分支,然后直接 CAS操作 修改 base 数据。
CASE1 实现原理:
分析完 CASE2 和 CASE3 ,我们再返回头看一下 CASE1,进入 CASE1 的前提是:cells数组 不为空,已经完成了初始化赋值的操作。
接着还是一点点往下拆分代码,首先看第一个判断分支CASE1.1:
if ((a = as[(n - 1) & h]) == null) {
if (cellsBusy == 0) {
Cell r = new Cell(x);
if (cellsBusy == 0 && casCellsBusy()) {
boolean created = false;
try {
Cell[] rs; int m, j;
if ((rs = cells) != null && (m = rs.length) > 0 && rs[j = (m - 1) & h] == null) {
rs[j] = r;
created = true;
}
} finally {
cellsBusy = 0;
}
if (created)
break;
continue;
}
}
collide = false;
}
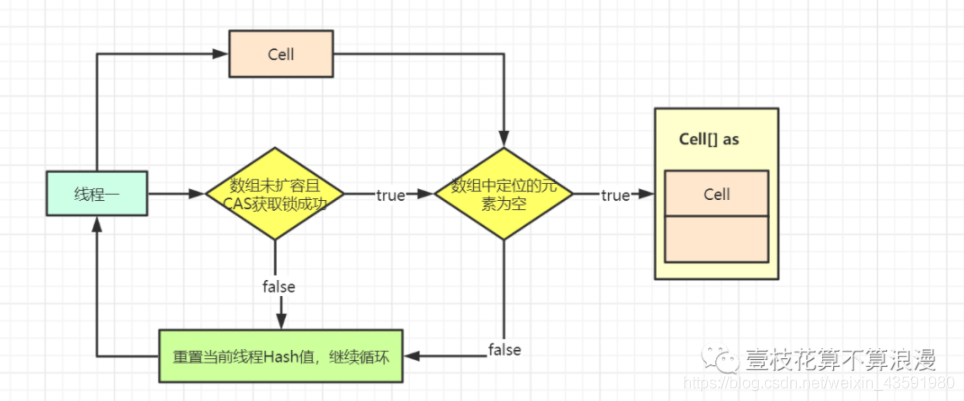
这个 if 条件中(a = as[(n - 1) & h]) == null代表当前线程对应的数组下标位置的 cell 数据为null,代表没有线程在此创建cell对象。
接着判断 cellBusy == 0 ,代表当前锁未被占用。然后新创建cell对象,接着又判断了一遍cellBusy == 0,然后执行caseBusy() 尝试通过CAS 操作修改 cellsBusy = 1,加锁成功后修改扩容意向为 collide = false。
for (;;) {
if ((rs = cells) != null && (m = rs.length) > 0 && rs[j = (m - 1) & h] == null) {
rs[j] = r;
created = true;
}
if (created)
break;
continue;
}
上面代码判断当前线程 hash 后指向的数据位置元素是否为空,如果为空则将 cell 数据放入数组中,跳出循环。如果不为空则继续循环。
继续往下看代码,CASE1.2:
else if (!wasUncontended)
wasUncontended = true;
h = advanceProbe(h);
wasUncontended 表示 cells 初始化后,当前线程竞争修改失败 wasUncontended = false,这里只是重新设置了这个值为 true ,紧接着执行 advanceProbe(h) 重置当前线程的 hash,重新循环。
接着看 CASE1.3:
else if (a.cas(v = a.value, ((fn == null) ? v + x : fn.applyAsLong(v, x))))
break;
进入CASE1.3 说明当前线程对应的数组中有了数据,也重置过 hahs 值,这时通过 CAS 操作尝试对当前数据中的 value值进行累加 x 操作,x 默认为 1,如果 CAS 成功则直接跳出循环。
接着看 CASE1.4:
else if (n >= NCPU || cells != as)
collide = false;
如果 cells 数组的长度达到了 CPU 核心数,或者 cells 扩容了,设置扩容意向为 collide为false并通过下面的 h = advanceProbe(h) 方法修改线程的 probe 再重新尝试。
至于这里为什么要提出和 CPU 数量 做判断的问题:每个线程会通过对cells[threadHash & cells.length -1] 位置的cell对象中的value做累加,这样相当于将线程绑定倒了cells 中的某个cell 对象上,如果超过 CPU数量的时候就不再扩容是因为CPU的数量代表了机器处理能力,当超过CPU数量的时候,多出来的cells数组元素没有太大作用。
接着看 CASE1.5:
else if (!collide)
collide = true;
如果扩容意向 collide 是false 则系应该它为true,然后重新计算当前线程的hash 值继续循环,再CASE1.4中,如果当前数组的长度已经大于CPU的核数了,就会再次设置意向collide = false,这里的意义是保证扩容意向为false后不再继续往后执行CAE1.6的扩容操作了。
接着看CASE1.6 分支:
else if (cellsBusy == 0 && casCellsBusy()) {
try {
if (cells == as) {
Cell[] rs = new Cell[n << 1];
for (int i = 0; i < n; ++i)
rs[i] = as[i];
cells = rs;
}
} finally {
cellsBusy = 0;
}
collide = false;
continue;
}
这里面执行的其实是扩容逻辑,首先是判断通过 CAS 改变cellsBusy 来尝试加锁,如果CAS成功则代表获取锁成功,继续向下执行,判断当前的cells数组和最先赋值的as是同一个,代表这时还没有被其他线程扩容过,然后进行扩容,扩容大小为之前的容量的两倍,这里用的按位左移 1 位来操作的。
Cell[] rs = new Cell[n << 1];
扩容后再将之前数组的元素拷贝到新数组中,释放锁设置 cellsBusy = 0,设置扩容状态,然后继续循环执行。
到了这里,我们已经分析完了longAccumulate()的所有逻辑,逻辑分支挺多,仔细看看还是挺清晰的,流程图如下:
我们再举一些线程执行的例子里面场景覆盖不全,大家可以按照这种模式自己模拟场景分析代码流程:
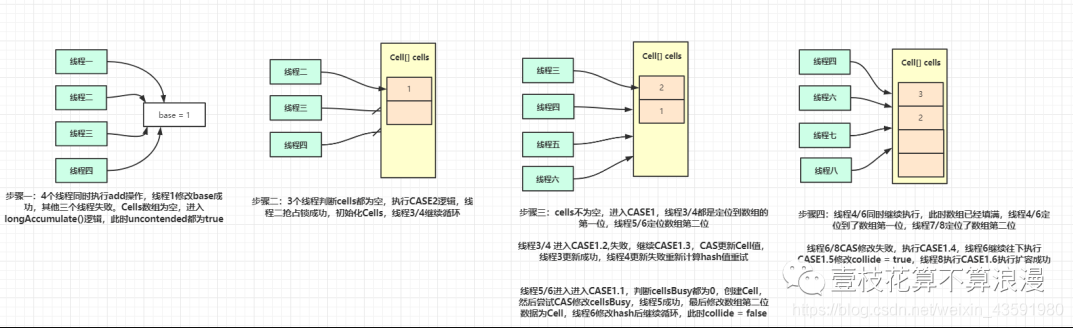
如果有问题也请及时指出,我会第一时间更正,不胜感谢。
4.5、LongAdder 的 sum 方法
当我们最终获取计数器的值的话,我们可以使用LongAdder.longValue() 方法,其内部就是使用 sum 方法来汇总数据的。
java.util.concurrent.atomic.LongAdder.sum():
public long sum() {
Cell[] as = cells; Cell a;
long sum = base;
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}
实现很简单,base +  ,遍历
,遍历 cells 数组中的值,然后累加。
4.6、AtomicLong 可以弃用了嘛?
看上去 LongAdder 的性能全面超越了 AtomicLong ,而且阿里巴巴开发手册页也提及到 推荐使用 LongAdder 对象,比 AtomicLong 性能更好(减少乐观锁的重试次数),但是我们真的就可以舍弃掉 AtomicLong 了嘛?
当然不是,我们需要看场景来使用,如果是并发不太高的系统,使用AtomicLong 可能会更好一些,而且内存需求也会小一些。
我们看过 sum() 方法后可以知道 LongAdder 在统计的时候如果有并发更新,可能导致统计的数据有误差。
而在高并发统计计数的场景下,才更适合使用 LongAdder。
5、总结
LongAdder 中最核心的思想就是利用空间来换时间,将热点 value 分散成一个 Cell 列表来承接并发的 CAS,以此来提高性能。
LongAdder 的原理以及实现都很简单,但其设计的思想值得我们品味和学习。
本文参考:http://www.wazhi.com.cn/SchoolManage/NewsDispatcher?NewsId=942ee429-0c82-4e3b-8df3-4910795d7cfc&SchoolId=1166&action=singlenews