JDK8中Stream 中Collectors 规约处理
Collectors常用方法详解
List<String> strings = Arrays.asList("abc", "", "bc", "efg", "abcd","","11","22","33", "jkl");
一般输出指定集合类型
strings.stream().collect(Collectors.toList());
strings.stream().collect(Collectors.toSet());
//重复key 会抛异常
// strings.stream().collect(Collectors.toConcurrentMap(String::toString,String->String));
//可以使用第三个参数根据逻辑获取value
strings.stream().collect(Collectors.toConcurrentMap(String::toString,String->String,(val1,val2)->{
if (val1.equals(val2)){
return val1;
}else {
return val2;
}
}));
//toCollection 可以指定集合
strings.stream().collect(Collectors.toCollection(LinkedList::new));
strings.stream().collect(Collectors.toCollection(LinkedHashSet::new));
filter过滤
过滤指定条件
可以使用lambda 表达式的语法写法 、也可以指定类型写
System.out.println(strings.parallelStream().filter(x -> x.length() > 1).collect(Collectors.toList()));
//Predicate 类型 过滤相同
System.out.println(strings.stream().filter(Predicate.isEqual("abc").or(Predicate.isEqual("11"))).collect(Collectors.toList()));
System.out.println(strings.stream().filter(Predicate.isEqual("abc").and(Predicate.isEqual("11"))).collect(Collectors.toList()));
输出
[abc, bc, efg, abcd, 11, 22, 33, jkl]
[abc, 11]
[]
joining方法
//默认拼接
System.out.println(strings.parallelStream().filter(x -> x.length() > 1).collect(Collectors.joining()));
//没有后缀
System.out.println(strings.parallelStream().filter(x -> x.length() > 1).collect(Collectors.joining(",")));
//前后缀
System.out.println(strings.parallelStream().filter(x -> x.length() > 1).collect(Collectors.joining("","<",">")));
输出
abcbcefgabcd112233jkl
abc,bc,efg,abcd,11,22,33,jkl
<abcbcefgabcd112233jkl>
统计信息
IntSummaryStatistics 和 LongSummaryStatistics 和 DoubleSummaryStatistics
这三个分别对应 三个方法 分别求不同类型的平均数,最大,最大小 数量 总数 求和

List<Integer> arrays1 = Arrays.asList(1, 2, 22, 11, 11,22,78,99,0, 145,54);
System.out.println(" ---- DoubleSummaryStatistics ----- ");
DoubleSummaryStatistics doubleSummaryStatistics = arrays1.stream().collect(
Collectors.summarizingDouble(Integer::intValue));
System.out.println(doubleSummaryStatistics.getSum());
System.out.println(doubleSummaryStatistics.getMax());
System.out.println(doubleSummaryStatistics.getMin());
System.out.println(doubleSummaryStatistics.getAverage());
System.out.println(doubleSummaryStatistics.getCount());
System.out.println(" ---- IntSummaryStatistics ----- ");
IntSummaryStatistics intSummaryStatistics = arrays1.stream().collect(Collectors.summarizingInt(Integer::intValue));
System.out.println(intSummaryStatistics.getSum());
System.out.println(intSummaryStatistics.getMax());
System.out.println(intSummaryStatistics.getMin());
System.out.println(intSummaryStatistics.getAverage());
System.out.println(intSummaryStatistics.getCount());
System.out.println(" ---- LongSummaryStatistics ----- ");
LongSummaryStatistics longSummaryStatistics = arrays1.stream().collect(Collectors.summarizingLong(Integer::intValue));
System.out.println(longSummaryStatistics.getSum());
System.out.println(longSummaryStatistics.getMax());
System.out.println(longSummaryStatistics.getMin());
System.out.println(longSummaryStatistics.getAverage());
System.out.println(longSummaryStatistics.getCount());
输出
---- DoubleSummaryStatistics -----
445.0
145.0
0.0
40.45454545454545
11
---- IntSummaryStatistics -----
445
145
0
40.45454545454545
11
---- LongSummaryStatistics -----
445
145
0
40.45454545454545
11
而averagingInt/averagingLong/averagingDouble 三个方法 ,分别有对应彼此的Double类型求平均数
System.out.println(" ---- 获取平均值的 Collectors.averaging xxxx 几个方法返回值都是Double类型。 ----- ");
Double aDouble = arrays1.stream().collect(Collectors.averagingDouble(Integer::intValue));
System.out.println(aDouble);
Double integer = arrays1.stream().collect(Collectors.averagingInt(Integer::intValue));
System.out.println(integer);
Double collect1 = arrays1.stream().collect(Collectors.averagingLong(Integer::intValue));
System.out.println(collect1);
输出
---- 获取平均值的 Collectors.averaging xxxx 几个方法返回值都是Double类型。 -----
40.45454545454545
40.45454545454545
40.45454545454545
partitioningBy 分组 和 groupingBy分组
groupingBy分组,partitioningBy分组之后还可以根据条件再过滤
groupingBy方法
构造函数
public static <T, K, A, D>
Collector<T, ?, Map<K, D>> groupingBy(Function<? super T, ? extends K> classifier,// 分组结果map的key的生成
Collector<? super T, A, D> downstream) {//分组结果map的value的生成
}
public static <T, K, D, A, M extends Map<K, D>>
Collector<T, ?, M> groupingBy(Function<? super T, ? extends K> classifier,// 分组结果map的key的生成
Supplier<M> mapFactory,// 分组结果map的生成
Collector<? super T, A, D> downstream) {//分组结果map的value的生成
}
实例
System.out.println("------ groupingBy方法 默认分组 -------");
//默认返回hashmap
Map<Boolean, List<String>> collect3 = strings.stream().collect(Collectors.groupingBy(x -> x.length() > 1));
System.out.println(collect3);
//两个参数 传递还是 Collector 也就是说还可以 使用 Collector继续操作
//这里使用统计数量
Map<Boolean, Long> collect4 = strings.stream().collect(Collectors.groupingBy(x -> x.length() > 1, Collectors.counting()));
System.out.println(collect4);
//这里继续分组
Map<Boolean, Map<Boolean, List<String>>> collect5 = strings.stream().collect(Collectors.groupingBy(x -> x.length() > 1, Collectors.groupingBy(x -> x.length() > 4)));
System.out.println(collect5);
//三个参数, 第二个指定返回类型
TreeMap<Boolean, Map<Boolean, List<String>>> collect6 = strings.stream().collect(Collectors.groupingBy(x -> x.length() > 1, TreeMap::new, Collectors.groupingBy(x -> x.length() > 2)));
System.out.println(collect6);
输出
------ groupingBy方法 默认分组 -------
{false=[, ], true=[abc, bc, efg, abcd, 11, 22, 33, jkl]}
{false=2, true=8}
{false={false=[, ]}, true={false=[abc, bc, efg, abcd, 11, 22, 33, jkl]}}
{false={false=[, ]}, true={false=[bc, 11, 22, 33], true=[abc, efg, abcd, jkl]}}
partitioningBy
构造
public static <T>
Collector<T, ?, Map<Boolean, List<T>>> partitioningBy(Predicate<? super T> predicate) {
return partitioningBy(predicate, toList());
}
partitioningBy和groupingBy 最大的区别是partitioningBy只能由于条件分组,不能用于值分组,而 groupingBy 即可以值分组 也可以条件分组
可以看到编译首先过不去

可以看到编译器提示 必须是布尔类型
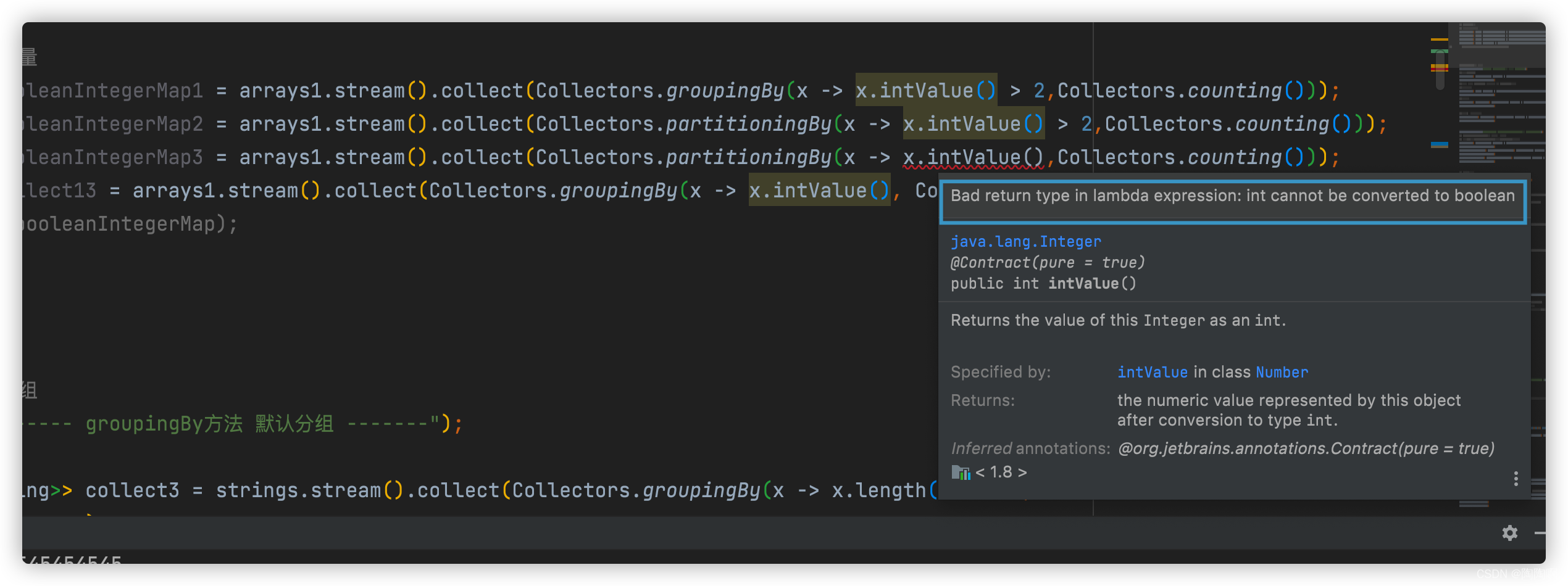
// groupingBy 根据条件分组 满足的和不满足的都分组 之后还可以分组,但是不能再过滤了
Map<Boolean, List<Integer>> collect2 = arrays1.stream().collect(Collectors.groupingBy(x -> x.intValue() > 2));
//大于2的分为一组 每个分组
System.out.println(collect2);
// partitioningBy 根据条件分组 满足的和不满足的都分组 之后还可以根据条件再进行过滤
Comparator<Integer> comparing = Comparator.comparing(Integer::intValue);
Map<Boolean, Optional<Integer>> booleanListMap = arrays1.stream().collect(Collectors.partitioningBy(x -> x.intValue() > 2,Collectors.reducing(BinaryOperator.maxBy(comparing))));
//大于2和不大于2的分组 共2组
System.out.println(booleanListMap);
输出
{false=[1, 2, 0], true=[22, 11, 11, 22, 78, 99, 145, 54]}
{false=Optional[2], true=Optional[145]}
{false=3, true=8} // 统计出数量
counting方法
统计总数 相当于 mapInt 之后的sum()方法
Map<Boolean, Long> booleanIntegerMap1 = arrays1.stream().collect(Collectors.groupingBy(x -> x.intValue() > 2,Collectors.counting()));
相当于
arrays1.stream().mapToInt(Integer::intValue).count();
toMap方法
toMap 将集合转为map类型
构造
public static <T, K, U> Collector<T, ?, Map<K,U>>
toMap(Function<? super T, ? extends K> keyMapper,
Function<? super T, ? extends U> valueMapper)
在上面输出指定集合类型中可以看到 相同key的话会报错,这里会用构造进行处理相同的Key,去选择value值
//todo 2个参数
// todo -------------------- 相同的存在相同的key会报错
/*Map<String, String> collect10 = strings.stream().collect(Collectors.toMap(
String::toString, //key
Function.identity() // 第二个参数 是value 也可以是: String->String
));
System.out.println(collect10);
//也可以写成
Map<String, String> collect11 = strings.stream().collect(Collectors.toMap(
String::toString, //key
String->String
));
System.out.println(collect11);
//也可以写成
Map<String, String> collect12 = strings.stream().collect(Collectors.toMap(
String::toString, //key
String->String
));
//相同的存在相同的key会报错,
System.out.println(collect12);*/
// todo -------------------- 相同的存在相同的key会报错
相同Key冲突 处理,以及指定返回map
构造
public static <T, K, U, M extends Map<K, U>>
Collector<T, ?, M> toMap(Function<? super T, ? extends K> keyMapper,
Function<? super T, ? extends U> valueMapper,
BinaryOperator<U> mergeFunction,
Supplier<M> mapSupplier) {
实例:
// 三个参数 构造方法 , 第三个参数 如果有冲突的key 自定义选择value值返回 最后一个mapSupplier参数指定返回Map类型
//如果有重复的key 比较value 值选择返回key的value值
Map<String, String> collect = strings.stream().collect(Collectors.toMap(
String::toString, //key
Function.identity(), // 第二个参数 是value 也可以是: String->String
(xValue,yValue)->{ // 第三个参数 如果有冲突的key 自定义选择value值返回
if (xValue.length() > yValue.length()) { // 这里根据逻辑选择相同Key的value值
return xValue;
}else {
return yValue;
}
},
// 第四个参数指定返回map构造器
()->{
// return new HashMap<>();
return new TreeMap<>();
}));
System.out.println(collect);
reduce 表示对元素里值做运算
reducing及其重载形式,maxBy,minBy
reducing表示对steam里的元素做运算,最终等到一个值。
identity:初值,设置一个steam元素与外部比较的一个初始值。
mapper: 将stream内部类型映射为U类型的方法
BinaryOperator:op两个U类型值合并运算的方法

上面两个是一个类型api 是否有初始值,第二是比较的函数
BinaryOperator<User> tBinaryOperator = BinaryOperator.maxBy(Comparator.comparing(User::getAge));
//传一个初始值 返回符合条件的值
User collect14 = list.stream().collect(Collectors.reducing(new User(), tBinaryOperator));
System.out.println(collect14);
User collect15 = list.stream().collect(Collectors.reducing(tBinaryOperator)).get();
System.out.println(collect15);
//将stream内部类型转化成合并运算的对象(User) 然后再根据 tBinaryOperator 获取符合条件的值
User collect16 = list.stream().collect(Collectors.reducing(new User(), x->{
x.setAge(x.getAge() + 1);
return x;
}, tBinaryOperator));
System.out.println(collect16);
输出
User{name='老王', age=29, classic='部门2', manager='Java'}
User{name='老王', age=29, classic='部门2', manager='Java'}
User{name='老王', age=30, classic='部门2', manager='Java'}
maxBy/minBy方法
和reduce连起来使用,对值进行运算返回一个值
BinaryOperator<Integer> maxBy = BinaryOperator.maxBy(Comparator.comparing(Integer::intValue));
BinaryOperator<Integer> minBy = BinaryOperator.minBy(Comparator.comparing(Integer::intValue));
// BinaryOperator 构造方法 public static <T> Collector<T, ?, Optional<T>> reducing(BinaryOperator<T> op)
Map<Boolean, Optional<Integer>> max = arrays1.stream().collect(Collectors.groupingBy(x -> x.intValue() > 1, Collectors.reducing(maxBy)));
Map<Boolean, Optional<Integer>> min = arrays1.stream().collect(Collectors.groupingBy(x -> x.intValue() > 1, Collectors.reducing(minBy)));
System.out.println(max);
System.out.println(min);
mapping方法
mapping方法用于对Stream中元素的某个具体属性做进一步的映射处理,一般是和其他方法一起组合使用
//按照年龄分组,然后,拼接
Map<Integer, String> collect10 = list.stream().collect(Collectors.groupingBy(User::getAge,
Collectors.mapping(User::getName, Collectors.joining(",")))
);
System.out.println(collect10);
//根据年龄分组 然后根据输出名字集合 等于 "先分组 再map属性"
Map<Integer, List<String>> collect11 = list.stream().collect(Collectors.groupingBy(User::getAge,
Collectors.mapping(User::getName, Collectors.toList())));
System.out.println(collect11);
//相当于 下面 listMap
//先分组
Map<Integer, List<User>> collect12 = list.stream().collect(Collectors.groupingBy(User::getAge));
Map<Integer, List<String>> listMap = new HashMap<>();
//再拿到List 去Map属性
collect12.forEach((key,list)->{
listMap.put(key,list.stream().map(User::getName).collect(Collectors.toList()));
});
}
public static final List<User> list = Arrays.asList(
new User("小王",18,"1班","学生"),
new User("小涨",23,"部门1","Java开发"),
new User("小李",23,"部门2","golang开发"),
new User("小吕",18,"2班","学生"),
new User("老王",29,"部门2","Java")
);
}
class User{
private String name;
private int age;
private String classic;
private String manager;
public User() {
}
public User(String name, int age, String classic, String manager) {
this.name = name;
this.age = age;
this.classic = classic;
this.manager = manager;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getClassic() {
return classic;
}
public void setClassic(String classic) {
this.classic = classic;
}
public String getManager() {
return manager;
}
public void setManager(String manager) {
this.manager = manager;
}
}
@Override
public String toString() {
return "User{" +
"name='" + name + '\'' +
", age=" + age +
", classic='" + classic + '\'' +
", manager='" + manager + '\'' +
'}';
}
输出
{18=小王,小吕, 23=小涨,小李, 29=老王}
{18=[小王, 小吕], 23=[小涨, 小李], 29=[老王]}
{18=[小王, 小吕], 23=[小涨, 小李], 29=[老王]}
collectingAndThen方法
// 该方法接收两个参数,表示在第一个参数执行基础上,再执行第二个参数对应的函数表达式,
Double aDouble1 = arrays2.stream().collect(Collectors.averagingDouble(Integer::intValue));
Double aDouble2 = arrays2.stream().collect(Collectors.collectingAndThen(Collectors.averagingDouble(Integer::intValue), s -> s * 2));
System.out.println(aDouble1);//40.45454545454545
System.out.println(aDouble2);//80.9090909090909
// 生成不可变List
List<Integer> unmodifiableList = arrays2.stream().collect(Collectors.collectingAndThen(Collectors.toList(), Collections::unmodifiableList));
System.out.println(unmodifiableList.size());
// 不可变list
// unmodifiableList.add(1); // todo java.util.Collections$UnmodifiableCollection.add
groupingByConcurrent方法
groupingByConcurrent方法 见名知其意 线程安全的
groupBy线程不安全
// 返回的Map类型是ConcurrentHashMap,用法和groupingBy方法是类似的
Map<Boolean, List<String>> collect8 = strings.stream().collect(Collectors.groupingBy(x -> x.length() > 1));
System.out.println(collect8);
ConcurrentMap<Boolean, ConcurrentMap<Boolean, List<String>>> collect9 = strings.stream().collect(Collectors.groupingByConcurrent(x -> x.length() > 1, Collectors.groupingByConcurrent(x -> x.length() > 2)));
System.out.println(collect9);
ConcurrentMap<Object, ConcurrentMap<Object, List<String>>> collect7 = strings.stream().collect(Collectors.groupingByConcurrent(x -> x.length() > 1, ConcurrentHashMap::new, Collectors.groupingByConcurrent(x -> x.length() > 2)));
System.out.println(collect7);