JVM是什么
JVM是Java Virtual Machine(Java虚拟机)的缩写
JVM就是Java虚拟机,Java虚拟机就是JVM
Java语言的一个非常重要的特点就是与平台的无关性。而使用Java虚拟机是实现这一特点的关键。一般的高级语言如果要在不同的平台上运行,至少需要编译成不同的目标代码。而引入Java语言虚拟机后,Java语言在不同平台上运行时不需要重新编译。Java语言会使用Java虚拟机屏蔽了与具体平台相关的信息,使得Java语言编译程序只需生成在Java虚拟机上运行的目标代码(字节码),就可以在多种平台上不加修改地运行。
为什么学习JVM
为何现在的Java明明执行代码的效率没有C或者C++快,但是它依旧霸占企业开发那么多年。就正是因为JVM代替了我们对内存管理。
我们在真正的java开发中就没有考虑过对内存管理 ,不像C或C++还要考虑什么时候释放资源。我们java只需要考虑业务实现就行了。
但是JVM的处理又不是万能的,如果它出错了,对内存的管理出现了问题,就要我们人工的去给他做处理。
JVM的作用
Java虚拟机就是一个二进制的字节码运行环境,负责装载字节码到其内部,
本来我们写的代码在对于不同的操作系统这些,都要编译成这个操作系统能读懂的编码格式。
但是这也就体现出Java的多平台机制, 解释/编译都是在java的jvm虚拟机中进行。对应平台上的机器码指令执行,每一条java指令,Java虚拟机中都有详细的定义,如怎么取操作数,怎么处理操作数,处理结果放在哪儿。
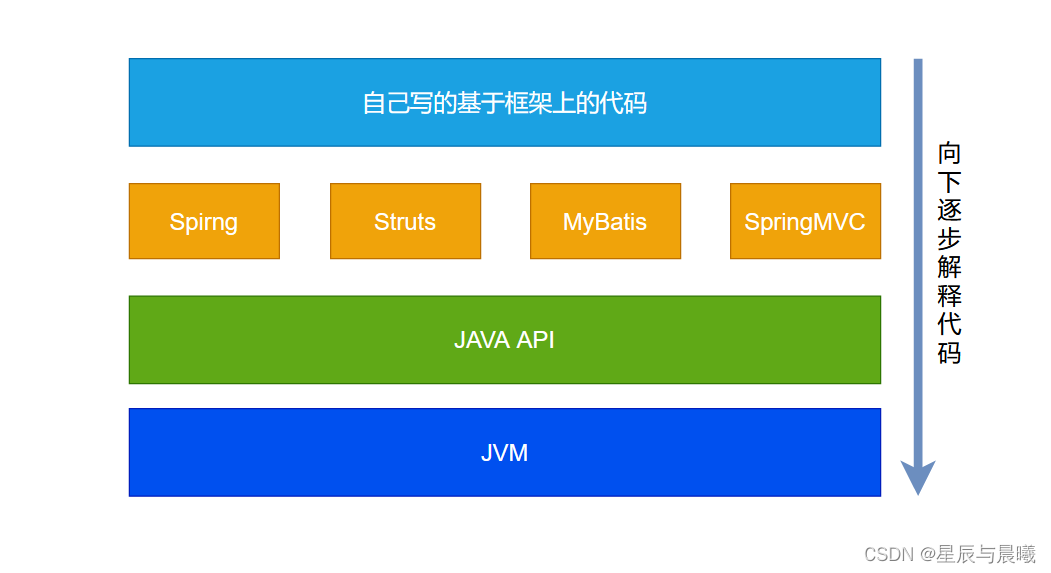
而我们常常说Java语言是跨平台的语言。而这个跨平台实地值的就是JVM的跨平台机制。
JAVA具有了JVM,使得从软件层面屏蔽了底层硬件、指令层面的细节让他兼容各种系统。
而像C和C++这样的语言就需要在编译器层面去兼容不同操作系统的不同层面,在代码的书写方面有一些的不同
JVM的特点
? 通过一次编译可以到处运行
? 自动进行内存的管理
? 自动垃圾回收管理
发展到现在的JVM不仅仅可以执行java的字节码文件,还可以执行的其他的汇编语言编译后的字节码文件,是一个跨语言的平台
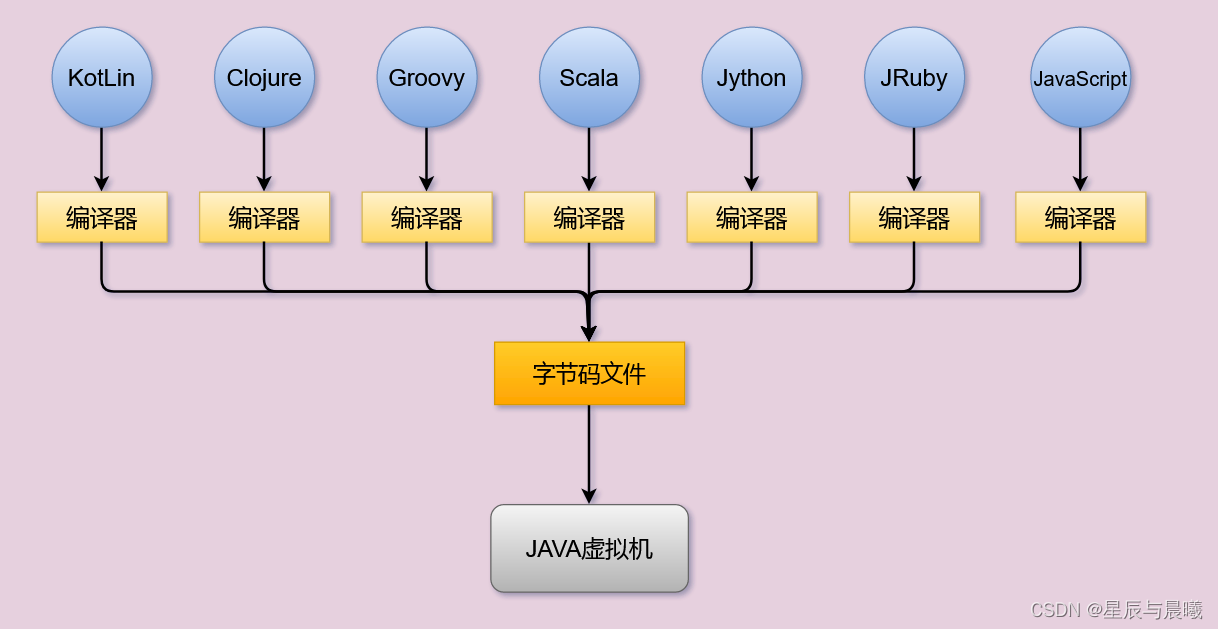
JVM的位置
JVM是运行在操作系统之上的,通过它使得编译后的代码可以向操作系统发起请求等操作,而它并没有直接和计算机硬件产生直接的交互。
根据官方的说明,Jdk中包括了Jre,Jre中包括了JVM
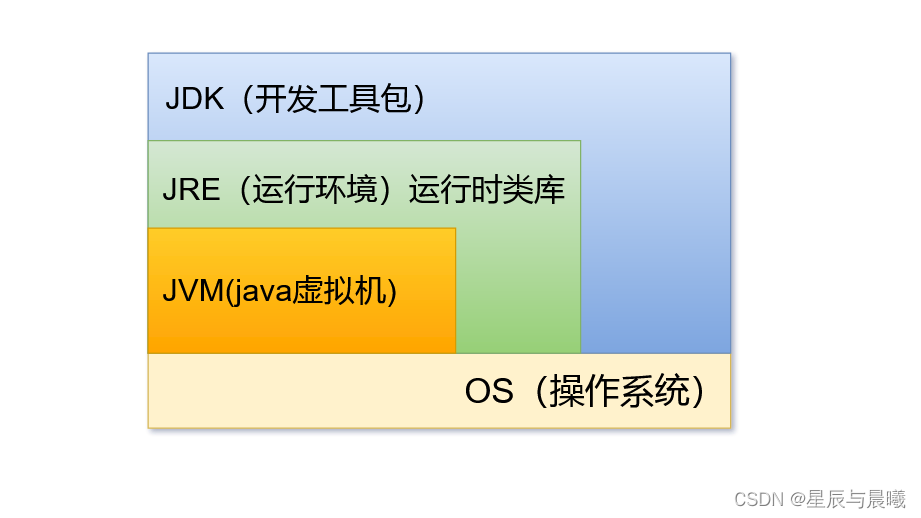
Jre大部分都是由 C 和 C++ 语言编写的,他是我们在编译java时所需要的基础的类库。
而Jdk还包括了一些Jre之外的东西 ,就是这些东西帮我们编译Java代码的, 还有就是监控Jvm的一些工具。
JVM的整体可以分为四个部分
- 类加载器子系统(ClassLoader)
- 运行时数据区(Runtime Data Area)
- 执行引擎(Execution Engine)
- 本地库接口(Native Interface)
JVM简图:
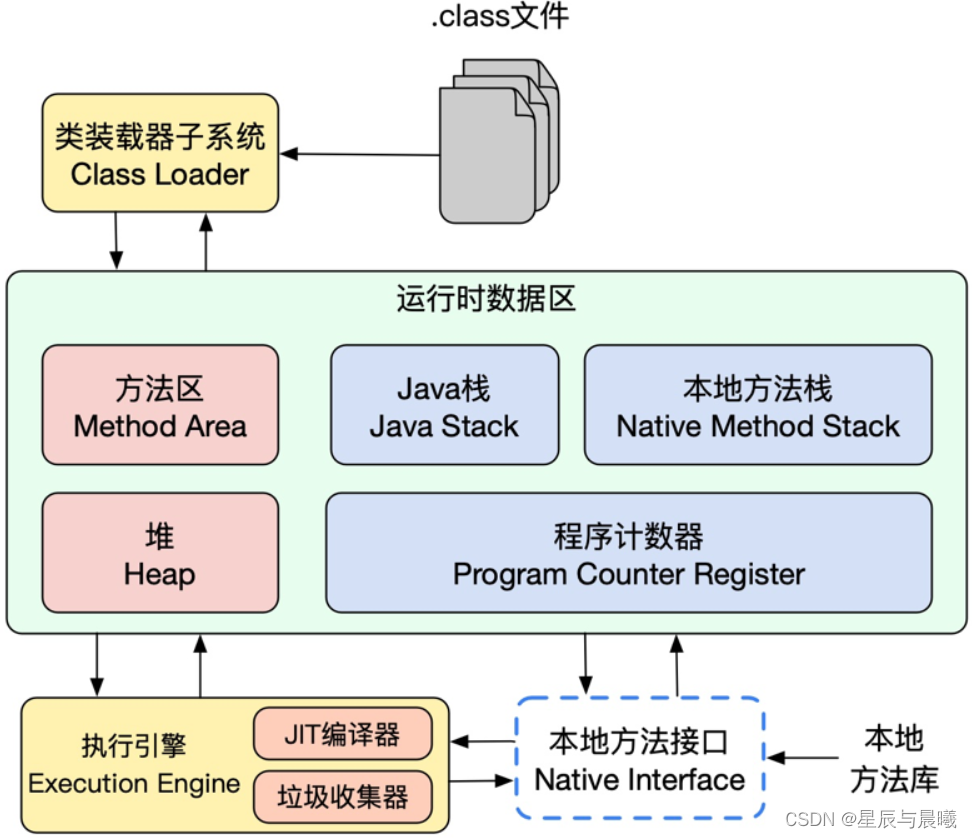 在运行时数据区中,方法区和堆都是线程共享的;
在运行时数据区中,方法区和堆都是线程共享的;
java栈、本地方法栈、程序计数器都是线程私有的。
JVM详细图:
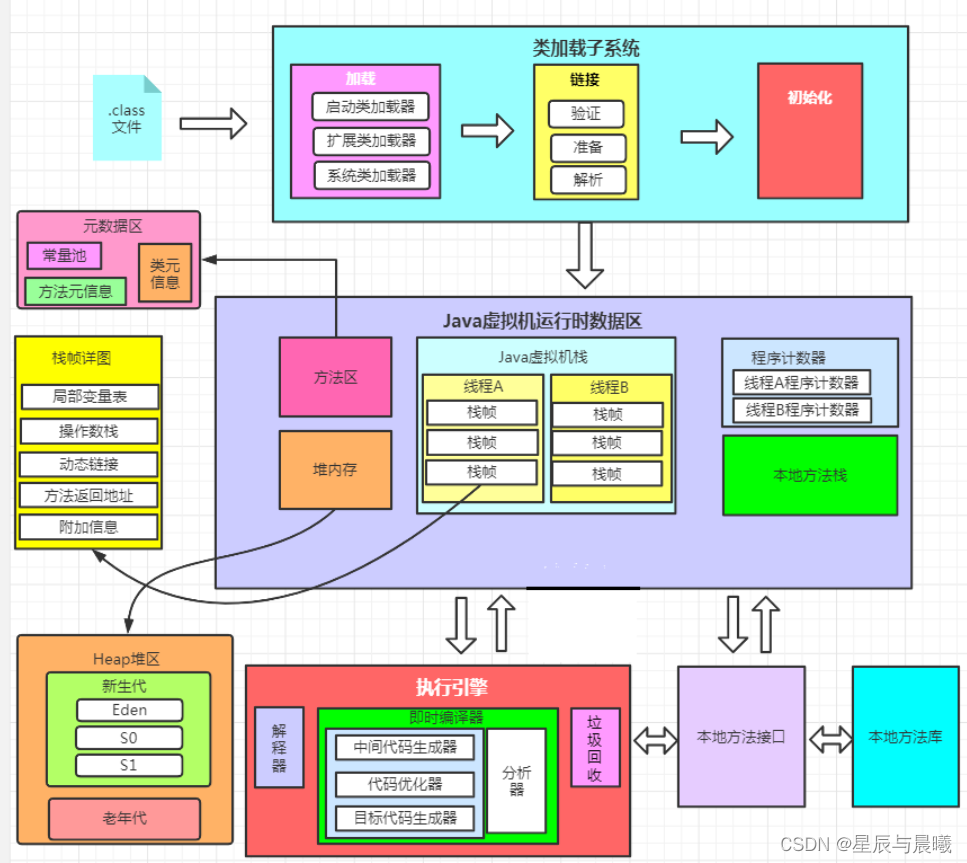
各个组成部分对数据的处理
程序在执行之前先要把java代码转换成字节码(Class文件)
然后jvm再进行具体操作,jvm首先就需要把字节码(Class文件)通过一定的方式类加载子系统(ClassLoader) 将文件加载到内存中的运行时数据区(Runntime Data Area) ,而字节码文件是jvm的一套指令集规范,并不能直接去交给子系统去执行,因此这里就需要特定的命令解析器执行引擎(Execution Engine) 将字节码翻译为最底层的系统指令,就可以交给CPU去处理执行处理这写指令。
而在这个处理的过程中还需要调用其它的语言接口(操作系统往往都是又C语言来写的,丢给系统的都不是用java语言写的)本地接口(Native Interface) 来实现整个程序的功能。
这就是JVM的4个主要组成部分的职责与功能。
而我们通常所说的JVM组成指的是 运行时数据区(Runtime Data),因为通常需要程序员去调试分析的就是“运行时数据区”,或者更加具体的说就是“运行时数据区”里的堆(Heap)模块
Java代码的执行流程
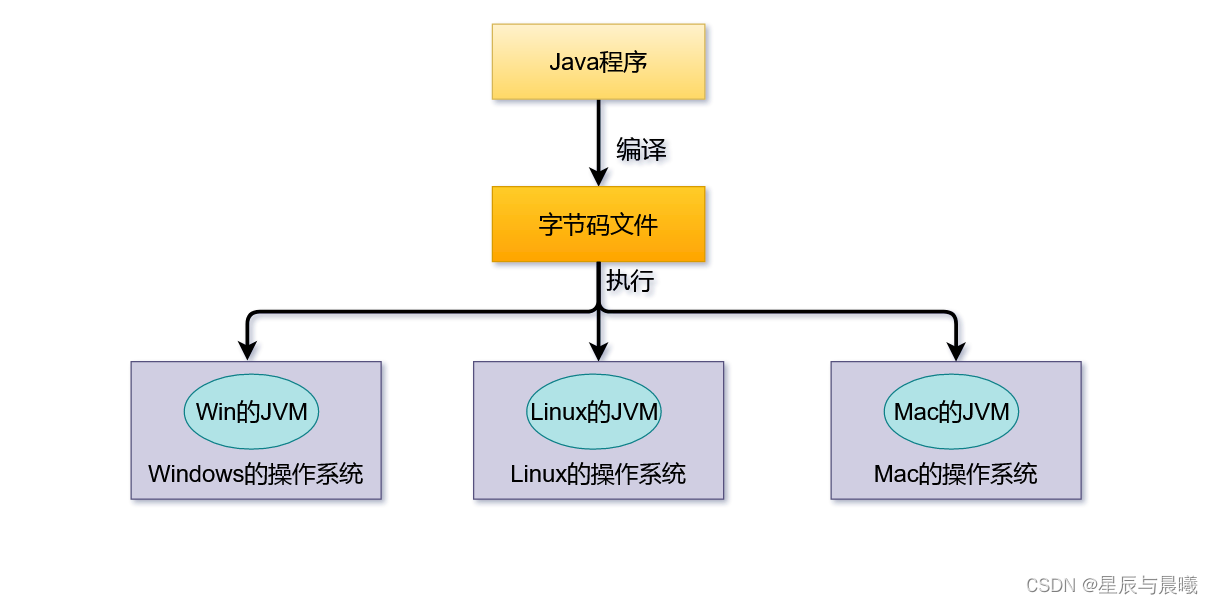
在Java编译的过程中,任何一个节点执行失败就会造成编译的失败。虽然各个平台的Java虚拟机内部实现细节都各有不同,但是它们执行的字节码内容却是一样的。
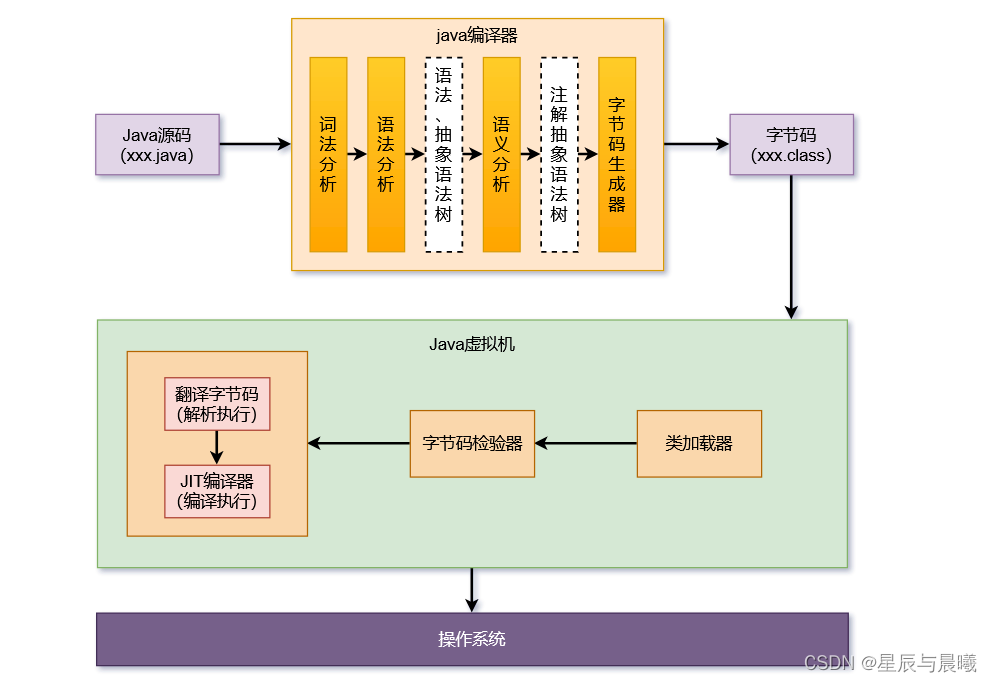
而JVM的主要任务就是负责将字节码装载到其内部,解释/编译为对应平台上的机器指令执行,JVM使用类加器(Class Loader)装载Class文件。
类加载完成后,会进行字节码的检验,字节码校验通过之后JVM解释器就会把字节器翻译成机器码交由操作系统来执行。
但不是所有的代码都是解释执行,JVM 对此作了优化,比如 HotSpot 虚拟机, 它本身提供了 JIT(Just In Time)的编译器。
JVM架构模型
Java编译器输入的指令流基本上是一种基于栈的指令集架构,另一种指令集架构就是基于寄存器的指令基架构 (比如C语言就可以直接对寄存器进行操作)。
这两者的区别:
-
基于栈式架构的特点
● 设计和实现更简单,适用于资源受限的系统。
● 避开了寄存器的分配难题:使用零地址指令方式分配。
● 使用零地址指令方式分配,其执行过程依赖于操作栈,指令集更小,编译器容易实现。
● 编译器容易实现。
● 不需要硬件支持,可移植性强,更好实现了跨平台。 -
基于寄存器式架构的特点
● 典型的应用是x86的二进制指令集:比如传统的Pc以及Android的Davlik虚拟机。
● 指令完全依赖于硬件,可移植性差。
性能优秀,执行更高效。
● 与栈式架构相比完成一项操作使用的指令更少。
● 在大部分情况下,基于寄存器架构的指令集往往都以一地址指令、二地址指令和三地址指令为主,而基于栈式架构的指令集却是以零地址指令为主
举例:
同样执行2+3的逻辑操作,指令分别如下:
基于栈的计算流程(以Java虚拟机为例)
iconst_2 //常量2入栈
istore_1
iconst_3 //常量3入栈
istore_2
iload_1
iload_2
iadd //常量2,3出栈,执行相加操作
istore_0 //结果5入栈
基于寄存器的计算流程
mov eax,2 //将eax寄存器的值设为1
add eax,3 //将eax寄存器的值加3
相比之下明显的基于寄存器的计算流程明显少于基于栈的计算流程
总结:
所以由于跨平台的设计思想,Java指令集都是根据栈来设计的,不同CPU机构不同,所以不能设计为基本的寄存器。
优点就是跨平台,指令集小,编译器容易实现。
缺点就是性能下降,实现同样的功能所需要更多的指令。
说明:什么叫零地址指令,一地址指令,二地址指令,三地址指令?
零地址指令是只有操作码,没有操作数。这种指令有两种情况:一是无需操作数,另一种是操作数为默认的(隐含的),默认为操作数在寄存器中,指令可直接访问寄存器。
零地址指令:在堆栈型计算机中,操作数一般存放在下推堆栈顶的两个单元中,结果又放入栈顶,地址均被隐含,因而大多数指令只有操作码而没有地址域。
一地址指令:(单地址指令)地址域中A 确定第一操作数地址。固定使用某个寄存器存放第二操作数和操作结果。因而在指令中隐含了它们的地址。
二地址指令:地址域中A1确定第一操作数地址,A2同时确定第二操作数地址和结果地址。
三地址指令:一般地址域中A1、A2分别确定第一、第二操作数地址,A3确定结果地址。下一条指令的地址通常由程序计数器按顺序给出。
栈数据结构,一般只有入栈和出栈,所操作的地方只有栈顶元素位置,所以位置是确定的,不需要地址。