��������
Java������ǿ��������,����ÿһ�����ݶ���������ȷ����������,��ͬ���������� Ҳ�����˲�ͬ���ڴ�ռ� �������DZ�ʾ�����ݴ�С Ҳ�Dz�һ���ġ�
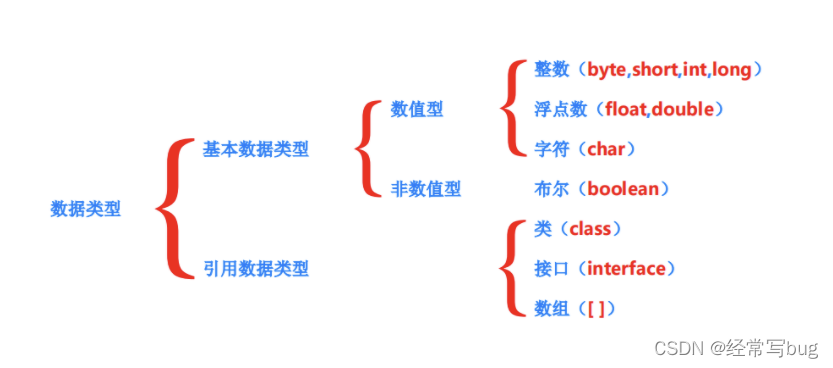
���������ڴ�ռ�ú�ȡֵ��Χ:
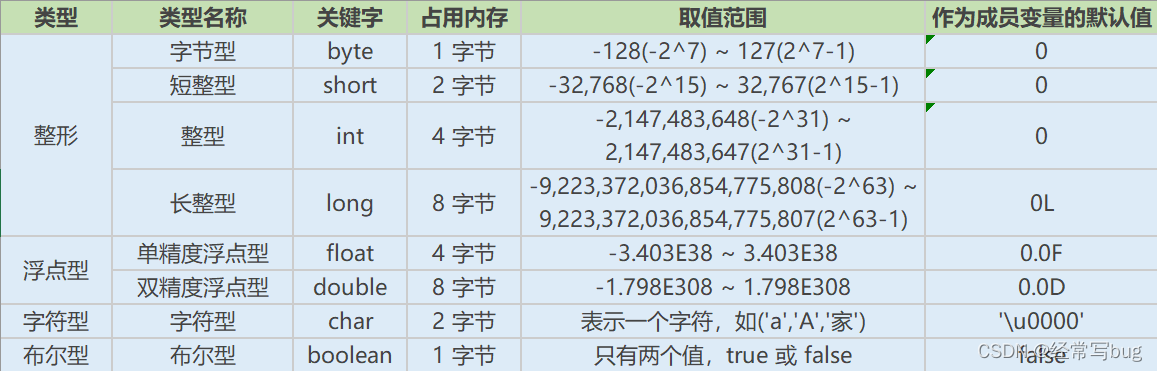
��Χ�Ĵ�С˳��:byte < short =char < int <long < float <double
- �����紫��Ĺ�����,Ϊ�˽�ʡ�ռ�,�����ֽ�����Ϊ���ݵĴ��䷽ʽ��
- Ϊ�˺� int ������,long �ͱ�����������ʱ��,ĩβҪ���ϴ�д�ġ�L����
- Ϊ�˺� double ������,float �ͱ�����������ʱ��,ĩβҪ����Сд�ġ�f��������Ҫʹ�ô�д�ġ�F��,����ΪСд�ġ�f�������ױ��
- double ͬ�����ʺ����ھ�ȷ����ֵ,����˵����,���ʹ�� BigDecimal��
- char ��Ȼֻ��һ���ַ�,Ϊʲôռ 2 ���ֽ���?
- ��Ҫ����Ϊ Java ʹ�õ��� Unicode �ַ��������� ASCII �ַ�����
Ϊʲô����Ҳ������������?
��������:
public class ArrayDemo {
public static void main(String[] args) {
int [] arrays = {1,2,3};
System.out.println(arrays);
}
}
arrays ��һ�� int ���͵������ӡ���������ʾ:
[I@2d209079
[I ��ʾ������ int ���͵�,@ ������ʮ�����Ƶ� hashCode���������Ĵ�ӡ���̫�����Ի�����,һ���˱�ʾ������!Ϊʲô��������ʾ��?�鿴һ�� java.lang.Object ��� toString() �����������ˡ�
������Ȼû����ʽ�����һ����,������ȷ��һ������,�̳��������� Object �����з�������Ϊʲô���鲻��������һ��������ʾ��?�����ַ��� String ��������?
һ�������Ľ����� Java ���������ˡ�������Ĵ���һ�� Array.java,����Ҳ���Լ�������ʵ������,������Ҫ����һ����������������Ԫ��,���� String ��������
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
/** The value is used for character storage. */
private final char value[];
}
Ϊʲô�ӿ�����������?
���ڽӿ����͵����ñ�����˵,��û��ֱ�� new һ��:
ֻ�� new һ��ʵ��������Ķ�������Ȼ�ӿ�Ҳ���������������ˡ�
����һ�»����������ͺ�������������֮�����IJ��
-
������������:
1��������ָ��������ֵ��
2�������������ʹ洢��ջ�ϡ�
-
������������:
1��������ָ����Ǵ洢������ڴ��ַ,��ջ�ϡ�
2���ڴ��ַָ��Ķ���洢�ڶ��ϡ�
��������ת��
-
��ʽ����ת��:
- ����: �Ǵ�С��Χ���������� ֱ��ת�� ��Χ����������
��������:byte < short = char < int < long < float < double
���ù���:
- ��int��(���ߵ���)������, �ڽ��������ʱ��, С���ͻ��Զ�����Ϊ�����ͽ�����
- :��intС����������, �ڽ��������ʱ��,���еĶ�Ҫ����Ϊ int���� ��ȥ���㡣
-
ǿ������ת��:
- ����:�ǴӴ�Χ���������� ǿ��ת�� С��Χ����������
-
ǿ������ת����ע������:
-
boolean���� �������κε�����ת��.
-
�����Ż�����:
-
1.��intС������ ���г����Ż�����:byte��short��char int
2.дһ������������ʱ��, ��������Ҳ�����������͵�, int����
3.дһ��С��������ʱ��,С������Ҳ�����������͵�, double���͡�
��������:byte d = 3 + 4; Ϊʲô������ִ���?
public class Test {
public static void main(String[] args) {
byte d = 3 + 4;
}
}
��Ϊ3��4,����������,Java�д��ڡ������Ż����ơ�
�����Ż�����:�ڱ���ʱ(javac),�ͻὫ3��4�����һ��7�Ľ��,���һ��Զ��жϸý���Ƿ���byteȡֵ��Χ�ڡ�
��:����ͨ��
����:����ʧ��
long���͵����ݺ��� ΪʲôҪ��L?
class Demo {
public static void main(String[] args){
int a = 100;
long lo = a; // ��ȷ ��ʽ����ת��
long lon = 100; // ��ȷ�� ��Ȼ����ȷ�� ��ôΪʲô��ʦһֱ˵ ������long�� �͵����ݺ��� ��һ��L�� ʵ�ڲ�����
System.out.println(100); // 100 ��int����
//System.out.println(10000000000); //100�� int���� (int���͵����� ���21������)
// ��ʱ ������, 100���Ѿ�������int��������
// ���� ֱ��дһ�� �������� ȷʵ����int���͵İ�, ���Կ϶�������
// ���� ���Ǿ��� �����ܲ���дһ��������ʱ�� ��jvm����������һ��long���͵�������,
������int��, ���� ��ֻ��Ҫ�����ݺ����һ�� L�Ϳ����ˡ�
System.out.println(10000000000L);
long lo = 100;
}
}
�����
���������: �������������ֵ�����������������Ƚ����������Ԫ�������λ�����
-
�����:�Գ������߱������в���������
-
����ʽ:������� �ѳ������߱���������������java���ʽ�� �Ϳ��Գ�Ϊ����ʽ��
-
��ͬ��������ӵı���ʽ���ֵ��Dz�ͬ���͵ı���ʽ��
-
int c = a + b;
- +:�������,���������������
- a + b:�DZ���ʽ,����+�����������,�����������ʽ����������ʽ������ʽ���ܵ�������䡣
-
ע������:
-
+,-��ʱҲ����������š�
-
��+��Ҳ����Ϊƴ�ӷ�ȥ�����ַ����ļӷ���
System.out.println(+10); // 10 ��ʱ+�Ŵ����� ���� System.out.println(-10); // -10 ��ʱ-�Ŵ������� ���� -
/
-
��������õ��Ķ�������,Ҫ��õ�С�� �ͱ�����С���������㡣
-
���������� 0 ��ʱ��(
10 / 0),���׳��쳣:Exception in thread "main" java.lang.ArithmeticException: / by zero at com.itwanger.eleven.ArithmeticOperator.main(ArithmeticOperator.java:32) -
��Ҫע�����,������������ 0 ��ʱ��,���Ϊ Infinity ���� NaN��
- Infinity ��������˼�������,NaN ��������˼���ⲻ��һ������(Not a Number)��
System.out.println(10.0 / 0.0); // Infinity System.out.println(0.0 / 0.0); // NaN -
���������ڽ��г�������ʱ,��Ҫ���жϳ����Ƿ�Ϊ 0,��������׳��쳣��
-
-
%
- ȡģ�Ľ�� �ķ��� �� %���������ķ���һ�¡�
-
++ �� �C
- ����++�����κε�λ�� �����������++ �����ͻ��1
- ++���ڱ����ĺ��� ����ȡ���� ������û��+1��ֵ��
- ++���ڱ�����ǰ�� ����ȡ���� ����+1֮���ֵ��
- ���������Լ��Լ��Լ�,�����ֱ�ӱ�����
-
�Ƚ������: > < >= <= == !=
- �Ƚ��������������Ľ�� ȫ������ boolean��������
-
�������:���ǿ�������˵,�������,���������ӹ�ϵ����ʽ��������� ��Ȼ,�������Ҳ����ֱ�����Ӳ������͵ij������߱�����
- & : ���ҵ���˼ ����, �м���١� ��false��false
- | : ���ߵ���˼ ����, ��������, ��true ��true
- ^ : ��� �� :��ͬ , ����� ��ͬ, true, ���� false
- ��� ����������� ֻ������ boolean���� Ҳ����˵ ^ ����ֻ��дtrue false
-
��·�������
- && ��& �Ľ����һ���ġ�&& Ч�ʸߡ�����, ��false��false�� �������false�� �Ҳ�Ͳ�ִ���ˡ�
- || ��| �Ľ����һ���ġ�|| Ч�ʸߡ� ����, ��true��true�� �������true�� �Ҳ�Ͳ�ִ����
- ����**&**,����������,�ұ߶�Ҫִ�С�
- ��·��**&&,������Ϊ��,�ұ�ִ��;������Ϊ��,�ұ߲�ִ��**��
- ����**|**,����������,�ұ߶�Ҫִ�С�
- ��·��**||,������Ϊ��,�ұ�ִ��;������Ϊ��,�ұ߲�ִ��**��
-
��Ԫ�����
- ��ϵ����ʽ ? ����ʽ1 : ����ʽ2
- �������������ݵĸ��� ֻ����3��
-
������: & | ~ ^
-

- ���������������һ����, ֻ���� ������������true��false λ������������1��0 ,��Ϳ��� ��1����true ��0����false Ȼ����������㡣
- & ��0��0 �κ��� ��0 ȥ������ ����0
- | ��1��1 ͬ���������� һ���� �� ͬ���������������� ȥ������ �õ� �����
- ~ ��0��1 ~x = -(x+1)
- ^ �� ��ͬ��true ��Ӧ1 ��ͬ��false ��Ӧ0 ������ͬ���� ��� �����0,����: һ������0ȥ��� �õ������� һ���� ������һ����������� ����������
- << ���� *2^
- ������� /2^
int a = 60, b = 13;
System.out.println("a �Ķ�����:" + Integer.toBinaryString(a)); // 111100
System.out.println("b �Ķ�����:" + Integer.toBinaryString(b)); // 1101
int c = a & b;
System.out.println("a & b:" + c + ",��������:" + Integer.toBinaryString(c));
c = a | b;
System.out.println("a | b:" + c + ",��������:" + Integer.toBinaryString(c));
c = a ^ b;
System.out.println("a ^ b:" + c + ",��������:" + Integer.toBinaryString(c));
c = ~a;
System.out.println("~a:" + c + ",��������:" + Integer.toBinaryString(c));
c = a << 2;
System.out.println("a << 2:" + c + ",��������:" + Integer.toBinaryString(c));
c = a >> 2;
System.out.println("a >> 2:" + c + ",��������:" + Integer.toBinaryString(c));
c = a >>> 2;
System.out.println("a >>> 2:" + c + ",��������:" + Integer.toBinaryString(c));