����Ŀ¼
Linux�̸߳���
ʲô���߳�
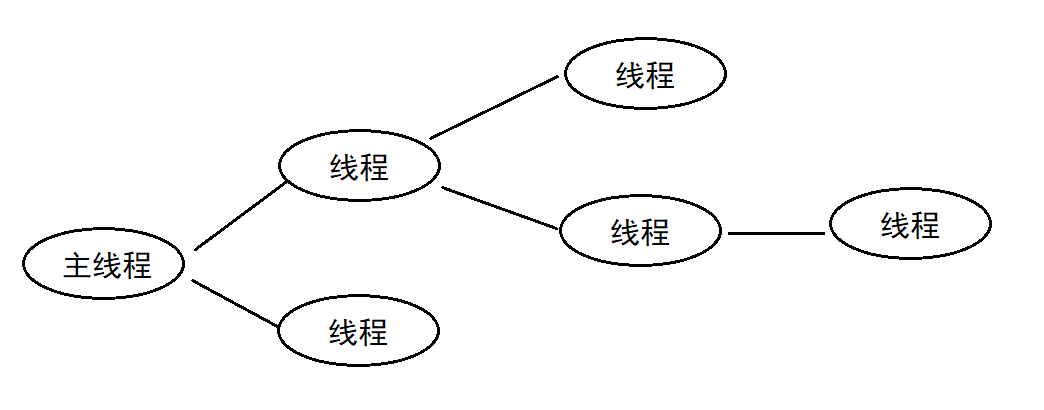
��һ���������һ��ִ��·�߾ͽ����߳�(thread)����ȷ�Ķ�����:�߳��ǡ�һ�������ڲ��Ŀ������С�
һ�н������ٶ���һ��ִ���߳�
�߳��ڽ����ڲ�����,�������ڽ��̵�ַ�ռ�������
��Linuxϵͳ��,��CPU����,������PCB��Ҫ�ȴ�ͳ�Ľ��̸���������
�����������ַ�ռ�,���Կ������̵Ĵ���Դ,��������Դ���������ÿ��ִ����,���γ����߳�ִ����
Linux���ṩ�̵߳Ĵ���
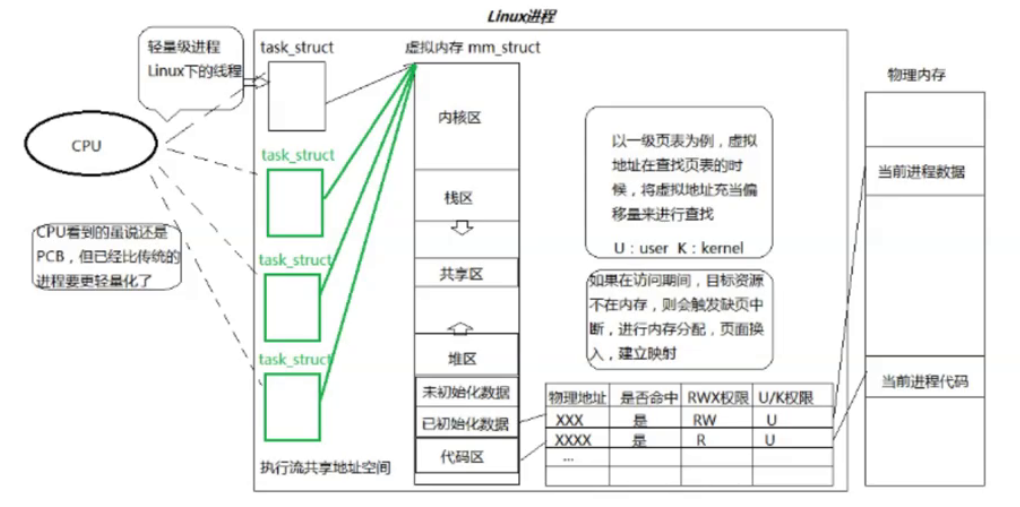
�̵߳��ŵ�
- ����һ�����̵߳Ĵ���Ҫ�ȴ���һ���½���С�ö�
- �����֮����л����,�߳�֮����л���Ҫ����ϵͳ���Ĺ���Ҫ�ٺܶ�
- �߳�ռ�õ���ԴҪ�Ƚ����ٺܶ�
- �ܳ�����öദ�����Ŀɲ�������
- �ڵȴ�����I/O����������ͬʱ,�����ִ�������ļ�������
- �����ܼ���Ӧ��,Ϊ�����ڶദ����ϵͳ������,������ֽ����߳���ʵ��
- I/O�ܼ���Ӧ��,Ϊ���������,��I/O�����ص����߳̿���ͬʱ�ȴ���ͬ��I/O����
�̵߳�ȱ��
������ʧ
һ�����ٱ��ⲿ�¼������ļ����ܼ����߳��������빲���̹߳���ͬһ������������������ܼ����̵߳������ȿ��õĴ�������,��ô���ܻ��нϴ��������ʧ,�����������ʧָ���������˶����ͬ���͵��ȿ���,�����õ���Դ���䡣��׳�Խ���
��д���߳���Ҫ��ȫ�������Ŀ���,��һ�����̳߳�����,��ʱ������ϵ�ϸƫ����������˲��ù����ı�������ɲ���Ӱ��Ŀ������Ǻܴ��,���仰˵�߳�֮����ȱ�������ġ�ȱ�����ʿ���
�����Ƿ��ʿ��ƵĻ�������,��һ���߳��е���ijЩOS������������������Ӱ�졣����Ѷ����
��д�����һ�����̳߳���ȵ��̳߳������ѵö�
�߳��쳣
- �����߳�������ֳ��㡢Ұָ���������̱߳���,����Ҳ�����ű���
- �߳��ǽ��̵�ִ�з�֧,�̳߳��쳣,�����ƽ��̳��쳣,���������źŻ���,��ֹ����,������ֹ,��
�����ڵ������߳�Ҳ���漴�˳�
�߳���;
- ������ʹ�ö��߳�,�����CPU�ܼ��ͳ����ִ��Ч��
- ������ʹ�ö��߳�,�����IO�ܼ��ͳ�����û�����(������������һ��д����һ�����ؿ�������,���Ƕ��߳����е�һ�ֱ���)
Linux����VS�߳�
���̺��߳�
��������Դ����Ļ�����λ
�߳��ǵ��ȵĻ�����λ
�̹߳�����������,��Ҳӵ���Լ���һ��������:
- �߳�ID
- һ��Ĵ���(�ص�),���Լ���Ӳ��������
- ջ(�ص�),���Լ���ջ�ռ�,���е�ջ�ռ���û���
- errno
- �ź�������
- �������ȼ�
���̵Ķ���̹߳��� ͬһ��ַ�ռ�,���Text Segment��Data Segment���ǹ�����,�������һ������,�ڸ��߳���
�����Ե���,�������һ��ȫ�ֱ���,�ڸ��߳��ж����Է��ʵ�,����֮��,���̻߳��������½�����Դ�ͻ���:
- �ļ���������
- ÿ���źŵĴ�����ʽ(SIG_ IGN��SIG_ DFL�����Զ�����źŴ�������)
- ��ǰ����Ŀ¼
- �û�id����id
���̺��̵߳Ĺ�ϵ����ͼ:
���ڽ����̵߳�����
��ο���֮ǰѧϰ�ĵ�����?����һ���߳�ִ�����Ľ���
Linux�߳̿���
POSIX�߳̿�
- ���߳��йصĺ���������һ��������ϵ��,����������������ֶ����ԡ�pthread_����ͷ��
- Ҫʹ����Щ������,Ҫͨ������ͷ�ļ�<pthread.h>
- ������Щ�̺߳�����ʱҪʹ�ñ���������ġ�-lpthread��ѡ��
�����߳�
����:����һ���µ��߳�
ԭ��
int pthread_create(pthread_t *thread, const pthread_attr_t *attr, void *(*start_routine)
(void*), void *arg);
����
thread:�����߳�ID
attr:�����̵߳�����,attrΪNULL��ʾʹ��Ĭ������
start_routine:�Ǹ�����ָ��,�߳�������Ҫִ�еĺ���
arg:�����߳���������start_routine�IJ���
����ֵ:�ɹ�����0;ʧ�ܷ��ش�����
������:
- ��ͳ��һЩ������,�ɹ�����0,ʧ�ܷ���-1,���Ҷ�ȫ�ֱ���errno��ֵ��ָʾ����
- pthreads��������ʱ��������ȫ�ֱ���errno(��������POSIX������������)�����ǽ��������ͨ������ֵ����
- pthreadsͬ��Ҳ�ṩ���߳��ڵ�errno����,��֧������ʹ��errno�Ĵ��롣����pthreads�����Ĵ���,����ͨ������ֵ�ж�,��Ϊ��ȡ����ֵҪ�ȶ�ȡ�߳��ڵ�errno�����Ŀ�����С
#include<stdio.h>
#include<pthread.h>
#include<stdlib.h>
#include<unistd.h>
void* pthread_handler(void *arg)
{
//�߳�1
while (1)
{
printf("I am thread 1\n");
sleep(1);
}
}
int main()
{
pthread_t tid;
int ret;
//�����߳�
ret = pthread_create(&tid, NULL, pthread_handler, NULL);
if (ret < 0)
{
perror("pthread_creat");
exit(1);
}
//���߳�
while (1)
{
printf("I am main thread\n");
sleep(1);
}
return 0;
}
���ɿ�ִ���ļ�ʱ,Ҫ��-lpthreadѡ��,Ҳ����д�� -pthread,�����Ƽ���Ҫ�ñ�����֪������ʹ�õ����ĸ�����Ŀ⡣
Ϊʲô����-I��-Lѡ����
��Ϊ��ͷ�ļ��Ϳ��·����ϵͳĬ��·����
���:
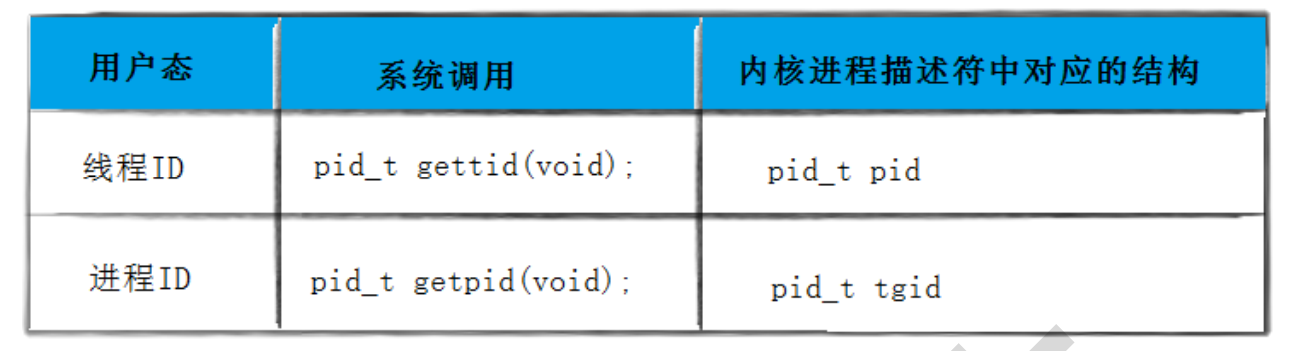
����ID���߳�ID
- ��Linux��,Ŀǰ���߳�ʵ����Native POSIX Thread Libaray,���NPTL��������ʵ����,�߳��ֱ���Ϊ���� ������(Light Weighted Process),ÿһ���û�̬���߳�,���ں��ж���Ӧһ������ʵ��,Ҳӵ���Լ��Ľ���������(task_struct�ṹ��)��
- û���߳�֮ǰ,һ�����̶�Ӧ�ں����һ������������,��Ӧһ������ID�����������̸߳���֮��,��������˱仯,һ���û������¹�ϽN���û�̬�߳�,ÿ���߳���Ϊһ�������ĵ���ʵ�����ں�̬�����Լ��Ľ���������,���̺��ں˵�������һ���Ӿͱ����1:N��ϵ,POSIX����Ҫ������ڵ������̵߳���getpid����ʱ������ͬ�Ľ���ID,��ν������������?
- Linux�ں��������߳���ĸ���
ͼ�е�tgid,������Thread Group ID,��ֵ��Ӧ�����û�����Ľ���ID ,gettid���Ի�ȡ��ǰ�̵߳�id
���ڽ��ܵ��߳�ID,��ͬ��pthread_t���͵��߳�ID,�ͽ���IDһ��,�߳�ID��pid_t���͵ı���,����������Ψһ��ʶ�̵߳�һ�����ͱ�������β鿴һ���̵߳�ID��?
[root@localhost linux]# ps -eLf |head -1 && ps -eLf |grep a.out |grep -v grep UID PID PPID LWP C NLWP STIME TTY TIME CMD root 28543 22937 28543 0 2 15:32 pts/0 00:00:00 ./a.out root 28543 22937 28544 0 2 15:32 pts/0 00:00:00 ./a.outps�����е�-Lѡ��,����ʾ������Ϣ:
LWP:�߳�ID,��gettid()ϵͳ���õķ���ֵ��
NLWP:�߳������̵߳ĸ���
���Կ�������a.out�����Ƕ��̵߳�,����IDΪ28543,��������2���߳�,�߳�ID(LWP��ID)�ֱ�Ϊ28543,28544

Linux�ṩ��gettidϵͳ�������������߳�ID,����glibc��û�н���ϵͳ���÷�װ����,�ڿ��Žӿ���������Աʹ�á����ȷʵ��Ҫ����߳�ID,���Բ������·���: #include <sys/syscall.h> pid_t tid; tid = syscall(SYS_gettid);
��������Կ���,a.out���̵�IDΪ28543,������һ���̵߳�IDҲ��28543,�ⲻ���ɺϡ��߳����ڵĵ�һ���߳�,���û�̬����Ϊ���߳�(main thread),���ں��б���Ϊgroup leader,�ں��ڴ�����һ���߳�ʱ,�Ὣ�߳����ID��ֵ���óɵ�һ���̵߳��߳�ID,group_leaderָ����ָ������,�����̵߳Ľ����������������߳����ڴ���һ���߳�ID���ڽ���ID,�����̼߳�Ϊ�߳�������߳�
/* �߳���ID�����߳�ID,group_leaderָ������ */ p->tgid = p->pid; p->group_leader = p; INIT_LIST_HEAD(&p->thread_group);�����߳��������̵߳�ID�����ں˸������,���߳���ID���Ǻ����̵߳��߳���IDһ��,���������߳�ֱ�Ӵ����߳�,���Ǵ����������߳��ٴδ����߳�,����������
if ( clone_flags & CLONE_THREAD ) p->tgid = current->tgid; if ( clone_flags & CLONE_THREAD ) { P->group_lead = current->group_leader; list_add_tail_rcu(&p->thread_group, &p->group_leader->thread_group); }ǿ��һ��,�̺߳ͽ��̲�һ��,�����и����̵ĸ���,�����߳�������,���е��̶߳��ǶԵȹ�ϵ
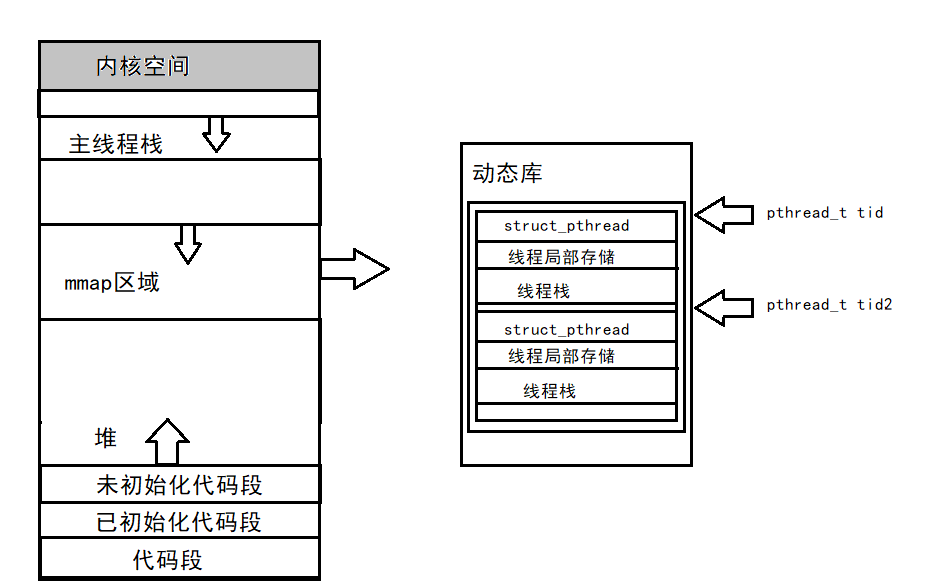
�߳�ID�����̵�ַ�ռ䲼��
pthread_ create���������һ���߳�ID,����ڵ�һ������ָ��ĵ�ַ�С����߳�ID��ǰ��˵���߳�ID����
һ���¡�ǰ�潲���߳�ID���ڽ��̵��ȵķ��롣��Ϊ�߳�������������,�Dz���ϵͳ����������С��λ,������Ҫ һ����ֵ��Ψһ��ʾ���̡߳�
pthread_ create������һ������ָ��һ�������ڴ浥Ԫ,���ڴ浥Ԫ�ĵ�ַ��Ϊ�´����̵߳��߳�ID,���� NPTL�߳̿�ķ��롣�߳̿�ĺ�������,���Ǹ��ݸ��߳�ID�������̵߳ġ�
�߳̿�NPTL�ṩ��pthread_ self����,���Ի���߳�������ID:
pthread_t pthread_self(void);pthread_t������ʲô������?ȡ����ʵ�֡�����LinuxĿǰʵ�ֵ�NPTLʵ�ֶ���,pthread_t���͵��߳�ID,���ʾ���һ�����̵�ַ�ռ��ϵ�һ����ַ�� Ҳ���Ƕ�Ӧ��ͼ��ÿһ���ṹ��pthread���ڴ����ʼ��ַ��
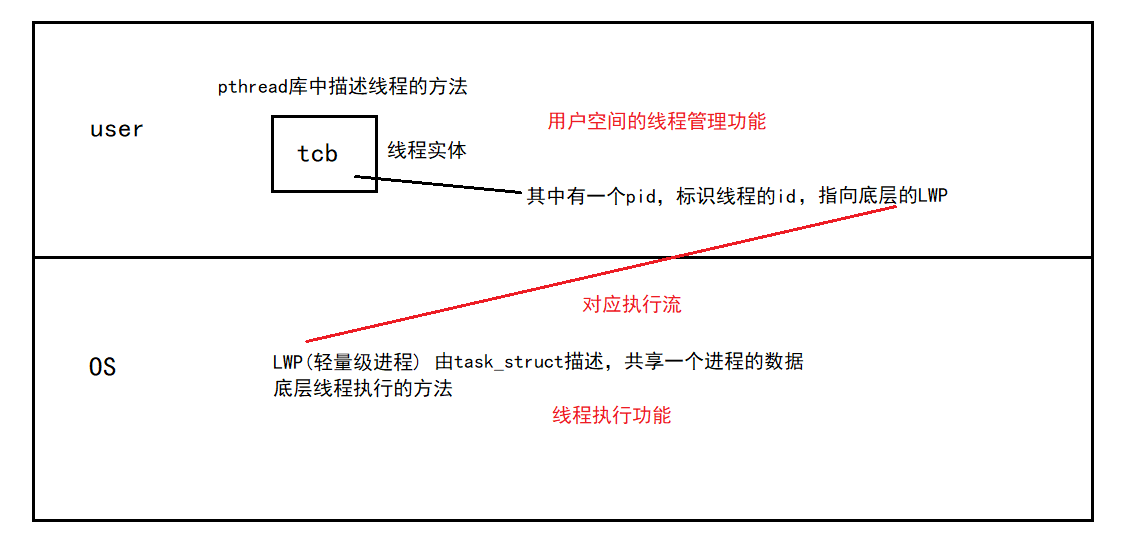
��ΪLinux���ᴴ���߳�,�����߳����û�����������, �ں����ɵײ��LWP(ִ����)ִ��
pthread���Ȼ�������߳�,��Ҫ��������߳�:����(�ṹ��TCB),��֯��
TCB����һ��pid���ݱ�ʶ�̵߳�id,ָ������������(LWP),LWP����������̵߳�ִ�й��ܡ�
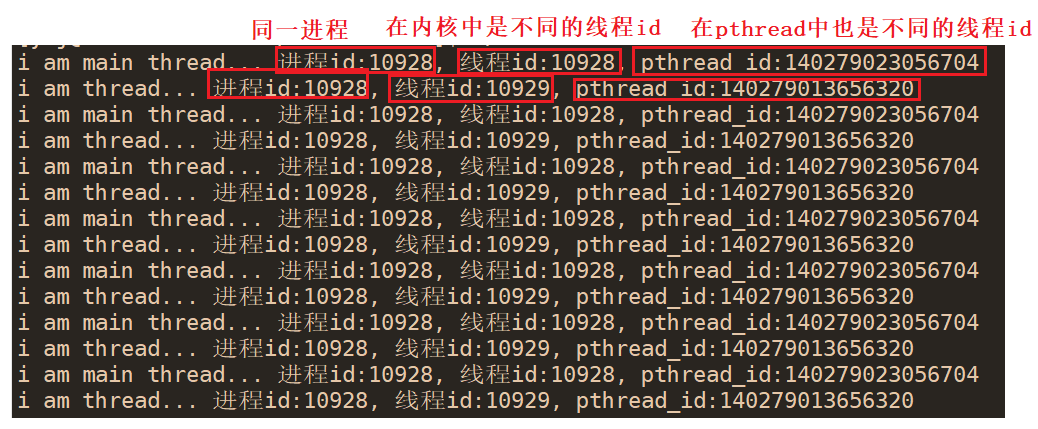
����id,�ں��߳�id,pthread�߳�id��ӡ:
#include <stdio.h>
#include <pthread.h>
#include <unistd.h>
#include <sys/syscall.h>
void* handler(void* arg)
{
while (1)
{
printf("i am thread... ����id:%d, �߳�id:%ld, pthread_id:%ld\n", getpid(), syscall(SYS_gettid), pthread_self());
sleep(1);
}
}
int main()
{
pthread_t tid;
int ret = 0;
ret = pthread_create(&tid, NULL, handler, NULL);
if (ret < 0)
{
perror("pthread_create error!");
return 1;
}
//���߳�
while (1)
{
printf("i am main thread... ����id:%d, �߳�id:%ld, pthread_id:%ld\n", getpid(), syscall(SYS_gettid), pthread_self());
sleep(1);
}
return 0;
}
�̵߳ȴ� Ϊʲô��Ҫ�̵߳ȴ�?
- �Ѿ��˳����߳�,��ռ�û�б��ͷ�,��Ȼ�ڽ��̵ĵ�ַ�ռ���,��������ƽ�ʬ���̵Ľ����
- �����µ��̲߳��Ḵ�øղ��˳��̵߳ĵ�ַ�ռ�
����:�ȴ��߳̽���
ԭ��
int pthread_join(pthread_t thread, void **value_ptr);
����
thread:�߳�ID
value_ptr:��ָ��һ��ָ��,ָ��ָ���̵߳ķ���ֵ
����ֵ:�ɹ�����0;ʧ�ܷ��ش�����
���øú������߳̽�����ȴ�,ֱ��idΪthread���߳���ֹ��thread�߳��Բ�ͬ�ķ�����ֹ,ͨ��pthread_join�õ�����ֹ״̬�Dz�ͬ��,�ܽ�����:
- ���thread�߳�ͨ��return����,value_ ptr��ָ��ĵ�Ԫ���ŵ���thread�̺߳����ķ���ֵ��
- ���thread�̱߳�����̵߳���pthread_ cancel�쳣��ֹ��,value_ ptr��ָ��ĵ�Ԫ���ŵ��dz���PTHREAD_CANCELED(ֵΪ-1)��
- ���thread�߳����Լ�����pthread_exit��ֹ��,value_ptr��ָ��ĵ�Ԫ��ŵ��Ǵ���pthread_exit�IJ�����
- �����thread�̵߳���ֹ״̬������Ȥ,���Դ�NULL��value_ ptr����

#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <pthread.h>
void *thread1(void *arg)
{
printf("thread 1 returning ... \n");
int *p = (int*)malloc(sizeof(int));
*p = 1;
return (void*)p;
}
void *thread2(void *arg)
{
printf("thread 2 exiting ...\n");
int *p = (int*)malloc(sizeof(int));
*p = 2;
pthread_exit((void*)p);
}
void *thread3(void *arg)
{
while ( 1 )
{
printf("thread 3 is running ...\n");
sleep(1);
}
return NULL;
}
int main( void)
{
pthread_t tid;
void *ret;
// thread 1 return
pthread_create(&tid, NULL, thread1, NULL);
pthread_join(tid, &ret);
printf("thread return, thread id %X, return code:%d\n", tid, *(int*)ret);
free(ret);
// thread 2 exit
pthread_create(&tid, NULL, thread2, NULL);
pthread_join(tid, &ret);
printf("thread return, thread id %X, return code:%d\n", tid, *(int*)ret);
free(ret);
// thread 3 cancel by other
pthread_create(&tid, NULL, thread3, NULL);
sleep(3);
pthread_cancel(tid);
pthread_join(tid, &ret);
if ( ret == PTHREAD_CANCELED )
printf("thread return, thread id %X, return code:PTHREAD_CANCELED\n", tid);
else
printf("thread return, thread id %X, return code:NULL\n", tid);
}
����:
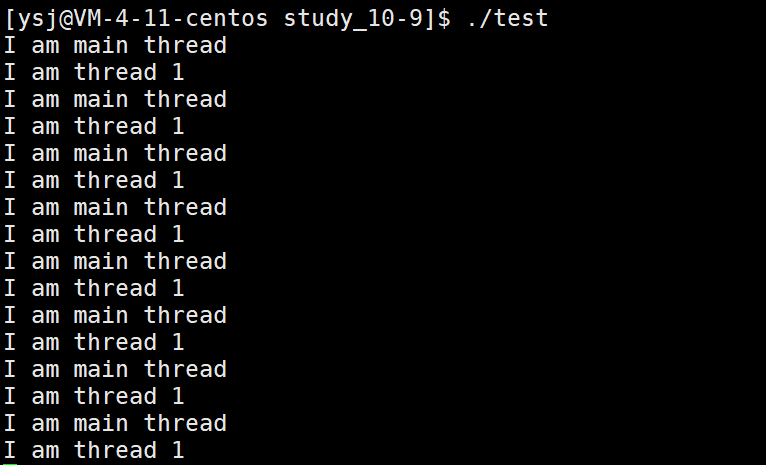
[root@localhost linux]# ./a.out
thread 1 returning ...
thread return, thread id 5AA79700, return code:1
thread 2 exiting ...
thread return, thread id 5AA79700, return code:2
thread 3 is running ...
thread 3 is running ...
thread 3 is running ...
thread return, thread id 5AA79700, return code:PTHREAD_CANCELED
�߳���ֹ
���ֻ��Ҫ��ֹij���̶߳�����ֹ��������,���������ַ���:
- ���̺߳���return�����ַ��������̲߳�����,��main����return�൱�ڵ���exit��
- �߳̿��Ե���pthread_ exit��ֹ�Լ�������߳�ֱ�ӵ���exit����,��ʹ���������˳�,����exit��ֹ���ǽ���
- һ���߳̿��Ե���pthread_ cancel��ֹͬһ�����е���һ���̡߳�
ע��:�̵߳��˳�ֻ����ִ�н��������ȷ,��Ϊ���߳��쳣�˳�ʱ,����Ҳ�˳��ˡ�
pthread_exit����
����:�߳���ֹ
ԭ��
void pthread_exit(void *value_ptr);
����
value_ptr:value_ptr����Ҫָ��һ���ֲ�������һ���ǽ����ǿתΪָ��,�ڶ�ȡ�˳���Ϣʱ��ǿתΪint/long����
����ֵ:����ֵ,������һ��,�߳̽�����ʱ�������ص����ĵ�����(����)
��Ҫע��,pthread_exit����return���ص�ָ����ָ����ڴ浥Ԫ������ȫ�ֵĻ�������malloc�����,�������̺߳���
��ջ�Ϸ���,��Ϊ�������̵߳õ��������ָ��ʱ�̺߳����Ѿ��˳��ˡ�
ʹ��ʾ��:
#include<stdio.h>
#include<pthread.h>
void* handle(void*arg)
{
int i = 0;
while(1)
{
if (5 == i)
break;
sleep(1);
printf("this is a thread: %d\n", pthread_self());
++i;
}
pthread_exit((void*) 10);//�����̵߳��˳���Ϊ10
}
int main()
{
pthread_t tid;
pthread_create(&tid, NULL, handle, NULL);
void*ptr = NULL;
pthread_join(tid, &ptr);//���̵߳ȴ����߳�
//��ӡ�˳���
printf("exit code:%d\n", (long long)ptr);
return 0;
}
���:

pthread_cancel����
����:ȡ��һ��ִ���е��߳�
ԭ��
int pthread_cancel(pthread_t thread);
����
thread:�߳�ID
����ֵ:�ɹ�����0;ʧ�ܷ��ش�����
��ȡ�����̻߳᷵�ؽ���PTHREAD_CANCELED(ֵΪ-1)���ظ��ȴ������߳�(�ȴ��������ͽ�)
��һ����ֻ�����߳�ȡ��,Ҳ��������������ȡ��,��Ȼ,Ҳ������ɱ(�Լ�ȡ���Լ�,������Ϊ�����)
ʾ��:
#include<stdio.h>
#include<pthread.h>
void* handle(void*arg)
{
int i = 0;
while(1)
{
//if (5 == i)
// break;
sleep(1);
printf("this is a thread: %d\n", pthread_self());
++i;
}
//pthread_exit((void*) 10);
}
int main()
{
pthread_t tid;
pthread_create(&tid, NULL, handle, NULL);
sleep(10);
//���̵߳�10s��ȡ�����߳�
pthread_cancel(tid);
void*ptr = NULL;
//��ȡ�˳���
pthread_join(tid, &ptr);
printf("exit code:%d\n", (long long)ptr);
return 0;
}
���:

ע��:���̵߳���pthread_cancel����, �����̵߳�״̬�����ΪZ, �����̲߳���Ӱ��
�����߳�
- Ĭ�������,�´������߳���joinable��,�߳��˳���,��Ҫ�������pthread_join����,�������ͷ���Դ,�Ӷ����ϵͳй©��
- ����������̵߳ķ���ֵ,join��һ�ָ���,���ʱ��,���ǿ��Ը���ϵͳ,���߳��˳�ʱ,�Զ��ͷ��߳���Դ��
int pthread_detach(pthread_t thread);
�������߳����������̶߳�Ŀ���߳̽��з���,Ҳ�������߳��Լ�����:
pthread_detach(pthread_self());
joinable�ͷ����dz�ͻ��,һ���̲߳��ܼ���joinable���Ƿ����
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <pthread.h>
void *thread_run( void * arg )
{
//�Լ�����
pthread_detach(pthread_self());
printf("%s\n", (char*)arg);
return NULL;
}
int main( void )
{
pthread_t tid;
if ( pthread_create(&tid, NULL, thread_run, "thread1 run...") != 0 ) //�����߳�
{
printf("create thread error\n");
return 1;
}
int ret = 0;
sleep(1);//����Ҫ,Ҫ���߳��ȷ���,�ٵȴ�
if ( pthread_join(tid, NULL ) == 0 )
{
printf("pthread wait success\n");
ret = 0;
}
else
{
printf("pthread wait failed\n");
ret = 1;
}
return ret;
}
ע��:���������̱߳�����,���̻߳��ǻ����,Ҳ���ǽ��̻��ǻ�������ꡣ
Linux�̻߳���
�����̼߳�Ļ�����ر�������
- �ٽ���Դ:���߳�ִ����ͬʱ��������Դ�ͽ����ٽ���Դ ,��һЩ��Դ��Ȼ�ǹ����ĵ����ᱻ����
- �ٽ���:ÿ���߳��ڲ�,�����ٽ���Դ�Ĵ���,�ͽ����ٽ���
- ����:�κ�ʱ��,���Ᵽ֤����ֻ��һ��ִ���������ٽ���,�����ٽ���Դ,ͨ�����ٽ���Դ�𱣻�����
- ԭ����(�����������ʵ��):���ᱻ�κε��Ȼ��ƴ�ϵIJ���,�ò���ֻ����̬,Ҫô���,Ҫôδ���
������mutex
- �����,�߳�ʹ�õ����ݶ��Ǿֲ�����,�����ĵ�ַ�ռ����߳�ջ�ռ���,�������,�������������߳�,�����߳���������ֱ�����
- ����ʱ��,�ܶ��������Ҫ���̼߳乲��,�����ı�����Ϊ��������,����ͨ�����ݵĹ���,����߳�֮��Ľ�����
- ����̲߳����ز�����������,�����һЩ����
��������Ҫ����,�߳�֮��Ĵ�������ݶ��ǹ�����,��ͬ�ڽ�����дʱ����,����һ���߳���������,�����߳̿�������ͬһ������,��˻�ȡ������Ҳ�DZ��ĵġ�
// �����������������������Ʊϵͳ����
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <pthread.h>
int ticket = 100;
void *get_ticket(void *arg)
{
int id = (int)arg;
while (1)
{
if ( ticket > 0 )
{
usleep(1000);
printf("thread %d sells ticket:%d\n", id, ticket);
ticket--;
}
else
{
break;
}
}
}
int main( void )
{
//ѭ����������
pthread_t arr[4];
int i = 0;
for (; i < 4; ++i)//�����ĸ��߳�
{
//arr+i����ÿ��Ԫ�صĵ�ַ,���Բ�����ȡ��ַ
pthread_create(arr + i, NULL, get_ticket, (void*)i);
}
//��Ʊ�ȴ�
for (i = 0; i < 4; ++i)
{
pthread_join(arr[i], NULL);
}
return 0;
}
һ��ִ�н��:
thread 4 sells ticket:100
...
thread 4 sells ticket:1
thread 2 sells ticket:0
thread 1 sells ticket:-1
thread 3 sells ticket:-2
Ϊʲô�����������ȡ���?
- if ����ж�����Ϊ���Ժ�,������Բ������л��������߳�
- usleep���ģ������ҵ��Ĺ���,�����������ҵ�������,�����кܶ���̻߳����ô����
--ticket���������Ͳ���һ��ԭ�Ӳ���
ticket�C�ĵײ���ʵ��:
//ȡ��ticket--���ֵĻ�����
objdump -d a.out > test.objdump
152 40064b: 8b 05 e3 04 20 00 mov 0x2004e3(%rip),%eax # 600b34 <ticket>
153 400651: 83 e8 01 sub $0x1,%eax
154 400654: 89 05 da 04 20 00 mov %eax,0x2004da(%rip) # 600b34 <ticket>
--����������ԭ�Ӳ���,���Ƕ�Ӧ�������ָ��:
- load:����������ticket���ڴ���ص��Ĵ�����c
- update: ���¼Ĵ��������ֵ,ִ��-1����
- store:����ֵ�ӼĴ���д�ع�������ticket���ڴ��ַ
���,���������ͬʱ����ifʱ,����ticket�C,�����ʱticketΪ1,��ij���̶߳���C��,ticket��Ϊ0��,�������̻߳���if����,���ǻ����ticket�C,���һ���Ʊ�ɹ�,������ʹ��ticketΪ0ʱ,���Ѿ�������Ʊ��,�������Ƕ����˼��Ų����ڵ�Ʊ��
Ҫ�����������,��Ҫ��������:
- �������Ҫ�л�����Ϊ:����������ٽ���ִ��ʱ,�����������߳̽�����ٽ�����
- �������߳�ͬʱҪ��ִ���ٽ����Ĵ���,�����ٽ���û���߳���ִ��,��ôֻ������һ���߳̽�����ٽ�����
- ����̲߳����ٽ�����ִ��,��ô���̲߳�����ֹ�����߳̽����ٽ�����
Ҫ����������,�����Ͼ�����Ҫһ������Linux���ṩ��������л�����
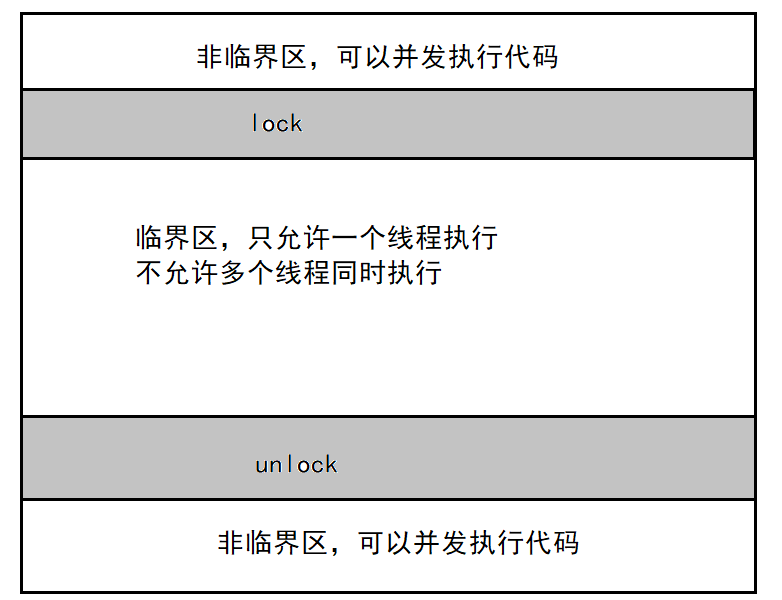
�������Ľӿ�
��ʼ��������
��ʼ�������������ַ���:
����1,��̬����:
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER����2,��̬����:
int pthread_mutex_init(pthread_mutex_t *restrict mutex, const pthread_mutexattr_t* restrict attr); ����: mutex:Ҫ��ʼ���Ļ����� attr:NULL,��������
���ٻ�����
���ٻ�������Ҫע��:
- ʹ��PTHREAD_ MUTEX_ INITIALIZER��ʼ���Ļ���������Ҫ����
- ��Ҫ����һ���Ѿ������Ļ�����
- �Ѿ����ٵĻ�����,Ҫȷ�����治�����߳��ٳ��Լ���
int pthread_mutex_destroy(pthread_mutex_t *mutex);
�����������ͽ���
int pthread_mutex_lock(pthread_mutex_t *mutex);
int pthread_mutex_unlock(pthread_mutex_t *mutex);
����ֵ:�ɹ�����0,ʧ�ܷ��ش����ź�
����pthread_ lock ʱ,���ܻ������������:
- ����������δ��״̬,�ú����Ὣ����������,ͬʱ���سɹ�
- ����������ʱ,�����߳��Ѿ�����������,���ߴ��������߳�ͬʱ���뻥����,��û�о�����������,��ôpthread_ lock���û���������(ִ����������),�ȴ�������������
�Ľ��������Ʊϵͳ:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <pthread.h>
#include <sched.h>
int ticket = 10000;
pthread_mutex_t mutex;
void *get_ticket(void *arg)
{
usleep(1000);
int num = (int)arg;
while (1)
{
pthread_mutex_lock(&mutex);
if ( ticket > 0 )
{
usleep(1000);
printf("thread:%d sells ticket:%d\n", num + 1, ticket);
ticket--;
pthread_mutex_unlock(&mutex);
}
else
{
pthread_mutex_unlock(&mutex);
break;
}
}
}
int main( void )
{
//���ij�ʼ��
pthread_mutex_init(&mutex, NULL);
//ѭ����������
pthread_t arr[4];
int i = 0;
for (; i < 4; ++i)
{
//arr+i����ÿ��Ԫ�صĵ�ַ,���Բ�����ȡ��ַ
pthread_create(arr + i, NULL, get_ticket, (void *)i);
}
//��Ʊ�ȴ�
for (i = 0; i < 4; ++i)
{
pthread_join(arr[i], NULL);
}
//������
pthread_mutex_destroy(&mutex);
}
������߳��Ѿ����������,�ڼ��������߳���������,�����벻���ġ�����,���߳̾�Ҫ��������״̬��
���������IJ���:������/�̶߳�Ӧ��PCBͶ�뵽�ȴ�������,��R״̬��ΪS״̬��������,һ���Ի���һ���߳���������
mutex������
��POSIX����,Ҫ������,����mutex��һ���ṹ��,�����������������:1.int lock 2.wait_queue��
lock���DZ�ʾ��ǰ���Ƿ�ռ�á�0��ʾû�б�ռ��,1��ʾ��ռ�á�
����һ���߳�ռ������,�����߳��������������,��Ҫ����ȴ�����,Ҳ����wait_queue��
֮ǰ��ѧ��pthread_mutex_init���ǽ�lock��Ϊ0,wait_queue��һ��headָ��,��headָ����ΪNULL��pthread_mutex_lock���ǽ�lock��Ϊ1,pthread_mutex_unlock���ǽ�lock��Ϊ0
�������ܱ�֤һ��ֻ��һ���߳̽����ٽ���,�����ٽ���Դ,����ǻ��⡣
������ʵ��ԭ��̽��
������˼��һ������:��һ���߳�ִ���ٽ�������ʱ(�Ѿ�ռ������),�߳�ʱ��Ƭ����,���Ǹ��̱߳��л���CPU��ͣ����,������Ӱ����̵߳�����������?
��Ӱ��,��Ϊ�ٽ���Դ�Ѿ�����������,��ʹ��û������,�����߳�Ҳ��������Щ�ٽ���Դ��
�������������,����Ѿ���ʶ��������i++����++i������ԭ�ӵ�,�п��ܻ�������һ��������
Ϊ��ʵ�ֻ���������,�������ϵ�ṹ���ṩ��swap��exchangeָ��,��ָ��������ǰѼĴ������ڴ浥Ԫ�������ཻ��,����ֻ��һ��ָ��,��֤��ԭ����,��ʹ�Ƕദ����ƽ̨,�����ڴ����������Ҳ���Ⱥ�,һ���������ϵĽ���ָ��ִ��ʱ��һ���������Ľ���ָ��ֻ�ܵȴ��������ڡ� �������ǰ�lock��unlock��α�����һ��

lock:
movb $0, %al
xchgb %al, mutex
if (al�Ĵ��������� > 0)
{
return 0;
}
else
{
����ȴ�;
goto lock;
}
unlock:
movb $1, mutex
���ѵȴ�Mutex���߳�
�Ըö�α���������:
����������һ���߳�A,�������һ���ٽ���Դ����,����ִ�� movb $0, %al,al�����ڸ��̵߳ļĴ���,��ֵ0����üĴ�����,Ȼ��ִ�� xchgb %al, mutex,���Ĵ���al�е�������mutex(һ������,��������˵��lock)�е����ݽ���,mutex�е�ֵĬ��Ϊ1,������,mutex�е�ֵ�ͱ����0,%al�е�ֵ�ͱ����1����ʱ,�߳�A��ʱ��Ƭ����,Ҫ�л����߳�B����,�߳�A�˳�ʱ,��CPU�������߳�A�ļĴ�������(����������)��Ҫ������,��ע��,mutex����������������,�����ڴ��е����ݡ��߳�B����ʱ,ҲҪ����ͬһ���ٽ���Դ����,����ִ�� movb $0, %al,��0ֵ�ŵ��Ĵ���al��,ע��,����al���߳�B����ʱ������B��,�����ı�����ǽ���/�߳�����ʱ��ʹ�üĴ����е�ֵ,���л��߳�/����ʱ,��Щ�Ĵ����������Ա�ʹ��,���Ե��´��߳�A������ʱ,��Щ�����ֻᱻ���ص���Ӧ�ļĴ����С����Ե��߳�Bִ���� movb $0, %al��,��Ҫִ�� xchgb %al, mutex��,��ʱmutex��ֵ��0,��Ĵ���%al��������0,���Խ���������ж�ʱ,�����else,�Ӷ�����ȴ�����ʱ�߳�A�ӵȴ������г���,����������������ݷ��ص�%al��,����%al�о���1��,��������,��if��ʼ,����if,�ɹ���������
ͨ������Ĺ���,������ʶ��
- ����������,Ϊ1��mutexֻ��һ��
- exchangeһ���������˼Ĵ������ڴ����ݵĽ���
- ����pthread_mutex_lock�Ǿ���ԭ���Ե�
��Ȼ,����Ҳһ���Ǿ���ԭ���Ե�,��Ϊֻ���Ѿ��������ɹ����̲߳��н�����Ȩ��,�����̲߳���ִ��unlock��
�������������ݵĴ��:
��������߳�A��BΪ��,�߳�A��B�ֱ��������Լ��Ľṹ��TSS,���д���Ŷ�Ӧ���мĴ����ı�������һ���߳�/����ʱ��Ƭ�����˳�����ʱ,��ǰ�Ѿ�ռ�õļĴ�����ֵ���Ӧ�ŵ��ýṹ����,�´�����ʱ,�ٽ���Щ���ݷ����Ӧ�ļĴ����������С�

������VS�̰߳�ȫ
����
- �̰߳�ȫ:����̲߳���ͬһ�δ���ʱ,������ֲ�ͬ�Ľ����������ȫ�ֱ������߾�̬�������в���,����û���������������,����ָ����⡣
- ����:ͬһ����������ͬ��ִ��������,��ǰһ�����̻�û��ִ����,����������ִ�����ٴν���,���dz�֮Ϊ���롣һ������������������,���н����������κβ�ͬ�����κ�����,��ú�������Ϊ�����뺯��,����,�Dz������뺯����
�������̲߳���ȫ�����
- �����������������
- ����״̬���ű�����,״̬�����仯�ĺ���
- ����ָ��̬����ָ��ĺ���
- �����̲߳���ȫ�����ĺ���
�������̰߳�ȫ�����
- ÿ���̶߳�ȫ�ֱ������߾�̬����ֻ�ж�ȡ��Ȩ��,��û��д���Ȩ��,һ����˵��Щ�߳��ǰ�ȫ��
- ����߽ӿڶ����߳���˵����ԭ�Ӳ���
- ����߳�֮����л����ᵼ�¸ýӿڵ�ִ�н�����ڶ�����
����������������
- ������malloc/free����,��Ϊmalloc��������ȫ�������������ѵ�
- �����˱�I/O�⺯��,��I/O��ĺܶ�ʵ�ֶ��Բ�������ķ�ʽʹ��ȫ�����ݽṹ
- �����뺯������ʹ���˾�̬�����ݽṹ
��������������
- ��ʹ��ȫ�ֱ�����̬����
- ��ʹ��malloc����new���ٳ��Ŀռ�
- �����ò������뺯��
- �����ؾ�̬��ȫ������,�������ݶ��к����ĵ������ṩ
- ʹ�ñ�������,����ͨ������ȫ�����ݵı��ؿ���������ȫ������
���������̰߳�ȫ��ϵ
- �����ǿ������,�Ǿ����̰߳�ȫ��
- �����Dz��������,�ǾͲ����ɶ���߳�ʹ��,�п��������̰߳�ȫ����
- ���һ����������ȫ�ֱ���,��ô��������Ȳ����̰߳�ȫҲ���ǿ�����ġ�
���������̰߳�ȫ����
- �����뺯�����̰߳�ȫ������һ��
- �̰߳�ȫ��һ���ǿ������,�������뺯����һ�����̰߳�ȫ�ġ�
- ��������ٽ���Դ�ķ��ʼ�����,������������̰߳�ȫ��,�����������뺯��������δ�ͷ�����������,����Dz��������
����
������ָ��һ������еĸ������̾�ռ�в����ͷŵ���Դ,���������뱻����������ռ�����ͷŵ���Դ�����ڵ�һ�����õȴ�״̬��
Ҳ�����߳�Aռ����һ����Դ��������,�߳�Bռ��������һ����ԴҲ������,��ʱ�߳�A���߳�B����������Է��Ѿ�ռ�в���������Դ,��˫���ֲ����ͷ��Ѿ�ռ�е���Դ,���������߳̾ɺ��š���������ͳ�Ϊ������
�����ĸ���Ҫ����
- ��������:һ����Դÿ��ֻ�ܱ�һ��ִ����ʹ��
- �����뱣������:һ��ִ������������Դ������ʱ,���ѻ�õ���Դ���ֲ���
- ����������:һ��ִ�����ѻ�õ���Դ,��ĩʹ����֮ǰ,����ǿ�а���
- ѭ���ȴ�����:����ִ����֮���γ�һ��ͷβ��ӵ�ѭ���ȴ���Դ�Ĺ�ϵ
��������
- �ƻ��������ĸ���Ҫ����
- ����˳��һ��
- ������δ�ͷŵij���
- ��Դһ���Է���
���������㷨
��������㷨
���м��㷨
����Ȥ��ͬѧ�����Լ�ȥ�˽�һ��