―― 目录 ――
1. 需求产生背景
在项目开发中过程中,遇到了一个根据用户动态添加的日程开始时间,在该时间来临前的前半个小时给予消息提醒的需求
第一时间就想到了定时任务调度,纠结了很久最后得出这套解决方案
总共经历了三个阶段,前俩个阶段在网上是有很多资源的,最后一个阶段是在参考了某位大神之后,自己构建出来的,如下:
阶段一:固定重复定时任务
我们知道 Spring 中有一个 @Scheduled 注解,可以使用 cron 表达式实现任务定时重复执行(如每天零点执行一次),但这种方式的缺点也很明显,那就是直接在程序中写死,想要更改必须重启程序
阶段二:动态重复定时任务
而如果能够根据数据库中定义的 cron 表达式,动态改变重复执行的规则,就灵活很多了,虽然这种方法还满足不了我们的需求,但却实实在在地为下一个阶段做好了铺垫
阶段三:动态时间点定时任务
在一些情况下(如本文的需求),任务并不是定时重复执行的,而是由用户或系统生成一个一个附带时间点的任务,希望程序在规定的时间点时执行相应的任务
感谢大神:springboot动态增加删除定时任务
2. 实现思路
在阶段二中,我们可以通过修改数据库中的 cron 表达式,完成定时任务规则的修改
而 cron 表达式与时间点是可以互相转化的(周和月只能同时存在一个,取月而周不确定)
如 2022-1-31 09:30:00 可以转化为 00 30 09 31 1 ?(秒 分 时 天 月 周)
这样下来就实现了通过读取时间点来执行任务了
但由于没有书写重复执行,故该表达式执行完一次定时任务后,就不会再执行了
这时候就需要获取下一个最近的时间点,解析成 cron 表达式,来完成按照时间点序列先后执行定时任务
下一个问题是:时间点全部执行完了,但可能会有新的时间点加入
这时候就需要动态监听数据库的变化了,这里产生了两种思路:
① 使用 AOP,在插入新记录时,刷新定时任务
② 在没有任务时,将 cron 设置为定时重复执行,不断轮询数据库,直到有新数据出现就更换 cron 规则
思路一比思路二更通用且节省资源,但思路二更容易实现,且能检测到我们手动往数据库中添加的数据,这里采用思路二
所以具体的实现思路就是:
- 在 springBoot 项目启动时,为每一个用户分配一个定时任务
- 在每一个定时任务中,读取出尚未发送通知的时间点最近的一条数据
- 解析其时间点为 cron 表达式,作为下一次定时任务执行的时间
- 执行完定时任务后,将该记录标识为已通知
- 然后继续读取下一条数据并解析为 cron 表达式和执行任务
- 直到没有任务了,进行轮询,有新数据就解析为新 cron 表达式
- 有新用户注册时,为新用户动态分配一个定时任务
3. 具体实现(实战)
① 示范建表(只想看逻辑的可以跳过)
实现上述逻辑有很多建表的方式,我这里这个只作为示例拉~
-- 定时任务表
CREATE TABLE t_task (
task_id INT AUTO_INCREMENT COMMENT'任务 id' PRIMARY KEY,
group_id INT DEFAULT 1 COMMENT'任务所属组别,未指定时为默认组别',
task_code INT COMMENT'任务代码',
task_time CHAR(19) COMMENT'任务执行时间',
task_run INT DEFAULT 0 COMMENT'任务执行标识',
create_date TIMESTAMP DEFAULT CURRENT_TIMESTAMP NOT NULL COMMENT'任务创建时间'
);
-- 定时任务分组
CREATE TABLE t_group (
group_id INT AUTO_INCREMENT COMMENT '组别 id' PRIMARY KEY,
group_name VARCHAR(255) COMMENT '组别名称',
group_task INT DEFAULT 0 COMMENT '组别任务数',
create_date TIMESTAMP DEFAULT CURRENT_TIMESTAMP NOT NULL COMMENT'组别创建时间'
);
-- 默认组别
INSERT INTO t_group(group_name) VALUE('defaultGroup');
这里建立了两张表,一张任务表和一张任务分组表
一个任务分组对应了一个调度任务,一组内可以有多个任务,各参数解析如下:
task_code指定该定时任务具体需要执行哪个任务,即 Runnable 中的具体逻辑task_time指定了任务将在什么时间点执行,即在 Trigger 中用它解析成 cron 表达式task_run标识了任务的执行状态,状态的含义可以自定义,这里定义的是 0 为未执行,-1 为执行完毕,大于 0 的所有值可以标识任务的各种状态(复杂任务需要),这里就具体需求啦,一般 0 和 -1 两个状态已经够用了
用来测试的数据如下:
② 自定义任务调度器(重 - 参考与改造)
这里主要用到 add 和 remove 方法,增加和移除调度任务,规则由外部传入
具体的实现参照了前边那位大神(基本上全搬过来拉)
本质上和阶段二中使用的 taskRegistrar.addTriggerTask 是一样的,不过阶段二中这个没有提供移除任务的接口,所以该类拆开了一层封装,将实际执行任务的 SheduledFuture 提取出来了
往后我们只需要对其构成的集合进行增删,就可以实现任务的动态增加和移除了
@Component
public class MyScheduling implements SchedulingConfigurer {
/** 定时任务注册器 */
private ScheduledTaskRegistrar taskRegistrar;
private Set<ScheduledFuture<?>> scheduledFutures = null;
/** 存放所有定时任务 */
private Map<String, ScheduledFuture<?>> taskMap = new ConcurrentHashMap<>();
@Override
public void configureTasks(ScheduledTaskRegistrar taskRegistrar) {
this.taskRegistrar = taskRegistrar;
}
@SuppressWarnings("unchecked")
private Set<ScheduledFuture<?>> getScheduledFutures() {
if (scheduledFutures == null) {
try {
scheduledFutures = (Set<ScheduledFuture<?>>) getProperty(taskRegistrar, "scheduledTasks");
}
catch (NoSuchFieldException e) {
throw new SchedulingException("not found scheduledFutures field.");
}
}
return scheduledFutures;
}
/**
* 添加定时任务
* @param taskId 定时任务唯一标识
* @param runnable 定时任务执行的具体逻辑
* @param trigger 下一个定时任务执行时机的触发器
*/
public void addTriggerTask(String taskId, Runnable runnable, Trigger trigger) {
// 若定时任务已经存在,则进行覆盖操作(即先移除)
if (taskMap.containsKey(taskId)) {
removeTriggerTask(taskId);
}
// 添加定时任务
ScheduledFuture<?> schedule = Objects.requireNonNull(taskRegistrar.getScheduler()).schedule(runnable, trigger);
getScheduledFutures().add(schedule);
taskMap.put(taskId, schedule);
}
/**
* 移除定时任务
* @param taskId 定时任务 id
*/
public void removeTriggerTask(String taskId) {
ScheduledFuture<?> future = taskMap.get(taskId);
if (future != null) {
future.cancel(true);
}
taskMap.remove(taskId);
getScheduledFutures().remove(future);
}
/** 获取当前的任务总数 */
public int getTaskNum() {
return taskMap.size();
}
/** 打印当前所有任务的简略信息 */
public void printTask() {
System.out.println(taskMap.keySet());
}
/** 辅助方法 * 3,可以略过 */
public static Field findField(Class<?> clazz, String name) {
try {
return clazz.getField(name);
} catch (NoSuchFieldException ex) {
return findDeclaredField(clazz, name);
}
}
public static Field findDeclaredField(Class<?> clazz, String name) {
try {
return clazz.getDeclaredField(name);
} catch (NoSuchFieldException ex) {
if (clazz.getSuperclass() != null) {
return findDeclaredField(clazz.getSuperclass(), name);
}
return null;
}
}
public static Object getProperty(Object obj, String name) throws NoSuchFieldException {
Object value = null;
Field field = findField(obj.getClass(), name);
if (field == null) {
throw new NoSuchFieldException("no such field [" + name + "]");
}
boolean accessible = field.isAccessible();
field.setAccessible(true);
try {
value = field.get(obj);
} catch (Exception e) {
throw new RuntimeException(e);
}
field.setAccessible(accessible);
return value;
}
}
② 自定义装载任务(重 - 初始化任务调度)
这里用到了 ApplicationRunner 接口,表示在项目启动后执行该方法一次
需要它完成初始化任务调度器的任务,即为每个任务组添加任务
添加任务的逻辑也很简单,就是设置任务 id(这里为 group+组别)
然后设置具体执行逻辑 Runnable 和触发器规则 Trigger
触发器 Trigger的规则为每次获取一个 最近的尚未完成的任务
服务类很简单就不放了,实现 sql 如下:
@Select("select * from t_task where group_id = #{groupId} and task_run != -1 order by task_time limit 1")
Task getNearestTask(Integer groupId);
在获取到的任务为空时(已经没有未执行的任务了),则进行 5 秒一次的轮询,直到有新任务加入,更新 cron 重新等待执行定时任务
当获取到的任务执行时间已经过去了(即任务超时了),则立即执行该任务(尽快执行弥补),这种情况由各种意外引起如程序中断,上一个任务执行过长时间等
具体任务执行逻辑 Runnable 也很简单,其中 ScheduleTasks 是一个自定义的类,用来存放具体任务逻辑以及其对应的 taskCode,runTask 就是根据 taskCode 取执行相应的方法
这里也加了一个超时处理,当当前时间大于指定的任务时间时,立即执行
而小于时则不执行,因为轮询时总会执行 Runnable 方法,所以动态添加进来的任务可以一开始就被 Runnable 执行了,这是不对的,故多加了一个判断(读者可以把 if 判断去掉,看看会发生什么)
@Component
@Slf4j
public class TaskScheduling implements ApplicationRunner {
@Autowired
MyScheduling myScheduling;
@Autowired
GroupService groupService;
@Autowired
TaskService taskService;
@Override
public void run(ApplicationArguments args) throws Exception {
// 在项目启动后,初始化任务调度器
initTaskScheduling();
}
public void initTaskScheduling() {
// 先获取所有组别的 id
List<Integer> groupIdList = groupService.getGroupIdList();
// 为每一个组别设置任务调度
for (Integer groupId : groupIdList) {
log.info("装载任务组:" + groupId);
myScheduling.addTriggerTask("group" + groupId, getTaskRunnable(groupId), getTaskTrigger(groupId));
}
}
/** 获取指定组别所属的任务执行逻辑 */
public Runnable getTaskRunnable(Integer groupId) {
return () -> {
// 获取该组别最近的为执行的任务
Task nearestTask = taskService.getNearestTask(groupId);
// 调用任务执行方法
if (nearestTask != null && DateUtils.getTime().compareTo(nearestTask.getTaskTime()) >= 0) {
ScheduleTasks.runTask(nearestTask);
}
};
}
/** 获取指定任务组所属的触发器 */
public Trigger getTaskTrigger(Integer groupId) {
return triggerContext -> {
// 通过获取该用户最近的未完成的日程,解析出下一个通知的发送时间
String cron;
Task nearestTask = taskService.getNearestTask(groupId);
if (nearestTask != null) {
// 任务存在的话,将执行时间解析为 cron 表达式
// 如果时间已经超过了,则立即执行,否则常规解析
cron = (DateUtils.getTime().compareTo(nearestTask.getTaskTime())) >= 0 ?
"* * * * * ?" : DateUtils.parseToCron(nearestTask.getTaskTime());
log.info("解析出的 cron:" + cron);
} else {
// 暂时:如果没有了,则进行为期 5 秒的轮询
cron = "*/5 * * * * ?";
log.info("轮询中");
}
// 返回执行周期
return new CronTrigger(cron).nextExecutionTime(triggerContext);
};
}
}
④ 测试执行效果
表中的数据如下(包含一个超时任务,其他正常):

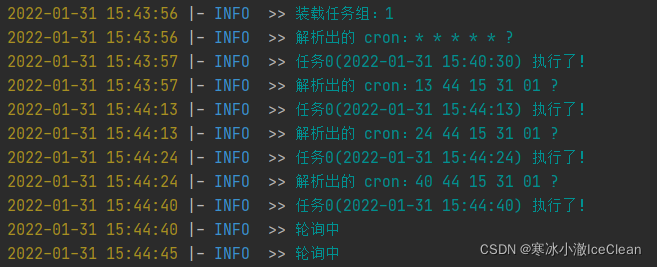
可以看到,第一条超时任务,在任务装载后就立即执行了(* * * * * ? 表示任意时刻,即立即执行)
执行完第一个任务后,第二个任务就被装载了,更新 cron 的规则,之后就在指定时间被执行了,往后依次取出任务,解析 cron,可以看到所有任务都在规定的时间被执行了!!!
等到所有任务执行完,便进入轮询状态
这时,我们再往数据库中插入一条记录:
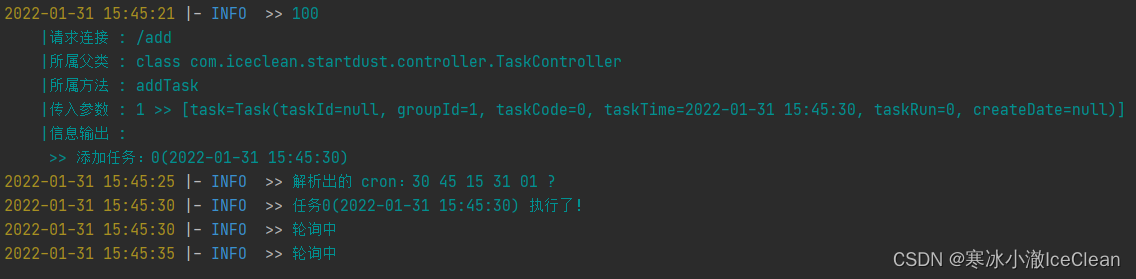
这里调用了添加任务的接口,直接往数据库中新插入数据当然也是没问题的!
可以看到新加入的任务随即就被解析了(21 秒加的,25 秒才被解析,因为轮询间隔是 5 秒)
解析完之后,也正确在相应的时间点执行了!
轮询的方法虽然存在一定的缺陷,如会导致任务超时执行(在轮询的 5 秒内需要执行),但胜在逻辑简单,而且支持直接往数据库中插入数据的监控(AOP 方式直接王数据库中添加数据是不会被检测到的,虽然实际情况直接添加的可能性也比较少)
4. 结语
这次这个逻辑的实现花了我挺长时间的,一开始是不知道有 SchedulingConfigurer 这个能动态进行任务调度的东西
后来了解到了也难以下手,因为这些模式的共同特点就是 重复,与我所需要的按时间点执行看似有很大的区别
但当思路捋清楚之后,发现这只是重复执行的一个变型而已,本质上就是通过不断改变 cron 的规则,来实现在规定的时间点上执行任务
总的来说,还是需要有前人的引导(说实话那个自定义任务调度器目前的我是写不出来的),再加上自己的思考,才能实现某些看似简单的功能
对于这次逻辑的实现还是比较满意的,对实力的提升挺有帮助
希望也对你们有帮助~(辛勤劳作大家动动手鼓励一下叭 >v<)
我依旧,守护着历代星辰(IceClean)