��ζ�λ����
- ���ü��� Reference Counting
ȱ��:�����ѭ������ - �ɴ��Է��� Tracing GC(GC Root)
������Ϊ GC Root �Ķ���
- JVM stack:Java �����ջ(ջ֡�еı��ر�����)���õĶ���
- native method stack:���ط���ջ�����õĶ���
- run-time constant:����ʱ������
- static references in method area:�������о�̬�������õĶ���
���� GC �㷨
- ������ Mark-Sweep(�����)
ȱ��:�ڴ治����,������Ƭ - �����㷨 Copying (�����,98%����Ϧ��)
�ŵ�:�ڴ�����,û����Ƭ
ȱ��:�ռ俪���� - ������� Mark-Compact(�����)
�ŵ�:û����Ƭ,���˷ѿռ�
ȱ��:Ч��ƫ��
| �㷨 | �ƶ����� | �ռ俪�� | ʱ�俪�� |
|---|---|---|---|
| Mark-Sweep | �� | ��(����Ƭ) | mark �������������������� O(L),sweep �������Ѵ�С������ O(H) |
| Mark-Compact | �� | ��(����Ƭ) | mark �������������������� O(L),compaction ���������Ĵ�С������ O(L) |
| Copying | �� | �� | �������������� O(L) |
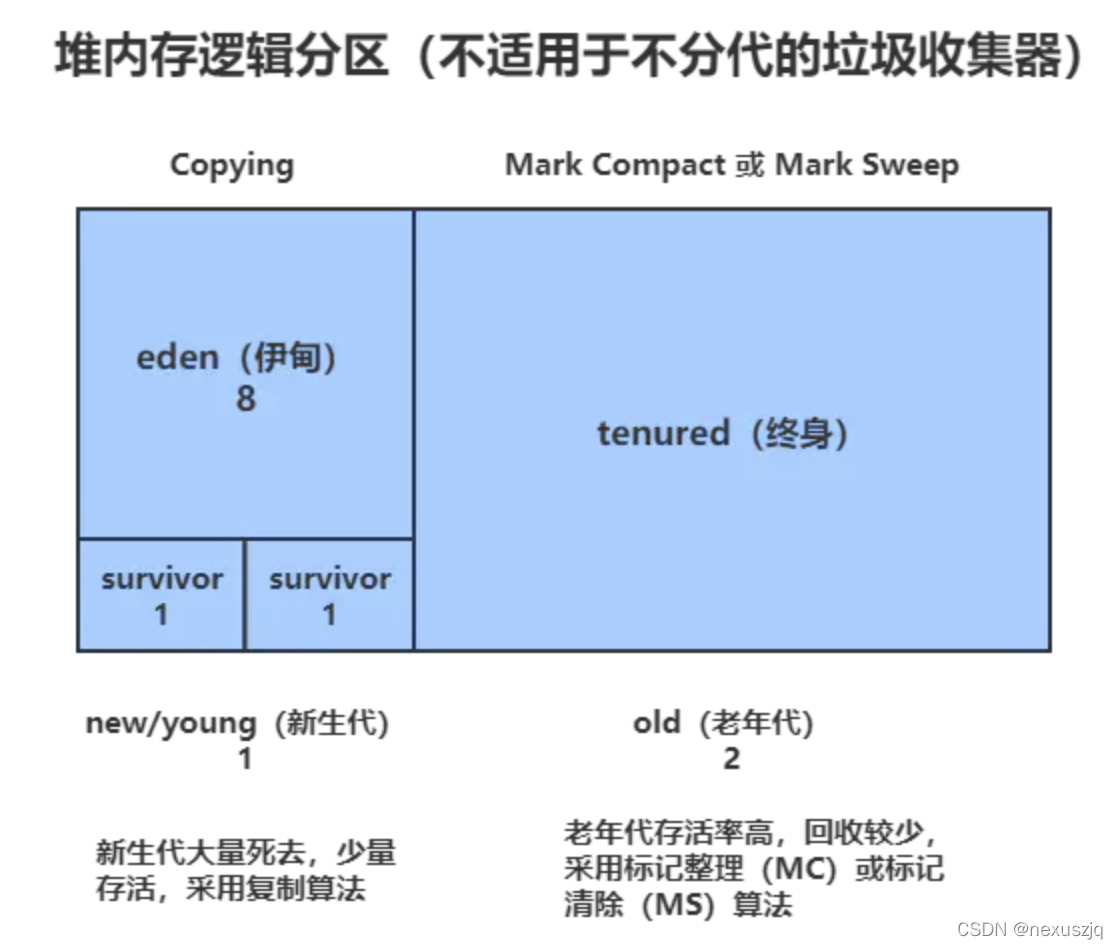
���ڴ�ִ�ģ��
������ + ����� + ���ô�(1.7) / Ԫ������(1.8) Meta Space
������ = eden + 2 * survivor
Ԫ��������С�����������ڴ�
1.7 �ַ��������������ô�,1.8 ���ڶ�
Eden : Survivor From : Survivor To = 8 : 1 : 1
������ : ����� = 1 : 2
��������չ���
- YGC(Young GC)���պ�,eden ���������ᱻ����,���Ķ����� survivor 0
- �ٴ� YGC,eden + survivor 0 ���Ķ����� survivor 1
- �ٴ� YGC,eden + survivor 1 ������ survivor 0
- ÿ������һ��,���� + 1,���䳬�� -XX:MaxTenuringThreshold ָ������,���������
(Parallel Scavenge:15,CMS:6,G1:15) - survivor װ����,���������
����ʲôʱ����������?
����ͷ mark word ��4λ�Ǽ�¼���������,4λ�����������15,Ҳ����˵�������Ϊ15
���������
��������˽���FGC(Full GC),GC������ҪĿ��:��������FGC
Minor GC = Young GC
Major GC = Full GC
java -XX:+PrintFlagsFinal:�鿴���ղ���ֵ
java -XX:+PrintFlagsInitial:�鿴Ĭ�ϲ���ֵ
java -XX:+PrintCommandLineFlags:�鿴�����в���
����������
- 1.8 Ĭ������������:Parallel Scavenge + Parallel Old
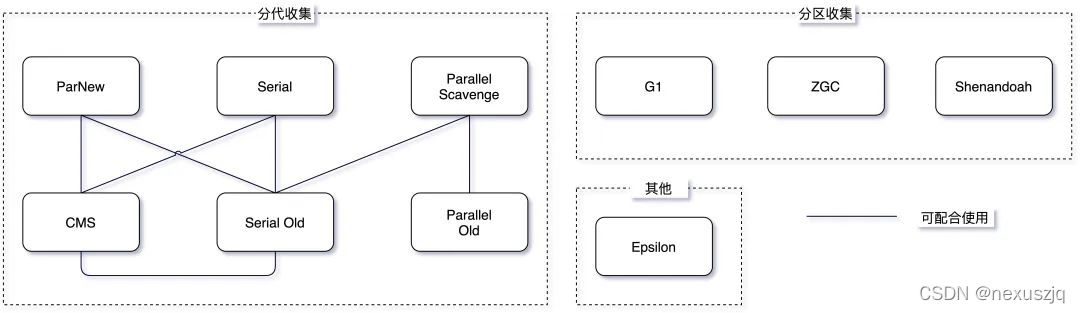
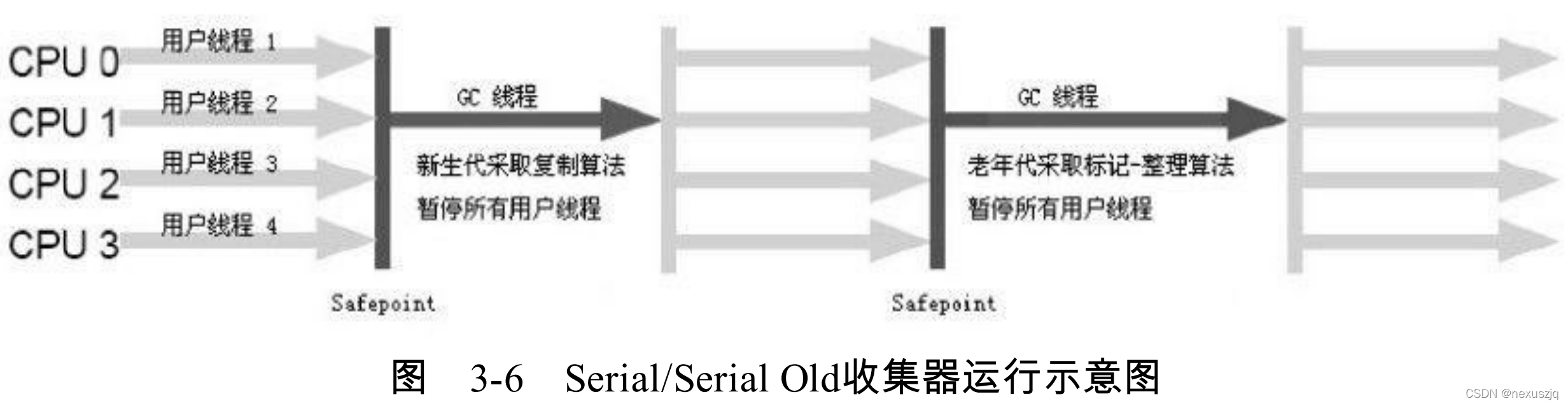
Serial Ӧ��������� ���л���
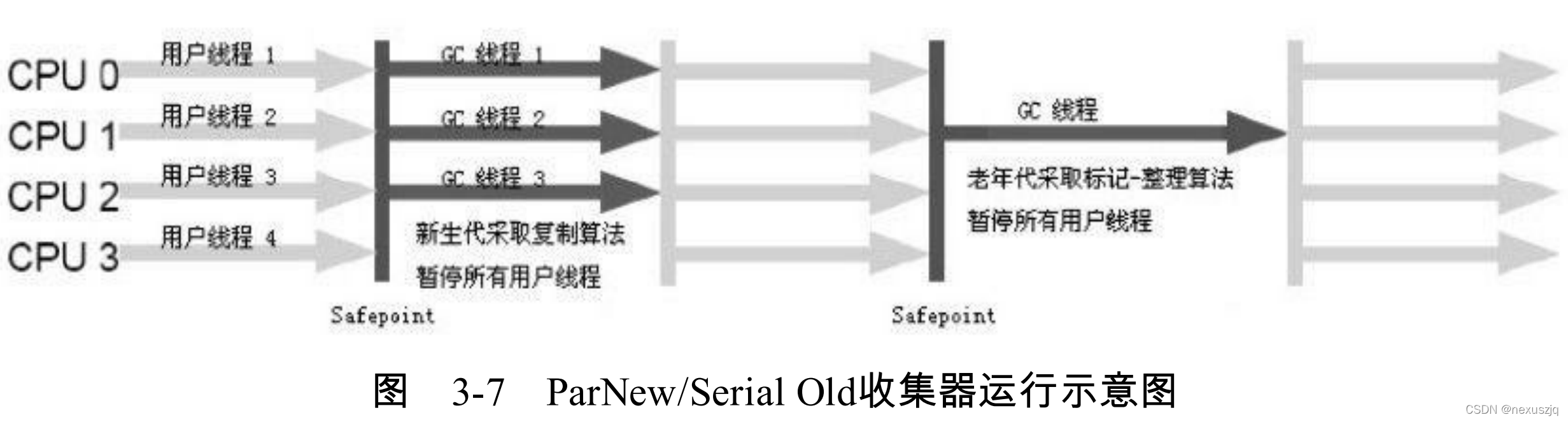
ParNew ����� ���CMS�IJ���� �����
SerialOld
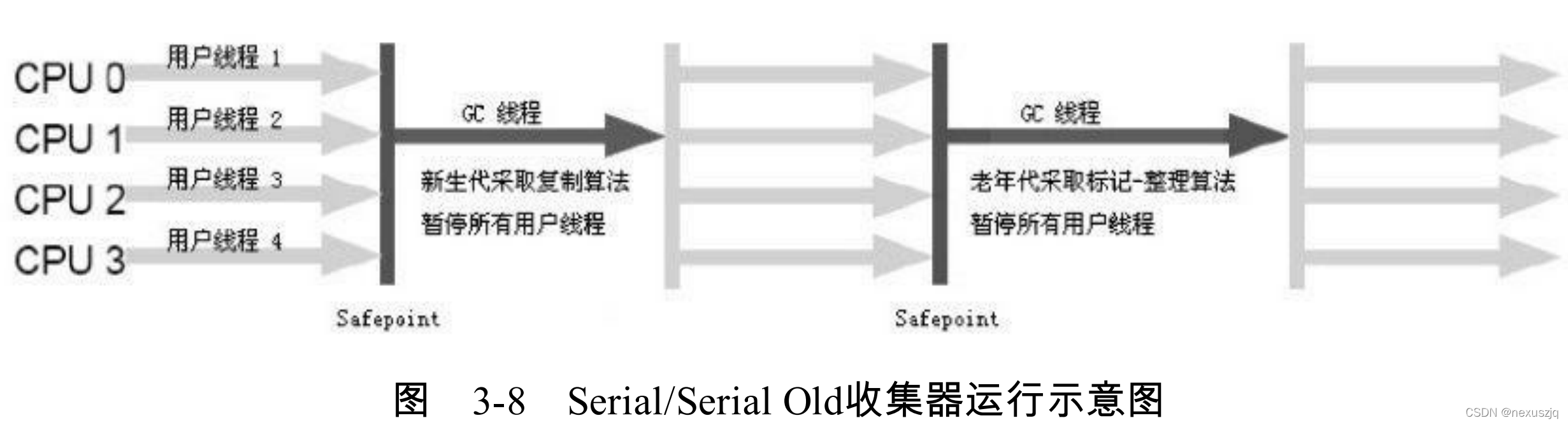
Parallel Scavenge Ӧ��������� ���л��� ����������
������ = �����û�����ʱ�� / (�����û�����ʱ�� + �����ռ�ʱ��)
ParallelOld
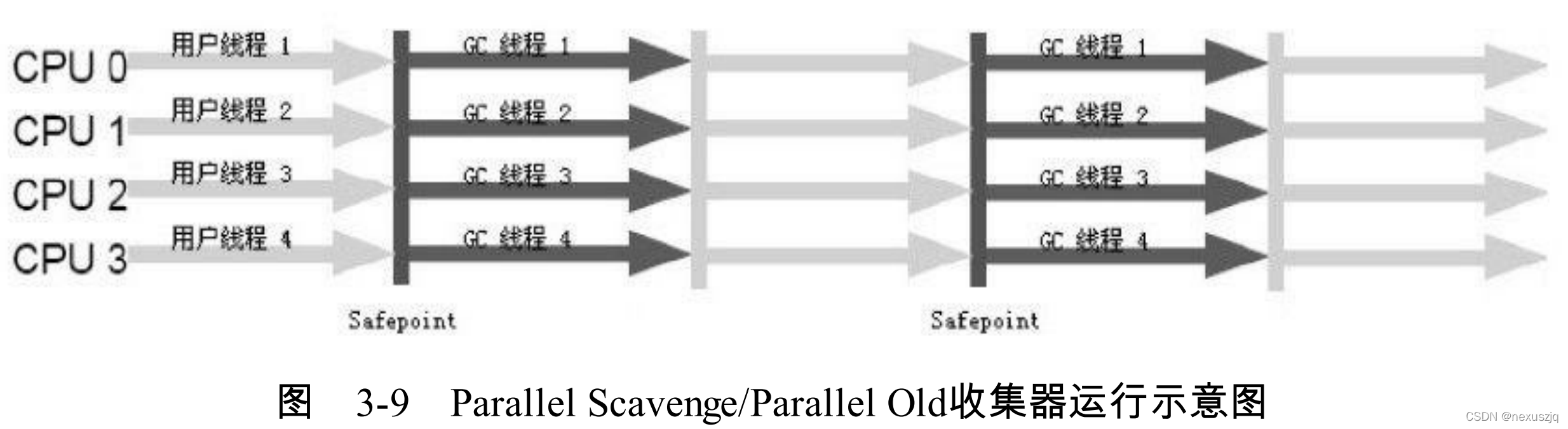
CMS ����� ����
�������պ�Ӧ�ó���ͬʱ����,����STWʱ��(���͵�200ms)
�ĸ�����
- ��ʼ���:��� GC Root ��ֱ�ӹ����Ķ���,��stw��ʱ���
- �������:
- ���±��:������������ڼ��û��������ж��仯�ı�Ǽ�¼,�� STW ��ʱ��϶�
- �������
����ȱ��
- ռ�� CPU ��Դ,Ĭ�Ͽ������������߳��� = (CPU�� + 3) / 4,4������ CPU ��ռ�ò����� 25% �� CPU ��Դ
- ��������������(�����������û������²���������,CMS �����,ֻ��������һ�� CG ������)
- ��������ʱ�û�����������,��Ҫ��һ���ֿռ乩�����ռ�ʱ�ij�������ʹ��,�������������������ȵ�������������ٴ����ռ�,1.5 Ĭ������� 68% �����ռ�,1.6 Ĭ�� 92%,Ԥ���ռ䲻������ Concurrent Mode Failure ʧ��,���ܽ���
- �������:���ʹ��� CMS ����ֵ,�CXX:CMSInitiatingOccupancyFraction 92% ���Խ������ֵ,�� CMS ����������㹻�Ŀռ�
- ���ڱ��-����㷨,�����ռ���Ƭ,-XX:+UseCMSCompactAtFullCollection �������ÿ�Ҫ FGC ǰ������Ƭ����,��ͣ��ʱ��߳� -XX:CMSFullGCsBeforeCompaction Ĭ��Ϊ0,ָ���Ǿ������ٴ� FGC �Ž���ѹ��,����Ƭ���ڴ�װ������������ʱ,��ʹ�� Serial Old ���б������
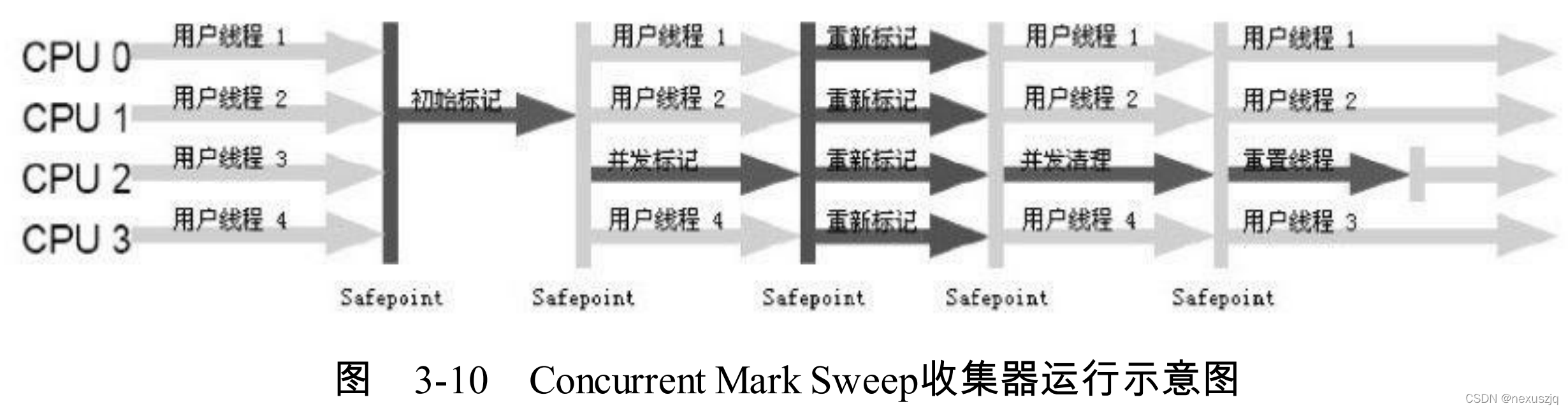
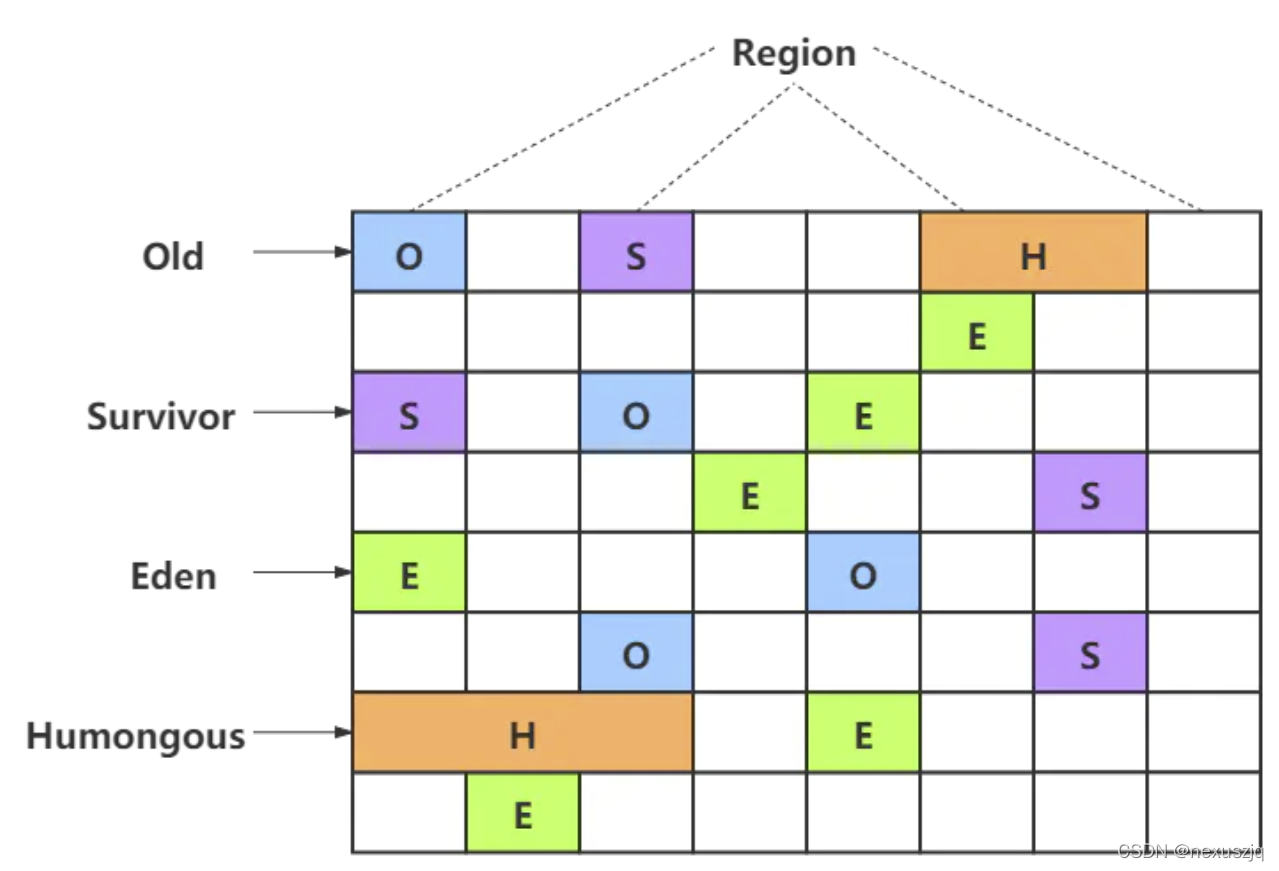
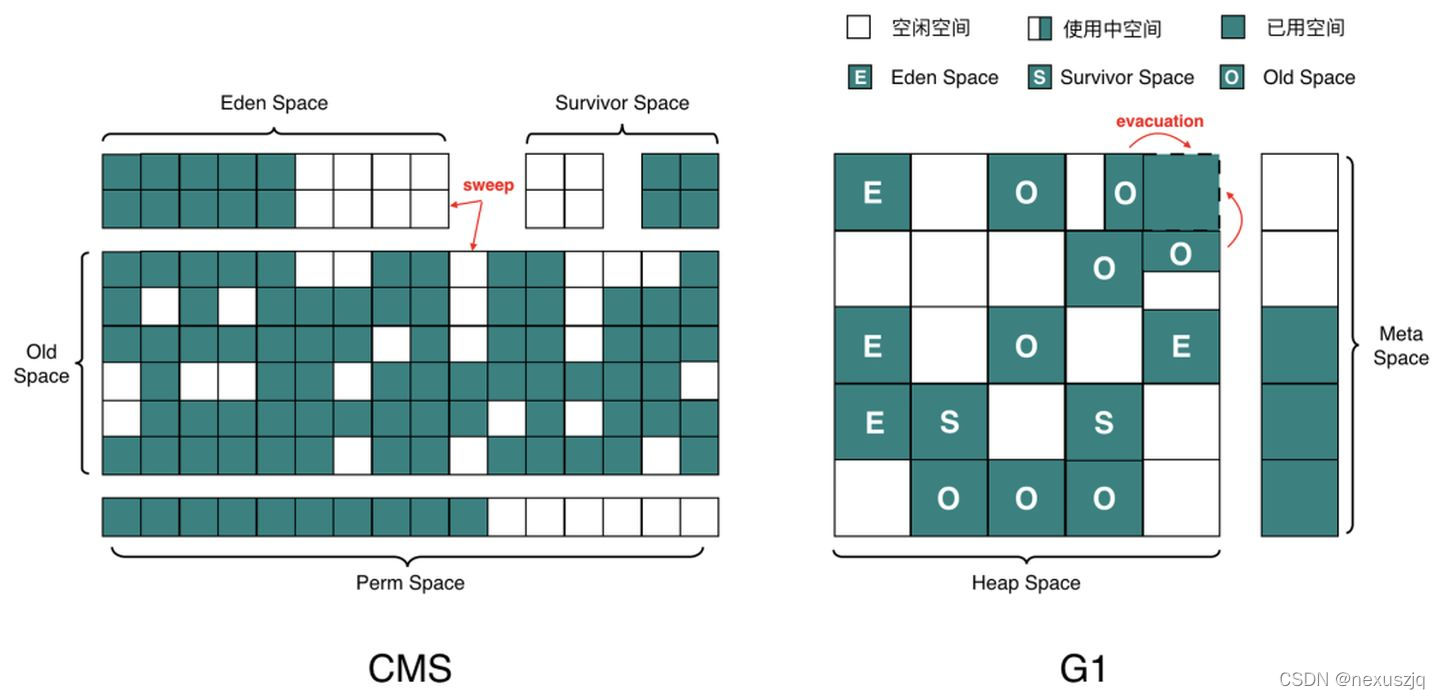
G1(10ms)���ٽ��������ִ�,�������ִ�
- ���ڴ��Ϊһ������ Region��һ�� Region(����)��������Ȼ�ִ�,��Ϊ����:Eden,Old,Survivor,Humongous(�����,���������� Region)��
- ����ÿ�������������������Ҳ�����������,������ͬһʱ��ֻ������ij������
- ��Ԥ���ͣ��(�ָ�ѳɴ�С��ȵĶ�� Region,�� Region �������ѻ���ֵ��С,ά�����ȼ�����)
- ���Ȼ����������ķ���,���ѽ��ٵ�ʱ����������Щ����������,��Ҳ���� G1 ���ֵ�����
- �ڻ���������ķ���ʱ,�ǽ����Ķ����һ��������������һ�����÷���,��������Ĺ��̾�ʵ���˾ֲ���ѹ����ÿ�������Ĵ�С�� 1M �� 32M ����,������2���ݴη���
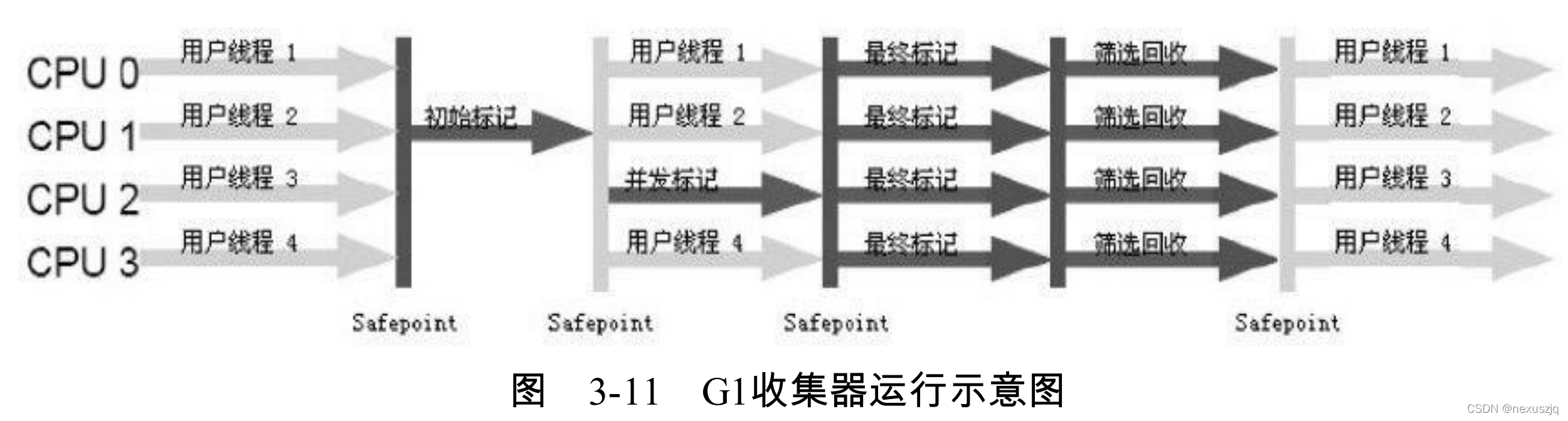
MixedGC
-XX:InitiatingHeapOccupacyPercent,Ĭ��ֵ45%,�����ڴ泬�����ֵ,����MixedGC
����ʱ�������������������ʲô��,region���˾ͻ��ա�
�ĸ�����
- ��ʼ��� STW
- �������
- ���ձ�� STW(���±��)
- ɸѡ���� STW(����)
- �� CMS �dz���,MixedGC �����ɸѡ����,���˸�ɸѡ���衣ɸѡ�����ҳ��������� region��ɸѡ�������Ƶ����� region,�ٽ�֮ǰ�� region ��ա�
CMS �� G1 �Ƚ�
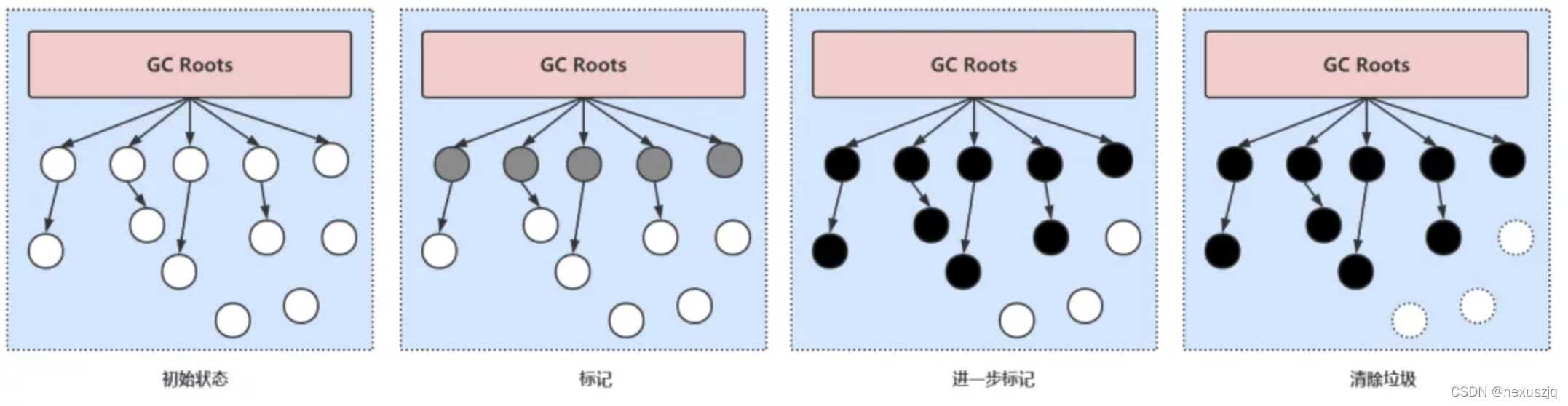
��ɫ����㷨
- ��ɫ:�ö���û�б���ǹ���(��������)
- ��ɫ:�ö����Ѿ�����ǹ���,���ö����µ�����û��ȫ������ꡣ(GC��Ҫ�Ӵ˶�����ȥѰ������)
- ��ɫ:�ö����Ѿ�����ǹ���,�Ҹö����µ�����Ҳȫ��������ǹ��ˡ�(��������Ҫ�Ķ���)
��ɫ��Ǵ�������
- ��������:������ǵĹ�����,��һ���Ѿ�����dzɺ�ɫ����ɫ�Ķ���,ͻȻ���������,���ڲ����ٶԺ�ɫ��ǹ��Ķ�������ɨ��,���Բ��ᱻ����,��ô��������ǰ�ɫ�ĵ��Dz��ᱻ���,���±��Ҳ���ܴ� GC Root ��ȥ�ҵ�,���Գ�Ϊ�˸�������,����������ϵͳ��Ӱ�첻��,������һ��GC���д������ɡ�
- ����©������(��Ҫ�Ķ�����):������ǵĹ�����,һ��ҵ���߳̽�һ��δ��ɨ����İ�ɫ����Ͽ����ó�Ϊ����(ɾ������),ͬʱ��ɫ���������˸ö���(��������)(���������Բ����Ⱥ�˳��);��Ϊ��ɫ����ĺ���Ϊ�����Զ��Ѿ�����ǹ���,���±��Ҳ����Ӻ�ɫ������ȥ��,���¸ö���������Ҫ,ȴ��Ҫ��GC���ա�
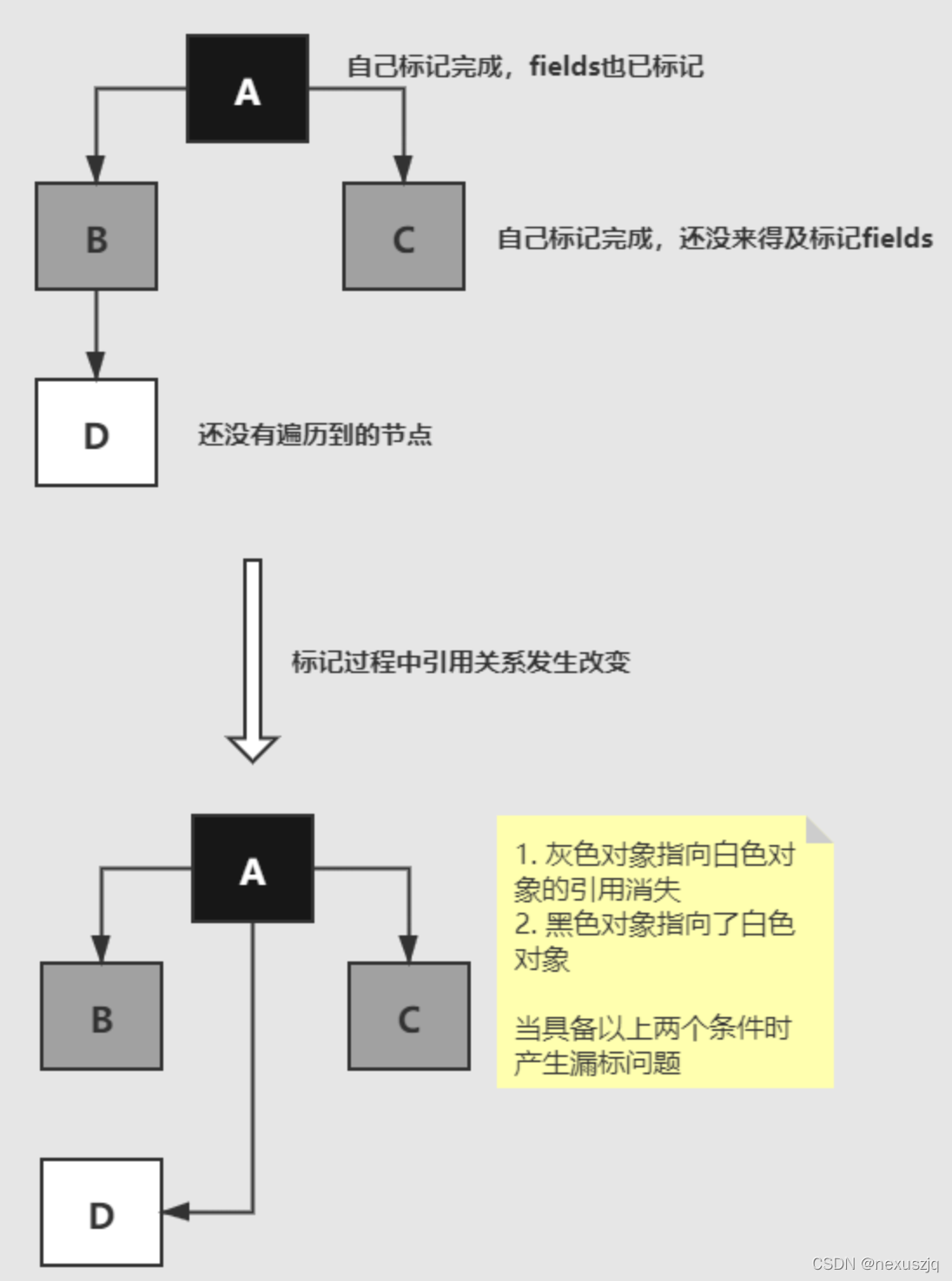
���ҽ���һ����������ͬʱ����ʱ,�����������ʧ������
- ��ֵ��ɾ����ȫ���ӻ�ɫ����ɫ�����ֱ�ӻ�������
- ��ֵ��������һ��������Ӻ�ɫ����ɫ�����������
����Ҫ���©������,������������֮һ����:
-
CMS:�������� Incremental Update,���ٺ�ָ�������,�ƻ�����2
����ɫ��������µ�ָ���ɫ��������ù�ϵʱ,������²�������ü�¼����,�ȵ�����ɨ�������,�ٽ���¼�����ù�ϵ�еĺ�ɫ����Ϊ��,����ɨ�衣
������Ϊ:��ɫ����һ������ָ���ɫ���������,���ͱ�ػ�ɫ������ -
G1:ԭʼ���� Snapshot At The Beginning SATB,��¼��ָ�����ʧ,�ƻ�����1
����ɫ����Ҫɾ��ָ���ɫ��������ù�ϵʱ,�Ͱ����Ҫɾ�������ü�¼����,����ɨ�������,�ٽ���Щ��¼�����ù�ϵ�Ļ�ɫ����Ϊ��,����ɨ��һ�顣
������Ϊ:����->����ʧʱ,Ҫ����� ���� �Ƶ� GC �Ķ�ջ,��֤���ܱ� GC ɨ�赽
ΪʲôG1����SATB������incremental update?
��Ϊ����incremental update�Ѻ�ɫ���±��Ϊ��ɫ��,֮ǰɨ����Ļ�Ҫ��ɨ��һ��,Ч��̫�͡�
Incremental Update �������©�������
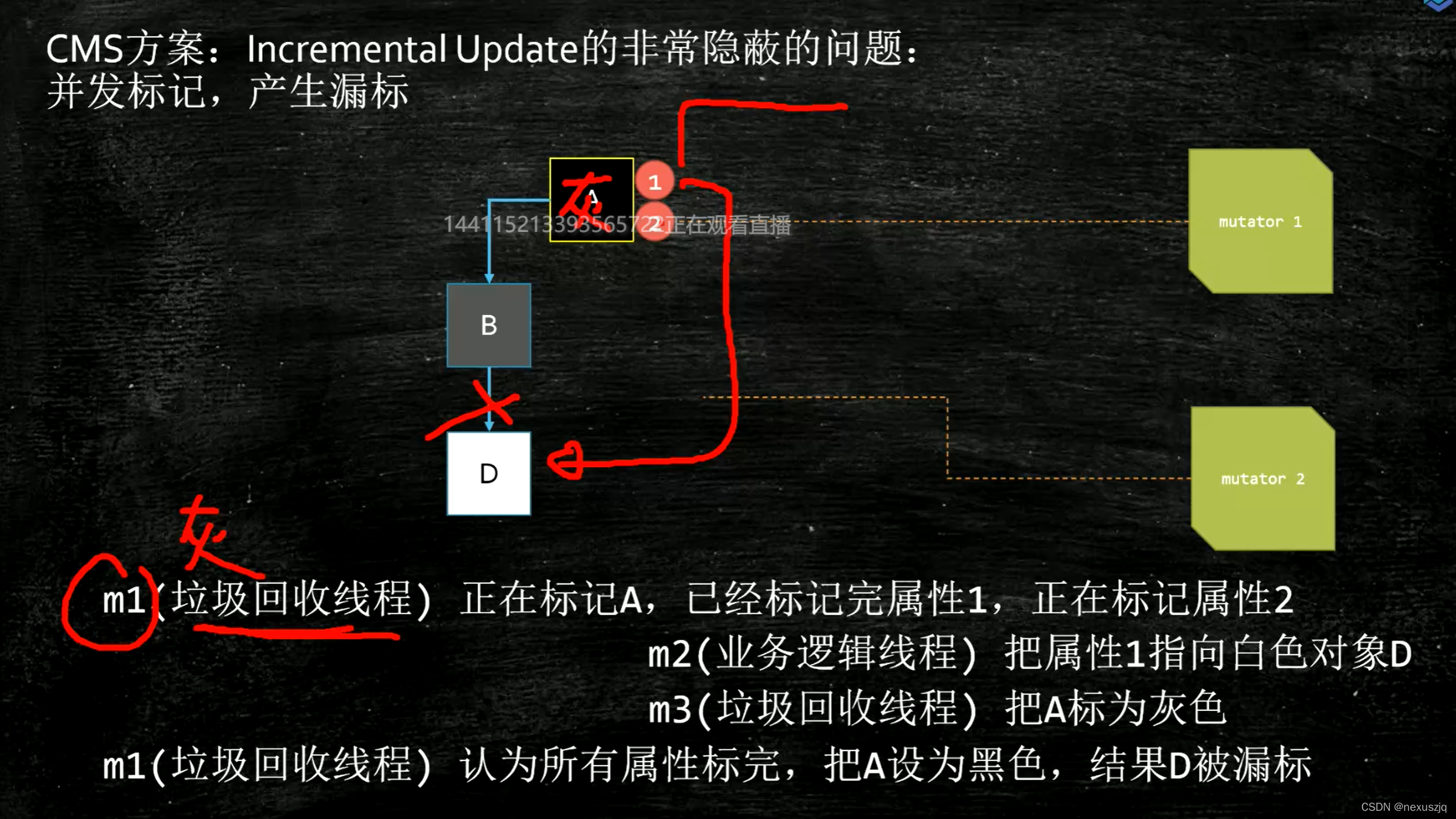
CMSͨ������ɨ��һ��������������