文章目录
前言
这篇文章讨论读写锁stampedLock。文章根据《Java并发编程的艺术》这本书以及黑马的视频 黑马多线程 做的笔记。
1. stampedLock
1. 概述
该类自 JDK 8 加入,是为了进一步优化读性能,它的特点是在使用读锁、写锁时都必须配合【戳】使用 加解读锁
long stamp = lock.readLock();
lock.unlockRead(stamp);
加解写锁
long stamp = lock.writeLock();
lock.unlockWrite(stamp);
乐观读,StampedLock 支持 tryOptimisticRead() 方法(乐观读),读取完毕后需要做一次 戳校验 如果校验通 过,表示这期间确实没有写操作,数据可以安全使用,如果校验没通过,需要重新获取读锁升级成真正的读锁,保证数据安全。
long stamp = lock.tryOptimisticRead();
// 验戳
if(!lock.validate(stamp)){
// 锁升级
}
2. 代码
提供一个 数据容器类 内部分别使用读锁保护数据的 read() 方法,写锁保护数据的 write() 方法
class DataContainerStamped {
//数据
private int data;
//StampedLock 锁
private final StampedLock lock = new StampedLock();
public DataContainerStamped(int data) {
this.data = data;
}
//读取操作
public int read(int readTime) {
//首先获取stamp
long stamp = lock.tryOptimisticRead();
log.debug("optimistic read locking...{}", stamp);
sleep(readTime);
//验证如果是有效的,证明这期间没有写操作,直接返回即可,这时还是乐观锁
if (lock.validate(stamp)) {
//就可以读到数据
log.debug("read finish...{}, data:{}", stamp, data);
return data;
}
// 否则证明已经有写锁修改过了,这里需要再次获取读锁,升级为真正的读锁
// 锁升级 - 读锁
log.debug("updating to read lock... {}", stamp);
try {
//获取stamp
stamp = lock.readLock();
log.debug("read lock {}", stamp);
sleep(readTime);
log.debug("read finish...{}, data:{}", stamp, data);
return data;
} finally {
log.debug("read unlock {}", stamp);
lock.unlockRead(stamp);
}
}
public void write(int newData) {
//获取戳
long stamp = lock.writeLock();
log.debug("write lock {}", stamp);
try {
sleep(2);
this.data = newData;
} finally {
log.debug("write unlock {}", stamp);
lock.unlockWrite(stamp);
}
}
}
1. 读读
public class TestStampedLock {
public static void main(String[] args) {
DataContainerStamped dataContainer = new DataContainerStamped(1);
new Thread(() -> {
dataContainer.read(1);
}, "t1").start();
sleep(0.5);
new Thread(() -> {
dataContainer.read(0);
}, "t2").start();
}
}
输出结果:下面结果中可以看到两个线程同时获取读锁并执行读操作,没有先后的关系。
19:09:07.857 [t1] DEBUG c.DataContainerStamped - optimistic read locking...256
19:09:08.361 [t2] DEBUG c.DataContainerStamped - optimistic read locking...256
19:09:08.362 [t2] DEBUG c.DataContainerStamped - read finish...256, data:1
19:09:08.873 [t1] DEBUG c.DataContainerStamped - read finish...256, data:1
2. 读写
public class TestStampedLock {
public static void main(String[] args) {
DataContainerStamped dataContainer = new DataContainerStamped(1);
new Thread(() -> {
dataContainer.read(1);
}, "t1").start();
sleep(0.5);
new Thread(() -> {
dataContainer.write(0);
}, "t2").start();
}
}
结果输出:一开始是读操作先睡眠一秒,在睡眠之前已经获取了戳了,在 t1 线程睡眠期间 t2 线程获取到了写锁,并将数据修改,而且戳也改成了384.此时 t1 线程醒过来校验发现戳已经被修改了,所以这时候 t1 线程会等待 t2 线程释放写锁之后去获取读锁。完成从乐观读 -> 读锁 的升级。
19:10:49.987 [t1] DEBUG c.DataContainerStamped - optimistic read locking...256
19:10:50.485 [t2] DEBUG c.DataContainerStamped - write lock 384
19:10:50.998 [t1] DEBUG c.DataContainerStamped - updating to read lock... 256
19:10:52.498 [t2] DEBUG c.DataContainerStamped - write unlock 384
19:10:52.498 [t1] DEBUG c.DataContainerStamped - read lock 513
19:10:53.508 [t1] DEBUG c.DataContainerStamped - read finish...513, data:0
19:10:53.508 [t1] DEBUG c.DataContainerStamped - read unlock 513
3. 注意
- StampedLock 不支持条件变量(await、signal 这些没法用)
- StampedLock 不支持可重入
2. Semaphore
1. 基本使用
信号量,用来限制能同时访问共享资源的线程上限。它通过协调各个线程,以保证合理的使用公共资源。
@Slf4j
public class TestSemaphore {
public static void main(String[] args) {
// 1. 创建 semaphore 对象
//这里设置上限为3,表示线程只支持三个,达到了3个线程之后这个变量就为0了
//第二个参数是表示公平非公平:其他线程来了如果是公平是不可能竞争的
//如果是非公平是可以和等待队列里面的线程竞争的
Semaphore semaphore = new Semaphore(3);
// 2. 10个线程同时运行
for (int i = 0; i < 10; i++) {
new Thread(() -> {
try {
//3. 获取许可,acquire后semaphore-1变成2
semaphore.acquire();
} catch (InterruptedException e) {
e.printStackTrace();
}
try {
log.debug("running...");
sleep(1);
log.debug("end...");
} finally {
semaphore.release();
}
}).start();
}
}
}
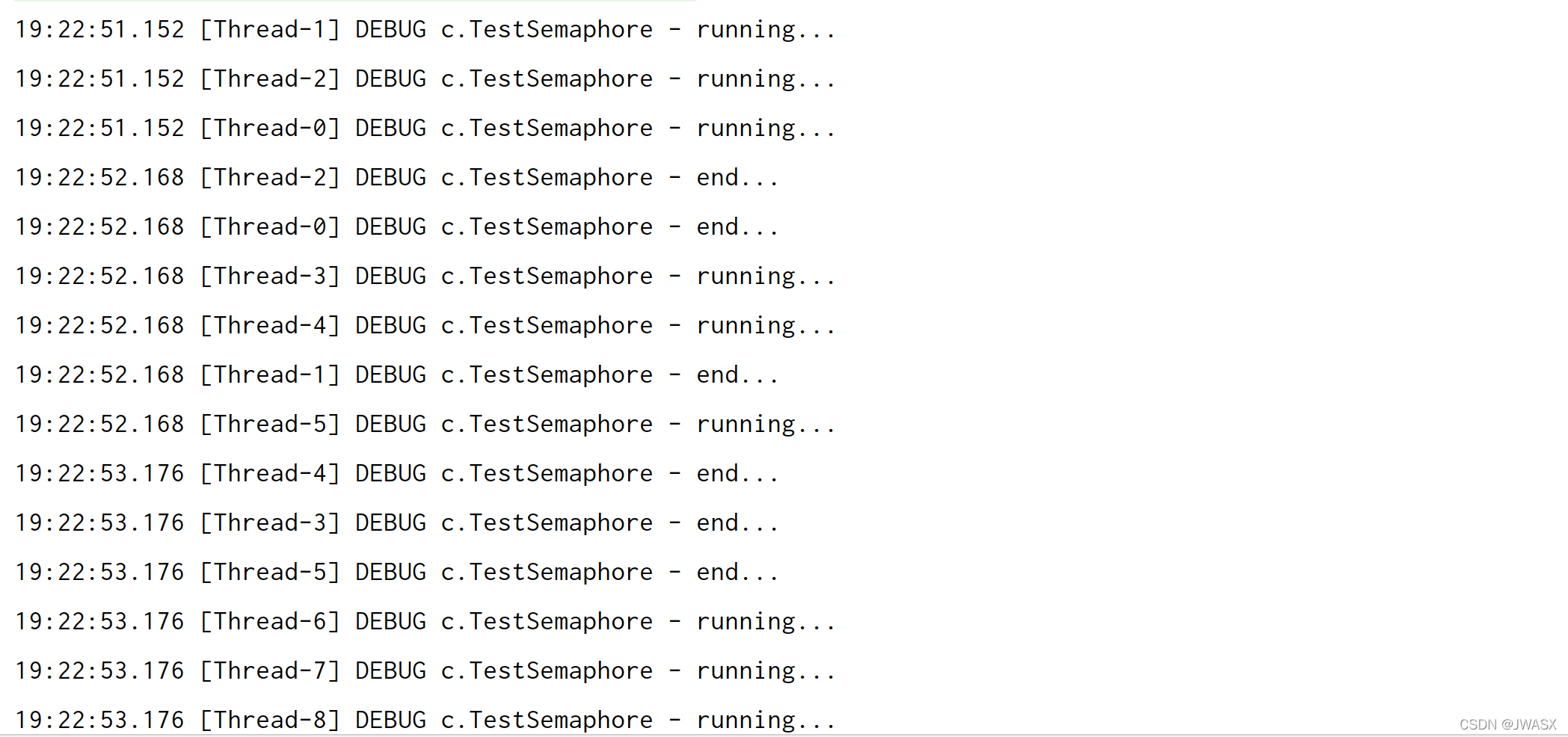
结果输出:很明显的是,首先 0,1,2三个线程先执行,然后其他线程暂停,然后线程0,1,2执行完成之后其他线程接着竞争三个名额。
2. 应用场景
Semaphore 可以用于流量控制,特别是公共资源有限的应用场景,比如数据库连接。加入有一个需求,需要读取几万个文件的数据,这属于 IO 密集型任务,我们可以启动几十个线程去读取文件,但是在读取到本地之后要写入数据库时我们就得控制连接数,否则连接数过多会报错无法获取连接。这时候就可以使用 Semaphore 来控制并发数。
- 使用 Semaphore 在高峰时让请求线程阻塞,等到高峰过去了再释放许可,当然它只适合限制单机线程数量(没有考虑分布式),并且仅仅是限制线程数而不是资源数。该处理多少资源还是得处理多少资源
- 使用 Semaphore 简单实现连接池(一个线程对应一个连接),对比享元模式下的实现(wait,notify),性能和可读性更好。
public class TestPoolSemaphore {
public static void main(String[] args) {
Pool pool = new Pool(2);
for (int i = 0; i < 5; i++) {
new Thread(() -> {
Connection conn = pool.borrow();
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
pool.free(conn);
}).start();
}
}
}
class Pool {
// 1. 连接池大小
private final int poolSize;
// 2. 连接对象数组
private Connection[] connections;
// 3. 连接状态数组 0 表示空闲, 1 表示繁忙
private AtomicIntegerArray states;
private Semaphore semaphore;
// 4. 构造方法初始化
public Pool(int poolSize) {
this.poolSize = poolSize;
// 让许可数与资源数一致,保证一个线程一个资源
this.semaphore = new Semaphore(poolSize);
this.connections = new Connection[poolSize];
this.states = new AtomicIntegerArray(new int[poolSize]);
for (int i = 0; i < poolSize; i++) {
connections[i] = new MockConnection("连接" + (i+1));
}
}
// 5. 借连接
public Connection borrow() {// t1, t2, t3
// 获取许可
try {
semaphore.acquire(); // 没有许可的线程,在此等待
} catch (InterruptedException e) {
e.printStackTrace();
}
for (int i = 0; i < poolSize; i++) {
// 获取空闲连接
if(states.get(i) == 0) {
if (states.compareAndSet(i, 0, 1)) {
log.debug("borrow {}", connections[i]);
return connections[i];
}
}
}
// 不会执行到这里,肯定能找到空闲连接的,线程数和连接数一样
return null;
}
// 6. 归还连接
public void free(Connection conn) {
for (int i = 0; i < poolSize; i++) {
if (connections[i] == conn) {
states.set(i, 0);
log.debug("free {}", conn);
//归还许可
semaphore.release();
break;
}
}
}
}
class MockConnection implements Connection{}
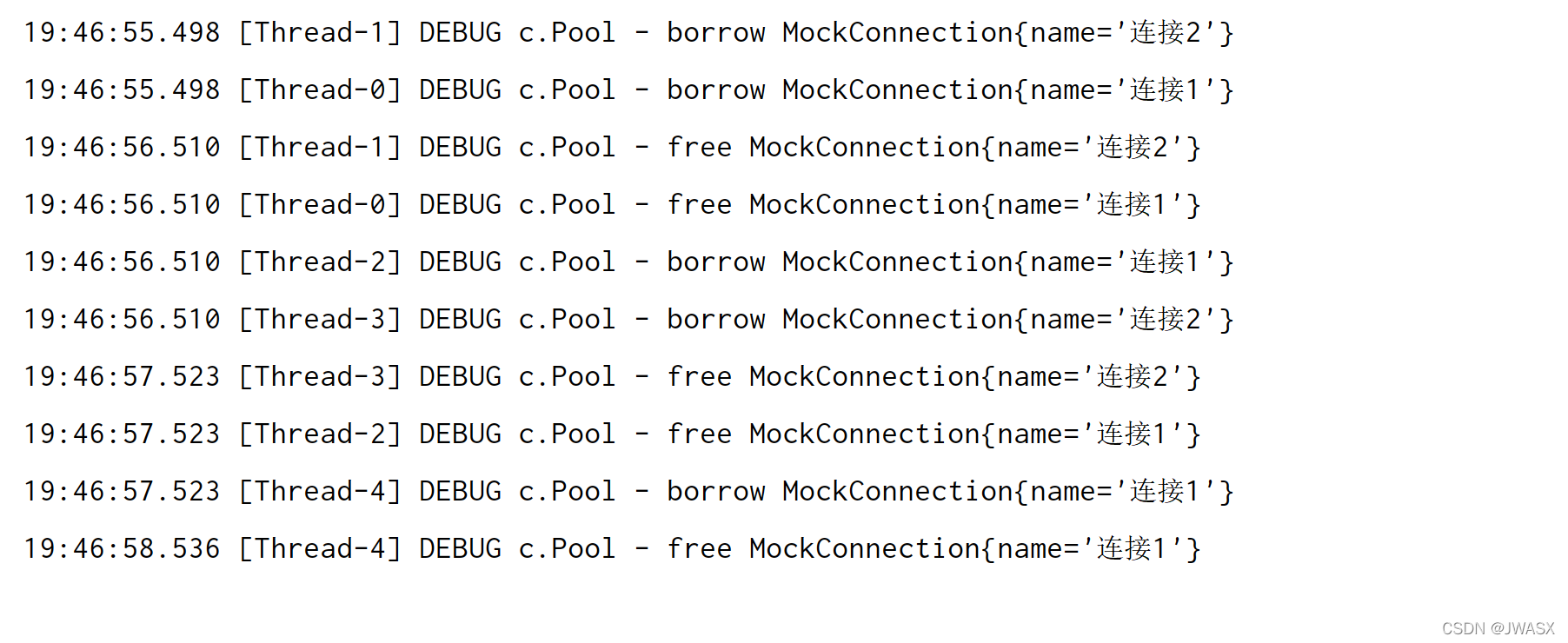
输出结果:可以看到,这里我们设置了大小为2之后,每次获取都是两个两个获取的。其他线程就在等着,下面就以这个为例,讲讲原理
3. 原理
Semaphore 有点像一个停车场,permits 就好像停车位数量,当线程获得了 permits 就像是获得了停车位,然后停车场显示空余车位减一
1、刚开始,假设permits(state)为 3,这时 5 个线程来获取资源,下面时构造方法的调用链
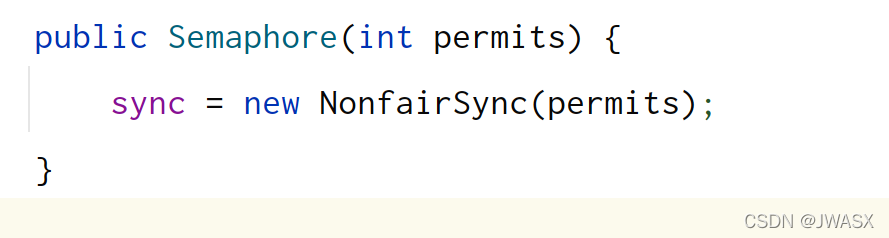
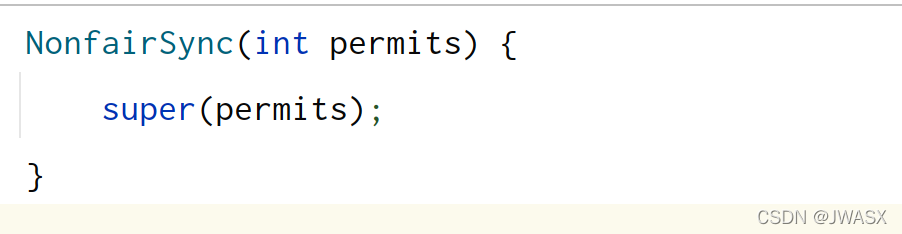
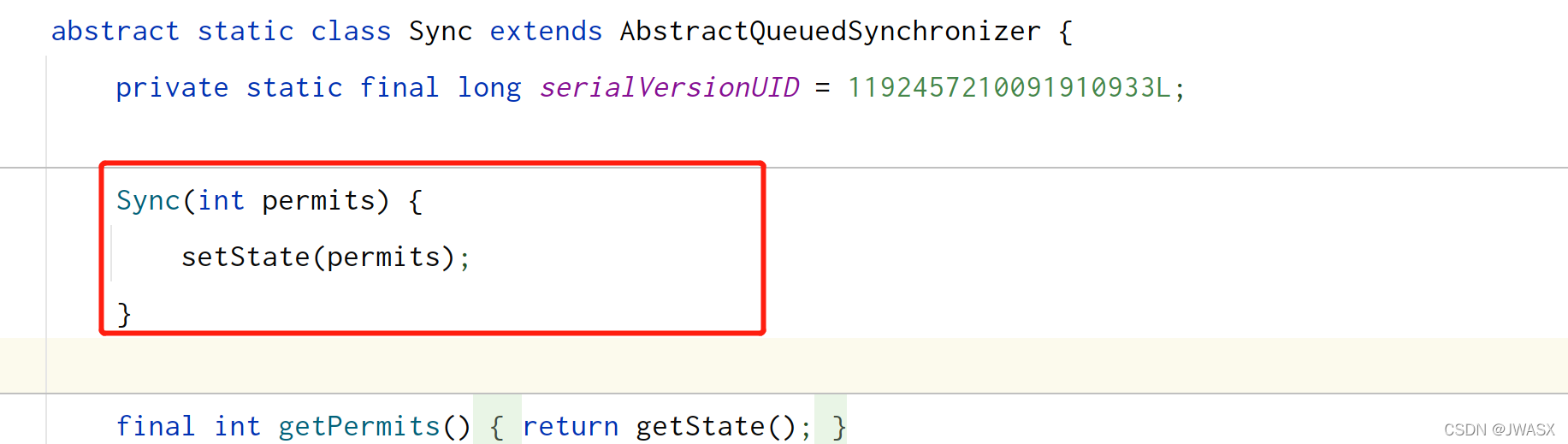
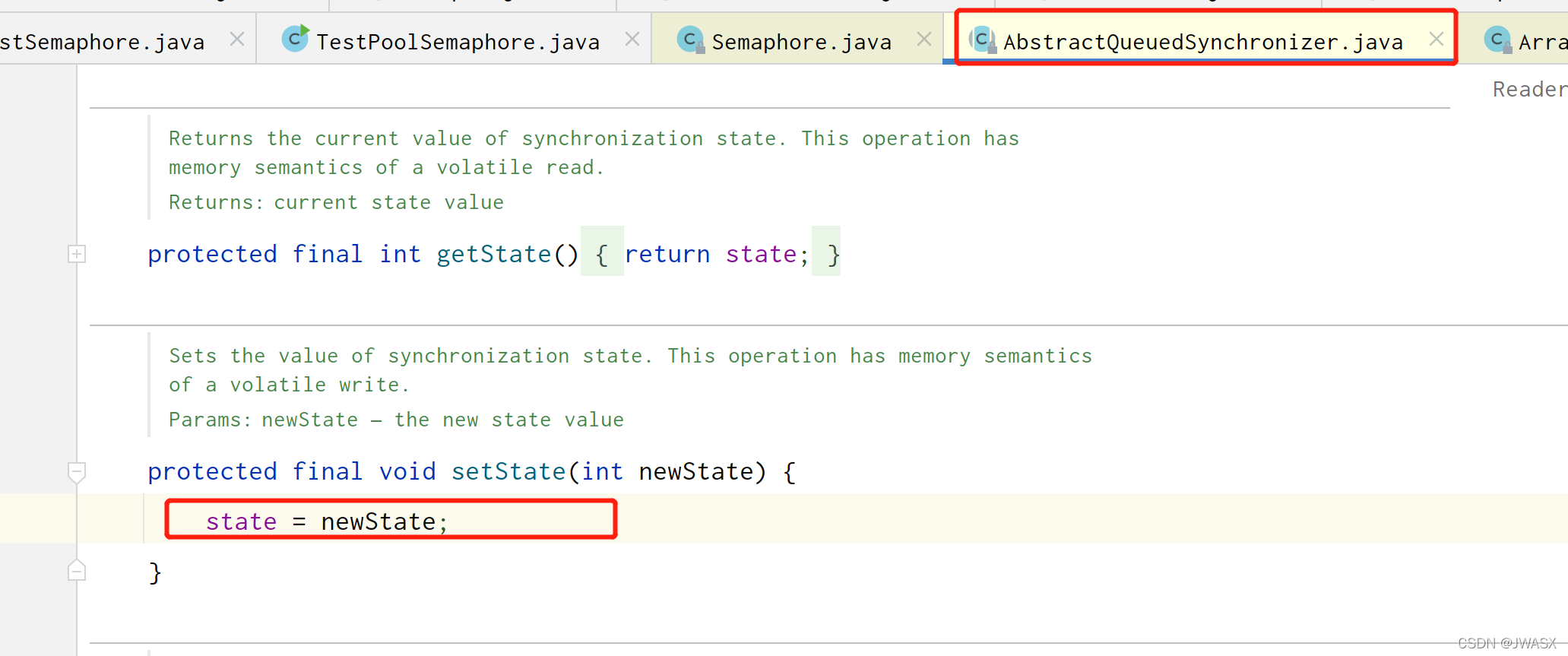
其实到这里,本质上就是赋值给了 AQS 中的 state
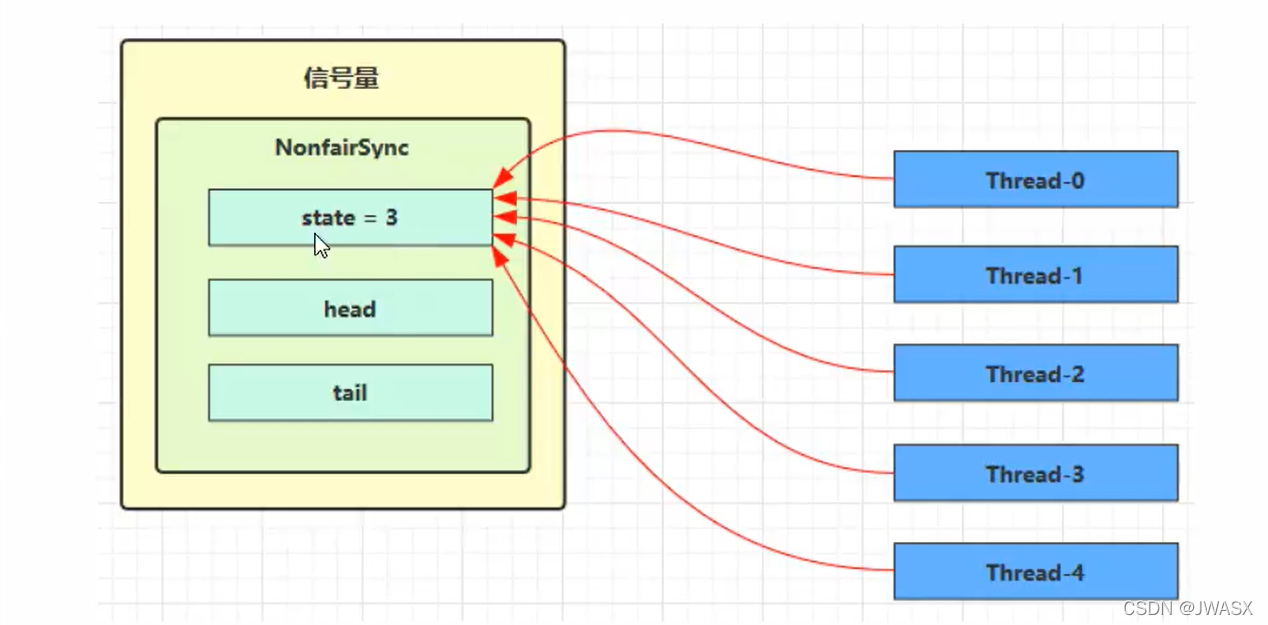
2、假设其中 Thread-1,Thread-2,Thread-4 cas 竞争成功,而 Thread-0 和 Thread-3 竞争失败,这时候就进入 AQS 队列park 阻塞
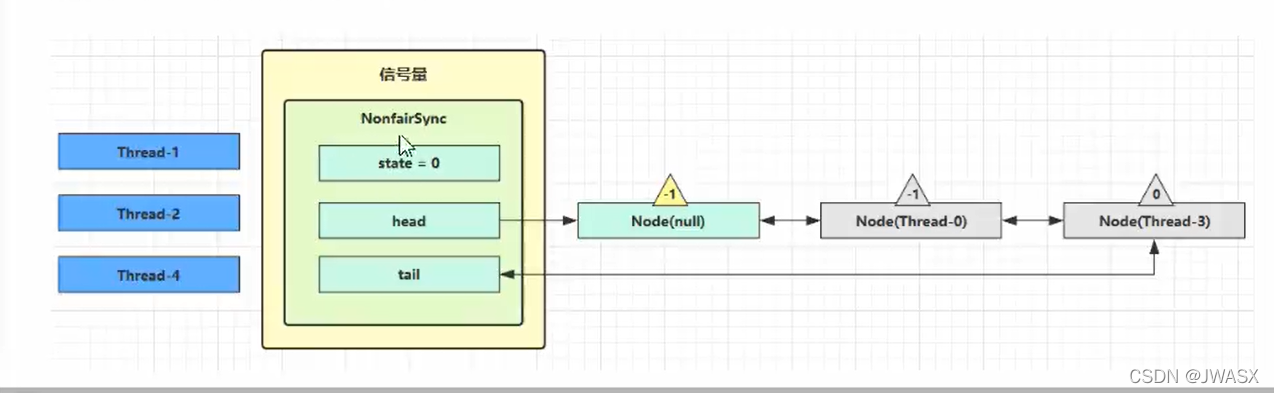
3、这时 Thread-4 释放了 permits,状态如下
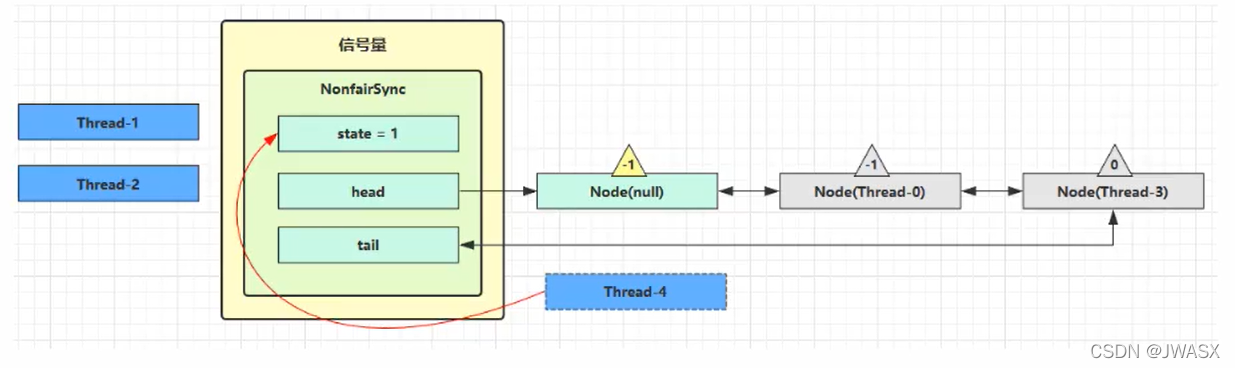
接下来 Thread-0 竞争成功,permits 从1再次设置为 0,设置自己为 head 节点,断开原来的 head 节点,unpark 接下来的 Thread-3 节点,但由于 permits 是 0,因此 Thread-3 在尝试不成功后再次进入 park 状态
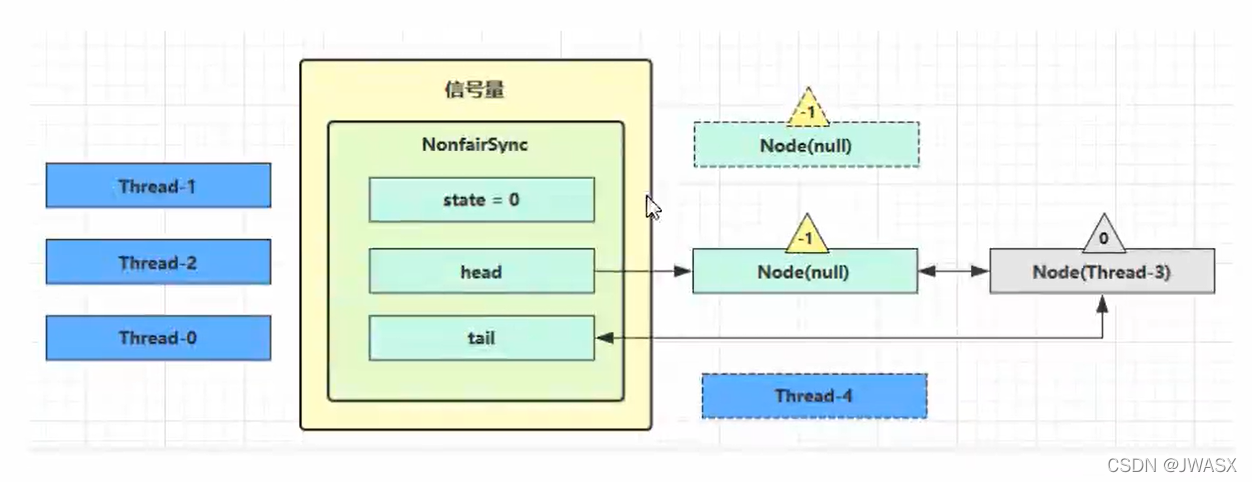
加锁
public void acquire() throws InterruptedException {
sync.acquireSharedInterruptibly(1);
}
public final void acquireSharedInterruptibly(int arg)
throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
//tryAcquireShared返回值时剩余的资源数,当满了之后就返回负数
if (tryAcquireShared(arg) < 0)
doAcquireSharedInterruptibly(arg);
}
//tryAcquireShared里面调用了一个这个方法
final int nonfairTryAcquireShared(int acquires) {
for (;;) {
//获取状态,还剩多少名额
int available = getState();
//减去许可数 3-1 = 2,如果这时候已经为0了,那么就返回负数
int remaining = available - acquires;
//设置剩余的许可数
if (remaining < 0 ||
compareAndSetState(available, remaining))
//返回剩余的数
return remaining;
}
}
//doAcquireSharedInterruptibly已经说过了
private void doAcquireSharedInterruptibly(int arg)
throws InterruptedException {
//创建 Share 节点
final Node node = addWaiter(Node.SHARED);
boolean failed = true;
try {
for (;;) {
//找到前驱节点
final Node p = node.predecessor();
//判断是不是头
if (p == head) {
//此时当前线程时老二,尝试再次获取
int r = tryAcquireShared(arg);
if (r >= 0) {
//获取成功了就设置头节点为空,并且唤醒后面所有的共享节点
setHeadAndPropagate(node, r);
p.next = null; // help GC
failed = false;
return;
}
}
//然后在这里park住
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
throw new InterruptedException();
}
} finally {
if (failed)
cancelAcquire(node);
}
}
解锁
public void release() {
sync.releaseShared(1);
}
public final boolean releaseShared(int arg) {
if (tryReleaseShared(arg)) {
doReleaseShared();
return true;
}
return false;
}
//释放
protected final boolean tryReleaseShared(int releases) {
for (;;) {
//拿到状态,就是剩余的资源数,此时是0
int current = getState();
//释放了一个当然要加上1了
int next = current + releases;
//如果next < 当前的,证明加法溢出了
if (next < current) // overflow
throw new Error("Maximum permit count exceeded");
//CAS设置
if (compareAndSetState(current, next))
return true;
}
}
private void doReleaseShared() {
//for循环
for (;;) {
//获取头节点,如果是tail,证明此时没有其他等待节点了
Node h = head;
if (h != null && h != tail) {
//获取状态
int ws = h.waitStatus;
//如果是-1,证明有义务唤醒下一个节点
if (ws == Node.SIGNAL) {
//把状态从 -1 改成 0
if (!compareAndSetWaitStatus(h, Node.SIGNAL, 0))
continue;
//唤醒下一个节点
unparkSuccessor(h);
}
else if (ws == 0 &&
!compareAndSetWaitStatus(h, 0, Node.PROPAGATE))
continue; // loop on failed CAS
}
if (h == head) // loop if head changed
break;
}
}
3. CountdownLatch
1. 介绍
用来进行线程同步协作,等待所有线程完成倒计时
其中构造参数用来初始化等待计数值,await() 用来等待计数归零,countDown() 用来让计数 -1
下面是内部的锁的实现
private static final class Sync extends AbstractQueuedSynchronizer {
private static final long serialVersionUID = 4982264981922014374L;
//设置状态,就是计数值
Sync(int count) {
setState(count);
}
int getCount() {
return getState();
}
//这个方法就是看看线程有没有都执行完了,如果是0就表示线程都执行完了
protected int tryAcquireShared(int acquires) {
return (getState() == 0) ? 1 : -1;
}
//释放锁
protected boolean tryReleaseShared(int releases) {
//一个线程用完就让计数值-1
for (;;) {
//获取状态
int c = getState();
if (c == 0)
return false;
//-1
int nextc = c-1;
//CAS修改
if (compareAndSetState(c, nextc))
return nextc == 0;
}
}
}
2. 使用
@Slf4j(topic = "c.TestCountDownLatch")
public class TestCountDownLatch {
public static void main(String[] args) throws InterruptedException, ExecutionException {
CountDownLatch latch = new CountDownLatch(3);
new Thread(()->{
log.debug("线程 t1 开始");
sleep(1);
latch.countDown();
log.debug("线程 t1 结束");
}, "t1").start();
new Thread(()->{
log.debug("线程 t2 开始");
sleep(2);
latch.countDown();
log.debug("线程 t2 结束");
}, "t2").start();
new Thread(()->{
log.debug("线程 t3 开始");
sleep(5);
latch.countDown();
log.debug("线程 t3 结束");
}, "t3").start();
log.debug("主线程等待其他线程执行完成再往下执行");
latch.await();
log.debug("主线程执行完成");
}
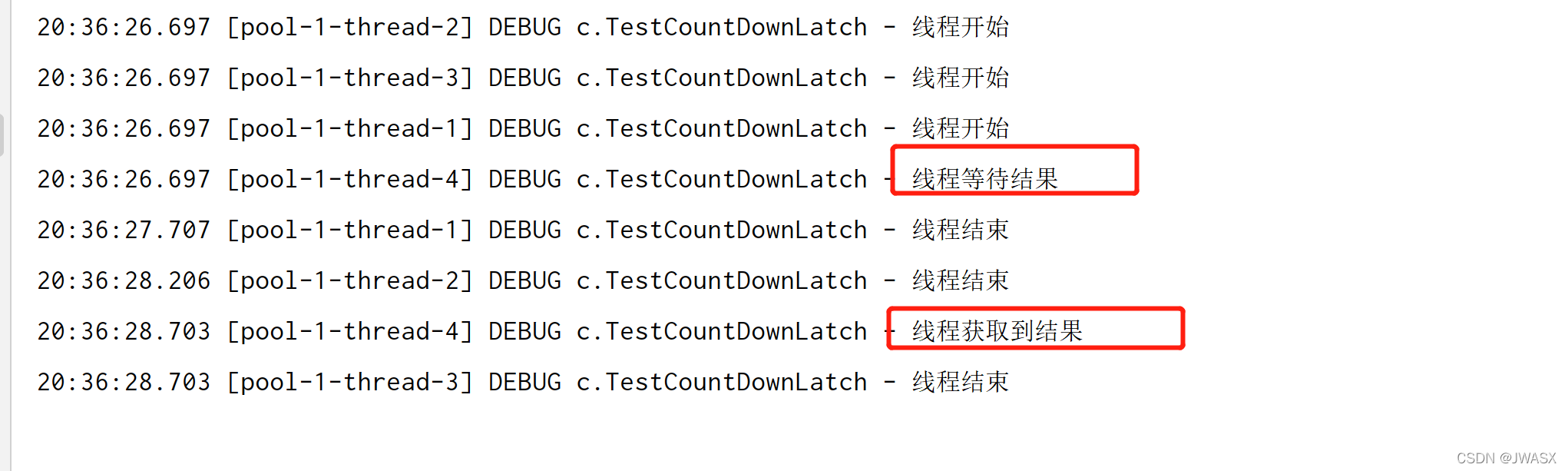
输出结果:可以看到下面主线程是等待其他线程执行完成了才继续往下执行的,至于下面的 t3 结束打印在最后是因为 t3 结束先唤醒了主线程

其实后来的线程的使用基本都是使用线程池的,所以线程一般不会轻易结束,这时候用 join 那些 api 就不行了。
我们来看下面的线程池用法:我们使用三个线程来执行任务,然后一个线程等待任务结束返回结果
@Slf4j(topic = "c.TestCountDownLatch")
public class TestCountDownLatch {
public static void main(String[] args) throws InterruptedException, ExecutionException {
CountDownLatch latch = new CountDownLatch(3);
ExecutorService service = Executors.newFixedThreadPool(4);
service.submit(()->{
log.debug("线程开始");
sleep(1);
latch.countDown();
log.debug("线程结束");
});
service.submit(()->{
log.debug("线程开始");
sleep(1.5);
latch.countDown();
log.debug("线程结束");
});
service.submit(()->{
log.debug("线程开始");
sleep(2);
latch.countDown();
log.debug("线程结束");
});
service.submit(()->{
try {
log.debug("线程等待结果");
latch.await();
log.debug("线程获取到结果");
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
}
输出结果:
3. 应用之等待多线程加载完毕
我们定义下面这个方法,然后实现10个用户加载的情况,等到加载完成打印一句游戏开始
private static void wangzherongyao() throws InterruptedException {
ExecutorService service = Executors.newFixedThreadPool(10);
CountDownLatch latch = new CountDownLatch(10);
Random r = new Random();
String[] all = new String[10];
//10个玩家
for (int j = 0; j < 10; j++) {
//final是因为lambda表达式接收的是常量
final int k = j;
service.submit(()->{
for (int i = 0; i <= 100; i++) {
try {
Thread.sleep(r.nextInt(100));
} catch (InterruptedException e) {
e.printStackTrace();
}
all[k] = i + "%";
//使用 \r 可以回退到最开始的输出位置然后对原来的输出进行覆盖
System.out.print("\r" + Arrays.toString(all));
}
//一个任务运行结束了就 -1
latch.countDown();
});
}
//主线程等待任务执行完成
latch.await();
System.out.println("\n游戏开始");
}
最终输出结果:
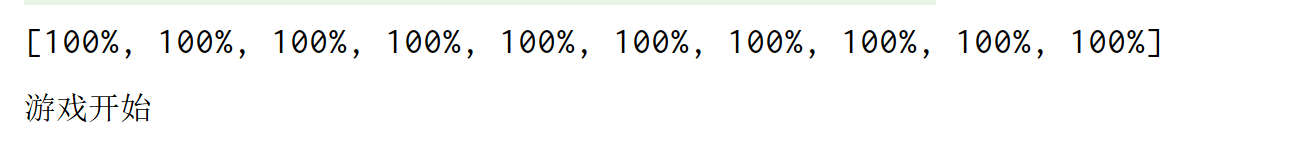
4. 应用之等待多个远程调用结束
下面是使用restTemplate来发送请求,在工作中的应用可以是当要不断一个接口请求多此的时候,此时可以用到多线程配合CountDown 来进行计数,当读取完成接口之后就可以对这些获取到的数据进行调用
private static void waitForObject() throws Exception {
RestTemplate restTemplate = new RestTemplate();
log.debug("等待远程服务调用返回结果");
ExecutorService service = Executors.newCachedThreadPool();
CountDownLatch latch = new CountDownLatch(4);
service.submit(() -> {
Map<String, Object> response = restTemplate.getForObject("http://localhost:8080/order/{1}", Map.class, 1);
latch.countDown();
});
service.submit(() -> {
Map<String, Object> response1 = restTemplate.getForObject("http://localhost:8080/product/{1}", Map.class, 1);
latch.countDown();
});
service.submit(() -> {
Map<String, Object> response1 = restTemplate.getForObject("http://localhost:8080/product/{1}", Map.class, 2);
latch.countDown();
});
service.submit(() -> {
Map<String, Object> response3 = restTemplate.getForObject("http://localhost:8080/logistics/{1}", Map.class, 1);
latch.countDown();
});
latch.await();
log.debug("执行完毕");
service.shutdown();
}
如果想要返回结果,那么还是使用 Future 更合使:
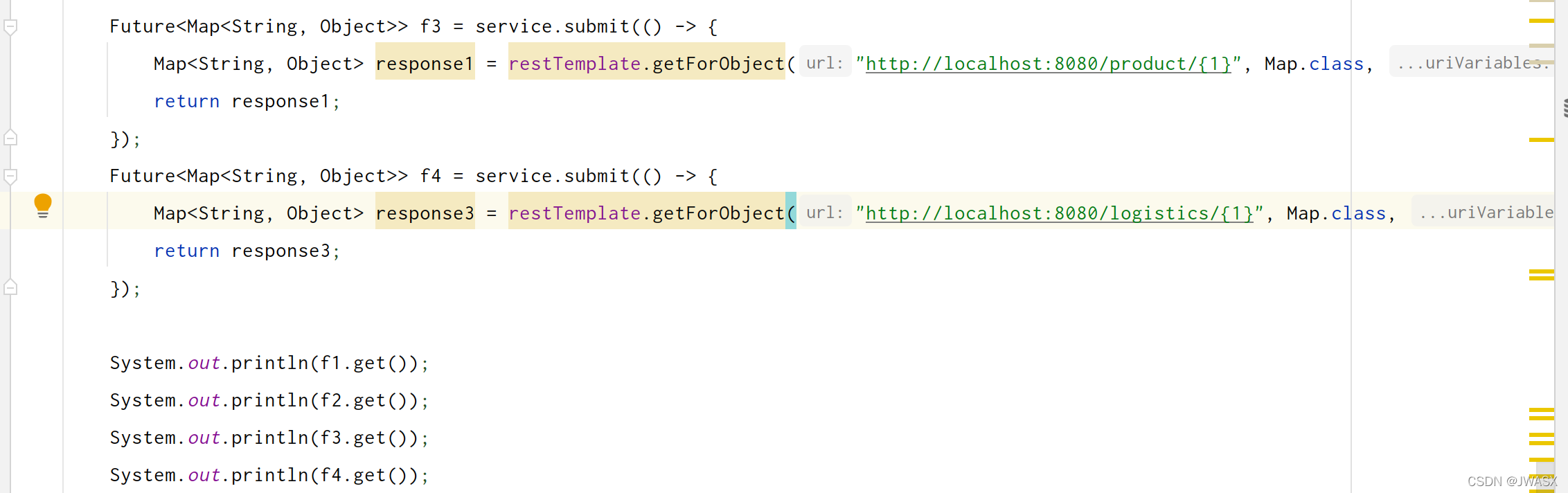
4. CyclicBarrier
1. 概念
循环栅栏,用来进行线程协作,等待线程满足某个计数。构造时设置『计数个数』,每个线程执行到某个需要“同步”的时刻调用 await() 方法进行等待,当等待的线程数满足『计数个数』时,继续执行。
为什么要用 CyclicBarrier,这个类作用和 CountdownLatch 类似,但是不同点就在于 CyclicBarrier是支持重用的,使用里面的 reset 方法进行重置。所以 CyclicBarrier可以处理更加复杂的业务,比如在计数错误的时候可以进行重置。此外 CyclicBarrier提供了 getNumberWaiting 方法可以获取阻塞的线程个数。isBroken() 方法可以用来了解阻塞的线程是否被中断
2. 基本使
private static void test2() {
//创建大小为3的线程池对象
ExecutorService service = Executors.newFixedThreadPool(2);
//我们设置计数为2,第二个参数是任务,实际是其他两个任务执行完成之后会执行这个任务
CyclicBarrier barrier = new CyclicBarrier(2, ()-> {
log.debug("任务1任务2结束");
});
for (int i = 0; i < 3; i++) { // task1 task2 task1
service.submit(() -> {
log.debug("任务1开始运行");
sleep(1);
try {
//调用 await 方法进行等待
barrier.await(); // 2-1=1
} catch (InterruptedException | BrokenBarrierException e) {
e.printStackTrace();
}
});
service.submit(() -> {
log.debug("任务2开始运行");
sleep(2);
try {
barrier.await(); // 1-1=0
} catch (InterruptedException | BrokenBarrierException e) {
e.printStackTrace();
}
});
}
service.shutdown();
}
输出结果:
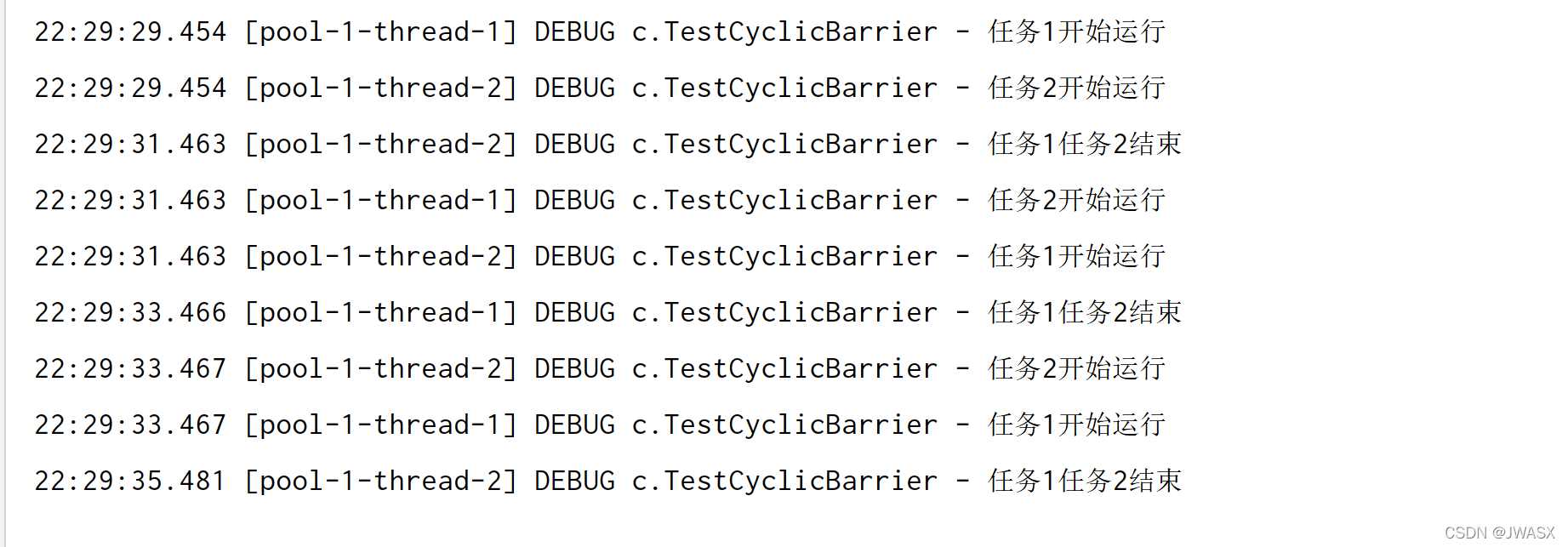
注意线程池的数量和计数值要一样,上面这个例子,如果设置线程为3,那么一次执行的顺序是 第1个任务1、第1个任务2 和 第2个任务1,注意任务二这时睡眠了2s,也就是说三个线程执行的时间刚刚好是2s,和线程数是2的时候的结果是一样的,此时执行完成后计数器重置。这样就不对了,这样就是第一个任务2 和 第二个 任务1 让计数器变为 0.
3. 业务场景
使用《Java并发编程的艺术》这本书里面给出的例子。这个计数器可以用于多线程计算数据,最终合并计算结果的场景。例如,用一个 Excel 保存了所有的银行流水,每个 Sheet 保存一个账户近一年的每笔银行流水,现在需要统计用户的日均银行流水,先用多线程处理每个 sheet 里的银行流水,都执行完成之后,得到每个 sheet 的日军银行流水,最后,再用 barrierAction 用这些线程的计算结果,计算出整个 Excel 的日均 银行流水,代码如下:
public class BankWaterService implements Runnable{
/**
* 创建4个屏障,处理完之后执行当前类的 run 方法
*/
private CyclicBarrier c = new CyclicBarrier(4, this);
/**
* 假设只有四个 sheet,那么启动四个线程
*/
private Executor executor = Executors.newFixedThreadPool(4);
/**
* 保存每个sheet处理出来的结果
*/
private ConcurrentHashMap<String, Integer> sheetBankWaterCount = new ConcurrentHashMap<>();
private void count(){
for (int i = 0; i < 4; i++) {
executor.execute(new Runnable() {
@Override
public void run() {
//计算当前sheet的影流数据,代码略,下面直接模拟结果
sheetBankWaterCount.put(Thread.currentThread().getName(), 1);
try {
c.await();
} catch (Exception e) {
e.printStackTrace();
}
}
});
}
}
@Override
public void run() {
int result = 0;
//汇总每个sheet计算出的结果
for (Map.Entry<String, Integer> sheet : sheetBankWaterCount.entrySet()) {
result += sheet.getValue();
}
//将结果输出
sheetBankWaterCount.put("result", result);
System.out.println(result);
}
public static void main(String[] args) {
BankWaterService bankWaterService = new BankWaterService();
bankWaterService.count(); //4
}
}
如有错误,欢迎指出!!!