����Ŀ¼
- Java���������--��һ����:Java����ƪ
- Java�������ͼ
- ��������(�ص�)
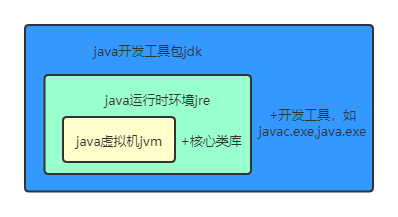
- 1��Java��һ��ʲô����,JDK,JRE,JVM���ߵ�����?
- 2��Java 1.5֮�������汾?
- 3��Java��ƽ̨����ԭ��?
- 4��Java ���Ե��ص�?
- 5��ʲô���ֽ���,�ֽ���ĺô�?
- 6��Java �� C++ ������?
- 7��Java����������?
- 8��Java�еĻ����������ͺ������������ͼ�������?
- 9��switch(expr),expr֧����Щ��������?
- 10��int �� Integer ��ʲô����,��ô�����Զ�����,�Զ�װ��?
- 11������2^3Ч����ߵķ�����?
- 12��Math.round(temp) ?
- 13��float f=3.4;�Ƿ���ȷ?
- 14��short s1 = 1; s1 = s1 + 1;���?
- 15��short s1 = 1; s1 += 1;���?
- 16��Java�е�ע��?
- 17��Java�еķ������η�?
- 18����д�����ص�����?
- 19������� &��&&������?
- 20��Java ��û�� goto?
- 21��this�ؼ��ֵ��÷�?
- 22��super�ؼ��ֵ��÷�?
- 23��Java ��final �ؼ���?
- 24��break ,continue ,return ����������?
- 25���� Java ��,���������ǰ�Ķ���Ƕ��ѭ��?
- 26��hashCode �� equals?
- 27��������ͽӿڵ�������ʲô?
- 28��ʲô�ǽӿ�?
- 29����̬������Ǿ�̬����������
- 30��ֵ���ݺ����ô��ݵ�������ʲô?
- 31��ʲô�Ƿ���?
- 32��String ���г��õķ���?
- 33��String �е�==�� equals ������?
- 34��Java �е� String,StringBuilder,StringBuffer ���ߵ�����?
- 35��Java��final��finally��finalize������?
- 36��Java��ɲ������ж�̳�?
- 37��HashMap �� Hashtable ������?
- 38��Map ��������Щʵ����,�ֱ����ʲô����?
- 39����� hashmap �̲߳���ȫ����?
- 40��Hashmap �ĵײ�ʵ��ԭ��?
- 41��hash ��ײ��ô����,��ô���?
- 42��HashMap Ϊʲô��Ҫ����?
- 43������ Map ����?
- 44��ArrayList �� LinkedList ����?
- 45��Java�е�ArrayList�ij�ʼ��������������?
- 46�����ʹ�õ� List ��������֤�̰߳�ȫ?
- 47��IO �� NIO ������?
- 48���� Java ��Ҫ��ʵ�ֶ��̴߳����������ֶ�?
- 49��Thread ���е� start() �� run() ������ʲô����?
- 50��Java �� notify �� notifyAll ��ʲô����?
- 51��Java ���߳��е��� wait() �� sleep()������ʲô��ͬ?
- 52��ʲô���̰߳�ȫ
- 53��Java�е� volatile ������ʲô?
- 54���̵߳�״̬?
- 55��ʵ���߳�ͬ�������ַ�ʽ?
- 56��Java�е����м��ַ�ʽ?
- 57��Lock�ļ���ʵ����?
- 58���̼߳�ͨ�ŵļ���ʵ�ַ�ʽ?
- 59��synchronized �� Lock �������Ӧ�ó���?
- 60��ΪʲôҪ���̳߳�?
- 61����δ����̳߳�?
- 62��Java�е��쳣��ϵ?
- 63��throw �� throws ������?
- 64��˵�� 5 ���������쳣?
Java��������ܨC��һ����:Java����ƪ
Java�������ͼ

��������(�ص�)

1����ȡ���½�PDF�����Ź��ںš�ITѧ�����ظ���java-01��
2����ȡ����Java�������������Ź��ںš�ITѧ�����ظ���java-pdf��,�������ϰ���:
- ��һ����:Java����ƪ
- �ڶ�����:JavaWebƪ
- ��������:Java�����ƪ
- ���IJ���:����ֲ�ʽ
- ���岿��:�㷨�ṹ���㷨ר��
- ��������:����ָ��,������
1��Java��һ��ʲô����,JDK,JRE,JVM���ߵ�����?
Java��һ����ȫ�������ı������,���м��ԡ�������ֲ�ʽ����׳�ԡ���ȫ�ԡ�ƽ̨���������ֲ�ԡ����̡߳���̬�Ե��ص�,��������c++���ŵ�,ȥ����c++�ж�̳�,ָ���������������ĸ��java���Բ���Unicode�������
JDK(Java Development Kit)����� Java ����Ա�IJ�Ʒ,������ Java �ĺ���,������ Java ���л��� JRE��Java ���ߺ� Java ������⡣
Java Runtime Environment(JRE)������ JAVA ����������Ļ����ļ���,���� JVM ��ʵ�ּ� Java ������⡣
JVM �� Java Virtual Machine(Java �����)����д,������ java ʵ�ֿ�ƽ̨������ĵIJ���,�ܹ������� Java ����д������������
2��Java 1.5֮�������汾?
- Java SE Java����
- Java EE Java��ҵ��
- Java ME Java�Ͱ�
3��Java��ƽ̨����ԭ��?
��ν�Ŀ�ƽ̨����JavaԴ�뾭��һ�α����Ժ�,�����ڲ�ͬ�IJ���ϵͳ�����С�
ԭ��:��������� .class �ļ�������Java�������,����ֱ�������ڲ���ϵͳ��,ֻҪ��װ���㲻ͬ����ϵͳ��JVM(JAVA�����)���ɡ�
4��Java ���Ե��ص�?
- �������Java �������������,�������������Ļ�������(��װ,�̳�,��̬)
- ��ƽ̨�� JVMʵ��Java���ԵĿ�ƽ̨
- ֧��������
- ֧�ֶ��߳�
- ��׳�ԡ�Java���Ե�ǿ���ͻ���,�쳣��������,GC�����Զ��ռ�����
5��ʲô���ֽ���,�ֽ���ĺô�?
- �ֽ���:Java ���� Javac ��������� .class �ļ������ֽ���
- �ֽ���ĺô�:
1. ��һ���̶��Ͻ���˽���������Ч�ʵ��µ�����
2. ������ض��Ļ���,�����˽��������ԵĿ���ֲ��
6��Java �� C++ ������?
Java��C++��������������ԡ���˶����������Ļ������Է�װ,�̳�,��̬�����ǵ���������:
- Java���ṩָ����ֱ�ӷ����ڴ�,�����ڴ���Ӱ�ȫ
- Java���ǵ��̳�,c++��֧�ֶ�̳�
- Java�����ڴ��������,�������Ա�ֶ��ͷ��ڴ�
7��Java����������?
- ��װ: �ѷ�����������װ������,��ߴ���İ�ȫ��
- �̳�: Java��Ϊ���̳�,��ߴ����������
- ��̬: ��̬����ͬһ������߽ӿ�,ʹ�ò�ͬ��ʵ�����ִ�в�ͬ�IJ���,��ߴ���������
8��Java�еĻ����������ͺ������������ͼ�������?
- 8�ֻ�����������
| ˵�� | ��ռ�ڴ��С(�ֽ�) | ȡֵ��Χ | Ĭ��ֵ | |
|---|---|---|---|---|
| byte | Java�������������� | 1 | ? 2 7 {-2^7} ?27~ 2 7 {2^7} 27-1 | 0 |
| short | ������ | 2 | ? 2 15 {-2^{15}} ?215~ 2 15 {2^{15}} 215-1 | 0 |
| int | ���� | 4 | ? 2 31 {-2^{31}} ?231~ 2 31 {2^{31}} 231-1 | 0 |
| long | ������ | 8 | ? 2 63 {-2^{63}} ?263~ 2 63 {2^{63}} 263-1 | 0L |
| float | ������ | 4 | -3.40E+38 ~ +3.40E+38 | 0 |
| double | ˫���� | 2 | -1.79E+308 ~ +1.79E+308 | 0 |
| char | �ַ��� | 2 | 0~65535 | null |
| boolean | ������ | 1 | true,false | false |
- ������������
��,�ӿ�����,��������,ö������,ע������
- �������������������������͵�����
�������������ڱ�����ʱ,����ջ�Ϸ���ռ�,ֱ�ӽ�֮�洢��ջ�С����������������ڱ�����ʱ,���Ȼ���ջ�Ϸ���ռ�,�������ô���ջ�ռ���,Ȼ���ڶ��п����ڴ�,ֵ����ڶ��ڴ���,ջ�е�����ָ����еĵ�ַ��
9��switch(expr),expr֧����Щ��������?
��Java5��ǰ,expr֧�� byte,short,int,char ������������,��Java5�Ժ�,�ֶ���ö��enum����,Java7��������string����,��Ŀǰ����֧��long���͡�
10��int �� Integer ��ʲô����,��ô�����Զ�����,�Զ�װ��?
int �ǻ�����������,Ĭ��ֵ��0
integer����������,��int �İ�װ��,Ĭ��ֵ�� null
�Զ�����:����װ�����Զ�ת��Ϊ��Ӧ�Ļ�����������
�Զ�װ��:�����������Զ�ת��Ϊ��Ӧ����������
11������2^3Ч����ߵķ�����?
����2^3Ч����ߵķ�����:2<<(3-1)
12��Math.round(temp) ?
���������ԭ������ԭ���IJ����ϼ�0.5,Ȼ���������ȡ����
13��float f=3.4;�Ƿ���ȷ?
����ȷ��3.4��˫��������,��ֵ��float��Ҫǿ������ת��,float f=(float)3.4,����д�� float f=3.4F��
14��short s1 = 1; s1 = s1 + 1;���?
short s1 = 1; s1 = s1 + 1 ����ȷ����Ϊ 1��int����,��� s1+1 Ҳ��int����,��ִ�� s1=s1+1 ʱ,��Ҫ��int���͵�s1+1��ֵ��short���͵�s1,��תС���ܻ��о�����ʧ,����ʾת����
15��short s1 = 1; s1 += 1;���?
short s1 = 1; s1 += 1 ��ȷ����Ϊ s1+=1 �൱��s1=(short)(s1+1),����������ǿ������ת����
16��Java�е�ע��?
����:ע������������˵����������֡���Ϊ:
- ����ע��:// ע�͵�����
- ����ע��:/* ע�͵����� */
- �ĵ�ע��:/** ע�͵����� **/
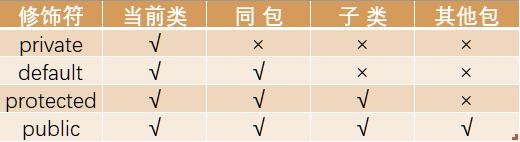
17��Java�еķ������η�?
Java�еķ������η���:public,private,protected,�Լ���д(Ĭ��)��
18����д�����ص�����?
��д: ���ٷ�������������,������������м̳л���ʵ�ֹ�ϵ,��ʾ�����еķ��������븸�������ȫ��ͬ�ķ�������,����ֵ,�����������еķ������Ǹ���ķ���,�����˶�̬�ԡ�
����: ������ͬһ������,�������������ͬ,��������,������˳��ͬ�ķ���������������,�뷵��ֵ�ء�
19������� &��&&������?
&:�������true����false,�ұ�Ҳ������жϡ�
&&:������Ϊfalse,�б߾Ͳ�������ж�,���&&��&Ч�ʸߡ�
ע��:���������(|)�Ͷ�·�������(||)�IJ��Ҳ����ˡ�
20��Java ��û�� goto?
goto �� Java �еı�����,��Ŀǰ�汾�� Java ��û��ʹ�á�
21��this�ؼ��ֵ��÷�?
1.��ͨ��ֱ������,this�൱����ָ��ǰ��������
2.�β����Ա��������,��this������:
public Person(String name, int age) {
this.name = name;
this.age = age;
}
3.���ñ���Ĺ��캯��:
class Person{
private String name;
private int age;
public Person() {
}
public Person(String name) {
this.name = name;
}
public Person(String name, int age) {
this(name);
this.age = age;
}
}
22��super�ؼ��ֵ��÷�?
1.��ͨ��ֱ�����á�
2.���ø����������������ķ�����
2.���ø���Ĺ��캯����
23��Java ��final �ؼ���?
��java��,final�ؼ��ֿ���������,�����ͷ�������final���κ������ص�:
final������:final���ε���ܱ��̳С�
final���α���:final���εı����dz���,���ܸı䡣
final���η���:final���εķ������ܱ���д��
24��break ,continue ,return ����������?
break:������ǰѭ��
continue:��������ѭ��,�����´�ѭ��
return:����
25���� Java ��,���������ǰ�Ķ���Ƕ��ѭ��?
�������ѭ�����ǰ����һ�����
ok:
for(int i=0;i<10;i++){
for(int j=0;j<10;j++){
system.out.println("i="+i+",j="+j);
if(j==5)break ok;
}
}
26��hashCode �� equals?
�����������equals()������������ǵ�hashCode����ֵһ��Ҫ��ͬ,������������hashCode����ֵ��ͬ,�����ǵ�equals()������һ����ȡ�
���������hashCode()����ֵ��Ȳ����ж���������������ȵ�,�����������hashcode()����ֵ�����������ж���������һ������ȡ�
27��������ͽӿڵ�������ʲô?
�ӿ��еķ������dz����,�������п����г���,Ҳ�����зdz�����
��jdk1.8�Ժ�ӿ���Ҳ��������defaule�ؼ������ε���ͨ����
28��ʲô�ǽӿ�?
�ӿ���һ�ֹ淶,Java�еĽӿ�:interface
29����̬������Ǿ�̬����������
| ��̬���� | �Ǿ�̬���� | |
|---|---|---|
| ���÷�ʽ | ��̬����ֻ��ͨ�� �� ����.������ �� ���� | �Ǿ�̬����ͨ��ʵ�������������� |
| ������ʽ | ��̬������ȫ�ֱ���,���������ʵ���������� | �Ǿ�̬�����Ǿֲ�����,������ |
| ����ʷ�ʽ | ��̬���������ʷǾ�̬���� | �Ǿ�̬�������Է��ʾ�̬���� |
30��ֵ���ݺ����ô��ݵ�������ʲô?
ֵ����: �ڷ����ĵ��ù�����,ʵ�ΰ�����ʵ��ֵ���ݸ��β�,�˴��ݹ��̾��ǽ�ʵ�ε�ֵ����һ�ݴ��ݵ������С�
���ô���: ���ô����ֲ���ֵ���ݵIJ���,������ݵ��������ܴ�,ֱ�Ӹ���ȥ�Ļ�,��ռ�ô������ڴ�ռ�,�����ô��ݾ��ǽ�����ĵ�ֵַ���ݹ�ȥ,�������յ���ԭʼֵ����ֵַ���ڷ�����ִ�й�����,�βκ�ʵ�ε�������ͬ,ָ��ͬһ���ڴ��ַ,Ҳ����˵��������ʵ����Դ����,���Է�����ִ�н���Ӱ�쵽ʵ�ʶ���
31��ʲô�Ƿ���?
JAVA ���������������״̬��,��������һ����,���ܹ�֪���������������Ժͷ���;��������һ������,���ܹ�������������һ�����������ԡ�
32��String ���г��õķ���?
| ���� | ˵�� |
|---|---|
| split() | ���ַ����ָ���ַ������� |
| indexOf() | ��ָ���ַ���ȡ����λ�� |
| append() | ���ַ����ַ��� |
| trim() | ȥ���ַ������˵Ŀո� |
| replace() | �滻 |
| hashCode() | �����ַ����Ĺ�ϣֵ |
| subString() | ��ȡ�ַ��� |
| equals() | �Ƚ��ַ����Ƿ���� |
| length() | ��ȡ�ַ������� |
| concat() | ��ָ���ַ������ӵ����ַ����Ľ�β |
33��String �е�==�� equals ������?
"=="�Ƚϵ��������ַ������ڴ��ַ�� "equals"�Ƚϵ��������ַ�����ʵ��ֵ
34��Java �е� String,StringBuilder,StringBuffer ���ߵ�����?
String: �ַ�������,�ײ��� final �ؼ�������,�ײ�ʵ����ά�� char ���͵��ַ�����,��ÿ�ζ�String���иı�ʱ,����Ҫ����һ���µ�String����,Ȼ��ָ��ָ��һ���µĶ���
//�ײ��� final �ؼ�������,�ײ�ʵ����ά�� char ���͵��ַ�����
public final class String implements java.io.Serializable, Comparable<String>, CharSequence {
/** The value is used for character storage. */
private final char value[];
}
StringBuilder: �ַ�������,�̰߳�ȫ,���ڶ��̲߳���
StringBuffer : �ַ�������,���̰߳�ȫ,���ڵ��̲߳���
35��Java��final��finally��finalize������?
final: ���η�,java �еĹؼ��֡�������������,����,����,�����յ���˼��
| ���εĶ��� | ˵�� |
|---|---|
| final ������ | ��������ܱ����������̳�,��Ҫע��:final�������еij�Ա����������ʽ�Ķ���Ϊfinal������ |
| final ���α��� | final��Ա������ʾ����,ֻ�ܱ���ֵһ��,��ֵ����ֵ���ٸı� |
| final ���η��� | final ���εķ������ܱ���д |
finally: finally �����쳣�ᆳ���õ���, ���� try �� cach ��Ĵ���ִ�����Ժ�,����Ҫִ�еķ���,���Ǿ����� finally ��дһЩ�ر���Դ�ķ���,����˵�ر����ݿ�����,���߹ر� IO ��.
finalize: finalize�Ƿ�����,java��������ʹ��finalize()�����������ռ�����������ڴ��������ȥ֮ǰ����Ҫ����������
36��Java��ɲ������ж�̳�?
Java�в�������̳�,������A����ͬʱ�̳���B����C,��Ҫ�д�������,�����ýӿڡ�
37��HashMap �� Hashtable ������?
HashMap �� Hashtable��Map�ӿڵ�ʵ����,���Ǵ�����һ�¼�������:
- �̳еĸ��ͬ��HashMap�Ǽ̳���AbstractMap��,��HashTable�Ǽ̳���Dictionary�ࡣ
- �̰߳�ȫ�Բ�ͬ��Hashtable �еķ�����Synchronize��,��HashMap�еķ�����ȱʡ������Ƿ�Synchronize�ġ�Hashtable ���ֳɰ�ȫ��,HashMap�Ƿ��̰߳�ȫ�ġ�
- key��value�Ƿ�����nullֵ��Hashtable��,key��value������������nullֵ�����������Hashtable��������put(null,null)�IJ���,����ͬ������ͨ��,��Ϊkey��value����Object����,������ʱ���׳�NullPointerException�쳣,����JDK�Ĺ淶�涨�ġ�HashMap��,null������Ϊ��,�����ļ�ֻ��һ��;������һ������������Ӧ��ֵΪnull����get()��������nullֵʱ,������ HashMap��û�иü�,Ҳ����ʹ�ü�����Ӧ��ֵΪnull�����,��HashMap�в�����get()�������ж�HashMap���Ƿ����ij����, ��Ӧ����containsKey()�������жϡ�
38��Map ��������Щʵ����,�ֱ����ʲô����?
| ʵ���� | ���� |
|---|---|
| HashMap | �̲߳���ȫ�ļ�ֵ�Լ���,���� null ֵ,key �� value ������ |
| HashTable | �̰߳�ȫ�ļ�ֵ�Լ���,������ null ֵ,key �� value �������� |
| TreeMap | �ܹ���������ļ�¼���ݼ�����,Ĭ���ǰ��������� |
39����� hashmap �̲߳���ȫ����?
- Collections.synchronizedMap() ����
- java.util.concurrent.ConcurrentHashMap ��
40��Hashmap �ĵײ�ʵ��ԭ��?
��JDK1.6,JDK1.7��,HashMap����λͰ+����ʵ��,��ʹ������������ͻ,ͬһhashֵ�ļ�ֵ�Իᱻ����ͬһ��λͰ��,��Ͱ��Ԫ�ؽ϶�ʱ,ͨ��keyֵ���ҵ�Ч�ʽϵ͡�
��JDK1.8��,HashMap����λͰ+����+�����ʵ��,���������ȳ�����ֵ(8),ʱ,������ת��Ϊ�����,�����������˲���ʱ�䡣
�����Ǵ��� hashmap ʱ ���ȴ���һ������,�������� put ����������ʱ,�ȸ��� key �� hashcode ֵ����� hash ֵ,Ȼ���������ϣֵȷ���������е�λ��,�ٰ� value ֵ�Ž�ȥ,������λ�ñ���û�� ����,�ͻ�ֱ�ӷŽ�ȥ,���֮ǰ����,�ͻ�����һ������,���·����ֵ����ͷ��,���� get ����ȡֵʱ,���ȸ��� key �� hashcode ֵ����� hash ֵ,ȷ��λ��,�ٸ��� equals �����Ӹ�λ���ϵ�������ȡ���� value ֵ��
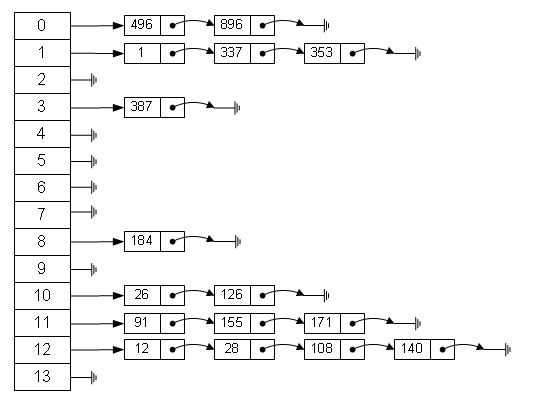
41��hash ��ײ��ô����,��ô���?
����Hash��ǰ����ʵ��equals()��hashCode()��������,��ôHashCode()�����þ��DZ�֤����Ψһhashֵ,���������������ֵһ��ʱ,��ͷ�������ײ��ͻ�����½�������δ�����ͻ,��Ȼ��ǰ����һ����hash��
���hash��ײ�����¼��ַ���:
- ���ŵ�ַ��
���ŵ�ִ����һ����ʽ:Hi=(H(key)+di) MOD m i=1,2,��,k(k<=m-1) ����,mΪ��ϣ���ı�����di �Dz�����ͻ��ʱ����������С����diֵ����Ϊ1,2,3,��m-1,������̽����ɢ�С����diȡ1,��ÿ�γ�ͻ֮��,����ƶ�1��λ��.���diȡֵ����Ϊ1,-1,2,-2,4,-4,9,-9,16,-16,��kk,-kk(k<=m/2),�ƶ���̽����ɢ�С����diȡֵ����Ϊα������С���α���̽����ɢ�С�
- �ٹ�ϣ��
��������ͻʱ,ʹ�õڶ���������������ϣ���������ַ,ֱ����ͻʱ��ȱ��:����ʱ�����ӡ����������һ�ΰ���������ĸ���й�ϣ,���������ͻ����������ĸ����ĸ�ڶ�λ���й�ϣ,�ٳ�ͻ,����λ,ֱ������ͻΪֹ��
- ����ַ��(������)
�����йؼ���Ϊͬ��ʵļ�¼�洢��ͬһ���������С�����:
42��HashMap Ϊʲô��Ҫ����?
��hashmap�е�Ԫ�ظ������������С��loadFactor��ʱ,�ͻ������������,loadFactor��Ĭ��ֵΪ 0.75,Ҳ����˵,Ĭ�������,�����СΪ 16,��ô��hashmap ��Ԫ�ظ������� 16*0.75=12 ��ʱ��,�Ͱ�����Ĵ�С��չΪ2*16=32,������һ����Ȼ�����¼���ÿ��Ԫ���������е�λ��,������һ���dz��������ܵIJ���,������������Ѿ�Ԥ֪ hashmap ��Ԫ�صĸ���,��ôԤ��Ԫ�صĸ����ܹ���Ч����� hashmap �����ܡ�����˵,������ 1000 ��Ԫ��new HashMap(1000), �������������� new HashMap(1024)������,��������annegu �Ѿ�˵��,��ʹ�� 1000,hashmap Ҳ�Զ��Ὣ������Ϊ 1024�� ����newHashMap(1024)�����Ǹ����ʵ�,��Ϊ 0.75*1000<1000,Ҳ����˵Ϊ����0.75*size>1000, ���DZ������� newHashMap(2048)�������,������resize �����⡣
43������ Map ����?
�Ȼ�ȡ Map �е� key �� set ���� map.keySet(); ͨ������ key ����,��ȡ value ֵ��Map.get(key)�Ȼ�ȡ Entry ���� map.entrySet(); ���� entrySet �ֱ��ȡ key value��
44��ArrayList �� LinkedList ����?
ArrayList ʹ�����鷽ʽ�洢����,���Ը���������ѯ�����ٶȿ�,���������� ɾ��Ԫ��ʱ��Ҫ��Ƶ�λ�Ʋ���,���ԱȽ�����
LinkedList ʹ��˫�����ӷ�ʽ�洢����,ÿ��Ԫ�ض���¼ǰ��Ԫ�ص�ָ��, ���Բ��롢ɾ������ʱֻ�Ǹ���ǰ��Ԫ�ص�ָ��ָ��,�ٶȷdz���,Ȼ��ͨ���±��ѯԪ��ʱ��Ҫ��ͷ��ʼ����,���ԱȽ���,���������ѯǰ����Ԫ�ػ� ��Ԫ���ٶȱȽϿ졣
ArrayList �� LinkedList �����̲߳���ȫ�ġ�
45��Java�е�ArrayList�ij�ʼ��������������?
ArrayList�Ǿ����ᱻ�õ���,һ�������,ʹ�õ�ʱ�����������������:
List arrayList = new ArrayList();
�������������ʹ��Ĭ�ϵĹ��췽��,��ʼ����������Ϊ10����ArrayList�е�Ԫ�س���10���Ժ�,�����·����ڴ�ռ�,ʹ����Ĵ�С������16��
����ͨ�����Կ�����̬�����������仯:10->16->25->38->58->88->��
Ҳ����ʹ������ķ�ʽ��������:
List arrayList = new ArrayList(4);
��ArrayList��Ĭ����������Ϊ4����ArrayList�е�Ԫ�س���4���Ժ�,�����·����ڴ�ռ�,ʹ����Ĵ�С������7��
����ͨ�����Կ�����̬�����������仯:4->7->11->17->26->��
��ô�����仯�Ĺ�����ʲô��?�뿴����Ĺ�ʽ:
((������ * 3) / 2) + 1
46�����ʹ�õ� List ��������֤�̰߳�ȫ?
1��ʹ�� Vector
2��ʹ�� Collections �еķ��� synchronizedList �� ArrayList ת��Ϊ�̰߳�ȫ�� List
3��ʹ�� java.util.current ���µ� CopyOnWriteArrayList(�Ƽ�)
47��IO �� NIO ������?
���NIO��JDK1.7�Ժ��е�,����������Ҫ������ :io ��������������io,nio������,�������� io; io��ÿ�δ����ж�ȡһ������ֽ�,ֱ����ȡ�����е��ֽ� ,û�л��浽�κεط���nio��ȡ�����������л���,����˵����ȡ���������ڻ�������ġ�����Ļ�,java�еĸ���io�������ġ�����˵һ���̵߳��� read �� �� write()ʱ,����߳̾��Ѿ���������,ֱ����ȡ��һЩ����Ϊֹ,��������ȫд�롣����������в��ܸ����������顣nio�ķ�����ģʽ ,������һ����ȡ���ݵ������ʱ�� ,���û�ж�ȡ�����õ����� ,��ʲôҲ���� ��ȡ ,�Ҳ������߳�����дҲ����������������IO�Ŀ���ʱ����������������IJ�������,һ���� ���ķ������� �̿��Թ��� �����������ͨ��,���� NIO ����һ��selector(ѡ �� �� ),���ǿ��Թ���������������ͨ��.
48���� Java ��Ҫ��ʵ�ֶ��̴߳����������ֶ�?
һ���Ǽ̳� Thread ��
��һ�־���ʵ�� Runnable �ӿ�
���һ�־���ʵ�� Callable �ӿ�
(������Ҳ��ʵ�� callable �ӿ�,ֻ�����з���ֵ����)
49��Thread ���е� start() �� run() ������ʲô����?
start()���������������´������߳�,���� start()�ڲ������� run()����,���ֱ�ӵ��� run()������Ч����һ����������� run()������ʱ��,ֻ������ԭ�����߳��е���,û���µ��߳�����,start()�����Ż��������̡߳�
50��Java �� notify �� notifyAll ��ʲô����?
notify()�������ܻ���ij��������߳�,����ֻ��һ���߳��ڵȴ���ʱ����
��������֮�ء��� notifyAll()���������̲߳���������������ȷ����������һ
���߳��ܼ������С�
51��Java ���߳��е��� wait() �� sleep()������ʲô��ͬ?
Java ������ wait �� sleep �������ij����ʽ����ͣ,���ǿ������㲻ͬ����Ҫ��wait()���������̼߳�ͨ��,����ȴ�����Ϊ���������̱߳�����ʱ�����ͷ���,�� sleep()���������ͷ� CPU ��Դ�����õ�ǰ�߳�ִֹͣ��һ��ʱ��,�������ͷ�����
52��ʲô���̰߳�ȫ
����߳�ͬʱ����һ�δ��롣���ÿ�����н���͵��߳����еĽ����һ����,���������ı�����ֵҲ��Ԥ�ڵ���һ����,�����̰߳�ȫ�ġ�ͬһ��ʵ�������ڱ�����߳�ʹ�õ������Ҳ������ּ���ʧ��,Ҳ���̰߳�ȫ��,��֮�����̲߳���ȫ�ġ�
53��Java�е� volatile ������ʲô?
Volatile: һ����������(��ij�Ա��������ľ�̬��Ա��)��volatile����֮��,��ô�;߱�����������:
a.��֤�˲�ͬ�̶߳�����������в���ʱ�Ŀɼ���,��һ���߳�����ij��������ֵ,����ֵ�������߳���˵�������ɼ��ġ�
b.��ֹ����ָ�����������������ܱ�֤������ԭ���ԡ�
Ӧ�ó���:��ֻ�漰�ɼ���,��Ա����IJ���ֻ�ǼĶ�д(��֤������
ԭ����)������¿���ʹ��volatile������߲�������,�����ʱ��Ա����IJ����Ƿ�ԭ�ӵIJ���,��ʱ���ֻ�Ǽ�i++ʽ�IJ���,����ʹ��ԭ����atomic������֤������ԭ����(����CASʵ��),����Ǹ��ӵ�ҵ�����,��ô����volatile,�������������������(synchronized����Lock)��
54���̵߳�״̬?
ʵ�߳�һ���������״̬,�����������������С���������ֹ��
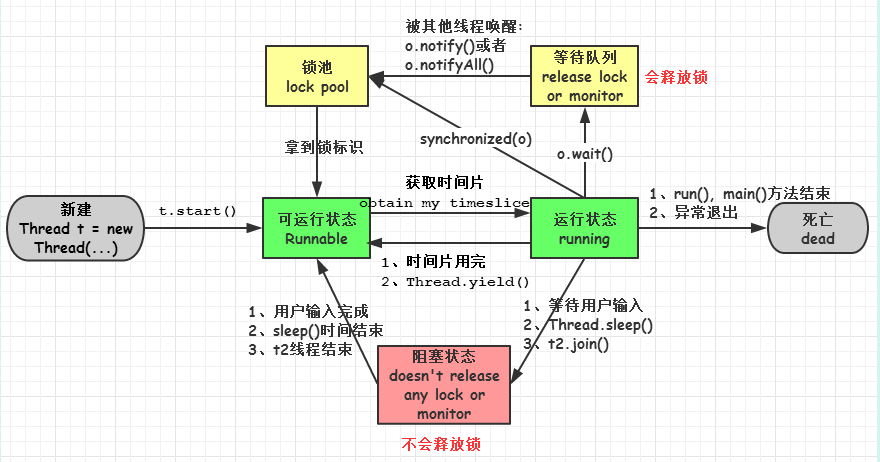
- �½�( new ):�´�����һ���̶߳���
- ������( runnable ):�̶߳�����,�����߳�(���� main �߳�)�����˸ö����start ()��������״̬���߳�λ�ڿ������̳߳���,�ȴ����̵߳���ѡ��,�� ȡ cpu ��ʹ��Ȩ ��
- ����( running ):������״̬( runnable )���̻߳���� cpu ʱ��Ƭ( timeslice ),ִ�г�����롣
- ����( block ):����״̬��ָ�߳���Ϊij��ԭ������� cpu ʹ��Ȩ,Ҳ���ó��� cpu timeslice ,��ʱֹͣ���С�ֱ���߳̽��������( runnable )״̬,���л����ٴλ�� cpu timeslice ת������( running )״̬�����������������:
(һ). �ȴ�����:����( running )���߳�ִ�� o.wait ()����,JVM ��Ѹ��̷߳� ��ȴ�����( waitting queue )�С�
(��). ͬ������:����( running )���߳��ڻ�ȡ�����ͬ����ʱ, ����ͬ����������߳�ռ��,�� JVM ��Ѹ��̷߳�������( lock pool )�С�
(��). ��������: ����( running )���߳�ִ�� Thread . sleep ( long ms )�� t.join ()����,���߷����� I / O ����ʱ,JVM ��Ѹ��߳���Ϊ����״̬���� sleep ()״̬��ʱ�� join ()�ȴ��߳���ֹ���߳�ʱ������ I / O �������ʱ,�߳�����ת�������( runnable )״̬��- ����( dead ):�߳� run ()�� main () ����ִ�н���,�������쳣�˳��� run ()����,����߳̽����������ڡ��������̲߳����ٴθ�����
55��ʵ���߳�ͬ�������ַ�ʽ?
1��ͬ�������:�ڴ�����ϼ��ϡ�synchronized���ؼ��ֵĻ�,��˴����ͳ�Ϊͬ���� ��顣
ͬ��������ʽ:
synchronized(���Ӷ���){
��Ҫͬ���Ĵ��� ;
}
����:���Ӷ���������:����String��.class �ļ�(ֻҪ�Dz���Ķ��������� �Ӷ���)
2��ͬ������
ͬ�����������ʽ:
synchronized ��������ֵ ��������(�����б�){
}
�ڷ����ϼ� synchronized,�ǰѵ�ǰ������Ϊ������
3��ͬ����
Lock lock = new ReentrantLock();(����������ֱ�� new)
lock.lock(); �м�Ĵ������м��� lock.unlock();
56��Java�е����м��ַ�ʽ?
- Synchronized
- Lock
Synchronized�ľ�����:
1).��������ȡ�����߳�����Ҫ�ȴ�IO��������ԭ��(�������sleep����)��������,������û���ͷ���,�����̱߳�ֻ�ܸɰͰ͵صȴ���(���������ͷ���)2).���ж���̶߳�д�ļ�ʱ,��������д�����ᷢ����ͻ����,д������д�����ᷢ����ͻ����,���Ƕ������Ͷ��������ᷢ����ͻ�����������̶߳�ֻ�ǽ��ж�����,���Ե�һ���߳��ڽ��ж�����ʱ,�����߳�ֻ�ܵȴ������ж�������(�������,һ������)
57��Lock�ļ���ʵ����?
ReentrantLock��һ��������Ļ�����,�ֱ���Ϊ����ռ����
ReadWriteLock,����˼��,�Ƕ�д������ά����һ����ص��� ��������ȡ�����͡�д������,һ�����ڶ�ȡ����,��һ������д���������������ʵ�������readerLock��д��writerLock��
58���̼߳�ͨ�ŵļ���ʵ�ַ�ʽ?
1��ʹ�� volatile �ؼ��֡����� volatile �ؼ�����ʵ���̼߳��ͨ����ʹ�ù����ڴ��˼��,������˼���Ƕ���߳�ͬʱ����һ������,��������������仯��ʱ�� ,�߳��ܹ���֪��ִ����Ӧ��ҵ����Ҳ�����һ��ʵ�ַ�ʽ��
2��ʹ��Object���wait() �� notify() ������Object���ṩ���̼߳�ͨ�ŵķ���:wait()��notify()��notifyaAl(),�����Ƕ��߳�ͨ�ŵĻ���,������ʵ�ַ�ʽ��˼����Ȼ���̼߳�ͨ�š�
ע��: wait�� notify�������synchronizedʹ��,wait�����ͷ���,notify�������ͷ���
59��synchronized �� Lock �������Ӧ�ó���?
1��Lock �ǽӿ�,�� synchronized �� Java �еĹؼ���,synchronized �����õ�����ʵ��;
2��synchronized �ڷ����쳣ʱ,���Զ��ͷ��߳�ռ�е���,��˲��ᵼ������������;�� Lock �ڷ����쳣ʱ,���û������ͨ�� unLock()ȥ�ͷ���,��ܿ��������������,���ʹ�� Lock ʱ��Ҫ�� finally �����ͷ���;
3��Lock �����õȴ������߳���Ӧ�ж�,�� synchronized ȴ����,ʹ��synchronized ʱ,�ȴ����̻߳�һֱ�ȴ���ȥ,���ܹ���Ӧ�ж�;
4��ͨ�� Lock ����֪����û�гɹ���ȡ��,�� synchronized ȴ���쵽��
5��Lock ������߶���߳̽��ж�������Ч�ʡ�
6��Lock ����� Synchronized ��ʵ�ֵ����й�������������˵,���������Դ������,Synchronized Ҫ���� Lock,����������Դ�dz�����ʱ(���д����߳�ͬʱ����),��ʱ Lock ������ҪԶԶ����synchronized������˵,�ھ���ʹ��ʱҪ�����ʵ����ѡ��
60��ΪʲôҪ���̳߳�?
�����߳�Ҫ���Ѱ������Դ��ʱ��,����������˲Ŵ����߳���ô��Ӧʱ���䳤,����һ�������ܴ������߳��� ���ޡ�Ϊ�˱�����Щ����,�ڳ���������ʱ��ʹ��������߳�����Ӧ����,���DZ���Ϊ�̳߳�,������߳̽й����̡߳���JDK1.5 ��ʼ,JavaAPI �ṩ�� Executor ���������Դ�����ͬ���̳߳ء����絥�̳߳�,ÿ�δ���һ�� ����;��Ŀ�̶����̳߳ػ����ǻ����̳߳�(һ���ʺϺܶ������ڶ̵�����ij���Ŀ���չ�̳߳�)��
61����δ����̳߳�?
1.�̳߳ض���ͨ���̳߳ع�������,�ٵ����̳߳��еķ�����ȡ�߳�,��ͨ���߳�ȥִ��������
Executors:�̳߳ش���������
2.�Լ����ݴ����̳߳ص������� new ����(ʹ��)
ע��:�̳߳ز�����ʹ�� Executors ȥ����,����ͨ�� ThreadPoolExecutor �ķ�ʽ,�����Ĵ�����ʽ��д��ͬѧ������ȷ�̳߳ص����й���,�����Դ�ľ��ķ��ա�
˵��:Executors ���ص��̳߳ض���ı�����:
1)FixedThreadPool �� SingleThreadPool:
������������г���Ϊ Integer.MAX_VALUE,���ܻ�ѻ�����������,�Ӷ�����OOM��
2)CachedThreadPool �� ScheduledThreadPool:
�����Ĵ����߳�����Ϊ Integer.MAX_VALUE,���ܻᴴ���������߳�,�Ӷ����� OOM��
�����Լ�ͨ�� new �ؼ��ִ��� newThreadPoolExecutor
62��Java�е��쳣��ϵ?

63��throw �� throws ������?
1��throws ���ں�����,����������쳣��,���Ը����;�� throw ���ں�����,������� ���쳣����
2��throws ���������쳣,�õ�����ֻ֪���ù��ܿ��ܳ��ֵ�����,���Ը���Ԥ�ȵĴ����� ʽ;throw �׳�������������,ִ�е� throw,���ܾ��Ѿ�������,��ת��������,�����������������������ߡ�Ҳ����˵ throw ����������ʱ,���治Ҫ�����������,��Ϊִ�в�����
3��throws ��ʾ�����쳣��һ�ֿ�����,����һ���ᷢ����Щ�쳣;throw�����׳����쳣, ִ�� throw ��һ�� �׳���ij���쳣����
4�����߶������������쳣�ķ�ʽ,ֻ���׳����߿����׳��쳣,���Dz����ɺ���ȥ�����쳣,�����Ĵ����쳣�ɺ������ϲ���ô�����
64��˵�� 5 ���������쳣?
1��NullpointException:��ָ���쳣 null ֵ����
2��IOExceptionIO �쳣 IO �����������쳣
3��SQLExceptionSQL ƴд�쳣,mybatis �е� sql ƴд�쳣
4��ClassNotFoundException ���Ҳ����쳣 һ��Ϊ jar ������ʧ�ܻ�����д spring ע��
5��ClassCastException ����ת���쳣