����Ŀ¼
����������
�������
-
����
�������Ե����Ƿ�,��ʵ�����ǻ������� -
ִ�й���
�����ͨ��->CPU��ȡ�ڴ��г���(���ź�����)->ʱ�ӷ�����������ͨ�ϵ�->�ƶ�CPU�ڲ�һ��һ��ִ��(ִ�ж��ٲ�ȡ����ָ����Ҫ��ʱ������)->�������->д��(���ź�)->д���Կ����(sout,����ͼ��)
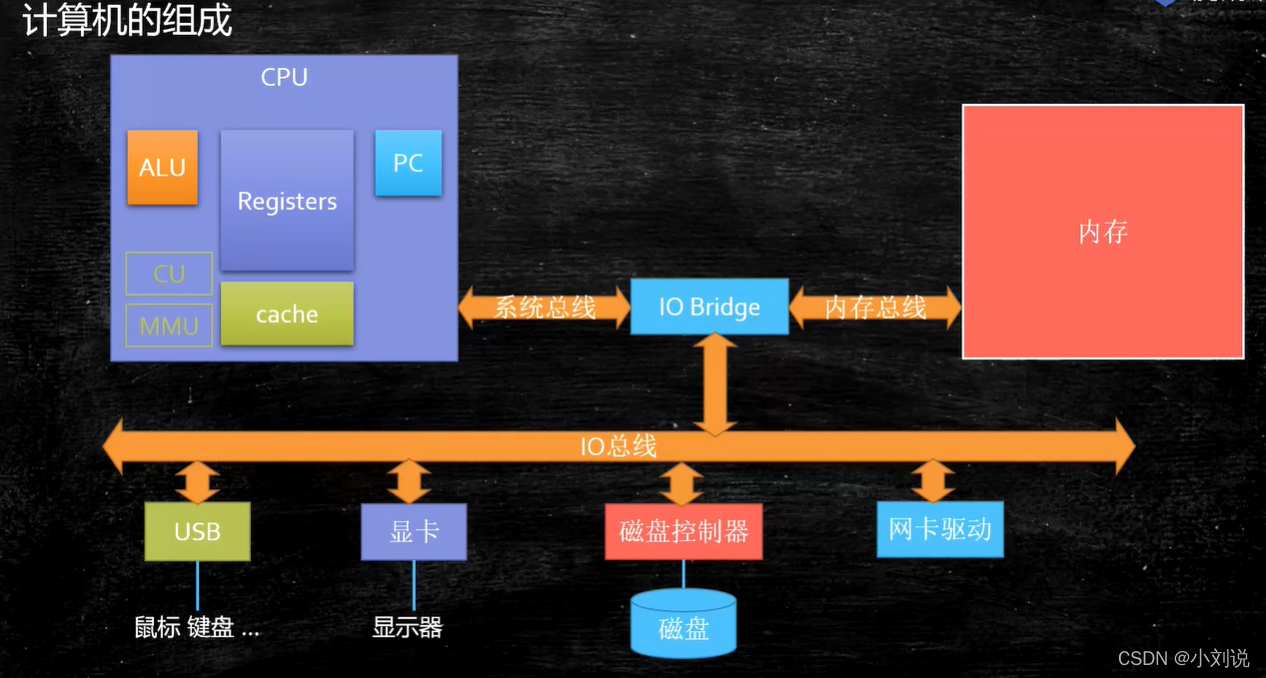
CPU
CPU ��ʲô
���봦����(CPU,Central Processing Unit)��һ�鳬���ģ�ļ��ɵ�·,��һ̨�������������ĺͿ��ƺ���,���Ĺ�����Ҫ�ǽ��ͼ����ָ��,�Լ���������������е�����
CPU �������
- PC
Program Counter ��������� ,��¼��ǰָ���ַ,ִ�����ǰָ��λ��Ϊ����Ӽ�ִ����һ������ - Registers
��ʱ�洢CPU������Ҫ�õ������� - ALU
Arithmetic & Logic Unit ���㵥Ԫ - CU
Control Unit ���Ƶ�Ԫ - MMU
Memory Management Unit �ڴ������Ԫ - cache
����,CPU��������,����CPU����һ������������,����CPU��������������
���߳�
һ��ALU��Ӧ���PC | Registers
����
-
������
������Խ��,�ֲ��Կռ�Ч��Խ��,����ȡʱ����
������ԽС,�ֲ��Կռ�Ч��Խ��,����ȡʱ���
ȡһ������ֵ,Ŀǰ����: 64 �ֽ� -
����һ����
MESI Cache һ����Э��,��Щ������������ݻ��߿�Խ��������е�����,��Ȼ����ʹ�������� -
�������
������Щ�ر����е�����,�ش����̸߳߾����ķ���,Ϊ�˱�֤������α����,����ʹ�û����ж��롣
ʹ�����ݲ���ͬһ��������
JDK7��,�ܶ����long padding ���Ч��
JDK8��,������@Contended ע��
����ִ��
- �ŵ�
���Ч��,ԭ��:CPU ��ָ������ - ��ֹ����
(1) CPU����
�ڴ�����,��ij�����ڴ�������ʱ�м���������,����ǰ��IJ�����������ִ��
(2) JVM �㼶
8�� hanppens-before ԭ��,4���ڴ�����(LL LS SL SS) - as if serial
�������������,���߳�ִ�н������
�ϲ�д
Write Combining Buffer,һ���ĸ��ֽ�,���� ALU �ٶ�̫��,������д�� L1 ��ͬʱ,д��һ�� WC Buffer,����֮��,ֱ�Ӹ��µ�L2
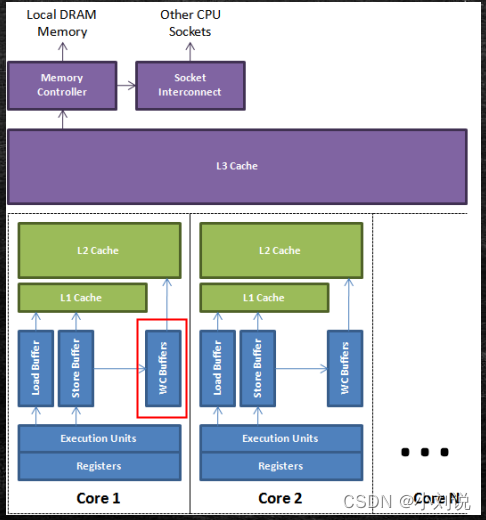
NUMA
- UMA �C Uniform Memory Access
���CPU ����һ���ڴ� - NUMA �C Non Uniform Memory Access
�����ڴ�����ȷ�����߳�����CPU������ڴ�
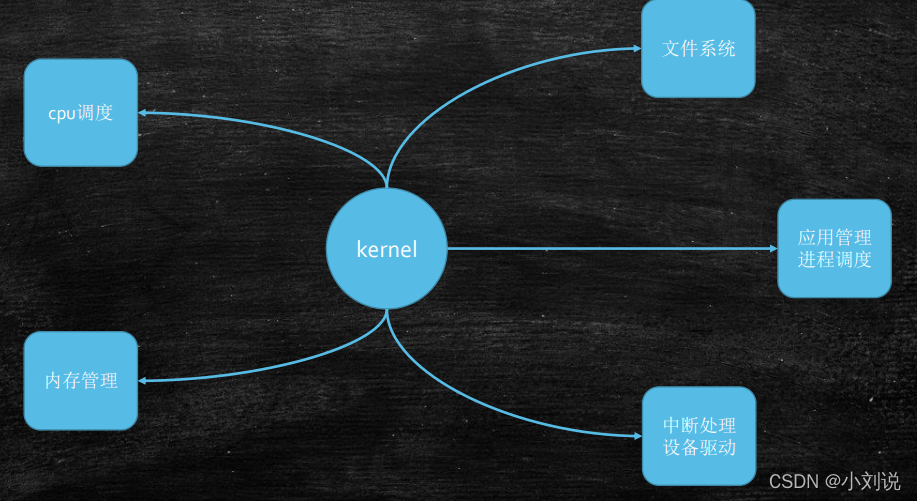
����ϵͳ(����linux)
����Ӳ��������Ӧ��
�ں�
- ���ں�

- �ں�
��ɢ�����Բ���,ռ�ý�С
���
ΪӦ�ö��Ʋ���ϵͳ
CPU ָ���
ring[0,1,2,3],�ں�̬ring0,�û�̬ring3,����ϵͳ�Ĺؼ�������Ҫ����kernel��ͬ��,��֤ϵͳ��׳��
���̹���
-
����
ϵͳ������Դ(�����ĵ�ַ�ռ䡢�ں����ݽṹ��ȫ�ֱ�����)�Ļ�����Ԫ -
�߳�
��ͨ�Ľ���,���������̹�����Դ,һ�������еIJ�ִͬ��·�� -
�˳�(Fiber)
�û�̬���߳�,�߳��е��߳�,�л��͵��ȶ�����Ҫ����OS
(1) �ŵ�
1.ռ����Դ���� OS����һ���߳� 1M ,����һ���˳� 4K
2.�л��Ƚϼ�
3.���������ܶ��
(2) Ӧ�ó���
�̵ܶļ�������,����Ҫ���ں˴�,�������� -
�ں��߳�
�ں�����֮����Ҫ��һЩ��̨����,��Щ���ں��߳������,ֻ���ں˿ռ����� -
���̵Ĵ�������
�ӽ���A��fock����B�Ļ�,AΪB�ĸ�����,ϵͳ����fork()->����,exec()->���� -
��ʬ���� �C defunct
�����̲����ӽ��̺�,��ά���ӽ��̵�һ��PCB(��Ž��̵Ĺ����Ϳ�����Ϣ�����ݽṹ)�ṹ,�ӽ����˳�,�и������ͷ�,���������û���ͷ����ӽ��̳�Ϊ��ʬ���� -
�¶�����
�ӽ��̽���֮ǰ,�������Ѿ��˳�,�¶����̻��Ϊһ���������(һ��Ϊ1�Ž���)�ĺ���,�ɴ��������ά�� -
���̺��߳���ʲô����
��:���̾���һ����������������״̬,�߳���һ�������еIJ�ͬ��ִ��·����
רҵ:������os������Դ�Ļ�����λ,�߳���ִ�е��ȵĻ�����λ��������Դ����Ҫ����:�������ڴ�ռ�,�̵߳���ִ��(�̹߳������̵��ڴ�ռ�,û���Լ��������ڴ�ռ�) -
�̺߳��˳�����
�˳����û�̬,jvm�Լ������Լ��л�,����˳̶�Ӧһ���߳� -
���̵���
(1) ��������
IO �ܼ��� �C ��ʱ�����ڵȴ�IO
CPU �ܼ��� �C �����ڼ���
(2)�������ȼ�
ʵʱ���� > ��ͨ����
(3) ������
����ռʽ �C ���ǽ��������ó�CPU,����һֱ����
��ռʽ �C �ɽ��̵�����ǿ�ƿ�ʼ����ͣ(��ռ)ijһ���̵�ִ�� -
���Ȳ���
Ĭ�ϲ��� :
ʵʱ���� -> ���ȼ����ߵ������� FIFO (First In First Out),���ȼ�һ���� RR (Round Robin)
��ͨ���� -> CFS (Completely Fair Scheduler, ��ȫ��ƽ�����㷨),�����ȼ�����ʱ��Ƭ�ı���,��¼ÿ�����̵�ִ��ʱ��,�����һ������ִ��ʱ�䲻��������ı���,����ִ�С�
���еȼ���ߵ���FIFO,���ֽ��̳����Լ��ó�CPU����ߵȼ���FIFO��RR��ռ�������һֱִ��,RRֻ���߳���ͬ����FIFO�е�ƽ�����䡣ֻ��ʵʱ���������ó�,����ִ����Ϻ�,��ͨ���̲��л���ִ��
�ж�(�ź�)
- Ӳ�ж�
Ӳ��������ϵͳ�ں˴���һ�ֻ��� - ���ж�
ϵͳ�ж�(80�ж�),int 0x80 ���� sysenter ԭ��
�ڴ����
-
��չ����
DOS ʱ��
ͬһʱ��ֻ����һ������������(Ҳ��һЩ�����㷨����֧�ֶ����)
Windows
�������װ���ڴ��ճ� :1���ڴ治���� 2���������
���:���������ڵ��ڴ����ϵͳ:��ҳװ��(����ڴ治��������) �����ַ(��������������) ��Ӳ�����Ѱַ -
��ҳ(����ڴ治����)
�ڴ��зֳɹ̶���С��ҳ��(��С4K),�ѳ���(Ӳ����)�ֳ�4K��С�Ŀ�,�õ���һ�������һ����ع������ڴ�����,�������õ�һ��ŵ�SWAP����,�����µ�һ����ؽ���,LRU �㷨
����
SWAP ����

LRU �㷨
�������ʹ��,��һ�ֳ�����ҳ���û��㷨,ѡ��������δʹ�õ�ҳ�������̭��ϣ��(��֤���Ҳ���O(1))+ ˫������ (��֤�����������������)
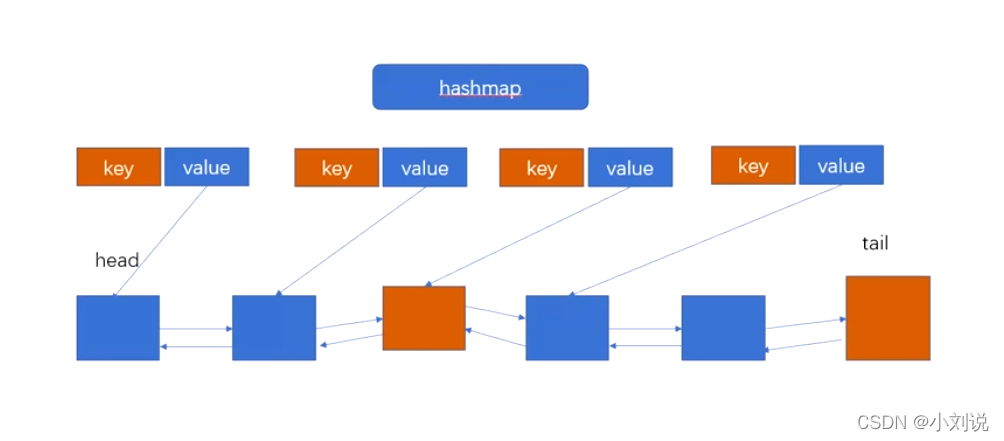
-
�����ڴ�(��������������)
ÿһ������ӵ������ռ�,�ý��̹���������ռ�,�������õ��Ŀռ��ַ������ֱ�ӵ�������ַ,��������ĵ�ַ,��֤A������Զ�����ܷ��ʵ�B���̵Ŀռ�
(1) ����ռ��С
Ѱַ�ռ� - 64λϵͳ 2^64 byte,�������ռ��ܶ�
(2) ʹ���ŵ�
1������Ӧ�ó���
2��ÿ��������Ϊ�Լ����������õ��ڴ�
3��ͻ�������ڴ�����
4��Ӧ�ó�����Ҫ���������ڴ��Ƿ���,�Ƿ��ܹ�����ȵײ����ⰲȫ
5�����������ڴ�,�������������� -
�����ַӳ��������ַ
����ַ = �εĻ���ַ
���Ե�ַ = ƫ���� + �εĻ���ַ
������ַ = ���Ե�ַͨ�� OS + MMU
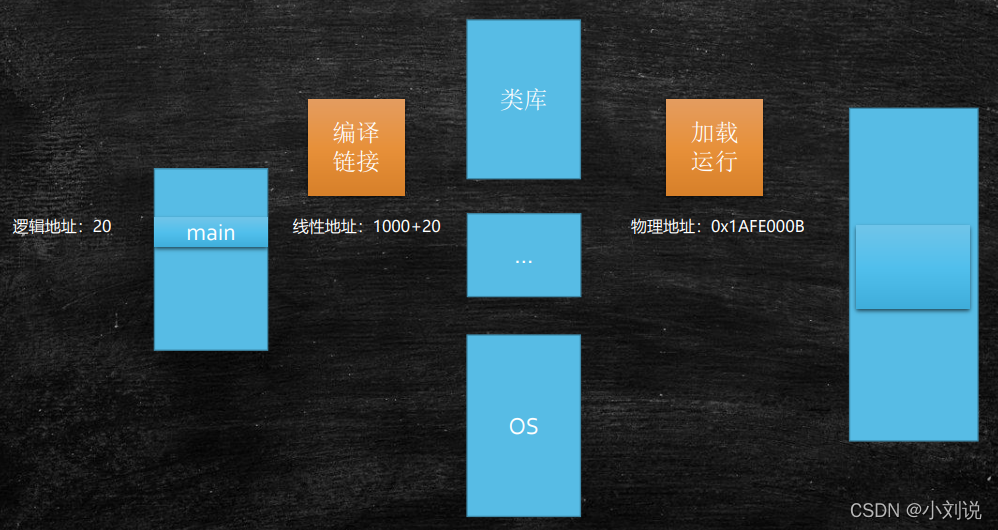
-
ȱҳ�ж�
��Ҫ�õ���ҳ���ڴ���û��,����ȱҳ�쳣(�ж�),���ں˴���������
����
����������ָ���һ����,����:�������� ��ַ���� ��������,��ַ����Ŀǰ48λ
�ں�ͬ��
��������
1���ٽ���(critical area) �C ���ʻ������������ݵĴ����(synchronized �����Ų���)
2����������(race conditions) �C �����߳�ͬʱӵ���ٽ�����ִ��Ȩ
3�����ݲ�һ��(data unconsistency) �C �ɾ�����������������ƻ�
4��ͬ��(synchronization) �C ���⾺������
5���� �C ���ͬ�����ֶ�
6��ԭ���� �C ��ԭ��һ�����ɷָ�IJ���
7�������� �C ����ָ������
8���ɼ��� �C һ���߳��ڵ���,��һ���߳̿ɼ�
�ں�ͬ�����÷���
1��ԭ�Ӳ��� �C �ں���������AtomicXXX
2�������� �C �ں���ͨ�����֧�ֵ�CAS
3������д���� �C ������ReadWriteLock,��ͬʱ��,ֻ��һ��д
4������ʱ������,д��ʱ��������
5���ź��� �C ������ Semaphore (down up ����,ռ�к��ͷ�)
6����������,�̻߳����wait,�ʺϳ�ʱ����е������
7������д�ź��� �C ���д,���Էֶ�д,�ֶ���
8�������� �C ������ź���(��ֵ�ź���)
9����ɱ��� �C ������ź���,�ӽ��̽���ʱͨ����ɱ������Ѹ�����,������Latch
10�����ں��� �C ����,���ڲ�����
11��˳���� �C �߳̿��Թ���Ķ�д������
���м�����(��0��ʼ,дʱ +1 ,д���ͷ� +1,��ǰ�����ǵ���,˵����д�߳�,�ȴ�,��ǰ������һ��,˵��û��д�̴߳��,����д��˵�Ƕ�ռ)
12����ֹ��ռ �C
13���ڴ����� �C volatile