目录
堆内存诊断:
1.jps:查看当前系统有多少线程;
2.jmap:查看堆内存的占用情况:jmap -heap[pid]
3.jconsole:图形界面,可连续检测:jconsole[pid],可以在图形界面执行GC
当我们需要抓取堆快照时,可以采用:jvisualvm或者MAT
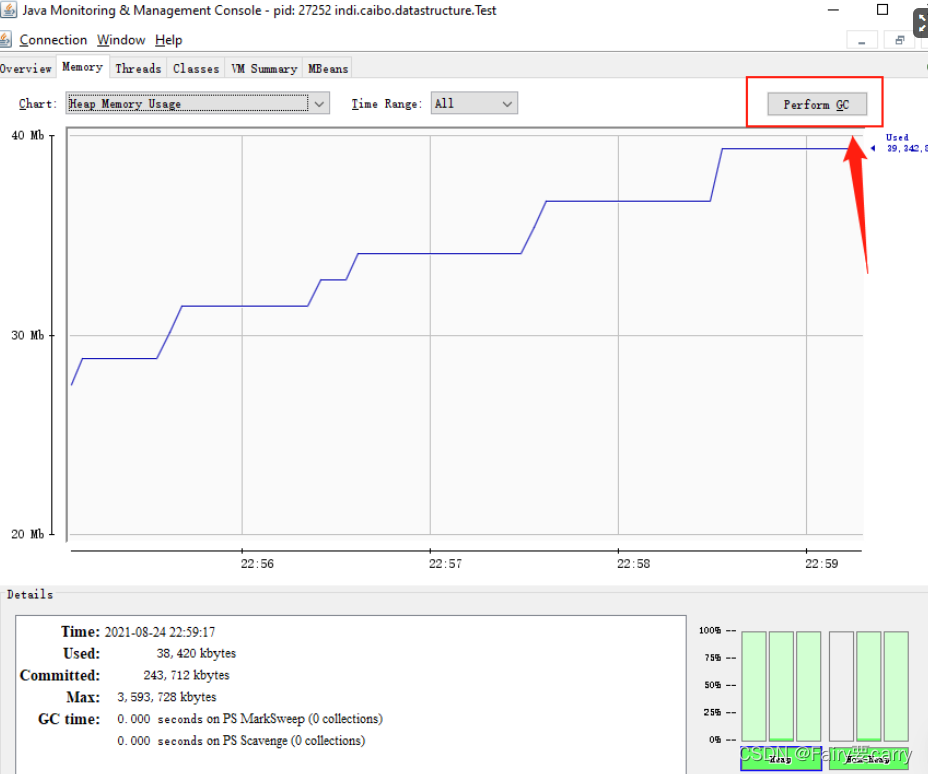
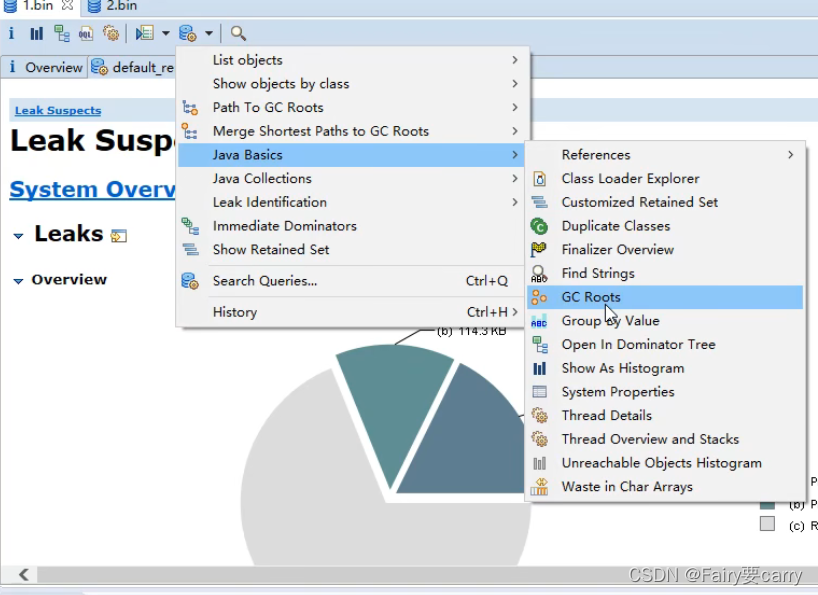
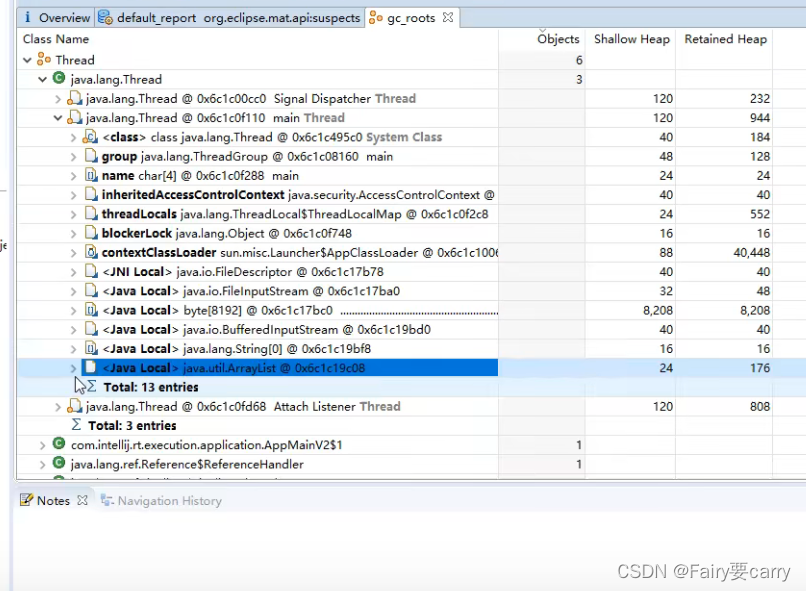
?MAT(可以用来查看根对象,因为根对象及其引用的对象是不会被垃圾回收的)
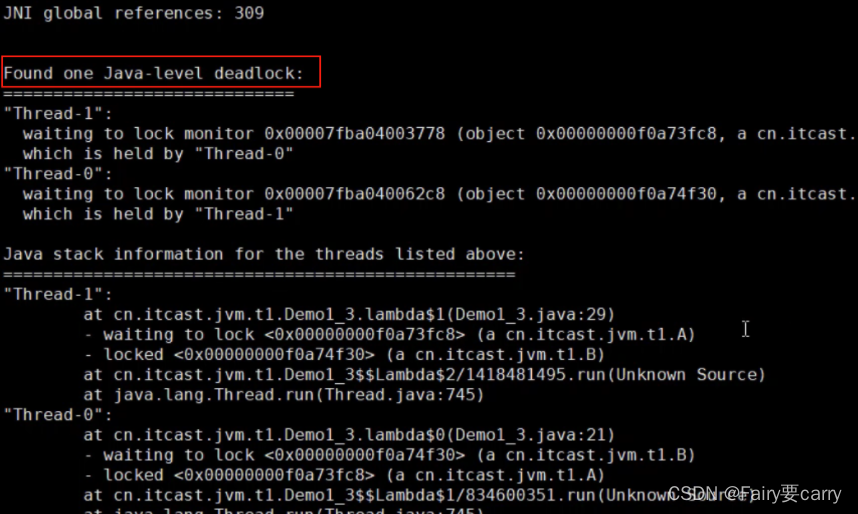
利用jstack分析线程状况:
使用Linux命令和jstack工具分析Java进程堆栈情况:如何使用jstack分析线程状态 - Jessica程序猿 - 博客园
此外如果发生了线程死锁,会在jstack命令的最后面展示:
?字符串拼接新的感悟:
字符串拼接一定要看发生的时期:是编译时期还是运行时期,因为时期不同,后面或者前面的一些变量就会加载,所以说这关系到字符串的拼接是否能入串池;
1.拼接字符串对象创建字符串,其实底层是调用StringBuilder来进行拼接,并且最后调用StringBuilder.toString()方法返回字符串对象。最后返回的这个对象是存在于堆内存的,并不是在串池中。
2.字符串常量拼接创建新的字符串时,因为内容是常量,javac编译器会在编译期进行优化,直接计算得到结果;如果常量池中有这个值,就直接获取;如果常量池中没有这个值,就加入常量池并且获取。
3.使用拼接字符串变量的方法来创建新的字符串时,因为内容是变量,只能在运行期确定它的值,所以需要使用StringBuilder来创建
例子:
public class Main {
public static void main(String[] args) {
//"a" "b" 被放入串池中,str则存在于堆内存之中
String str = new String("a") + new String("b");
//调用str的intern方法,这时串池中没有"ab",则会将该字符串对象放入到串池中,此时堆内存与串池中的"ab"是同一个对象
String st2 = str.intern();
//给str3赋值,因为此时串池中已有"ab",则直接将串池中的内容返回
String str3 = "ab";
//因为堆内存与串池中的"ab"是同一个对象,所以以下两条语句打印的都为true
System.out.println(str == st2);
System.out.println(str == str3);
}
}package Demo;
/**
* @author diao 2022/2/14
*/
public class Demo2 {
public static void main(String[] args) {
//他是按步骤来的,两个常量ab先放在串池中,然后在堆中创建了a与b,然后连接放入ab放入堆中;
String s=new String("a")+new String("b");//s是堆中的
// 此时串池中是[a,b,ab]
String x="ab";
//因为串池中是不存在相同的串的;
String s2=s.intern();//记住是在串池中找,如果有的话就返回串池中的对象,如果没有就自己创建一个并且返回
// s.intern()应该是找ab在串池中,返回给x的ab,所以第一个为true;
System.out.println(s2==x);
System.out.println(s==x);
}
}
JDK1.6和JDK1.8中intern()方法的区别:
1.6:如果串池中没有该字符串对象,会将该字符串对象复制一份,再放入到串池中;如果有该字符串对象,则放入失败。无论成功与否,都会返回串池中的对象。但由于是拷贝一份放入串池,因此无论成功与否,原来的字符串对象都指向堆内存。
1.8:调用字符串对象的intern()方法,会尝试将该字符串对象放入串池中。
若串池中没有该字符串对象,则加入成功,否则加入失败。无论成功与否,都会返回串池中的对象。若加入成功,原字符串会指向串池中的对象,若加入失败,原字符串对象的指向不会变,还是指向堆内存中的对象;
区别就是给了str一个机会让他有资格加入串池;
?
StringTable:
调优:因为StringTable是HashTable实现的,因此可以适当增加HashTable桶的个数来减少哈希冲突,从而减少垃圾回收的时间;
-xx:StringTableSize=xxx若进行大量字符串操作,而且这些字符串很可能有重复值,可以考虑将字符串加入StringTable,这样只会保留一份
直接内存:
简而言之,就是操作系统和Java代码都可以访问的一块区域,比较方便;
怎么就方便了呢?
?例子:像读取文件,如果是普通IO:你需要开启两个缓存空间(1.系统内存,java代码不能直接进行访问,2.java堆内存)――>所以说,只有进了Java堆内存才能进行读写操作;
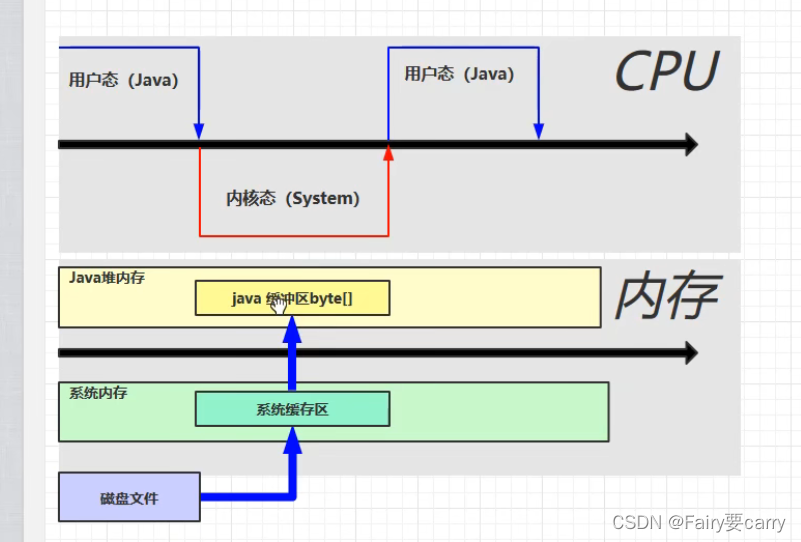
直接内存(用NIO读取):
开辟了一块直接内存,java代码可以直接进行访问,相同于桥梁一样的角色;
好处:读写性能较好,不受JVM内存回收管理;
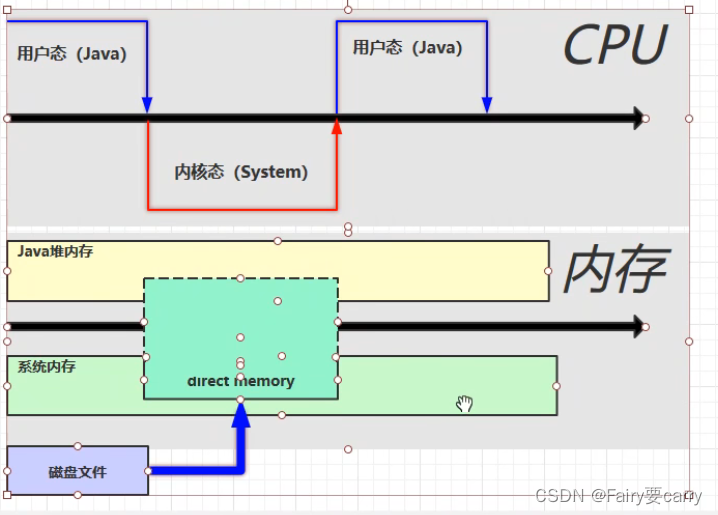
直接内存的申请:
//通过ByteBuffer申请1M的直接内存
ByteBuffer byteBuffer = ByteBuffer.allocateDirect(_1M);package Demo;
import java.io.IOException;
import java.nio.ByteBuffer;
/**
* @author diao 2022/2/15
*/
public class demo10 {
static int _1Gb=1024*1024*1024;
public static void main(String[] args) throws IOException {
//分配直接内存ByteBuffer与unSafe关联
ByteBuffer byteBuffer = ByteBuffer.allocateDirect(_1Gb);
System.out.println("分配完毕...");
System.in.read();
System.out.println("开始释放");
//开始回收
byteBuffer=null;
// 显示的垃圾回收(Full GC老年代新生代都会回收)
/*可以加参数 -xx:+DisableExplicitGC 显示的
* */
System.gc();
System.in.read();
}
}
直接内存释放原理:
ByteBuffer中封装了DirectByteBuffer类――>里面使用了unsafe类来完成直接内存的分配回收;
public static ByteBuffer allocateDirect(int capacity) {
return new DirectByteBuffer(capacity);
} public void run() {
if (address == 0) {
// Paranoia
return;
}
unsafe.freeMemory(address);
address = 0;
Bits.unreserveMemory(size, capacity);
}
}回收需要主动调用freeMemory()方法;
allocateMemory()申请内存;
1.ByteBuffer内部实现用来Cleaner来检测ByteBuffer,一旦ByteBuffer被回收,Referencehandler就会调用Cleaner中的clean方法调用freeMemory来释放内存;
DirectByteBuffer(int cap) { // package-private
super(-1, 0, cap, cap);
boolean pa = VM.isDirectMemoryPageAligned();
int ps = Bits.pageSize();
long size = Math.max(1L, (long)cap + (pa ? ps : 0));
Bits.reserveMemory(size, cap);
long base = 0;
try {
base = unsafe.allocateMemory(size); //申请内存
} catch (OutOfMemoryError x) {
Bits.unreserveMemory(size, cap);
throw x;
}
unsafe.setMemory(base, size, (byte) 0);
if (pa && (base % ps != 0)) {
// Round up to page boundary
address = base + ps - (base & (ps - 1));
} else {
address = base;
}
cleaner = Cleaner.create(this, new Deallocator(base, size, cap)); //通过虚引用,来实现直接内存的释放,this为虚引用的实际对象
att = null;
}public void run() {
if (address == 0) {
// Paranoia
return;
}
unsafe.freeMemory(address); //释放直接内存中占用的内存
address = 0;
Bits.unreserveMemory(size, capacity);
}JVM垃圾回收:
如何判断对象可以回收:
1.引用计数法:
记录对象被引用了多少次,弊端是无法解决循环引用的问题,因此JVM并不会简单采用此方法。
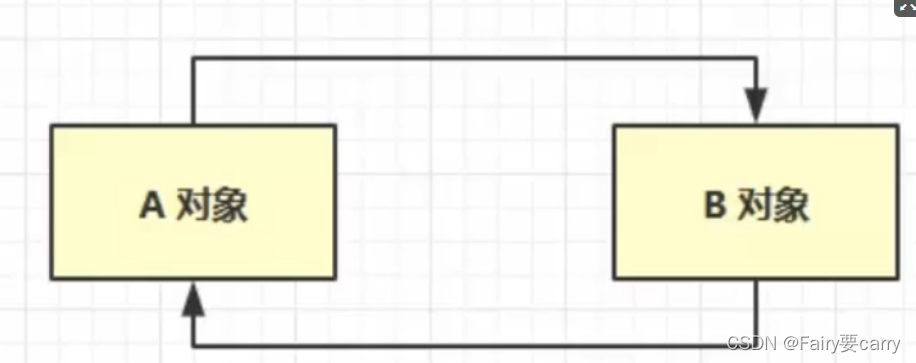
?
?2.可达分析:
垃圾回收器会通过可达分析来去寻找所有存活对象;
扫描堆中对象,根据GC Root对象作为起点的引用链找到对象,如果找不到就回收;
哪些可以作为GC Root的对象?
虚拟机栈(栈帧中的本地变量表)中引用的对象。
方法区中类静态属性引用的对象
方法区中常量引用的对象
本地方法栈中JNI(即一般说的Native方法)引用的对象
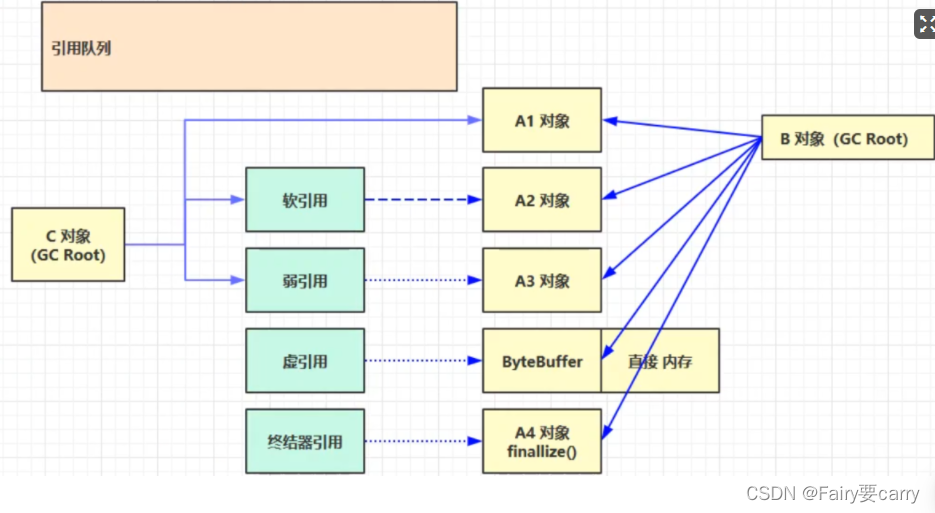
?五种引用:
强引用:
Java中默认声明的就是强引用,只要强引用存在,垃圾回收器将永远不会回收被引用的对象,哪怕内存不足时,JVM也会直接抛出
OutOfMemoryError,不会去回收。如果想中断强引用与对象之间的联系,可以显示的将强引用赋值为null,这样一来,JVM就可以适时的回收对象了;意思就是只有GC Root不引用该对象 ,这个对象才能被回收
Object obj = new Object(); //只要obj还指向Object对象,Object对象就不会被回收 obj = null; //手动置null
软引用:
本质上是描述那些非必需但是有用的对象;只有内存够的时候,软引用引用的对象就不会被回收,内存不足时,系统则会回收这些软引用对象,若回收之后内存还是不够,就会抛出异常;――>例如缓存
public class Demo1 { public static void main(String[] args) { final int _4M = 4*1024*1024; //使用软引用对象 list和SoftReference是强引用,而SoftReference和byte数组则是软引用 List<SoftReference<byte[]>> list = new ArrayList<>(); SoftReference<byte[]> ref= new SoftReference<>(new byte[_4M]); } }
那么问题来了,软引用这个引用他实际上也是占用内存的,那么怎么将引用给清理呢?
需要用到引用队列;
package Demo;
import java.lang.ref.Reference;
import java.lang.ref.ReferenceQueue;
import java.lang.ref.SoftReference;
import java.util.ArrayList;
import java.util.List;
/**
* @author diao 2022/2/15
*/
/*-Xmx20m -XX:printGCDetails -verbose:gc(打印垃圾详细参数)
* */
//当内存不够时,软引用中的byte[]资源就会被释放;
public class demo_ruanyingyong {
private static final int _4m=1024*1024*4;
//list->SoftReference->byte[]:弱引用对象引用byte[]
public static void main(String[] args) {
List<SoftReference<byte[]>> list = new ArrayList<>();
// 引用队列
ReferenceQueue<Object> referenceQueue = new ReferenceQueue<>();
for(int i=0;i<5;i++){
//new一个软引用对象,并且封装创建内存; 关联了引用队列
//当软引用所关联的byte[]数组被回收时,你这个软引用就会自己加入到引用队列中
SoftReference<byte[]> softReference = new SoftReference<>(new byte[_4m],referenceQueue);
System.out.println(softReference.get());
list.add(softReference);
System.out.println(list.size());//打印集合中元素数量
}
//将队列先进的软引poll出来,Reference是SoftReference的父类
Reference<?> poll = referenceQueue.poll();
while(poll!=null){
list.remove(poll);//集合将多余的软引用去除
poll=referenceQueue.poll();//引用队列poll出软引用,如果还有软引用的话就进行下一次循环
}
//放完之后。我们再来遍历一遍
System.out.println("循环结束"+list.size());
System.out.println("============");
for (SoftReference<byte[]>ref : list) {
System.out.println(ref.get());
}
}
}
弱引用:
引用强度<软引用,无论内存是否足够,只要JVM进行垃圾回收,弱引用引用的对象都会被回收;
而软引用的话:必须内存满了进行垃圾回收才能将对象回收;
package Demo;
import java.lang.ref.WeakReference;
import java.util.ArrayList;
/**
* @author diao 2022/2/15
*/
//弱引用对象new WeakReference<>(new byte[_4MB])这玩意超20,开始对前面的进行垃圾回收,以便于当前弱引用对象引用的byte[]有内存
public class demo_ruoyingyong {
private static final int _4MB=4*1024*1024;
public static void main(String[] args) {
// list->WeakReference->byte[]
ArrayList<WeakReference<byte[]>> list = new ArrayList<>();
for(int i=0;i<10;i++){
//弱引用对象引用byte[]
WeakReference<byte[]> weakReference = new WeakReference<>(new byte[_4MB]);
//将弱引用添加到集合当中
list.add(weakReference);
for (WeakReference<byte[]> reference : list) {
System.out.println(reference.get()+" ");
}
System.out.println();
}
System.out.println("循环结束:"+list.size());
}
}
虚引用:
虚引用跟以上最明显的一个区别就是,虚引用对象创建的时候会被强制关联引用队列;
这里我们来回顾一下直接内存释放:
为了释放引用内存,在引用队列中要释放的引用会直接创建一个直接内存,并且将直接内存地址给到虚引用引用的对象;然后根据虚引用引用的对象的方法Unsafe.freeMemory()调用直接内存地址――>将直接内存回收;
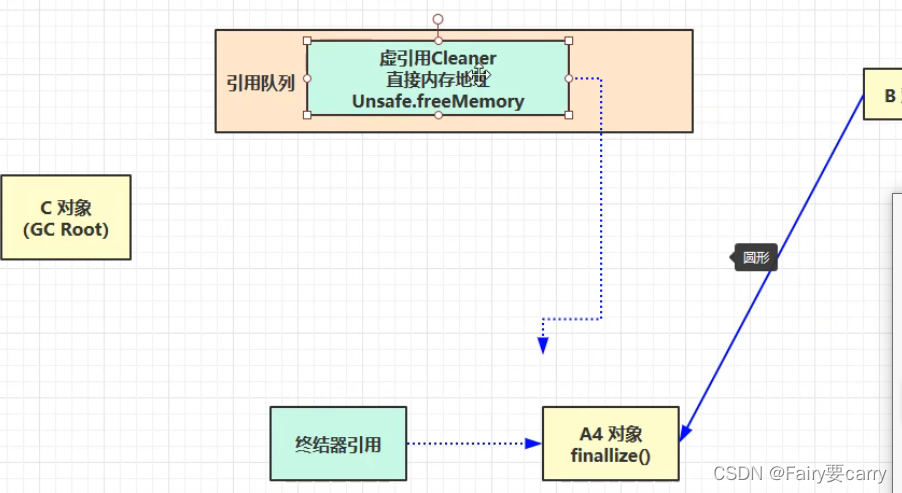
?终结器引用:
所有Java对象都会继承Object对象――>里面有finalize终结方法;
当没有强引用引用我们这个对象的时候,JVM会创建对应的终结器引用,当垃圾回收时,
终结器引用会被放到引用队列中――>下次回收时,对应线程才会将其回收(调用终结器引用对象的finalize方法)――>优先级很低
垃圾回收算法:
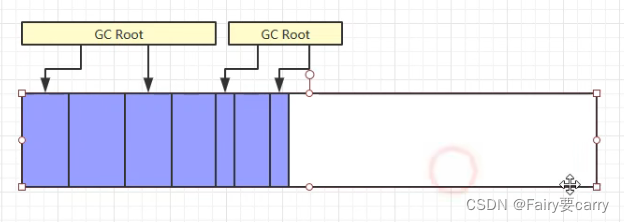
标记清除:
没有被根对象GC root标记――>垃圾回收
流程:
1.先标记 ;2.清除(记录要被清除内存的地址放在地址列表中,下次分配内存的时候,就把内存给到新的对象)
缺点:这样清除后,内存空间是不连续的,所以大的对象会放不进,造成资源浪费;
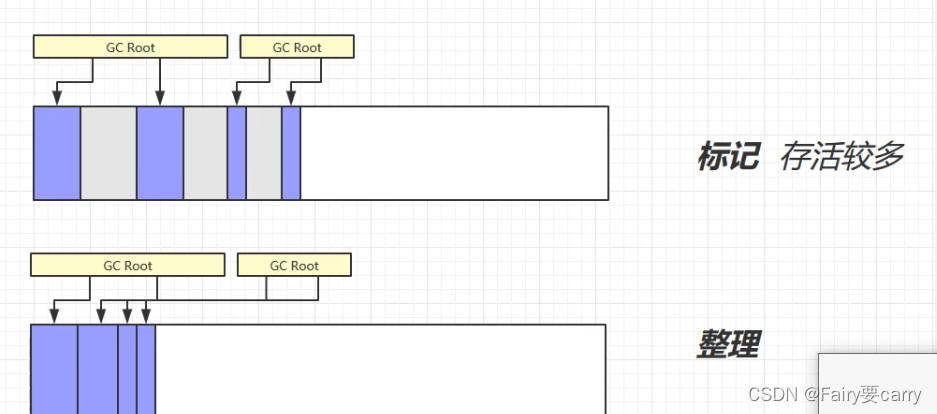
标记整理:
特点:标记之后会整理内存,不会造成内存空间浪费;
缺点:需要清除对象发生了移动,所以说引用这种对象的引用就要改变引用地址――>速度变慢;
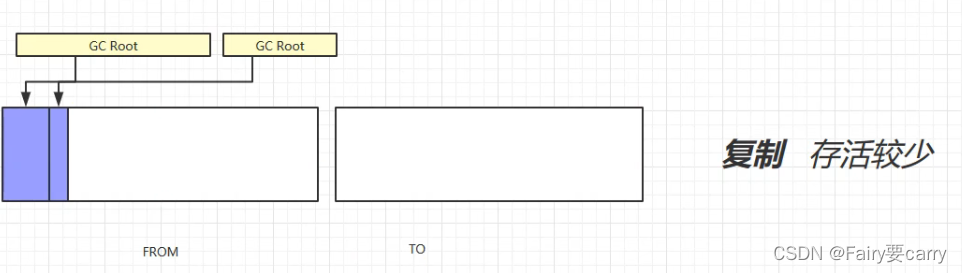
复制:
特点:先标记,然后将要被清除内存的对象放到另外一个内存中,最后交换内存;
缺点:占用内存过大,用了双倍内存;
?JVM分代回收机制:
为什么要进行分代回收?
堆内存是虚拟机管理的内存中最大的一块,也是垃圾回收最频繁的一块区域,我们程序所有的对象实例都存放在堆内存中。给堆内存分代是为了提高对象内存分配和垃圾回收的效率。
试想一下,如果堆内存没有区域划分,所有的新创建的对象和生命周期很长的对象放在一起,随着程序的执行,堆内存需要频繁进行垃圾收集,而每次回收都要遍历所有的对象,遍历这些对象所花费的时间代价是巨大的,会严重影响我们的GC效率,这简直太可怕了。
有了内存分代,情况就不同了,新创建的对象会在新生代中分配内存,经过多次回收仍然存活下来的对象存放在老年代中,静态属性、类信息等存放在永久代中,新生代中的对象存活时间短,只需要在新生代区域中频繁进行GC,老年代中对象生命周期长,内存回收的频率相对较低,不需要频繁进行回收,永久代中回收效果太差,一般不进行垃圾回收,还可以根据不同年代的特点采用合适的垃圾收集算法。
分代收集大大提升了收集效率,这些都是内存分代带来的好处。
总结:
1.分代之后不同年代回收频率不一样。
2.不同年代回收算法不一样。
既然这样,我们是不是要直到堆内存是怎样划分区域的呢?
JVM堆内存模型:
新生代:用完就可以丢弃的对象放在新生代
老年代:经常要用的,长时间存活
例子:
在楼下设置一个垃圾场,每天都有丢的,丢的比较频繁,所以说楼下的垃圾场可以说是新生代,保洁每天都会去垃圾场清理;
而家里的收藏堆就可以理解为老年代,到一定时候的时候才会需要保洁来清理;
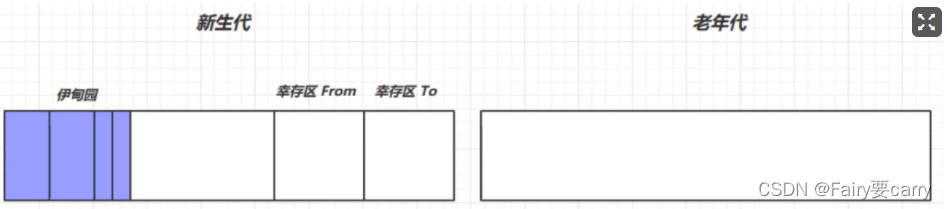
?回收流程:
- 对象首先分配在伊甸园区域
- 新生代空间不足时,触发 minor gc,伊甸园和 from 存活的对象使用 copy 复制到 to 中,存活的对象年龄加 1并且交换 from to
- minor gc 会引发 stop the world,暂停其它用户的线程,等垃圾回收结束,用户线程才恢复运行
- 当对象寿命超过阈值时,会晋升至老年代,最大寿命是15(4bit)
- 当老年代空间不足,会先尝试触发 minor gc,如果之后空间仍不足,那么触发 full gc,STW的时间更长
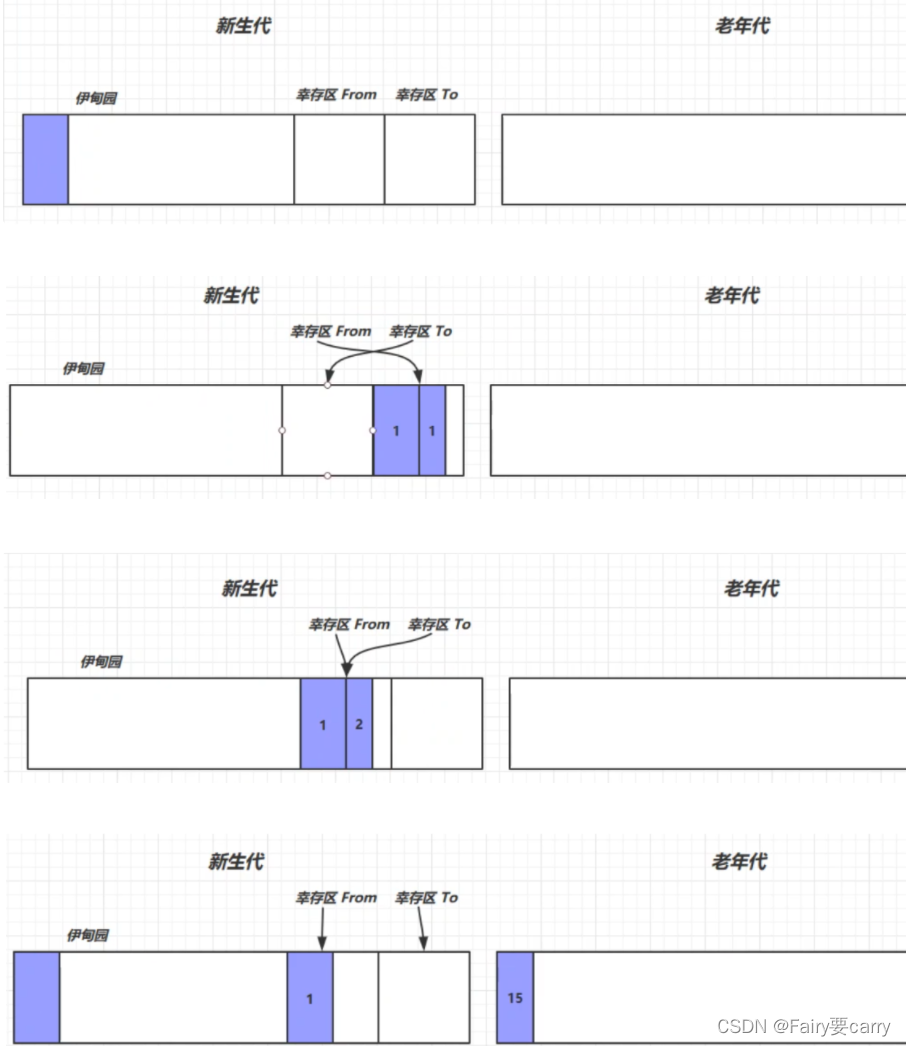
?GC分析:
大对象处理策略:
若创建的对象直接就大于了伊甸园容量,则直接晋升为老年代中;
package Demo; import java.util.ArrayList; /** * @author diao 2022/2/16 */ public class demo14 { private static final int _512KB=512*1024; private static final int _1MB=1024*1024; private static final int _6MB=6*1024*1024; private static final int _8MB=8*1024*1024; private static final int _7MB=7*1024*1024; //-Xms20M -Xmx20M -Xmn10M -XX:+UseSerialGC -XX:+PrintGCDetails -verbose:gc public static void main(String[] args) { ArrayList<byte[]> list = new ArrayList<>(); //当新生代容纳不下时,就算是GC也放不了时,它会直接放到老年代中,并且不会触发垃圾回收(ref new) list.add(new byte[_8MB]); // 这两个byte数组对象都是由GC root(ArrayList)引用 // 会发现当超过老年代内存与新生代内存时,会OutOfMemoryError list.add(new byte[_8MB]); } }线程内存溢出
某个线程的内存溢出了而抛异常(out of memory),不会让其他的线程结束运行
这是因为当一个线程抛出OOM异常后,它所占据的内存资源会全部被释放掉,从而不会影响其他线程的运行,进程依然正常
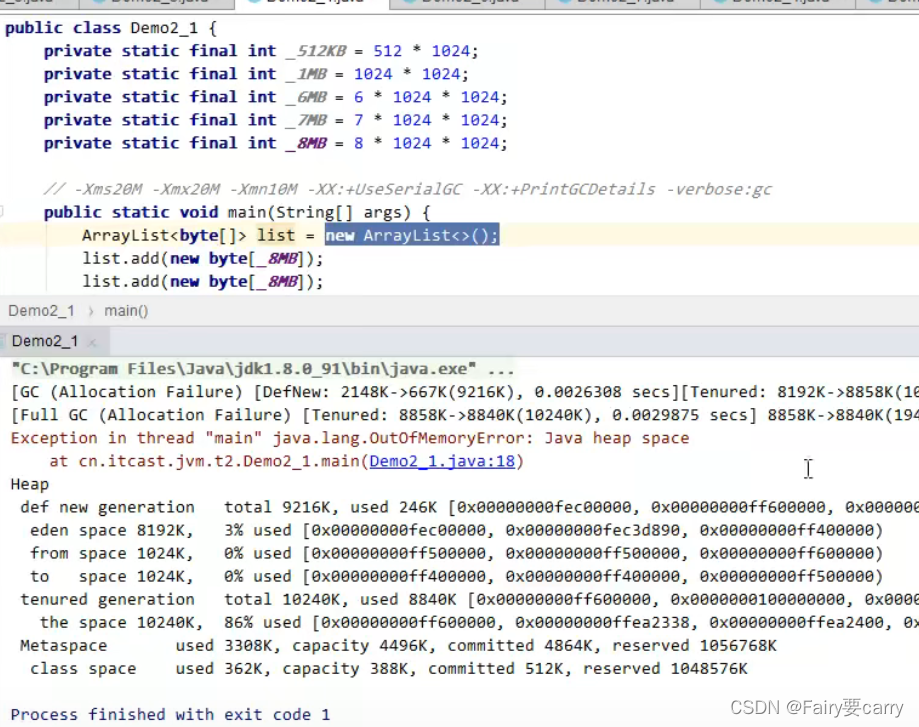
相关JVM参数

之前我们讲了垃圾回收的几种算法,那么垃圾回收器有哪几种呢?
垃圾回收器
大致分类:
1.串行:单线程的垃圾回收器(其他线程会因为他的垃圾回收而暂停):堆内存较小的时候,适合个人电脑;->就跟保洁打扫楼区卫生一样;
2.吞吐量优先:
多线程->就是多找几个保洁,去加快速度(适合堆内存较大的场景,多核cpu);
为什么要多个cpu?
因为你多个保洁如果放在一个cpu上的话,就会并发,也就是说轮流垃圾回收,这样就很慢了;
所以我们多个cpu就可以实现并行操作,以至于实现堆内存较大时的垃圾回收;
3.响应时间优先:
多线程,多个保洁―>堆内存较大,并发,
吞吐量优先和响应时间优先的不同之处:
吞吐量优先是注重效率的:一次垃圾回收清理的较多,其他线程等待耗时较长――>吞吐量优先,也就是垃圾回收器回收时间更长;
响应式时间优先:是注重时间的,意思就是它会将垃圾回收分很多次,以此来加快时间,但是每次清理的内存没有吞吐量优先那么多;

相关概念:
并行收集:指多条垃圾收集线程并行工作,但此时用户线程仍处于等待状态。
并发收集:指用户线程与垃圾收集线程同时工作(不一定是并行的可能会交替执行)。用户程序在继续运行,而垃圾收集程序运行在另一个CPU上
吞吐量:即CPU用于运行用户代码的时间与CPU总消耗时间的比值(吞吐量 = 运行用户代码时间 / ( 运行用户代码时间 + 垃圾收集时间 )),也就是。例如:虚拟机共运行100分钟,垃圾收集器花掉1分钟,那么吞吐量就是99%
安全点:让其他线程都在这个点停下来,以免垃圾回收时移动对象地址,使得其他线程找不到被移动的对象