今天摸鱼的时候接到一个需求
有如下数据
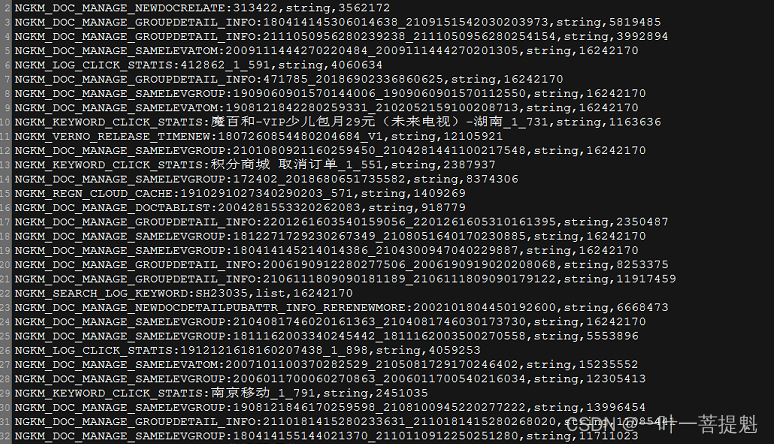
在一个文件夹里大概800M 需要统计 每一个 NGKM_********* :前的 数量
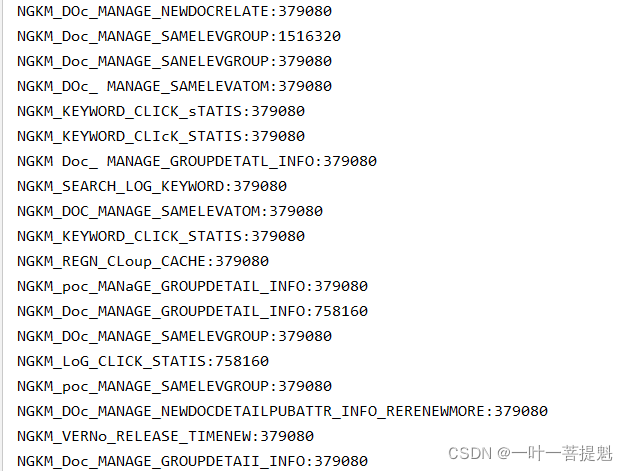
输出
问题分析
看见这个需求 第一反应是 正则写
因为是特定格式吗
我写的是这样的 因为正则不会
String rgex = "(((NGKM)|(ngkm))(.*?)(\\:))";
这样能在特定的字符串里找出要的内容了
但是字符串哪里来? 肯定是在文件里读取了
但是文件读取的类那么多用那个?
如果都保存在字符串里肯定保存不完
保存在lis里? 800M 的数据会堆溢出的
想到了一个方法 一行一行读取
然后匹配保存
大致代码如下
但是 800M的数据跑了 24秒 太慢了
有好的方法私信我
import java.io.BufferedReader;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* 正则表达式匹配两个字符串之间的内容
*
* @author Administrator
*/
public class test {
public static void main(String[] args) throws IOException {
// 使用ArrayList来存储每行读取到的字符串
long startTime = System.currentTimeMillis();
Map<String, Integer> map = new HashMap<String, Integer>();
try {
FileReader fr = new FileReader("G:\\key.txt");
BufferedReader bf = new BufferedReader(fr);
String str;
// 按行读取字符串
while ((str = bf.readLine()) != null) {
String rgex = "(((NGKM)|(ngkm))(.*?)(\\:))";
List<String> lists =getSubUtil(str, rgex);
for (String string : lists) {
if (map.containsKey(string)) {
map.put(string, map.get(string) + 1);
} else {
map.put(string, 1);
}
}
}
bf.close();
fr.close();
} catch (
IOException e) {
e.printStackTrace();
}
map.forEach((k, v) ->
{
System.out.println(k + v);
});
long endTime = System.currentTimeMillis(); //获取结束时间
System.out.println("程序运行时间:" + (endTime - startTime) + "ms");
}
/**
* 正则表达式匹配两个指定字符串中间的内容
*
* @param soap
* @return
*/
public static List<String> getSubUtil(String soap, String rgex) {
List<String> list = new ArrayList<String>();
Pattern pattern = Pattern.compile(rgex);// 匹配的模式
Matcher m = pattern.matcher(soap);
while (m.find()) {
int i = 1;
list.add(m.group(i));
i++;
}
return list;
}
}