摘要:本文介绍一种由北京联高软件开发有限公司实现的对C#|Java源代码进行深度混淆,进而保护原创代码的技术与软件――DeepConfuser。不同于市面上的其他混淆工具软件,DeepConfuser用最普通的编译原理实现“先混淆,再编译”,保护更全面。
一、概述
基于中间语言(IL)的C#|Java语言具有无与伦比的优秀特性,开发效率高,特别适合团队开发,因而是世界上绝大多数(实际在运行的)生产系统的核心开发语言。但IL是也一种双刃剑。优点只是其中一方面。而另一方面,IL很容易被反编译。辛辛苦苦用C#|Java写的exe执行程序或DLL库,很轻易就被反编译为阅读性不错的(几乎完全一样,除了没有注释)的源代码。除了知识产权的问题,同时还给系统安全带来极大的隐患。
欧美国家基于C#|Java的开源项目和软件,发展的比较好,这得益于欧美人与生俱来的“骑士精神”。他们倾向于透明地Unconfuser,并明示来源,对原创者给与基本的尊重。而国内的开源项目则很难发展起来,人们或许缺乏“骑士精神”,更热衷于“白嫖”。一些所谓“大咖”,实际上没有任何过人的技能,道德水平更低下,喜欢用各种低级乃至非法的手段获得他人的成果,稍加包装后转手去获得利益与名声。很多C#、Java及其他语言的的开发项目与产品深受其害,这些人是中国软件生态的破坏者,真可谓“一颗老鼠屎坏了一锅汤”。
实践中知识产权的保护,法律成本与时间成本都非常高,因而更多地要靠自己和一些技术手段。用一些工具对源代码进行适当的混淆,就是保护策略之一。
大多数(尤其指IL)源代码的技术保护,核心要点是限制调试与代码混淆。
1、限制调试是指不能调试或者促使调试成本、调试难度较高;
限制与控制调试层面的混淆技术主要是:
(1)代码乱序、复杂化与截断;
(2)时间探针;
(3)逻辑复杂化;
2、代码混淆是指使得无法阅读或很难阅读。
目前的代码混淆工具,一般是通过修改 .exe 或 .dll 文件实施混淆效果。
主要有:MaxtoCode、ConfuserEx、NET Reactor、Dotfuscator等等。
北京联高软件开发有限公司DeepConfuser则直接从项目文件(比如C#的?.csproj)切入,混淆并重写全部相关的源程序(*.cs,*.java)(保存至其他文件夹),然后用户以新的csprj编译成为 exe 或 dll 文件即可。DeepConfuser的源代码混淆使用了“深度混淆”技术。
二、源程序的深度混淆
源程序的深度混淆涉及:逻辑层面的混淆,数据体(类class、结构体struct与枚举enum)及各种变量、参数的混淆,还有数值常量与字符串的混淆。混淆策略有“逻辑混淆”与“名称混淆”。
1、逻辑和语句的混淆
逻辑与语句的混淆是指用复杂的语句替代简单的语句。混淆的方法很多,每个用户可以设计或提出自己的混淆策略。你可以联系DeepConfuser开发者加入个性化的混淆策略。
这里举一个实例。比如,用 switch 语句替代简单的赋值语句,也可以用 if else 。
原始代码:
int a = func(b);
混淆后成为:
int O0O0O0000OOO00OO = O000O0O0OOO0OO0O.OOOO0O0O0OOOOOOO();
switch(O000O0O0OO0OOO0O.OO0OOOOOO0O0OOOO())
{
case 0:
O0O0O0000OOO00OO = O000OOO0OOO0O00O.OOO0OOOOOO0O0OOO();
break;
case 2:
O0O0O0000OOO00OO = O0O0OOO000O0OO0O.OOOOOOO0O0O0OOOO();
break;
case 4:
O0O0O0000OOO00OO = O00OO00O0OO0OO0O.OOOOOO0OOO0O0OOO();
break;
default:
O0O0O0000OOO00OO = O00O0O00OO0OOO0O.OO0OOOOOOOO00OOO();
break;
}2、数据体与变量的混淆
数据体与变量的混淆是指数据体名称与各种变量的“名称混淆”。数据体名称包括但不限于类class,结构体struct,枚举enum;类或结构体的属性attribute,函数(方法)method;枚举的项目。变量则包括但不限于:全局变量;局部变量;函数参数;函数out参数;for/foreach循环参数等等。混淆就是用容易混乱的、阅读性差的名称代替原来的阅读性好的名称。
名称混淆可以选择:0O混淆,1l混淆,0O1l混淆,类MD5混淆及非可视字符混淆等等。
(1)0O混淆
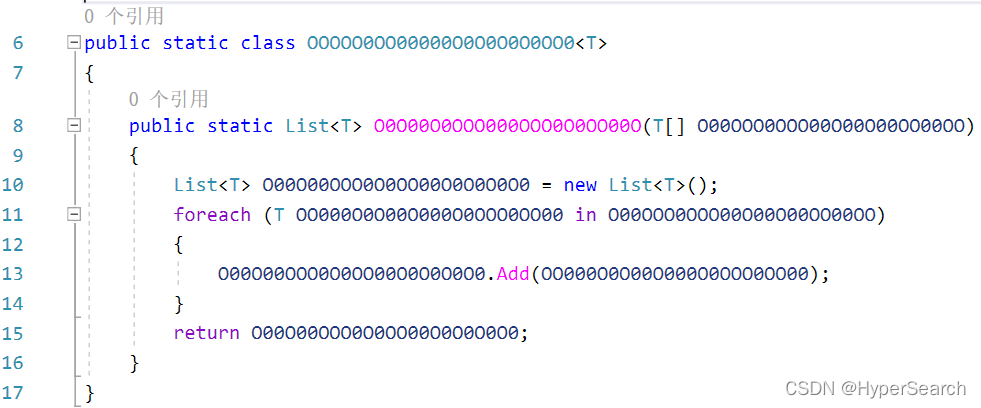
(2)1l混淆
?
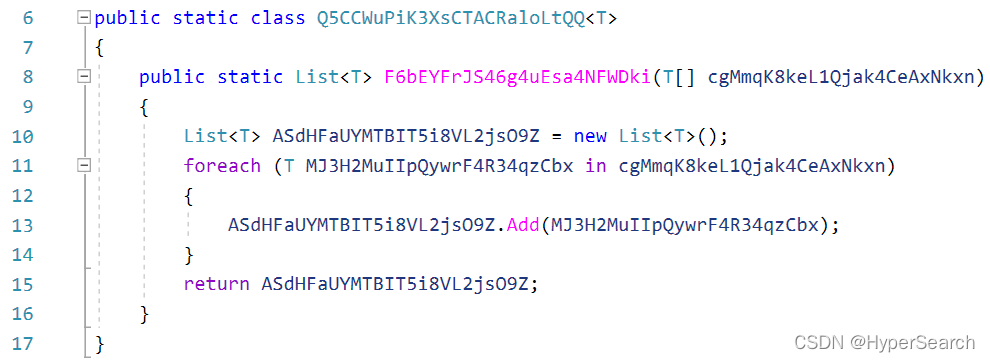
(3)0O1l混淆

?(4)类MD5混淆?
?(5)不可显示字符混淆
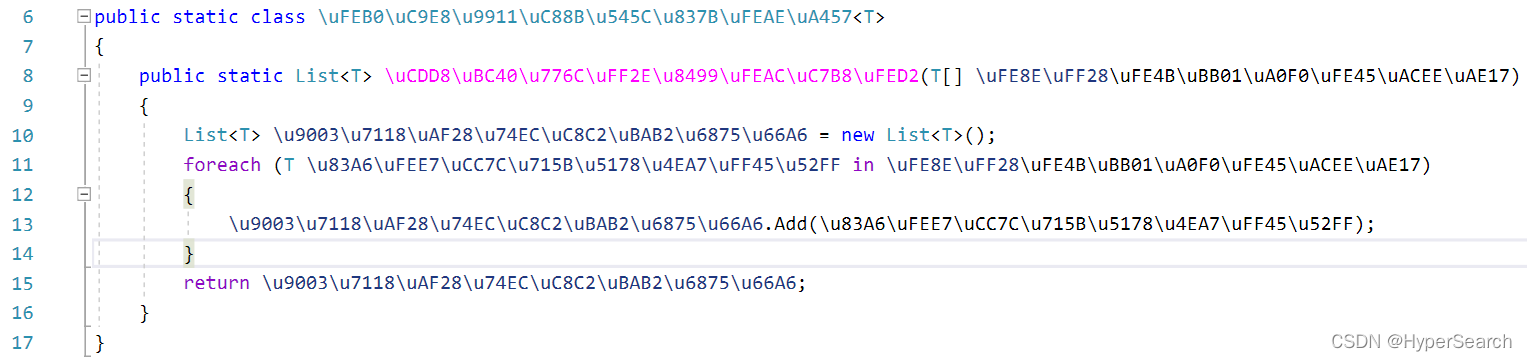
可见,通过名称混淆后的源代码,其阅读性变得极差。
窃取者使用反编译工具获得代码,阅读性也是一样的差。
3、数值常量与字符串的混淆
以C#为例,常见的数据类型有double, float, decimal,sbyte, byte, int, uint, short, ushort,long, ulong, string, bool, char等等。源代码中的数值常量很可能是重要的参数,对数值常量加以混淆可以提高程序的混沌度,阅读性更差,安全性更高。字符串常量如果是明文,利于窃取者调试与修改,因此更应该混淆。
数值常量与字符串的混淆,其核心技术是建立一个复杂的类和函数的“调用图call graph”,以Floyd、Dijkstra等算法求解最短路径后获得数值。比如:
源代码:
?
int a = 11;
string b = "用户姓名";
混淆后成为:
int O0O0O0000OOO00OO = O000O0O0OOO0OO0O.OOOO0O0O0OOOOOOO();
string O00000OOOO0O00OO = O00O0OOO0OO0O00O.OO0OOOOOO0O0OOOO();
其中的 O000O0O0OOO0OO0O O00O0OOO0OO0O00O 都是随机静态类;OOOO0O0O0OOOOOOO() 和 OO0OOOOOO0O0OOOO 是具有复杂调用关系和时间探针(防止或限制调试)的函数。
数值常量与字符串混淆的好处是进一步降低了代码可阅读性。字符串还可以用AES等方法加密。但带来的问题之一是性能的问题。DeepCofuser允许用户设定哪些常量或字符串可以被混淆。比如,如果设定一般数值不混淆,那么 int a = 11; 不被混淆。而 int b = (12); 的常量12则被混淆。字符串也是如此。
三、程序混淆需要处理的一些特殊情况
如果不分青红皂白地对各种名称加以混淆,其结果是灾难性的。如果不能针对团队开发的成果都加以混淆,而仅仅限于局部,其效果也会不甚理想。因此,DeepConfuser在混淆是充分考虑了一些特殊的情况,这些特殊情况的的科学处置是重要而必需的。
1、Json序列化的问题
越来越多的程序与项目用 json 格式进行数据交换、存储。
json 的序列化与反序列化的过程,实现了数据(文件)与数据体(class)之间的准确转换。
比如:
[
{
"Id": 1,
"Name": "I"
},
{
"Id": 2,
"Name": "Love"
},
{
"Id": 3,
"Name": "You"
}
]与:
public class MemberInfo
{
public int Id { get; set; } = 0;
public string Name { get; set; } = String.Empty;
}
两个之间,用 Newtonsoft.Json 组件实现转换。
using Newtonsoft.Json;
List<MemberInfo> members = JsonConvert.DeserializeObject<List<MemberInfo>>(jsonBuffer);
如果以上MemberInfo 代码被混淆了,成为:
public class O00000OOOO00OOO0
{
public string O000OOO00OO00OO0 { get; set; } = String.Empty;
public int O000OO00OOOO00O0 { get; set; } = 0;
}
则序列化的时候就不对了。这是目前MaxtoCode、ConfuserEx、NET Reactor、Dotfuscator这些工具普遍遇到的问题,不得已只能放弃名称混淆(或称为名字混淆)对class进行混淆。混淆效果就打了大折扣。DeepConfuser使用特定的技术解决之,可以混淆!
json格式的混淆另外一个问题是嵌套的数据体。比如:
public class SchoolInfo
{
public int Id { get; set; } = 0;
public string Name { get; set; } = String.Empty;
}
public class MemberInfo
{
public int Id { get; set; } = 0;
public string Name { get; set; } = String.Empty;
public List<SchoolInfo> Schools { get; set;} = new List<SchoolInfo>();
}
如果是这种情况,那么对于普通的的混淆工具而言,SchoolInfo 是不能被混淆的。
DeepConfuser可以混淆!
2、团队开发的共享DLL问题
大中型系统,一般都是团队内各小组分别开发不同的 DLL,大家分享这些程序功能。DeepConfuser应用ShareConfuse技术,将各 DLL 之间的混淆名打通,实现整个项目的全面混淆。ShareConfuse技术简单滴地就是统一标准,统一策略。
3、基类base
类的继承、方法的重载等是常用的编程技术,然而这样的技术会给代码混淆带来困难,如果不能很好地处理,则混淆后的代码是灾难性的。因为DeepConfuser是基于源代码级别的混淆,而不是IL级别的混淆,使用编译原理技术,透彻地分析 class 与 base 之间的关系,实现 base 与 class 的混淆协调。
实际应用中,混淆面对的特殊情况远不止这些,DeepConfuser均予以较好的处置。
推荐大家先用 DeepConfuser 混淆代码,然后用 ConfuserEx 强化混淆(不要选择名字混淆),可获得较好的混淆效果。
请访问北京联高软件开发有限公司官网:
http://www.legalsoft.com.cn![]() http://xn--1lqwgs6ez5bw0azg210chtg88tdj1dglc372ehys3po
http://xn--1lqwgs6ez5bw0azg210chtg88tdj1dglc372ehys3po
联系客服,咨询并定制C# java Android 源代码深度混淆工具――DeepConfuser,为你解决软件知识产权保护的一点难题。
?