正则表达式是一种强大而灵活的文本处理工具。使用正则表达式,能够以编程的方式,构造复杂的文本模式,并对输入的字符串进行搜索。一旦找到了匹配这些模式的部分,就能够随心所欲地对它们进行处理。
初学正则表达式时,其语法是一个难点,但它确实是一种简洁、动态的语言。
正则表达式提供了一种完全通用的方式,能够解决各种字符串处理相关的问题:匹配、选择、编辑以及验证。
基础
一般来说,正则表达式就是以某种方式来描述字符串,因此你可以说:“如果一个字符串含有这些东西,那么它就是我正在找的东西。”
在java中,\\的意思是“我要插入一个正则表达式的反斜线,所以其后的字符具有特殊的意义。”例如,如果你想表示一位数字,那么正则表达式应该是\\d。如果在其他语言中使用过正则表达式,那你立刻就能发现java对反斜线\的不同处理。在其他语言中,\表示“我想要在正则表达式中插入一个普通的反斜线,请不要给它任何特殊意义”。而在java中,\的意思是“我想要插入一个正则表达式的反斜线,所以其后的字符具有特殊的意义”,如果想插入一个普通的反斜线,则应该是\\\\。不过换行会让制表符之类的东西只需要使用单反斜线:\n\t。
应用正则表达式的最简单途径,就是利用String类内建的功能。例如,可以检查一个String是否匹配正则表达式:
public class test {
@Override
public String toString() {
return super.toString();
}
public static void main(String[] args) {
System.out.println("-1234".matches("(-|\\+)?\\d+"));
}
}
//output:true
String类还自带一个非常有用的正则表达式工具――split方法,其功能是“将字符串从正则表达式匹配的地方切开”
public class test {
@Override
public String toString() {
return super.toString();
}
public static void main(String[] args) {
String str = "Hello World Brett Li";
System.out.println(Arrays.toString(str.split("\\W+")));
}
}
//output:[Hello, World, Brett, Li]
String类自带的最后一个正则表达式工具是“替换”。可以只替换正则表达式第一个匹配的子串,或者替换所有匹配的地方。
public class test {
@Override
public String toString() {
return super.toString();
}
public static void main(String[] args) {
String str = "Hello World Brett Li";
// System.out.println(Arrays.toString(str.split("\\W+")));
System.out.println(str.replaceFirst("\\W+"," and "));
System.out.println(str.replaceAll("\\W+"," and "));
}
}
//output:
//Hello and World Brett Li
//Hello and World and Brett and Li
创建正则表达式
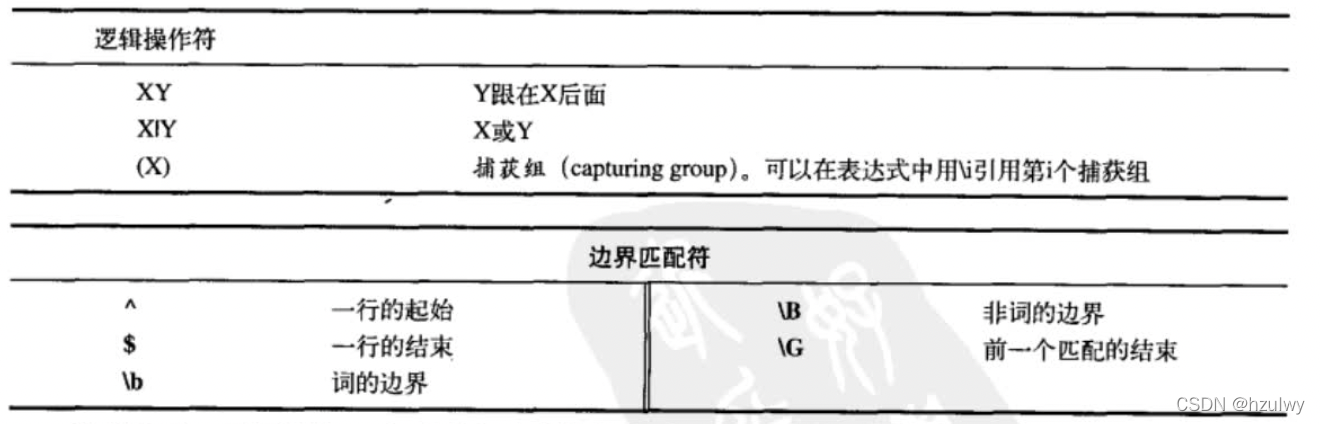
正则表达式完整的构造子列表,参考java.util.regex.Pattern源码。


public class test {
@Override
public String toString() {
return super.toString();
}
public static void main(String[] args) {
for (String pattern:new String[]{"Brett","[bB]rett","[zZ]rett","[bB][rR]e[Tt]t","[bB].*"}){
System.out.println("Brett".matches(pattern));
}
}
}
//output
//true true false true true
量词
量词描述了一个模式吸收出入文本的方式:

Pattern和Matcher
- find方法
public class test {
@Override
public String toString() {
return super.toString();
}
public static void main(String[] args) {
Matcher matcher = Pattern.compile("\\w+")
.matcher("Evening is full of the linnet's wings");
while (matcher.find()){
System.out.println(matcher.group()+" ");
}
int i =0;
while (matcher.find(i)){
System.out.println(matcher.group()+" ");//默认是调用group(0)方法
i++;
}
}
}
//output:
//Evening is full of the linnet s wings
//Evening vening ening ning ing ng g is is s full full ull ll l of of f the the he e linnet linnet innet nnet net et t s s wings wings ings ngs gs s
模式\w+将字符串划分为单词,find方法像迭代器那样便利输入字符串。而第二个find方法能够接收一个整数作为参数,该整数表示字符串中字符的位置,并以其作为搜索的起点。从结果中可以看出,后一个版本的find方法能够根据其参数的值,不断重新设定搜索的起始位置。
- 组
组是用括号划分的正则表达式,可以根据组的编号来引用某个组。组号为0表示整个表达式,组号1表示被第一对括号括起的组,以此类推。因此,在下面这个表达式,A(B?)D中有三个组:组0是ABCD,组1是BC,组2是C。

案例:https://blog.csdn.net/sinat_35209943/article/details/51580173
start方法和end方法
在匹配操作成功之后,start返回先前匹配的起始位置的索引,而end返回所匹配的最后字符的索引加1的值。匹配操作失败之后(或先于一个正在进行的匹配操作去尝试)调用start方法或end方法将会产生异常。
Pattern标记
Pattern类的compile方法还有另一个版本,它接受一个标记参数,以调整匹配的行为:
Pattern.compile(String regex,int flag)
| 编译标记 | 效果 |
|---|---|
| Pattern.CANON_EQ | 两个字符当且仅当它们的完全规范分解相匹配时,就认为它们是匹配的。例如,如果我们指定这个标记,表达式a\u030A就会匹配字符串?。在默认的情况下,匹配不考虑规范的等价性。 |
| Pattern.CASE_INSENSITIVE(?i) | 默认情况下,大小写不敏感的匹配假定只有US-ASCII字符集中的字符才能进行。这个标记允许模式匹配不必考虑大小写(大写或小写)。通过指定UNICODE_CASE标记及结合此标记。基于Unicode的大小写不满干的匹配就可以开启了。 |
| Pattern.COMMENTS(?x) | 在这种模式下,空格符将被忽略掉,并且以#开始直到行末的注释也会被忽略掉。通过嵌入的标记表达式也可以开启Unix的航模式 |
| Pattern.DOTALL(?s) | 在dotall模式中,表达式"." 匹配所有字符,包括终结符。默认情况下,”." 表达式不匹配行终结符。 |
| Pattern.MULTILINE(?m) | 在多行模式下,表达式和$分别匹配一行的开始和结束。还匹配输入字符串的开始,而$还匹配输入字符串的结尾。默认情况下,这些表达式仅匹配输入的完整字符串的开始和结束。 |
| Pattern.UNICODE_CASE(?u) | 当指定这个标记, 并且开启CASE_INSENSITIVE时,大小写不敏感的匹配将按照与Unicode标准相一致的方式进行。默认情况下,大小写不敏感的匹配假定只能在US-ASCII 字符集中的字符才能进行 |
| Pattern.UNIX_LINES(?d) | 在这种模式下,在., ^和$行为中, 只识别行终结符\n |
public class test {
@Override
public String toString() {
return super.toString();
}
public static void main(String[] args) {
Pattern p = Pattern.compile("^java", Pattern.CASE_INSENSITIVE | Pattern.MULTILINE);
Matcher m = p.matcher(
"java has regex\nJava has regex\n" +
"JAVA has pretty good regular expressions\n" +
"Regular expressions are in Java");
while (m.find()) {
System.out.println(m.group());
}
}
}
//output:
//java Java JAVA
在这个例子中,我们创建了一个模式,它将匹配所有以“java”,“Java” 和 ”JAVA“等开头的行,并且是在设置了多行的状态下, 对每一行(从字符序列的第一个字符开始,至每一个行终结符)都进行匹配。注意,group()方法只返回以匹配的部分。
split方法
split方法将输入字符串断开成字符串对象数组。
public class test {
@Override
public String toString() {
return super.toString();
}
public static void main(String[] args) {
String input = "This!!unusual use !!of exclamation!!points";
System.out.println(Arrays.toString(Pattern.compile("!!").split(input)));
System.out.println(Arrays.toString(Pattern.compile("!!").split(input,3)));//限制将输入分割成字符串的数量
}
}
//output:
//[This, unusual use , of exclamation, points]
//[This, unusual use , of exclamation!!points]
替换操作

static String s = "/*! Here's a block of text to use as input to\n" +
" the regular expression matcher. Note that we'll \n" +
" first extract the block of text by looking for\n" +
" extracted block. !*/";
public static void main(String[] args) {
System.out.println(s);
Matcher mInput = Pattern.compile("/\\*!(.*)!\\*/",Pattern.DOTALL).matcher(s);
if (mInput.find()){
s = mInput.group(1);
}
s = s.replaceAll(" {2,}"," ");
s = s.replaceAll("(?m)^ +","");
System.out.println(s);
s = s.replaceFirst("[aeiou]","(VOWEL1)");
StringBuffer sbuf = new StringBuffer();
Pattern p = Pattern.compile("[aeiou]");
Matcher m = p.matcher(s);
while (m.find()){
m.appendReplacement(sbuf,m.group().toUpperCase());
}
m.appendTail(sbuf);
System.out.println(sbuf);
}
上面代码的意思:将存在两个或两个以上空格的地方,缩减为1个空格,并且删除每行开头部分的所有空格(为了使每一行都达到这个效果,而不仅仅只是删除文本开头部分的空格,这里特意打开了多行状态)。这两个替换操作所使用的replaceAll方法是String对象自带的方法,在这里,使用此方法更方便。注意,因为这两个替换操作都只使用了一次replaceAll方法,所以,与其编译为Pattern,不如直接使用String的replaceAll方法,开销更小。
replaceFirst方法只对找到的第一个匹配进行替换,而replaceAll会替换所有合适的匹配。此外,replaceAll和replaceFirst方法用来替换的只是普通的字符串,所以,如果想对这些替换字符串执行某些特殊处理,这两个方法是无法胜任的。如果想要那么做,就应该使用appendReplacement方法。该方法允许你在执行替换的过程中,操作用来替换的字符串。在这个例子中,先构造了sbuf用来保存最终结果,然后用group选择一个组,并对其进行处理,将正则表达式找到的元音字母转换成大写字母,然后调用appendTail方法,将剩余未处理的部分存入sbuf即可。
reset方法
通过reset方法,可以将现有的Matcher对象应用于一个新的字符序列:
public static void main(String[] args) {
Matcher matcher = Pattern.compile("[frb][aiu][gx]")
.matcher("fix the rug with bags");
while (matcher.find()){
System.out.print(matcher.group()+" ");
}
System.out.println();
matcher.reset("fix the rig with rags");
while (matcher.find()){
System.out.print(matcher.group()+" ");
}
}
//output:
//fix rug bag
//fix rig rag
扫描输入
java中从文件或标准输入读取数据是一件相当痛苦的事情。一般的解决之道是读入一行文本,对其进行分词,然后使用Integer、Double等类的各种解析方法来解析数据:
public static BufferedReader input = new BufferedReader(new StringReader("Sir Robin of Camelot\n22 1.61803"));
public static void main(String[] args) {
try {
System.out.println("What is your name?");
String name = input.readLine();
System.out.println(name);
System.out.println("How old are you? What is your favorite double?");
System.out.println("(input: <age> <double>)");
String numbers = input.readLine();
System.out.println(numbers);
String[] numArray = numbers.split(" ");
int age = Integer.parseInt(numArray[0]);
double favorite = Double.parseDouble(numArray[1]);
System.out.format("Hi %s.\n",name);
System.out.format("In 5 years you will be %d.\n",age+5);
System.out.format("My favorite double is %f.",favorite/2);
}catch (IOException e){
e.printStackTrace();
}
}
/*output:
What is your name?
Sir Robin of Camelot
How old are you? What is your favorite double?
(input: <age> <double>)
22 1.61803
Hi Sir Robin of Camelot.
In 5 years you will be 27.
My favorite double is 0.809015.
*/
StringReader将String转化为可读的流对象,然后用这个对象来构造BufferReader对象,因为我们要使用readLine方法。最终,可以使用input对象一次读取一行文本,就像是从控制台毒入标准输入一样。
readLine方法将一行输入转为String对象。如果每一行数据正好对应一个输入值,那这个方法也还可行。但是,如果两个输入值在同一行中,事情就不好办了,我们必须分解这个行,才能分别翻译所需的输入值。在这个例子中,分解的操作发生在创建numArray时,不过要注意,split方法是j2se1.4中的方法,所以在这之前,必须做些别的准备。
java5中新增了Scanner类,它可以减轻扫描输入的工作负担:
public static BufferedReader input = new BufferedReader(new StringReader("Sir Robin of Camelot\n22 1.61803"));
public static void main(String[] args) {
Scanner stdin = new Scanner(input);
System.out.println("What is your name?");
String name = stdin.nextLine();
System.out.println(name);
System.out.println("How old are you? What is your favorite double?");
System.out.println("(input: <age> <double>)");
int age = stdin.nextInt();
double favorite = stdin.nextDouble();
System.out.format("Hi %s.\n",name);
System.out.format("In 5 years you will be %d.\n",age+5);
System.out.format("My favorite double is %f.",favorite/2);
}
/* output:
What is your name?
Sir Robin of Camelot
How old are you? What is your favorite double?
(input: <age> <double>)
Hi Sir Robin of Camelot.
In 5 years you will be 27.
My favorite double is 0.809015.
*/
Scanner的构造器可以接受任何类型的输入对象,包括File对象、InputStream、String或者Readable对象。Readable是java se5中新加入的一个接口,表示“具有read方法的某种东西”。有了Scanner,所有的输入、分词以及翻译的操作都隐藏在不同类型的next方法中。普通的next方法返回下一个String。所有的基本类型(除char之外)都有对应的next方法,包括BigDecimal和BigInteger。所有的next方法,只有在找到一个完整的分词之后才会返回。
在默认的情况下,Scanner根据空白字符对输入进行分词,但是可以使用正则表达式指定自己所需的定界符:
public static void main(String[] args) {
Scanner stdin = new Scanner("12,42,78,99,42");
stdin.useDelimiter("\\s*,\\s*");
while (stdin.hasNext()){
System.out.println(stdin.nextInt());
}
}
除了能够扫描基本类型之外,还可以使用正则表达式进行扫描,这在扫描复杂数据时非常有用:
static String threatData =
"58.27.82.161@02/10/2022\n"+
"202.27.122.161@02/10/2022\n"+
"58.27.82.161@02/10/2022\n"+
"58.27.82.161@02/10/2022\n"+
"58.27.82.161@02/10/2022\n"+
"58.27.82.161@02/10/2022\n";
public static void main(String[] args) {
Scanner stdin = new Scanner(threatData);
String pattern = "(\\d+[.]\\d+[.]\\d+[.]\\d+)@"+"(\\d{2}/\\d{2}/\\d{4})";
while (stdin.hasNext()){
stdin.next(pattern);
MatchResult match = stdin.match();
String ip = match.group(1);
String date = match.group(2);
System.out.format("Threat on %s from %s\n",date,ip);
}
}