���Ϲ���֮-�ڴ�����
�ڴ����
�ڴ�й©(Memory Leak)
��ָ�������Ѷ�̬����Ķ��ڴ�����ij��ԭ�����δ�ͷŻ����ͷ�,���ϵͳ�ڴ���˷�,���³��������ٶȼ�������ϵͳ���������غ����
һ���ڴ�й¶�ķ�ʽ:
- �������ڴ�й©:�����ڴ�й©�Ĵ���ᱻ���ִ�е�,ÿ�α�ִ��ʱ���ᵼ��һ���ڴ�й©��
- ż�����ڴ�й©:�����ڴ�й©�Ĵ���ֻ����ijЩ�ض���������������²Żᷢ���������Ժ�ż��������Եġ������ض��Ļ���,ż���Ե�Ҳ���ͱ���˳����Եġ����Բ��Ի����Ͳ��Է����Լ���ڴ�й©������Ҫ��
- һ�����ڴ�й©:�����ڴ�й©�Ĵ���ֻ�ᱻִ��һ��,���������㷨�ϵ�ȱ��,�����ܻ���һ���ҽ���һ���ڴ淢��й©��
- ��ʽ�ڴ�й©:���������й����в�ͣ�ķ����ڴ�,����ֱ��������ʱ����ͷ��ڴ档�ϸ��˵���ﲢû�з����ڴ�й©,��Ϊ���ճ����ͷ�������������ڴ档���Ƕ���һ������������,��Ҫ���м���,��������������,����ʱ�ͷ��ڴ�Ҳ���ܵ������պľ�ϵͳ�������ڴ档����,���dz������ڴ�й©Ϊ��ʽ�ڴ�й©�����û�ʹ�ó���ĽǶ�����,�ڴ�й©�����������ʲôΣ��,��Ϊһ����û�,�����о������ڴ�й©�Ĵ��ڡ�������Σ�������ڴ�й©�Ķѻ�,������պľ�ϵͳ���е��ڴ档������Ƕ���˵,һ�����ڴ�й©��û��ʲôΣ��,��Ϊ������ѻ�,����ʽ�ڴ�й©Σ������dz���,��Ϊ��֮�ڳ����Ժ�ż�����ڴ�й©�����ѱ�����
�����dz���ʱ����Ƶ�ʲ�ͬ
JAVA�е��ڴ�й¶:
��������������ͨ�����ڴ�й¶��ʽ,��ȻҲ������java,���Ƕ���java����,�����ƺ���ü���,JAVA��һ����Ҫ���Ծ���ͨ�������ռ���(GC)�Զ������ڴ�Ļ���,������Ҫ����Ա�Լ����ͷ��ڴ档������Java�����в����ٱ����õĶ�����ռ�õ��ڴ�,�����Ա�GC����,����JavaҲ�����ڴ�й¶,�����ı�����C����C++��ͬ���ѡ���ͨ��������Ʋ�������ɵ�,Ҳ���ͨ������ǿ��Ա���ġ�������������,�Ƿ�������Ҫ�ƿصĶ���,��Ӧ�����ٵ�ʱ��û������,����û��Ԥ�ϵ�����������������ǵ�Ԥ�롣
1-������������Ԥ��
2-���Ӧ�����ٵĶ���,����פ�ڴ�
��������һ,��һ����������ƹ�Լ:�̳߳صĴ���Ӧ����ʾָ���������еõ�С,����Ĭ��ֵʧȥ����,����������´����˴������߳�,����OOM��
�����,������������ƻ���,�洢��map,list��,��������,ʧȥ���ơ�
�������������ڴ�й¶�ĵ�
1-�̳߳ش���δ��ʾָ���������д�С
2-ThreadLocal �Ĺ��������ǻ��ն���
objectThreadLocal.set(userInfo);
try {
// ...
} finally {
objectThreadLocal.remove();
}
3-�����漰��Դ���ӵĵط�,����Ҫ���ǹر���Դ
4-��ij�Ա����Ϊ����,���ߵ�����ģʽ���м���,�����˴�������������
5-java����,�Ǵ�ֵ���Ǵ�����,��ɵ�Сʱ�����,�ڴ�û����Ԥ����յ�
�ڴ����(Out Of Memory)
�ڴ���������ڴ�Խ�硣�ڴ�Խ����һ�ֺܳ���������ǵ���ջ���(��stackoverflow),��Ȼ����������Կ�����ջ�ڴ治����һ������
�ڴ�������ڴ�й¶����
�ڴ����:�����ڴ�ʱ,JVMû���㹻���ڴ�ռ䡣
�ڴ�й¶:�������ڴ�,����û���ͷ�,�����ڴ�ռ��˷ѡ�
JVM�ڴ沼��

�����������
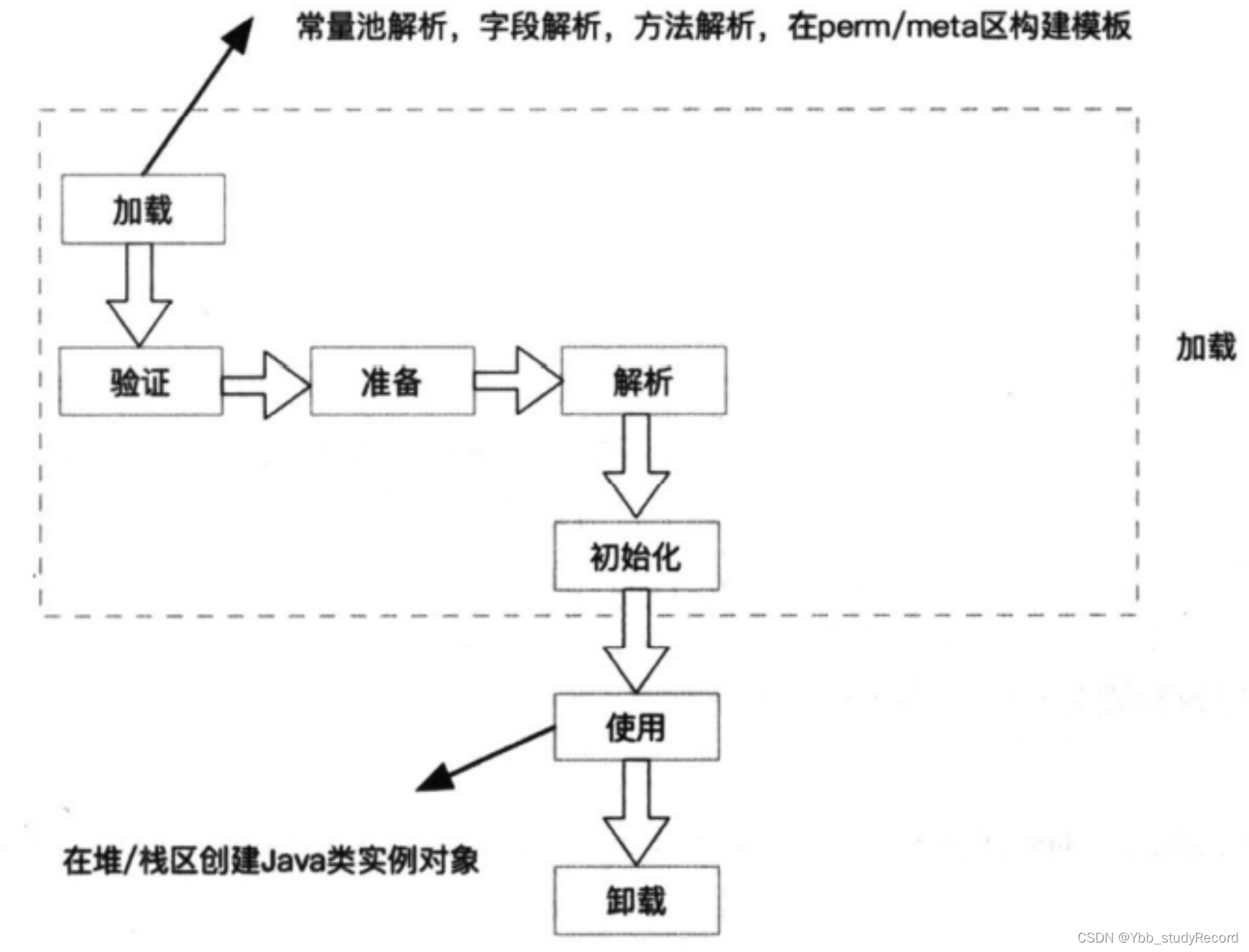
JVM����
1-JVM�IJ�������
1.1 �������:-version,-help
1.2 X����(�˽�):-Xint,-Xmixed
1.3 XX����:
1.3.1 boolean����:-XX:+PrintGCDetails
1.3.2 KV��ֵ����:-XX:MetaspaceSize=128m
2-�鿴�ڴ����
2.1 -XX:+PrintFlagsInitial ��Ҫ�鿴��ʼĬ��(������java����)
case:java -XX:+PrintFlagsInitial
2.2 -XX:+PrintFlagsFinal ��Ҫ�鿴�ĸ���(������java����)
case:java -XX:+PrintFlagsFinal
2.3 -XX:+PrintCommandLineFlags ��ӡ�����в���
2.4 jinfo �鿴�����������
case: jinfo -flag MetaspaceSize pid
����:
-Xms:��ʼ��С�ڴ�,Ĭ�������ڴ�1/64,�ȼ���-XX:InitialHeapSize
-Xmx:�������ڴ�,Ĭ��Ϊ�����ڴ�1/4,�ȼ���-XX:MaxHeapSize
-Xss:���õ����߳�ջ�Ĵ�С,һ��Ĭ��Ϊ512k~1024k,�ȼ���-XX:ThreadStackSize
�ο�:https://docs.oracle.com/javase/8/docs/technotes/tools/unix/java.html
��������
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=heapdump.txt
-XX:+PrintGCDetails
-Xloggc:gc.log
ģ���ڴ����
/**
* ��ջ�������ģ��
*
*/
public class _1_StackOverflowErrorMock {
public static void main(String[] args) throws InterruptedException {
new Thread(() -> {
try {
stackOverflowError();
} catch (Exception e) {
e.printStackTrace();
}
}).start();
new Thread(() -> {
int num = 0;
while (true) {
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(num);
num++;
}
}).start();
new CountDownLatch(1).await();
}
private static void stackOverflowError() {
try {
TimeUnit.NANOSECONDS.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
stackOverflowError();
}
}
/**
* �ѿռ����ģ��
* JVM����:-Xms20m -Xmx20m
*
*/
public class _2_JavaHeapSpaceDemo {
public static void main(String[] args) {
new Thread(() -> {
String str = "asdasd";
while (true) {
str += str + new Random().toString();
}
}).start();
new Thread(() -> {
int num = 0;
while (true) {
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(num);
num++;
}
}).start();
}
}
/**
* JVM����
* -XX:MetaspaceSize=12m -XX:MaxMetaspaceSize=12m
* <p>
* java 8��֮��İ汾ʹ��Metaspace��������ô�,�����������Ϣ:
* <p>
* ��������ص�����Ϣ
* ��ʱ�����Ĵ���
* <p>
* ģ��Metaspace�ռ����
**/
public class _3_MataspaceOOMTest {
public static void main(String[] args) {
new Thread(() -> {
try {
while (true) {
Enhancer enhancer = new Enhancer();
enhancer.setSuperclass(OOMTest.class);
enhancer.setUseCache(false);
enhancer.setCallback((MethodInterceptor) (o, method, objects, methodProxy) -> methodProxy.invoke(o, args));
enhancer.create();
}
} catch (Throwable throwable) {
throwable.printStackTrace();
}
}).start();
new Thread(() -> {
int num = 0;
while (true) {
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(num);
num++;
}
}).start();
}
static class OOMTest {
}
}
/**
* �߲������������ʱ,�������������쳣:java.lang.OutOfMemoryError:unable to create new native thread
* native thread�쳣���Ӧ��ƽ̨�й�
* <p>
* ����ԭ��:
* 1 Ӧ�ô�����̫���߳���,һ��Ӧ�ý��̴�������߳�,����ϵͳ���ؼ���
* 2 ��������������Ӧ�ó�����ô���߳�,linuxϵͳĬ�������������̿��Դ������߳�����1024��,
* Ӧ�ô��������������,�ͻᱨjava.lang.OutOfmemoryError:unable to create new native thread
* <p>
* ����취:
* 1.��취������Ӧ�ó����̵߳�����,����Ӧ���Ƿ������Ҫ������ô���߳�,�������,�Ĵ��뽫�߳������������
* 2.�����е�Ӧ��,ȷʵ��Ҫ�����ܶ��߳�,Զ����linuxϵͳ��Ĭ��1024���̵߳�����,����ͨ����linux����������,����linuxĬ������
**/
public class _4_UnableCreateNewThreadDemo {
public static void main(String[] args) {
for (int i = 0; ; i++) {
System.out.println("********i=" + i);
new Thread(() -> {
try {
TimeUnit.SECONDS.sleep(Integer.MAX_VALUE);
} catch (InterruptedException e) {
e.printStackTrace();
}
}, "" + i).start();
}
}
}
/**
* ��һ�仰���ܼ�����<br>
* ����:
* -Xms10m -Xmx10m -XX:+PrintGCDetails -XX:MaxDirectMemorySize=5m
* <p>
* ��������
* Exception in thread "main" java.lang.OutOfMemoryError:Direct buffer memory
* <p>
* ����ԭ��:
* дNIO����ʹ��ByteBuffer����ȡ����д������,����һ�ֻ���ͨ��(Channel)�뻺����(Buffer)�� I/O��ʽ,
* ����ʹ��native������ֱ�ӷ�������ڴ�,Ȼ��ͨ��һ���洢��Java�������DirectByteBuffer������Ϊ����ڴ�����ý��в�����
* ��������һЩ�����������������,��Ϊ��������Java�Ѻ�Native�������ظ������ݡ�
* <p>
* ByteBuffer.allocate(capability) ��һ�ַ�ʽ�Ƿ���JVM���ڴ�,
* ByteBuffer.allocateDirect(capability)��һ�ַ�ʽʱ����OS�����ڴ�,���ڲ���Ҫ�ڴ濽�������ٶ���ԽϿ졣
* <p>
* ��������Ϸ��䱾���ڴ�,���ڴ����ʹ��,��ôJVM�Ͳ���Ҫִ��GC,DirectByteBuffer�����ǾͲ��ᱻ���ա�
* ��ʱ����ڴ�����,�������ڴ�����Ѿ�ʹ�ù���,�ٴγ��Է��䱾���ڴ�ͻ��OutOfMemoryError,�dz����ֱ�ӱ����ˡ�
**/
public class _5_DirectBufferMemoryDemo {
public static void main(String[] args) {
System.out.println("���õ�maxDirectMemory:" + (sun.misc.VM.maxDirectMemory() / (double) 1024 / 1024) + "MB");
ByteBuffer bb = ByteBuffer.allocateDirect(6 * 1024 * 1024);
}
}
/**
* ��һ�仰���ܼ�����<br>
* <p>
* JVM����������ʾ
* -Xms20m -Xmx20m -XX:+PrintGCDetails
* <p>
* GC ����ʵ������ʱ���׳�OutOfMemoryError�������Ķ�����,����98%��ʱ��������GC���һ����˲���2%�Ķ��ڴ�
* �������GC��ֻ���յ��˲���2%�ļ�������²Ż��׳������粻�׳�GC overhead limit����ᷢ��ʲô�����?
* <p>
* �Ǿ���GC��������ô���ڴ�ܿ���ٴ�����,��ʹGC�ٴ�ִ��,�������γ��˶���ѭ��,
* CPUʹ����һֱ100%,��GCȴû���κγɹ�
**/
public class _6_GCOverheadDemo {
public static void main(String[] args) {
int i = 0;
List<String> list = new ArrayList<>();
try {
while (true) {
list.add(String.valueOf(++i).intern());
}
} catch (Throwable e) {
System.out.println("*******i:" + i);
e.printStackTrace();
throw e;
}
}
}
ʲô��������GC-CMSΪ��
1-eden������?��ᴥ��?
2-��������˻�ᴥ��?
3-ֱ�ӻ��������˻�ᴥ��?
4-Ԫ�ռ�����,��ᴥ��?
����
1-jvm gc��־��������:https://javagc.cn/
https://gceasy.io/ft-index.jsp
2-�ڴ���շ�������:mat,jprofile,VisualVM
3-java�Դ�:
-jps ���̲鿴
-jstat:���ڼ����������������״̬��Ϣ�������й��ߡ�������ʾ���ػ���Զ������������е�����ء��ڴ桢�����ռ���JIT�������������.
jstat -gc pid #��������ͳ��
jstat -gccapacity pid #���ڴ�ͳ��
jstat -gcnew pid #��������������ͳ��
jstat -gcnewcapacity pid #�������ڴ�ͳ��
jstat -gcold pid #�������������ͳ��
jstat -gcoldcapacity pid #������ڴ�ͳ��
jstat -gcutil pid #�ܽ���������ͳ��
jstat -printcompilation pid #JVM���뷽��ͳ��
jstat -class pid #�����ͳ��
-jinfo �������ò鿴
-jmap �ڴ���
jmap -clstats pid #��ӡ���̵��������������������صij־ô�������Ϣ
jmap -heap pid #�鿴���̶��ڴ�ʹ�����,����ʹ�õ�GC�㷨�������ò��������ж��ڴ�ʹ�������
jmap -histo[:live] pid #�鿴���ڴ��еĶ�����Ŀ����Сͳ��ֱ��ͼ,�������live��ֻͳ�ƻ����
jmap -dump:format=b,file=dumpFileName pid #jmap�ѽ����ڴ�ʹ�����dump���ļ���
-jstatck�̼߳��
˼��
1-eden space+ from space > to space����ô? �ᷢ��ʲôGC
2-IntegerΪʲô��equals�ж����
�Ƕ��ڴ�й¶
����:
����·��ϵͳ�����ṩ�IJ�ѯ����ȫ�̸��ٽӿڵ��÷�TP99�ϸ�,�ṩ��TP99�ܵ�,���ϴ�,ΪѰ��ԭ��,�����˼���ѹ��
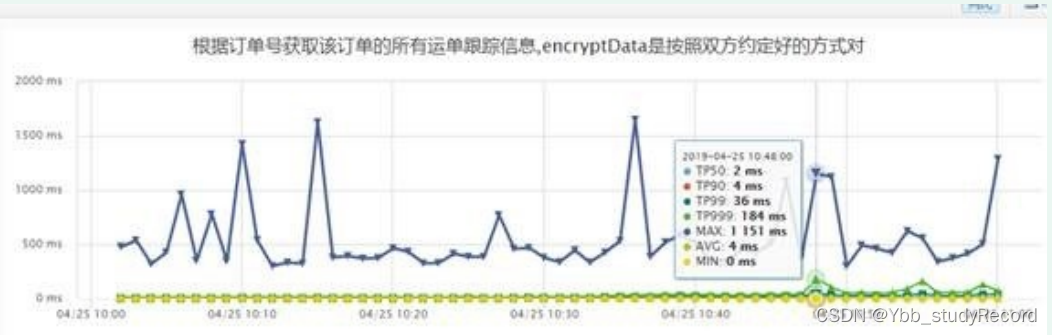
1�� �����ṩ��TP99 30��ms,�����÷�TP99 250ms����,��Ҫ����Ϊ����ѹ������з���
�ṩ��������������,�����÷����������ǵļ�ʮ��,��ͳ�Ʒ�ʽ��(������ά��),���ǵ�
TP999������Maxֵ���ǵ��÷���TP99,����TP999��Maxֵ����,����ӿڻ����ڿ����Ż���
�ռ�,����ͨ��Jtrace�鿴����ִ�����ķ���Ҳ�������ر�Ķ���,��Щ��SQLִ�����ݿ���,��Щ�Ǹ�Jimdb������,������������ʵ�������sql�����ߵ�����,����ֱ���СҲ��250w����,������������������֡�
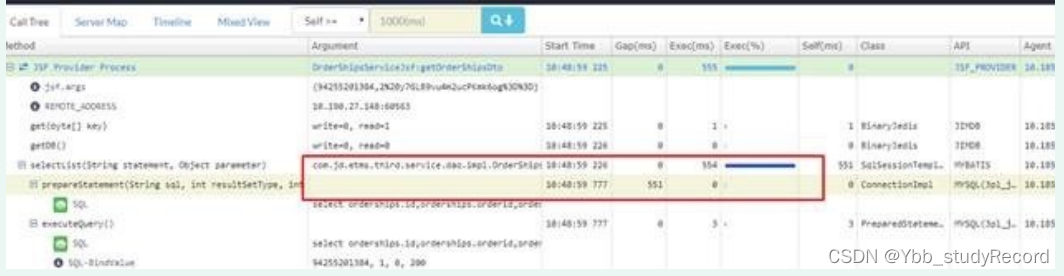
2�� ����������GC,���ִ��ڴ���FullGC,�Ҷ�ռ�ú�С��ʱ���ִ��FullGC��,�����·Ƕ�,�ǶѴ�С��0-2GƵ���仯,�ɴ��ж϶���й¶��,��һ���������ֶ���й¶����,jvm�ڴ�ֲ�-������,����ط���������,���ڴ���MAT,dump֮���кܶ������ʽ,�Ƕ�զ����?(��ͼFullGCƽ��ʱ��Ӧ����700ms),����Ĺ���Ҳ��Ѱ�ҿ��Է����Ƕ��ڴ�Ĺ���,����һȦ������,һ����google��greftools,�������������Ҫ��װһЩ��,����ʵ�ʹ۲�,���ŵ��������ӷǶ��ڴ����ӵ�Խ��,�ж���ij���������ֵ��ڴ�й¶,��֪���ĸ������������û������������,�������������������װ����Ҫ��ά��æ,���ܻ�Ƚ��鷳������û��������ʽ���ɵIJ鿴�Ƕ��ڴ�ֲ���?���ǿ϶���,�и�����jmap �Cpermstat,���Ǻܿ�ϧ,�����������������ʹ�õ�ʱ��Ȼ������,���ֱ�ӵ���jvm����,JSFû�ܼ�ʱ�Ƴ�����ڵ�,���µ��÷���ʱ��
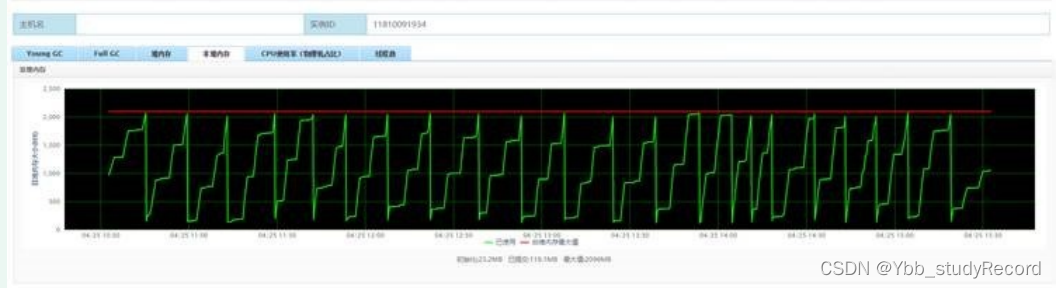
3�� ������ѯ����ʦ(��л����ʦ,�����ؼ��Ե�һ��),�����Ľ�������������ʱ�����Ӳ���-
verbose:class����,�����������,���뵽��jstat �Cclass�鿴class��������,��Ȼ������96w��class����,����ʱ����Ҳ��Ч��,����̨Ƶ���������class����������������������λ��,ԭ����JAXBContext��ʹ�÷�ʽ����(�������),����Ӧ�õ���,ȴÿ�ζ���������ʹ�á��Ĵ���-����-����-�ٴμ���ѹ�⡣������֤��ȷ,��Ҳû���ַǶ����,Ҳû����FullGC,�����Լ���TP999 ��MAXֵ���ȶ�,���÷�TP99Ҳά����10ms����,������������
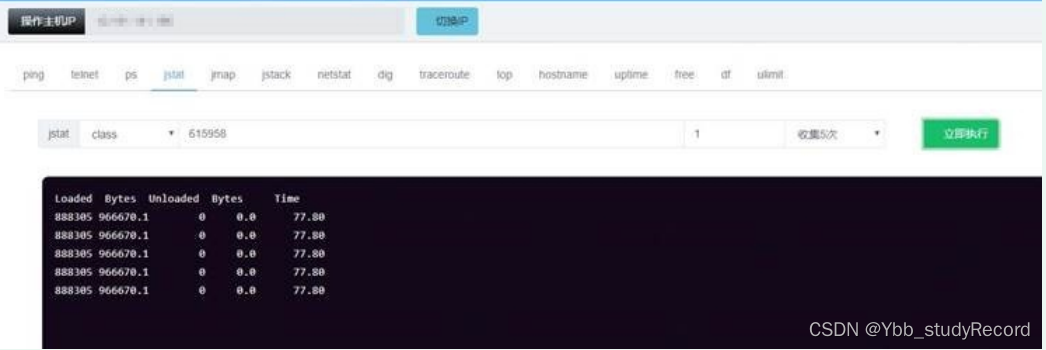
4�� ����why?,������������JAXBContext.newInstance��������з���JAXB�ڲ�ʹ���˷���
��ȡ�������Ժͷ���(JAXBxmlת����Ĺ���)���ɴ�����,��������Ҫͨ��classLoader����,��
����ع���,˫��ί��,���������ֻ����һ�ξ���,���ǻ�֪��ͬһ��classLoader��ͬһ������������Dz��ܶ�μ��ص�,����û����,Ȼ�������ڲ�Injector�����������Ĺ�����ʹ����������WeakReference�� ,���±����վͻ����¼��ش�����,����֮ǰ��������û����,���¼���ͬһ������,������سɹ�,֮ǰ��Ҳ����ô���,ֱ���ϵ����,�����˸�duplicate class֮��,�����ִ�ӡ��Load class��־,����,���������jdk��bug,�ظ�����ͬһ����,��Ȼʧ��,����Ӧ�����������ڴ�ȴû������,���ſ��ϵ�,���ִ���Loadclass��־,�����ô�,��������,����FullGC����,class����Ҳ��һֱ����,�ظ�.��ʵ��Ҳ����JAXB��һ��bug,�����ظ�����ͬһ����������(˵��:��ԭclassLoader.load�����������ж��Ƿ���ع�class�Ĺ���,����JAXB���Լ�������classLoader�ڲ���defineClass��resolveClass����,�Ǵ�����˫��ί�ɻ���,���¶���ظ�����class,�����ڴ�й¶,��������˵��JAXB��bug,��ȻJDK�ײ����쳣ȴ���ͷŶ��ڴ��ռ����Ҳ���������,������classLoder��ʹ��,����ʹ��������load����)
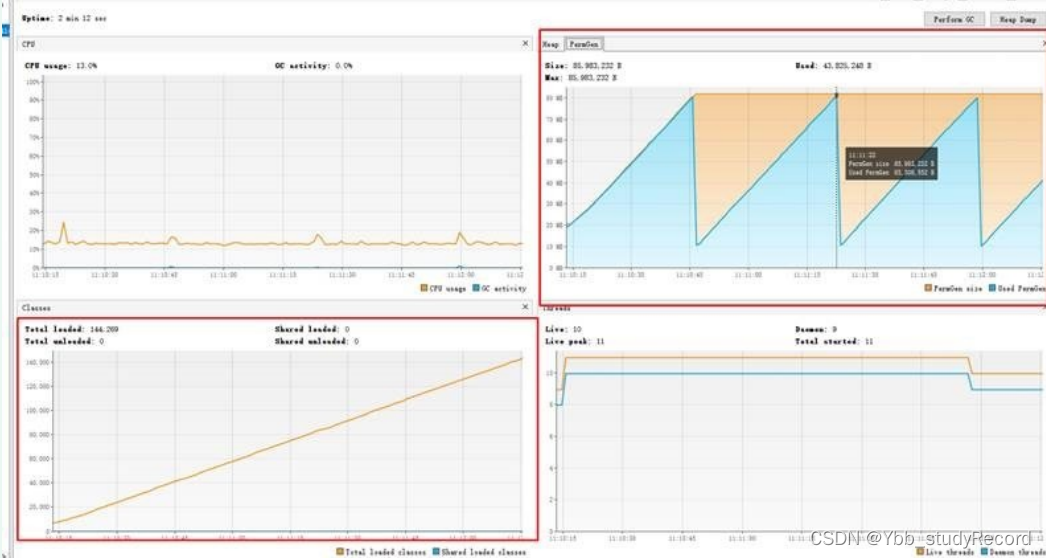
�˵��Ƕ��ڴ���������Ų�
1������������
���л���:JDK�汾 1.8.0
��������:
�˵�ϵͳÿ��һ��ʱ��,�ڴ�ʹ�ú�CPU����������ֵ85%,ͨ�����ƽ̨���Կ����Ƕ��ڴ��
�����Ӳ����� ������Ƶ��FullGC,����CPU100%��
����ϵͳ���ͼ:
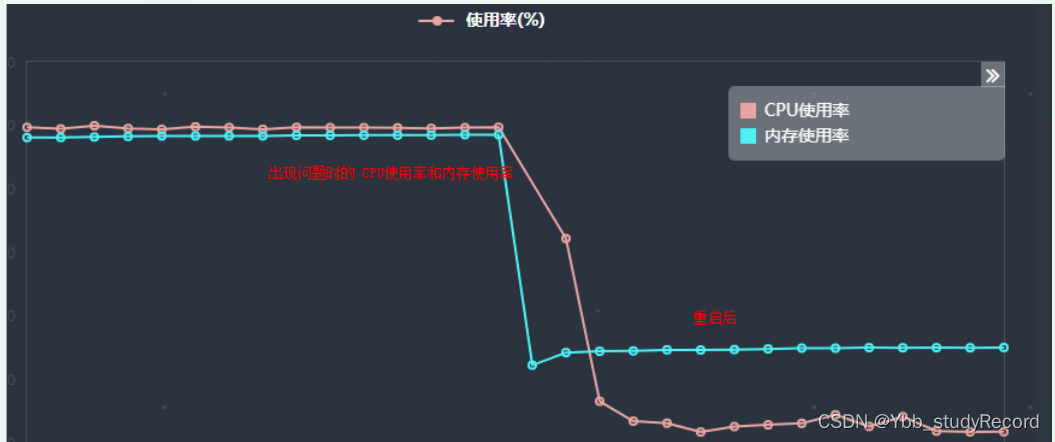
JVM�ڴ���
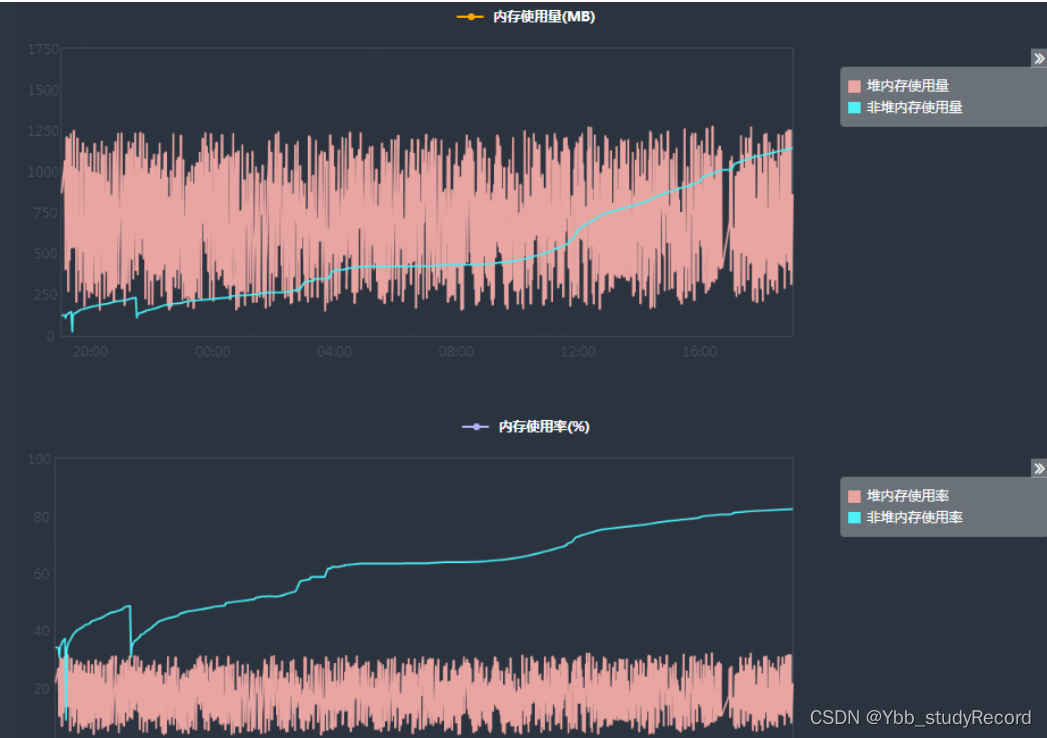
�Ӽ���Ͽ��Ƕ��ڴ����ô�(JDK8 HotSpot JVM ���Ƴ�������,ʹ�ñ����ڴ����洢��Ԫ����
��Ϣ����֮Ϊ:Ԫ�ռ�(Metaspace))һֱ�����������ա��ⲿ���ڴ���Ҫ���ڴ洢�����
Ϣ���������ݡ����������,���������Ԫ�ռ䲻��ռ�úܴ��ڴ�, ���Զ��ڶ�̬�����������Ƚ����׳������ô����ڴ��������ʼ����Ӧ����ʹ�÷��䡢�����ȼ��������˴���������ص�Ԫ�ռ������ա�
�����Ų�
1��ʹ��jstat �鿴�ڴ漰GC���:

�����: jstat (oracle.com)
S0C:��һ���Ҵ����Ĵ�С
S1C:�ڶ����Ҵ����Ĵ�С
S0U:��һ���Ҵ�����ʹ�ô�С
S1U:�ڶ����Ҵ�����ʹ�ô�С
EC:�������Ĵ�С
EU:��������ʹ�ô�С
OC:�������С
OU:�����ʹ�ô�С
MC:��������С
MU:������ʹ�ô�С
CCSC:ѹ����ռ��С
CCSU:ѹ����ռ�ʹ�ô�С
YGC:������������մ���
YGCT:�����������������ʱ��
FGC:������������մ���
FGCT:�����������������ʱ��
GCT:��������������ʱ��
���Կ���������FullGC, MU �� CCSU ���ܴ�,FullGC��û�л��յ�,�ٴ�ȷ����Ԫ�ռ��ڴ�
����Ŀ��ܡ�
2����ӡ�������Ϣ ��������
��JAVA_OPION ������ -verbose:class ��ӡ�������Ϣ��������۲���־���
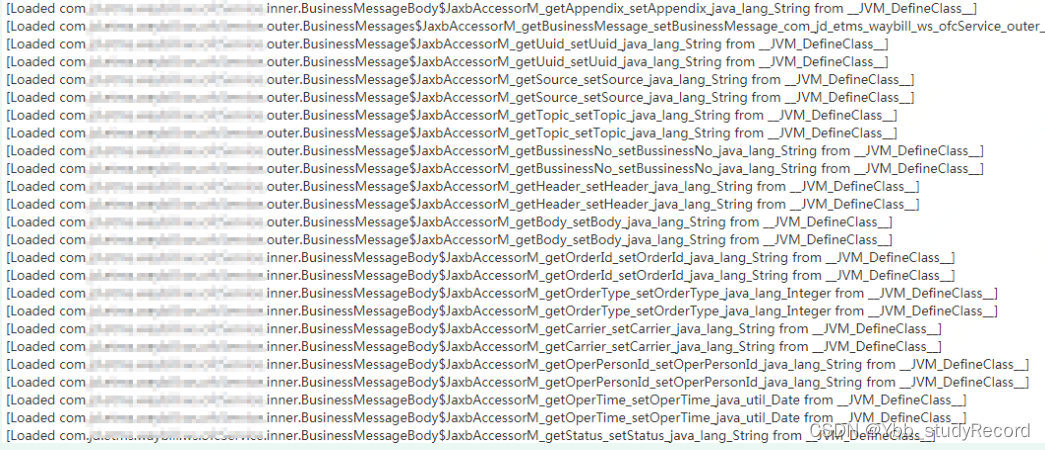
�������������Ϣ,����һֱ��ͣ��Loaded�� ��ӡ������ص�ҵ����.BusinessMessageBody
��BusinessMessage ,��������ʹ��Jaxb ���л���XMLʱ���������⡣����Ŀ��������ش�
��:
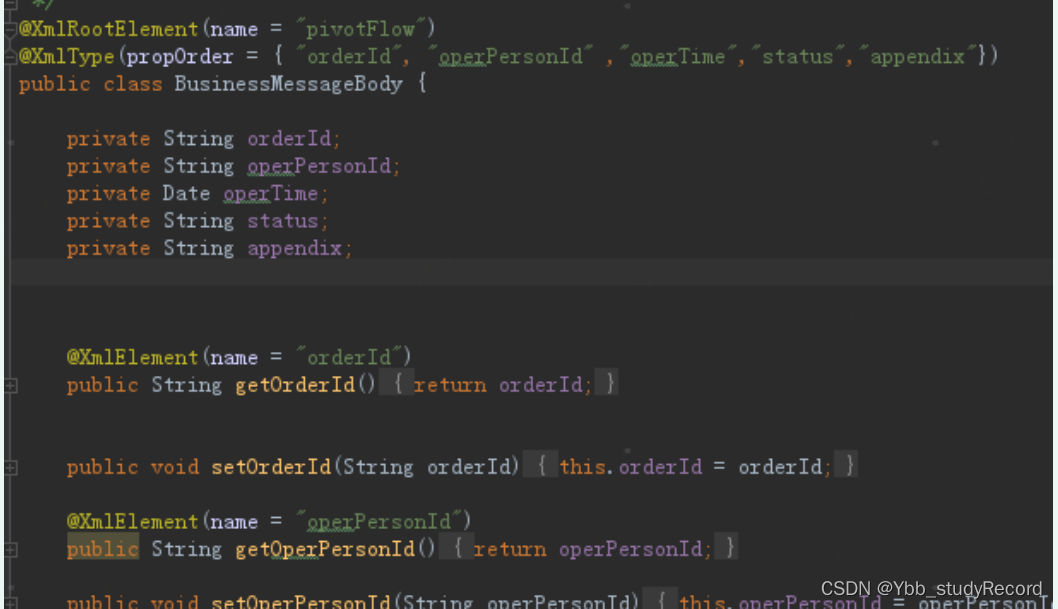
��Xml��ע��
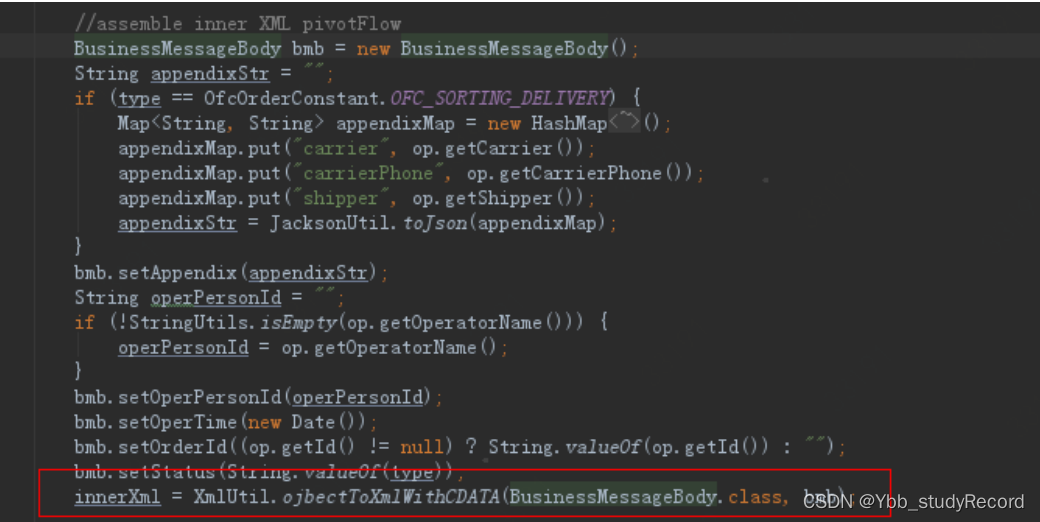
ҵ�������ʹ�� XmlUtil ������ת��XML ���������� XmlUtil.ojbectToXmlWithCDATA
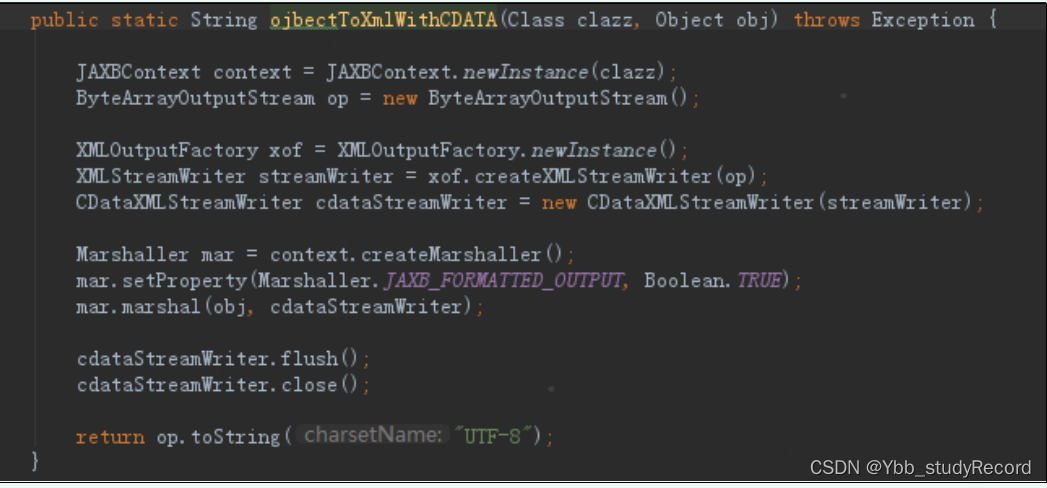
ע XML����:
XML,���ǿ���չ�������Extensible Markup Language,����XML/DTD/XSD/XPATH��w3c�淶,��webservice�� ����ҪӦ����SOAP/WSDL��(WSDL������w3c�淶)
JAVA�淶APIͳ��JAXP,��Ҫ��DOM/SAX/STAX/XPATH�ȱ�API,������Ĭ��ʵ�֡�����JAXP�Ļ����Ͻ����� JAXB/JAX-WS�ȹ淶
������JAXP API(������)ʵ����xerces/crimson/woodstox/xalan�ȿ�Դʵ��,Ҳ��һЩ���̵�ʵ��(��IBM)��
���õ�XML��������dom4j/jdom��JAXP API�Ķ��η�װ(��ʵҲ��װ������һЩ�ǹ淶��ʵ��)
������webservice����axis2/xfire/cxf��,���Լ��ķ�ʽʵ����SOAP/WSDL�ȹ���(XML��ع��ܻ���JAXP),
����JAX-WS�淶������,��Щ��Ҳʵ����JAX-WS�淶
������ʵ����IJ���ģʽ��������,�������Dz��������á�SPI��Ĭ��ʵ�ֵ�˳���������Ҫ(�����bug/�� ������),���Ը����������˳�������ͬ��ʵ�ַ�ʽ��
��������ʹ�� JAXB �����������XML��JAXB(Java Architecture for XML Binding),����
JAXP(Java API for XML Processing),������XML��Java�����ӳ�䴦����ϵ,������JAXB �� ��
- ����,��������ļ�jaxb.properties��û�ж���javax.xml.bind.context.factory������,ͨ
��createContext���� - ���û���ҵ�,��ͨ��SPI(Service Provider Interface)����( JDK���õ�һ�ַ����ṩ���� ���� ),������û��ʵ���ඨ��: META-INF/services/javax.xml.bind.XXX
- ���û���ҵ�,ѡ��Ĭ���ڲ�ʵ��(oracle JDK):com.sun.xml.internal.bind.v2.ContextFactory
����ĿĿ¼��δ�ҵ� jaxb.properties �ļ�,����maven�������������˼������:
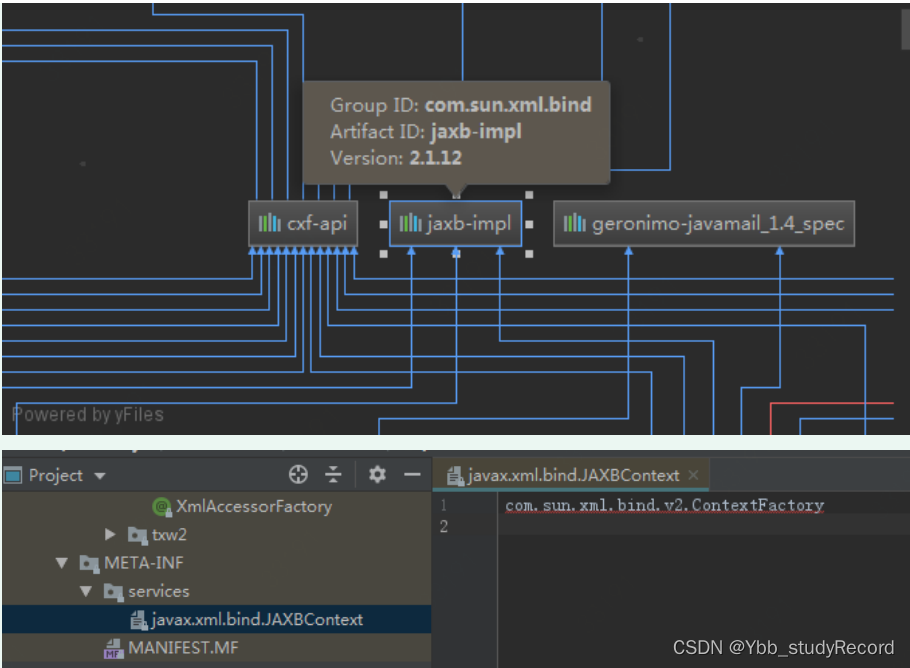
���Կ���ͨ��SPI���� ����com.sun.xml.bind.v2.ContexFactory ʵ����������JAXBContext��
JAXB ���и����ڷ���bean���ض����Ե���Accessor,���ඨ����һ������optimize�����Ż���
Accessor��,
��optimize������ ʹ�� OptimizedAccessorFactory ������ȡ�Ż���Accessor,��������ʵ
��
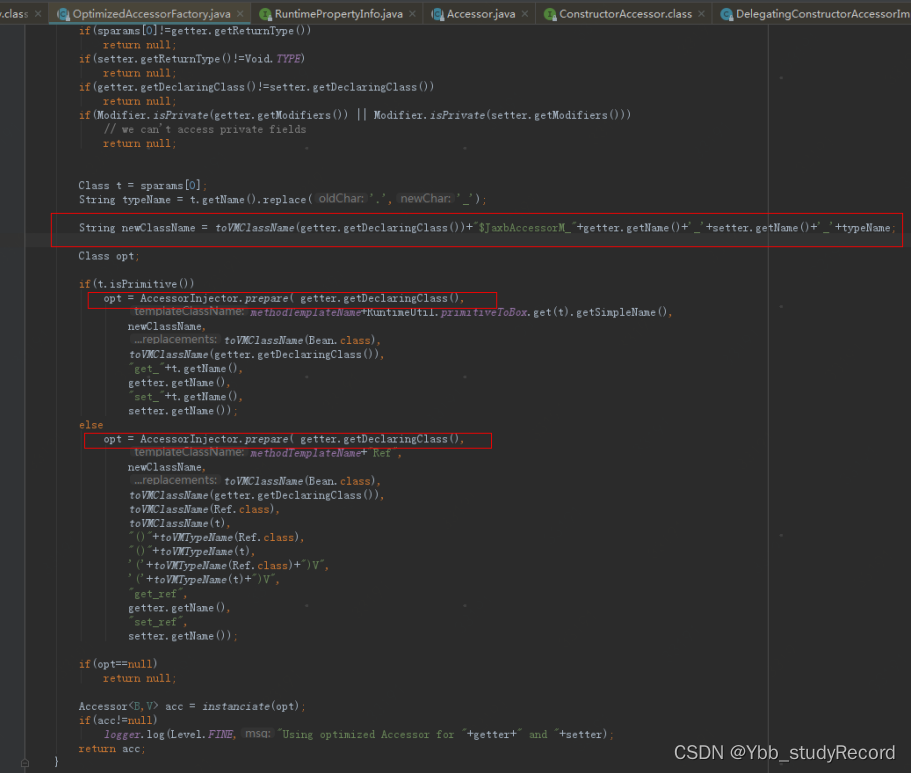
��һ������� newClassName ��������־���Ѿ������˼��������ɵ�������������ʹ��
AccessorInjector.prepare �������ɶ�Ӧ��Class ����AccessorInjector.prepare �������ֵ�
����
Injector.find ��Injector.inject ,������������ �������� ��������������ڻ�ȡ���������Ӧ��
Injector ����,����Ѵ��ڻ����Injector ֱ�ӷ���,���Ϊ������½�WeakReference ���뻺�� injectors (����ΪWeakHashMap����),injectors �����Valueʹ�õ���WeakReference������ ,��GC����ʱ,�����ռ�����ij��ʱ������һ�����������ɴ��(weaklyreachable)(Ҳ����˵��ǰָ������ȫ����������),��ʱ�����ռ������������ָ��ö���������á�
private static Injector get(ClassLoader cl) {
Injector injector = null;
WeakReference<Injector> wr = (WeakReference)injectors.get(cl);
if (wr != null) {
injector = (Injector)wr.get();
}
if (injector == null) {
try {
injectors.put(cl, new WeakReference(injector = new Injector(cl)));
} catch (SecurityException var4) {
logger.log(Level.FINE, "Unable to set up a back-door for the injector", var4);
return null;
}
}
return injector;
}
��� injector ��Ϊ����������淽�����ض�Ӧ�� Class :

��Ϊ��һ��,���ظ�ִ����Ķ���,һ���ظ�����,�ظ�����,��jvm�ڲ�����һ��Լ������׳�
LinkageError,����ʱ�����Ľṹ,�ȴ�GCȥ���ա�
��ô�ع�����,Ϊʲô injectors �����պ�,��Ӧ��Classʵ��δ������ж�ص���? ����������Ļ�����������Ϊ������JDK�汾,��JDK7������JDK8, ��ôJDK8����������������Щ�ı�,�Ƿ���Щ�ı䵼���˴�����IJ���������������ʼ��� google,�õ��˴𰸡�
��JDK 7��,��Permgen�ж���Ļ��ջ���д���Լ��,����ظ�����ʱ���������ݻ���GCʱ��������Ȼ����JDK 8��,Metaspace�Ļ���ֻ����classloader�Ĵ��,��classloader������ʱ,���������Ķ������۴������ᱻ����,�ɴ�������OOM��
����������dump�������ڴ��ļ���������֤����һ��:
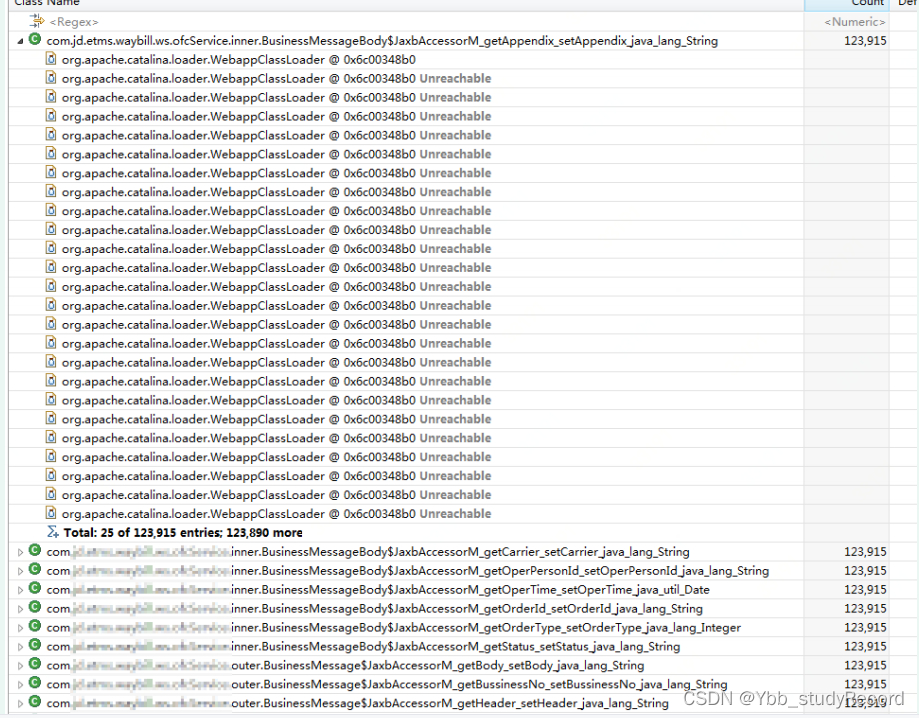
�μ� :
https://zhuanlan.zhihu.com/p/25634935
http://lovestblog.cn/blog/2016/04/24/classloader-unload/
http://blog.yongbin.me/2017/03/20/jaxb_metaspace_oom/
�����ᵽ JAXB 2.2.2 ���ϰ汾������,�����ҵ�һ��2.2.11 ���������²���:
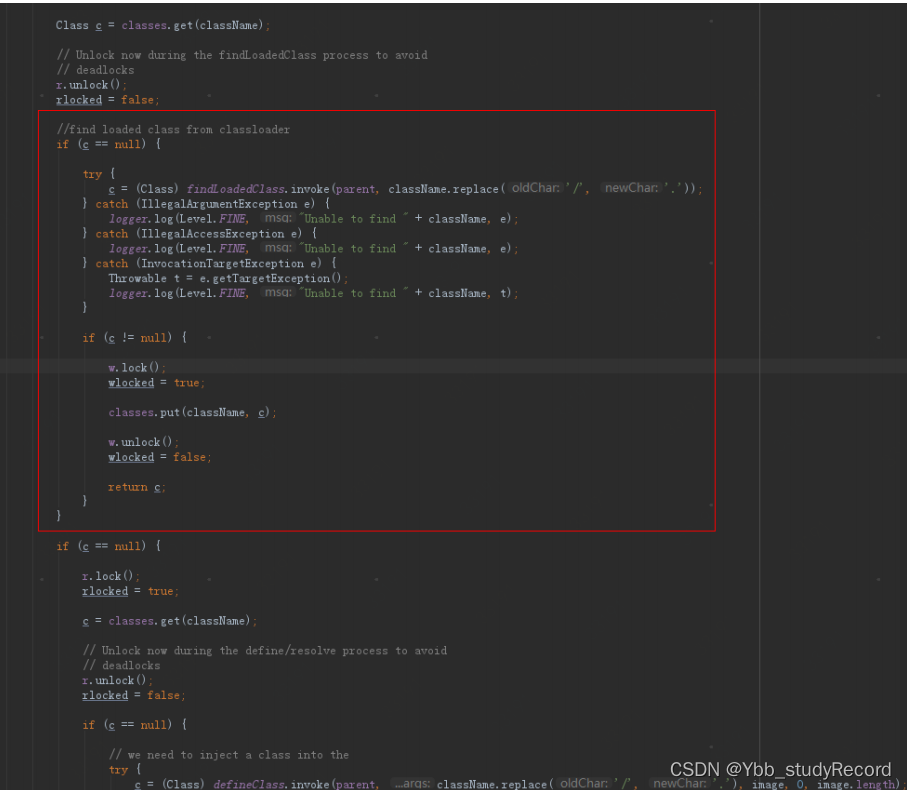
JAXB-impl 2.2.11 �汾 inject �汾��������һ�� findLoadedClass`` ��,�����Ʋ����Ƿ����� ���ص���,�����ظ�������ء�
3�����ػ�����֤����
���˵�����ش���ժ�������Թ۲�ʹ��JAXB-impl��ͬ�汾���Ԫ�ռ�仯���ɡ�
JAXB-Impl 2.1.12 �汾 �������: ���Կ����� Ԫ�ռ� ��������,���ﵽ���õ����ֵ,����Ƶ��FullGC,ͬʱCPUʹ���ʴﵽ100%,Ҳ�ɿ����Ѽ��ص��������� 26501��
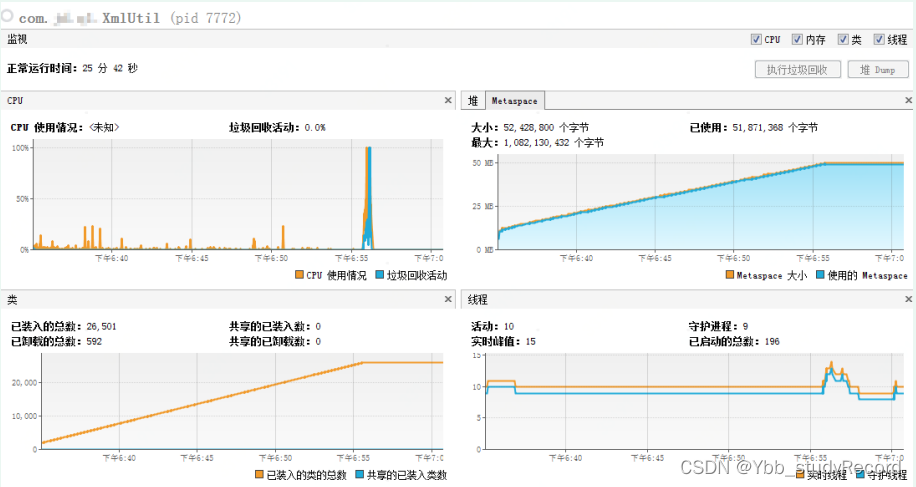
JAXB-Impl 2.2.11 �汾 �������,Ԫ�ռ�ʹ�ñ�����12906832 ,��������������� 2156,CPU����,GC����,�����ȶ���
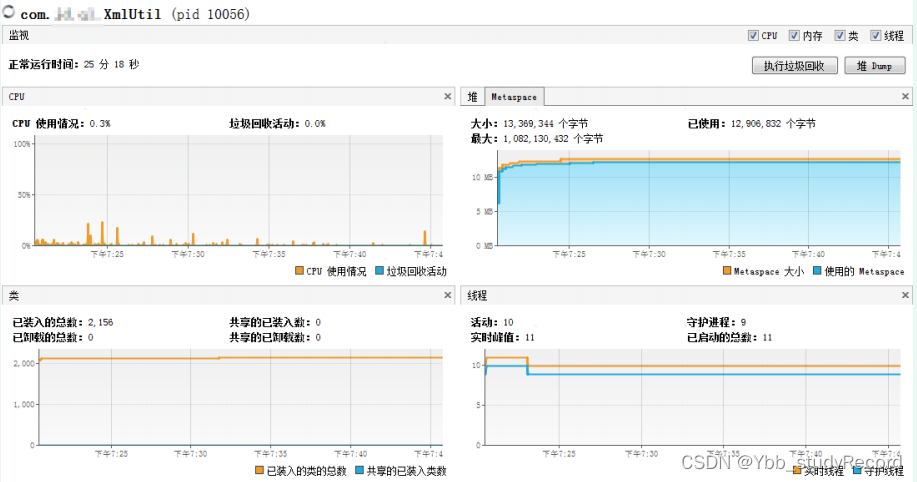
4�����ϸ��°汾�۲�
�Ƕ��ڴ�ά����150M��С,�ȶ����С�
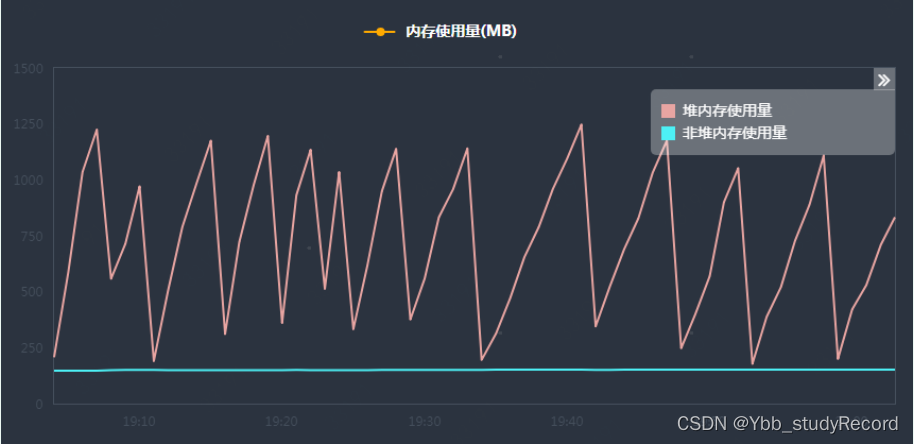
����ڴ�й¶�ܽ�
������������,һ����ѯ����һ���������еļ�¼����ѯ������,�������ܴ�,���ڴ��,����ֳ����տ�,��,����
��LAOS����jmap -dump�����JVM�������ڴ���Ϣ
Ȼ����MAT���ѵĴ��ļ�,��ͼ:
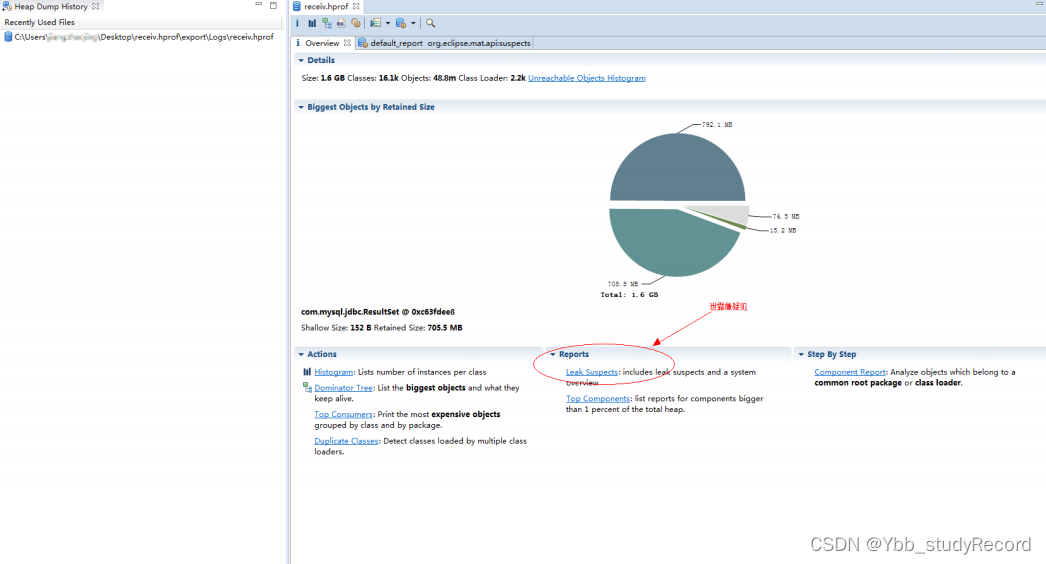
���ٶ�λ�������й¶���ɷ�,�����ȥ,��ͼ,�������������ɷ�ռ����49.90%+44.45%=94,35%���ڴ�,������������զ����??
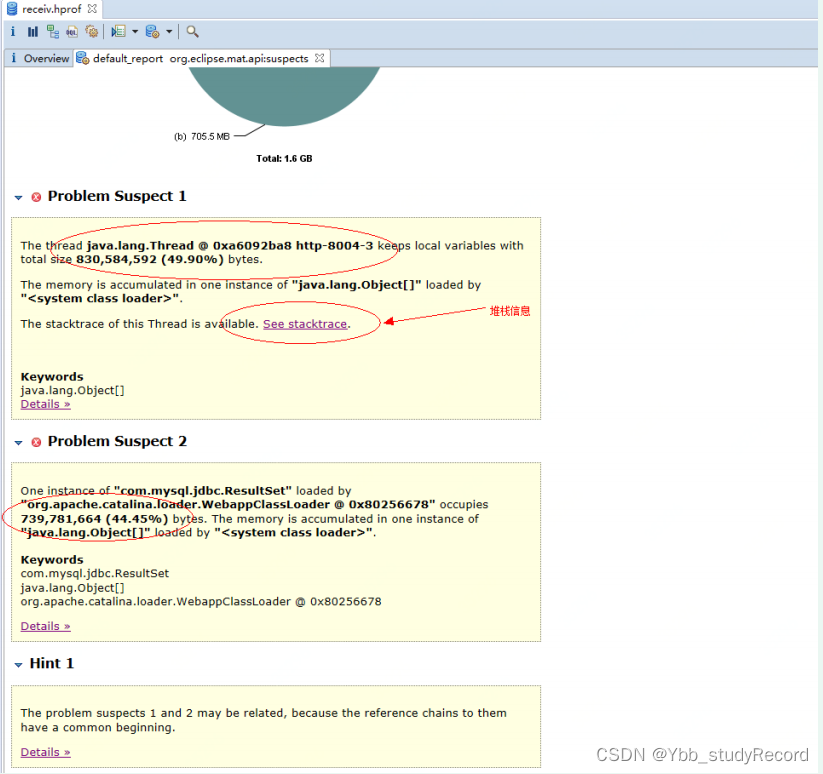
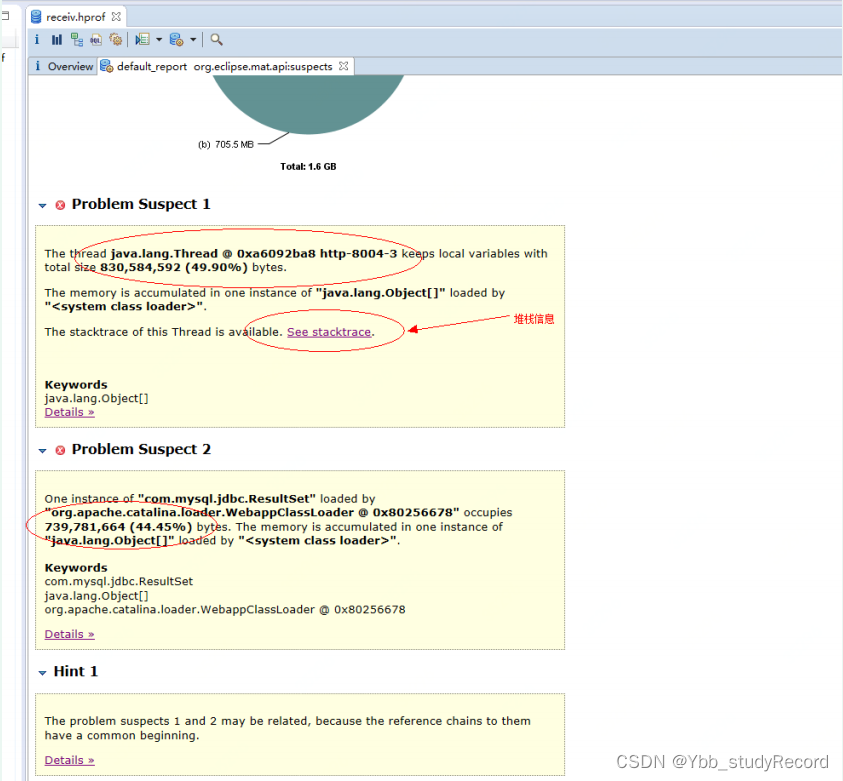
�����һ�����ɷ��Ķ�ջ��Ϣ����,��ϸ�����ܷ��ָ����ɷ����������,����ͼ:
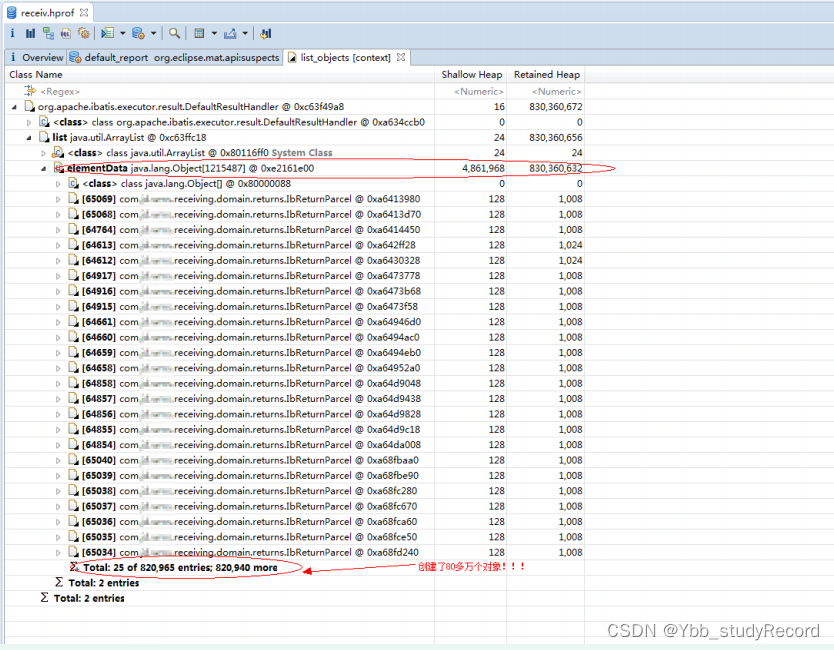
�ܽ�:�ڴ���������кܶ�,ʹ��MAT�����е�һ�ַ���������,�����ֶ�����JVM�ڴ���Ϣ��,������ͨ������JVM����,��JVM�����ڴ�й¶��ʱ���Զ������ļ���
ArrayList�ݹ����addAll���������ڴ����
1����������
casegroupIdΪ7197�ķ�����ɾ���ɹ���
����һ̨�������ڴ��20%������60%,cpuһֱ����100%״̬��
����һ��ʱ��÷���������������Network error�쳣��
��־�ϱ� Java.Lang.OutOfMemoryError:Java heap space�ڴ�����쳣
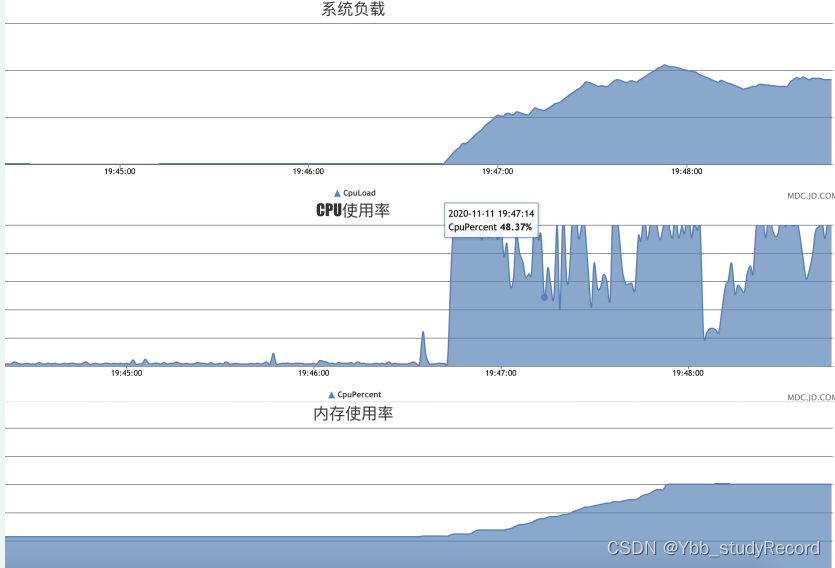
2���Ų����
����log��־�Ų鷢��,ÿ�η������ڴ�����ǰ���е���ɾ������casegroupIdΪ7197�ӿڵIJ�����
�����ݿ��������ػ�����,�����˸�����,��λ�������������:
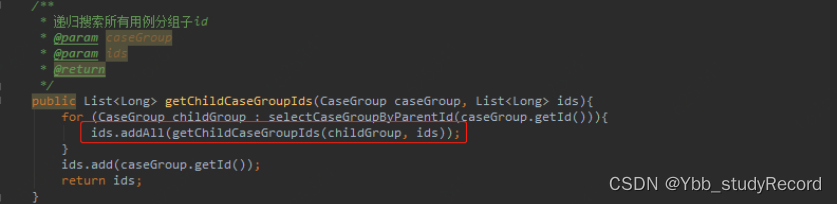
3��ԭ�����
���εݹ�ԭ˼����ids(ArrayList)Ϊ����,ѭ������ÿ���ӽڵ������ȫ������id,�����������ڵ�,���з��ء�
����,����idsΪ���ô���,ÿ��addAll�������Ὣ���������е�ids�ظ����ӵ�������,���ÿ�����������е����ݶ��ᷢ������
�ӷ�����Сʱ,���ᷢ���쳣����ArrayList ��ÿ�����ݰ�������1.5����������ռ�,����������ʷ���ݵĿ�����
���ӷ���������27��ʱ,���鳤�ȴﵽ��134217726,�����ȳ���Integer.MAX_VALUE-8��ϵͳ����ArrayList�����㹻���������ڴ�ռ�ʱ,�ͻ���OOM�쳣��
ArrayList��Ƶ�������뿽������,Ҳ��������ִ�еݹ鷽����ʼ���׳�OOM�쳣��ι�����,Cpuһֱ����100%��״̬,��������������
����Ĵ�������,����idsΪ���ô���,����ҪaddAll�����ظ������������С�
4�������ܽ�
1����д��ݹ鷽����,�Բ�һ��Ҫ������Ե��ݹ鷽����������뷵��,����ͨ�����ܴ�������û�����⡣
2����ʹ��ArrayList��ʱ��,�������Ԥ֪����Ĵ�С��Χ,�����������������С�ij�ʼ��,������Ƶ�����ݡ�
��ȡexcel�������ڴ�й¶
1.ҵ����las.im.**.com����ʾ502,ȥ��logbook��־����Ӧ�ó����ڴ����

2.ȥump��jvm��ز�dump�ļ�����·����-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/export/Instances/las-im-manager-new/server1/logs��,��¼��ά��
��ƽ̨����dump�ļ�
3.ʹ��MAT���ߴ�dump�ļ�,�鿴�����ľ����ջ��Ϣ
at org.apache.poi.xssf.usermodel.XSSFSheet.read(Ljava/io/InputStream;)V (XSSFSheet.java:138)
at org.apache.poi.xssf.usermodel.XSSFSheet.onDocumentRead()V (XSSFSheet.java:130)
at org.apache.poi.xssf.usermodel.XSSFWorkbook.onDocumentRead()V (XSSFWorkbook.java:286)
at org.apache.poi.POIXMLDocument.load(Lorg/apache/poi/POIXMLFactory;)V (POIXMLDocument.java:159)
at org.apache.poi.xssf.usermodel.XSSFWorkbook.<init>(Lorg/apache/poi/openxml4j/opc/OPCPackage;)V
(XSSFWorkbook.java:186)
at
org.apache.poi.ss.usermodel.WorkbookFactory.create(Ljava/io/InputStream;)Lorg/apache/poi/ss/userm
odel/Workbook; (WorkbookFactory.java:73)
at
com.jd.las.im.manager.service.wareservice.impl.ImportExcelWareAddrRelationServiceImpl.importExcel
(Lorg/springframework/web/multipart/MultipartFile;)Lcom/jd/las/im/util/data/Result;
(ImportExcelWareAddrRelationServiceImpl.java:114)
at
com.jd.las.im.manager.action.basis.wareservice.WareAddrRelationController.upload(Lorg/springframe
work/web/multipart/MultipartFile;)Lcom/jd/las/im/util/data/Result;
(WareAddrRelationController.java:401)
4.ȥ�����в����,excel�����ȡ��ʹ��WorkBook�ķ�ʽ,�����Լ���excel�ļ������ռ�ô������ڴ�(��1g)
5.ȥ��poi�ĵ�http://poi.apache.org/spreadsheet/how-to.html ,����POI�ṩ��2�ж�ȡ
Excel��ģʽ,�ֱ���:
�û�ģʽ:Ҳ����poi�µ�usermodel�йذ�,�����û��Ѻ�,��ͳһ�Ľӿ���ss����,�������ǰ������ļ���ȡ���ڴ��е�,���ڴ������ݺ������ڴ����,����ֻ������������Խ�С��������;
�¼�ģʽ:��poi�µ�eventusermodel����,�����˵ʵ�ֱȽϸ���,�����������ٶȿ�,ռ���ڴ���,������������������Excel����
6.�ο���poi�ٷ�example,ʹ���¼�ģʽ,��ȡexcel,���������
ͨ��sql��ѯ����ȫif���µ��ڴ����
����:
20210726����grafanaƽ̨�� ���Ӹ��˽���������� 17s���ҵĵ���(ƽʱ�˷�����ִ��ʱ��ԼΪ400-600ms)
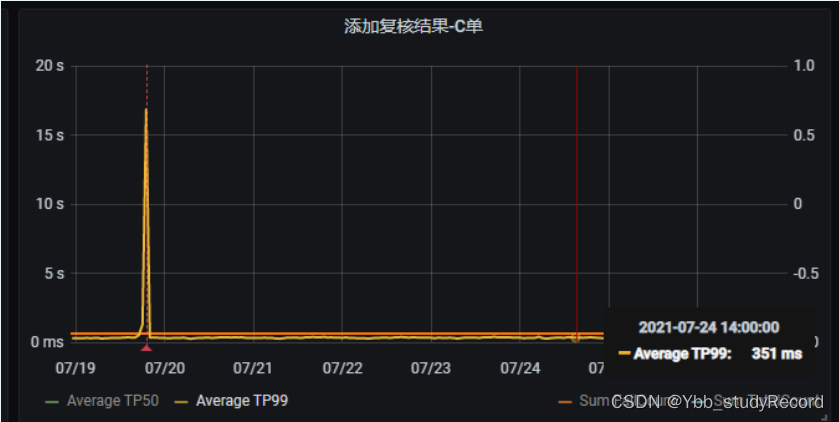
�������:
1.����WMS�ǰ���������ġ���Ӧ����ȡ����ȫ��ƽ��ֵ,������Ҫʹ���Զ��忴������ ȷ����Ӧ����,���ö�Ӧ�Ŀ���������鿴:
����7��19�ճ�����һ������ʱ�� ����42min��ump �澯
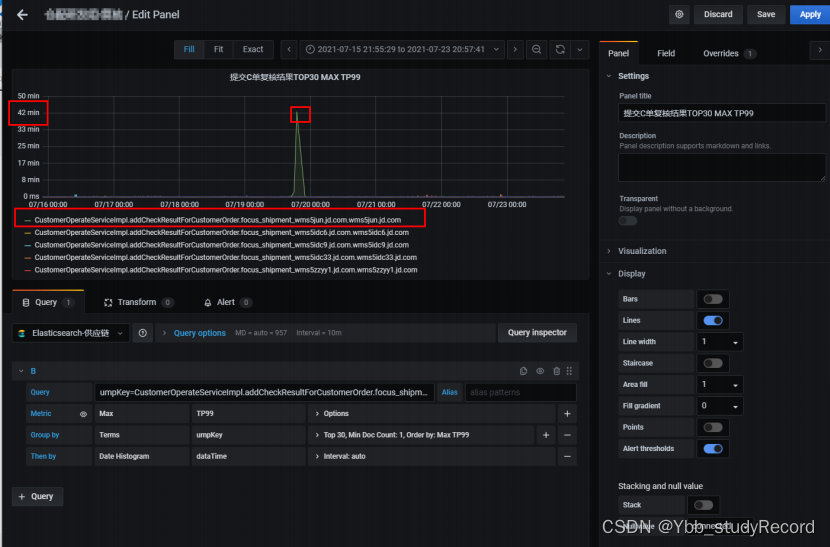
2.ʹ�ö�ӦumpKeyֵ:���Ҷ�Ӧ�Ļ���IP,���� wms�ͻ��˵��ú�̨���ȴ�ʱ��Ϊ1.5min,���Ի��ɴ˵���Ϊ ��������������ϱ�UMP,UMPһֱ�ȴ�profiler.end�����ϴ�,��ȡ����������Ļ���Ϊ172.31.136.xx
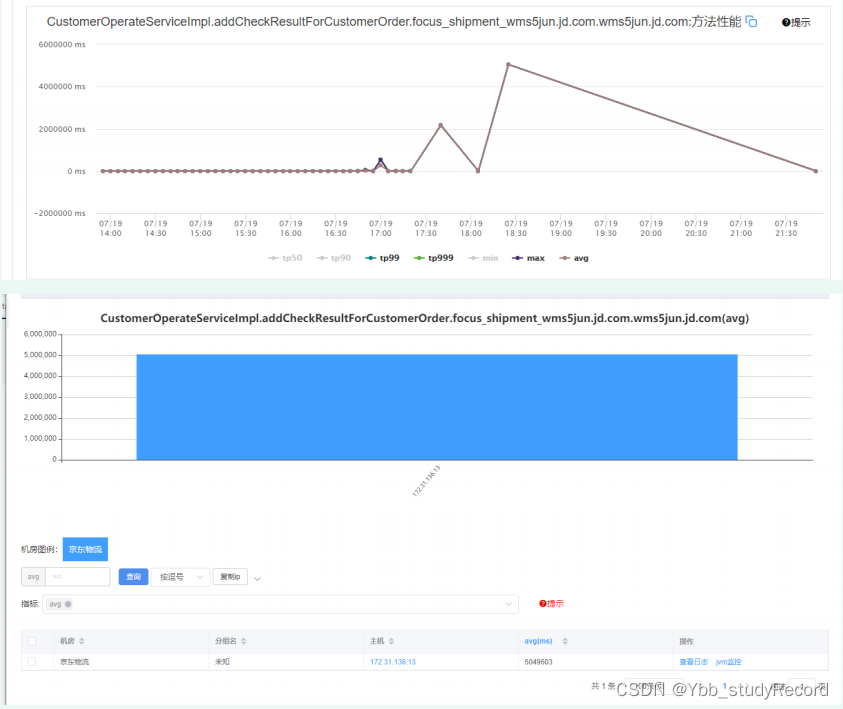
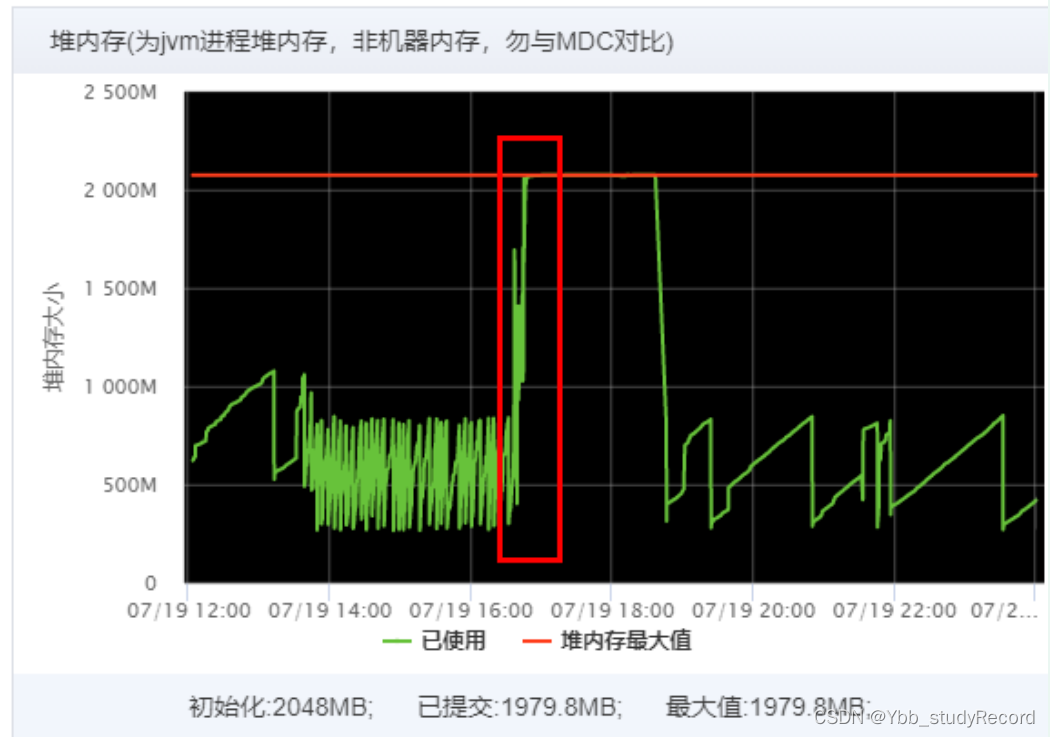
3.��ѯIP ��Ӧ������Ӧ��jvm�ڴ�,���ֶ��ڴ� �� 7��19��17�����ҿ�ʼ쮸�,���ռ����
profiler.end���ύʱ����� ��Ӧ�����ʱ������16:58���ҷ���,��ͼ��JVM���ʱ��һ��
��ѯ��ַ:
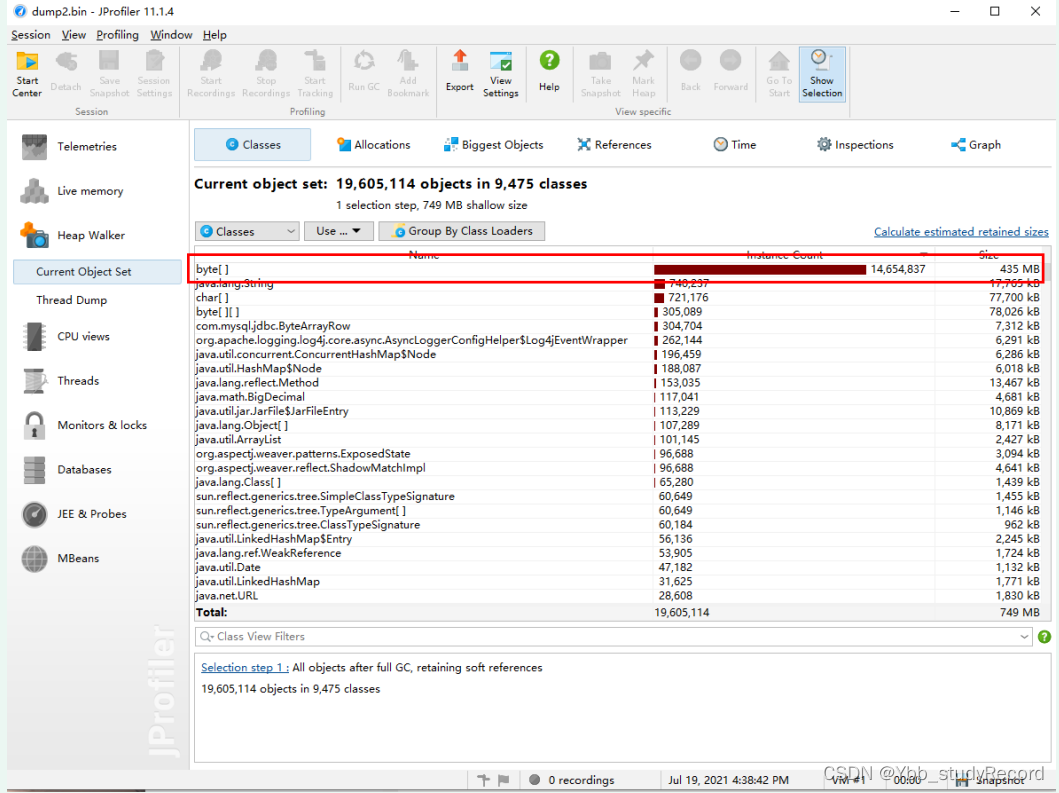
4.ĿǰJVM������־�ж������� �ڴ����ǰ�Զ�dump,ǰ����Ӧ�Ļ���dump��־���з���,ʹ�ù���Ϊjprofiler,�������� ����byte����ռ����435MB������,���ҵ�����ԴΪ
ibatis.executor.resultset.ResultWrapper,����jprofiler����,������ȫ����ѯ��� �����˴�����µ��ڴ����
5.��¼myops���в�ѯ��Ӧ���ݿ��Ƿ������sqlȫ����ѯ
�ҵ��������,ͼ��SQLֱ�ӹ��������ϸ�Ͷ�����ϸ���в�ѯ δ�����κ�����,���ݲ�ѯʱ�� ���鵽��Ӧ���������־: ȷ��ԭ��Ϊ�з������ָı��ĵ��÷���� ���µ��ڴ����(���յ�:ͨ��sqlΪ�˱�֤������,����������ȫif�ж�,����ȫ����ѯ)
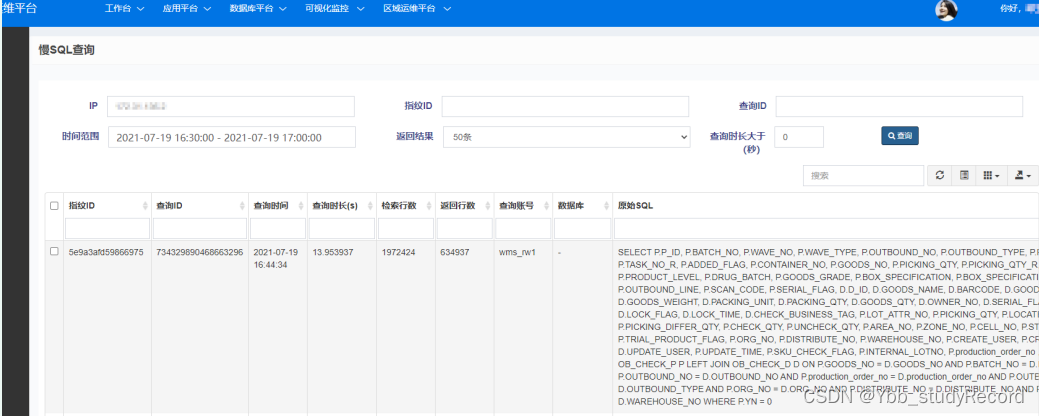
����sql:
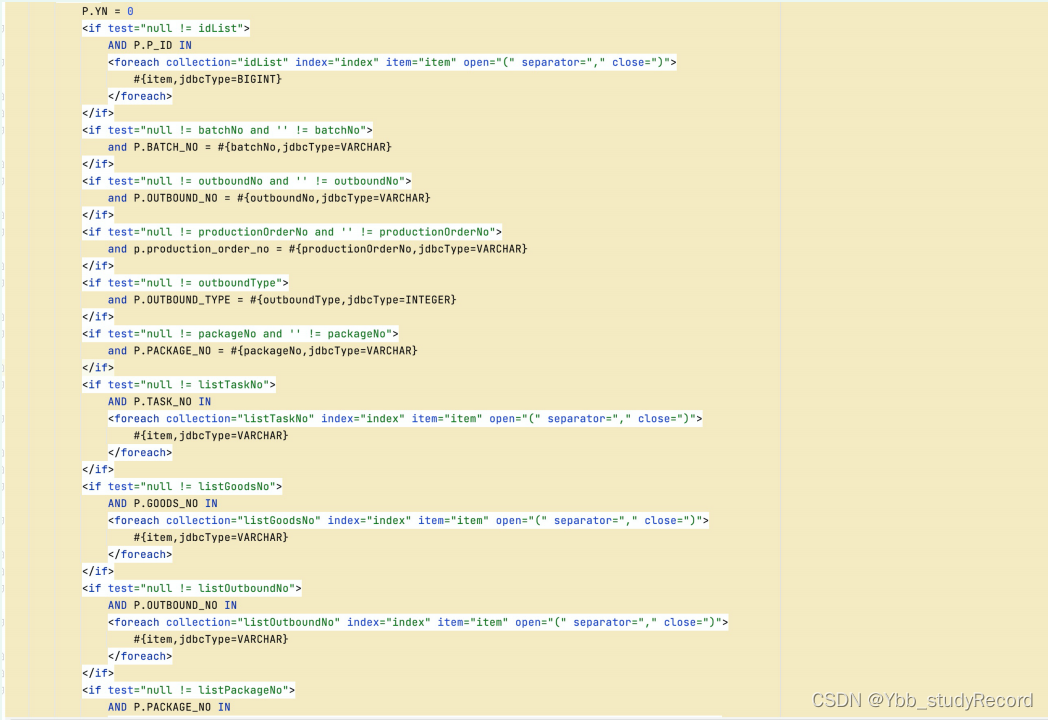
�ķ���: ���Dao���һЩ������������ǿ��У��(��Ҫ��)
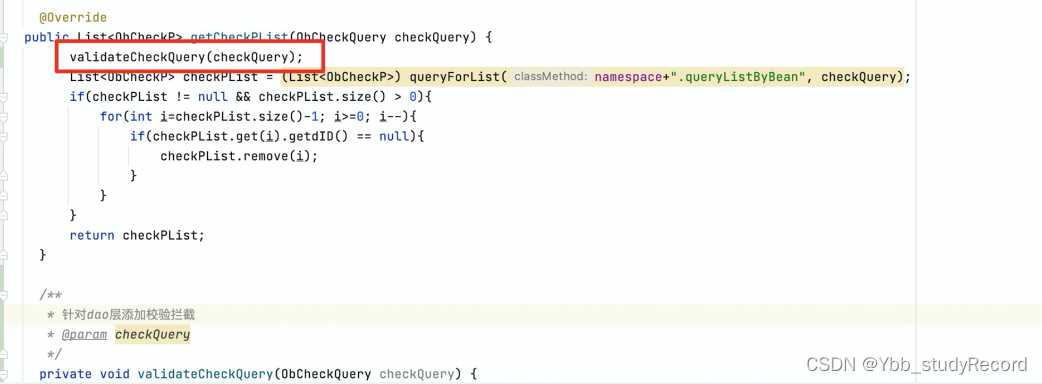
JVM��ջ�ڴ�����������
һ���¼��ع�
���崦��ʱ��:2020��07��23�� ����18:10 �� 21: 50
�漰����: 10.176.213.11, 10.176.213.7, 10.176.243.78, 10.176.243.75
�ؼ��澯����:JVM��ض��ڴ�ʹ���ʳ�����ֵ,URL̽������x�η���Ŀ���ַ�������糬ʱ����ϵͳ�쳣;
�澯Ӱ�췶Χ:�����û�(5������)
�¼���ϸ����:
18:10 ���յ� 10.176.213.11 ������������JVM�ڴ�ʹ���ʳ����澯,������յ���
������������URL̽�����Ŀ���ַ�������糬ʱ����ϵͳ�쳣�澯;
18:11 ��¼NPϵͳ,ժ��������
18:11 ��¼J-One,�ų���Ϊ����ϵͳ
18:12 ��¼��־ϵͳ,�鿴������־�������;�ų�log4j����־Bug;
18:12 ��¼UMPϵͳ,�鿴����JVMָ��:Yong GC 0~1 ��/���� (����),Full GC
20+��/����(������,ƽʱΪ0),���ڴ� 3.99G,ռ��100% (������,ƽʱΪ500M~1.7G,ռ�Ȳ�����50%),�߳��� < 1500 (����)
18:15 ����J-Oneϵͳ,����������ջ��Ϣ��������־;
18:16 �յ� 10.176.213.7 ������������JVM�澯,�������յ���������������URL̽�����Ŀ���ַ�������糬ʱ����ϵͳ�쳣�澯;
18:17 NP�ϲ��� 10.176.213.7 ��������
18:18 ��UMPϵͳ�鿴10.176.213.7 �� JVM����ָ��,ָ�������10.176.213.11��ͬ;
18:20 ������10.176.213.11 ִ��Ӧ����������
18:28 ������10.176.213.7 ִ��Ӧ����������
18:30 ������10.176.213.11 �������,����ָ��ָ�����ˮƽ,��֤��һ�����;
18:35 ����10.176.213.7 �������,����ָ��ָ�����ˮƽ,��֤��һ�����;
18:41 ���յ� 10.176.243.78 ������������JVM�ڴ�ʹ���ʳ����澯,������յ���������������URL̽�����Ŀ���ַ�������糬ʱ����ϵͳ�쳣�澯;
18:42 NP��ժ�� 10.176.243.78 ������;
18:45 ����10.176.243.78 �����Ķ�ջ��־��������־;Ϊ�����¹�ԭ�����,������δ������������;
21:49 �յ� 10.176.243.75 ����������JVM�ڴ�ʹ���ʳ����澯,������յ���������������URL̽�����Ŀ���ַ�������糬ʱ����ϵͳ�쳣�澯;
21:50 ��NP��ժ�� 10.176.243.75 ����;
�ڶ��� ����: �����Ѿ�������һ̨�¹�����,��������10.176.243.** ����,��֤��һ�;
�����������
������Դ:
����JVM�ڴ����ʱ���ɵ�hprof; һ������,�ֱ���Դ��10.176.243.������10.176.213.��
��;
��־:һ���ķ�:�ֱ���Դ�ڳ����������̨������eclp_selle.log;
�ؼ�����:
JVM��ջ������:�����
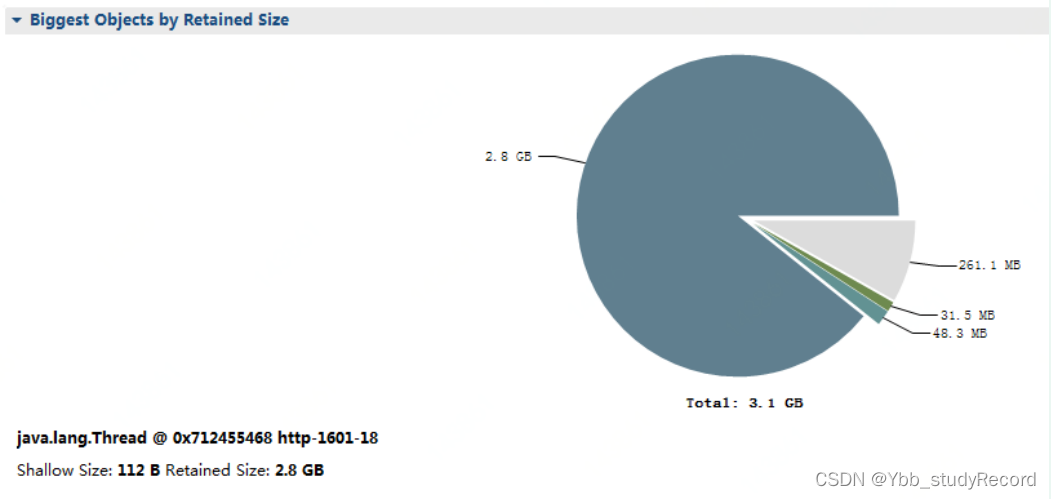
������е�ռ���ڴ���������
δ���ü��ͷŵ�XML��������: �������Ѿ�����,�ں���
�̵߳��õ�HTTP��Ӧ����:
�û��ϴ��ļ�
����ԭ�����:
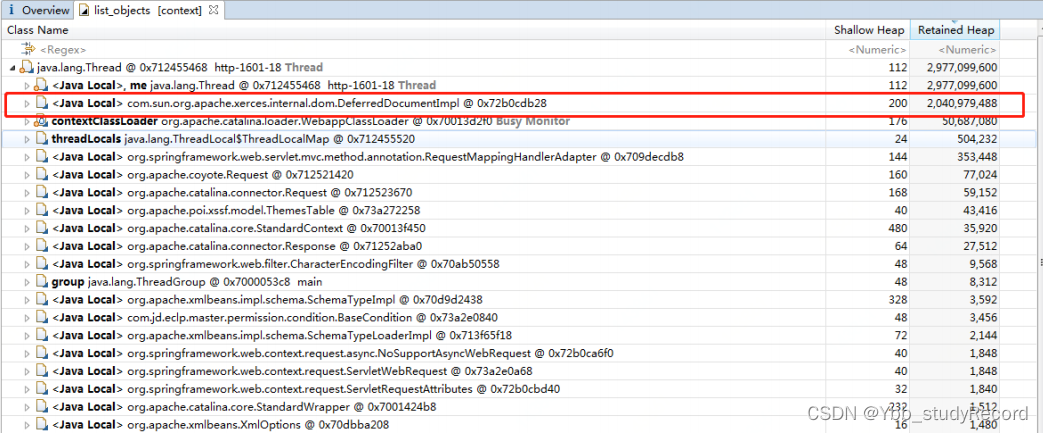
�ڲ鿴JVM�ڴ��ջ��Ϣ���������,Orverview�Ĵ����ͼ����,˵����Ϊ"http-1601-18"���߳�����ʱռ���ڴ泬��2G;�̶��鿴���߳�ʵ����������ʵ����ϸ�б�;
�����߳���ռ���ڴ�����ʵ����Ϊ:
com.sun.org.apache.xerces.internal.dom.DeferredDocumentImpl ,ռ���ڴ� 2G ����;��
������ȷ����ʵ���Ĵ��������JVM�ڴ����;
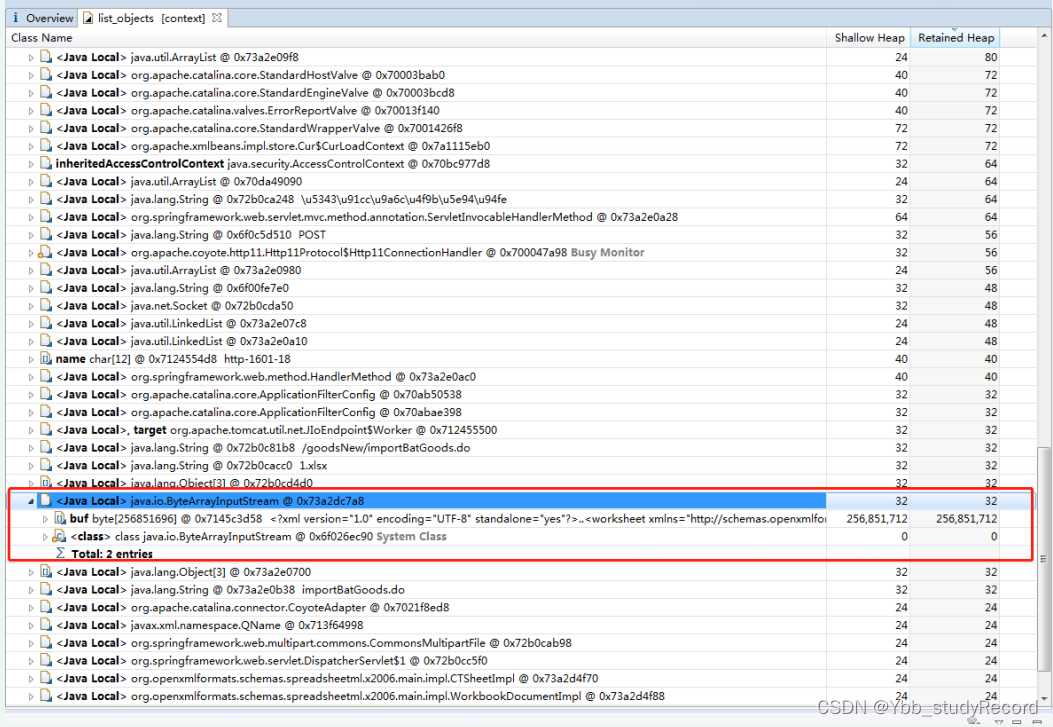
����ʵ����POI���߰����ڽ���xlsx��ʽ�ļ��е�XML�ļ��õ�,Ҳ����˵����Ϊ���߳�ִ�й�������Ҫ��xlsx�ļ���������
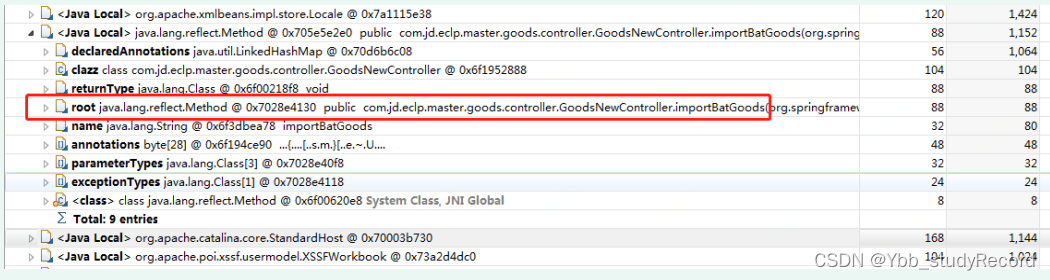
������ѯ���̵߳ĵ���HTTPҵ��ӿ�,��:com��master.goods.controller.GoodsNewController#importBatGoods ;
��ϴ���,��֪�˷�������������������ҵ����Ʒ���ݵ�,���������:
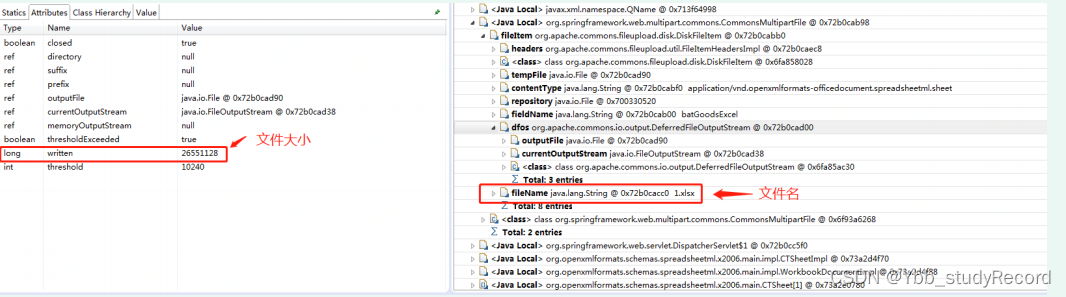
- �����û������xlsx�ļ�
- ʹ��POI�����ļ����н���
- ѭ�����������������,�����ǽ���������֤���������(��������Ʒ)����
- ���ص�����
��ϵĴ�����,��ջ��Ϣ����,��������Ϊijһ�û���ִ�иIJ���ʱ,�����˹����ļ�,���´˴ε�JVM �ڴ�����¹�;
Ȼ���ѯ��̨����������־:��Ȼ����ͬһ���û���ÿ�θ澯ǰ�ļ�����,�����̼ҹ���ִ̨������Ʒ�������;
����ó�����JVM�ڴ����������ԭ��Ϊ:ϵͳ��δ�Ե����ļ���С�����ƻ�����̫����; �Ӷ������û�����ϴ���ļ�ʱ�ڽ��������г��� JVM�ڴ��������;
�ġ�����������
1�����ϴ����ļ����д�С����;���Ƶ�ԭ����Ǹ���ģ���������Ŀ����,���� ��һ����������ֵ;����ʵ��:1000���������ļ���СԼ��135K,5000������ ����С��619K;Ҳ����˵�ļ���С��Ӧ�ó���1M; ����������,�û��ϴ����ļ���С��26M����;
2����������ʱ,Ҫ�Ƚ�������������֤,�ڶ������ݽ��н���;������������ת ��������
�����������ֻ����ڴ���������
һ��ժҪ
ʱ��:2018.1.31 13:30:00 --2018.1.31 17:00:00
����:3c�����û��������ʱ,�����������502������;���²���������ʧ��
ԭ��**:**����������һ̨������,jvm��Ϊ�ڴ��������崻�
Ӱ��:�û�����ʱ����,Ӱ�췶Χ��С,5̨������,һ̨��������
Ӧ����ʩ:��������Ļ����Ӹ�����ȥ��,��֤���Ϸ�����������,����ʱ��Լ30������
�����¹ʱ���
ϵͳ����11�µ�����,һֱ��������,û�����ⷴ��,ǰ���г����۲������,û�з������⡣��2018��1��31��,�ӵ�ҵ������Ԥ���ʼ�,�����������502����������鿴����5̨�������е�һ̨崻�,Tomcat�����Ѿ��������ˡ�
�����¹ʷ�������
��һ��:�ѳ��������̨�������Ӹ�����ȥ���������������֮��,��jdos�ļ�����ĶԸ÷������������µ�����������������״̬���й۲췢��:�÷�������jvm�Ѿ�û������,����������jvm�ڴ���ӽ�100%,��������������Ҳ�᧿�Σ����
�ڶ���:�鿴����崻�����̨��������־,�ؼ���Ϣ����:

Ϊ�˲鿴����־�ļ�,��jdosͬ��,���뿪ͨ�� �÷����� �� ����һ̨���ٱ����ķ������� �ն�������Ϣ;
���ļ���Ϣ������ȫ�ǵ�ʱ�����ǵ��ڴ��һЩ��С����(���ǽ�ͼ),�ο����岻��;
������:������Ϊ�˲鿴�ڴ��е�����ʲô���������ڴ�ı���,����jvm������,��ȡ�������ڵ�һЩ��Ϣ��,�������ӵ�����һ̨����Σ���ķ�������,ȥ�鿴jvm�ڴ��һЩ״��,�����������
����ʹ�ò鿴���� jvm����IDΪ 139
ʹ�ø����� :sudo -u admin ./jmap -histo 139|more �鿴�����������:
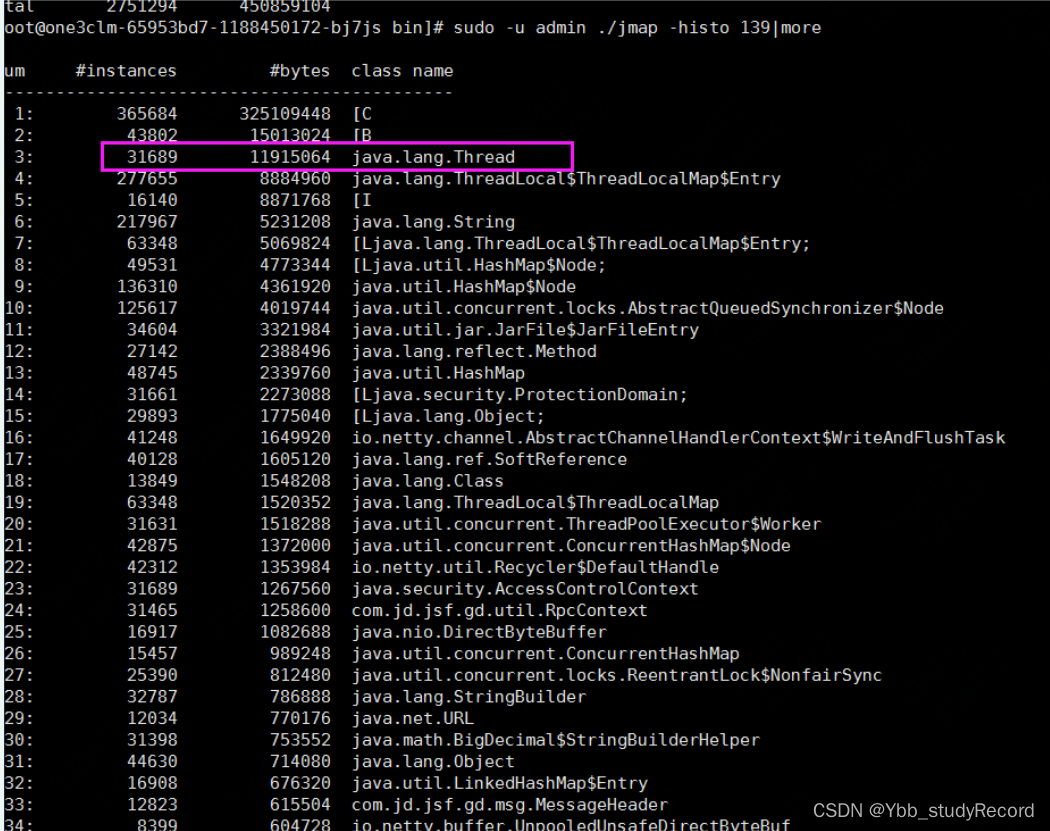
�鵽��7000����̳߳�,���Զ�λij���ط��ڷ���̳߳�,�϶��˵�һ�����ж�
Ȼ��ȫ���� Executors,����֮ǰ��ͬ�������������̳߳�,������ÿ�θ�����ӿڻ����϶��ᴴ��һ���̶�4����С���̳߳�!ԭ�������ҵ���;�˴��о�һ��: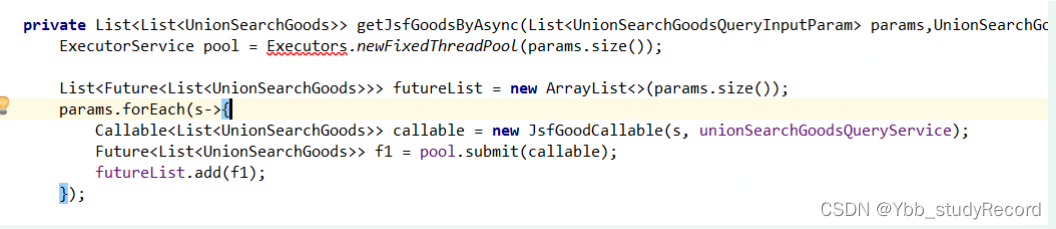
����,��崵��Ļ�������,Ȼ��Ƶ����ȥ����ýӿ�,�������쳣���,�ɴ˿��Կ϶����жϡ��˴���Ϊ������ʱ��һ���̳߳�,�����ʱ��һ��Callableʵ�ּ��ɡ�
��:���ϴ˴η�������jvm����,�Լ�dump�ļ���С

ʹ������ sudo -u admin ./jmap -dump:format=b,file=a.hprof 139��
�ġ��¹ʷ�˼�ܽ�
1�������������Ԥ������λ,�˴�����Ԥ��,���·������쳣,û�м�ʱ����,������ҵ��֪ͨ���ֵ�,�Ժ�Ӧ������������ٴη�����
2�����˺�����Ŀ,��Ŀʱ�䳤һЩϸ�ڶ����Ѿ��ǵIJ�������,�Ժ���Ҫ����Ƶ�������������,������˽�����⡣
3���б�Ҫ����codeReview,���ѧϰ,�������
4��Ӧ������ǿ����ѧϰjvm���֪ʶ,�˴����¹�����һ����ѧϰjvm��·�ϵ�һ���ɹ����������
JVM�쳣��ֹ�����Ų�
1.����
11��19��,jdos��̨����JVMͻȻ�ҵ�(11.26.78.xx��10.190.183.xx),
�鿴MDC���,����jvm�ҵ���ʱ��� �����ڴ�ռ�úܸ�(99%);
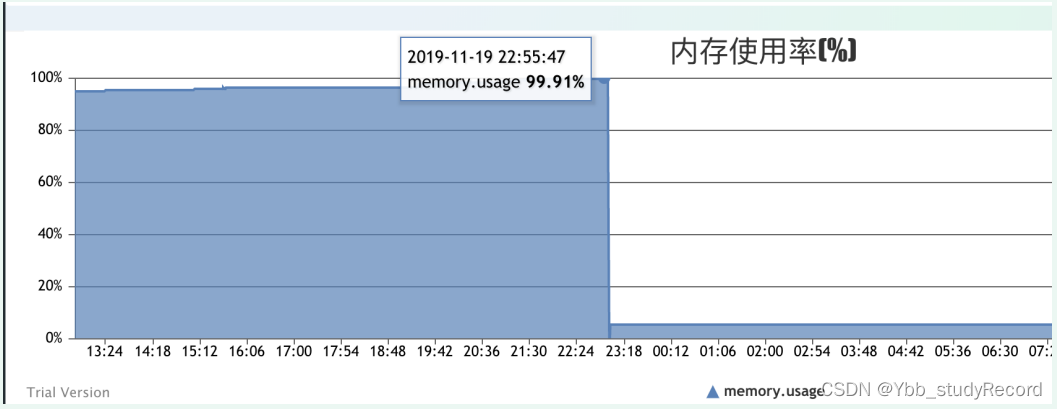
�鿴UMP-JVM���,JVM����ָ�������
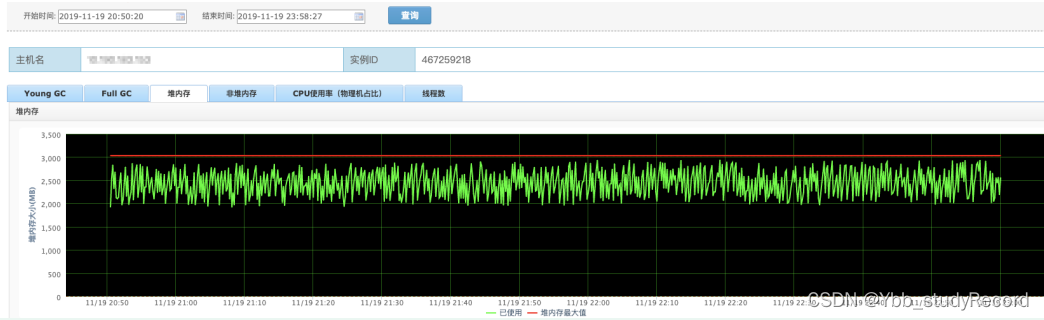
�����ڴ���ܲ�ȷ
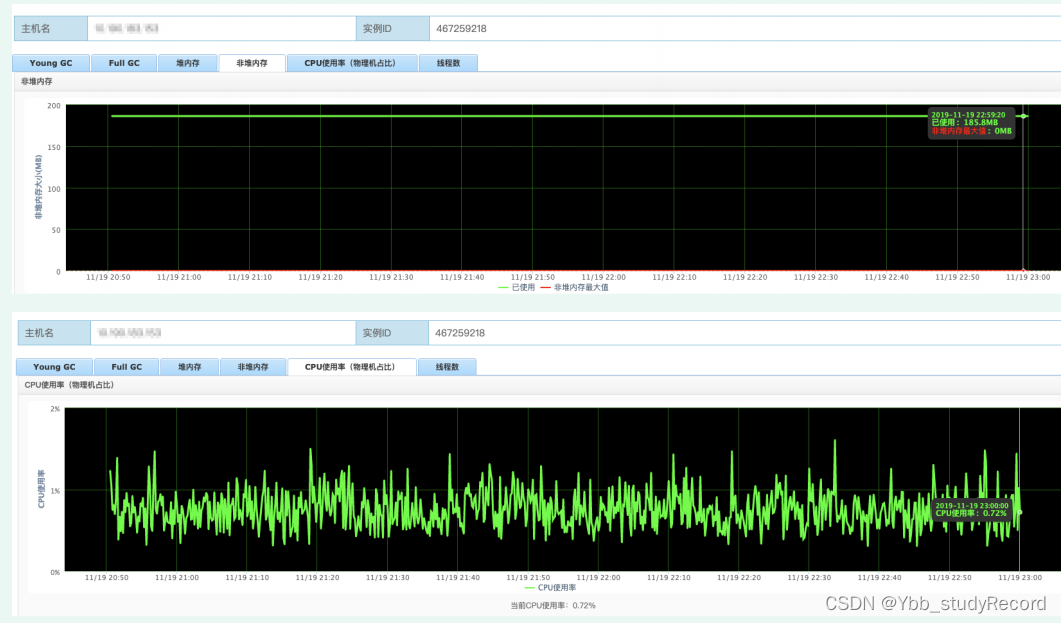
�ڴ��ƽ��,ÿ��yong gc,���ܽ�����;��JVM�ҵ�֮ǰ,δ������full gc;CPU���߳���Ҳ����������
2.�������������λ-����Google
linux��OOM killer
Linux �ں��и����ƽ�OOM killer(Out-Of-Memory killer),�û��ƻ�����Щռ���ڴ��
��,������˲��ܿ����Ĵ����ڴ�Ľ���,Ϊ�˷�ֹ�ڴ�ľ����ں˻�Ѹý���ɱ���� ���,�㷢��java����ͻȻû��,����Ҫ�����Dz��DZ�linux��OOM killer���ɵ���!
OK,˳�����˼·,ȷ�������Dz��DZ�oom killer�ɵ��ġ�
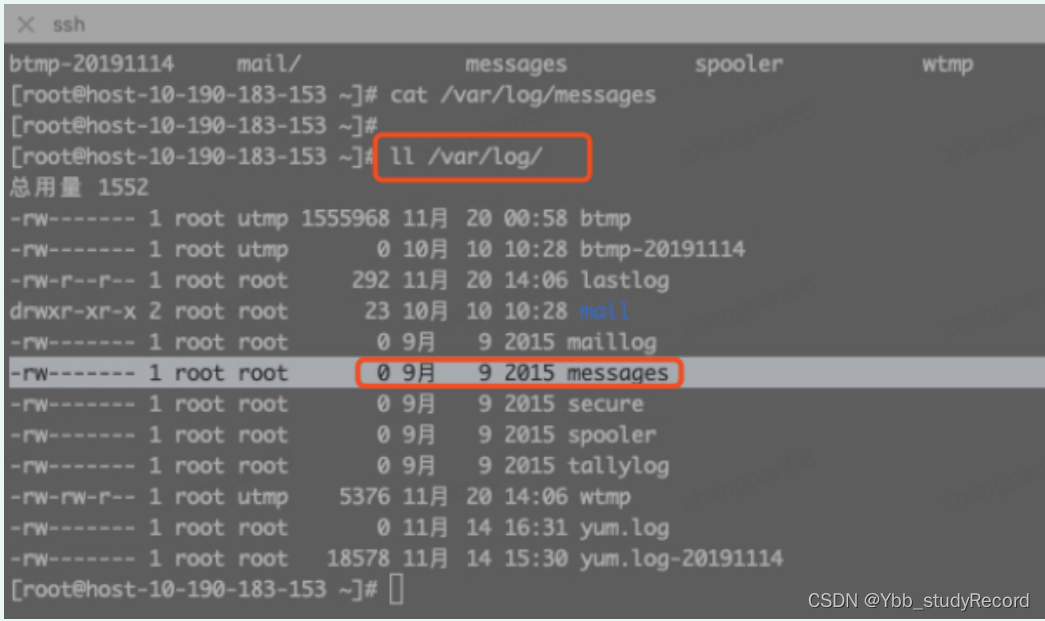
�鿴ϵͳ������־: /var/log/messages,���ִ��ļ��ǿյ�(������ѯjdos��άͬ�µ�֪,dockerʵ�� д����־������)
�鿴�ں���־:
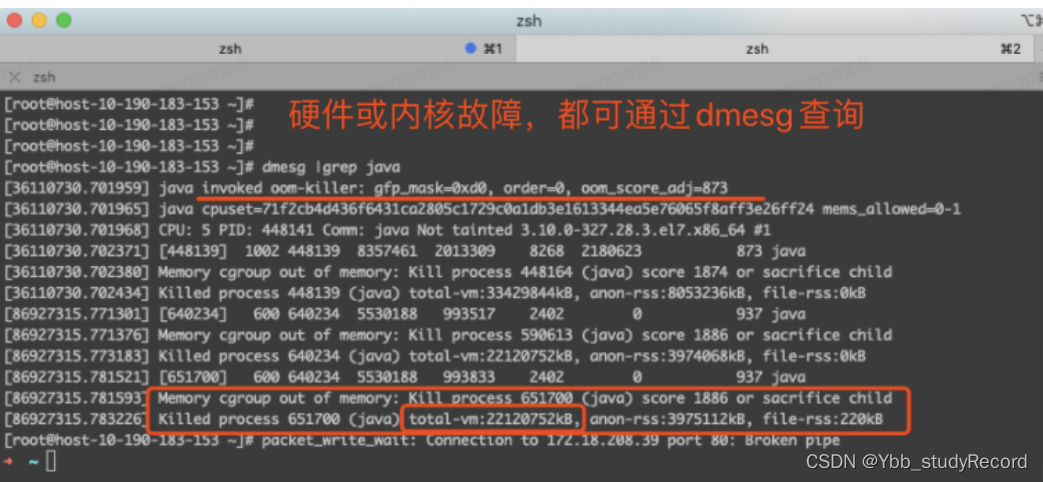
dmesg�����Ϣ�е���oom-killer,���Ǵ��ڴ�����ò������������(total-vm:22120752kB),ʱ�����ȷ��;
��ϵ��ά��ѯ:
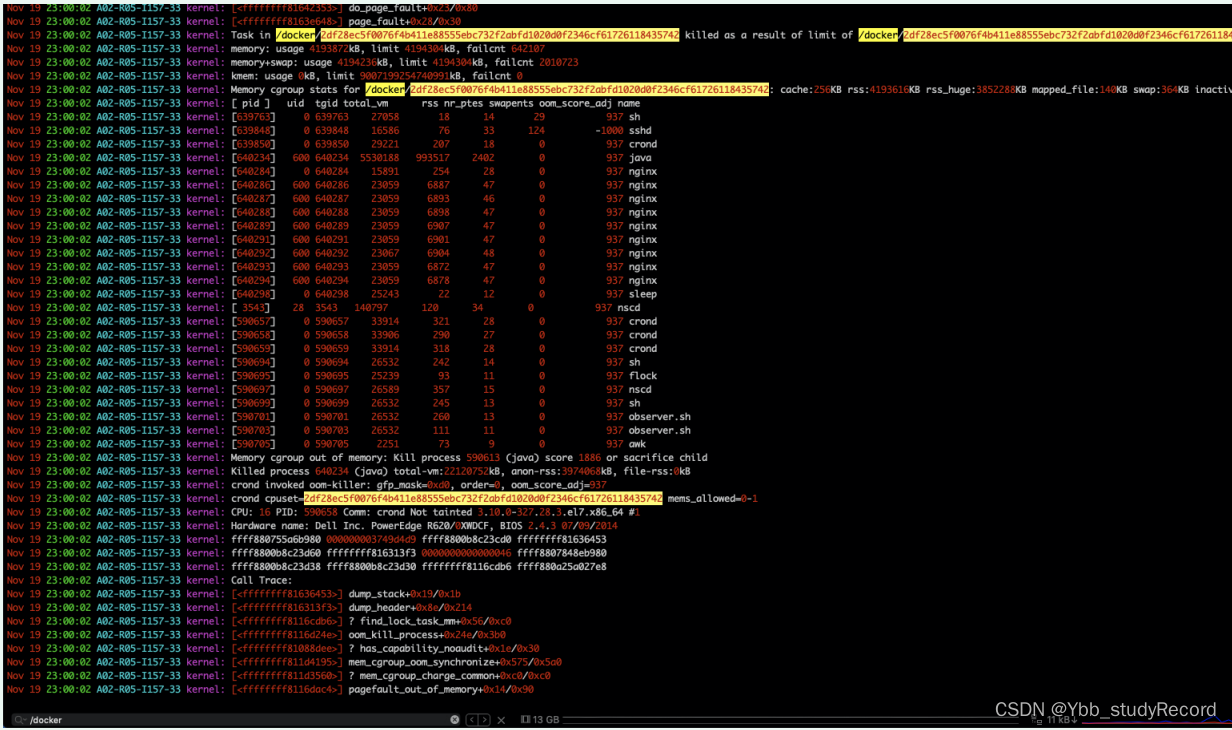
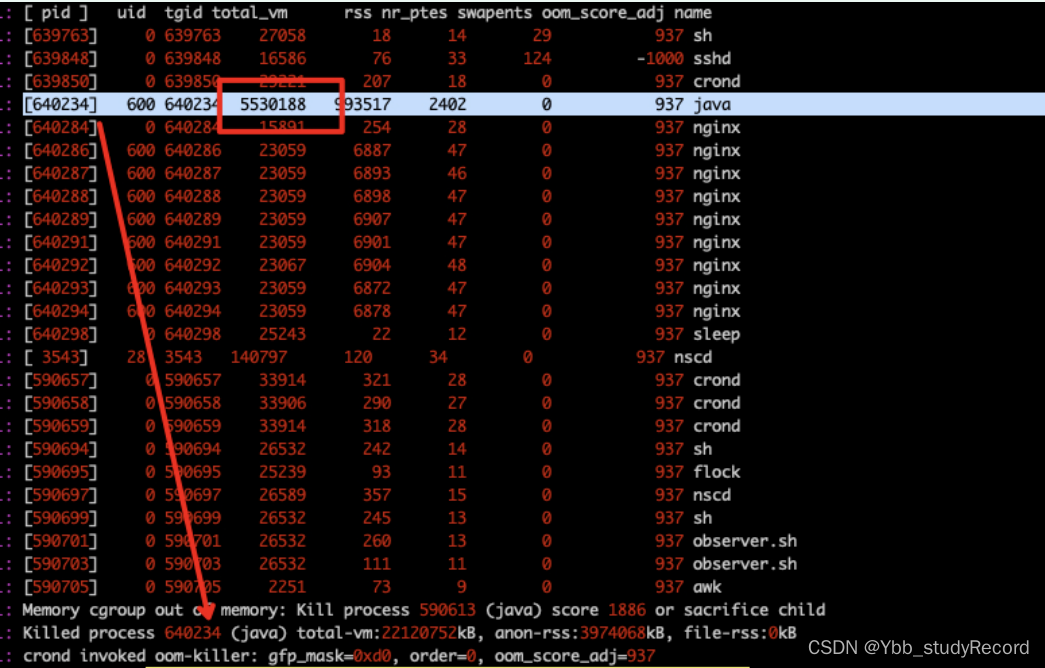
����ȷ��JVM�DZ�����ϵͳoom killer�ɵ���,
����:docker���4c4g,Ϊ��java���̻�ռ��5.2g?
jdk1.8��֮ǰ,JVM�Ǹ�֪���������Ĵ��ڵ�,���Ի�ʹ������������Ϣ������,docker -m����һ����������Ӧ���ڴ��С,������汾Ҳ�кܴ��ϵ,�еİ汾���ƵIJ���൱�������ڴ�İٷ�֮50.
ģ��:OOMKilled
����˵��һ������:����jvm�쳣�˳�,����dump�ļ�,dump���û��,��
hs_err_pid.log��־�������û��,���ں���־��
jvm��������
��8G�ڴ�Ϊ��:
1-�����������IJ���
2-Ԫ�ռ���Ҫ��(�������������)?512,350
3-���ڴ������С?4G
4-ջ��С?512k
5-ֱ�������ڴ�? nio,��һ�������
6-GC��־,
���������õ�:
��������ı���,Ĭ��ֵ,