1.����
1.JVM����ܹ�
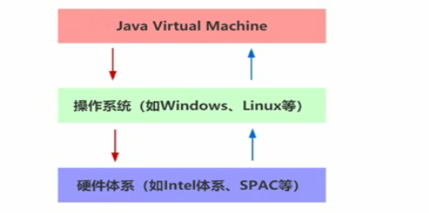
JVM(�����):ָ�������ķ�ʽģ���������Ӳ��ϵͳ���ܡ�������һ����ȫ���뻷���е����������ϵͳ ,��������������ʵ�֡�
- ��Ϊһ�ֱ�����Ե������,ʵ���ϲ�ֻ��ר����Java����,ֻҪ���ɵı����ļ�ƥ��JVM�Լ��ر����ļ���ʽҪ��,�κ����Զ�������JVM�������С�����kotlin��scala�ȡ�
- b.jvm�кܶ�,��ֻ��Hotspot,����JRockit��J9�ȵ�
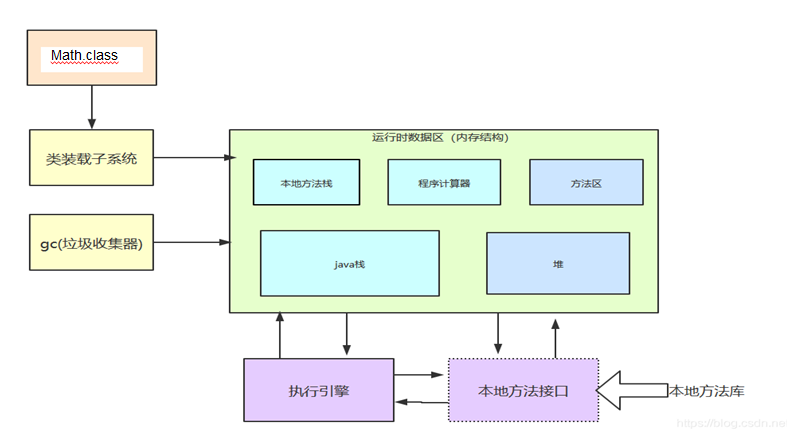
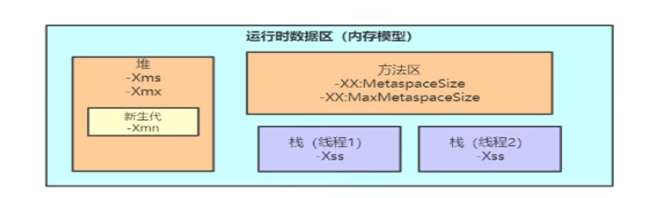
2.JVM�ڴ�ṹ
3.����ع���

1.����:��Ӳ���ϲ��Ҳ�ͨ��IO�����ֽ����ļ�
2.����:ִ����֤��������������
3.��֤:У���ֽ����ļ�����ȷ��
4.��:����ľ�̬���������ڴ�,������Ĭ��ֵ
5.����:�����������滻Ϊֱ������,�ýλ��һЩ��̬����(��������,����main())�滻Ϊָ�����������ڴ��ָ�������(ֱ������),������ν�ľ�̬���ӹ���(������ڼ����),��̬������ָ�ڳ��������ڼ���ɵķ��������滻Ϊֱ������
6.��ʼ��:����ľ�̬������ʼ��Ϊָ����ֵ,ִ�о�̬�����
4.�������
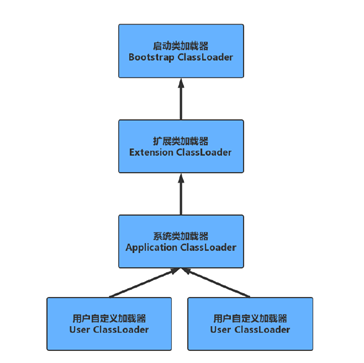
�����������:�������֧��JVM���е�λ��JRE��libĿ¼�µĺ������,��JREĿ���µ�rt.jar,charsets.jar��
��չ�������:�������֧��JVM���е�λ��JRE��lib Ŀ¼�µ�ext��չĿ¼�е�jar���
ϵͳ�������:�������ClassPath·���µ����,��Ҫ���������Լ�д����Щ��
�û��Զ��������:��������û��Զ���·���µ����
5.����ػ��ƨC˫��ί�ɻ���
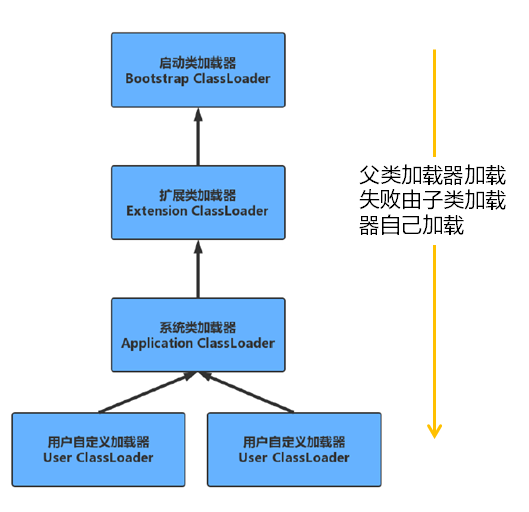
��ν��˫��ί��,�������ø����������ͼ���ظ�Class,ֻ���ڸ�������������ظ���ʱ�ų��Դ��Լ�����·���м��ظ��ࡣͨ�Ľ�,����ij���ض�����������ڽӵ������������ʱ,���Ƚ���������ί�и���������,���εݹ�,���������������������������,�ͳɹ�����;ֻ�и�����������ɴ˼�������ʱ,���Լ�ȥ���ء�
ɳ�䰲ȫ����+��������ظ�����
ɳ�䰲ȫ����:�����Լ�д��String.class��ᱻ����,�������Է�ֹ���Ŀⱻ����۸�
��������ظ�����:����ClassLoader�Ѿ������˸����ʱ��,�Ͳ���Ҫ��ClassLoader�ټ���һ��
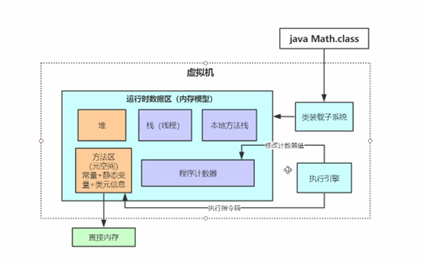
2.�ڴ�ģ��
1.�����ջ

Java�߳�ִ�з������ڴ�ģ��,һ���̶߳�Ӧһ��ջ,ÿ��������ִ�е�ͬʱ���ᴴ��һ��ջ֡(���ڴ洢�ֲ�������,������ջ,��̬����,�������ڵ���Ϣ)������������������,ֻҪ�߳�һ������ջ���ͷ�,�������ں��߳�һ�¡�
2.������
��ų���,��̬����,��Ԫ��Ϣ
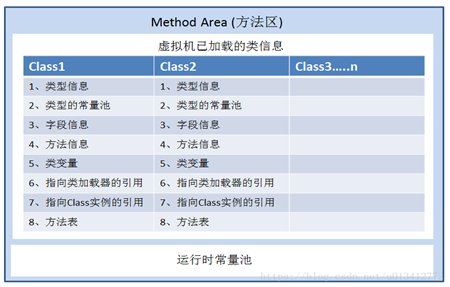
��������ֶκͷ����ֽ���,�Լ�һЩ���ⷽ���繹�캯��,�ӿڴ���Ҳ�����ﶨ�塣
����˵,���ж���ķ�������Ϣ�������ڸ�����,��̬����+����+����Ϣ(���췽��/�ӿڶ���)+����ʱ�����ض����ڷ�������,��ȻJava������淶�ѷ���������Ϊ�ѵ�һ��������,������ȴ��һ����������Non-Heap(�Ƕ�),Ŀ��Ӧ����Ϊ�˺�Java�Ķ����ֿ�
װ����ϵͳ��class�ļ����ص�������,����Ԫ��ʽ���
3.���ط���ջ
���ط���ջҲ���߳�˽�е��ڴ�����,��Javaջ���ñȽ�����,��֮ͬ�����ڸ�������Ҫ�DZ���native������ص����ݡ��Ǽ�native����,��Execution Engineִ��ʱ���ر��ط����⡣
Native�����Ƿ�Java���Ա�д�ķ�����
4.��
���������ʱ�Զ����䴴��,���ڴ�Ŷ����ʵ��,�������ж����ڶ��Ϸ����ڴ�,���������ڸÿռ����뵽�ڴ�ʱ���׳�OutOfMemoryError�쳣��ͬʱҲ�������ռ�����������Ҫ����
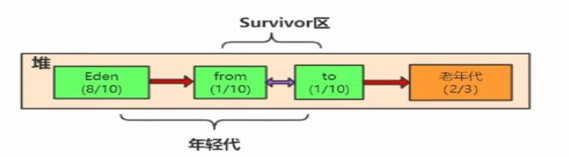
4.1 ������(Young Generation)
��������ɳ�������������,һ�������������,Ӧ��,��������������ռ�,
����������
��������Ϊ������:������(Eden space)���Ҵ�����(Survivor space),���е��������������new�����ġ�
�Ҵ����ַ�ΪFrom��To������Eden���Ŀռ�������,��������Ҫ��������,JVM��������������Eden��������������(Minor GC),��Eden���еIJ��ٱ���������Ӧ�õĶ���������١�Ȼ��Eden����ʣ��Ķ����Ƶ�From Survivor������From Survivor��Ҳ����,�ٶԸ���������������,Ȼ���ƶ���To Survivor����
4.2 �����(Old Generation)
�������������GC��Ȼ����Ķ����ƶ������������������Ҳ����,��ʱ����Major GC(Ҳ���Խ�Full GC),
�������������ڴ���������������ִ����Full GC֮������Ȼ�����ж���ı���,�ͻ��׳�
OOM(OutOfMemoryError)�쳣
4.3 Ԫ�ռ�(Meta Space)
��JDK1.8֮��,Ԫ�ռ���������ô�,���Ƕ�JVM�淶�з�������ʵ��,��������Ԫ�������������������,�����õı����ڴ�,���ô������������,���ô����ṹ��Ҳ���ڶ�,���������ϲ����ڡ�
3.JVM�ڴ����ͻ��ղ���
��ʼ֮ǰ�Ƚ�JVM����������ģʽ�Ͷ������ݷ������м���
JVM��3������ģʽ
a.����ģʽ(Interpreted Mode):ֻʹ�ý�����(-Xint ǿ��JVMʹ�ý���ģʽ),ִ��һ��JVM�ֽ���ͱ���һ��Ϊ�����롣
b.����ģʽ(Compiled Mode):ֻʹ�ñ�����(-Xcomp JVMʹ�ñ���ģʽ),�Ƚ����е�JVM�ֽ���һ�α���Ϊ������,Ȼ��һ����ִ�����л����롣
c.���ģʽ(Mixed Mode):(-Xmixed ����JVMʹ�û��ģʽ)��Ȼʹ�ý���ģʽִ�д���,���Ƕ���һЩ���ȵ㡱�����ȡ������ģʽִ��,��Щ�ȵ�����Ӧ�Ļ�����ᱻ��������,�´�ִ�������ٱ��롣JVMһ����û��ģʽִ�д��롣
�������ݷ���:���Ƿ�������̬������,��һ�������ڷ����б������,�����ܱ��ⲿ����������,����,���õ��ò������ݵ������ط��С�(����:-XX:+DoEscapeAnalysis �ر�: -XX:-DoEscapeAnalysis )��
1.����������Eden������
����������,��������������Eden�����䡣��Eden��û���㹻�ռ���з���ʱ,�����������һ��Minor GC
Minor GC��Full GC������
Minor GC/Young GC:ָ�����������������ռ�����,Minor GC�dz�Ƶ��,�����ٶ�һ��Ҳ�ȽϿ졣
Major GC/Full GC:һ����������,�����,������������,Major GC��Minor GC��10������
2.���ڴ��Ķ����������
1.����������˷ִ��ռ���˼���������ڴ�,��ô�ڴ����ʱ�ͱ�����ʶ����Щ����Ӧ�÷���������,��Щ����Ӧ�����������Ϊ��������һ��,�������ÿ������һ����������(Age)��������
2.���������Eden����������һ��Minor GC�����ܴ��,�����ܱ�Survivor���ɵĻ�,�����Ƶ�Survivor�ռ���,��������������Ϊ1.������Survivor��ÿ����һ��Minor GC,���������1��,�������������ӵ�һ���̶�(Ĭ��15��),�ͻᱻ�������������������ṩ��-XX:MaxTenuringThreshold���������á�
a.Minor GC����Ķ���Survivor���Ų���
���������Ѵ��Ķ���Ų�������,���ֻ����ܻ����Survivor��
b.�����ֱ�ӽ��������
����������Ҫ���������ڴ�ռ�Ķ���(����:�ַ���������)
JVM����-XX:PretenureSIzeThreshold�������ô����Ĵ�С,����������ô�С��ֱ�ӽ��������,������������,�������ֻ��Serial��ParNew�����ռ�������Ч��
����: -XX:PretenureSizeThreshold=1000000 �CXX:+UseSerialGC
ΪʲôҪ��������?
Ϊ�˱�����������ڴ�ʱ�ĸ��Ӳ���������Ч�ʡ�
c.����̬�����ж�
��ǰ�Ŷ����Survivor������(����һ������,�Ŷ�����ǿ�Survivor��),һ��������ܴ�С�������Survivor�����ڴ��С��50%,��ô��ʱ���ڵ������������������ֵ�Ķ���,�Ϳ���ֱ�ӽ���������ˡ�
1.����Survivor����������һ������,����1+����2+������+����n�Ķ����������ܺͳ�����Survivor�����50%,��ʱ�ͻ������n���ϵĶ������������
2.Minor GC ֮��
d.������ռ���䵣������
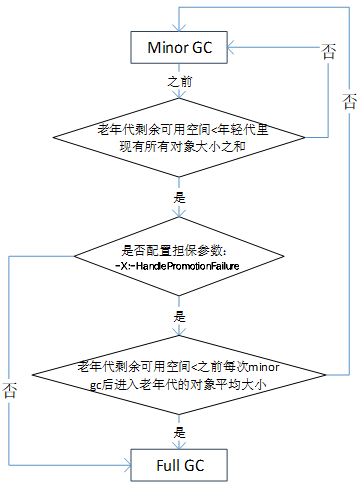
1.�����ÿ��minor gc֮ǰJVM��������������ʣ����ÿռ䡣
2.���������ÿռ�С������������е����ж����С֮��(������������),�ͻῴһ����-X:HandlePromotionFailure��(JDK1.8Ĭ�Ͼ�������)�IJ����Ƿ�������,������������,�ͻῴ��������Ŀ����ڴ��С,�Ƿ����֮ǰÿ��minor gc�����������Ķ���ƽ����С��
3.�����һ�������С�ڻ��߲���û������,��ô�ͻᴥ��һ��Full GC,��������������һ�����һ��������
4.��������껹��û���㹻�ռ����µĶ���ͻᷢ����OOM��
4.�ж϶���/���Ƿ���Ա�����
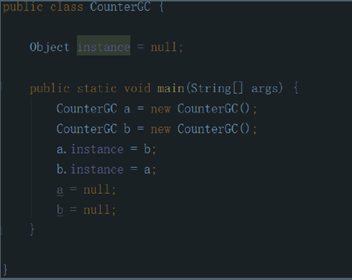
1.���ü�����
a.����������һ�����ü�����,ÿ����һ���ط�����,�������ͼ�1��������ʧЧ,�������ͼ�1���κ�ʱ�������Ϊ0�Ķ�����Dz������ٱ�ʹ�õġ�
b.�������ʵ�ּ�,Ч�ʸ�,����Ŀǰ�������������û��ѡ������㷨�������ڴ�,����Ҫ��ԭ���������ѽ������֮ǰ�ѭ�����õ����⡣
����֮��������
���˶���a��b������ŶԷ�֮��,����������֮�������κ����á�����������Ϊ�������öԷ�,�������ǵ����ü���������Ϊ0,�������ü���������֪ͨGC�������������ǡ�
2.�ɴ��Է����㷨
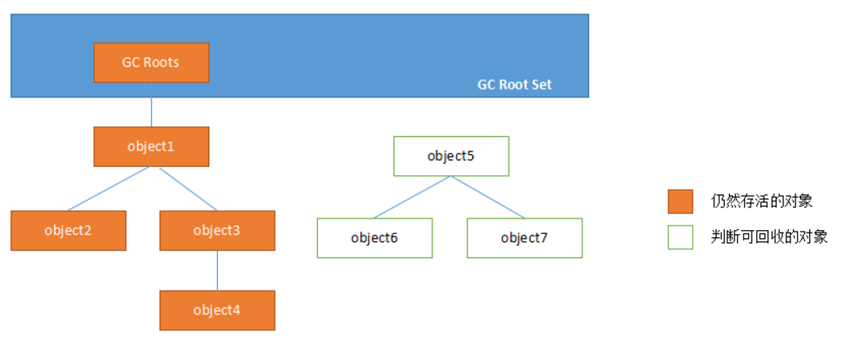
a.����㷨�Ļ���˼�����ͨ��һϵ�еij�Ϊ��GC Roots���Ķ�����Ϊ���,����Щ�ڵ㿪ʼ��������,�ڵ����߹���·����Ϊ������,��һ������GC Rootsû���κ������������Ļ�,��֤���˶����Dz����õġ�
b.GC Roots���ڵ�:���������Thread�������ջ�ı��ر�������static��Ա���������á����ط���ջ�ı����ȵ�
--------------------------------------�ж����Ƿ���Ա�����-----------------
��Ҫ����������������:
1.�������е�ʵ�����Ѿ�������,Ҳ���� Java ���в����ڸ�����κ�ʵ����
2.���ظ���� ClassLoader �Ѿ������ա�
3.�����Ӧ�� java.lang.Class ����û�����κεط�������,�����κεط�ͨ��������ʸ���ķ�����
��������Զ���������3����������������л���,��������ǡ����ԡ�,�������ǺͶ���һ���������˾ͱ�Ȼ�ᱻ���ա�
5.�����ռ��㷨
1.���-����㷨
������������ռ��㷨,����㷨��Ϊ������,����ǡ��͡�����������ȱ�dz�������Ҫ���յĶ���,�ڱ����ɺ�ͳһ�������б���ǵĶ���
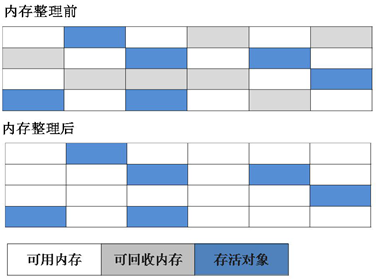
a.Ч������,��Ǻ�����������̵�Ч�ʶ�����
b.�ռ�����,��������������������������Ƭ
2.�����㷨
Ϊ�˽��Ч������,�����㷨�����ˡ��������ڴ��Ϊ��С��ͬ������,ÿ��ֻʹ�����е�һ�顣����һ����ڴ�ʹ�����,�ͽ������Ķ����Ƶ���һ����,Ȼ���ٰ�ʹ�õĿռ�һ����������������ʹÿ�ε��ڴ���ն��Ƕ��ڴ������һ����л��ա�
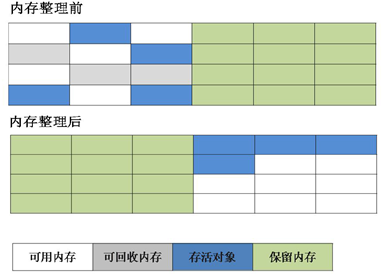
a.�ڴ�ʹ�ò�����-����㷨
b.�ʺ������
3.���-�����㷨
������������ص������һ�ֱ���㷨,��ǹ��̺͡����-������㷨һ��,���Ǻ������費��ֱ�ӶԿɻ��ն�����л���,���������д��Ķ�����һ���ƶ�,Ȼ��ֱ���������߽�������ڴ档
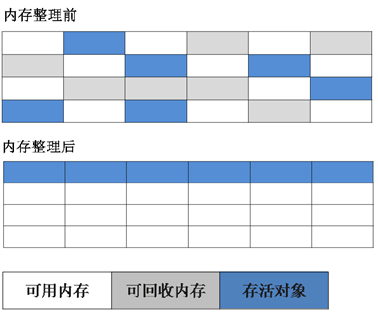
4.�ִ��ռ��㷨
���ڵ�����������������ռ�������������"�ִ��ռ�"�㷨,�����㷨���Ǹ��ݶ��������ڵIJ�ͬ���ڴ��Ϊ���顣һ�㽫java�ѷ�Ϊ�������������,�������ǾͿ��Ը��ݸ���������ص�ѡ����ʵ������ռ��㷨��
����������,ÿ���ռ����д���������ȥ,���Կ���ѡ�����㷨,ֻҪ������������ĸ��Ƴɱ��Ϳ������ÿ�������ռ�����������Ķ������ʱ�Ƚϸߵ�,����û�ж���Ŀռ�������з��䵣��,�ͱ���ѡ���-��������ߡ����-�������㷨���������ռ���
6.����������
���л����㷨����Ϊʵ�����������������,�����������������ڴ���յľ���ʵ�֡�
ĿǰHotSpot������õ�����������������ͼ��ʾ��ע��ֻ������������֮�������߲������ʹ��
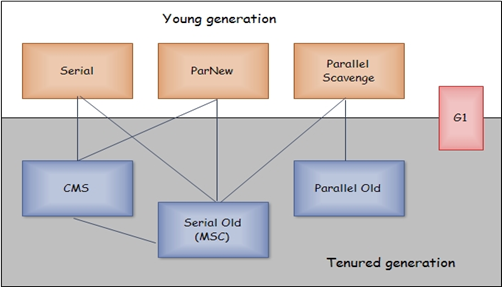
a.����(Parallel):ָ���������ռ��̲߳��й���,����ʱ�û��߳���Ȼ���ڵȴ�״̬��
b.����(Concurrent):ָ�û��߳��������ռ��߳�ͬʱִ��(����һ���Dz��е�,���ܻύ��ִ��),�û������������,�������ռ�������������һ��CPU�ϡ�
1.���������ռ��� �� Serial/Serial Old
�����ռ����ռ�����һ�����߳��ռ��������� �����̡߳� �����岻������ζ����ֻ��ʹ��һ�������ռ��߳�ȥ��������ռ�����,����Ҫ�������ڽ��������ռ�������ʱ�������ͣ�������еĹ����߳�( ��Stop The World�� ),ֱ�����ռ�������
���е������ռ���������,Serial��Serial Old,һ�����ߴ���ʹ�á�����������Serial,�����ø����㷨;�����ʹ��Serial Old���ñ��-�����㷨��
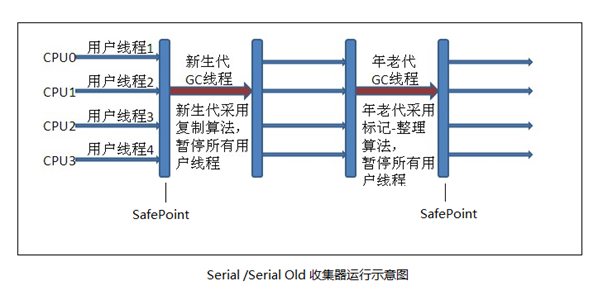
2.���������ռ��� �� ParNew
ParNew�ռ���(-XX:+useParNewGC)
ParNew�ռ�����ʵ����Serial�ռ����Ķ��̰߳汾,����ʹ�ö��߳̽��������ռ���,������Ϊ(���Ʋ������ռ��㷨�����ղ��Եȵ�)��Serial�ռ�����ȫһ����
���������ø����㷨,��������ñ��-�����㷨��
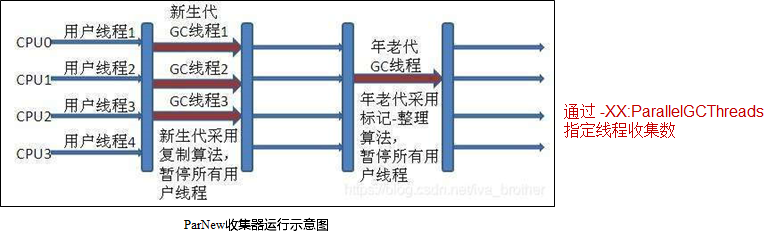
��������������Serverģʽ�µ����������Ҫѡ��,����Serial�ռ�����,ֻ��������CMS�ռ���(���������ϵIJ����ռ���,�������ܵ�)��Ϲ�����
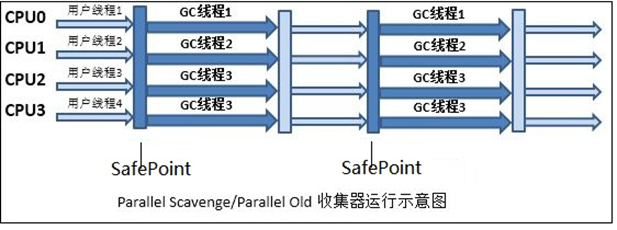
3.���������ռ��� �� Parallel Scavenge/ Parllel Old
a.Parallel Scavenge�ռ���(-XX:+UseParallelGC (�����) �CX:+UseParallelOldGC(�����))
��ע����������(��Ч�ʵ�����CPU)��CMS�������ռ����Ĺ�ע���������û��̵߳�ͣ��ʱ��(����û�����)��������=CPU�����������û������ʱ��/(�����û�����ʱ��+�����ռ�ʱ��)
b. Parllel Old:Parallel Scavenge��������汾��JDK 1.6��ʼ�ṩ�ġ�ͨ��-XX:+UseParallelOldGC����ʹ��Parallel Scavenge + Parallel Old����Ͻ����ڴ����
4.CMS�ռ���
CMS�ռ���(-XX:+useConcMarkSweepGC(�����))
CMS(Concurrent Mark Sweep)�ռ�����һ���Ի�ȡ��̻���ͣ��ʱ��ΪĿ����ռ��������dz�������ע���û������Ӧ����ʹ�á�����HotSpot�������һ�����������ϵIJ����ռ���,����һ��ʵ�����������ռ��߳����û��߳�(������)ͬʱ������
�������̷�Ϊ�ĸ�����:
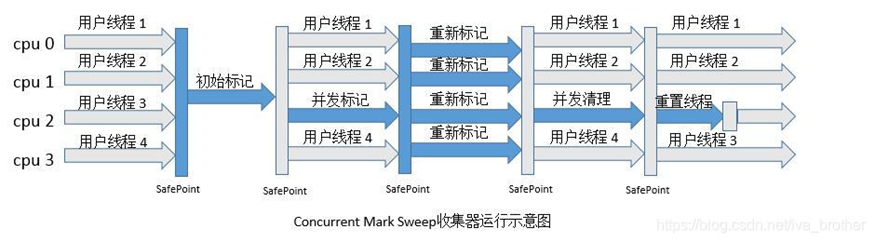
��Ҫ�ŵ�:�����ռ�,��ͣ�١������������漸�����Ե�ȱ��:
1.��CPU��Դ����(��ͷ�������Դ)
2.��������������(�ڲ����������ֲ�������,���ָ�������ֻ�ܵȵ���һ��GC������)
3.CMS�ǻ��ڡ���� -������㷨ʵ�ֵ��ռ���,ʹ�á����-������㷨�ռ���,�����������Ƭ����Ȼͨ������-XX:UseCMSCompactAtFullCollection������JVM��ִ������-���������������
4.ִ�й����еIJ�ȷ����,�������һ���������ջ�ûִ����,Ȼ�����������ֱ����������,�ر����ڲ�����ǺͲ�������γ���,һ����,ϵͳһ������,Ҳ��û��������ٴδ���full GC,Ҳ���ǡ�Concurrent Mode Failure��,��ʱ����롰Stop The World��,��Serial Old�����ռ��������ա�
��ز���:
1. -XX:+UseConcMarkSweepGC:����CMS
2. -XX:ConcGCThreads:������GC�߳���
3. -XX:+UseCMSCompactAtFullCollection:Full GC֮����ѹ������
4. -XX:CMSFullGCsBeforeCompaction:���ٴδ�Full GC֮��ѹ��һ��,Ĭ����0,����ÿ��Full GC֮��ѹ��һ��
5. -XX:CMSInitiatingOccupancyFraction:�������ʹ�ôﵽ�ñ���ʱ�ᴥ��Full GC(Ĭ����92,�ٷֱ�)
6. -XX:+UseCMSInitiatingOccupancyOnly:ֻʹ���趨�Ļ��շ�ֵ( -XX:CMSInitiatingOccupancyFraction �趨��ֵ),�����ָ��,JVM�ڵ�һ��ʹ���趨ֵ,�������Զ�������
7. -XX:+CMSScavengeBeforeRemark:��CMS GCǰ����һ��minor GC,Ŀ�����ڼ���������������������,����CMS GC�ı�ǽ�ʱ�Ŀ���,һ��CMS��GC��ʱ80%���ڱ�ǽΡ�
5.G1�ռ���
G1 (Garbage-First)��һ������������������ռ���,��Ҫ����䱸��Ŵ��������������ڴ�Ļ���. �Լ��߸�������GCͣ��ʱ��Ҫ���ͬʱ,���߱�����������������������ΪJDK1.7��HotSpot�������һ����Ҫ�������������߱������ص�:
1.**�����벢��:**G1�ܳ������CPU����˻����µ�Ӳ������,ʹ�ö��CPU(CPU����CPU����)������Stop-The-Worldͣ��ʱ�䡣���������ռ���ԭ����Ҫͣ��Java�߳�ִ�е�GC����,G1�ռ�����Ȼ����ͨ�������ķ�ʽ��java�������ִ�С�
2.**�ִ��ռ�:**��ȻG1���Բ���Ҫ�����ռ�����Ͼ��ܶ�����������GC��,���ǻ��DZ����˷ִ��ĸ��
3.**�ռ�����:**��CMS�ġ���ǨC�������㷨��ͬ,G1�����������ǻ��ڡ�����������㷨ʵ�ֵ��ռ���;�Ӿֲ��������ǻ��ڡ����ơ��㷨ʵ�ֵġ�
4.**��Ԥ���ͣ��:**����G1�����CMS����һ��������,����ͣ��ʱ����G1 �� CMS ��ͬ�Ĺ�ע��,��G1 �������ͣ����,���ܽ�����Ԥ���ͣ��ʱ��ģ��,����ʹ������ȷָ����һ������ΪM�����ʱ��Ƭ���ڡ�
G1�����ĸ���
G1�Ķ����ڷִ��Ļ�����,��������ĸ��G1���ѷֳ�������Region(��������)��(��Щ������Ҫ�����������ڴ�ռ�)Region�Ĵ�С����ͨ��G1HeapRegionSize������������,�������2����,��Χ����Ϊ1Mb��32Mb��
JVM�Ļ���ڶ��ڴ�ij�ʼֵ�����ֵ��ƽ������������ijߴ�,ƽ���Ķѳߴ��ֳ�Լ2000��Region��������Сһ������,������֮���ٱ仯��
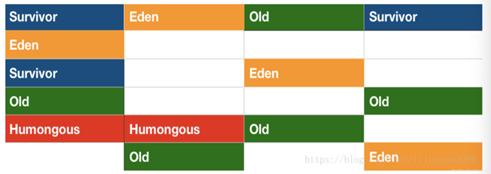
a.Humongous��:�����洢���Ͷ���(ռ����Region������50%���ϵ�һ������)��
���һ��H��װ����һ�����Ͷ���,���ͨ������������H�������洢����Ϊ���Ͷ����ת�ƻ�Ӱ��GCЧ��,���Բ�����ǽη��־��Ͷ����ٴ��ʱ,�Ὣ��ֱ�ӻ��ա�
b.����������Ч�����ڴ�ռ�,��Ϊ�ռ�������ʹ�á����-������,Region֮����ڡ����ơ��㷨,GC��Ὣ�������Ƶ����÷���(δ����ķ���),���Բ�������ռ���Ƭ��
G1�ռ������������·�Ϊ���¼�������:
��ʼ���
�������
���ձ��
ɸѡ����
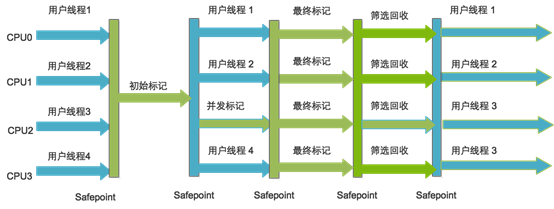
G1�ռ����ں�̨ά����һ�������б�,ÿ�θ����������ռ�ʱ��,����ѡ����ռ�ֵ����Region(��Ҳ������������Garbage-First������)������ʹ��Region�����ڴ�ռ��Լ������ȼ���������շ�ʽ,��֤��GF�ռ���������ʱ���ڿ��Ծ����ܸߵ��ռ�Ч��(���ڴ滯��Ϊ��)��
������������������������������������������������������������������
��ôѡ�������ռ���?
1.���ȵ����ѵĴ�С�÷������Լ���ѡ��
2.����ڴ�С��100m,ʹ�ô����ռ���
3.����ǵ���,����û��ͣ��ʱ���Ҫ��,���л�JVM�Լ�ѡ��
4.�������ͣ��ʱ�䳬��1��,ѡ���л���JVM�Լ�ѡ
5.�����Ӧʱ������Ҫ,���Ҳ��ܳ���1��,ʹ�ò����ռ���
6.�ٷ��Ƽ�G1,���ܸߡ�