分布式事务(一)
一、分布式事务简介
如果不是分布式环境的话一般不会接触到这种,一旦是微服务这种,分布式事务是必须要处理的一个问题。
1、分布式事务引言和介绍
a、什么是分布式事务

b、分布式事务架构
最早的分布式事务应用架构很简单,不涉及服务间的访问调用,仅仅是服务内操作涉及到对多个数据库资源的访问。
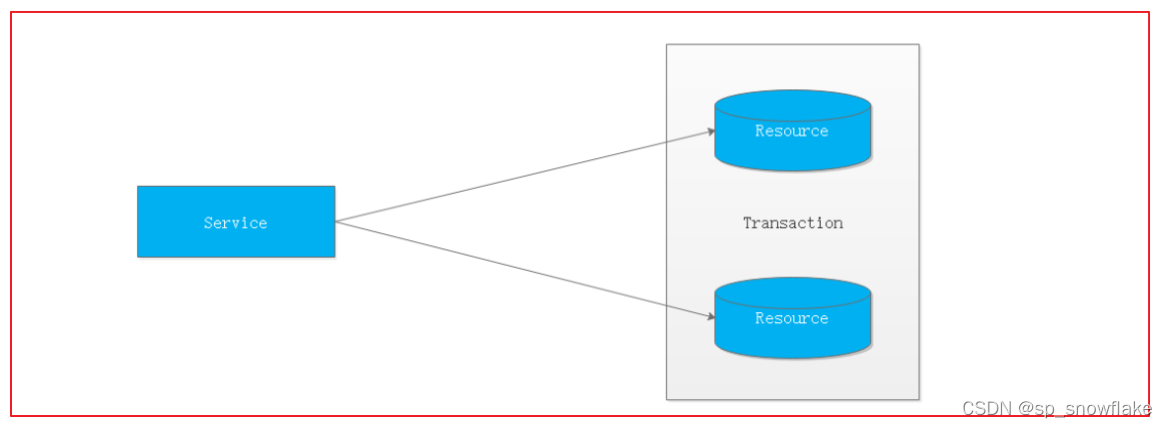
当一个服务操作访问不同的数据库资源,又希望对它们的访问具有事务特性时,就需要采用分布式事务来协调所有的事务参与者。
? 对于上面介绍的分布式事务应用架构,尽管一个服务操作会访问多个数据库资源,但是毕竟整个事务还是控制在单一服务的内部。如果一个服务操作需要调用另外一个服务,这时的事务就需要跨越多个服务了。在这种情况下,起始于某个服务的事务在调用另外一个服务的时候,需要以某种机制流转到另外一个服务,从而使被调用的服务访问的资源也自动加入到该事务当中来。下图反映了这样一个跨越多个服务的分布式事务:
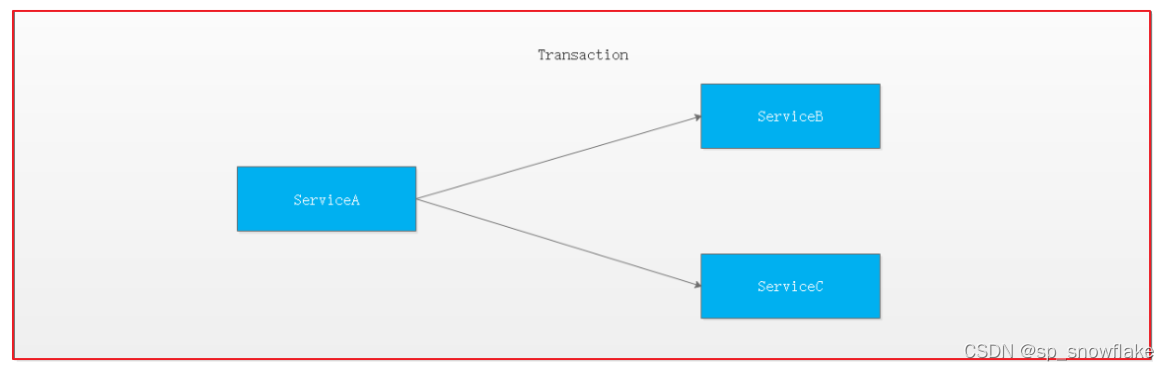
如果将上面这两种场景(一个服务可以调用多个数据库资源,也可以调用其他服务)结合在一起,对此进行延伸,整个分布式事务的参与者将会组成如下图所示的树形拓扑结构。在一个跨服务的分布式事务中,事务的发起者和提交均系同一个,它可以是整个调用的客户端,也可以是客户端最先调用的那个服务。

2、分布式相关理论
a、CAP 定理
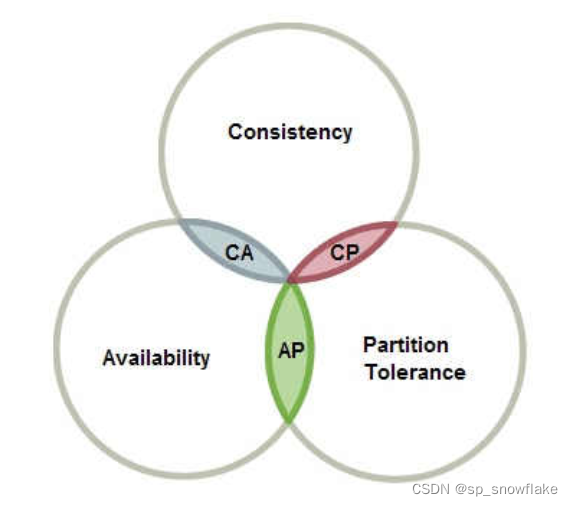

b、分区容错性
分布式系统集群中, 一个机器坏掉不应该影响其他机器

b、可用性
一个请求, 必须返回一个响应, 意思是只要收到用户的请求,服务器就必须给出回应
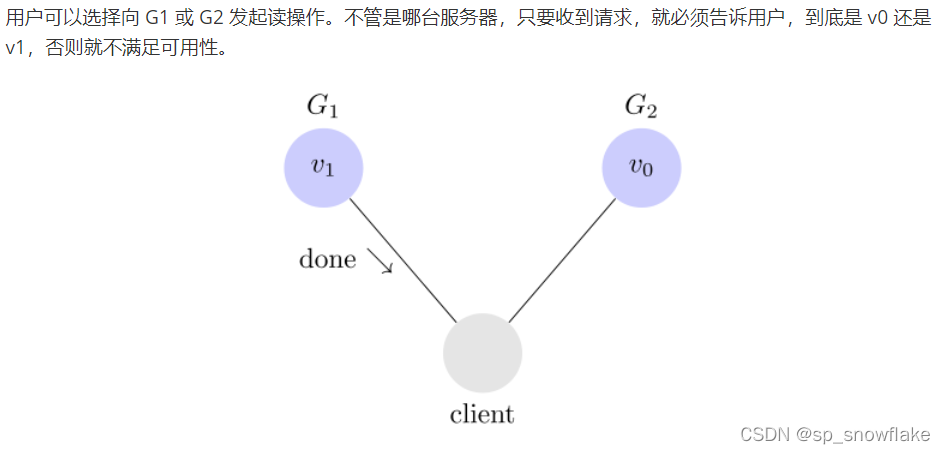
c、一致性
一定能读取到最新的数据, 意思是,写操作之后的读操作,必须返回该值。

d、 一致性和可用性的矛盾

3、BASE 理论

a、基本可用

b、软状态

c、最终一致性

4、分布式事务解决方案
1、通过消息中间件,将分布式事务转为本地事务(技术比较简单,业务比较复杂)
2、Seata:AT、TCC、XA、Saga
对上面的 1 举例子:

在 MQ 搞一个成功队列和失败队列,失败了就回滚。用户服务需要调用到物流服务和订单服务时,就向 MQ 发送一个消息,物流服务和订单服务则监听,有消息了就去消费,成功或者失败都去告诉 MQ。这么一来,用户服务即便要调用到另外两个服务,也不需要在同一个项目中,因为有消息中间件负责传输消息;意味着用户服务无需亲自去调用到数据库即可获取到数据。
a、基于XA协议的两阶段提交(2PC方案)

b、TCC补偿机制
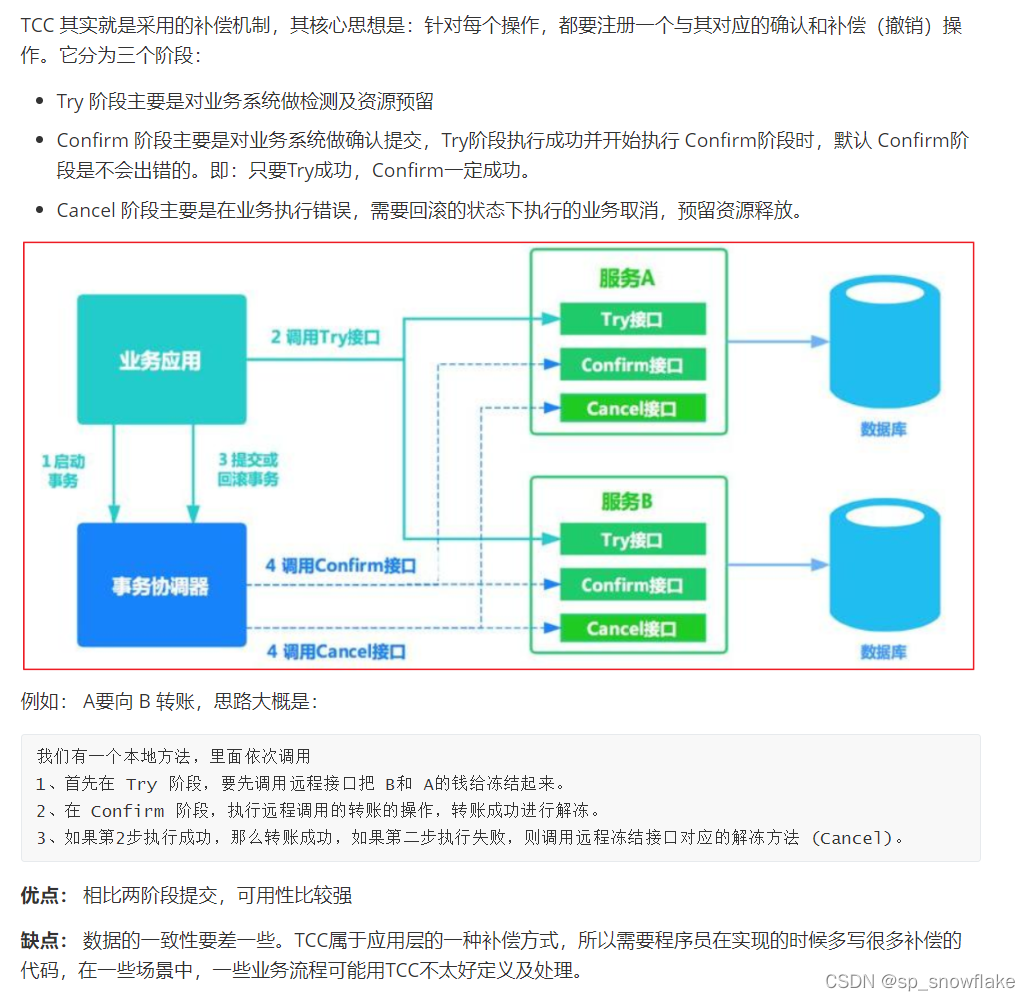
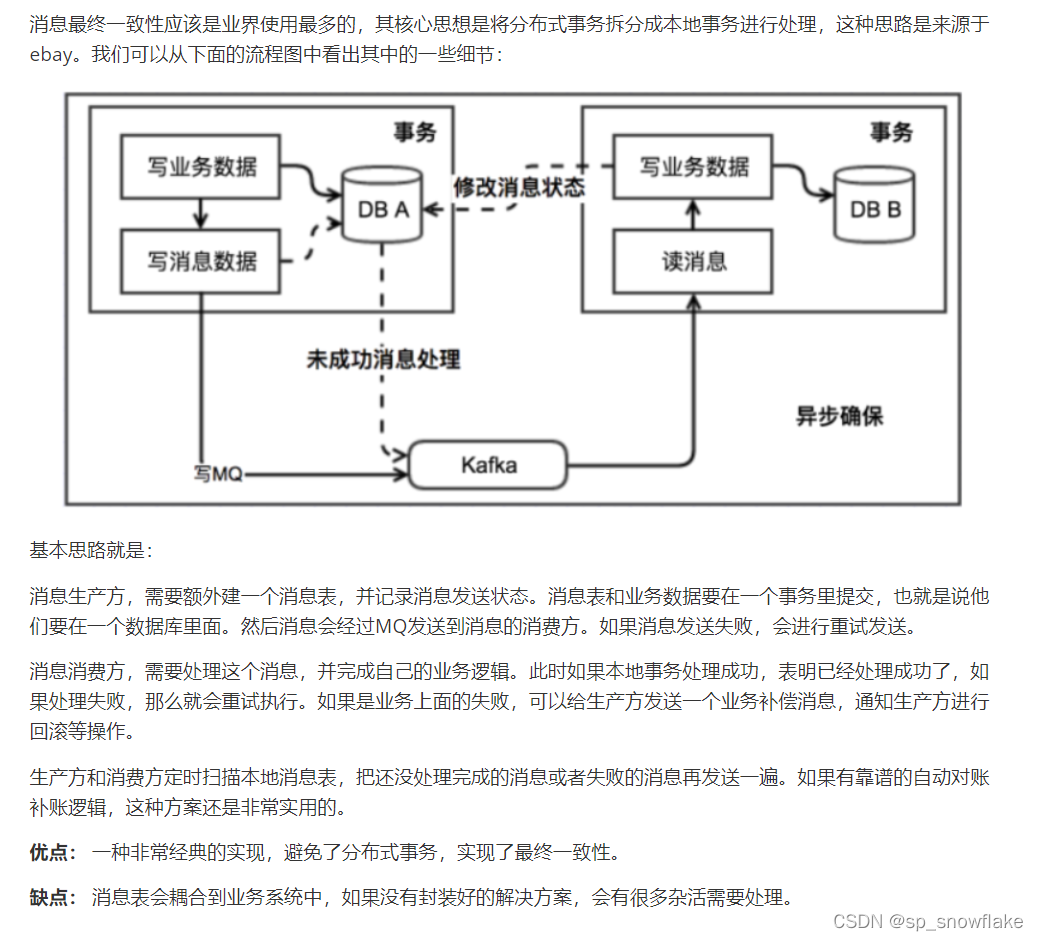
c、消息最终一致性(最多使用)
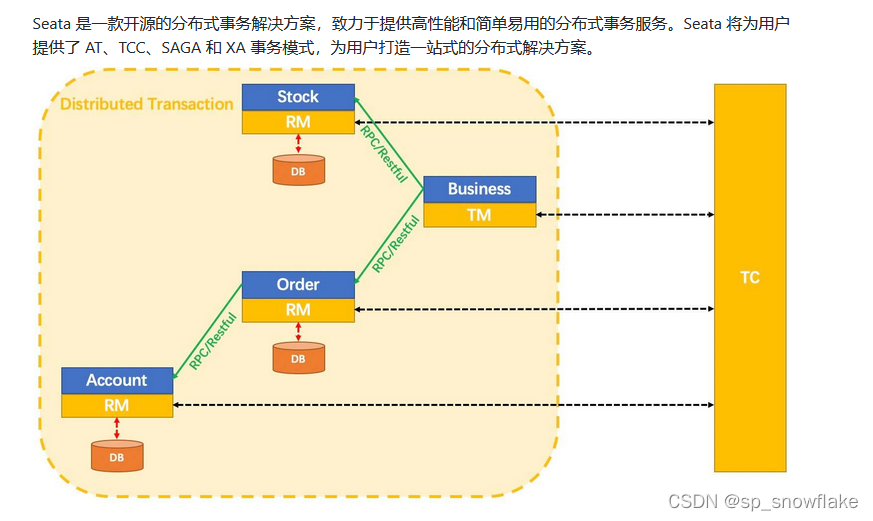
二、分布式事务框架 Seata
1、Seata 介绍


四种模式,
下载地址:https://github.com/seata/seata/releases

下载 Seata Server Docker 镜像和 NacOS Server Docker 镜像令如下 :
[root@localhost ~]# docker pull seataio/seata-server:1.4.0
[root@localhost ~]# docker pull nacos/nacos-server:1.2.0
Seata是什么?
2、Seata 理论概念

3、AT模式
AT 模式适用前提:
- 基于支持本地 ACID 事务的关系型数据库。
- Java 应用,通过 JDBC 访问数据库。
.两阶段提交协议的演变:
- 一阶段:业务数据和回滚日志记录在同一个本地事务中提交,释放本地锁和连接资源。
- 二阶段:
- 提交异步化,非常快速地完成。
- 回滚通过一阶段的回滚日志进行反向补偿。
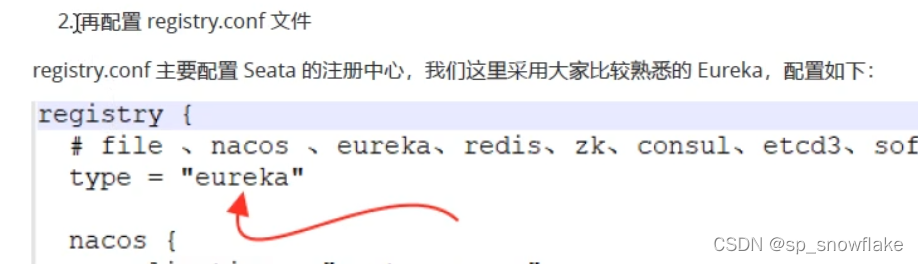
a、前期准备
首先需要修改配置文件:


b、了解案例和启动
这个例子就是用户下单的例子,这个例子讲得这些:


启动服务:


c、代码 / 业务理解
由于代码比较多和篇幅关系,这里只作关键部分的代码便于理解,
这块代码主要是体现模拟全局事务提交:
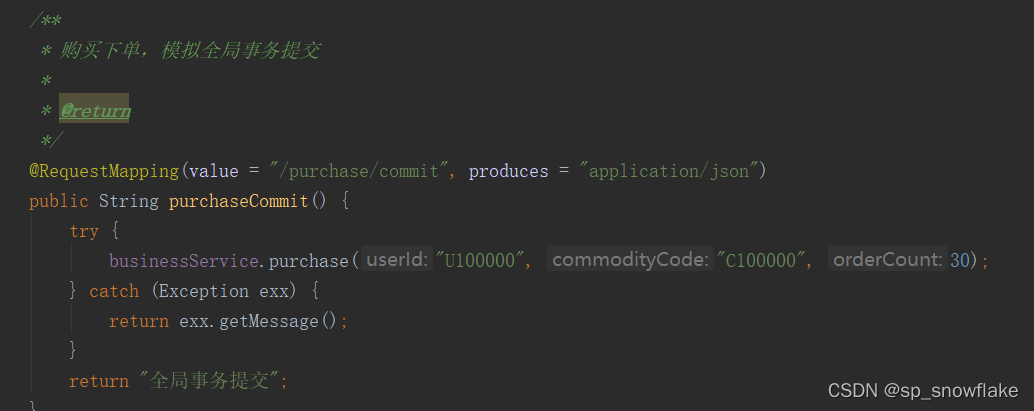
这块代码主要是体现模拟全局事务回滚:

全局事务 / 分布式事务 开始:
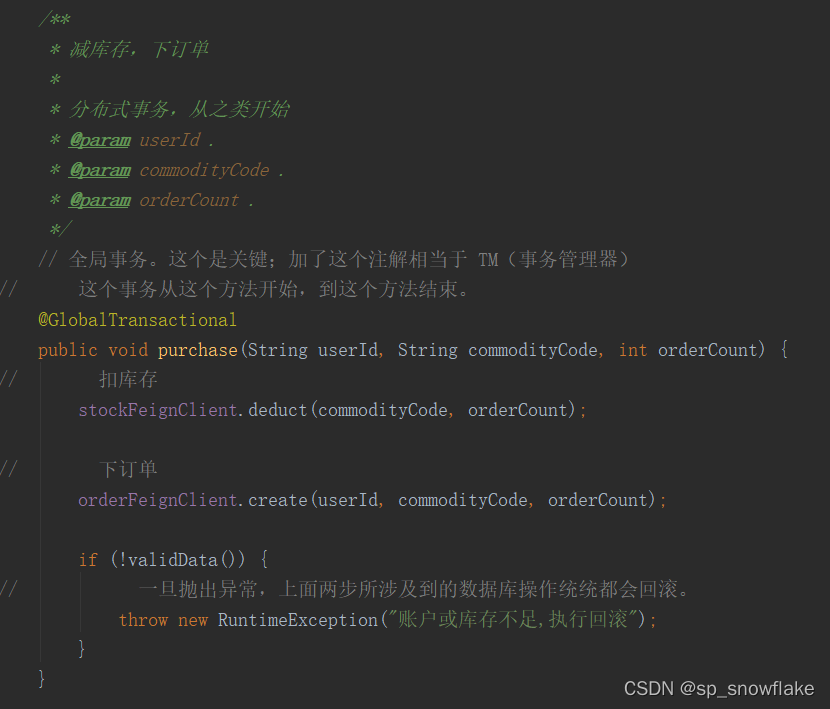
不记得 TM 的看前面的架构图。
初始化:
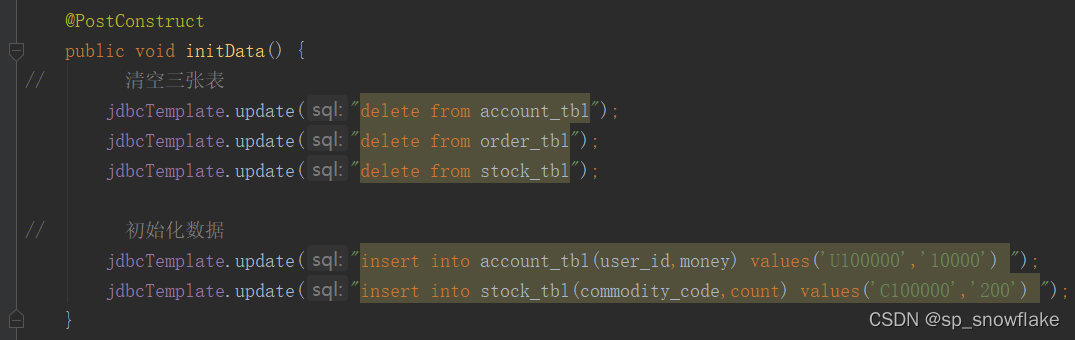
判断余额和检查库存:
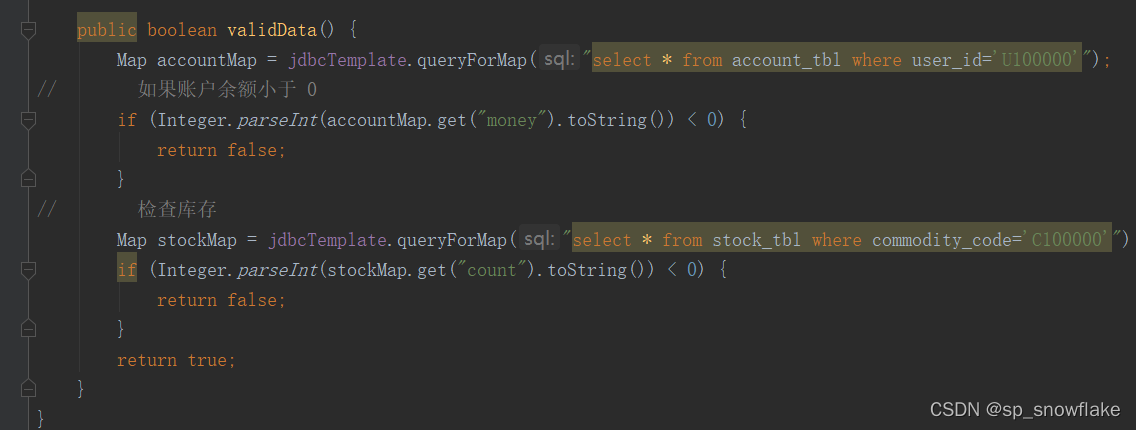
扣除库存的接口:

但是上图跟上面其他代码不属于同一个项目,意思是调用这个接口,使用了其他项目里面的代码。那么这里是怎么做到的呢?这里使用到了 SpringCloud 里面的工具,这个后面博客再说。这里来看下:
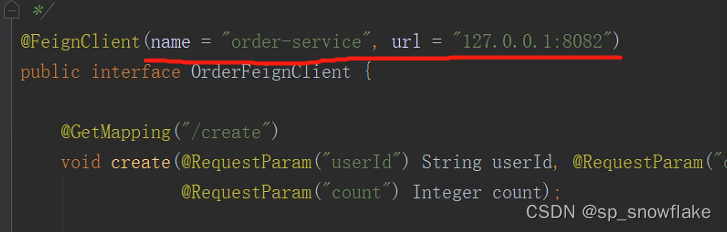
这是一个接口。可以看到这个工具有指定接口和 url,很明显猜得到是通过这个工具,A 项目才能使用到 B项目里面的代码,再来看看:
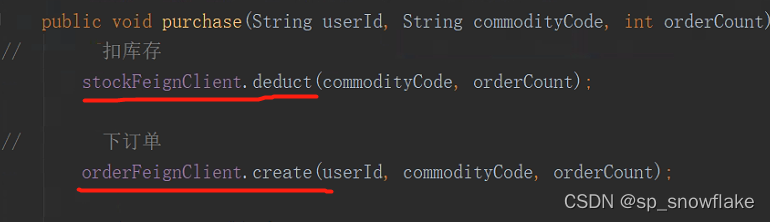
这两个调用就是调用到了其他项目的代码了。关于这块地方就不详细讲了,只需要大概了解到是通过这些方式调用了其他项目的功能即可。详细的后面的博客介绍到 SpringCloud 的时候会说到。
到此为止就基本介绍完了,其实还是互相调用。
d、反向补偿
在执行插入或者更新操作以前,会先把这条记录记下来,看看数据库:

这里会把修改前和修改后的记录都记下来,如果成功提交了,会把刚才记录下来的日志给删除了。如果要回滚,会自动根据之前的状态,生成语句,再把数据改回去。所以这里所说的回滚其实是又执行了一条语句,把数据再改回去。而不是以前讲的那种回滚,把数据复原。这种回滚就叫反向补偿。
这里来尝试查看这里的日志是什么:
先看这两个 id:这里 xid 代表的是全局事务 ID,前面的 branch_id 代表的是分支事务 ID,代表各自事务的 ID。那么这里的 xid 是同一个,说明这三个分支事务是同属于同一个全局事务的。

再看下 rollback_info,其实里面都是 json 数据,来解析看看里面的数据:
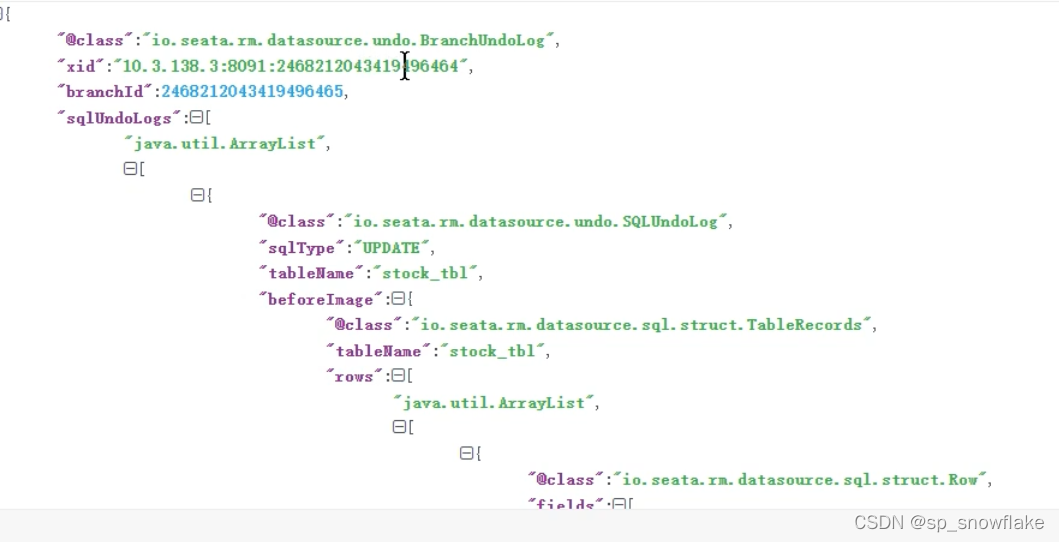
主要看这两处:
before_image :修改前的镜像

after_image :修改后的镜像:
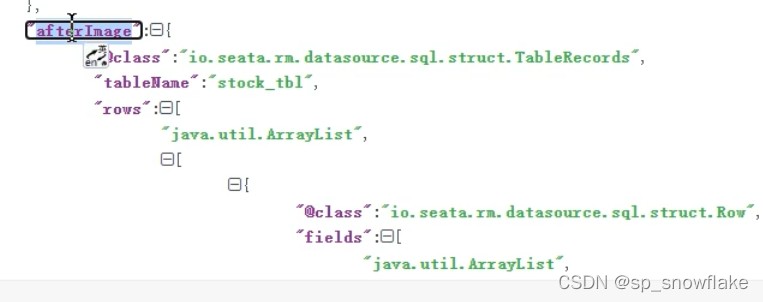
这里面的数据记录了改之前和改之后的数据,就是根据这些数据生成的语句,来完成回滚。
e、小结
AT 模式最显著的特征就是会把数据库修改之前的状态记录下来,回滚会自动回滚。
4、Tcc 模式
Tcc 模式跟上面不同,主要是把转账分成了两个阶段,且数据库多了个冻结金额的字段。把扣钱作为一阶段操作,加钱作为二阶段操作。
后续补上