һ��ǰ��:����,�������˽�һ��ΪʲôҪʹ����·��
????????����ܹ���һ���ֲ�ʽ�ܹ�,����ҵ�ַ���Ԫ,һ���ֲ�ʽϵͳ�����кܶ������Ԫ�����ڷ���Ԫ�����ڶ�,ҵ��ĸ��ӳ̶Ȳ�ͬ,��������˴�����쳣 , ����ȥ��λ����Ҫ������, һ�����������Ҫ���úܶ������,���ڲ�����ĵ��ø�����,�������������Զ�λ��
????????�����ڷ���ܹ���,����ʵ�ֲַ�ʽ��·��,ȥ����һ����������Щ�������,�����˳������������,�Ӷ��ﵽÿ������IJ��������ɼ�,��������,�ܿ춨λ����·������� Google �� Dapper,Twitter �� Zipkin,�Լ������ Eagleeye (ӥ��)��,���Ƕ��Ƿdz��������·�ٿ�Դ�����

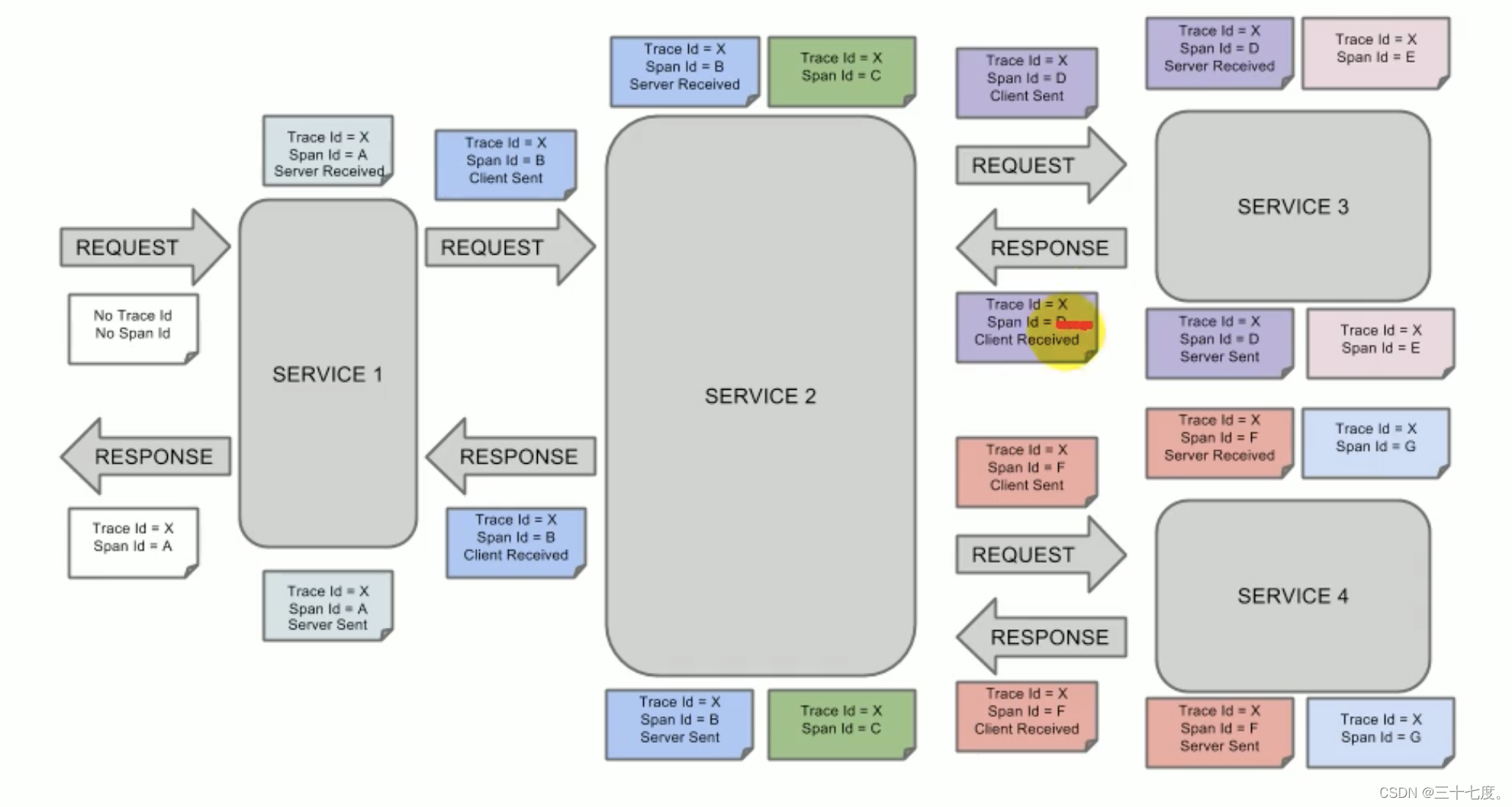
������������
Span(���):����������Ԫ,����һ��Զ�̵������� �ͻ����һ�� Span,Span ��һ�� 64 λ ID Ψһ��ʶ��,Trace ������һ�� 64 λ ID Ψһ��ʶ��,Span ��������������Ϣ,����ժҪ��ʱ����¼���Span �� ID���Լ����� ID��
Trace(����):һϵ�� Span ��ɵ�һ����״�ṹ������һ������ϵͳ�� API �ӿ�,��� API �ӿ�,��Ҫ���ö������,����ÿ���������һ���µ� Span,������������������ Span �������� Trace��
Annotation(��ע):������ʱ��¼һ���¼���,һЩ����ע����������һ������Ŀ�ʼ�ͽ��� ����Щע���������:
- cs - Client Sent -�ͻ��˷���һ������,���ע����������� Span �Ŀ�ʼ
- sr - Server Received -����˻����������ʼ������,�� sr ��ȥ cs ʱ�����ɵõ����紫���ʱ�䡣
- ss - Server Sent (����˷�����Ӧ)�C��ע����������������(�����ؿͻ���),��� ss ��ʱ�����ȥ sr ʱ���,�Ϳ��Եõ������������ʱ�䡣
- cr - Client Received (�ͻ��˽�����Ӧ)-��ʱ Span �Ľ���,��� cr ��ʱ�����ȥ cs ʱ�������Եõ��������������ĵ�ʱ��
������Ŀ����Zipkin
1��docker ��װ zipkin
docker run -d -p 9411:9411 openzipkin/zipkin2����pom����������
<!--zipkin ����Ҳͬʱ������ sleuth,����ʡ�� sleuth ������-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>3����application.yml������������
spring:
zipkin:
base-url: http://192.168.2.190:9411/ # zipkin �������ĵ�ַ
discovery-client-enabled: false # �رշ�����,���� Spring Cloud ��� zipkin �� url ������������
sender:
type: web # ����ʹ�� http �ķ�ʽ��������
sleuth:
sampler:
probability: 1 # ���ó����ɼ���Ϊ 100% ,Ĭ��Ϊ 0.1 ,�� 10%�ġ����ز���
������Ŀ,���й��ܶ���һ��,Ȼ����� zipkin ��������ַ,��ʾ����: