����������
һ GC�ķ���������ָ��
-
���߳�����
- �������������� ��CPU,���ýϵ�,ֻ��һ��GC�߳�
- �������������� ������ǿ��CPU ����GC
-
���չ���ģʽ
-
����ʽ����������
��Ӧ�ó����߳̽��湤��,�Ծ����ܼ���Ӧ�ó����ͣ��ʱ�䡣
-
��ռʽ����������
һ������,��ֹͣӦ�ó����е������û��߳�,ֱ���������չ�����ȫ������
-

-
-
����Ƭ������ʽ
-
ѹ��ʽ����������
? ������ɺ�,�Դ��������ѹ������,�������պ����Ƭ��
-
��ѹ��ʽ����������
? �ǻ�����Ƭ,�ٴ�������ʹ�ÿ����б���
-
-
���������ڴ������
- ���������������
- ���������������
����ָ��
-
������:�����û������ʱ��ռ������ʱ��ı���
-
����������CPU���������û������ʱ����CPU������ʱ��ı�ֵ,��������=�����û�����ʱ��/ (�����û�����ʱ��+�����ռ�ʱ��)
- ?����:������ܹ�������100����,���������ռ�����1����,������������99%
-
���������,Ӧ�ó��������̽ϸߵ���ͣʱ��,���,����������Ӧ�ó����и�����ʱ���,������Ӧ�Dz��ؿ��ǵġ�
-
����������,��ζ���ڵ�λʱ����,STW��ʱ�����: 0.2 + 0.2 = 0.4

-
-
�����ռ�����:�������IJ���,�����ռ�����ʱ����������ʱ��ı�����
-
��ͣʱ��:ִ�������ռ�ʱ,����Ĺ����̱߳���ͣ��ʱ��
-
����ͣʱ�䡱��ָһ��ʱ�����Ӧ�ó����߳���ͣ,��GC�߳�ִ�е�״̬
- ?����,GC�ڼ�100�������ͣʱ����ζ������100�����ڼ���û��Ӧ�ó����߳��ǻ�ġ�.
-
��ͣʱ������,��ζ�ž������õ���STW��ʱ�����: 0.1 + 0.1 + 0.1 + 0.1+0.1=0.5

-
-
�ռ�Ƶ��:�����Ӧ�ó����ִ��,�ռ�����������Ƶ�ʡ�
-
�ڴ�ռ��: Java������ռ���ڴ��С
-
����:һ������ӵ�������������������ʱ�䡣
-
�������ֹ�ͬ����һ�������������ǡ�����������ı��ֻ����ż���������Խ��Խ�á�һ��������ռ���ͨ�����ͬʱ�������е����
-
��������,��ͣʱ�����Ҫ�������ԡ���Ϊ����Ӳ����չ,�ڴ�ռ�� ��ЩԽ��Խ������,Ӳ�����ܵ�����Ҳ�����ڽ����ռ�������ʱ��Ӧ�ó����Ӱ��,������������������ڴ������,���ӳٷ�����������Ч����
�� ��ͬ����������������
1. ������������չʷ
-
1999����JDK1.3.1һ �������Ǵ��з�ʽ��Serial GC,���ǵ�һ��GC��ParNew�����ռ�����Serial�ռ����Ķ��̰߳汾
-
2002��2��26��,Parallel GC��Concurrent Mark Sweep GC����JDK1.4.2һ��
-
Parallel GC��JDK6֮���ΪHotSpotĬ��GC��
-
2012��,��JDK1.7u4�汾��,G1���á�
-
2017��,JDK9��G1���Ĭ�ϵ������ռ���,�����CMS��
-
2018��3��,JDK10��G1�����������IJ���������������,ʵ�ֲ����������������µ��ӳ١�
----------------- ��ˮ�� ---------------------
-
2018��9��,JDK11����������Epsilon����������,�ֱ���Ϊ"Noһ0p (����) "��������ͬʱ,����ZGC:�������ĵ��ӳ�����������(Experimental)��
-
2019��3��,JDK12������ ��ǿG1,�Զ�����δ�ö��ڴ������ϵͳ��ͬʱ,����Shenandoah GC:��ͣ��ʱ���GC (Experimental)��
-
2019��9��,JDK13��������ǿZGC,�Զ�����δ�ö��ڴ������ϵͳ��
-
2020��3��,JDK14������ɾ��CMS��������������չZGC��macOS��Windows.�ϵ�Ӧ��
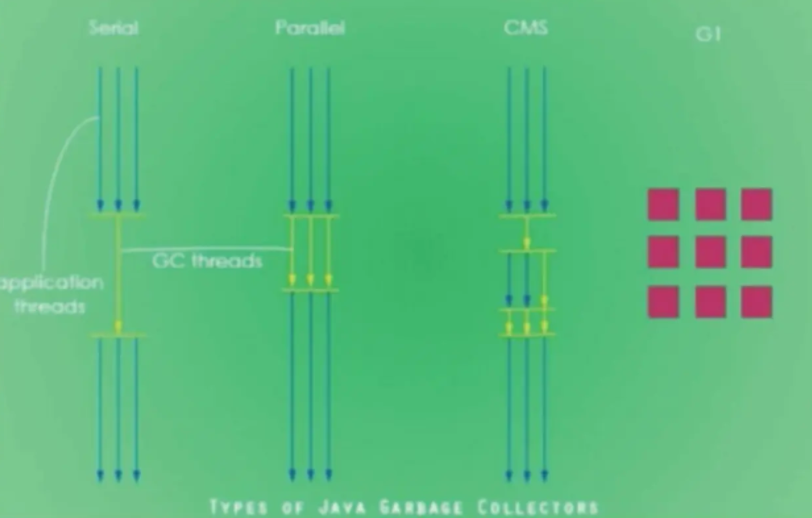
2. �߿�������������
- �������:Serial. Serial Old
- �������:ParNew. Parallel Scavenge. Parallel Old
- ����������:CMS. G1
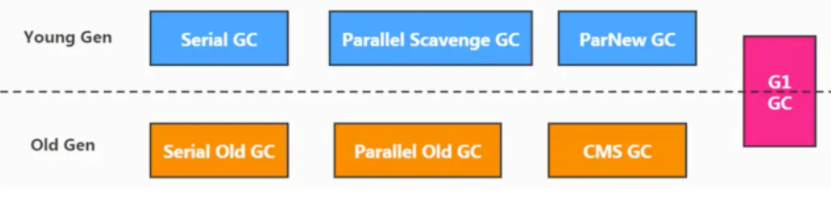
3. �߿��������ռ����������ִ�֮��Ĺ�ϵ
- �������ռ���: Serial�� ParNeW��Parallel Scavenge
- ������ռ���: Serial 0ld�� Parallel 0ld�� CMS
- �����ռ���: G1
4. �����ռ�������Ϲ�ϵ
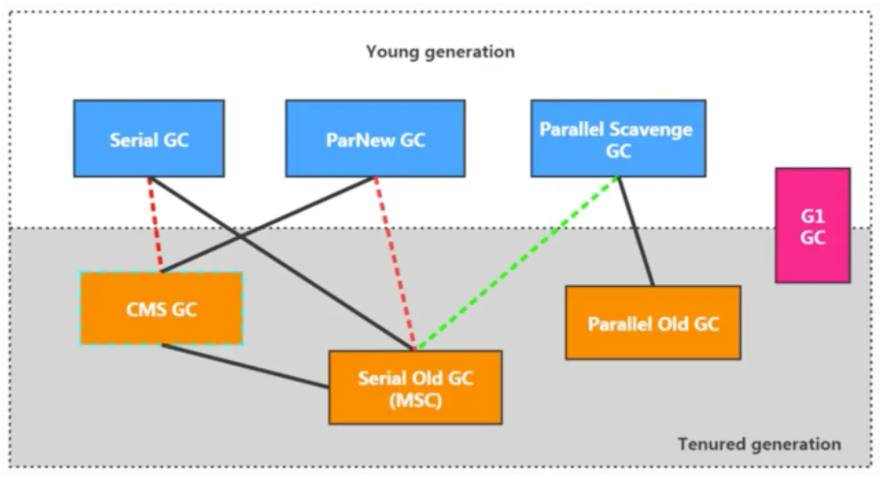
ע��:
- JDK1.3��1.5Ĭ��ʹ��SerialGC + SerialOldGC
- JDK1.6��1.8Ĭ����ParallerlGC + parallerlOldGC
- JDK9���Ժ�Ĭ��ʹ��G1
- CMS��9֮�����,14֮���Ƴ�
˵��:
- �����ռ�����������,�������ǿ��Դ���ʹ��
- ����Serial 0ld��ΪCMS ����"Concurrent Mode Failure"ʧ�ܵĺ� ��Ԥ����
- (��ɫ����)����ά���ͼ����Բ��Եijɱ�,JDK8��ʱ,JDK 9���Ƴ���
- (��ɫ����)JDK 14��:��ʱ δ�����Ƴ�
- (��ɫ����)JDK 14��:ɾ��CMS����������
- ΪʲôҪ�кܶ��ռ�����������? ��ΪJava��ʹ�ó����ܶ�, �ƶ���,�������ȡ����Ծ���Ҫ��Բ�ͬ�ij���,�ṩ��ͬ�������ռ���,��������ռ������ܡ�
- ��Ȼ���ǻ�Ը����ռ������бȽ�,������Ϊ����ѡһ����õ��ռ���������û��һ�ַ�֮�ĺ������κγ����¶����õ������ռ�������,����û�����ܵ��ռ�������������ѡ���ֻ�ǶԾ���Ӧ������ʵ��ռ���
-
�鿴Ĭ�ϵ������ռ���
- -XX:+PrintCommandLineFlags: �鿴��������ز���(����ʹ�õ������ռ���)
- JDK1.8���: +UseParallelGC +UseParallelOldGC
- JDK11���:+UseG1GC
- ʹ��������ָ��: jinfo -flag���������������������ID
- -XX:+PrintCommandLineFlags: �鿴��������ز���(����ʹ�õ������ռ���)
�� Serial������(�����)
SerialGC
- Serial�ռ��������������ʷ���ƾõ������ռ����ˡ�JDK1.3֮ǰ����������Ψһ��ѡ��
- Serial�ռ�����ΪHotSpot��Clientģʽ�µ�Ĭ�������������ռ�����
- Serial�ռ������ø����㷨�����л��պ�"Stopһ theһWorld"���Ƶķ�ʽִ���ڴ���ա�
SerialOldGC
- ���������֮��,Serial�ռ������ṩ����ִ������������ռ���Serial 0ld�ռ����� Serial Old�ռ���ͬ��Ҳ�����˴��л��� ��"Stop the World"����,ֻ�����ڴ�����㷨ʹ�õ������ѹ���㷨��
- ?Serial 0ld��������Clientģʽ��Ĭ�ϵ��������������������
- ?Serial 0ld�ڷ����(Linux)����Ҫ��������;:
- ������������ParallelScavenge���ʹ��;
- ����Ϊ�����CMS�ռ����ĺ������ռ�����
�ص�
-
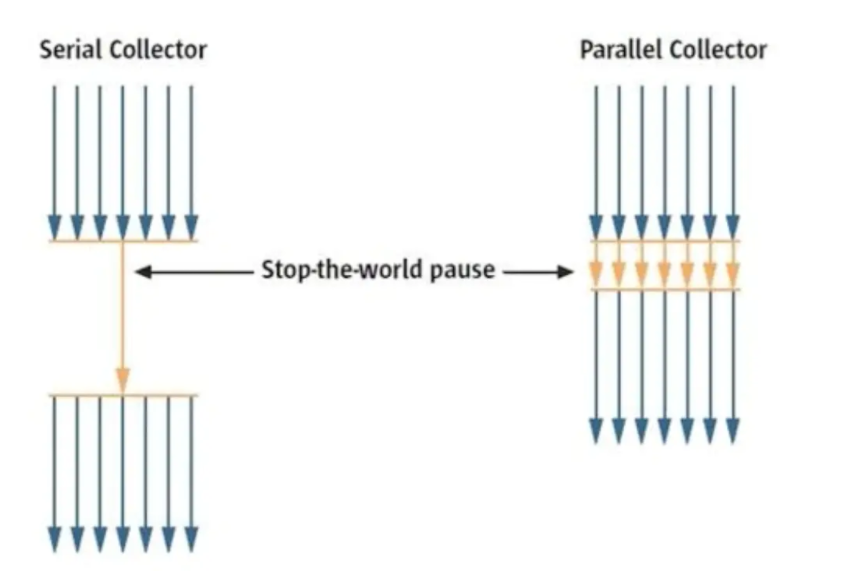
����ռ�����һ�����̵߳��ռ���,�����ġ����̡߳������岢��������ʹ��һ��CPU��һ���ռ��߳�ȥ��������ռ�����,����Ҫ�����������������ռ�ʱ,������ͣ�������еĹ����߳�,ֱ�����ռ�����(Stop The World )��
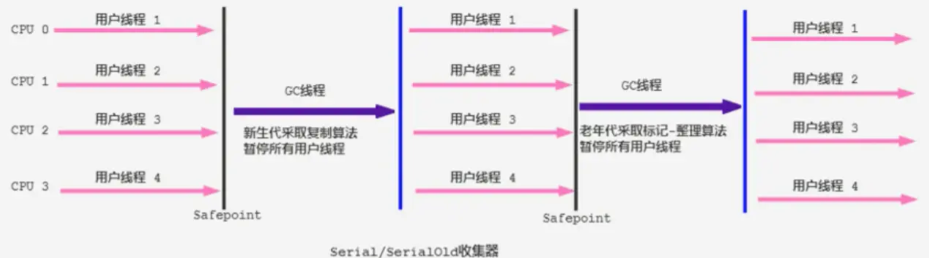
����
-
����Ч(�������ռ����ĵ��̱߳�),����������CPU�Ļ�����˵,Seria1�ռ�������û���߳̽����Ŀ���,ר���������ռ���Ȼ���Ի����ߵĵ��߳��ռ�Ч�ʡ�
-
���û�������Ӧ�ó�����,�����ڴ�һ�㲻��(��ʮMB��һ����MB), �����ڽ϶�ʱ������������ռ�(��ʮms��һ�ٶ�ms) ,ֻҪ��Ƶ������,ʹ�ô��л������ǿ��Խ��ܵġ�
-
��HotSpot̓�����,ʹ��
-XX:+UseSerialGC��ʾ�����ʹ��SerialGC�������ʹ��SerialOldGC�ռ�����
�ܽ�
- ���������ռ�������˽�,�����Ѿ����ô��е��ˡ�������������cpu�ſ����á����ڶ����ǵ��˵��ˡ�
- ���ڽ�����ǿ��Ӧ�ö���,���������ռ����Dz��ܽ��ܵġ�һ����JavawebӦ�ó������Dz�����ô��������ռ����ġ�
�� ParNew������(�����)
ParNew����һ��Serial�Ķ��̰߳汾
-
ParNew�ռ������˲��ò��л��յķ�ʽִ���ڴ������,���������ռ���֮�伸��û���κ�����ParNew�ռ������������ͬ��Ҳ�Dz��������㷨�������ͬ���������ѹ���㷨��"Stopһ theһWorld"���ơ�
-
ParNew�Ǻܶ�JVM������Serverģʽ����������Ĭ�������ռ�����
-

-
����������,���մ���Ƶ��,ʹ�ò��з�ʽ��Ч��
���������,���մ�����,ʹ�ô��з�ʽ��ʡ��Դ��(CPU���� ��Ҫ�л��߳�,���п���ʡȥ�л��̵߳���Դ)
����ParNew�ռ����ǻ��ڲ��л���,��ô�Ƿ���Զ϶�ParNew�ռ����Ļ���Ч�����κγ����¶����Serial�ռ�������Ч?
- ?ParNew �ռ��������ڶ�CPU�Ļ�����,���ڿ��Գ�����ö�CPU�� ����ĵ�����Ӳ����Դ����,���Ը����ٵ���������ռ�,�����������������
- ?�����ڵ���CPU�Ļ�����,ParNew�� ��������Serial�ռ������� Ч����ȻSerial�ռ����ǻ��ڴ��л���,��������CPU����ҪƵ�����������л�,��˿�����Ч������߳̽��������в�����һЩ�������
��Ϊ��Serial��,Ŀǰֻ��ParNew GC����CMS�ռ�����Ϲ���
-
�ڳ�����,������Ա����ͨ��ѡ��
-XX: +UseParNewGC�ֶ�ָ��ʹ��.ParNew�ռ���ִ���ڴ������������ʾ�����ʹ�ò����ռ���,��Ӱ��������� -
``-XX:ParallelGCThreads`�����߳�����,Ĭ�Ͽ�����CPU������ͬ���߳�����
�� Parallel������(����������)
Parallel Scavenge�ռ�����Ŀ�����ﵽһ���ɿ��Ƶ�������(Throughput),��Ҳ����Ϊ���������ȵ������ռ�����
-
?����Ӧ���ڲ���Ҳ��Parallel Scavenge ��ParNewһ����Ҫ����
-
������������Ը�Ч�ʵ�����CPU ʱ��,������ɳ������������,�� Ҫ�ʺ��ں�̨���������Ҫ̫�ཻ�����������,�����ڷ�����������ʹ�á�����,��Щִ��������������������������֧������ѧ�����Ӧ�ó���
-
Parallel�ռ�����JDK1.6ʱ�ṩ������ִ������������ռ��� Parallel 0ld�ռ���,���������������Serial 0ld�ռ�����
-
Parallel 0ld�ռ������������һѹ���㷨,��ͬ��Ҳ�ǻ��ڲ��л��պ͡�StopһtheһWorld"���ơ�
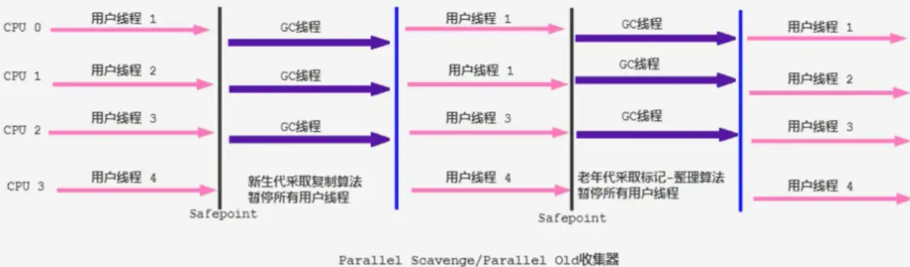
- �ڳ������������ȵ�Ӧ�ó�����,Parallel �ռ�����Parallel 0ld�ռ��������,��Serverģʽ�µ��ڴ�������ܺܲ�����
- ��Java8��,Ĭ���Ǵ������ռ���
��������
-
-XX:MAxGCPauseMillis �������������������ͣ��ʱ��(STWʱ��)��λms
- Ϊ�˾����ܵĽ�STW������xms��,�ռ��������Ӧ�ѵĴ�С��һЩ�������� ����STWС,���ҲС
- �����û�����ͣ�ٵ�ʱ��Խ��Խ��,�����ڷ����,ע�ظ߲���,����������������Է���˸����ʺ�Parallel ���п���
-
-XX:GCTimeRatio ��������ʱ��ռ��ʱ��ı���
- Ĭ��Ϊ99 ����������ʱ�䲻����1%
-
-XX:+UseAdaptiveSizePolicy �Ƿ�����������Ӧ����
- ������ģʽ��,������Ĵ�С��Eden��Survivor�ı������������� ���Ķ�������Ȳ����ᱻ�Զ�����,�Ѵﵽ�ڶѴ�С����������ͣ��ʱ��֮���ƽ��㡣
- ���ֶ����űȽ����ѵij���,����ֱ��ʹ����������Ӧ�ķ�ʽ,��ָ ������������ѡ�Ŀ���������(GCTimeRatio)��ͣ��ʱ��(MaxGCPauseMills),��������Լ���ɵ��Ź�����
�� CMS������(���ӳ�)(9����,14�Ƴ�)
-
��JDK1.5ʱ��, HotSpot�Ƴ���һ����ǿ����Ӧ���м�������Ϊ�л� ʱ������������ռ���: CMS - (Concurrent -Mark -Sweep)�ռ���,
����ռ�����HotSpot������е�һ�����������ϵIJ����ռ���,����һ��ʵ�����������ռ��߳����û��߳�ͬʱ������ -
CMS�ռ����Ĺ�ע����
���������������ռ�ʱ�û��̵߳�ͣ��ʱ����ͣ��ʱ ��Խ��(���ӳ�)��Խ�ʺ����û������ij���,���õ���Ӧ�ٶ��������û����顣- ?Ŀǰ�ܴ�һ���ֵ�JavaӦ�ü����ڻ�����վ����B/Sϵͳ�ķ������,����Ӧ���������ӷ������Ӧ�ٶ�,ϣ��ϵͳͣ��ʱ�����,�Ը��û������Ϻõ����顣CMS�ռ����ͷdz���������Ӧ�õ�����
-
���ҵ���,CMS ��Ϊ��������ռ���,ȴ����JDK 1.4.0 ���Ѿ����ڵ��������ռ���Parallel Scavenge��Ϲ���,������JDK 1. 5��ʹ��CMS���ռ��������ʱ��,������ֻ��ѡ��ParNew����Serial�ռ����е�һ����
-
��G1����֮ǰ,CMSʹ�û��Ƿdz��㷺�ġ�һֱ������,��Ȼ�кܶ�ϵͳʹ��CMS GC��
-
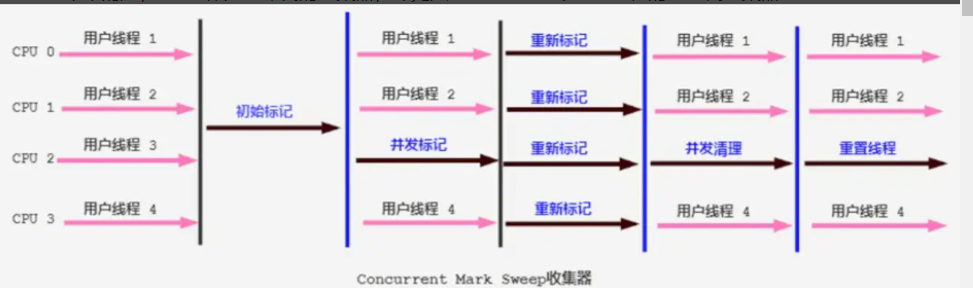
CMS�������̱�֮ǰ���ռ���Ҫ����,�������̷�Ϊ4����Ҫ��
-
��ʼ���(InitialһMark) ��:���������,���������еĹ����̶߳�������Ϊ. ��StopһtheһWorld"���ƶ����ֶ��ݵ���ͣ,����ε���Ҫ�������ֻ����dz�GCRoots��ֱ�ӹ������Ķ�����
һ��������֮��ͻ�ָ�֮ǰ����ͣ������Ӧ��.�̡߳�����ֱ�ӹ�������Ƚ�С,����������ٶȷdz��졣 -
�������(ConcurrentһMark)��:
��GC Roots�� ֱ�ӹ�������ʼ������������ͼ�Ĺ���,������̺�ʱ�ϳ����Dz���Ҫͣ���û��߳�,�����������ռ��߳�һ�����С� -
���±��(Remark) ��:�����ڲ�����ǽ���,����Ĺ����̻߳�������ռ��߳�ͬʱ���л��߽�������,���Ϊ��
������������ڼ�,���û�����������������±�Dz����䶯����һ���ֶ���ı�Ǽ�¼,����ε�ͣ��ʱ��ͨ����ȳ�ʼ��ǽ��Գ�һЩ,
��ҲԶ�Ȳ�����ǽε�ʱ��̡� -
�������( ConcurrentһSweep)��:�˽�==����ɾ������ǽ��жϵ��Ѿ������Ķ���,�ͷ��ڴ�ռ䡣==���ڲ���Ҫ�ƶ�������,���������Ҳ�ǿ������û��߳�ͬʱ������
-
-
����CMS�ռ������õ��Dz�������(�Ƕ�ռʽ),���������ʼ����Ǻ��ٴα��������������Ȼ��Ҫִ�С�StopһtheһWorld��������ͣ�����еĹ����߳�,������ͣʱ�䲢����̫��,
��˿���˵��Ŀǰ���е������ռ�������������ȫ����Ҫ��StopһtheһWorld��,ֻ�Ǿ����ܵ�������ͣʱ�䡣������ķ�ʱ��IJ�������벢������ζ�����Ҫ��ͣ����,����
����Ļ����ǵ�ͣ�ٵ��� -
����,�����������ռ����û��߳�û���ж�,������CMS���չ�����,��Ӧ��ȷ��Ӧ�ó����û��߳����㹻���ڴ���á����,CMS�ռ��������������ռ��������ȵ������������ȫ���������ٽ����ռ�,
���ǵ����ڴ�ʹ���ʴﵽijһ��ֵʱ,�㿪ʼ���л���,��ȷ��Ӧ�ó�����CMS������������Ȼ���㹻�Ŀռ�֧��Ӧ�ó������С�Ҫ��CMS�����ڼ�Ԥ�����ڴ������������Ҫ,�ͻ����һ�Ρ�Concurrent Mode Failure��ʧ��,
��ʱ�������������Ԥ��:��ʱ����Serial 0ld�ռ��������½���������������ռ�,����ͣ��ʱ��ͺܳ��ˡ� -
CMS�ռ����������ռ��㷨���õ���
�������㷨,����ζ��ÿ��ִ�����ڴ���պ�,
���ڱ�ִ���ڴ���յ����ö�����ռ�õ��ڴ�ռ伫�п����Dz�������һЩ�ڴ��,���ɱ���ؽ������һЩ�ڴ���Ƭ��
��ôCMS��Ϊ�¶�������ڴ�ռ�ʱ,����ʹ��ָ����ײ(Bump the Pointer) ����,
��ֻ�ܹ�ѡ������б�(Free List) ִ���ڴ���䡣 -
��ȻMark Sweep������ڴ���Ƭ,��ôΪʲô�����㷨����Mark Compact��?
����ʵ�ܼ��,��Ϊ�����������ʱ��,��Compact�����ڴ�Ļ�,ԭ�����û��߳�ʹ�õ��ڴ滹��ô����?Ҫ��֤�û��߳��ܼ���ִ��,ǰ��������е���Դ����Ӱ���Mark Compact���ʺϡ�Stop the World�����ֳ�������ʹ�� -
CMS���ŵ�:
- �����ռ�
- ���ӳ�
CMS�ı�:
- 1)
������ڴ���Ƭ,���²��������,�û��߳̿��õĿռ䲻�㡣������������������,���ò���ǰ����Full GC�� - 2)
CMS�ռ�����CPU��Դ�dz��������ڲ�����,����Ȼ���ᵼ���û�ͣ��,���ǻ���Ϊռ����һ�����̶߳�����Ӧ�ó������,���������ή�͡� - 3)
CMS�ռ����������������������ܳ��֡�Concurrent Mode Failure" ʧ�ܶ�������һ��Full GC�IJ�����
�ڲ�����ǽ����ڳ���Ĺ����̺߳������ռ��߳���ͬʱ���л��߽������е�,��ô�ڲ�����ǽ���������µ���������,
CMS�� ������Щ����������б��,���ջᵼ����Щ�²�������������û�б���ʱ����,�Ӷ�ֻ������һ��ִ��GCʱ�ͷ���Щ֮ǰδ�����յ��ڴ�ռ䡣
��������
-
һXX:+UseConcMarkSweepGC ʹ��CMS�ռ���
- ?�����ò�������Զ���һXX: +UseParNewGc����: ParNew (Young����) +CMS (0ld����) +Serial 0ld(��ѡ)����ϡ�
-
һXX:CMS1ni tiatingOccupanyFraction���ö��ڴ�ʹ���ʵ���ֵ,һ���ﵽ����ֵ,�㿪ʼ���л��ա�
- JDK5����ǰ�汾��Ĭ��ֵΪ68
- JDK6�����ϰ汾Ĭ��ֵΪ92
- ?����ڴ���������,���������һ���Դ��ֵ,�����ֵ������Ч����CMS�Ĵ���Ƶ��,������������յĴ������Խ�Ϊ���Եظ���Ӧ�ó������ܡ�
��֮,���Ӧ�ó����ڴ�ʹ���������ܿ�,��Ӧ�ý��������ֵ,�Ա���Ƶ����������������ռ��������ͨ����ѡ��������Ч����Full GC��ִ�д�����
-
һXX: +UseCMSCompactAtFullCollection����ָ����ִ����Full GC����ڴ�ռ����ѹ������,�Դ˱����ڴ���Ƭ�IJ��������������ڴ�ѹ����������������ִ��,���������������ͣ��ʱ���ø����ˡ�
-
һXX:CMSFullGCsBeforeCompaction������ִ�ж��ٴ�Full GC����ڴ�ռ����ѹ��������
-
һXX:ParallelCMSThreads ����CMS���߳�������
- CMS Ĭ���������߳�����(ParallelGCThreads+3)/4, ParallelGCThreads������������ռ������߳�������CPU��Դ�ȽϽ���ʱ,�ܵ�CMS�ռ����̵߳�Ӱ��,Ӧ�ó�����������������սο��ܻ�dz���⡣
-
�ж�ʹ����������������
- �������Ҫ
��С����ʹ���ڴ�Ͳ��п���,��ѡSerial GC;�����Ĭ��ʹ��SerialOld - �������Ҫ
���Ӧ�ó����������,��ѡParallel GC;�����Ĭ��ʹ��ParallelOld - �������Ҫ
��С��GC���жϻ�ͣ��ʱ��,��ѡCMS GC�������Ĭ��ʹ��ParNew ��ѡ SerialOld
- �������Ҫ
�� G1������:����/��������
��Ȼ�����Ѿ�����ǰ�漸��ǿ���GC,Ϊʲô��Ҫ����Garbage First (G1)GC?
? ?ԭ�������Ӧ�ó�����Ӧ�Ե�ҵ��Խ��Խ�Ӵ���,�û�Խ��Խ��,û��GC�Ͳ��ܱ�֤Ӧ�ó�����������,���������STW��GC�ָ�����ʵ�ʵ�����,���ԲŻ�ϵس��Զ�GC�����Ż���G1 (GarbageһFirst) ��������������Java7 update4֮�������һ���µ�����������,�ǵ����ռ���������չ����ǰ�سɹ�֮һ��
?���ͬʱ,Ϊ����Ӧ���ڲ���������ڴ�Ͳ������ӵĴ���������,��һ��������ͣʱ��(pause time) ,ͬʱ������õ���������
?�ٷ���G1�趨��Ŀ�������ӳٿɿ�(STW)������»�þ����ܸߵ�������,���Բŵ�����ȫ�����ռ�������������������
- ? ��ΪG1��һ�����л�����,���Ѷ��ڴ�ָ�Ϊ�ܶ��ص�����(Region) (������ ��������)��ʹ�ò�ͬ��Region����ʾEden���Ҵ���0��,�Ҵ���1��,������ȡ�
- ? G1 GC�мƻ��ر���������Java ���н���ȫ����������ռ���G1���ٸ���Region ����������ѻ��ļ�ֵ��С(��������õĿռ��С�Լ���������ʱ��),�ں�̨ά��һ�������б�,ÿ�������������ռ�ʱ��,���Ȼ��ռ�ֵ����Region��
- ? �������ַ�ʽ�IJ��ص�����������������Ŀ,�������Ǹ�G1һ������:��������(Garbage First)
- ? G1 (GarbageһFirst) ��һ����������Ӧ�õ������ռ���,��Ҫ����䱸���CPU���������ڴ�Ļ���,�Լ��߸�������GCͣ��ʱ���ͬʱ,����߸�������������������
- ? ��JDK1. 9�汾��ʽ����,��Oracle�ٷ���Ϊ��ȫ���ܵ������ռ����� ��
- ? ���ͬʱ,CMS�Ѿ���JDK 9�б����Ϊ����(deprecated) ����jdk8�л�����Ĭ�ϵ�����������,��Ҫʹ��һXX: +UseG1GC�����á�
����
-
��߲����벢��
- ?������: G1�ڻ����ڼ�,�����ж��GC�߳�ͬʱ����,��Ч���ö�˼�����������ʱ�û��߳�STW
- ?������: G1ӵ����Ӧ�ó�����ִ�е�����,���ֹ������Ժ�Ӧ�ó���ͬʱִ��,���,һ����˵,�������������սη�����ȫ����Ӧ�ó�������
-
�ִ��ռ�
- ?�ӷִ��Ͽ�,G1��Ȼ���ڷִ�������������,��������������������,�������Ȼ��Eden����Survivor�������ӶѵĽṹ,�Ͽ�,����Ҫ������Eden����������������������������,Ҳ���ټ�̶ֹ���С�̶�������
- ?���ѿռ��Ϊ���ɸ�����(Region) ,��Щ�����а��������ϵ���������������
- ?��֮ǰ�ĸ����������ͬ,��ͬʱ�����������������
-
�ռ�����
- ?CMS: �����һ������㷨���ڴ���Ƭ�����ɴ�GC�����һ����Ƭ����
- ?G1���ڴ滮��Ϊһ������region�� �ڴ�Ļ�������region��Ϊ������λ��.Region֮���Ǹ����㷨,��������ʵ�ʿɿ����DZ��-ѹ��(MarkһCompact)�㷨,�����㷨�����Ա����ڴ���Ƭ���������������ڳ���ʱ������,��������ʱ������Ϊ���ҵ������ڴ�ռ����ǰ������һ��GC�������ǵ�Java�ѷdz����ʱ��,G1�����Ƹ������ԡ�
-
��Ԥ���ͣ��ʱ��ģ��
- ����G1�����CMS����һ������,G1�������ͣ����,���ܽ�����Ԥ���ͣ��ʱ��ģ��,����ʹ������ȷָ����һ������ΪM�����ʱ��Ƭ����,�����������ռ��ϵ�ʱ�䲻�ó���N���롣
- ?���ڷ�����ԭ��,G1����ֻѡȡ������������ڴ����,������С�˻��յķ�Χ,��˶���ȫ��ͣ������ķ���Ҳ�ܵõ��ϺõĿ��ơ�
- ?G1���ٸ���Region����������ѻ��ļ�ֵ��С(��������õĿռ��С�� ����������ʱ��ľ���ֵ),�ں�̨ά��һ�������б�,ÿ�θ����������ռ�ʱ��,���Ȼ��ռ�ֵ����Region����֤��G1 �ռ���������ʱ���ڿ��Ի�ȡ�����ܸߵ��ռ�Ч�ʡ�
- ?�����CMSGC,G1δ��������CMS���������µ���ʱͣ��,����������Ҫ.�úܶࡣ
-
ȱ��
- �����CMS,G1�����߱�ȫ��λ��ѹ�������ơ��������û��������й�����,G1������Ϊ�������ռ��������ڴ�ռ��(Footprint) ���dz�������ʱ�Ķ���ִ�и���(overload) ��Ҫ��CMSҪ�ߡ�
- �Ӿ�������˵,��С�ڴ�Ӧ����CMS�ı��ִ���ʻ�����G1,��G1�ڴ��ڴ�Ӧ��,���������ơ�ƽ�����6-8GB֮�䡣
G1����������
-
�����GC (Young GC )
-
�����������ǹ���( Concurrent Marking)
-
��ϻ���(Mixed GC )
-
(�����Ҫ,���̡߳���ռʽ����ǿ�ȵ�Full GC���Ǽ������ڵġ������GC������ʧ���ṩ��һ��ʧ�ܱ�������,��ǿ�����ա�)
��������
- һXX:+UseG1GC �ֶ�ָ��ʹ��G1�ռ���ִ���ڴ��������
- һXX:G1HeapRegionSize ����ÿ��Region�Ĵ�С��ֵ��2����,��Χ��1MB ��32MB֮��,Ŀ���Ǹ�����С��Java�Ѵ�С���ֳ�Լ2048������Ĭ���Ƕ��ڴ��1/2000��
- һXX:MaxGCPauseMillis ���������ﵽ�����Gcͣ��ʱ��ָ��(JVM�ᾡ��ʵ��,������֤�ﵽ)��Ĭ��ֵ��200ms
- һxX:ParallelGCThread ����sTw.�����߳�����ֵ���������Ϊ8
- һXX:ConcGCThreads ���ò�����ǵ��߳�������n����Ϊ�������������߳���(ParallelGCThreads)��1/4���ҡ�
- һXX:Ini tiatingHeapOccupancyPercent ���ô�������GC���ڵ�Java��ռ������ֵ��������ֵ,�ʹ���GC��Ĭ��ֵ��45��
G1�������ij�����������
G1�����ԭ����Ǽ�JVM���ܵ���,������Աֻ��Ҫ������������ɵ���:
- ��һ��:����G1�����ռ���
- �ڶ���:���öѵ�����ڴ�
- ������:��������ͣ��ʱ��
G1���ṩ��������������ģʽ: YoungGC�� Mixed GC��Full GC, �ڲ�ͬ�������±�������
����
- ��������Ӧ��,��Ծ��д��ڴ桢�ദ�����Ļ�����
- ����Ҫ��Ӧ������Ҫ��GC�ӳ�,�����д�ѵ�Ӧ�ó����ṩ�������;
- ��:�ڶѴ�СԼ6GB�����ʱ,��Ԥ�����ͣʱ����Ե���0.5��; ( G1ͨ��ÿ��ֻ����һ���ֶ�����ȫ����Region������ʽ��������֤ÿ��GCͣ��ʱ�䲻�����)��
- �����滻��JDK1.5�е�CMS�ռ���; ����������ʱ,ʹ��G1���ܱ�CMS��:
�ٳ���50%��Java�ѱ������ռ��;
�ڶ������Ƶ�ʻ��������Ƶ�ʱ仯�ܴ�;
��GCͣ��ʱ�����(����0. 5��1��)�� - HotSpot�����ռ�����,����G1����,�����������ռ���ʹ�����õ�JVM�߳�ִ�� GC�Ķ��̲߳���,��G1 GC���Բ���Ӧ���̳߳е���̨���е�GC����,����JVM��GC�̴߳����ٶ���ʱ,ϵͳ�����Ӧ�ó����̰߳��������������չ��̡�
����region,������
ʹ��G1�ռ���ʱ,��������Java�ѻ��ֳ�Լ2048����С��ͬ�Ķ���Region��,ÿ��Region���С���ݶѿռ��ʵ�ʴ�С����,���屻������1MB��32MB֮��,��Ϊ2��N����,��1MB, 2MB, 4MB, 8MB, 1 6MB, 32MB������ͨ��һ XX:G1HeapRegionSize�趨�����е�Region��С��ͬ,����JVM���������ڲ��ᱻ�ı䡣
?��Ȼ����������������������ĸ���,��������������������������������,���Ƕ���һ����Region (����Ҫ����)�ļ��ϡ�ͨ��Region�Ķ�̬���䷽ʽʵ����_�ϵ�������
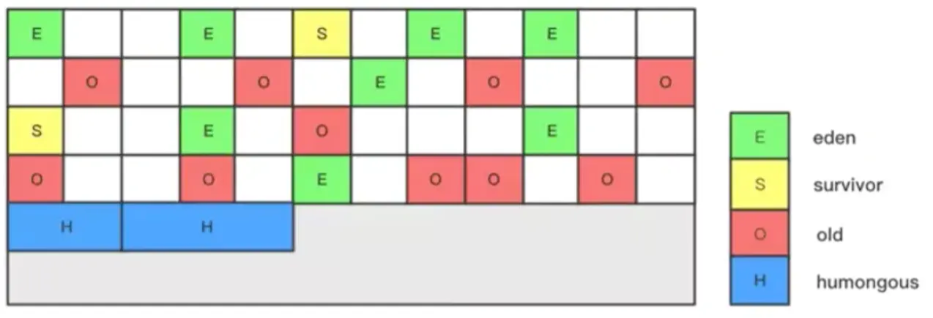
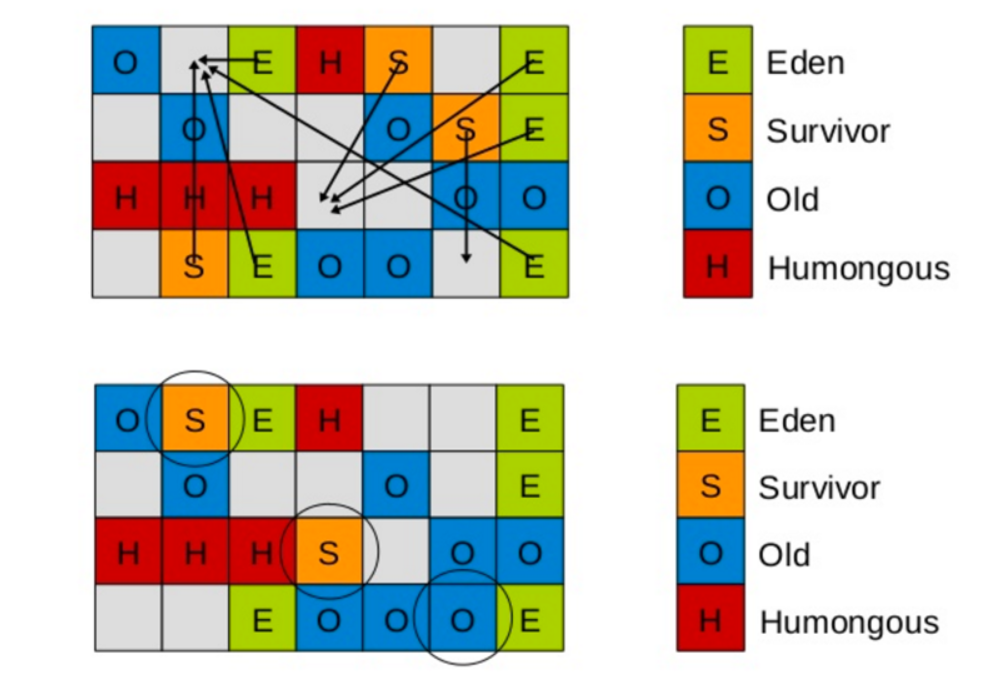
һ��region �п�������Eden, Survivor ����0ld/Tenured �ڴ�������һ��regionֻ��������һ����ɫ��ͼ�е�E��ʾ��region����Eden�ڴ�����,s��ʾ����Survivor�ڴ�����,0��ʾ����0ld�ڴ�����ͼ�пհı�ʾδʹ�õ��ڴ�ռ䡣
G1�����ռ�����������һ���µ��ڴ�����,����Humongous�ڴ�����,��ͼ�е�H�顣��Ҫ���ڴ洢�����,�������1. 5��region,�ͷŵ�H��
����H��ԭ��:
- ���ڶ��еĴ����,Ĭ��ֱ�ӻᱻ���䵽�����,�����������һ�����ڴ��ڵĴ����,�ͻ�������ռ�����ɸ���Ӱ�졣Ϊ�˽���������,G1������һ��Humongous��,������ר�Ŵ�Ŵ�������һ��H��װ����һ�������,��ôG1��Ѱ��������H�����洢��Ϊ�����ҵ�������H��,��ʱ�ò�����Full GC��G1�Ĵ������Ϊ����H����Ϊ�������һ������������
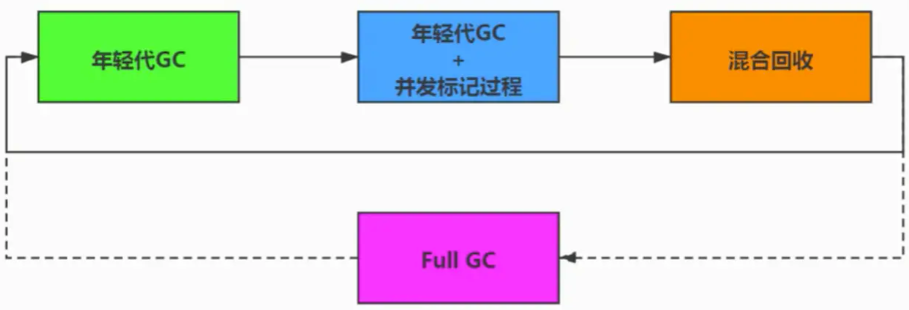
G1�������������չ���
G1 GC���������չ�����Ҫ����������������:
-
�����GC (Young GC )
-
�����������ǹ���( Concurrent Marking)
-
��ϻ���(Mixed GC )
-
(�����Ҫ,���̡߳���ռʽ����ǿ�ȵ�Full GC���Ǽ������ڵġ������GC������ʧ���ṩ��һ��ʧ�ܱ�������,��ǿ�����ա�)
-
-
Ӧ�ó�������ڴ�,���������Eden���þ�ʱ��ʼ��������չ���; G1��������ռ�����һ�����е���ռʽ�ռ������������������,G1 GC��ͣ����Ӧ�ó����߳�,�������߳�ִ����������ա�Ȼ�������������ƶ�������Survivor���������������,Ҳ�п������������䶼���漰��
-
�����ڴ�ʹ�ôﵽһ��ֵ(Ĭ��45%)ʱ,��ʼ�����������ǹ��̡�
-
���������Ͽ�ʼ��ϻ��չ��̡�����һ����ϻ�����,G1 GC�����������ƶ�������������,��Щ��������Ҳ�ͳ�Ϊ���������һ���֡����������ͬ,�������G1������������GC��ͬ,G1�����������������Ҫ���������������,һ��ֻ��Ҫɨ��/����һС�����������Region�Ϳ����ˡ�ͬʱ,��������Region�Ǻ������һ�� �����յġ�
-
�ٸ�����:һ��web������,Java���������ڴ�Ϊ4G,ÿ������Ӧ1500������,ÿ45���ӻ��·����Լ2G���ڴ档G1��ÿ45���ӽ���һ�����������,ÿ31 ��Сʱ�����ѵ�ʹ���ʻ�ﵽ45%,�Ὺʼ�����������ǹ���,�����ɺ�ʼ�ĵ���εĻ�ϻ��ա�
�� �ܽ�
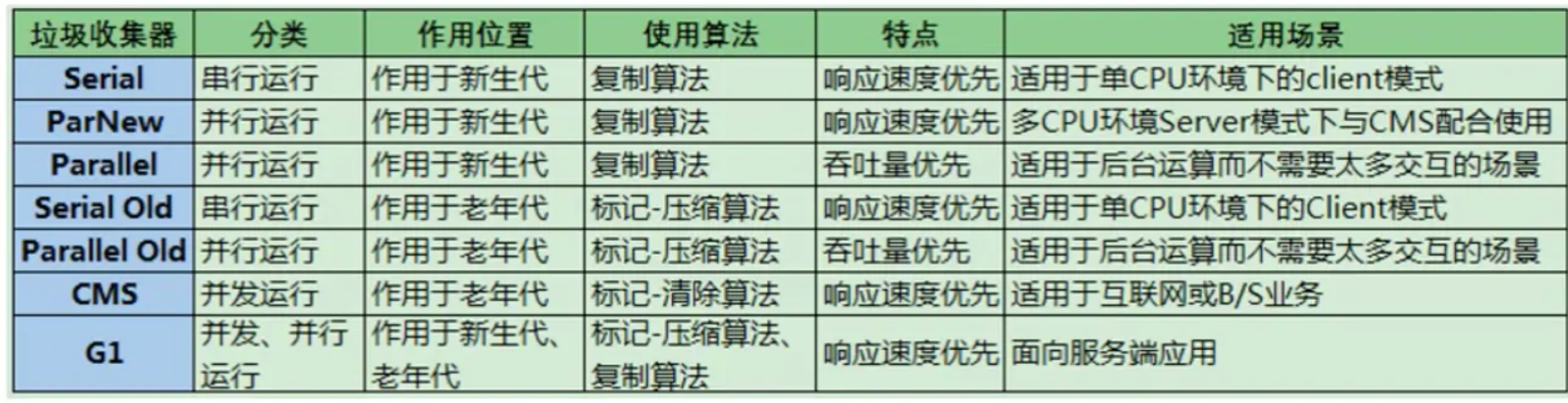
��ֹJDK 1.8,һ����7�ͬ�������ռ�����
1.�Ա�
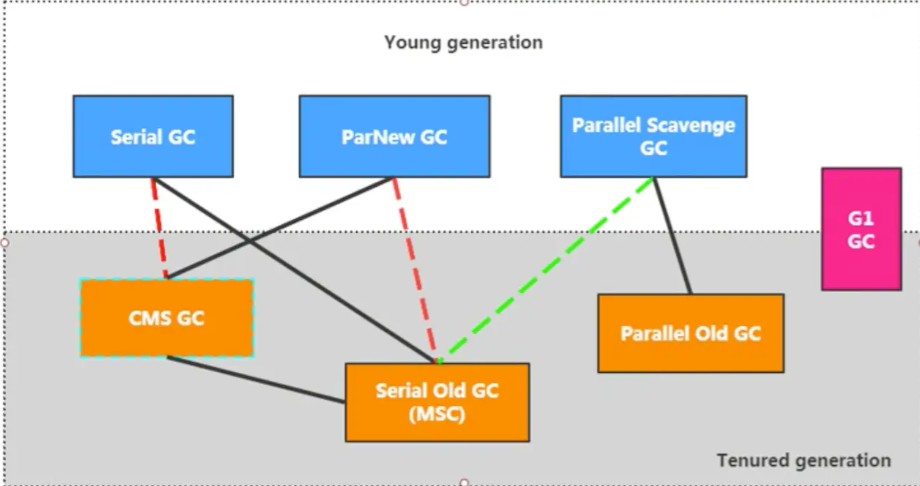
2.���
3.���ѡ��
- 1.���ȵ����ѵĴ�С��JVM����Ӧ��ɡ�
- 2.����ڴ�С��100M,ʹ�ô����ռ���
- 3.����ǵ��ˡ���������,����û��ͣ��ʱ���Ҫ��,�����ռ���
- 4.����Ƕ�CPU����Ҫ��������������ͣ��ʱ�䳬��1��,ѡ���л���JVM�Լ�ѡ��
- 5.����Ƕ�CPU�����ͣ��ʱ��,�������Ӧ(�����ӳٲ��ܳ���1��,�绥����Ӧ��),ʹ�ò����ռ���
- �ٷ��Ƽ�G1,���ܸߡ����ڻ���������Ŀ,��������ʹ��G1��
�����Ҫ��ȷ���۵�:
- 1.û����õ��ռ���,��û�����ܵ��ռ�;
- 2.������Զ������ض��������ض�����,������һ�����ݵ��ռ���
�� GC��־����
ͨ���Ķ�GC��־,���ǿ����˽�Java̓����ڴ��������ղ��ԡ��ڴ�������������յIJ����б�
-
-XX:+PrintGC ���GC��־�� ��ʾ�ܵ�GC�ѵı仯
-
��GC��־:-verbose:gc
-
���ֻ����ʾ�ܵ�GC�ѵı仯, ����:
-
���
[GC (Allocation Failure) 80832Kһ>19298K(227840K),0.0084018 secs] [GC (Metadata GC Threshold) 109499Kһ>21465K (228352K),0.0184066 secs] [Full GC (Metadata GC Threshold) 21 465Kһ>16716K (201728K),0.0619261 secs ] -
����
GC��Full GC: GC������,GCֻ���������Ͻ���,Full GC����������,������, ������� Allocation Failure: GC������ԭ�� 80832Kһ> 19298K:����GCǰ�Ĵ�С��GC��Ĵ�С�� 228840k:���ڵĶѴ�С�� 0.0084018 secs: GC������ʱ�䡣
-
-
-XX: +PrintGCDetails ���GC����ϸ��־
- ���
[GC (Allocation Failure) [ PSYoungGen: 70640Kһ> 10116K(141312K) ] 80541Kһ>20017K (227328K),0.0172573 secs] [Times: user=0.03 sys=0.00, real=0.02 secs ] [GC (Metadata GC Threshold) [PSYoungGen:98859Kһ>8154K(142336K) ] 108760Kһ>21261K (228352K), 0.0151573 secs] [Times: user=0.00 sys=0.01, real=0.02 secs] [Full GC (Metadata GC Threshold) [PSYoungGen: 8154Kһ>0K(142336K) ] [ParOldGen: 13107Kһ>16809K(62464K) ] 21261Kһ>16809K (204800K),[Metaspace: 20599Kһ>20599K (1067008K) ],0.0639732 secs] [Times: user=0.14 sys=0.00, real=0.06 secs]- ����:
PSYoungGen:ʹ����Parallel Scavenge���������ռ�����������GCǰ���С�ı仯 ParOldGen:ʹ����Parallel Old���������ռ����������Gcǰ���С�ı仯 Metaspace: Ԫ������GCǰ���С�ı仯,JDK1.8�������� Ԫ��������������ô� xxx secs : ָGc���ѵ�ʱ�� Times: user: ָ���������ռ������ѵ�����CPUʱ��,sys: �����ڵȴ�ϵͳ���û�ϵͳ�¼���ʱ��, real :GC�ӿ�ʼ��������ʱ��,������������ռ��ʱ��Ƭ��ʵ��ʱ�䡣 -
-XX: +PrintGCTimeStamps ���GC��ʱ���(�Ի�ʱ�����ʽ)
- ��GC��־:
һverbose:gc һXX: +PrintGCDetails һXX:+PrintGCTimeStamps һ XX: +PrintGCDateStamps - ������Ϣ����:
2019һ09һ24T22:15:24.518+0800:3.287: [GC(Allocation Failure) [ PSYoungGen: 1361 62Kһ>5113K(136192K) ] 141425Kһ>17632K (222208K) ,0.0248249 secs] [Times: user=0.05sys=0.00, real=0.03 secs ] 2019һ09һ24T22:15:25.559+0800:4.329: [ GC(Metadata GC Threshold)[PSYoungGen:97578Kһ>10068K(274944K) ] 110096Kһ>22658K (360960K),0.0094071 secs] [Times: user=0. 00sys=0.00, real=0. 01 secs] 2019һ09һ24T22:15:25.569+0800:4.338: [Full GC (Metadata GC Threshold)[ PSYoungGen:10068Kһ>0K(274944K) ] [ ParoldGen: 12590Kһ>13564K (56320K) ] 22658Kһ>13564K (331264K) , [Metaspace: 20590Kһ>20590K(1067008K)], 0. 0494875 secs] [Times: user=0.17 sys=0. 02,real=0.05 secs ] - ��GC��־:
-
-XX: +PrintGCDateStamps���GC��ʱ���(�����ڵ���ʽ,��2013һ05һ04T21 : 53:59.234+0800 )
-
-XX: +PrintHeapAtGC �ڽ���GC��ǰ���ӡ���ѵ���Ϣ
-
-Xloggc:. . /logs/gc. log��־�ļ������·��
��־��������ʹ��
������һЩ����ȥ������Щgc��־��
���õ���־����.������: GCViewer��GCEasy��GCHisto��GCLogViewer ��Hpjmeter��garbagecat�ȡ�
X �������������·�չ
GC��Ȼ���ڷ��ٷ�չ֮��,Ŀǰ��Ĭ��ѡ��G1 GC�ڲ��ϵĽ��иĽ�,�ܶ�����ԭ����Ϊ��ȱ��,���紮�е�Full GC��Card Tableɨ��ĵ�Ч��,���Ѿ�������Ľ�,����,JDK 10�Ժ�,Fu1l GC�Ѿ��Dz�������,�ںܶೡ����,����ֻ�������Parallel GC�IJ���Full GCʵ�֡�
?��ʹ��Serial GC,��Ȼ�ȽϹ���,���Ǽ���ƺ�ʵ��δ�ؾ��ǹ�ʱ��,�������Ŀ���,������GC������ݽṹ�Ŀ���,�����̵߳Ŀ���,���Ƿdz�С��,���������Ƽ��������,��Serverless���µ�Ӧ�ó�����,Serial GC�ҵ����µ���̨��
?�Ƚϲ��ҵ���CMS GC, ��Ϊ���㷨������ȱ�ݵ�ԭ��,��Ȼ���ڻ��зdz�����û�Ⱥ��,����JDK9���Ѿ������Ϊ����,����JDK14�汾���Ƴ���
JDK11 ������
- JEP318 : Epsilon: A NoһOp Garbage Collector (Epsilon ����������,"NoһOp (����) "������) http: / /openidk.java.net/ieps/318
- JEP333: ZGC: A Scalable Lowһ Latency ;Garbage Collector (Experimental) ( ZGC:����s�ĵ����˸p�������,���������Խ�)
Open JDK12��Shenandoah GC
- ����G1�������ѳ�ΪĬ�ϻ������ü����ˡ�
- ���ǻ������������������µ��ռ���: ZGC ( JDK11����)��Shenandoah(Open JDK12) ��
- ?�����ص�:��ͣ��ʱ��
Open JDK12 ��Shenandoah GC:��ͣ��ʱ���GC (ʵ����)
- Shenandoah,�������ڶ�GC����¶���һ�����ǵ�һ���Oracle��˾�Ŷ��쵼������HotSpot�����ռ��������ɱ�����ܵ��ٷ����ż�������ų�OpenJDK��OracleJDKû�������Oracle��˾�Ծܾ���OracleJDK12��֧��Shenandoah��
- Shenandoah���������������RedHat���е�һ���� ���ռ����о���ĿPauselessGC��ʵ��,ּ�����JVM�ϵ��ڴ����ʵ�ֵ�ͣ�ٵ�������2014�깱��OpenJDK��
- Red Hat�з�Shenandoah�ŶӶ�������,Shenandoah�� ������������ͣʱ����Ѵ�С��,����ζ�����۽�������Ϊ200MB����200GB,99.9%��Ŀ�궼���������ռ���ͣ��ʱ��������ʮ�������ڡ�����ʵ��ʹ�����ܽ�ȡ����ʵ�ʹ����ѵĴ�С�������ء�
- [����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-Ghu7kbOw-1649145193481)(https://user-gold-cdn.xitu.io/2020/6/28/172f8949968d9d3e?imageView2/0/w/1280/h/960/format/webp/ignore-error/1)]
- ����RedHat��2016�귢������������,����������ʹ��Es��200GB��ά���ٿ����ݽ����������ӽ����:
- ͣ��ʱ������������ռ���ȷʵ�����ʵķ�Ծ,��Ҳδʵ�����ͣ��ʱ�������ʮ�������ڵ�Ŀ�ꡣ
- ��������������������Ե��½�,������ʱ�������в����ռ�������ġ�
- Shenandoah GC������:�����и����µ��������½���
- Shenandoah GC��ǿ��:���ӳ�ʱ�䡣
�����Ե�ZGC
��������
?ZGC��ShenandoahĿ��߶�����,�ھ����ܶ�������Ӱ�첻���ǰ����,ʵ����������ڴ��С�¶����������ռ���ͣ��ʱ��������ʮ�������ڵĵ��ӳ١�
?����������Java�������һ������������ZGC: ZGC�ռ�����һ�����Region�ڴ沼�ֵ�,(��ʱ) ����ִ���,ʹ���˶����ϡ�Ⱦɫָ����ڴ����ӳ��ȼ�����ʵ�ֿɲ����ı��һѹ���㷨��,�Ե��ӳ�Ϊ��ҪĿ���һ�������ռ�����
?ZGC�Ĺ������̿��Է�Ϊ4����:�������һ����Ԥ���ط���һ�����ط���һ������ӳ��ȡ�
?ZGC���������еط�����ִ�е�,���˳�ʼ��ǵ���sTW�ġ�����ͣ��ʱ��.�����ͺķ��ڳ�ʼ�����,�ⲿ�ֵ�ʵ��ʱ���Ƿdz��ٵġ�
����������ͼ:
���ƱȽ� [����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-7LwZTZ7A-1649145193481)(https://user-gold-cdn.xitu.io/2020/6/28/172f894ed354442d?imageView2/0/w/1280/h/960/format/webp/ignore-error/1)]
���ƱȽ� [����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-P6ByfijR-1649145193481)(https://user-gold-cdn.xitu.io/2020/6/28/172f895334a0a7b8?imageView2/0/w/1280/h/960/format/webp/ignore-error/1)]
��ZGC��ǿ��ͣ��ʱ�������,����������Ľ�Parallel��G1�����������������IJ�ࡣ����ƽ��ͣ�١�958ͣ�١�998ͣ�١�99. 98ͣ��,�������ͣ��ʱ��,ZGC ���ܺ����Ѿ�������10�������ڡ�
JDK14������
JEP 364: ZGCӦ����macOS��
JEP 365: ZGCӦ����windows�� JDK14֮ǰ,ZGC��Linux��֧��
- ��������ʹ��ZGC���û���ʹ����Linux�Ļ���,����Windows��macOS ��,����Ҳ��ҪZGC���п�������Ͳ��ԡ���������Ӧ��Ҳ���Դ�ZGC�����档���,ZGC���Ա���ֲ����Windows��macOs.�ϡ�
- ����mac��Windows ��Ҳ��ʹ��zGC��,ʾ������: һXX: +Unloc kExperimentalVMOptions һXX: +UseZGC .
��������������:AliGC
AliGC�ǰ���Ͱ�JVM�Ŷӻ���G1�㷨,�� ����(LargeHeap)Ӧ�ó�����ָ�������µĶԱ�: [����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-BhvuPKio-1649145193482)(https://user-gold-cdn.xitu.io/2020/6/28/172f89618e0f433e?imageView2/0/w/1280/h/960/format/webp/ignore-error/1)] ��Ȼ,��������Ҳ�ṩ�˸��ֶ���һ���GCʵ��,����Ƚ������ĵ��ӳ�GC