目录
一、概述
RocketMQ中的消息存储在本地文件系统中,主要是由ConsumeQueue和CommitLog配合完成的,消息真正的物理存储文件是CommitLog,ConsumeQueue是消息的逻辑队列,类似数据库的索引文件,存储的是指向物理存储的地址。每个Topic下的每个Message Queue都有一个对应的ConsumeQueue文件。
来看一张RocketMQ消息存储整体架构图:
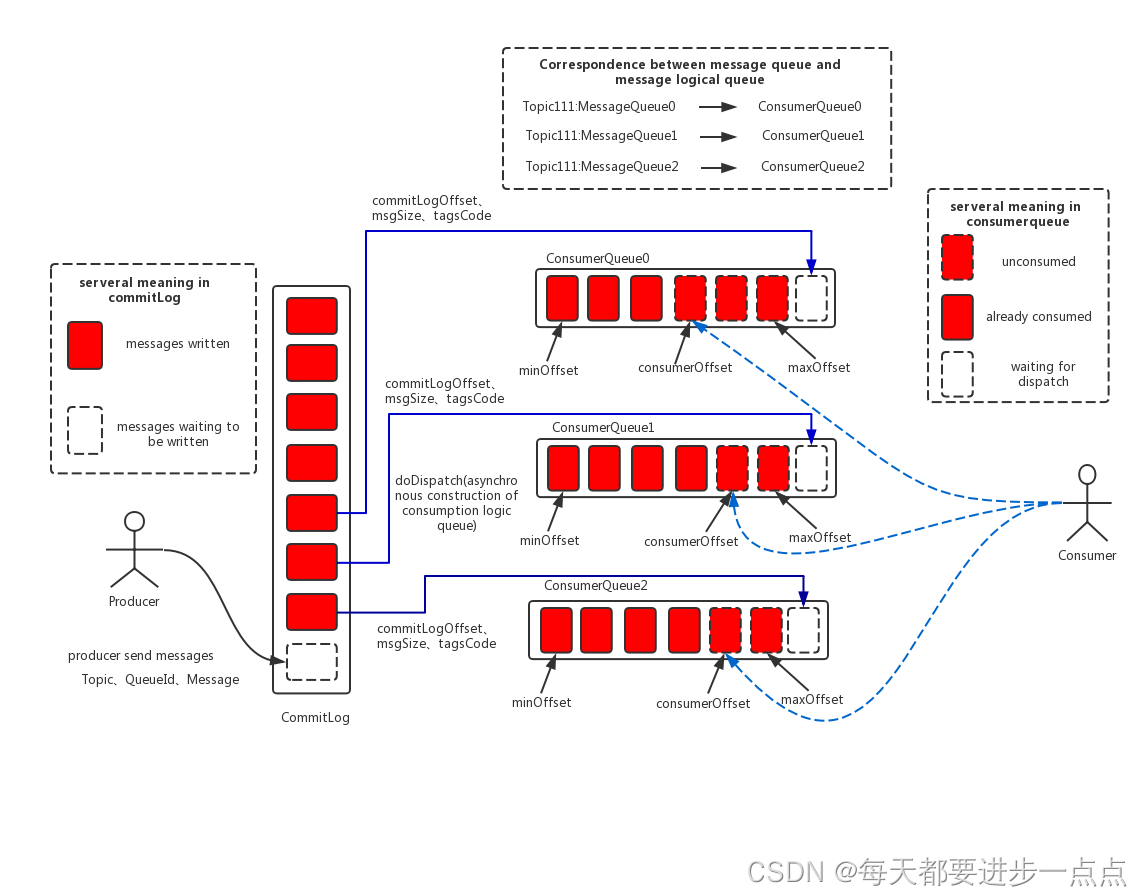
我们可以在broker的配置文件中配置store存储的目录。例如前面搭建RocketMQ时我们就自定义了存储目录。
#存储路径
storePathRootDir=/rocketmq/rocketmq-4.9.2/store
#commitLog 存储路径
storePathCommitLog=/rocketmq/rocketmq-4.9.2/store/commitlog
#消费队列存储路径存储路径
storePathConsumeQueue=/rocketmq/rocketmq-4.9.2/store/consumequeue
#消息索引存储路径
storePathIndex=/rocketmq/rocketmq-4.9.2/store/index
#checkpoint 文件存储路径
storeCheckpoint=/rocketmq/rocketmq-4.9.2/store/checkpoint
#abort 文件存储路径
abortFile=/rocketmq/rocketmq-4.9.2/store/abort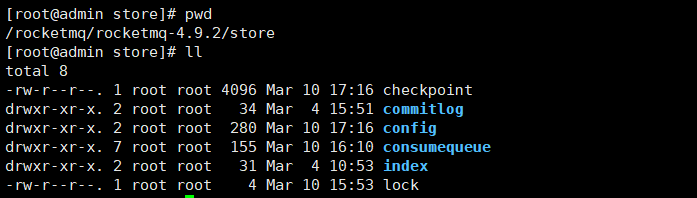
分别介绍一下各个文件夹/文件的含义:
- abort:该文件在Broker启动后会自动创建,正常关闭Broker,该文件会自动消失。若在没有启动 Broker的情况下,发现这个文件是存在的,则说明之前Broker的关闭是非正常关闭;
- checkpoint:其中存储着commitlog、consumequeue、index文件的最后刷盘时间戳;
- commitlog:其中存放着commitlog文件,而消息是写在commitlog文件中的;
- config:存放着Broker运行期间的一些配置数据;
- consumequeue:其中存放着consumequeue文件,队列就存放在这个目录中;
- index:其中存放着消息索引文件indexFile;
lock:运行期间使用到的全局资源锁;
二、CommitLog文件
CommitLog是消息主体以及元数据的存储主体,存储Producer端写入的消息主体内容,消息内容不是定长的。单个文件大小默认1G, 文件名长度为20位,左边补零,剩余为起始偏移量,比如00000000000000000000代表了第一个文件,起始偏移量为0,文件大小为1G=1073741824;当第一个文件写满了,第二个文件为00000000001073741824,起始偏移量为1073741824,以此类推。消息主要是顺序写入日志文件,当文件满了,写入下一个文件。

需要注意的是,一个Broker中仅包含一个commitlog目录,所有的mappedFile文件都是存放在该目录中 的。即无论当前Broker中存放着多少Topic的消息,这些消息都是被顺序写入到了mappedFile文件中。
RocketMQ利用“零拷贝”技术,提高消息存盘和网络发送的速度。这里需要注意的是,采用MappedByteBuffer这种内存映射的方式有几个限制,其中之一是一次只能映射1.5~2G 的文件至用户态的虚拟内存,这也是为何RocketMQ默认设置单个CommitLog日志数据文件为1G的原因。
三、ConsumerQueue消费逻辑队列
ConsumerQueue是消息消费队列,引入的目的主要是提高消息消费的性能,由于RocketMQ是基于主题topic的订阅模式,消息消费是针对主题进行的,如果要遍历commitlog文件中根据topic检索消息是非常低效的。Consumer即可根据ConsumeQueue来查找待消费的消息。其中,ConsumeQueue(逻辑消费队列)作为消费消息的索引,保存了指定Topic下的队列消息在CommitLog中的起始物理偏移量offset,消息大小size和消息Tag的HashCode值。consumequeue文件可以看成是基于topic的commitlog索引文件,故consumequeue文件夹的组织方式如下:topic/queue/file三层组织结构:
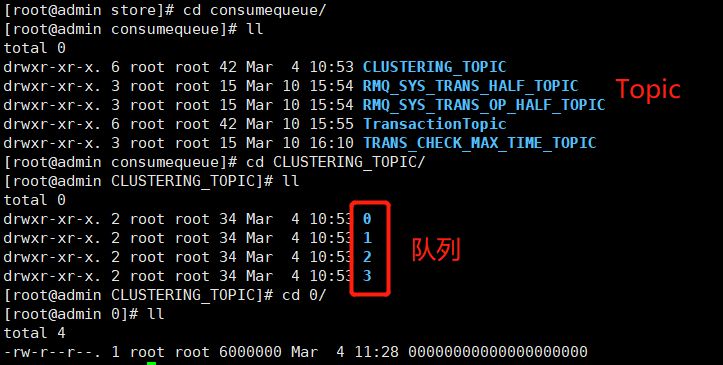
如下图,可以看到一个consumequeue中的索引条目结构为:

同样consumequeue文件采取定长设计,单个consumequeue文件由30W个索引条目组成。每一个索引条目包含了三个重要属性:消息在commitlog中的偏移量(8字节)、消息长度(4字节)、消息Tag的hashcode值(8字节)。可以像数组一样随机访问每一个索引条目,每个索引条目这三个属性占20个字节,所以每个ConsumeQueue文件的大小是固定的30w * 20字节,约5.72M。
四、IndexFile索引文件
除了通过通常的指定Topic进行消息消费外,RocketMQ还提供了根据key进行消息查询的功能。该查询是通过store目录中的index子目录中的indexFile进行索引实现的快速查询。当然,这个indexFile中的索引数据是在包含了key的消息被发送到Broker时写入的。如果消息中没有包含key,则不会写入。

RocketMQ的索引文件逻辑结构,类似JDK中HashMap的实现。索引文件的具体结构如下:
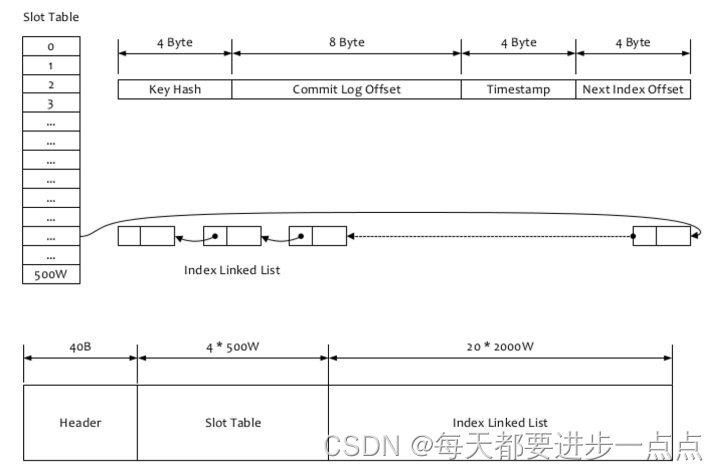
每个Broker中会包含一组indexFile,每个indexFile都是以一个时间戳命名的(这个indexFile被创建时的时间戳),文件大小是固定的。如果消息的properties中设置了UNIQ_KEY这个属性,就用 topic + “#” + UNIQ_KEY的value作为 key 来做写入操作。如果消息设置了KEYS属性(多个KEY以空格分隔),也会用 topic + “#” + KEY 来做索引。
其中的索引数据包含了Key Hash、CommitLog Offset、Timestamp、NextIndex offset 这四个字段,一共20 字节。NextIndex offset 即前面读出来的slotValue,如果有 hash冲突,就可以用这个字段将所有冲突的索引用链表的方式串起来了。Timestamp记录的是消息storeTimestamp之间的差,并不是一个绝对的时间。整个Index File的结构如图,40 Byte 的Header用于保存一些总的统计信息,4*500W的 Slot Table并不保存真正的索引数据,而是保存每个槽位对应的单向链表的头。20*2000W 是真正的索引数据,即一个 Index File 可以保存 2000W个索引。
五、页缓存与内存映射
页缓存(PageCache)是OS对文件的缓存,用于加速对文件的读写。一般来说,程序对文件进行顺序读写的速度几乎接近于内存的读写速度,主要原因就是由于OS使用PageCache机制对读写访问操作进行了性能优化,将一部分的内存用作PageCache。对于数据的写入,OS会先写入至Cache内,随后通过异步的方式由pdflush内核线程将Cache内的数据刷盘至物理磁盘上。对于数据的读取,如果一次读取文件时出现未命中PageCache的情况,OS从物理磁盘上访问读取文件的同时,会顺序对其他相邻块的数据文件进行预读取。
在RocketMQ中,ConsumeQueue逻辑消费队列存储的数据较少,并且是顺序读取,在page cache机制的预读取作用下,Consume Queue文件的读性能几乎接近读内存,即使在有消息堆积情况下也不会影响性能。而对于CommitLog消息存储的日志数据文件来说,读取CommitLog消息内容时候会产生较多的随机访问读取,严重影响性能。如果选择合适的系统IO调度算法,比如设置调度算法为“Deadline”(此时块存储采用SSD的话),随机读的性能也会有所提升。
另外,RocketMQ主要通过MappedByteBuffer(零拷贝)对文件进行读写操作。其中,利用了NIO中的FileChannel模型将磁盘上的物理文件直接映射到用户态的内存地址中(这种Mmap的方式减少了传统IO将磁盘文件数据在操作系统内核地址空间的缓冲区和用户应用程序地址空间的缓冲区之间来回进行拷贝的性能开销),将对文件的操作转化为直接对内存地址进行操作,从而极大地提高了文件的读写效率(正因为需要使用内存映射机制,故RocketMQ的文件存储都使用定长结构来存储,方便一次将整个文件映射至内存)。

